 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Causal Reasoning and Large Language Models: Opening a New Frontier for Causality
May 08, 2023
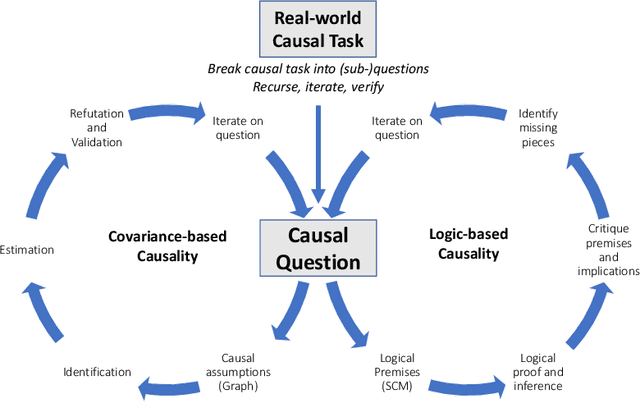
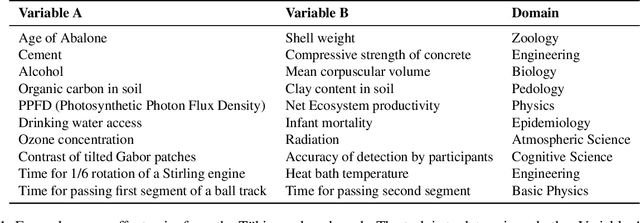

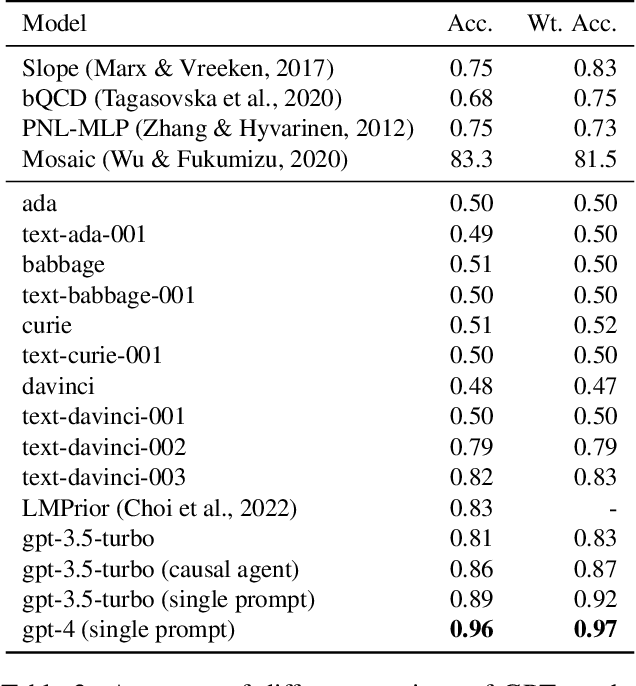
The causal capabilities of large language models (LLMs) is a matter of significant debate, with critical implications for the use of LLMs in societally impactful domains such as medicine, science, law, and policy. We further our understanding of LLMs and their causal implications, considering the distinctions between different types of causal reasoning tasks, as well as the entangled threats of construct and measurement validity. LLM-based methods establish new state-of-the-art accuracies on multiple causal benchmarks. Algorithms based on GPT-3.5 and 4 outperform existing algorithms on a pairwise causal discovery task (97%, 13 points gain), counterfactual reasoning task (92%, 20 points gain), and actual causality (86% accuracy in determining necessary and sufficient causes in vignettes). At the same time, LLMs exhibit unpredictable failure modes and we provide some techniques to interpret their robustness. Crucially, LLMs perform these causal tasks while relying on sources of knowledge and methods distinct from and complementary to non-LLM based approaches. Specifically, LLMs bring capabilities so far understood to be restricted to humans, such as using collected knowledge to generate causal graphs or identifying background causal context from natural language. We envision LLMs to be used alongside existing causal methods, as a proxy for human domain knowledge and to reduce human effort in setting up a causal analysis, one of the biggest impediments to the widespread adoption of causal methods. We also see existing causal methods as promising tools for LLMs to formalize, validate, and communicate their reasoning especially in high-stakes scenarios. In capturing common sense and domain knowledge about causal mechanisms and supporting translation between natural language and formal methods, LLMs open new frontiers for advancing the research, practice, and adoption of causality.
DiffBFR: Bootstrapping Diffusion Model Towards Blind Face Restoration
May 08, 2023
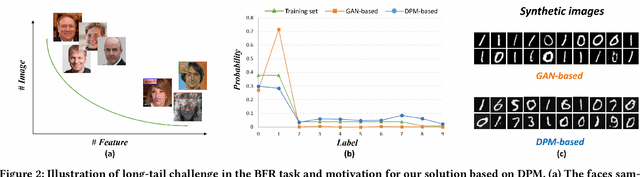
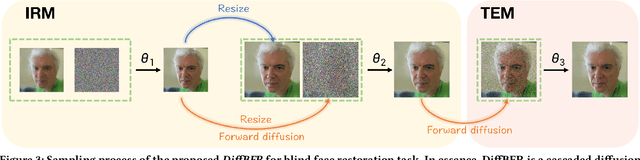
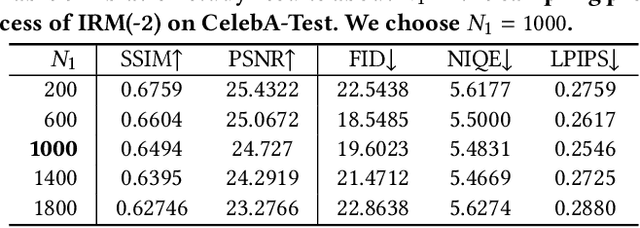
Blind face restoration (BFR) is important while challenging. Prior works prefer to exploit GAN-based frameworks to tackle this task due to the balance of quality and efficiency. However, these methods suffer from poor stability and adaptability to long-tail distribution, failing to simultaneously retain source identity and restore detail. We propose DiffBFR to introduce Diffusion Probabilistic Model (DPM) for BFR to tackle the above problem, given its superiority over GAN in aspects of avoiding training collapse and generating long-tail distribution. DiffBFR utilizes a two-step design, that first restores identity information from low-quality images and then enhances texture details according to the distribution of real faces. This design is implemented with two key components: 1) Identity Restoration Module (IRM) for preserving the face details in results. Instead of denoising from pure Gaussian random distribution with LQ images as the condition during the reverse process, we propose a novel truncated sampling method which starts from LQ images with part noise added. We theoretically prove that this change shrinks the evidence lower bound of DPM and then restores more original details. With theoretical proof, two cascade conditional DPMs with different input sizes are introduced to strengthen this sampling effect and reduce training difficulty in the high-resolution image generated directly. 2) Texture Enhancement Module (TEM) for polishing the texture of the image. Here an unconditional DPM, a LQ-free model, is introduced to further force the restorations to appear realistic. We theoretically proved that this unconditional DPM trained on pure HQ images contributes to justifying the correct distribution of inference images output from IRM in pixel-level space. Truncated sampling with fractional time step is utilized to polish pixel-level textures while preserving identity information.
Recurrent Neural Networks and Long Short-Term Memory Networks: Tutorial and Survey
Apr 22, 2023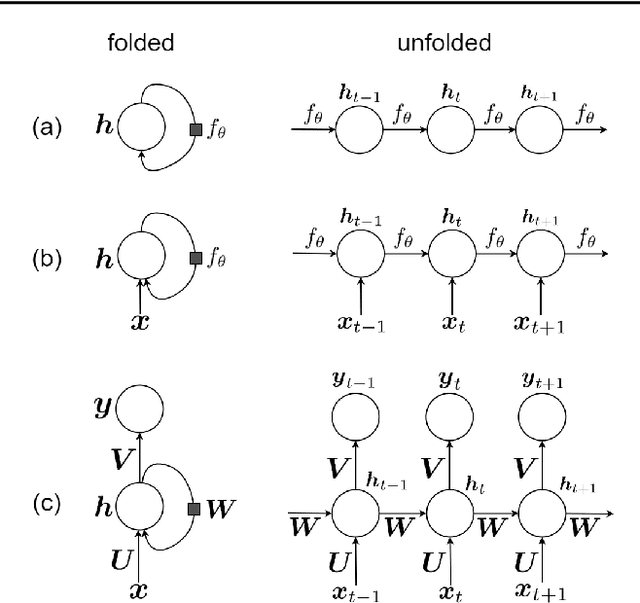
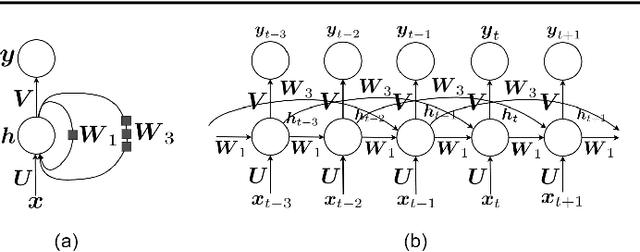
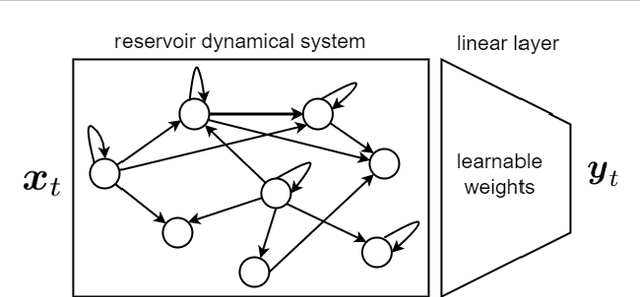
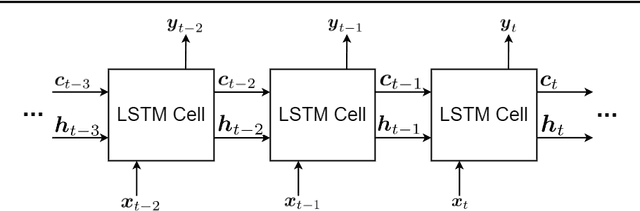
This is a tutorial paper on Recurrent Neural Network (RNN), Long Short-Term Memory Network (LSTM), and their variants. We start with a dynamical system and backpropagation through time for RNN. Then, we discuss the problems of gradient vanishing and explosion in long-term dependencies. We explain close-to-identity weight matrix, long delays, leaky units, and echo state networks for solving this problem. Then, we introduce LSTM gates and cells, history and variants of LSTM, and Gated Recurrent Units (GRU). Finally, we introduce bidirectional RNN, bidirectional LSTM, and the Embeddings from Language Model (ELMo) network, for processing a sequence in both directions.
SMILE: Single-turn to Multi-turn Inclusive Language Expansion via ChatGPT for Mental Health Support
Apr 30, 2023
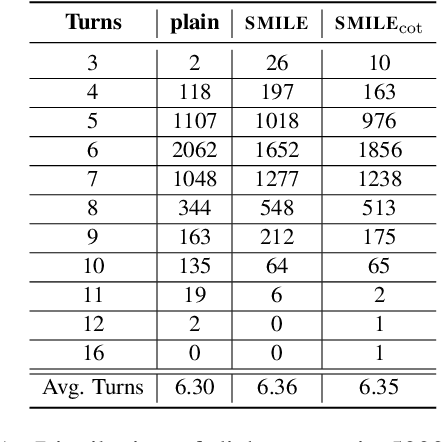


There has been an increasing research interest in developing specialized dialogue systems that can offer mental health support. However, gathering large-scale and real-life multi-turn conversations for mental health support poses challenges due to the sensitivity of personal information, as well as the time and cost involved. To address these issues, we introduce the SMILE approach, an inclusive language expansion technique that employs ChatGPT to extend public single-turn dialogues into multi-turn ones. Our research first presents a preliminary exploratory study that validates the effectiveness of the SMILE approach. Furthermore, we conduct a comprehensive and systematic contrastive analysis of datasets generated with and without the SMILE approach, demonstrating that the SMILE method results in a large-scale, diverse, and close-to-real-life multi-turn mental health support conversation corpus, including dialog topics, lexical and semantic features. Finally, we use the collected corpus (SMILECHAT) to develop a more effective dialogue system that offers emotional support and constructive suggestions in multi-turn conversations for mental health support.
Electricity Price Prediction for Energy Storage System Arbitrage: A Decision-focused Approach
Apr 30, 2023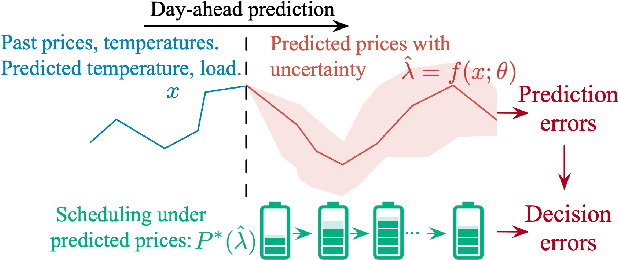
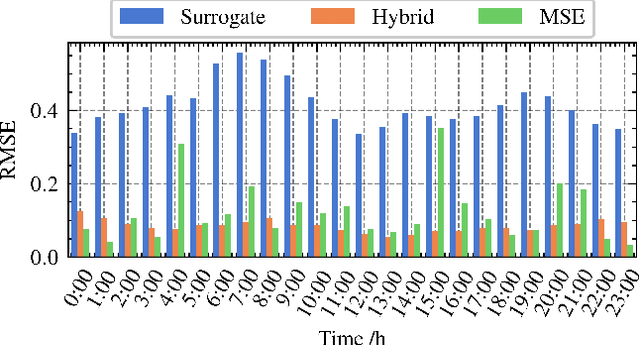
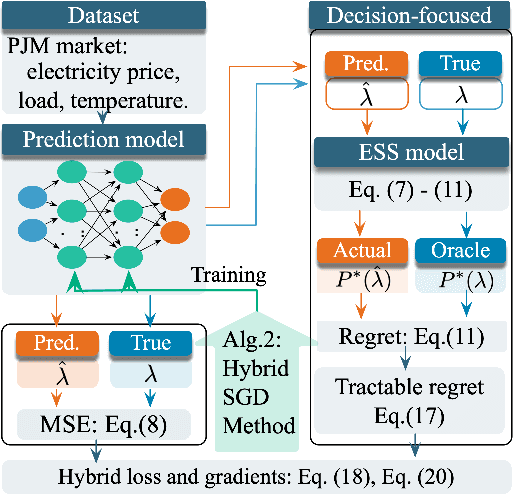
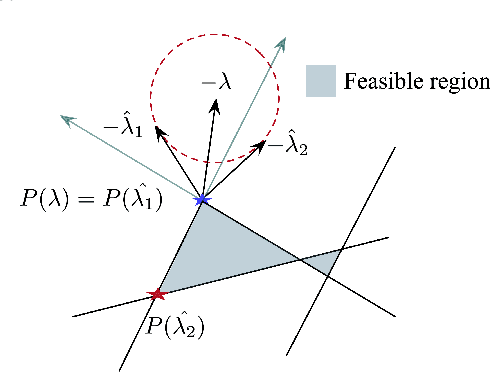
Electricity price prediction plays a vital role in energy storage system (ESS) management. Current prediction models focus on reducing prediction errors but overlook their impact on downstream decision-making. So this paper proposes a decision-focused electricity price prediction approach for ESS arbitrage to bridge the gap from the downstream optimization model to the prediction model. The decision-focused approach aims at utilizing the downstream arbitrage model for training prediction models. It measures the difference between actual decisions under the predicted price and oracle decisions under the true price, i.e., decision error, by regret, transforms it into the tractable surrogate regret, and then derives the gradients to predicted price for training prediction models. Based on the prediction and decision errors, this paper proposes the hybrid loss and corresponding stochastic gradient descent learning method to learn prediction models for prediction and decision accuracy. The case study verifies that the proposed approach can efficiently bring more economic benefits and reduce decision errors by flattening the time distribution of prediction errors, compared to prediction models for only minimizing prediction errors.
RPTQ: Reorder-based Post-training Quantization for Large Language Models
Apr 25, 2023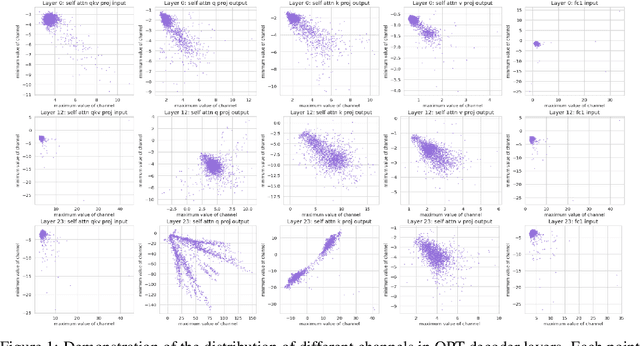
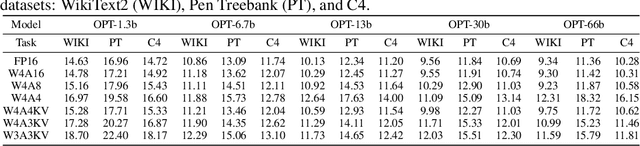
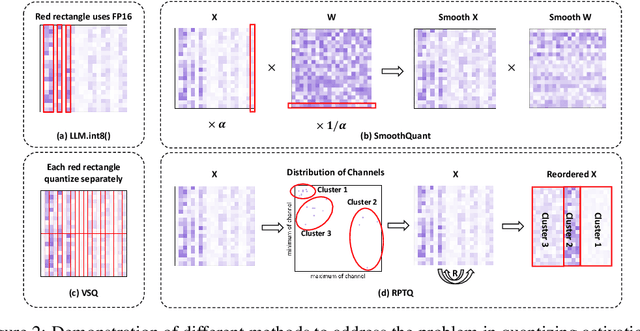
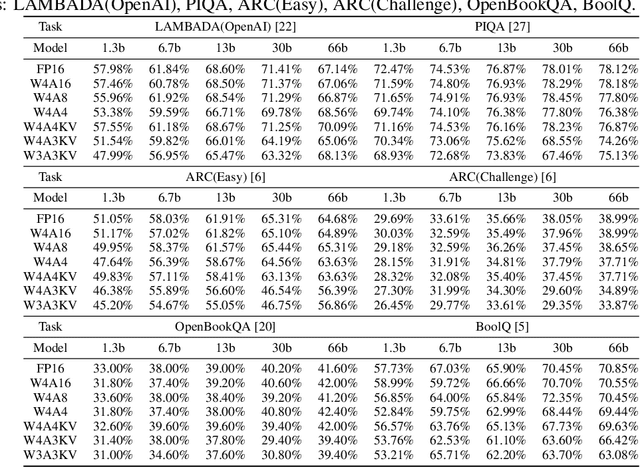
Large-scale language models (LLMs) have demonstrated outstanding performance on various tasks, but their deployment poses challenges due to their enormous model size. In this paper, we identify that the main challenge in quantizing LLMs stems from the different activation ranges between the channels, rather than just the issue of outliers.We propose a novel reorder-based quantization approach, RPTQ, that addresses the issue of quantizing the activations of LLMs. RPTQ rearranges the channels in the activations and then quantizing them in clusters, thereby reducing the impact of range difference of channels. In addition, we reduce the storage and computation overhead by avoiding explicit reordering. By implementing this approach, we achieved a significant breakthrough by pushing LLM models to 3 bit activation for the first time.
EV-Catcher: High-Speed Object Catching Using Low-latency Event-based Neural Networks
Apr 14, 2023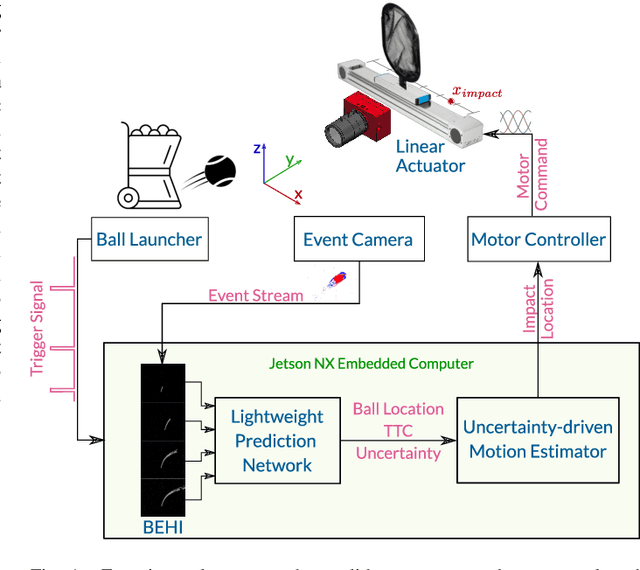
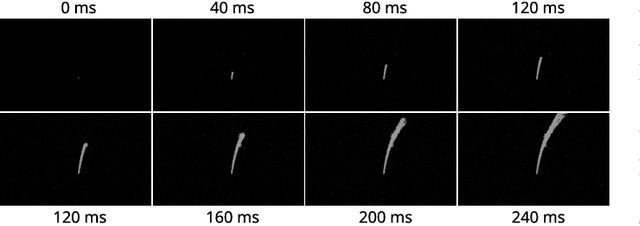
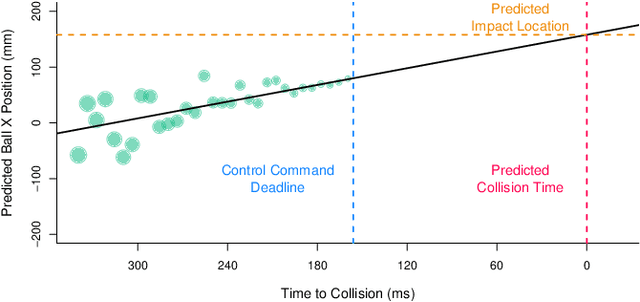
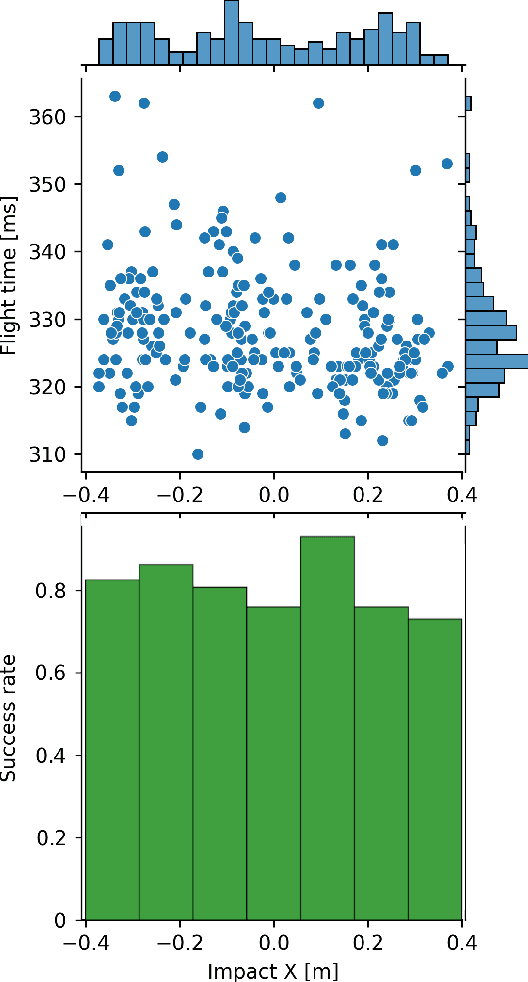
Event-based sensors have recently drawn increasing interest in robotic perception due to their lower latency, higher dynamic range, and lower bandwidth requirements compared to standard CMOS-based imagers. These properties make them ideal tools for real-time perception tasks in highly dynamic environments. In this work, we demonstrate an application where event cameras excel: accurately estimating the impact location of fast-moving objects. We introduce a lightweight event representation called Binary Event History Image (BEHI) to encode event data at low latency, as well as a learning-based approach that allows real-time inference of a confidence-enabled control signal to the robot. To validate our approach, we present an experimental catching system in which we catch fast-flying ping-pong balls. We show that the system is capable of achieving a success rate of 81% in catching balls targeted at different locations, with a velocity of up to 13 m/s even on compute-constrained embedded platforms such as the Nvidia Jetson NX.
A Multimodal Dynamical Variational Autoencoder for Audiovisual Speech Representation Learning
May 05, 2023In this paper, we present a multimodal \textit{and} dynamical VAE (MDVAE) applied to unsupervised audio-visual speech representation learning. The latent space is structured to dissociate the latent dynamical factors that are shared between the modalities from those that are specific to each modality. A static latent variable is also introduced to encode the information that is constant over time within an audiovisual speech sequence. The model is trained in an unsupervised manner on an audiovisual emotional speech dataset, in two stages. In the first stage, a vector quantized VAE (VQ-VAE) is learned independently for each modality, without temporal modeling. The second stage consists in learning the MDVAE model on the intermediate representation of the VQ-VAEs before quantization. The disentanglement between static versus dynamical and modality-specific versus modality-common information occurs during this second training stage. Extensive experiments are conducted to investigate how audiovisual speech latent factors are encoded in the latent space of MDVAE. These experiments include manipulating audiovisual speech, audiovisual facial image denoising, and audiovisual speech emotion recognition. The results show that MDVAE effectively combines the audio and visual information in its latent space. They also show that the learned static representation of audiovisual speech can be used for emotion recognition with few labeled data, and with better accuracy compared with unimodal baselines and a state-of-the-art supervised model based on an audiovisual transformer architecture.
On Contrastive Learning of Semantic Similarity forCode to Code Search
May 05, 2023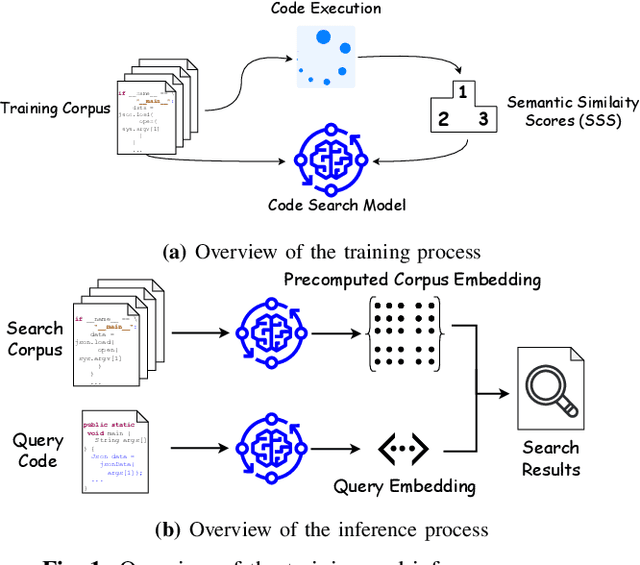
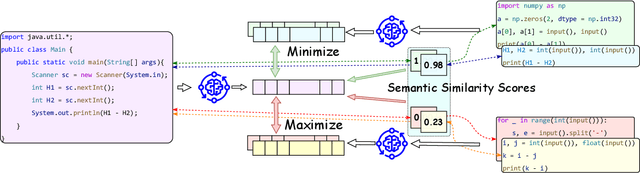
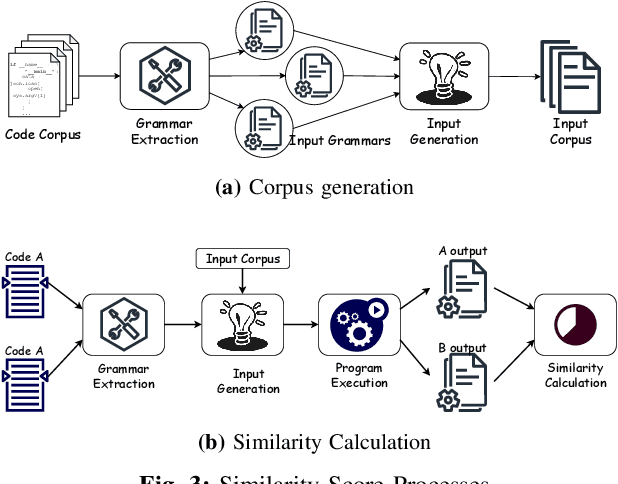
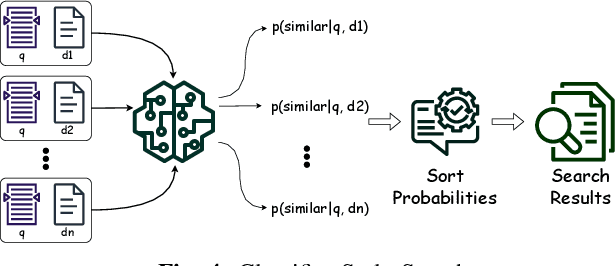
This paper introduces a novel code-to-code search technique that enhances the performance of Large Language Models (LLMs) by including both static and dynamic features as well as utilizing both similar and dissimilar examples during training. We present the first-ever code search method that encodes dynamic runtime information during training without the need to execute either the corpus under search or the search query at inference time and the first code search technique that trains on both positive and negative reference samples. To validate the efficacy of our approach, we perform a set of studies demonstrating the capability of enhanced LLMs to perform cross-language code-to-code search. Our evaluation demonstrates that the effectiveness of our approach is consistent across various model architectures and programming languages. We outperform the state-of-the-art cross-language search tool by up to 44.7\%. Moreover, our ablation studies reveal that even a single positive and negative reference sample in the training process results in substantial performance improvements demonstrating both similar and dissimilar references are important parts of code search. Importantly, we show that enhanced well-crafted, fine-tuned models consistently outperform enhanced larger modern LLMs without fine tuning, even when enhancing the largest available LLMs highlighting the importance for open-sourced models. To ensure the reproducibility and extensibility of our research, we present an open-sourced implementation of our tool and training procedures called Cosco.
Harnessing the Power of BERT in the Turkish Clinical Domain: Pretraining Approaches for Limited Data Scenarios
May 05, 2023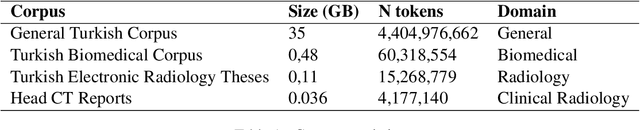
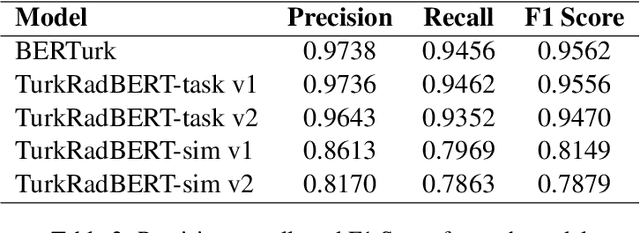
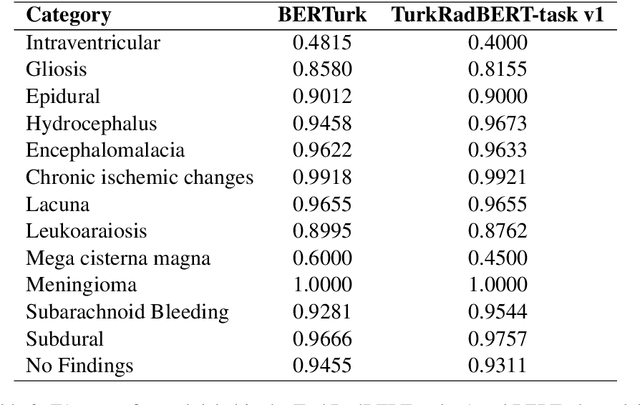
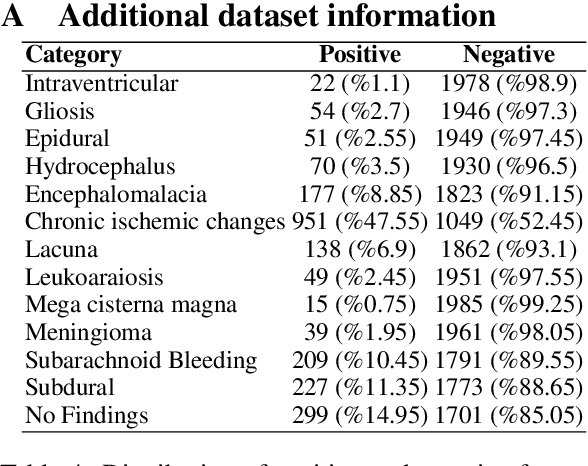
In recent years, major advancements in natural language processing (NLP) have been driven by the emergence of large language models (LLMs), which have significantly revolutionized research and development within the field. Building upon this progress, our study delves into the effects of various pre-training methodologies on Turkish clinical language models' performance in a multi-label classification task involving radiology reports, with a focus on addressing the challenges posed by limited language resources. Additionally, we evaluated the simultaneous pretraining approach by utilizing limited clinical task data for the first time. We developed four models, including TurkRadBERT-task v1, TurkRadBERT-task v2, TurkRadBERT-sim v1, and TurkRadBERT-sim v2. Our findings indicate that the general Turkish BERT model (BERTurk) and TurkRadBERT-task v1, both of which utilize knowledge from a substantial general-domain corpus, demonstrate the best overall performance. Although the task-adaptive pre-training approach has the potential to capture domain-specific patterns, it is constrained by the limited task-specific corpus and may be susceptible to overfitting. Furthermore, our results underscore the significance of domain-specific vocabulary during pre-training for enhancing model performance. Ultimately, we observe that the combination of general-domain knowledge and task-specific fine-tuning is essential for achieving optimal performance across a range of categories. This study offers valuable insights for developing effective Turkish clinical language models and can guide future research on pre-training techniques for other low-resource languages within the clinical domain.