 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Time series Forecasting to detect anomalous behaviours in Multiphase Flow Meters
Dec 30, 2022
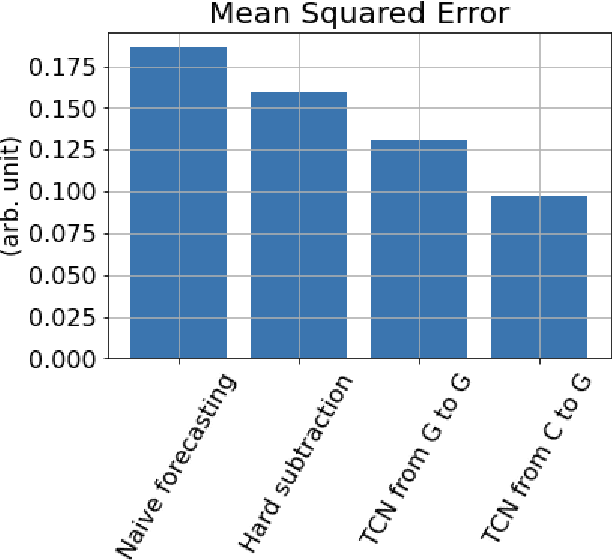
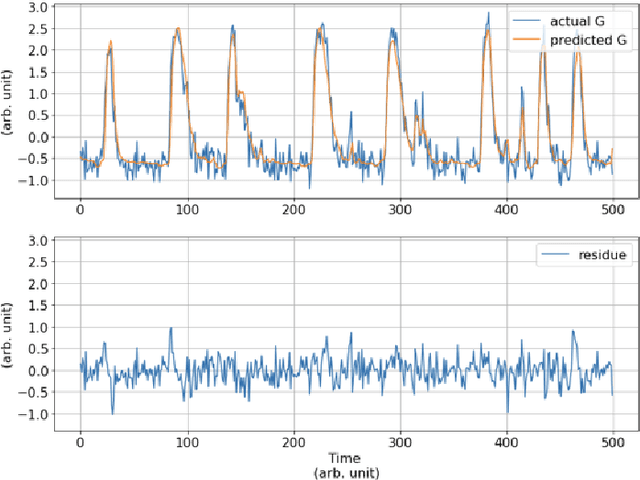
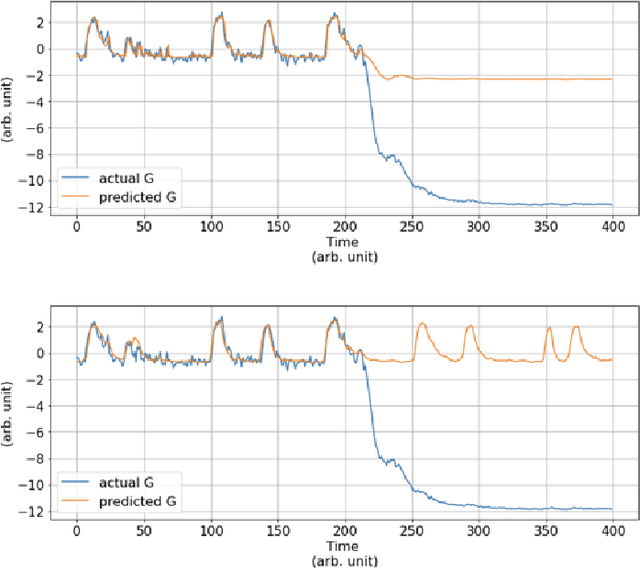
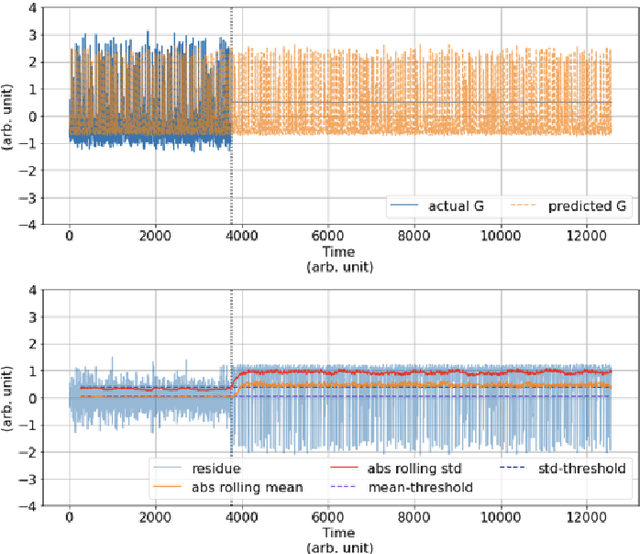
An Anomaly Detection (AD) System for Self-diagnosis has been developed for Multiphase Flow Meter (MPFM). The system relies on machine learning algorithms for time series forecasting, historical data have been used to train a model and to predict the behavior of a sensor and, thus, to detect anomalies.
First De-Trend then Attend: Rethinking Attention for Time-Series Forecasting
Dec 15, 2022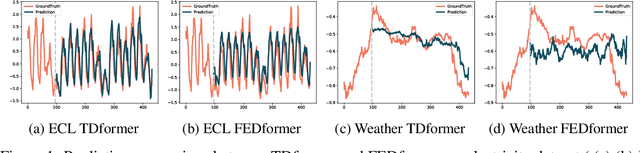

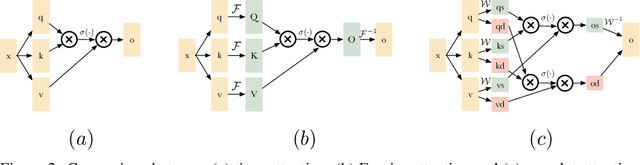

Transformer-based models have gained large popularity and demonstrated promising results in long-term time-series forecasting in recent years. In addition to learning attention in time domain, recent works also explore learning attention in frequency domains (e.g., Fourier domain, wavelet domain), given that seasonal patterns can be better captured in these domains. In this work, we seek to understand the relationships between attention models in different time and frequency domains. Theoretically, we show that attention models in different domains are equivalent under linear conditions (i.e., linear kernel to attention scores). Empirically, we analyze how attention models of different domains show different behaviors through various synthetic experiments with seasonality, trend and noise, with emphasis on the role of softmax operation therein. Both these theoretical and empirical analyses motivate us to propose a new method: TDformer (Trend Decomposition Transformer), that first applies seasonal-trend decomposition, and then additively combines an MLP which predicts the trend component with Fourier attention which predicts the seasonal component to obtain the final prediction. Extensive experiments on benchmark time-series forecasting datasets demonstrate that TDformer achieves state-of-the-art performance against existing attention-based models.
Accelerating Trajectory Generation for Quadrotors Using Transformers
Mar 27, 2023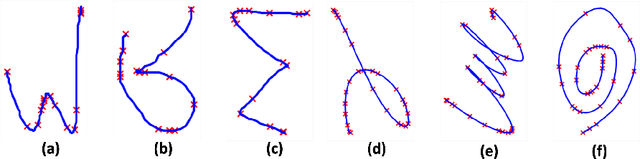
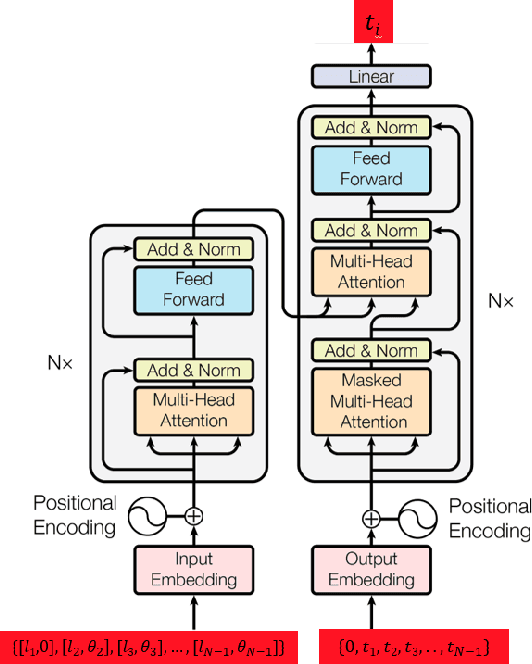
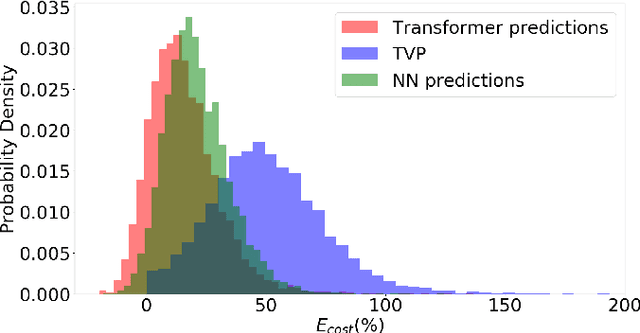
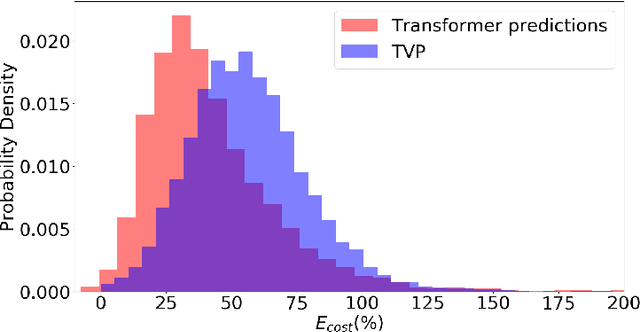
In this work, we address the problem of computation time for trajectory generation in quadrotors. Most trajectory generation methods for waypoint navigation of quadrotors, for example minimum snap/jerk and minimum-time, are structured as bi-level optimizations. The first level involves allocating time across all input waypoints and the second step is to minimize the snap/jerk of the trajectory under that time allocation. Such an optimization can be computationally expensive to solve. In our approach we treat trajectory generation as a supervised learning problem between a sequential set of inputs and outputs. We adapt a transformer model to learn the optimal time allocations for a given set of input waypoints, thus making it into a single step optimization. We demonstrate the performance of the transformer model by training it to predict the time allocations for a minimum snap trajectory generator. The trained transformer model is able to predict accurate time allocations with fewer data samples and smaller model size, compared to a feedforward network (FFN), demonstrating that it is able to model the sequential nature of the waypoint navigation problem.
An autoencoder compression approach for accelerating large-scale inverse problems
Apr 10, 2023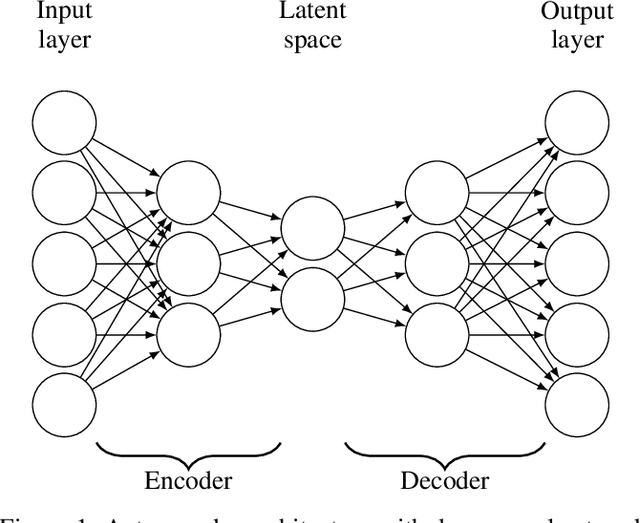



PDE-constrained inverse problems are some of the most challenging and computationally demanding problems in computational science today. Fine meshes that are required to accurately compute the PDE solution introduce an enormous number of parameters and require large scale computing resources such as more processors and more memory to solve such systems in a reasonable time. For inverse problems constrained by time dependent PDEs, the adjoint method that is often employed to efficiently compute gradients and higher order derivatives requires solving a time-reversed, so-called adjoint PDE that depends on the forward PDE solution at each timestep. This necessitates the storage of a high dimensional forward solution vector at every timestep. Such a procedure quickly exhausts the available memory resources. Several approaches that trade additional computation for reduced memory footprint have been proposed to mitigate the memory bottleneck, including checkpointing and compression strategies. In this work, we propose a close-to-ideal scalable compression approach using autoencoders to eliminate the need for checkpointing and substantial memory storage, thereby reducing both the time-to-solution and memory requirements. We compare our approach with checkpointing and an off-the-shelf compression approach on an earth-scale ill-posed seismic inverse problem. The results verify the expected close-to-ideal speedup for both the gradient and Hessian-vector product using the proposed autoencoder compression approach. To highlight the usefulness of the proposed approach, we combine the autoencoder compression with the data-informed active subspace (DIAS) prior to show how the DIAS method can be affordably extended to large scale problems without the need of checkpointing and large memory.
Unsupervised Multivariate Time-Series Transformers for Seizure Identification on EEG
Jan 03, 2023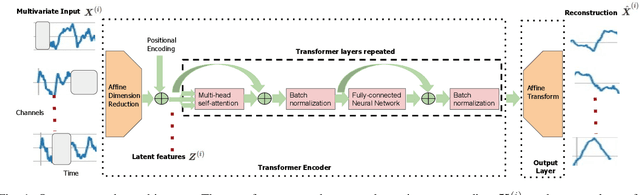

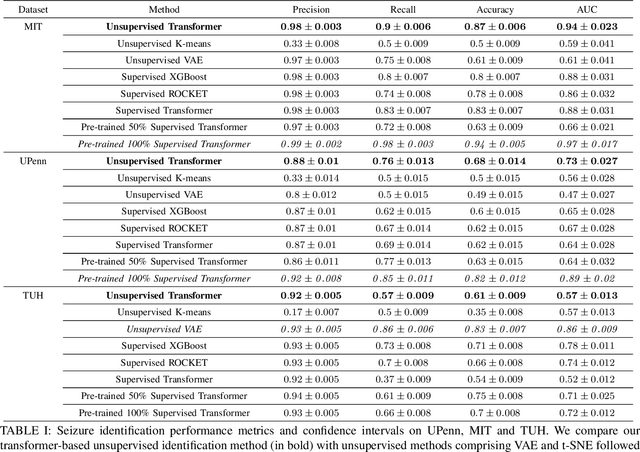
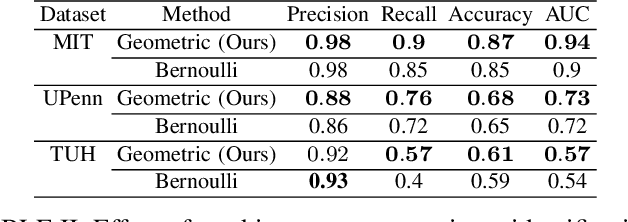
Epilepsy is one of the most common neurological disorders, typically observed via seizure episodes. Epileptic seizures are commonly monitored through electroencephalogram (EEG) recordings due to their routine and low expense collection. The stochastic nature of EEG makes seizure identification via manual inspections performed by highly-trained experts a tedious endeavor, motivating the use of automated identification. The literature on automated identification focuses mostly on supervised learning methods requiring expert labels of EEG segments that contain seizures, which are difficult to obtain. Motivated by these observations, we pose seizure identification as an unsupervised anomaly detection problem. To this end, we employ the first unsupervised transformer-based model for seizure identification on raw EEG. We train an autoencoder involving a transformer encoder via an unsupervised loss function, incorporating a novel masking strategy uniquely designed for multivariate time-series data such as EEG. Training employs EEG recordings that do not contain any seizures, while seizures are identified with respect to reconstruction errors at inference time. We evaluate our method on three publicly available benchmark EEG datasets for distinguishing seizure vs. non-seizure windows. Our method leads to significantly better seizure identification performance than supervised learning counterparts, by up to 16% recall, 9% accuracy, and 9% Area under the Receiver Operating Characteristics Curve (AUC), establishing particular benefits on highly imbalanced data. Through accurate seizure identification, our method could facilitate widely accessible and early detection of epilepsy development, without needing expensive label collection or manual feature extraction.
Few-shot Domain-Adaptive Visually-fused Event Detection from Text
May 04, 2023
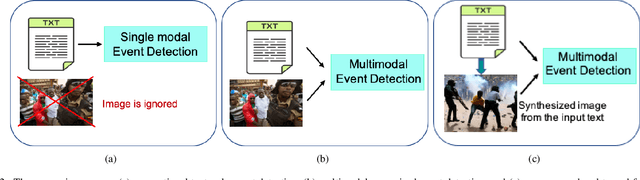
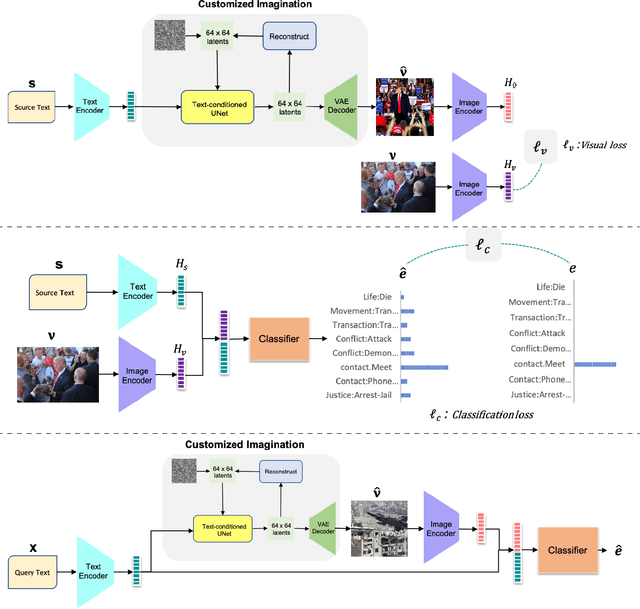

Incorporating auxiliary modalities such as images into event detection models has attracted increasing interest over the last few years. The complexity of natural language in describing situations has motivated researchers to leverage the related visual context to improve event detection performance. However, current approaches in this area suffer from data scarcity, where a large amount of labelled text-image pairs are required for model training. Furthermore, limited access to the visual context at inference time negatively impacts the performance of such models, which makes them practically ineffective in real-world scenarios. In this paper, we present a novel domain-adaptive visually-fused event detection approach that can be trained on a few labelled image-text paired data points. Specifically, we introduce a visual imaginator method that synthesises images from text in the absence of visual context. Moreover, the imaginator can be customised to a specific domain. In doing so, our model can leverage the capabilities of pre-trained vision-language models and can be trained in a few-shot setting. This also allows for effective inference where only single-modality data (i.e. text) is available. The experimental evaluation on the benchmark M2E2 dataset shows that our model outperforms existing state-of-the-art models, by up to 11 points.
Few-shot In-context Learning for Knowledge Base Question Answering
May 04, 2023
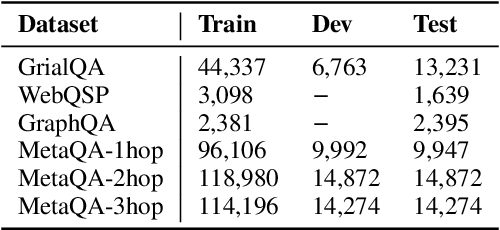
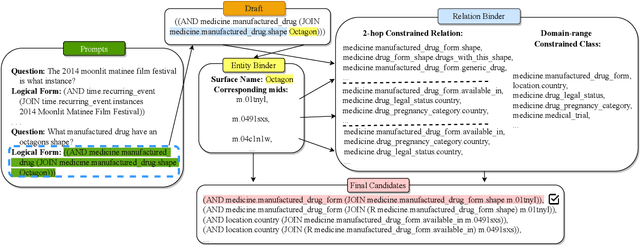
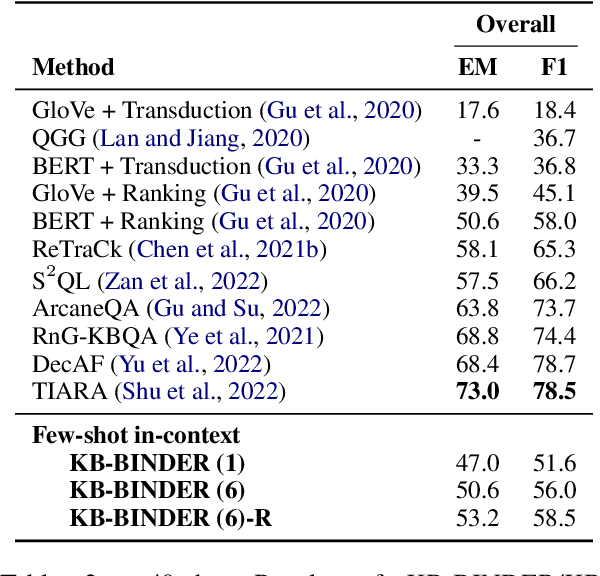
Question answering over knowledge bases is considered a difficult problem due to the challenge of generalizing to a wide variety of possible natural language questions. Additionally, the heterogeneity of knowledge base schema items between different knowledge bases often necessitates specialized training for different knowledge base question-answering (KBQA) datasets. To handle questions over diverse KBQA datasets with a unified training-free framework, we propose KB-BINDER, which for the first time enables few-shot in-context learning over KBQA tasks. Firstly, KB-BINDER leverages large language models like Codex to generate logical forms as the draft for a specific question by imitating a few demonstrations. Secondly, KB-BINDER grounds on the knowledge base to bind the generated draft to an executable one with BM25 score matching. The experimental results on four public heterogeneous KBQA datasets show that KB-BINDER can achieve a strong performance with only a few in-context demonstrations. Especially on GraphQA and 3-hop MetaQA, KB-BINDER can even outperform the state-of-the-art trained models. On GrailQA and WebQSP, our model is also on par with other fully-trained models. We believe KB-BINDER can serve as an important baseline for future research. Our code is available at https://github.com/ltl3A87/KB-BINDER.
Neuralizer: General Neuroimage Analysis without Re-Training
May 04, 2023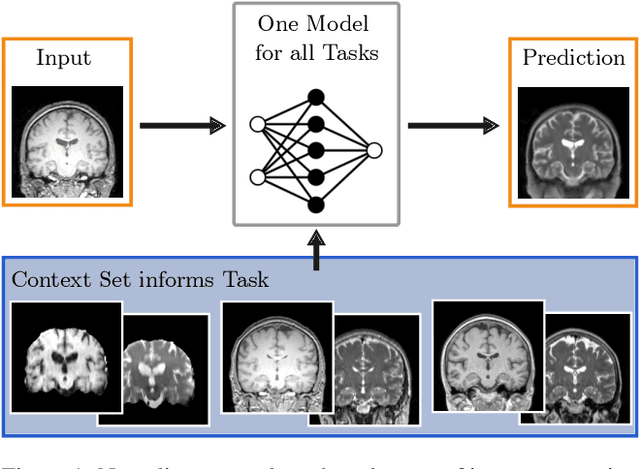
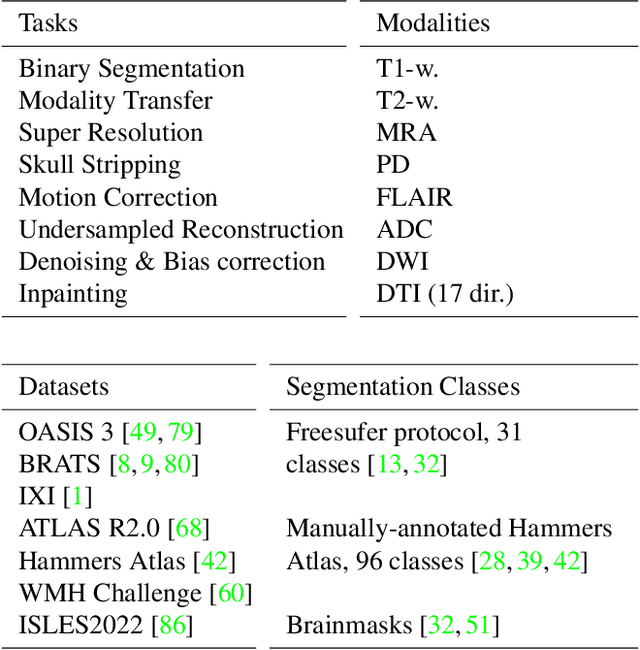
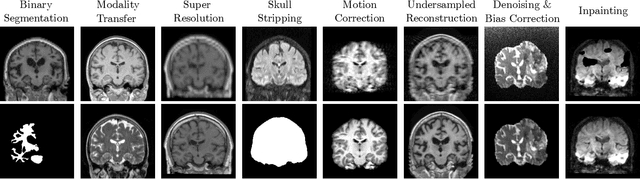

Neuroimage processing tasks like segmentation, reconstruction, and registration are central to the study of neuroscience. Robust deep learning strategies and architectures used to solve these tasks are often similar. Yet, when presented with a new task or a dataset with different visual characteristics, practitioners most often need to train a new model, or fine-tune an existing one. This is a time-consuming process that poses a substantial barrier for the thousands of neuroscientists and clinical researchers who often lack the resources or machine-learning expertise to train deep learning models. In practice, this leads to a lack of adoption of deep learning, and neuroscience tools being dominated by classical frameworks. We introduce Neuralizer, a single model that generalizes to previously unseen neuroimaging tasks and modalities without the need for re-training or fine-tuning. Tasks do not have to be known a priori, and generalization happens in a single forward pass during inference. The model can solve processing tasks across multiple image modalities, acquisition methods, and datasets, and generalize to tasks and modalities it has not been trained on. Our experiments on coronal slices show that when few annotated subjects are available, our multi-task network outperforms task-specific baselines without training on the task.
Correcting for Interference in Experiments: A Case Study at Douyin
May 04, 2023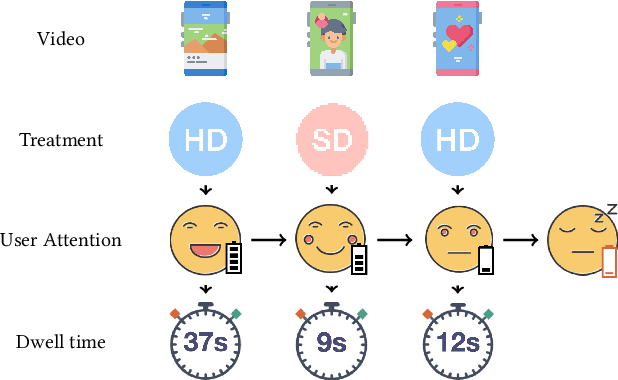
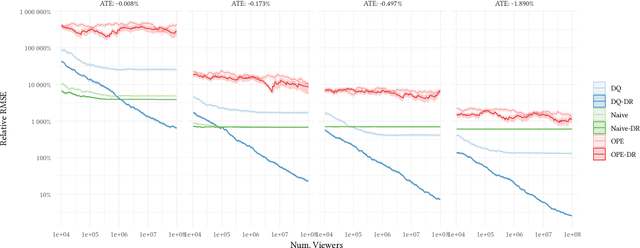
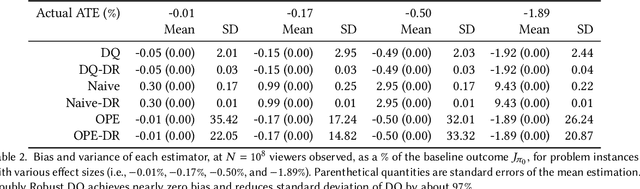
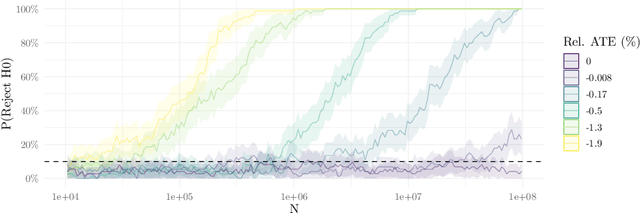
Interference is a ubiquitous problem in experiments conducted on two-sided content marketplaces, such as Douyin (China's analog of TikTok). In many cases, creators are the natural unit of experimentation, but creators interfere with each other through competition for viewers' limited time and attention. "Naive" estimators currently used in practice simply ignore the interference, but in doing so incur bias on the order of the treatment effect. We formalize the problem of inference in such experiments as one of policy evaluation. Off-policy estimators, while unbiased, are impractically high variance. We introduce a novel Monte-Carlo estimator, based on "Differences-in-Qs" (DQ) techniques, which achieves bias that is second-order in the treatment effect, while remaining sample-efficient to estimate. On the theoretical side, our contribution is to develop a generalized theory of Taylor expansions for policy evaluation, which extends DQ theory to all major MDP formulations. On the practical side, we implement our estimator on Douyin's experimentation platform, and in the process develop DQ into a truly "plug-and-play" estimator for interference in real-world settings: one which provides robust, low-bias, low-variance treatment effect estimates; admits computationally cheap, asymptotically exact uncertainty quantification; and reduces MSE by 99\% compared to the best existing alternatives in our applications.
The Manifestation of Spatial Wideband Effect in Circular Array: From Beam Split to Beam Defocus
May 04, 2023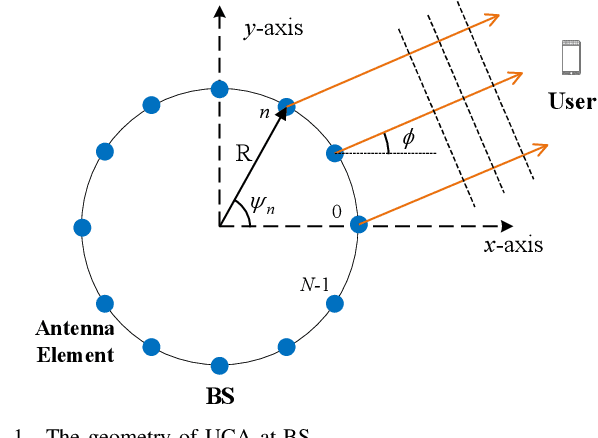
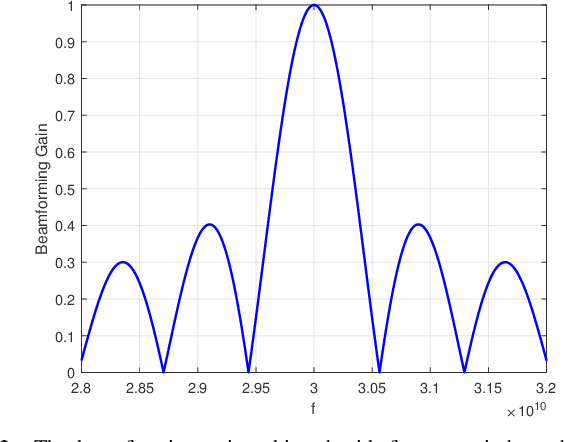
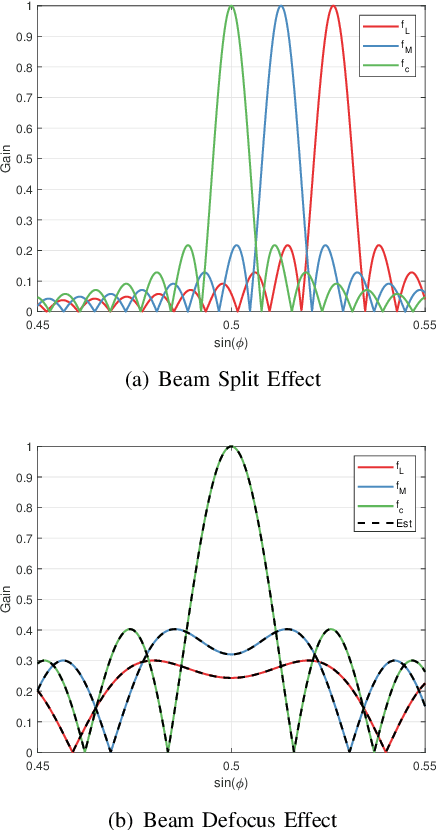
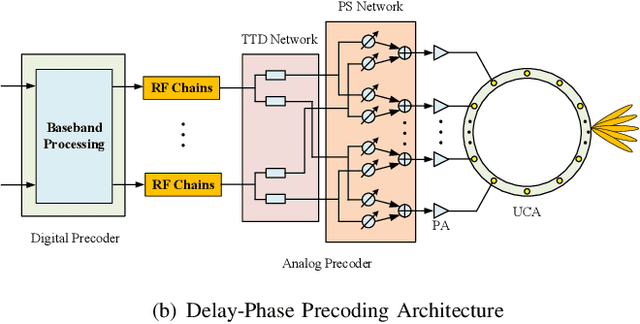
Millimeter-wave (mmWave) and terahertz (THz) communications with hybrid precoding architectures have been regarded as energy-efficient solutions to fulfill the vision of high-speed transmissions for 6G communications. Benefiting from the advantages of providing a wide scan range and flat array gain, the uniform circular array (UCA) has attracted much attention. However, the growing bandwidth of mmWave and THz communications require frequency-independent phase shifts, which can not be perfectly realized through frequency-independent phase shifters (PSs) in classical hybrid precoding architectures. This mismatch causes the beam defocus effect in UCA wideband communications, where the high-gain beams could not form at non-central frequencies. In this paper, we first investigate the characteristics of the beam defocus effect distinguishing itself from the beam split effect in uniform linear array (ULA) systems. The beam pattern of UCA in both frequency domain and angular domain is analyzed, characterizing the beamforming loss caused by the beam defocus effect. Then, the delay-phase-precoding (DPP) architecture which leverages the true-time-delay (TTD) devices to generate frequency-dependent phase shifts is employed to mitigate the beam defocus effect. Finally, performance analysis and extensive simulation results are provided to evaluate the effectiveness of the DPP architecture in UCA systems.