 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Machine-Learned Invertible Coarse Graining for Multiscale Molecular Modeling
May 02, 2023
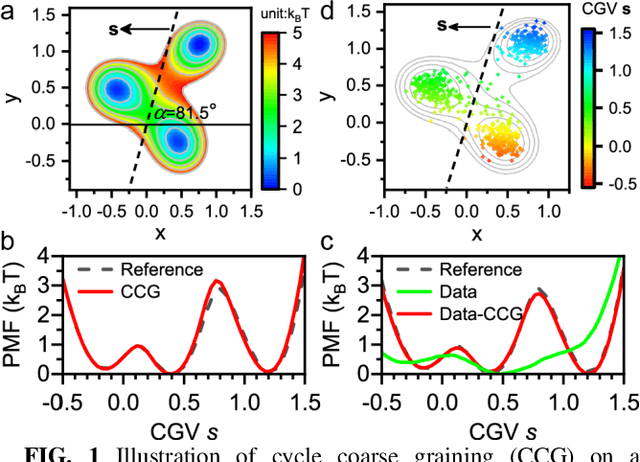
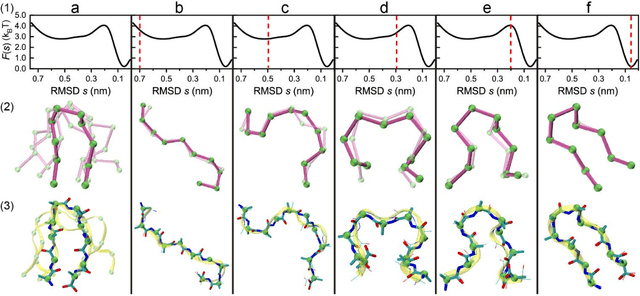
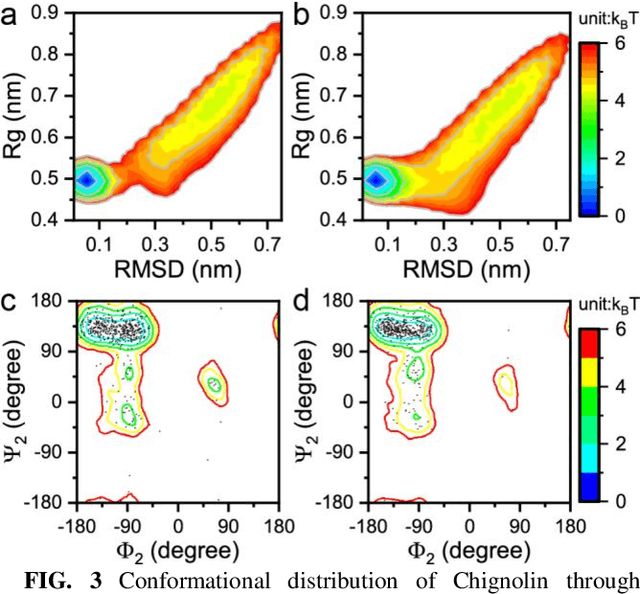
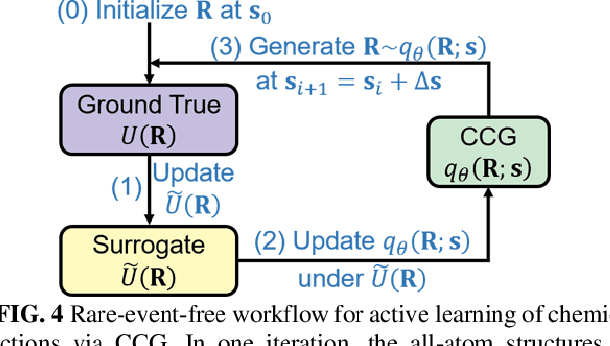
Multiscale molecular modeling is widely applied in scientific research of molecular properties over large time and length scales. Two specific challenges are commonly present in multiscale modeling, provided that information between the coarse and fine representations of molecules needs to be properly exchanged: One is to construct coarse grained (CG) models by passing information from the fine to coarse levels; the other is to restore finer molecular details given CG configurations. Although these two problems are commonly addressed independently, in this work, we present a theory connecting them, and develop a methodology called Cycle Coarse Graining (CCG) to solve both problems in a unified manner. In CCG, reconstruction can be achieved via a tractable optimization process, leading to a general method to retrieve fine details from CG simulations, which in turn, delivers a new solution to the CG problem, yielding an efficient way to calculate free energies in a rare-event-free manner. CCG thus provides a systematic way for multiscale molecular modeling, where the finer details of CG simulations can be efficiently retrieved, and the CG models can be improved consistently.
Multimodal Detection and Identification of Robot Manipulation Failures
May 08, 2023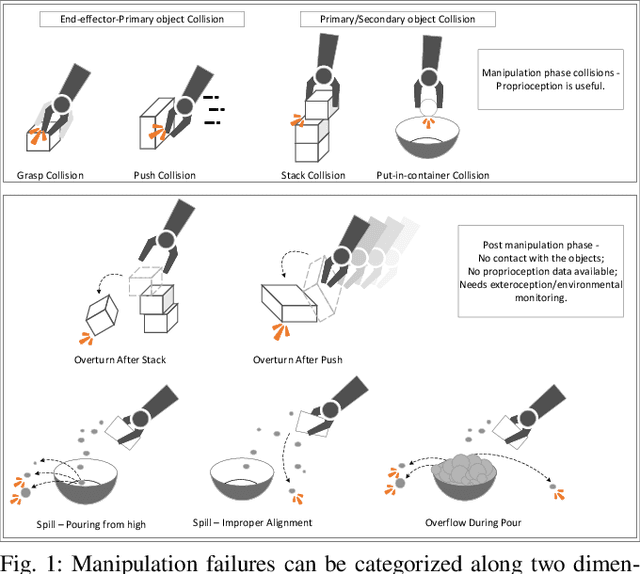

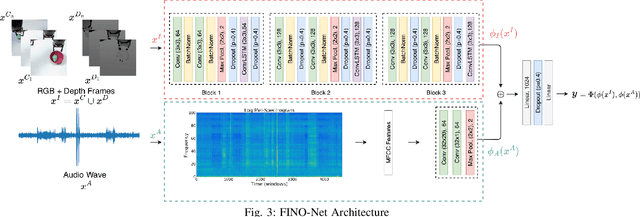
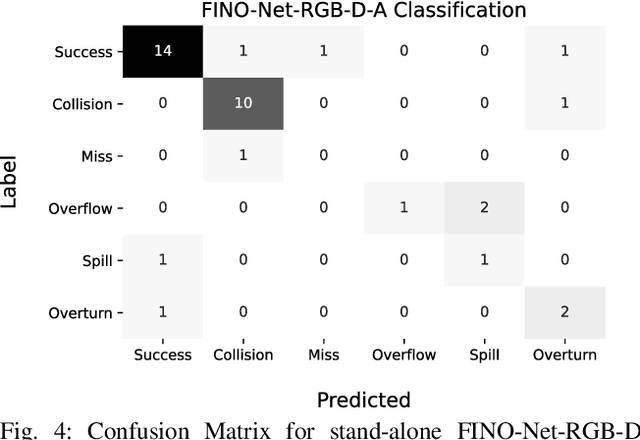
An autonomous service robot should be able to interact with its environment safely and robustly without requiring human assistance. Unstructured environments are challenging for robots since the exact prediction of outcomes is not always possible. Even when the robot behaviors are well-designed, the unpredictable nature of physical robot-object interaction may prevent success in object manipulation. Therefore, execution of a manipulation action may result in an undesirable outcome involving accidents or damages to the objects or environment. Situation awareness becomes important in such cases to enable the robot to (i) maintain the integrity of both itself and the environment, (ii) recover from failed tasks in the short term, and (iii) learn to avoid failures in the long term. For this purpose, robot executions should be continuously monitored, and failures should be detected and classified appropriately. In this work, we focus on detecting and classifying both manipulation and post-manipulation phase failures using the same exteroception setup. We cover a diverse set of failure types for primary tabletop manipulation actions. In order to detect these failures, we propose FINO-Net [1], a deep multimodal sensor fusion based classifier network. Proposed network accurately detects and classifies failures from raw sensory data without any prior knowledge. In this work, we use our extended FAILURE dataset [1] with 99 new multimodal manipulation recordings and annotate them with their corresponding failure types. FINO-Net achieves 0.87 failure detection and 0.80 failure classification F1 scores. Experimental results show that proposed architecture is also appropriate for real-time use.
An Enhanced Sampling-Based Method With Modified Next-Best View Strategy For 2D Autonomous Robot Exploration
May 08, 2023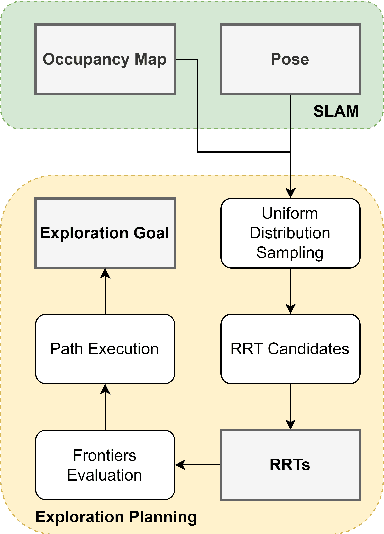
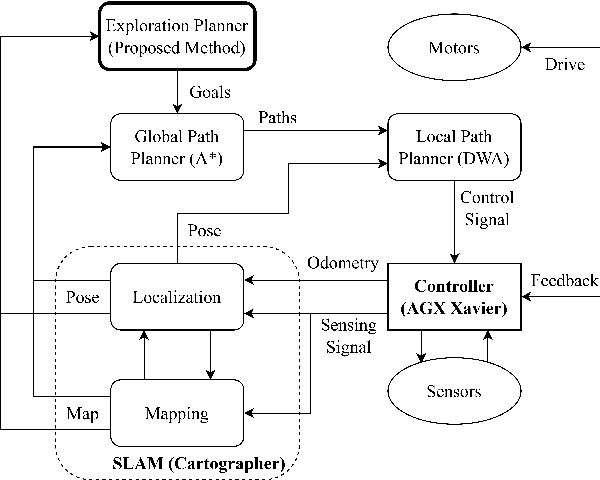
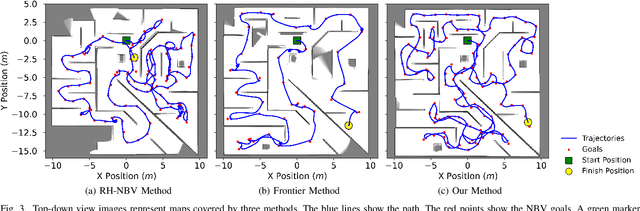
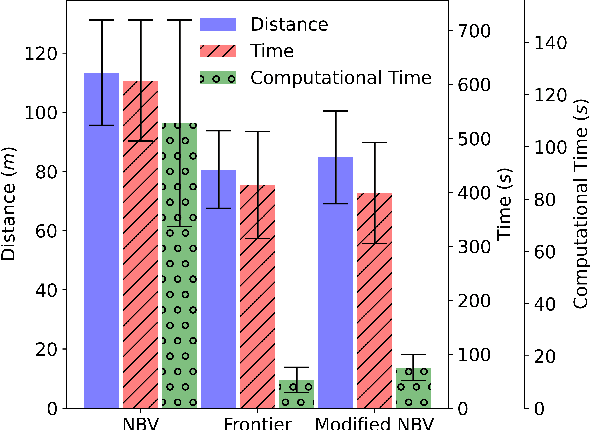
Autonomous exploration is a new technology in the field of robotics that has found widespread application due to its objective to help robots independently localize, scan maps, and navigate any terrain without human control. Up to present, the sampling-based exploration strategies have been the most effective for aerial and ground vehicles equipped with depth sensors producing three-dimensional point clouds. Those methods utilize the sampling task to choose random points or make samples based on Rapidly-exploring Random Trees (RRT). Then, they decide on frontiers or Next Best Views (NBV) with useful volumetric information. However, most state-of-the-art sampling-based methodology is challenging to implement in two-dimensional robots due to the lack of environmental knowledge, thus resulting in a bad volumetric gain for evaluating random destinations. This study proposed an enhanced sampling-based solution for indoor robot exploration to decide Next Best View (NBV) in 2D environments. Our method makes RRT until have the endpoints as frontiers and evaluates those with the enhanced utility function. The volumetric information obtained from environments was estimated using non-uniform distribution to determine cells that are occupied and have an uncertain probability. Compared to the sampling-based Frontier Detection and Receding Horizon NBV approaches, the methodology executed performed better in Gazebo platform-simulated environments, achieving a significantly larger explored area, with the average distance and time traveled being reduced. Moreover, the operated proposed method on an author-built 2D robot exploring the entire natural environment confirms that the method is effective and applicable in real-world scenarios.
Integrated Ray-Tracing and Coverage Planning Control using Reinforcement Learning
Apr 19, 2023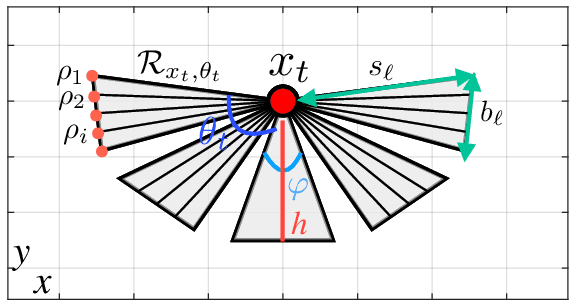
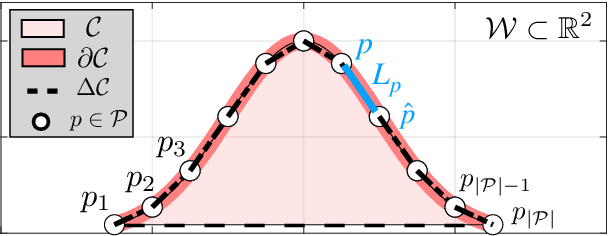
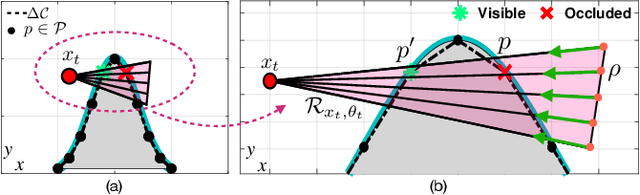
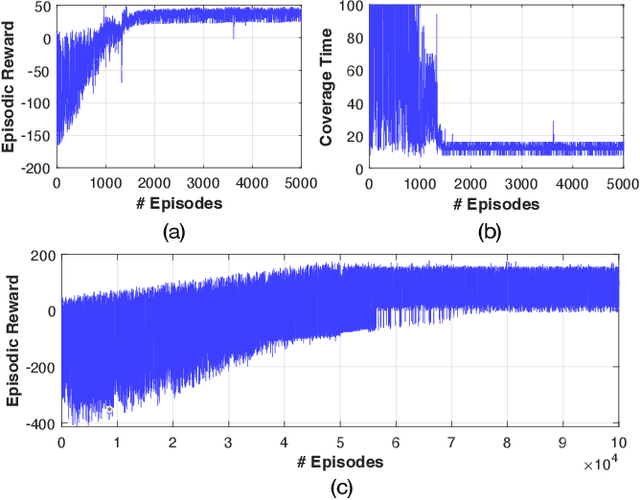
In this work we propose a coverage planning control approach which allows a mobile agent, equipped with a controllable sensor (i.e., a camera) with limited sensing domain (i.e., finite sensing range and angle of view), to cover the surface area of an object of interest. The proposed approach integrates ray-tracing into the coverage planning process, thus allowing the agent to identify which parts of the scene are visible at any point in time. The problem of integrated ray-tracing and coverage planning control is first formulated as a constrained optimal control problem (OCP), which aims at determining the agent's optimal control inputs over a finite planning horizon, that minimize the coverage time. Efficiently solving the resulting OCP is however very challenging due to non-convex and non-linear visibility constraints. To overcome this limitation, the problem is converted into a Markov decision process (MDP) which is then solved using reinforcement learning. In particular, we show that a controller which follows an optimal control law can be learned using off-policy temporal-difference control (i.e., Q-learning). Extensive numerical experiments demonstrate the effectiveness of the proposed approach for various configurations of the agent and the object of interest.
* 2022 IEEE 61st Conference on Decision and Control (CDC), 06-09 December 2022, Cancun, Mexico
Recurrent neural network based parameter estimation of Hawkes model on high-frequency financial data
Apr 24, 2023This study examines the use of a recurrent neural network for estimating the parameters of a Hawkes model based on high-frequency financial data, and subsequently, for computing volatility. Neural networks have shown promising results in various fields, and interest in finance is also growing. Our approach demonstrates significantly faster computational performance compared to traditional maximum likelihood estimation methods while yielding comparable accuracy in both simulation and empirical studies. Furthermore, we demonstrate the application of this method for real-time volatility measurement, enabling the continuous estimation of financial volatility as new price data keeps coming from the market.
Model Evaluation in Medical Datasets Over Time
Nov 14, 2022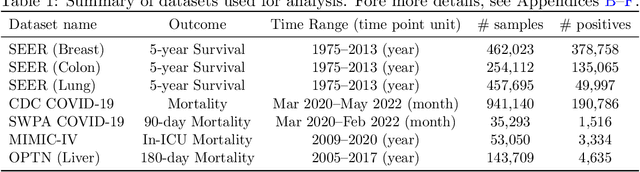
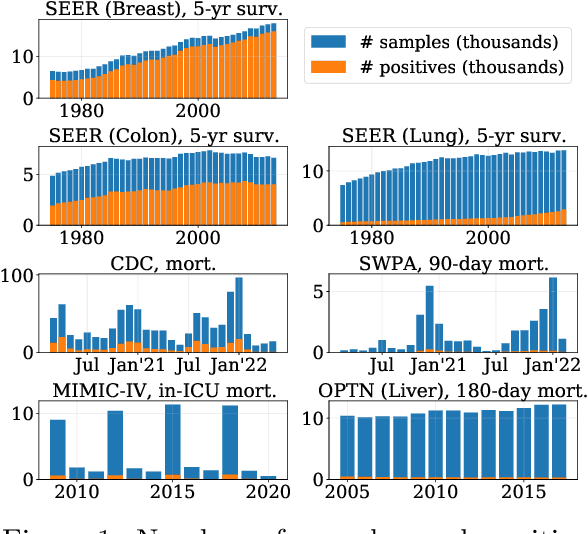
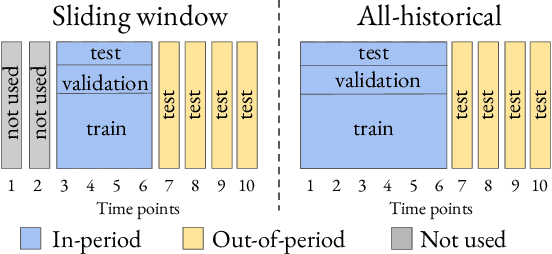
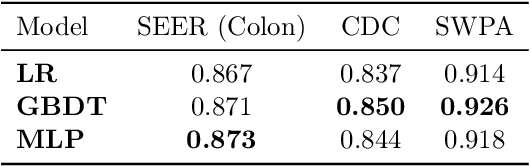
Machine learning models deployed in healthcare systems face data drawn from continually evolving environments. However, researchers proposing such models typically evaluate them in a time-agnostic manner, with train and test splits sampling patients throughout the entire study period. We introduce the Evaluation on Medical Datasets Over Time (EMDOT) framework and Python package, which evaluates the performance of a model class over time. Across five medical datasets and a variety of models, we compare two training strategies: (1) using all historical data, and (2) using a window of the most recent data. We note changes in performance over time, and identify possible explanations for these shocks.
Pushing the Boundaries of Tractable Multiperspective Reasoning: A Deduction Calculus for Standpoint EL+
Apr 27, 2023
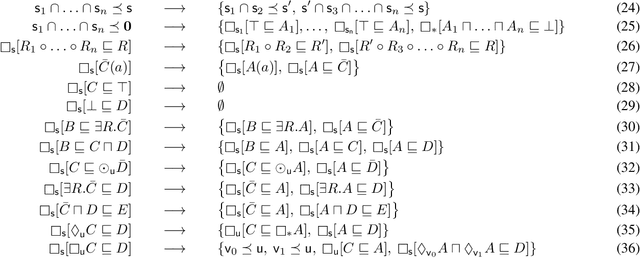

Standpoint EL is a multi-modal extension of the popular description logic EL that allows for the integrated representation of domain knowledge relative to diverse standpoints or perspectives. Advantageously, its satisfiability problem has recently been shown to be in PTime, making it a promising framework for large-scale knowledge integration. In this paper, we show that we can further push the expressivity of this formalism, arriving at an extended logic, called Standpoint EL+, which allows for axiom negation, role chain axioms, self-loops, and other features, while maintaining tractability. This is achieved by designing a satisfiability-checking deduction calculus, which at the same time addresses the need for practical algorithms. We demonstrate the feasibility of our calculus by presenting a prototypical Datalog implementation of its deduction rules.
GPT-PINN: Generative Pre-Trained Physics-Informed Neural Networks toward non-intrusive Meta-learning of parametric PDEs
Apr 11, 2023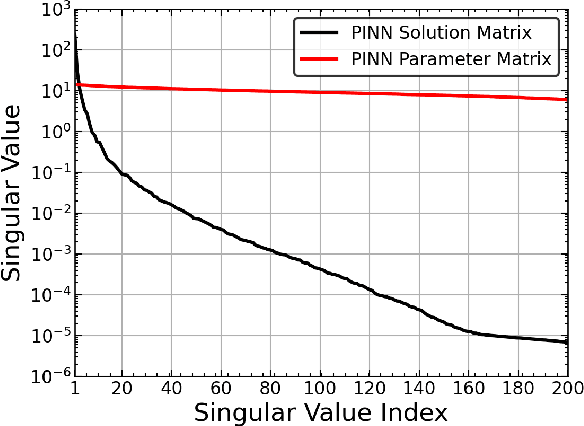

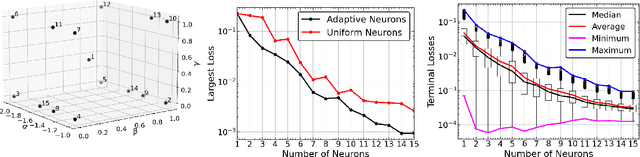
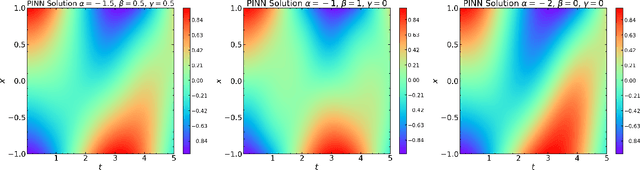
Physics-Informed Neural Network (PINN) has proven itself a powerful tool to obtain the numerical solutions of nonlinear partial differential equations (PDEs) leveraging the expressivity of deep neural networks and the computing power of modern heterogeneous hardware. However, its training is still time-consuming, especially in the multi-query and real-time simulation settings, and its parameterization often overly excessive. In this paper, we propose the Generative Pre-Trained PINN (GPT-PINN) to mitigate both challenges in the setting of parametric PDEs. GPT-PINN represents a brand-new meta-learning paradigm for parametric systems. As a network of networks, its outer-/meta-network is hyper-reduced with only one hidden layer having significantly reduced number of neurons. Moreover, its activation function at each hidden neuron is a (full) PINN pre-trained at a judiciously selected system configuration. The meta-network adaptively ``learns'' the parametric dependence of the system and ``grows'' this hidden layer one neuron at a time. In the end, by encompassing a very small number of networks trained at this set of adaptively-selected parameter values, the meta-network is capable of generating surrogate solutions for the parametric system across the entire parameter domain accurately and efficiently.
RED-PSM: Regularization by Denoising of Partially Separable Models for Dynamic Imaging
Apr 07, 2023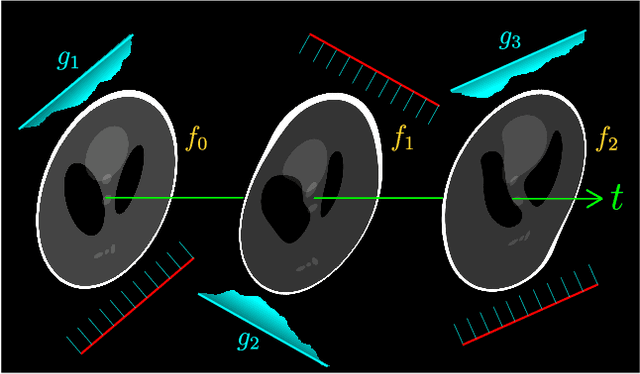
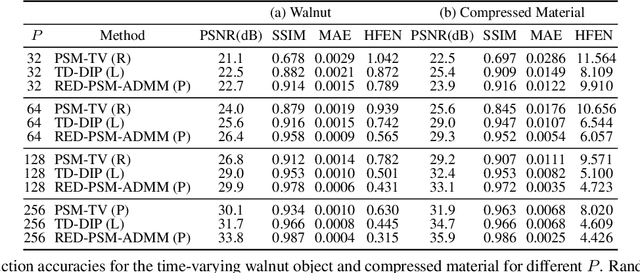
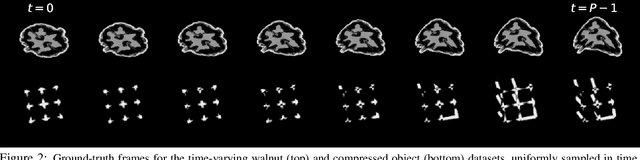
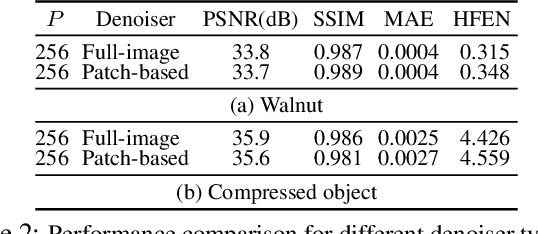
Dynamic imaging addresses the recovery of a time-varying 2D or 3D object at each time instant using its undersampled measurements. In particular, in the case of dynamic tomography, only a single projection at a single view angle may be available at a time, making the problem severely ill-posed. In this work, we propose an approach, RED-PSM, which combines for the first time two powerful techniques to address this challenging imaging problem. The first, are partially separable models, which have been used to efficiently introduce a low-rank prior for the spatio-temporal object. The second is the recent Regularization by Denoising (RED), which provides a flexible framework to exploit the impressive performance of state-of-the-art image denoising algorithms, for various inverse problems. We propose a partially separable objective with RED and an optimization scheme with variable splitting and ADMM, and prove convergence of our objective to a value corresponding to a stationary point satisfying the first order optimality conditions. Convergence is accelerated by a particular projection-domain-based initialization. We demonstrate the performance and computational improvements of our proposed RED-PSM with a learned image denoiser by comparing it to a recent deep-prior-based method TD-DIP.
Ripple: Concept-Based Interpretation for Raw Time Series Models in Education
Dec 08, 2022
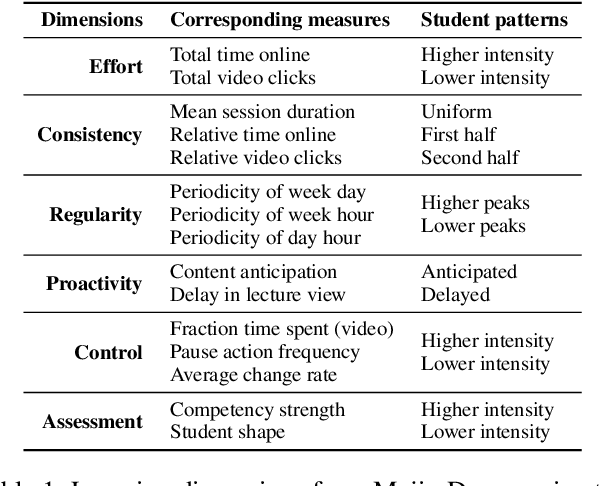
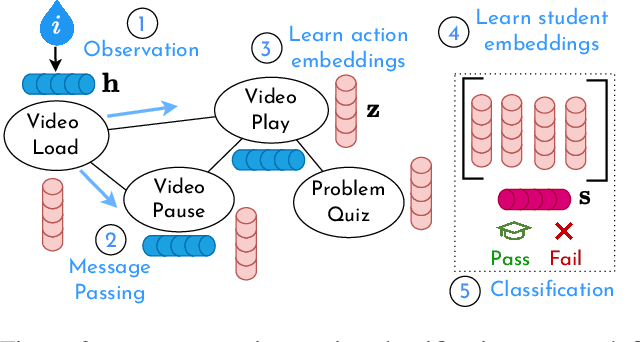

Time series is the most prevalent form of input data for educational prediction tasks. The vast majority of research using time series data focuses on hand-crafted features, designed by experts for predictive performance and interpretability. However, extracting these features is labor-intensive for humans and computers. In this paper, we propose an approach that utilizes irregular multivariate time series modeling with graph neural networks to achieve comparable or better accuracy with raw time series clickstreams in comparison to hand-crafted features. Furthermore, we extend concept activation vectors for interpretability in raw time series models. We analyze these advances in the education domain, addressing the task of early student performance prediction for downstream targeted interventions and instructional support. Our experimental analysis on 23 MOOCs with millions of combined interactions over six behavioral dimensions show that models designed with our approach can (i) beat state-of-the-art educational time series baselines with no feature extraction and (ii) provide interpretable insights for personalized interventions. Source code: https://github.com/epfl-ml4ed/ripple/.