 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Outage and DMT Analysis of Partition-based Schemes for RIS-aided MIMO Fading Channels
May 07, 2023
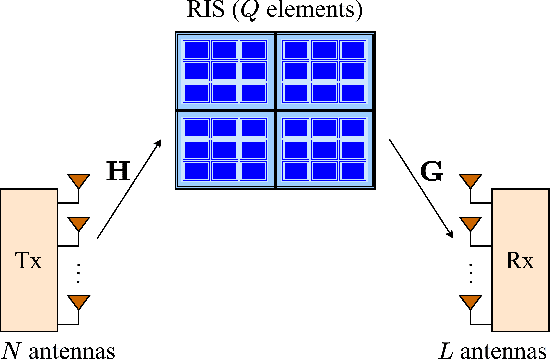
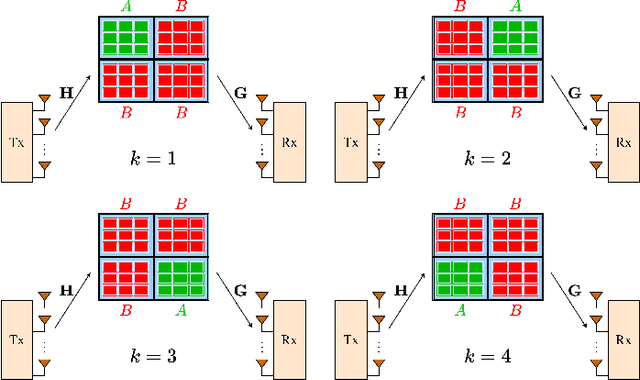
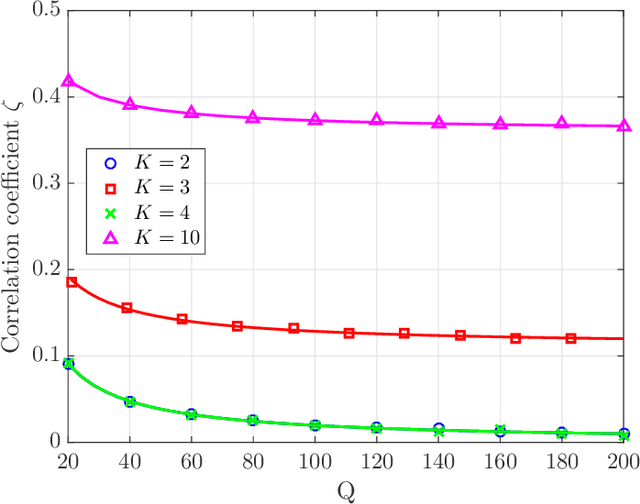
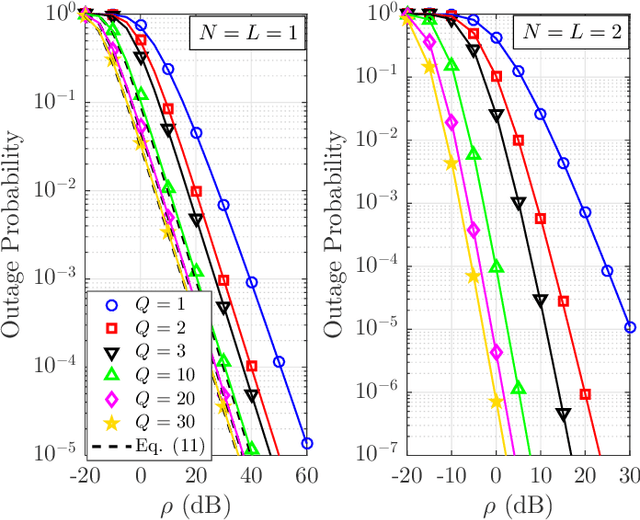
In this paper, we investigate the performance of multiple-input multiple-output (MIMO) fading channels assisted by a reconfigurable intelligent surface (RIS), through the employment of partition-based RIS schemes. The proposed schemes are implemented without requiring any channel state information knowledge at the transmitter side; this characteristic makes them attractive for practical applications. In particular, the RIS elements are partitioned into sub-surfaces, which are periodically modified in an efficient way to assist the communication. Under this framework, we propose two low-complexity partition-based schemes, where each sub-surface is adjusted by following an amplitude-based or a phase-based approach. Specifically, the activate-reflect (AR) scheme activates each sub-surface consecutively, by changing the reflection amplitude of the corresponding elements. On the other hand, the flip-reflect (FR) scheme adjusts periodically the phase shift of the elements at each sub-surface. Through the sequential reconfiguration of each sub-surface, an equivalent parallel channel in the time domain is produced. We analyze the performance of each scheme in terms of outage probability and provide expressions for the achieved diversity-multiplexing tradeoff. Our results show that the asymptotic performance of the considered network under the partition-based schemes can be significantly enhanced in terms of diversity gain compared to the conventional case, where a single partition is considered. Moreover, the FR scheme always achieves the maximum multiplexing gain, while for the AR scheme this maximum gain can be achieved only under certain conditions with respect to the number of elements in each sub-surface.
* 13 pages, 9 figures
Batch Quantum Reinforcement Learning
Apr 27, 2023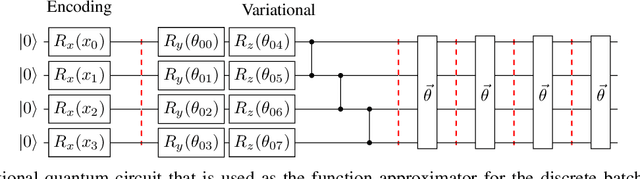
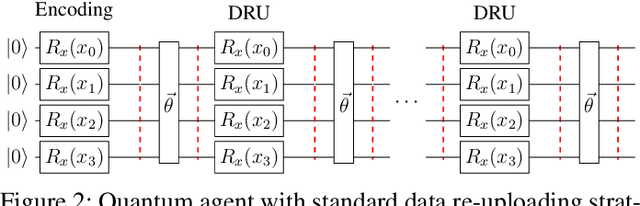
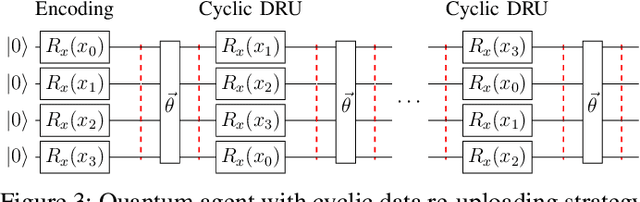
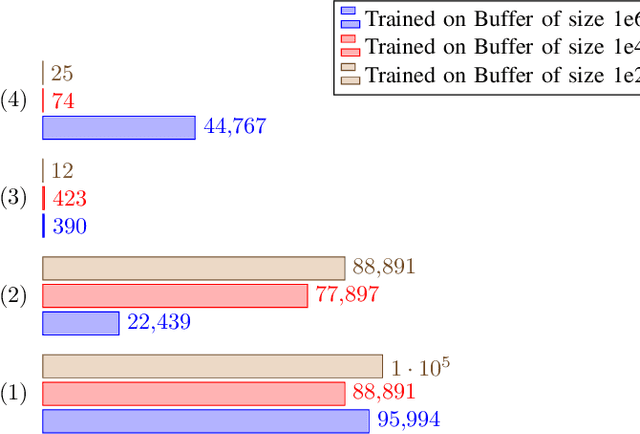
Training DRL agents is often a time-consuming process as a large number of samples and environment interactions is required. This effect is even amplified in the case of Batch RL, where the agent is trained without environment interactions solely based on a set of previously collected data. Novel approaches based on quantum computing suggest an advantage compared to classical approaches in terms of sample efficiency. To investigate this advantage, we propose a batch RL algorithm leveraging VQC as function approximators in the discrete BCQ algorithm. Additionally, we present a novel data re-uploading scheme based on cyclically shifting the input variables' order in the data encoding layers. We show the efficiency of our algorithm on the OpenAI CartPole environment and compare its performance to classical neural network-based discrete BCQ.
Cramer-Rao Lower Bound Analysis for OTFS and OFDM Modulation Systems
Apr 27, 2023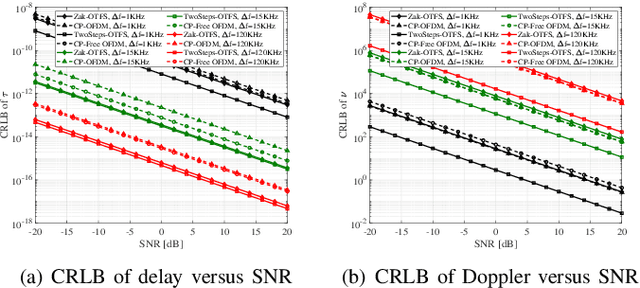
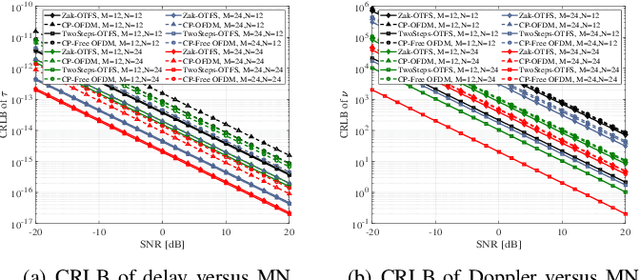
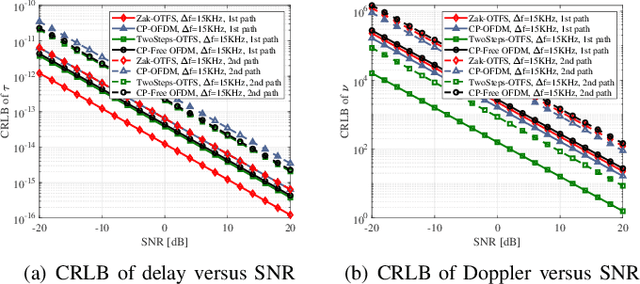
The orthogonal time frequency space (OTFS) modulation as a promising signal representation attracts growingcinterest for integrated sensing and communication (ISAC), yet its merits over orthogonal frequency division multiplexing (OFDM) remain controversial. This paper devotes to a comprehensive comparison of OTFS and OFDM for sensing from the perspective of Cramer-Rao lower bounds (CRLB) analysis. To this end, we develop the cyclic prefix (CP)-Free and CP-added model for OFDM, while for OTFS, we consider the Zak transform based and the Two-Step conversion based models, respectively. Then we rephrase these four models into a unified matrix format to derive the CRLB of the delays and doppler shifts for multipath scenario. Numerical results demonstrate the superiority of OTFS modulation for sensing, and the effect of physical parameters for performance achievement.
Learning a Diffusion Prior for NeRFs
Apr 27, 2023

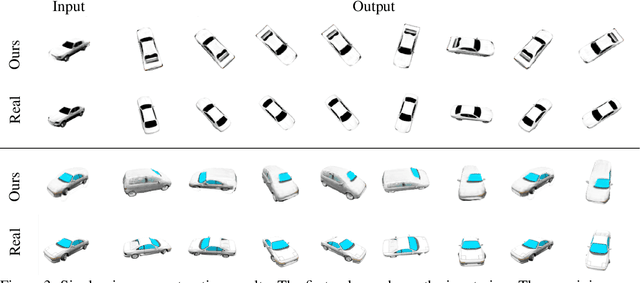
Neural Radiance Fields (NeRFs) have emerged as a powerful neural 3D representation for objects and scenes derived from 2D data. Generating NeRFs, however, remains difficult in many scenarios. For instance, training a NeRF with only a small number of views as supervision remains challenging since it is an under-constrained problem. In such settings, it calls for some inductive prior to filter out bad local minima. One way to introduce such inductive priors is to learn a generative model for NeRFs modeling a certain class of scenes. In this paper, we propose to use a diffusion model to generate NeRFs encoded on a regularized grid. We show that our model can sample realistic NeRFs, while at the same time allowing conditional generations, given a certain observation as guidance.
Logarithmic-Regret Quantum Learning Algorithms for Zero-Sum Games
Apr 27, 2023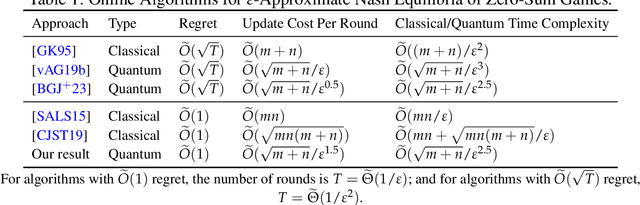

We propose the first online quantum algorithm for zero-sum games with $\tilde O(1)$ regret under the game setting. Moreover, our quantum algorithm computes an $\varepsilon$-approximate Nash equilibrium of an $m \times n$ matrix zero-sum game in quantum time $\tilde O(\sqrt{m+n}/\varepsilon^{2.5})$, yielding a quadratic improvement over classical algorithms in terms of $m, n$. Our algorithm uses standard quantum inputs and generates classical outputs with succinct descriptions, facilitating end-to-end applications. As an application, we obtain a fast quantum linear programming solver. Technically, our online quantum algorithm "quantizes" classical algorithms based on the optimistic multiplicative weight update method. At the heart of our algorithm is a fast quantum multi-sampling procedure for the Gibbs sampling problem, which may be of independent interest.
First- and Second-Order Bounds for Adversarial Linear Contextual Bandits
May 01, 2023We consider the adversarial linear contextual bandit setting, which allows for the loss functions associated with each of $K$ arms to change over time without restriction. Assuming the $d$-dimensional contexts are drawn from a fixed known distribution, the worst-case expected regret over the course of $T$ rounds is known to scale as $\tilde O(\sqrt{Kd T})$. Under the additional assumption that the density of the contexts is log-concave, we obtain a second-order bound of order $\tilde O(K\sqrt{d V_T})$ in terms of the cumulative second moment of the learner's losses $V_T$, and a closely related first-order bound of order $\tilde O(K\sqrt{d L_T^*})$ in terms of the cumulative loss of the best policy $L_T^*$. Since $V_T$ or $L_T^*$ may be significantly smaller than $T$, these improve over the worst-case regret whenever the environment is relatively benign. Our results are obtained using a truncated version of the continuous exponential weights algorithm over the probability simplex, which we analyse by exploiting a novel connection to the linear bandit setting without contexts.
Ripple: Concept-Based Interpretation for Raw Time Series Models in Education
Dec 08, 2022
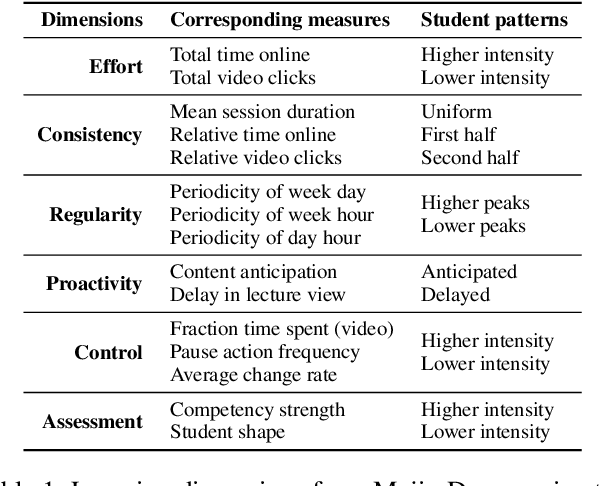
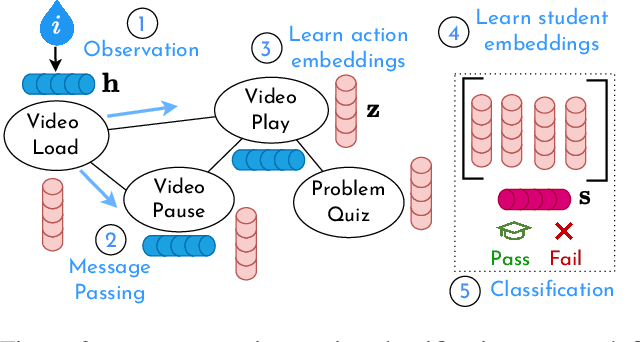

Time series is the most prevalent form of input data for educational prediction tasks. The vast majority of research using time series data focuses on hand-crafted features, designed by experts for predictive performance and interpretability. However, extracting these features is labor-intensive for humans and computers. In this paper, we propose an approach that utilizes irregular multivariate time series modeling with graph neural networks to achieve comparable or better accuracy with raw time series clickstreams in comparison to hand-crafted features. Furthermore, we extend concept activation vectors for interpretability in raw time series models. We analyze these advances in the education domain, addressing the task of early student performance prediction for downstream targeted interventions and instructional support. Our experimental analysis on 23 MOOCs with millions of combined interactions over six behavioral dimensions show that models designed with our approach can (i) beat state-of-the-art educational time series baselines with no feature extraction and (ii) provide interpretable insights for personalized interventions. Source code: https://github.com/epfl-ml4ed/ripple/.
Robotic Gas Source Localization with Probabilistic Mapping and Online Dispersion Simulation
Apr 18, 2023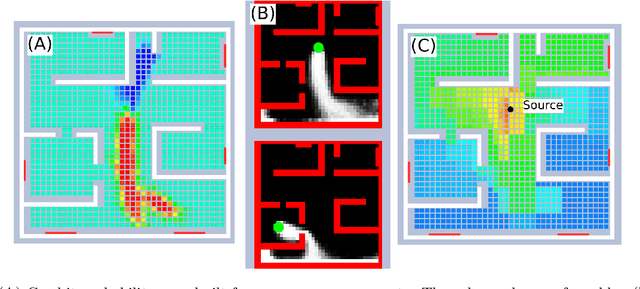
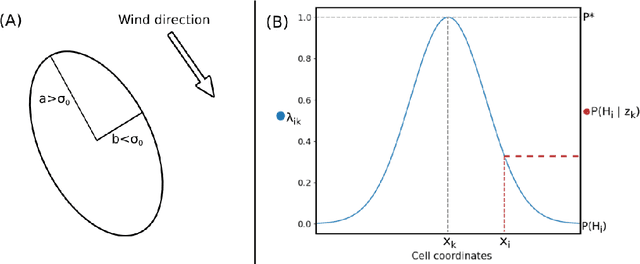
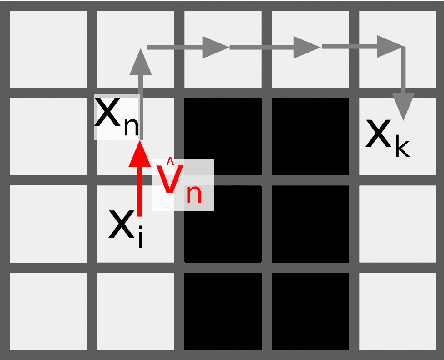
Gas source localization (GSL) with an autonomous robot is a problem with many prospective applications, from finding pipe leaks to emergency-response scenarios. In this work we present a new method to perform GSL in realistic indoor environments, featuring obstacles and turbulent flow. Given the highly complex relationship between the source position and the measurements available to the robot (the single-point gas concentration, and the wind vector) we propose an observation model that derives from contrasting the online, real-time simulation of the gas dispersion from any candidate source localization against a gas concentration map built from sensor readings. To account for a convenient and grounded integration of both into a probabilistic estimation framework, we introduce the concept of probabilistic gas-hit maps, which provide a higher level of abstraction to model the time-dependent nature of gas dispersion. Results from both simulated and real experiments show the capabilities of our current proposal to deal with source localization in complex indoor environments. To the best of our knowledge, this is the first work in olfactory robotics that doesn't make simplistic assumptions about environmental conditions like operating in open spaces and/or having an unrealistic laminar flow wind.
HiQ -- A Declarative, Non-intrusive, Dynamic and Transparent Observability and Optimization System
Apr 26, 2023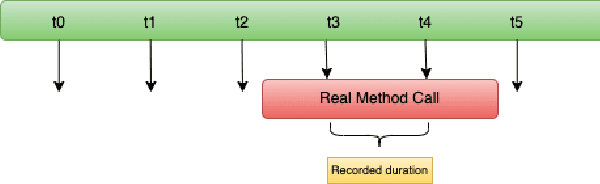
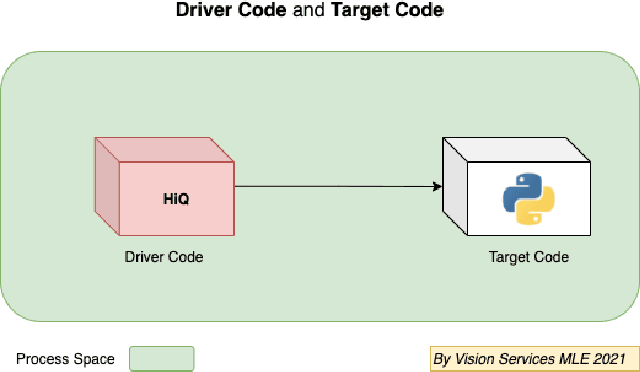
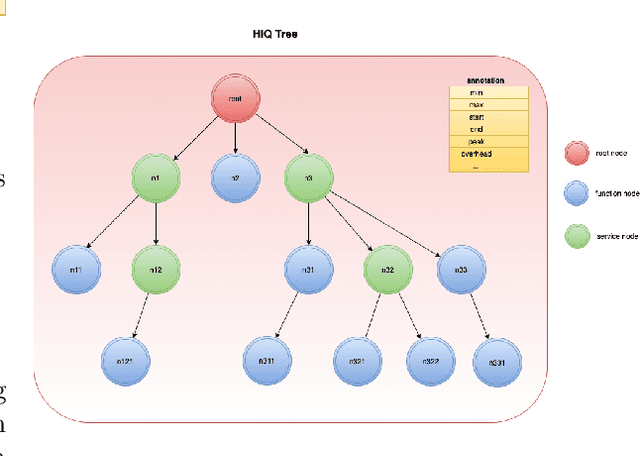
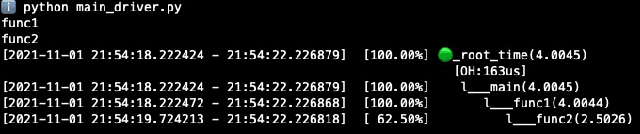
This paper proposes a non-intrusive, declarative, dynamic and transparent system called `HiQ` to track Python program runtime information without compromising on the run-time system performance and losing insight. HiQ can be used for monolithic and distributed systems, offline and online applications. HiQ is developed when we optimize our large deep neural network (DNN) models which are written in Python, but it can be generalized to any Python program or distributed system, or even other languages like Java. We have implemented the system and adopted it in our deep learning model life cycle management system to catch the bottleneck while keeping our production code clean and highly performant. The implementation is open-sourced at: [https://github.com/oracle/hiq](https://github.com/oracle/hiq).
USTEP: Structuration des logs en flux gr{â}ce {à} un arbre de recherche {é}volutif
Apr 24, 2023Logs record valuable system information at runtime. They are widely used by data-driven approaches for development and monitoring purposes. Parsing log messages to structure their format is a classic preliminary step for log-mining tasks. As they appear upstream, parsing operations can become a processing time bottleneck for downstream applications. The quality of parsing also has a direct influence on their efficiency. Here, we propose USTEP, an online log parsing method based on an evolving tree structure. Evaluation results on a wide panel of datasets coming from different real-world systems demonstrate USTEP superiority in terms of both effectiveness and robustness when compared to other online methods.