 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
DC3DCD: unsupervised learning for multiclass 3D point cloud change detection
May 09, 2023
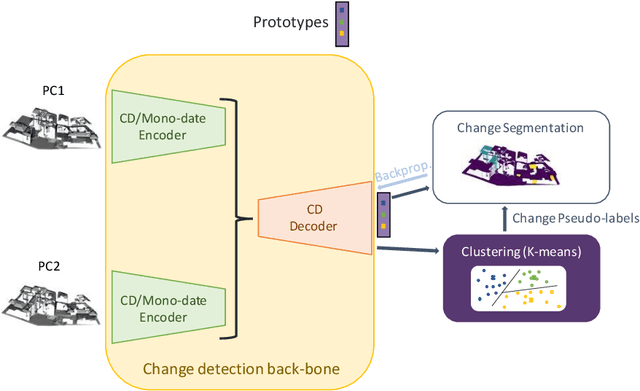
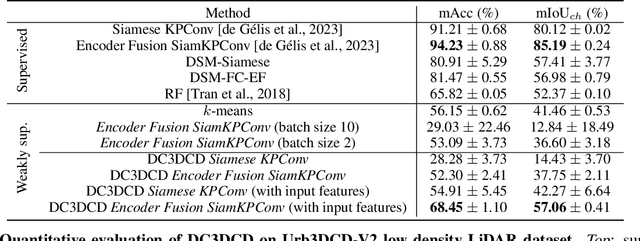
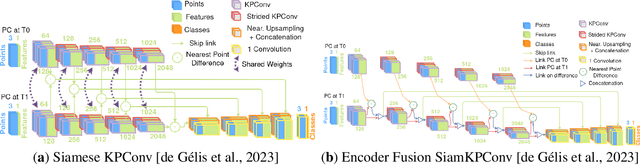
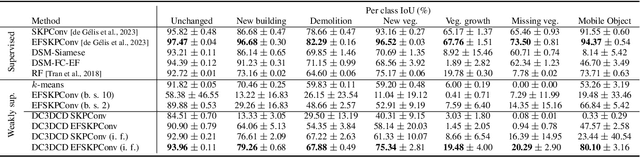
In a constant evolving world, change detection is of prime importance to keep updated maps. To better sense areas with complex geometry (urban areas in particular), considering 3D data appears to be an interesting alternative to classical 2D images. In this context, 3D point clouds (PCs) obtained by LiDAR or photogrammetry are very interesting. While recent studies showed the considerable benefit of using deep learning-based methods to detect and characterize changes into raw 3D PCs, these studies rely on large annotated training data to obtain accurate results. The collection of these annotations are tricky and time-consuming. The availability of unsupervised or weakly supervised approaches is then of prime interest. In this paper, we propose an unsupervised method, called DeepCluster 3D Change Detection (DC3DCD), to detect and categorize multiclass changes at point level. We classify our approach in the unsupervised family given the fact that we extract in a completely unsupervised way a number of clusters associated with potential changes. Let us precise that in the end of the process, the user has only to assign a label to each of these clusters to derive the final change map. Our method builds upon the DeepCluster approach, originally designed for image classification, to handle complex raw 3D PCs and perform change segmentation task. An assessment of the method on both simulated and real public dataset is provided. The proposed method allows to outperform fully-supervised traditional machine learning algorithm and to be competitive with fully-supervised deep learning networks applied on rasterization of 3D PCs with a mean of IoU over classes of change of 57.06% and 66.69% for the simulated and the real datasets, respectively.
An Enhanced Sampling-Based Method With Modified Next-Best View Strategy For 2D Autonomous Robot Exploration
May 08, 2023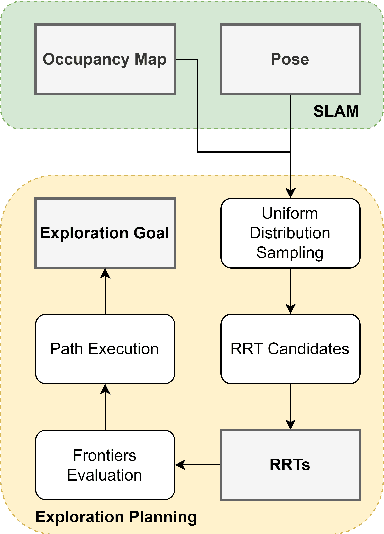
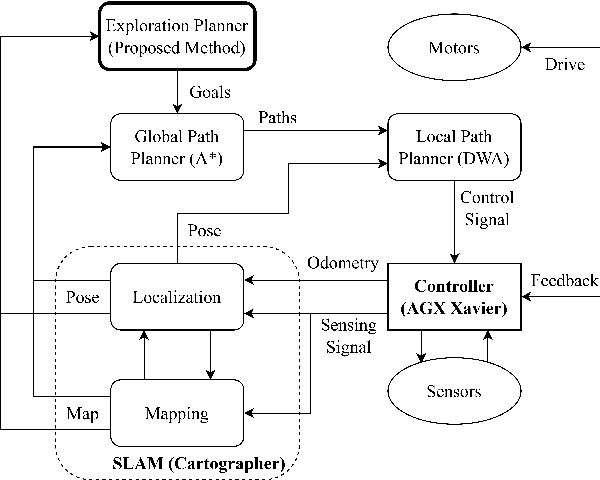
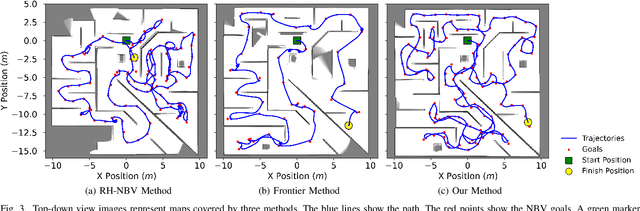
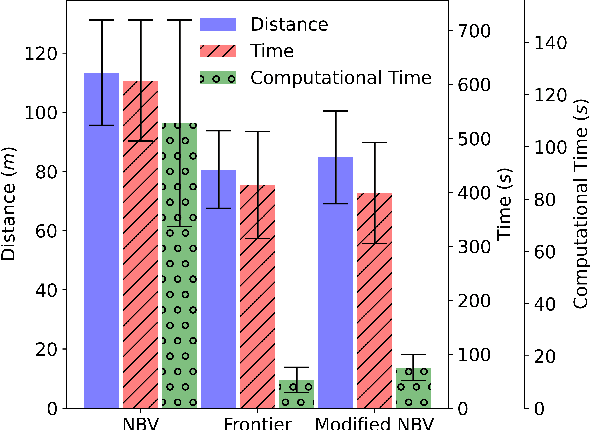
Autonomous exploration is a new technology in the field of robotics that has found widespread application due to its objective to help robots independently localize, scan maps, and navigate any terrain without human control. Up to present, the sampling-based exploration strategies have been the most effective for aerial and ground vehicles equipped with depth sensors producing three-dimensional point clouds. Those methods utilize the sampling task to choose random points or make samples based on Rapidly-exploring Random Trees (RRT). Then, they decide on frontiers or Next Best Views (NBV) with useful volumetric information. However, most state-of-the-art sampling-based methodology is challenging to implement in two-dimensional robots due to the lack of environmental knowledge, thus resulting in a bad volumetric gain for evaluating random destinations. This study proposed an enhanced sampling-based solution for indoor robot exploration to decide Next Best View (NBV) in 2D environments. Our method makes RRT until have the endpoints as frontiers and evaluates those with the enhanced utility function. The volumetric information obtained from environments was estimated using non-uniform distribution to determine cells that are occupied and have an uncertain probability. Compared to the sampling-based Frontier Detection and Receding Horizon NBV approaches, the methodology executed performed better in Gazebo platform-simulated environments, achieving a significantly larger explored area, with the average distance and time traveled being reduced. Moreover, the operated proposed method on an author-built 2D robot exploring the entire natural environment confirms that the method is effective and applicable in real-world scenarios.
Multimodal Detection and Identification of Robot Manipulation Failures
May 08, 2023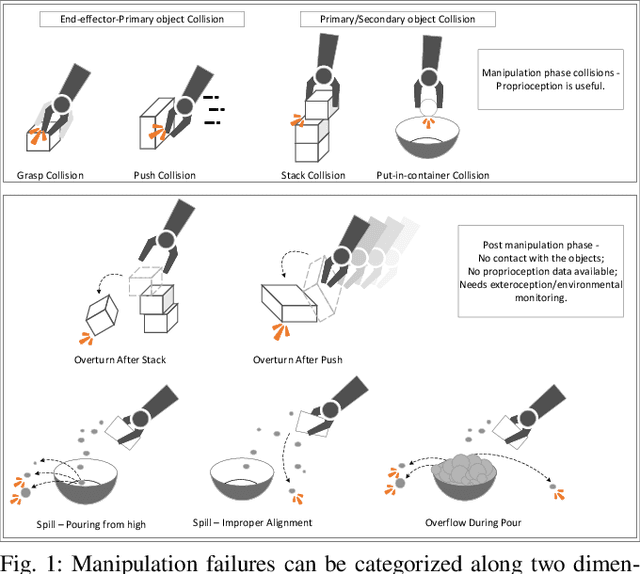

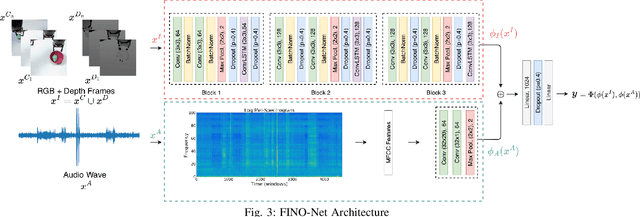
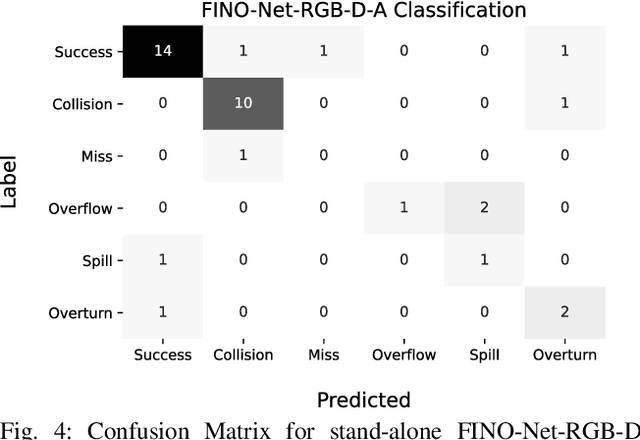
An autonomous service robot should be able to interact with its environment safely and robustly without requiring human assistance. Unstructured environments are challenging for robots since the exact prediction of outcomes is not always possible. Even when the robot behaviors are well-designed, the unpredictable nature of physical robot-object interaction may prevent success in object manipulation. Therefore, execution of a manipulation action may result in an undesirable outcome involving accidents or damages to the objects or environment. Situation awareness becomes important in such cases to enable the robot to (i) maintain the integrity of both itself and the environment, (ii) recover from failed tasks in the short term, and (iii) learn to avoid failures in the long term. For this purpose, robot executions should be continuously monitored, and failures should be detected and classified appropriately. In this work, we focus on detecting and classifying both manipulation and post-manipulation phase failures using the same exteroception setup. We cover a diverse set of failure types for primary tabletop manipulation actions. In order to detect these failures, we propose FINO-Net [1], a deep multimodal sensor fusion based classifier network. Proposed network accurately detects and classifies failures from raw sensory data without any prior knowledge. In this work, we use our extended FAILURE dataset [1] with 99 new multimodal manipulation recordings and annotate them with their corresponding failure types. FINO-Net achieves 0.87 failure detection and 0.80 failure classification F1 scores. Experimental results show that proposed architecture is also appropriate for real-time use.
Light-weight Deep Extreme Multilabel Classification
Apr 20, 2023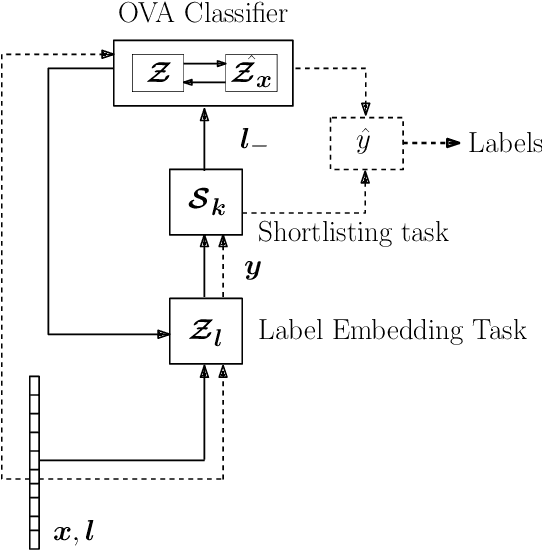
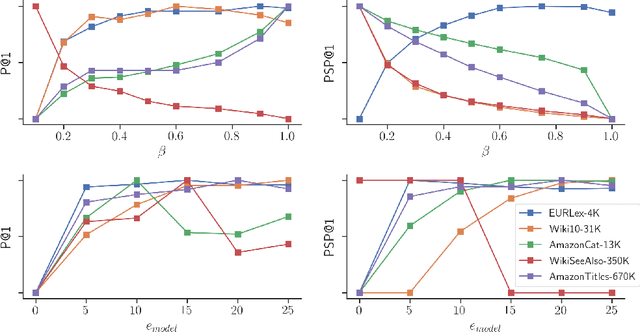

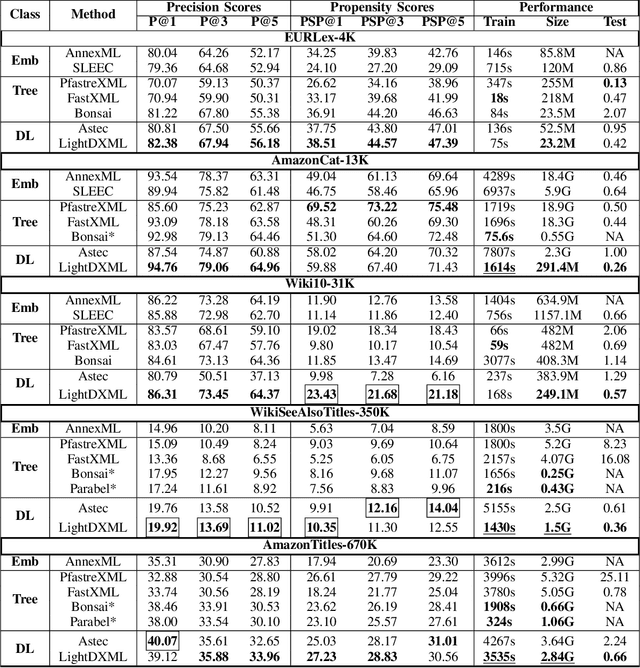
Extreme multi-label (XML) classification refers to the task of supervised multi-label learning that involves a large number of labels. Hence, scalability of the classifier with increasing label dimension is an important consideration. In this paper, we develop a method called LightDXML which modifies the recently developed deep learning based XML framework by using label embeddings instead of feature embedding for negative sampling and iterating cyclically through three major phases: (1) proxy training of label embeddings (2) shortlisting of labels for negative sampling and (3) final classifier training using the negative samples. Consequently, LightDXML also removes the requirement of a re-ranker module, thereby, leading to further savings on time and memory requirements. The proposed method achieves the best of both worlds: while the training time, model size and prediction times are on par or better compared to the tree-based methods, it attains much better prediction accuracy that is on par with the deep learning based methods. Moreover, the proposed approach achieves the best tail-label prediction accuracy over most state-of-the-art XML methods on some of the large datasets\footnote{accepted in IJCNN 2023, partial funding from MAPG grant and IIIT Seed grant at IIIT, Hyderabad, India. Code: \url{https://github.com/misterpawan/LightDXML}
Efficient Quantum Algorithms for Quantum Optimal Control
Apr 05, 2023
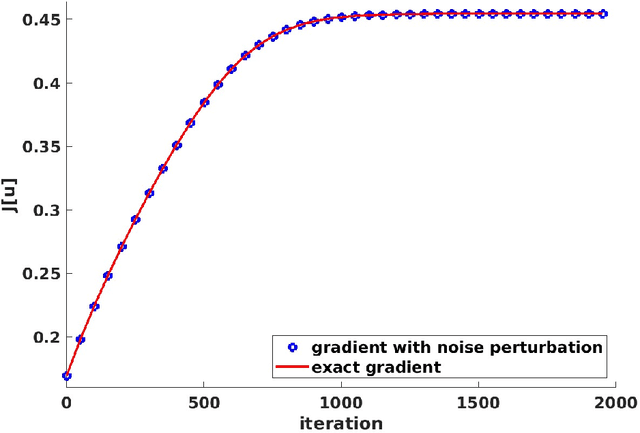
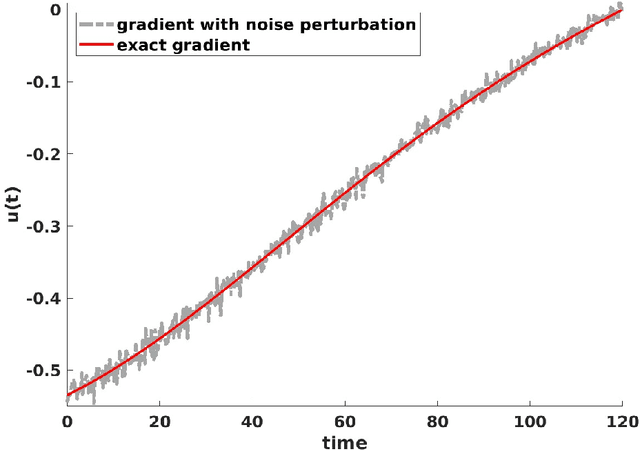
In this paper, we present efficient quantum algorithms that are exponentially faster than classical algorithms for solving the quantum optimal control problem. This problem involves finding the control variable that maximizes a physical quantity at time $T$, where the system is governed by a time-dependent Schr\"odinger equation. This type of control problem also has an intricate relation with machine learning. Our algorithms are based on a time-dependent Hamiltonian simulation method and a fast gradient-estimation algorithm. We also provide a comprehensive error analysis to quantify the total error from various steps, such as the finite-dimensional representation of the control function, the discretization of the Schr\"odinger equation, the numerical quadrature, and optimization. Our quantum algorithms require fault-tolerant quantum computers.
eTOP: Early Termination of Pipelines for Faster Training of AutoML Systems
Apr 17, 2023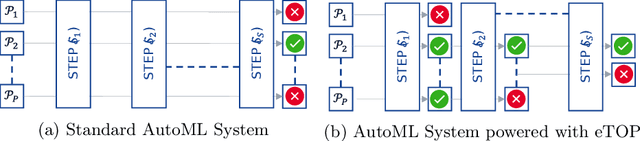

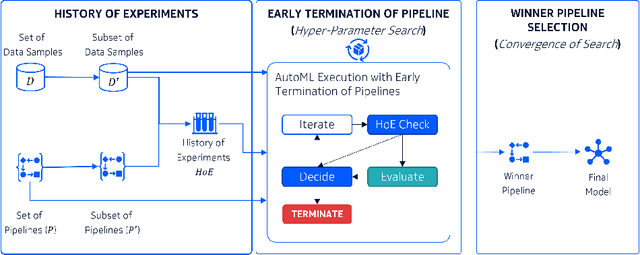
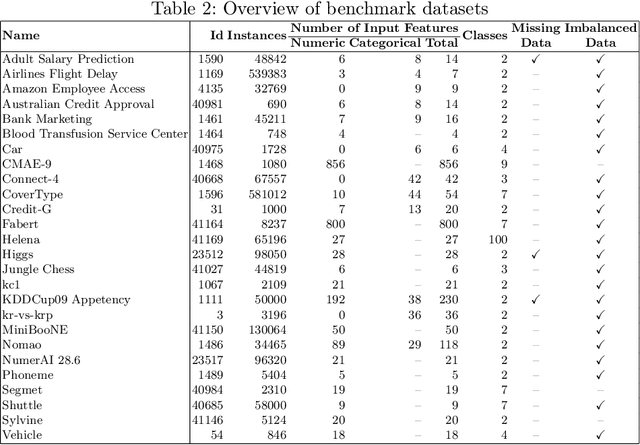
Recent advancements in software and hardware technologies have enabled the use of AI/ML models in everyday applications has significantly improved the quality of service rendered. However, for a given application, finding the right AI/ML model is a complex and costly process, that involves the generation, training, and evaluation of multiple interlinked steps (called pipelines), such as data pre-processing, feature engineering, selection, and model tuning. These pipelines are complex (in structure) and costly (both in compute resource and time) to execute end-to-end, with a hyper-parameter associated with each step. AutoML systems automate the search of these hyper-parameters but are slow, as they rely on optimizing the pipeline's end output. We propose the eTOP Framework which works on top of any AutoML system and decides whether or not to execute the pipeline to the end or terminate at an intermediate step. Experimental evaluation on 26 benchmark datasets and integration of eTOPwith MLBox4 reduces the training time of the AutoML system upto 40x than baseline MLBox.
Always Strengthen Your Strengths: A Drift-Aware Incremental Learning Framework for CTR Prediction
Apr 17, 2023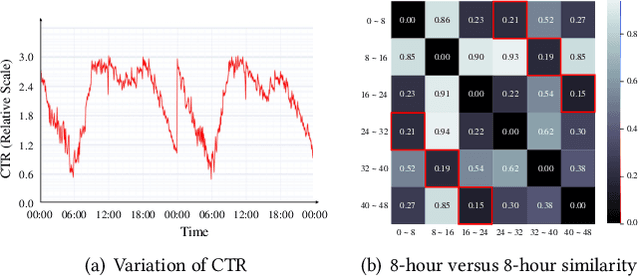

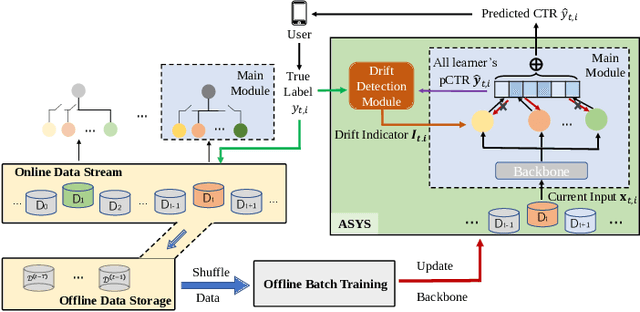
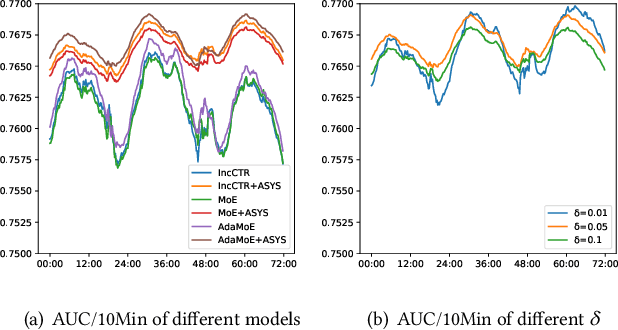
Click-through rate (CTR) prediction is of great importance in recommendation systems and online advertising platforms. When served in industrial scenarios, the user-generated data observed by the CTR model typically arrives as a stream. Streaming data has the characteristic that the underlying distribution drifts over time and may recur. This can lead to catastrophic forgetting if the model simply adapts to new data distribution all the time. Also, it's inefficient to relearn distribution that has been occurred. Due to memory constraints and diversity of data distributions in large-scale industrial applications, conventional strategies for catastrophic forgetting such as replay, parameter isolation, and knowledge distillation are difficult to be deployed. In this work, we design a novel drift-aware incremental learning framework based on ensemble learning to address catastrophic forgetting in CTR prediction. With explicit error-based drift detection on streaming data, the framework further strengthens well-adapted ensembles and freezes ensembles that do not match the input distribution avoiding catastrophic interference. Both evaluations on offline experiments and A/B test shows that our method outperforms all baselines considered.
Can a virtual conductor create its own interpretation of a music orchestra?
Apr 17, 2023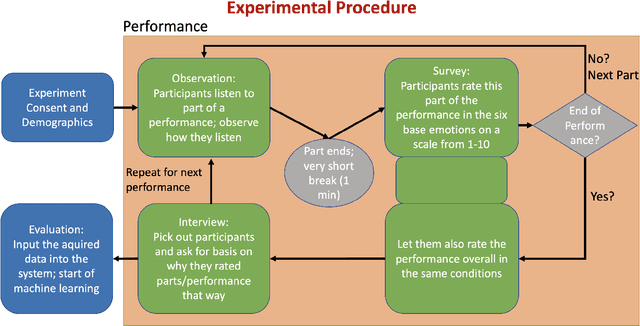
Having a computer do the work for you has become more and more common over time. But in the entertainment area, where a human is a creator, we want to avoid having too much influence on technology. On the other hand, inspiration is still important; we developed a virtual conductor that can generate an emotionally associated interpretation of known music work. This was done by surveying a set number of people to determine, which emotions were associated with a specific interpretation and instruments. As a result of machine learning this conductor was then able to achieve his goal. Unlike earlier studies of virtual conductors, which would replace the role of a human conductor, this new one is supposed to be an assisting tool for conductors. As a result, starting on a new interpretation will be easier because it streamlines research time and provides a technical perspective that can inspire new ideas. By using this technology as a supplement to human creativity, we can create richer, more nuanced interpretations of musical works.
Self-Supervised Mental Disorder Classifiers via Time Reversal
Nov 30, 2022
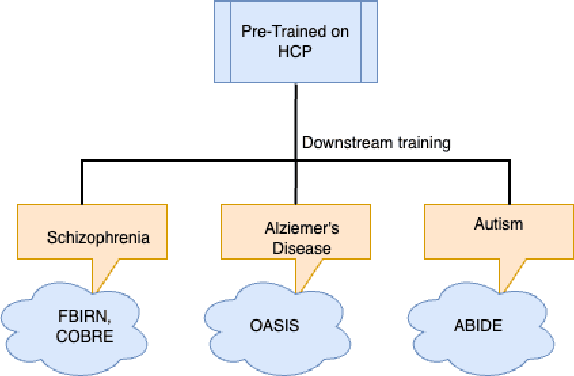
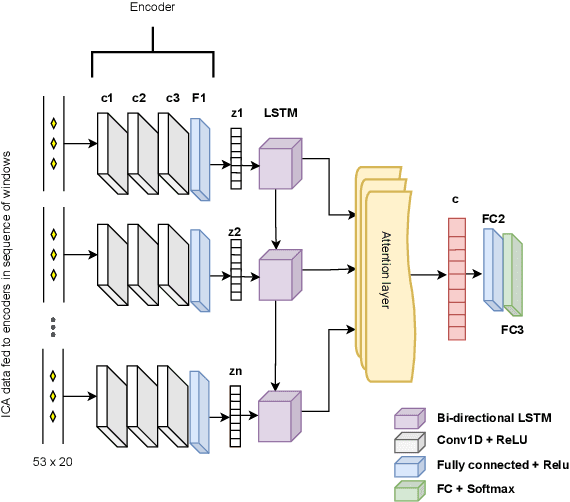
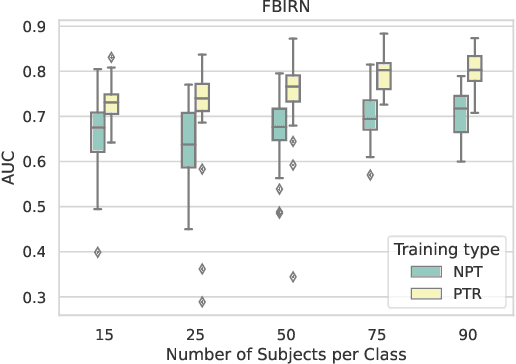
Data scarcity is a notable problem, especially in the medical domain, due to patient data laws. Therefore, efficient Pre-Training techniques could help in combating this problem. In this paper, we demonstrate that a model trained on the time direction of functional neuro-imaging data could help in any downstream task, for example, classifying diseases from healthy controls in fMRI data. We train a Deep Neural Network on Independent components derived from fMRI data using the Independent component analysis (ICA) technique. It learns time direction in the ICA-based data. This pre-trained model is further trained to classify brain disorders in different datasets. Through various experiments, we have shown that learning time direction helps a model learn some causal relation in fMRI data that helps in faster convergence, and consequently, the model generalizes well in downstream classification tasks even with fewer data records.
Fracture Detection in Pediatric Wrist Trauma X-ray Images Using YOLOv8 Algorithm
Apr 21, 2023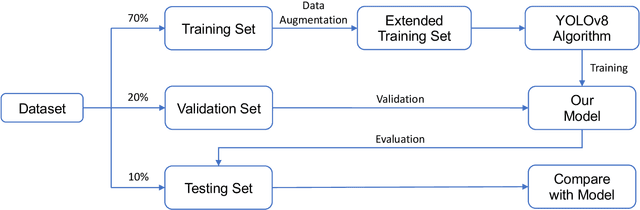
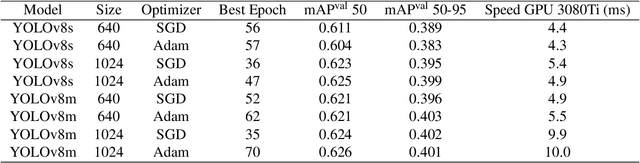
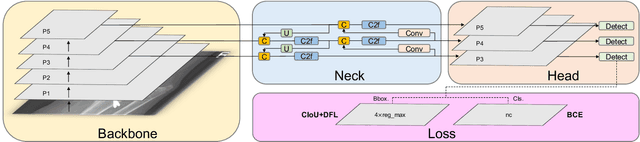
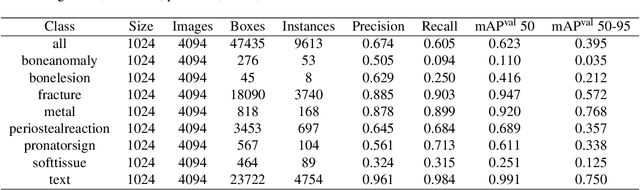
Hospital emergency departments frequently receive lots of bone fracture cases, with pediatric wrist trauma fracture accounting for the majority of them. Before pediatric surgeons perform surgery, they need to ask patients how the fracture occurred and analyze the fracture situation by interpreting X-ray images. The interpretation of X-ray images often requires a combination of techniques from radiologists and surgeons, which requires time-consuming specialized training. With the rise of deep learning in the field of computer vision, network models applying for fracture detection has become an important research topic. In this paper, YOLOv8 algorithm is used to train models on the GRAZPEDWRI-DX dataset, which includes X-ray images from 6,091 pediatric patients with wrist trauma. The experimental results show that YOLOv8 algorithm models have different advantages for different model sizes, with YOLOv8l model achieving the highest mean average precision (mAP 50) of 63.6%, and YOLOv8n model achieving the inference time of 67.4ms per X-ray image on one single CPU with low computing power. This work demonstrates that YOLOv8 algorithm has good generalizability and creates the "Fracture Detection Using YOLOv8 App" to assist surgeons in interpreting fractures in X-ray images, reducing the probability of error, and providing more useful information for fracture surgery. Our implementation code is released at https://github.com/RuiyangJu/Bone_Fracture_Detection_YOLOv8.