 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Real-time Health Monitoring of Heat Exchangers using Hypernetworks and PINNs
Dec 20, 2022

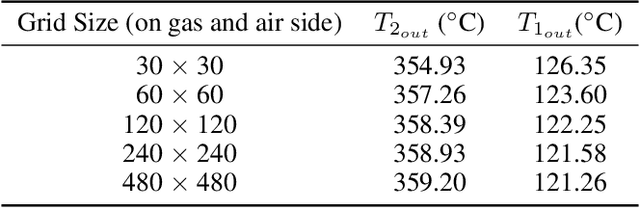
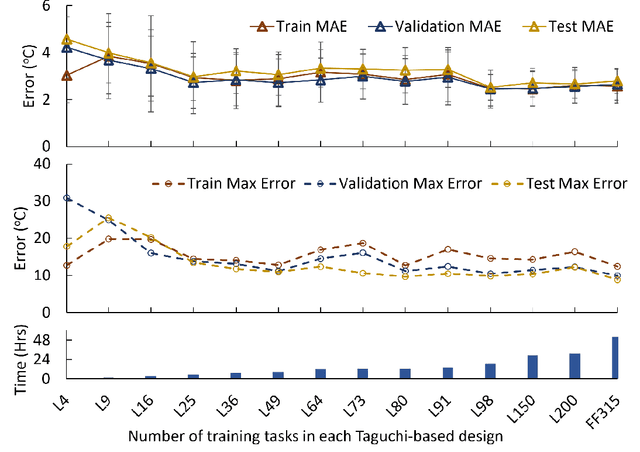
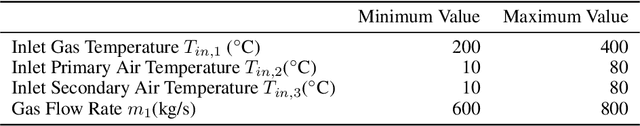
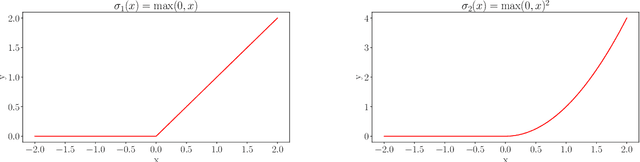
We demonstrate a Physics-informed Neural Network (PINN) based model for real-time health monitoring of a heat exchanger, that plays a critical role in improving energy efficiency of thermal power plants. A hypernetwork based approach is used to enable the domain-decomposed PINN learn the thermal behavior of the heat exchanger in response to dynamic boundary conditions, eliminating the need to re-train. As a result, we achieve orders of magnitude reduction in inference time in comparison to existing PINNs, while maintaining the accuracy on par with the physics-based simulations. This makes the approach very attractive for predictive maintenance of the heat exchanger in digital twin environments.
Predictions Based on Pixel Data: Insights from PDEs and Finite Differences
May 01, 2023
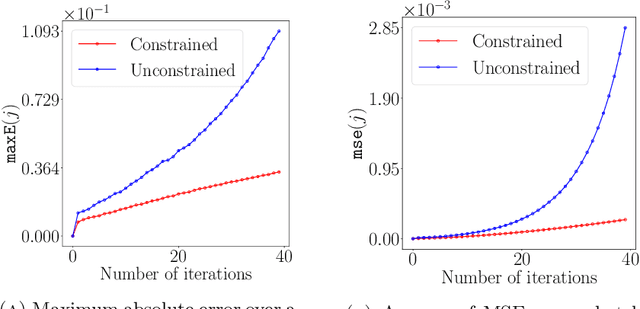
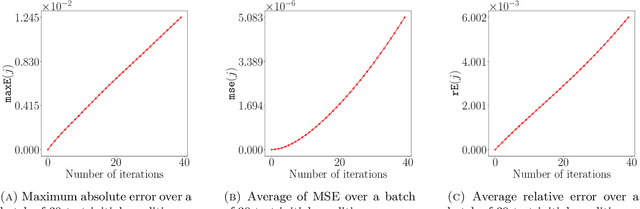
Neural networks are the state-of-the-art for many approximation tasks in high-dimensional spaces, as supported by an abundance of experimental evidence. However, we still need a solid theoretical understanding of what they can approximate and, more importantly, at what cost and accuracy. One network architecture of practical use, especially for approximation tasks involving images, is convolutional (residual) networks. However, due to the locality of the linear operators involved in these networks, their analysis is more complicated than for generic fully connected neural networks. This paper focuses on sequence approximation tasks, where a matrix or a higher-order tensor represents each observation. We show that when approximating sequences arising from space-time discretisations of PDEs we may use relatively small networks. We constructively derive these results by exploiting connections between discrete convolution and finite difference operators. Throughout, we design our network architecture to, while having guarantees, be similar to those typically adopted in practice for sequence approximation tasks. Our theoretical results are supported by numerical experiments which simulate linear advection, the heat equation, and the Fisher equation. The implementation used is available at the repository associated to the paper.
A Simplified Framework for Contrastive Learning for Node Representations
May 01, 2023
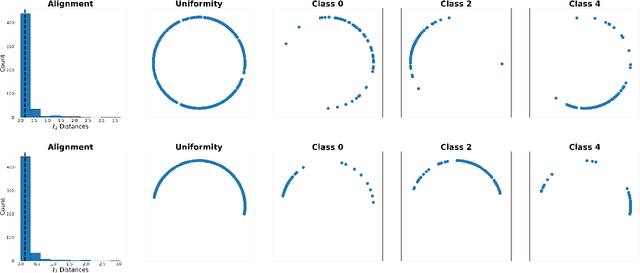
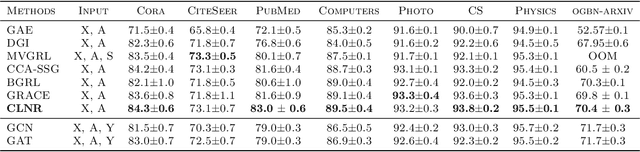
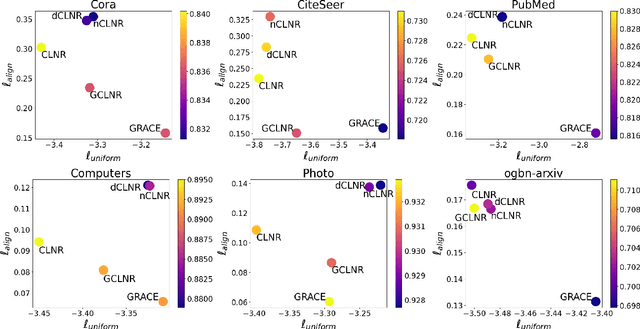
Contrastive learning has recently established itself as a powerful self-supervised learning framework for extracting rich and versatile data representations. Broadly speaking, contrastive learning relies on a data augmentation scheme to generate two versions of the input data and learns low-dimensional representations by maximizing a normalized temperature-scaled cross entropy loss (NT-Xent) to identify augmented samples corresponding to the same original entity. In this paper, we investigate the potential of deploying contrastive learning in combination with Graph Neural Networks for embedding nodes in a graph. Specifically, we show that the quality of the resulting embeddings and training time can be significantly improved by a simple column-wise postprocessing of the embedding matrix, instead of the row-wise postprocessing via multilayer perceptrons (MLPs) that is adopted by the majority of peer methods. This modification yields improvements in downstream classification tasks of up to 1.5% and even beats existing state-of-the-art approaches on 6 out of 8 different benchmarks. We justify our choices of postprocessing by revisiting the "alignment vs. uniformity paradigm", and show that column-wise post-processing improves both "alignment" and "uniformity" of the embeddings.
A Spectral Algorithm for List-Decodable Covariance Estimation in Relative Frobenius Norm
May 01, 2023We study the problem of list-decodable Gaussian covariance estimation. Given a multiset $T$ of $n$ points in $\mathbb R^d$ such that an unknown $\alpha<1/2$ fraction of points in $T$ are i.i.d. samples from an unknown Gaussian $\mathcal{N}(\mu, \Sigma)$, the goal is to output a list of $O(1/\alpha)$ hypotheses at least one of which is close to $\Sigma$ in relative Frobenius norm. Our main result is a $\mathrm{poly}(d,1/\alpha)$ sample and time algorithm for this task that guarantees relative Frobenius norm error of $\mathrm{poly}(1/\alpha)$. Importantly, our algorithm relies purely on spectral techniques. As a corollary, we obtain an efficient spectral algorithm for robust partial clustering of Gaussian mixture models (GMMs) -- a key ingredient in the recent work of [BDJ+22] on robustly learning arbitrary GMMs. Combined with the other components of [BDJ+22], our new method yields the first Sum-of-Squares-free algorithm for robustly learning GMMs. At the technical level, we develop a novel multi-filtering method for list-decodable covariance estimation that may be useful in other settings.
BCEdge: SLO-Aware DNN Inference Services with Adaptive Batching on Edge Platforms
May 01, 2023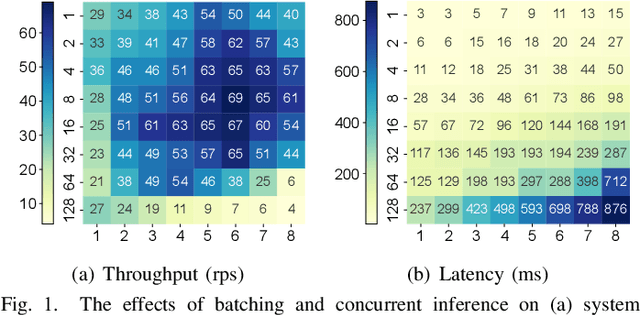
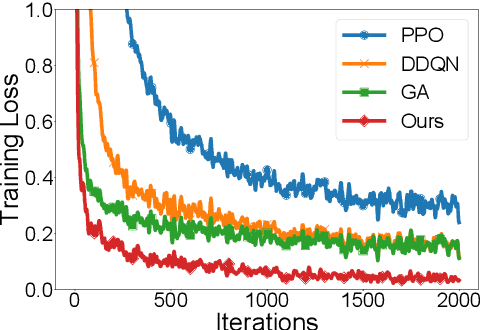
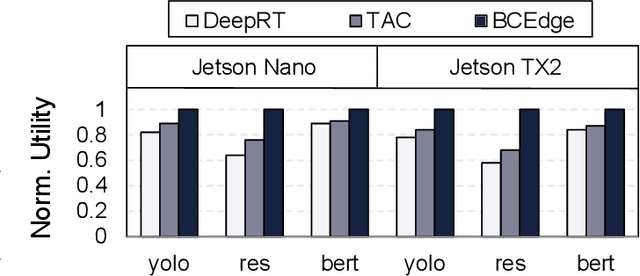
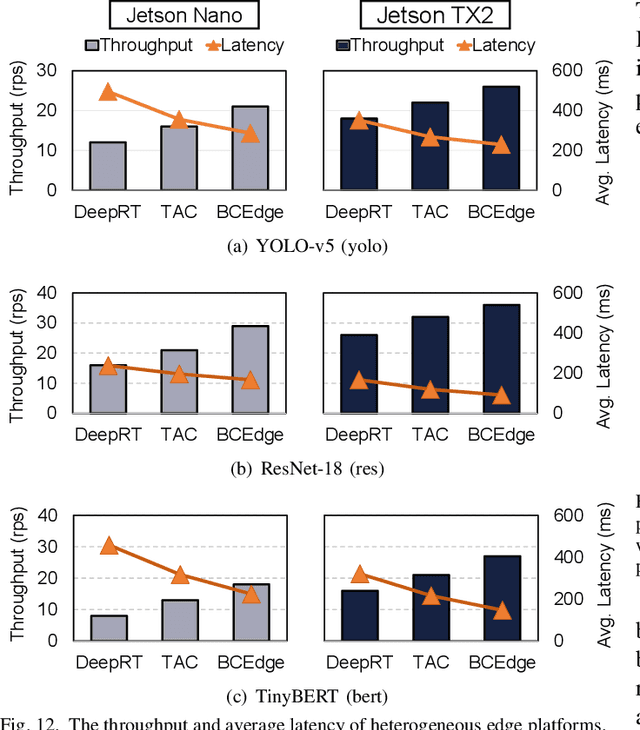
As deep neural networks (DNNs) are being applied to a wide range of edge intelligent applications, it is critical for edge inference platforms to have both high-throughput and low-latency at the same time. Such edge platforms with multiple DNN models pose new challenges for scheduler designs. First, each request may have different service level objectives (SLOs) to improve quality of service (QoS). Second, the edge platforms should be able to efficiently schedule multiple heterogeneous DNN models so that system utilization can be improved. To meet these two goals, this paper proposes BCEdge, a novel learning-based scheduling framework that takes adaptive batching and concurrent execution of DNN inference services on edge platforms. We define a utility function to evaluate the trade-off between throughput and latency. The scheduler in BCEdge leverages maximum entropy-based deep reinforcement learning (DRL) to maximize utility by 1) co-optimizing batch size and 2) the number of concurrent models automatically. Our prototype implemented on different edge platforms shows that the proposed BCEdge enhances utility by up to 37.6% on average, compared to state-of-the-art solutions, while satisfying SLOs.
Meat Freshness Prediction
May 01, 2023
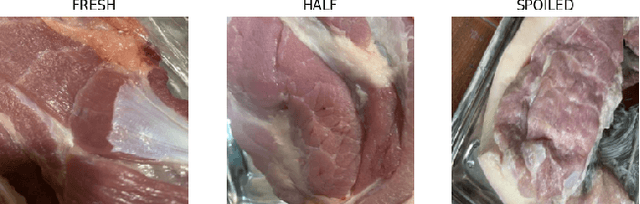
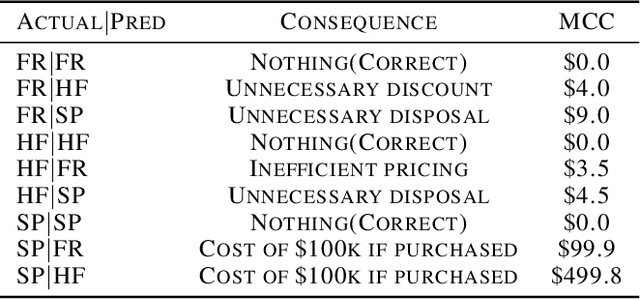
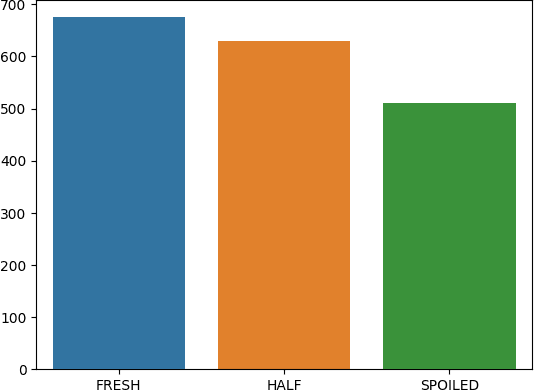
In most retail stores, the number of days since initial processing is used as a proxy for estimating the freshness of perishable foods or freshness is assessed manually by an employee. While the former method can lead to wastage, as some fresh foods might get disposed after a fixed number of days, the latter can be time-consuming, expensive and impractical at scale. This project aims to propose a Machine Learning (ML) based approach that evaluates freshness of food based on live data. For the current scope, it only considers meat as a the subject of analysis and attempts to classify pieces of meat as fresh, half-fresh or spoiled. Finally the model achieved an accuracy of above 90% and relatively high performance in terms of the cost of misclassification. It is expected that the technology will contribute to the optimization of the client's business operation, reducing the risk of selling defective or rotten products that can entail serious monetary, non-monetary and health-based consequences while also achieving higher corporate value as a sustainable company by reducing food wastage through timely sales and disposal.
Task-oriented Memory-efficient Pruning-Adapter
Mar 26, 2023

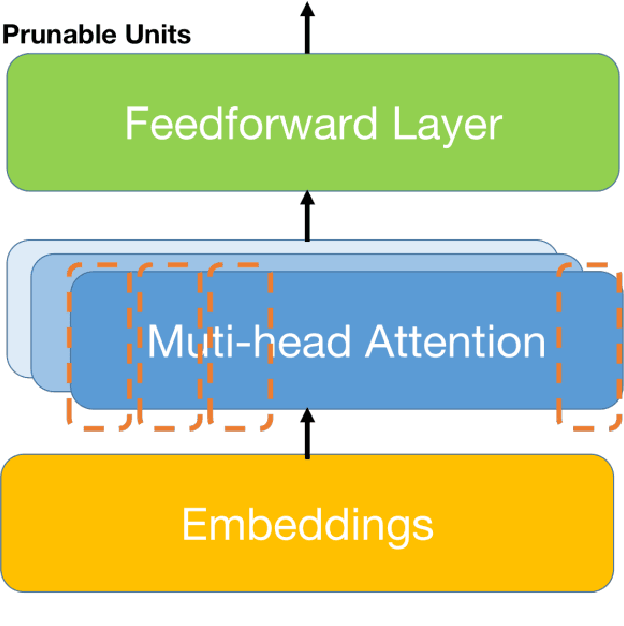

The Outstanding performance and growing size of Large Language Models has led to increased attention in parameter efficient learning. The two predominant approaches are Adapters and Pruning. Adapters are to freeze the model and give it a new weight matrix on the side, which can significantly reduce the time and memory of training, but the cost is that the evaluation and testing will increase the time and memory consumption. Pruning is to cut off some weight and re-distribute the remaining weight, which sacrifices the complexity of training at the cost of extremely high memory and training time, making the cost of evaluation and testing relatively low. So efficiency of training and inference can't be obtained in the same time. In this work, we propose a task-oriented Pruning-Adapter method that achieve a high memory efficiency of training and memory, and speeds up training time and ensures no significant decrease in accuracy in GLUE tasks, achieving training and inference efficiency at the same time.
Kullback-Leibler Maillard Sampling for Multi-armed Bandits with Bounded Rewards
Apr 28, 2023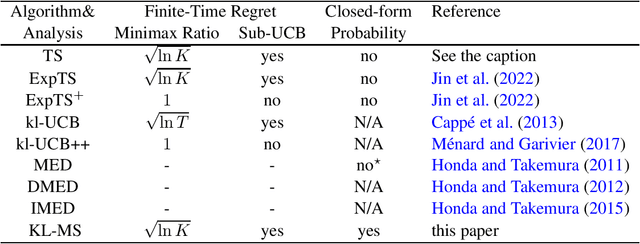
We study $K$-armed bandit problems where the reward distributions of the arms are all supported on the $[0,1]$ interval. It has been a challenge to design regret-efficient randomized exploration algorithms in this setting. Maillard sampling~\cite{maillard13apprentissage}, an attractive alternative to Thompson sampling, has recently been shown to achieve competitive regret guarantees in the sub-Gaussian reward setting~\cite{bian2022maillard} while maintaining closed-form action probabilities, which is useful for offline policy evaluation. In this work, we propose the Kullback-Leibler Maillard Sampling (KL-MS) algorithm, a natural extension of Maillard sampling for achieving KL-style gap-dependent regret bound. We show that KL-MS enjoys the asymptotic optimality when the rewards are Bernoulli and has a worst-case regret bound of the form $O(\sqrt{\mu^*(1-\mu^*) K T \ln K} + K \ln T)$, where $\mu^*$ is the expected reward of the optimal arm, and $T$ is the time horizon length.
X-RLflow: Graph Reinforcement Learning for Neural Network Subgraphs Transformation
Apr 28, 2023
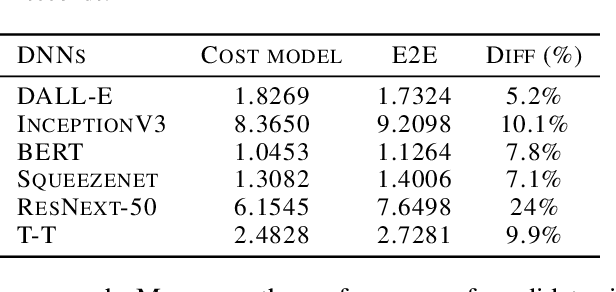
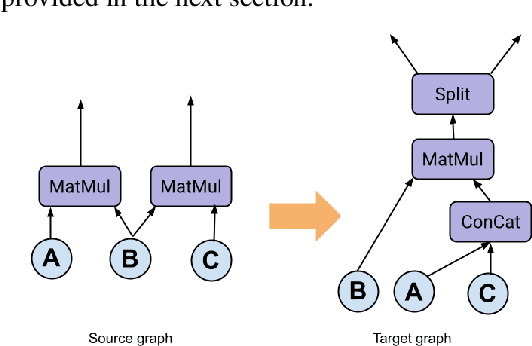
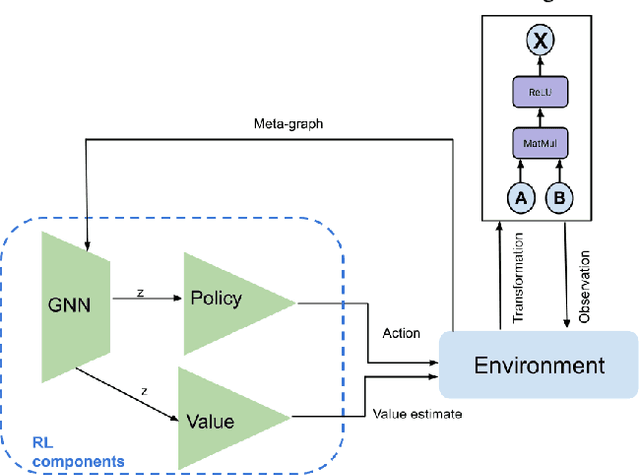
Tensor graph superoptimisation systems perform a sequence of subgraph substitution to neural networks, to find the optimal computation graph structure. Such a graph transformation process naturally falls into the framework of sequential decision-making, and existing systems typically employ a greedy search approach, which cannot explore the whole search space as it cannot tolerate a temporary loss of performance. In this paper, we address the tensor graph superoptimisation problem by exploring an alternative search approach, reinforcement learning (RL). Our proposed approach, X-RLflow, can learn to perform neural network dataflow graph rewriting, which substitutes a subgraph one at a time. X-RLflow is based on a model-free RL agent that uses a graph neural network (GNN) to encode the target computation graph and outputs a transformed computation graph iteratively. We show that our approach can outperform state-of-the-art superoptimisation systems over a range of deep learning models and achieve by up to 40% on those that are based on transformer-style architectures.
Input-to-State Stability in Probability
Apr 28, 2023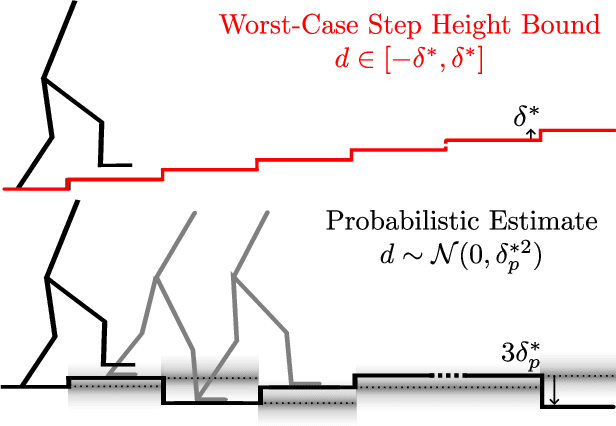
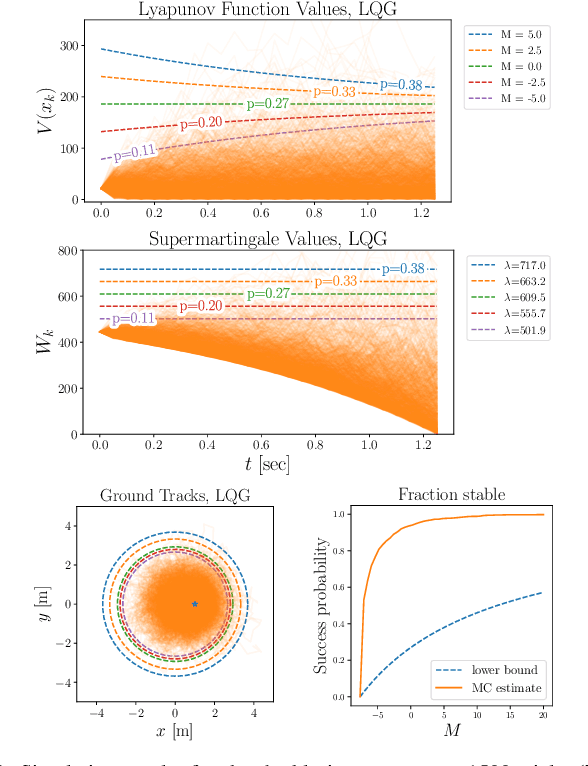

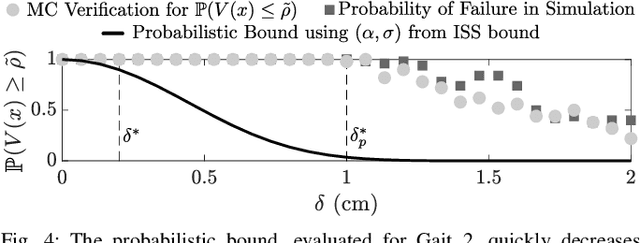
Input-to-State Stability (ISS) is fundamental in mathematically quantifying how stability degrades in the presence of bounded disturbances. If a system is ISS, its trajectories will remain bounded, and will converge to a neighborhood of an equilibrium of the undisturbed system. This graceful degradation of stability in the presence of disturbances describes a variety of real-world control implementations. Despite its utility, this property requires the disturbance to be bounded and provides invariance and stability guarantees only with respect to this worst-case bound. In this work, we introduce the concept of ``ISS in probability (ISSp)'' which generalizes ISS to discrete-time systems subject to unbounded stochastic disturbances. Using tools from martingale theory, we provide Lyapunov conditions for a system to be exponentially ISSp, and connect ISSp to stochastic stability conditions found in literature. We exemplify the utility of this method through its application to a bipedal robot confronted with step heights sampled from a truncated Gaussian distribution.