 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Boosted Prompt Ensembles for Large Language Models
Apr 12, 2023
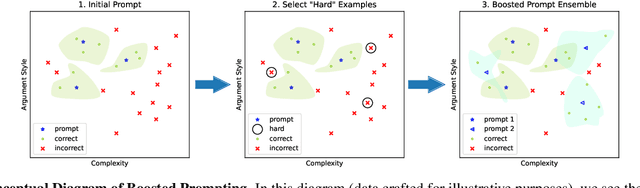
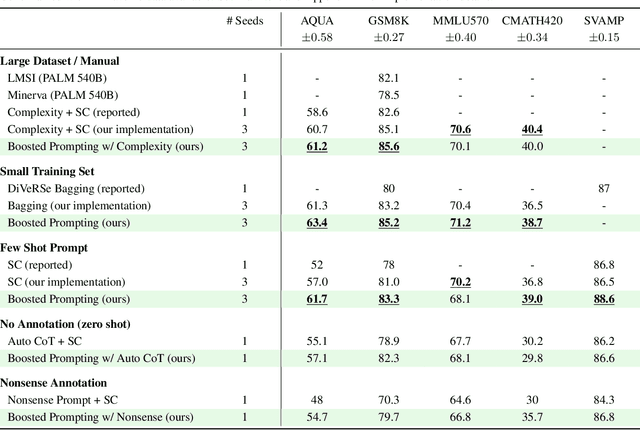

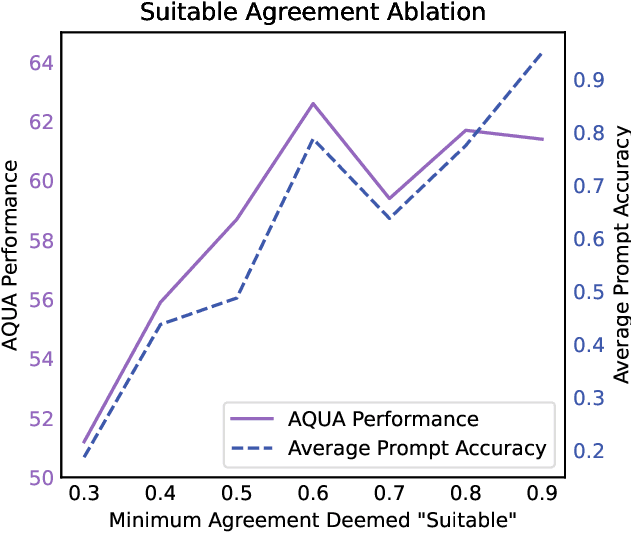
Methods such as chain-of-thought prompting and self-consistency have pushed the frontier of language model reasoning performance with no additional training. To further improve performance, we propose a prompt ensembling method for large language models, which uses a small dataset to construct a set of few shot prompts that together comprise a ``boosted prompt ensemble''. The few shot examples for each prompt are chosen in a stepwise fashion to be ``hard'' examples on which the previous step's ensemble is uncertain. We show that this outperforms single-prompt output-space ensembles and bagged prompt-space ensembles on the GSM8k and AQuA datasets, among others. We propose both train-time and test-time versions of boosted prompting that use different levels of available annotation and conduct a detailed empirical study of our algorithm.
Sublinear Time Algorithms for Several Geometric Optimization (With Outliers) Problems In Machine Learning
Jan 07, 2023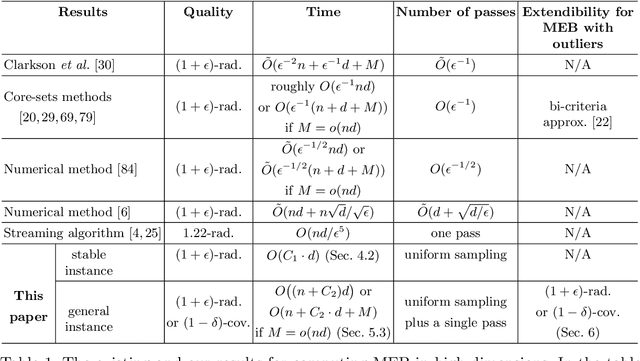
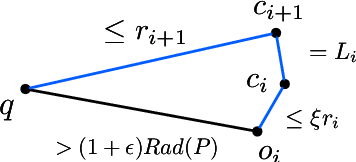
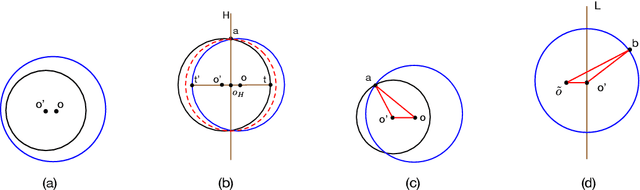
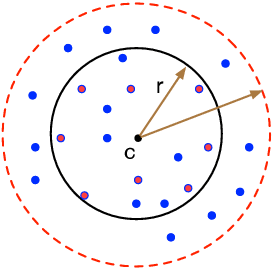
In this paper, we study several important geometric optimization problems arising in machine learning. First, we revisit the Minimum Enclosing Ball (MEB) problem in Euclidean space $\mathbb{R}^d$. The problem has been extensively studied before, but real-world machine learning tasks often need to handle large-scale datasets so that we cannot even afford linear time algorithms. Motivated by the recent studies on {\em beyond worst-case analysis}, we introduce the notion of stability for MEB, which is natural and easy to understand. Roughly speaking, an instance of MEB is stable, if the radius of the resulting ball cannot be significantly reduced by removing a small fraction of the input points. Under the stability assumption, we present two sampling algorithms for computing radius-approximate MEB with sample complexities independent of the number of input points $n$. In particular, the second algorithm has the sample complexity even independent of the dimensionality $d$. We also consider the general case without the stability assumption. We present a hybrid algorithm that can output either a radius-approximate MEB or a covering-approximate MEB. Our algorithm improves the running time and the number of passes for the previous sublinear MEB algorithms. Our method relies on two novel techniques, the Uniform-Adaptive Sampling method and Sandwich Lemma. Furthermore, we observe that these two techniques can be generalized to design sublinear time algorithms for a broader range of geometric optimization problems with outliers in high dimensions, including MEB with outliers, one-class and two-class linear SVMs with outliers, $k$-center clustering with outliers, and flat fitting with outliers. Our proposed algorithms also work fine for kernels.
Segmentation based tracking of cells in 2D+time microscopy images of macrophages
Jan 02, 2023

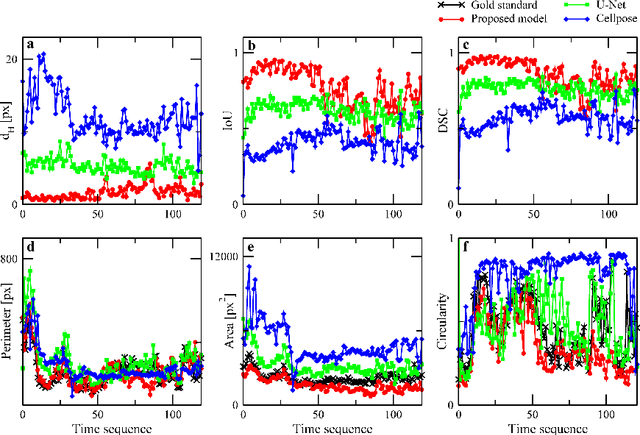
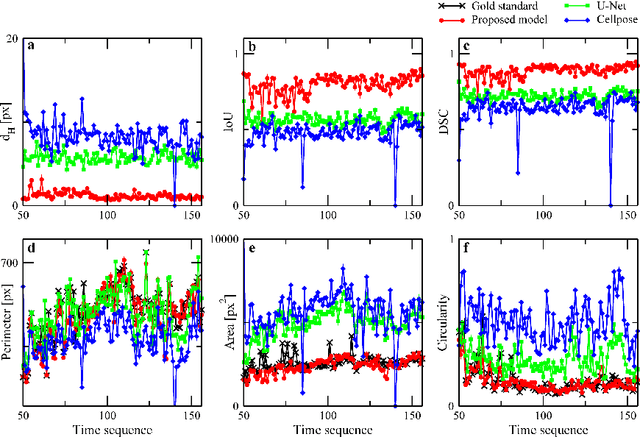
The automated segmentation and tracking of macrophages during their migration are challenging tasks due to their dynamically changing shapes and motions. This paper proposes a new algorithm to achieve automatic cell tracking in time-lapse microscopy macrophage data. First, we design a segmentation method employing space-time filtering, local Otsu's thresholding, and the SUBSURF (subjective surface segmentation) method. Next, the partial trajectories for cells overlapping in the temporal direction are extracted in the segmented images. Finally, the extracted trajectories are linked by considering their direction of movement. The segmented images and the obtained trajectories from the proposed method are compared with those of the semi-automatic segmentation and manual tracking. The proposed tracking achieved 97.4% of accuracy for macrophage data under challenging situations, feeble fluorescent intensity, irregular shapes, and motion of macrophages. We expect that the automatically extracted trajectories of macrophages can provide pieces of evidence of how macrophages migrate depending on their polarization modes in the situation, such as during wound healing.
ViewFormer: View Set Attention for Multi-view 3D Shape Understanding
Apr 29, 2023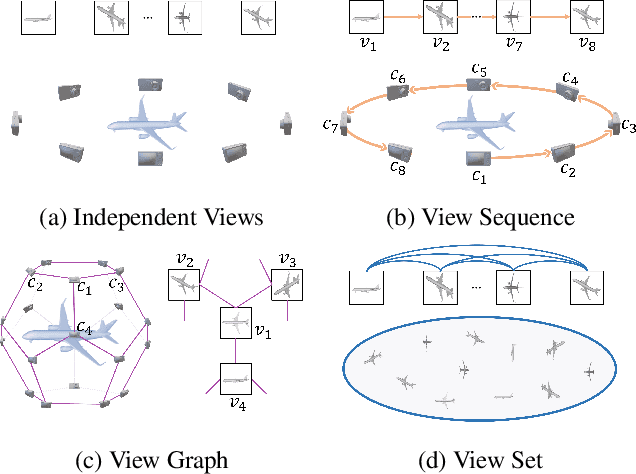
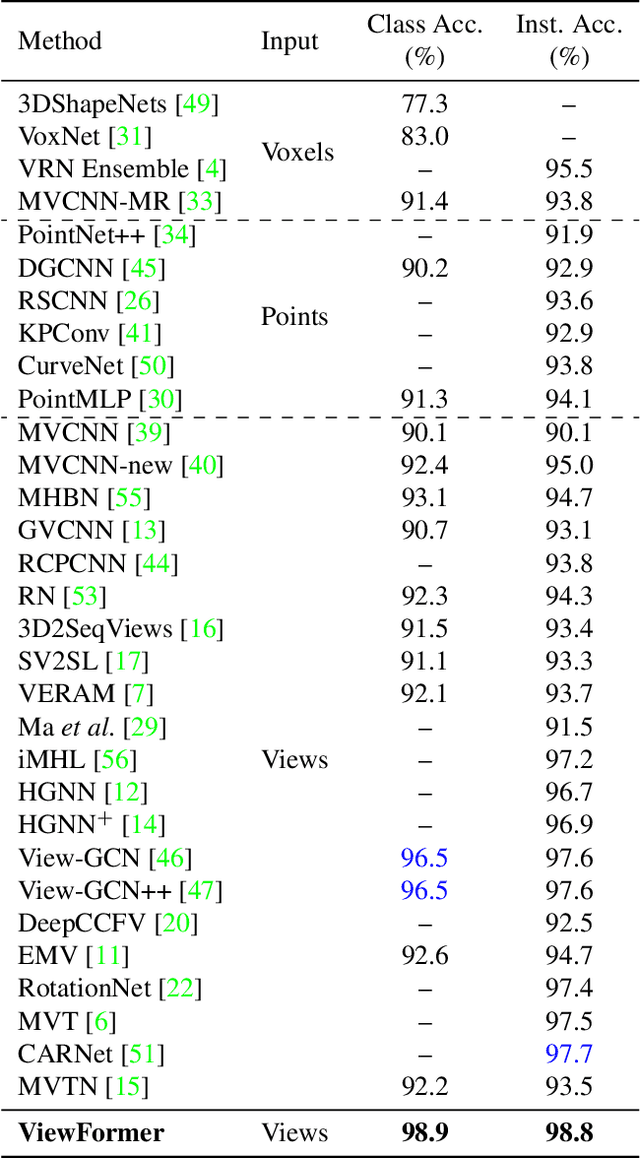

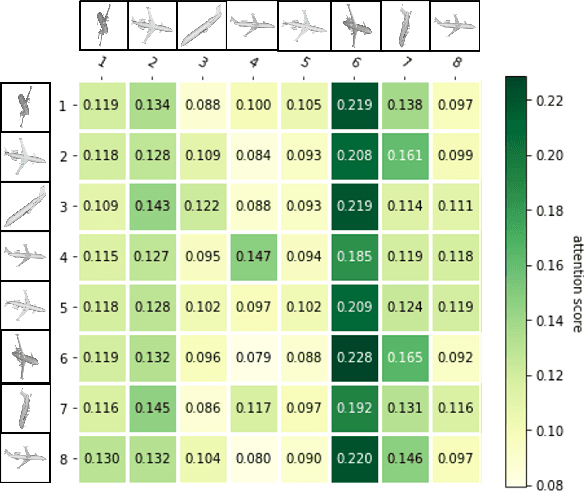
This paper presents ViewFormer, a simple yet effective model for multi-view 3d shape recognition and retrieval. We systematically investigate the existing methods for aggregating multi-view information and propose a novel ``view set" perspective, which minimizes the relation assumption about the views and releases the representation flexibility. We devise an adaptive attention model to capture pairwise and higher-order correlations of the elements in the view set. The learned multi-view correlations are aggregated into an expressive view set descriptor for recognition and retrieval. Experiments show the proposed method unleashes surprising capabilities across different tasks and datasets. For instance, with only 2 attention blocks and 4.8M learnable parameters, ViewFormer reaches 98.8% recognition accuracy on ModelNet40 for the first time, exceeding previous best method by 1.1% . On the challenging RGBD dataset, our method achieves 98.4% recognition accuracy, which is a 4.1% absolute improvement over the strongest baseline. ViewFormer also sets new records in several evaluation dimensions of 3D shape retrieval defined on the SHREC'17 benchmark.
End-to-End Deep Learning Framework for Real-Time Inertial Attitude Estimation using 6DoF IMU
Feb 13, 2023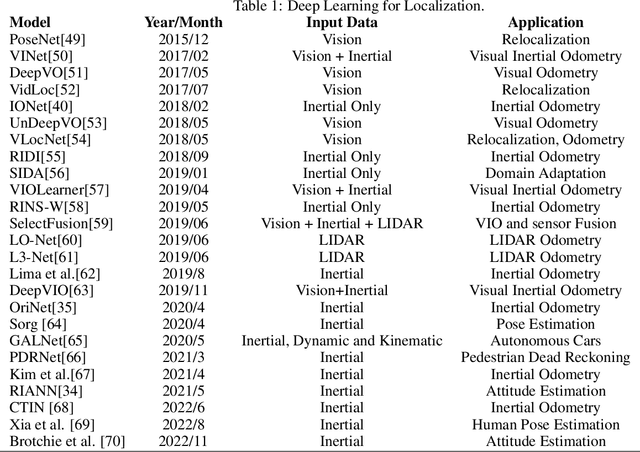
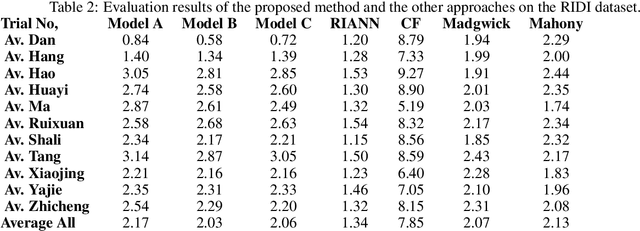
Inertial Measurement Units (IMU) are commonly used in inertial attitude estimation from engineering to medical sciences. There may be disturbances and high dynamics in the environment of these applications. Also, their motion characteristics and patterns also may differ. Many conventional filters have been proposed to tackle the inertial attitude estimation problem based on IMU measurements. There is no generalization over motion and environmental characteristics in these filters. As a result, the presented conventional filters will face various motion characteristics and patterns, which will limit filter performance and need to optimize the filter parameters for each situation. In this paper, two end-to-end deep-learning models are proposed to solve the problem of real-time attitude estimation by using inertial sensor measurements, which are generalized to motion patterns, sampling rates, and environmental disturbances. The proposed models incorporate accelerometer and gyroscope readings as inputs, which are collected from a combination of seven public datasets. The models consist of convolutional neural network (CNN) layers combined with Bi-Directional Long-Short Term Memory (LSTM) followed by a Fully Forward Neural Network (FFNN) to estimate the quaternion. To evaluate the validity and reliability, we have performed an extensive and comprehensive evaluation over seven publicly available datasets, which consist of more than 120 hours and 200 kilometers of IMU measurements. The results show that the proposed method outperforms the state-of-the-art methods in terms of accuracy and robustness. Furthermore, it demonstrates that this model generalizes better than other methods over various motion characteristics and sensor sampling rates.
MoStGAN-V: Video Generation with Temporal Motion Styles
Apr 05, 2023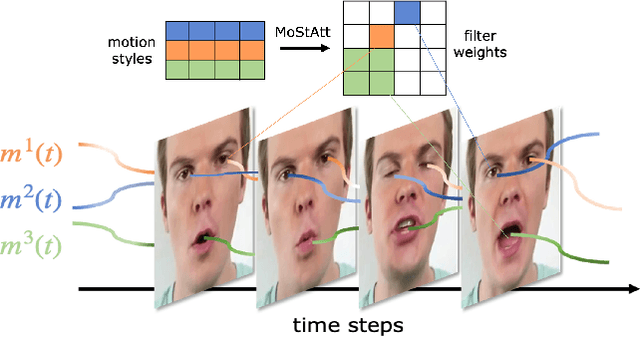

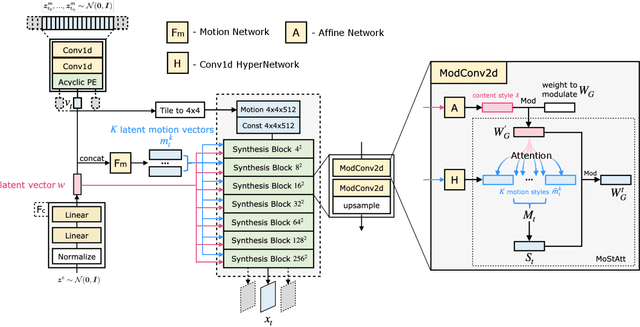

Video generation remains a challenging task due to spatiotemporal complexity and the requirement of synthesizing diverse motions with temporal consistency. Previous works attempt to generate videos in arbitrary lengths either in an autoregressive manner or regarding time as a continuous signal. However, they struggle to synthesize detailed and diverse motions with temporal coherence and tend to generate repetitive scenes after a few time steps. In this work, we argue that a single time-agnostic latent vector of style-based generator is insufficient to model various and temporally-consistent motions. Hence, we introduce additional time-dependent motion styles to model diverse motion patterns. In addition, a Motion Style Attention modulation mechanism, dubbed as MoStAtt, is proposed to augment frames with vivid dynamics for each specific scale (i.e., layer), which assigns attention score for each motion style w.r.t deconvolution filter weights in the target synthesis layer and softly attends different motion styles for weight modulation. Experimental results show our model achieves state-of-the-art performance on four unconditional $256^2$ video synthesis benchmarks trained with only 3 frames per clip and produces better qualitative results with respect to dynamic motions. Code and videos have been made available at https://github.com/xiaoqian-shen/MoStGAN-V.
Physics-informed Neural Network Combined with Characteristic-Based Split for Solving Navier-Stokes Equations
Apr 21, 2023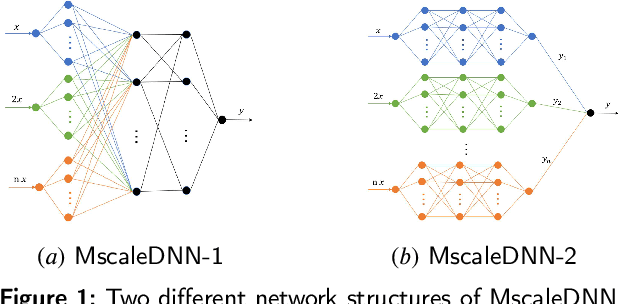
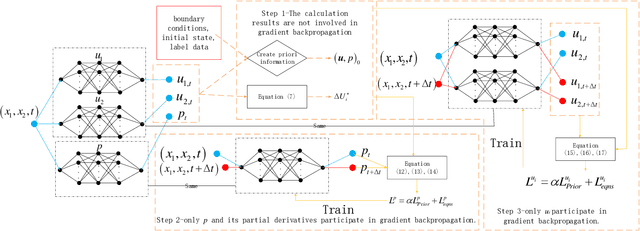
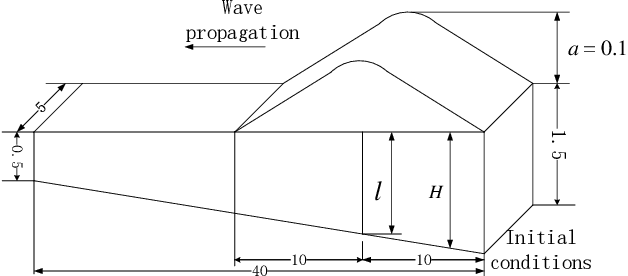
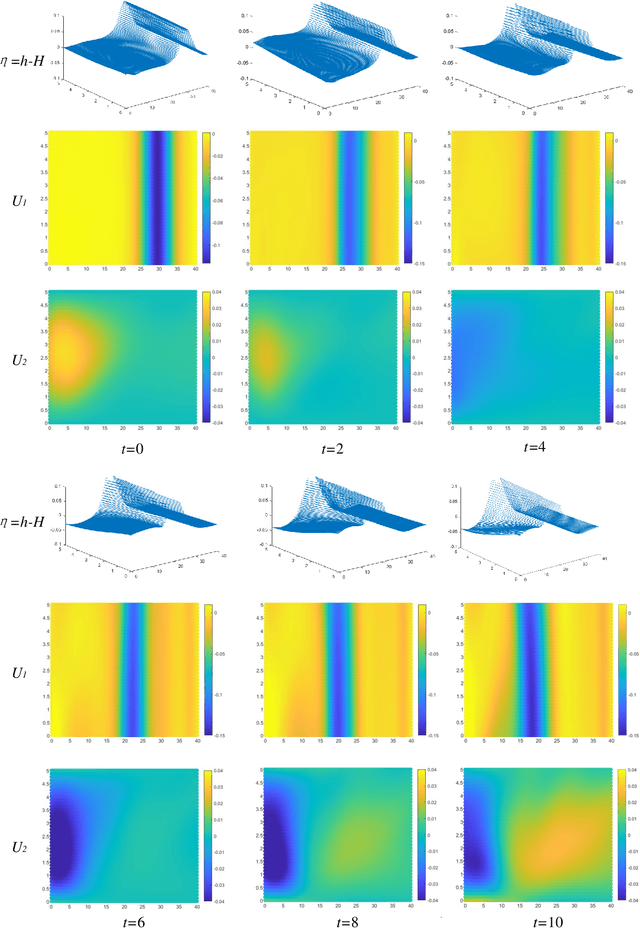
In this paper, physics-informed neural network (PINN) based on characteristic-based split (CBS) is proposed, which can be used to solve the time-dependent Navier-Stokes equations (N-S equations). In this method, The output parameters and corresponding losses are separated, so the weights between output parameters are not considered. Not all partial derivatives participate in gradient backpropagation, and the remaining terms will be reused.Therefore, compared with traditional PINN, this method is a rapid version. Here, labeled data, physical constraints and network outputs are regarded as priori information, and the residuals of the N-S equations are regarded as posteriori information. So this method can deal with both data-driven and data-free problems. As a result, it can solve the special form of compressible N-S equations -- -Shallow-Water equations, and incompressible N-S equations. As boundary conditions are known, this method only needs the flow field information at a certain time to restore the past and future flow field information. We solve the progress of a solitary wave onto a shelving beach and the dispersion of the hot water in the flow, which show this method's potential in the marine engineering. We also use incompressible equations with exact solutions to prove this method's correctness and universality. We find that PINN needs more strict boundary conditions to solve the N-S equation, because it has no computational boundary compared with the finite element method.
MultiZenoTravel: a Tunable Benchmark for Multi-Objective Planning with Known Pareto Front
Apr 28, 2023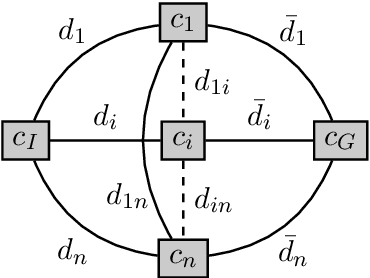
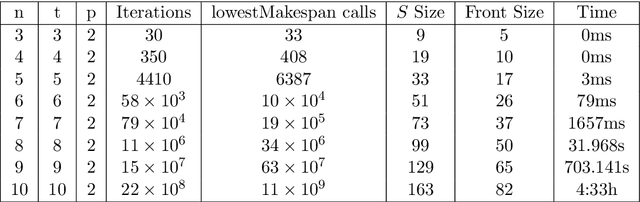
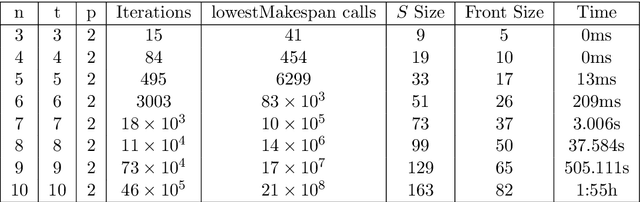
Multi-objective AI planning suffers from a lack of benchmarks exhibiting known Pareto Fronts. In this work, we propose a tunable benchmark generator, together with a dedicated solver that provably computes the true Pareto front of the resulting instances. First, we prove a proposition allowing us to characterize the optimal plans for a constrained version of the problem, and then show how to reduce the general problem to the constrained one. Second, we provide a constructive way to find all the Pareto-optimal plans and discuss the complexity of the algorithm. We provide an implementation that allows the solver to handle realistic instances in a reasonable time. Finally, as a practical demonstration, we used this solver to find all Pareto-optimal plans between the two largest airports in the world, considering the routes between the 50 largest airports, spherical distances between airports and a made-up risk.
MCPrioQ: A lock-free algorithm for online sparse markov-chains
Apr 28, 2023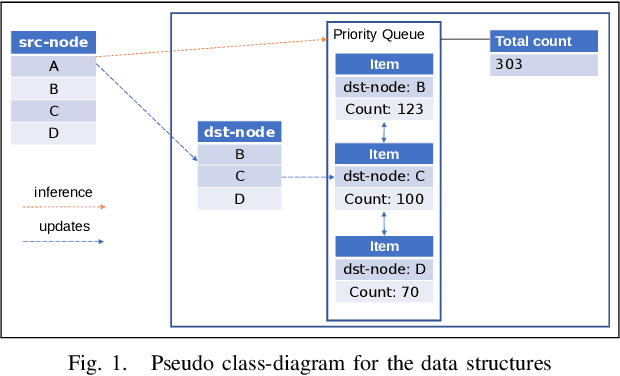
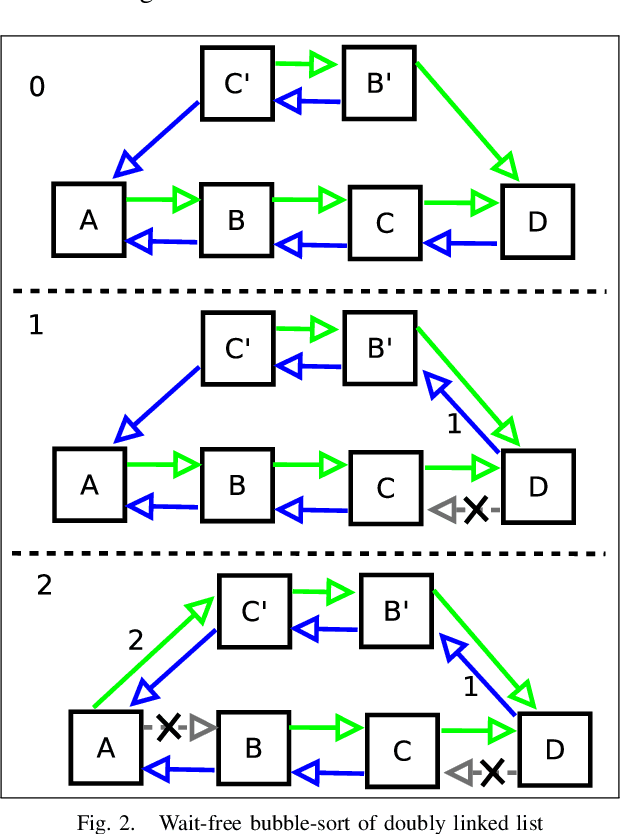
In high performance systems it is sometimes hard to build very large graphs that are efficient both with respect to memory and compute. This paper proposes a data structure called Markov-chain-priority-queue (MCPrioQ), which is a lock-free sparse markov-chain that enables online and continuous learning with time-complexity of $O(1)$ for updates and $O(CDF^{-1}(t))$ inference. MCPrioQ is especially suitable for recommender-systems for lookups of $n$-items in descending probability order. The concurrent updates are achieved using hash-tables and atomic instructions and the lookups are achieved through a novel priority-queue which allows for approximately correct results even during concurrent updates. The approximatly correct and lock-free property is maintained by a read-copy-update scheme, but where the semantics have been slightly updated to allow for swap of elements rather than the traditional pop-insert scheme.
Identifying Unique Causal Network from Nonstationary Time Series
Nov 21, 2022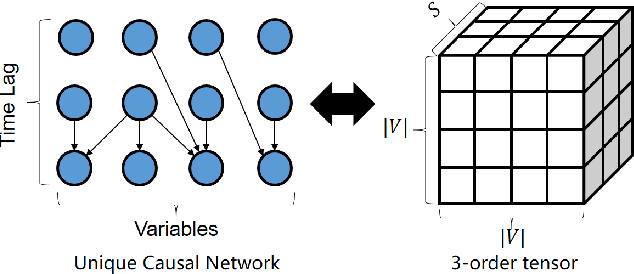

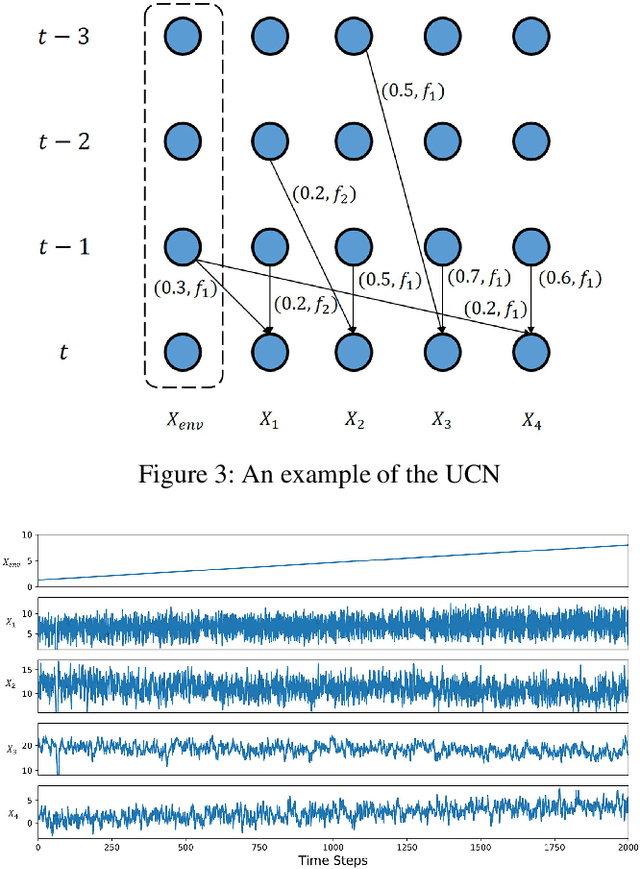
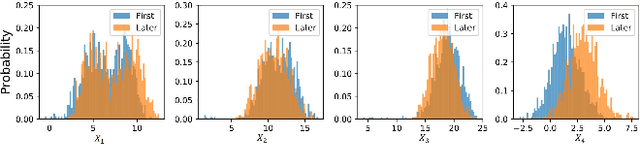
Identifying causality is a challenging task in many data-intensive scenarios. Many algorithms have been proposed for this critical task. However, most of them consider the learning algorithms for directed acyclic graph (DAG) of Bayesian network (BN). These BN-based models only have limited causal explainability because of the issue of Markov equivalence class. Moreover, they are dependent on the assumption of stationarity, whereas many sampling time series from complex system are nonstationary. The nonstationary time series bring dataset shift problem, which leads to the unsatisfactory performances of these algorithms. To fill these gaps, a novel causation model named Unique Causal Network (UCN) is proposed in this paper. Different from the previous BN-based models, UCN considers the influence of time delay, and proves the uniqueness of obtained network structure, which addresses the issue of Markov equivalence class. Furthermore, based on the decomposability property of UCN, a higher-order causal entropy (HCE) algorithm is designed to identify the structure of UCN in a distributed way. HCE algorithm measures the strength of causality by using nearest-neighbors entropy estimator, which works well on nonstationary time series. Finally, lots of experiments validate that HCE algorithm achieves state-of-the-art accuracy when time series are nonstationary, compared to the other baseline algorithms.