 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Critical Scenario Generation for Developing Trustworthy Autonomy
Apr 29, 2023

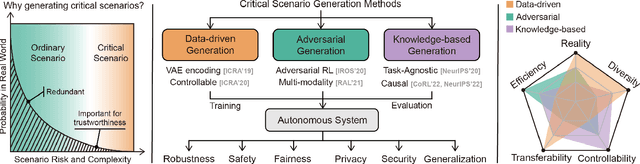
Autonomous systems, such as self-driving vehicles, quadrupeds, and robot manipulators, are largely enabled by the rapid development of artificial intelligence. However, such systems involve several trustworthy challenges such as safety, robustness, and generalization, due to their deployment in open-ended and real-time environments. To evaluate and improve trustworthiness, simulations or so-called digital twins are largely utilized for system development with low cost and high efficiency. One important thing in virtual simulations is scenarios that consist of static and dynamic objects, specific tasks, and evaluation metrics. However, designing diverse, realistic, and effective scenarios is still a challenging problem. One straightforward way is creating scenarios through human design, which is time-consuming and limited by the experience of experts. Another method commonly used in self-driving areas is log replay. This method collects scenario data in the real world and then replays it in simulations or adds random perturbations. Although the replay scenarios are realistic, most of the collected scenarios are redundant since they are all ordinary scenarios that only consider a small portion of critical cases. The desired scenarios should cover all cases in the real world, especially rare but critical events with extremely low probability. Critical scenarios are rare but important to test autonomous systems under risky conditions and unpredictable perturbations, which reveal their trustworthiness.
NPRL: Nightly Profile Representation Learning for Early Sepsis Onset Prediction in ICU Trauma Patients
Apr 25, 2023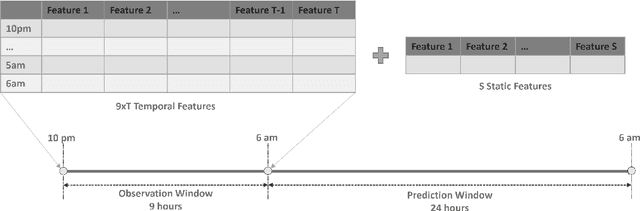
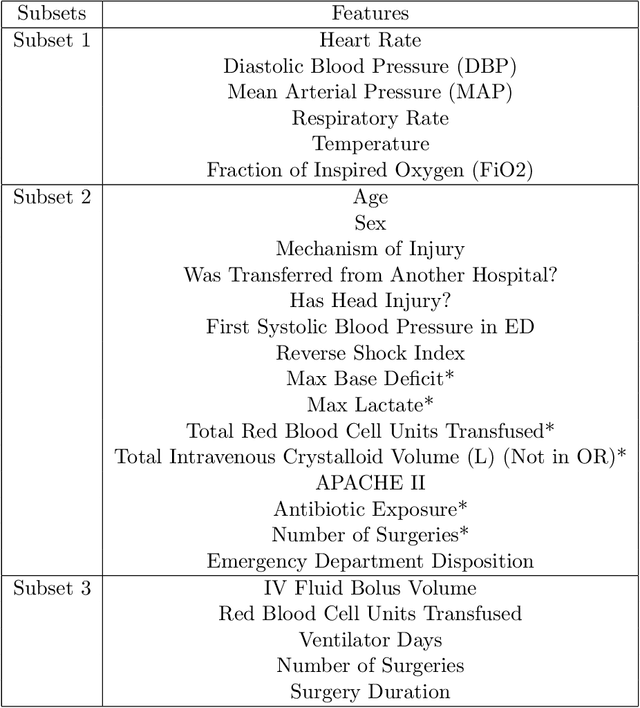
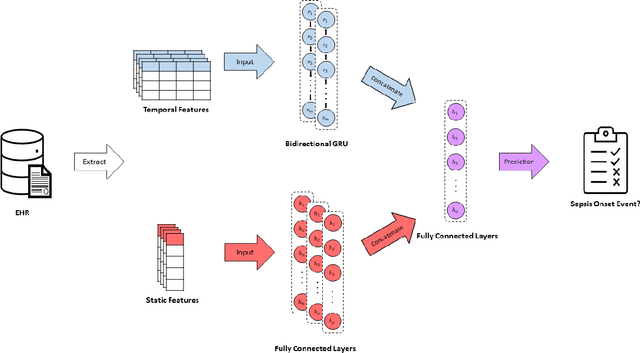
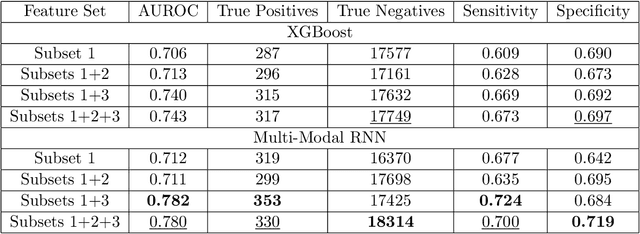
Sepsis is a syndrome that develops in response to the presence of infection. It is characterized by severe organ dysfunction and is one of the leading causes of mortality in Intensive Care Units (ICUs) worldwide. These complications can be reduced through early application of antibiotics, hence the ability to anticipate the onset of sepsis early is crucial to the survival and well-being of patients. Current machine learning algorithms deployed inside medical infrastructures have demonstrated poor performance and are insufficient for anticipating sepsis onset early. In recent years, deep learning methodologies have been proposed to predict sepsis, but some fail to capture the time of onset (e.g., classifying patients' entire visits as developing sepsis or not) and others are unrealistic to be deployed into medical facilities (e.g., creating training instances using a fixed time to onset where the time of onset needs to be known apriori). Therefore, in this paper, we first propose a novel but realistic prediction framework that predicts each morning whether sepsis onset will occur within the next 24 hours using data collected at night, when patient-provider ratios are higher due to cross-coverage resulting in limited observation to each patient. However, as we increase the prediction rate into daily, the number of negative instances will increase while that of positive ones remain the same. Thereafter, we have a severe class imbalance problem, making a machine learning model hard to capture rare sepsis cases. To address this problem, we propose to do nightly profile representation learning (NPRL) for each patient. We prove that NPRL can theoretically alleviate the rare event problem. Our empirical study using data from a level-1 trauma center further demonstrates the effectiveness of our proposal.
Implications of Deep Circuits in Improving Quality of Quantum Question Answering
May 12, 2023Question Answering (QA) has proved to be an arduous challenge in the area of natural language processing (NLP) and artificial intelligence (AI). Many attempts have been made to develop complete solutions for QA as well as improving significant sub-modules of the QA systems to improve the overall performance through the course of time. Questions are the most important piece of QA, because knowing the question is equivalent to knowing what counts as an answer (Harrah in Philos Sci, 1961 [1]). In this work, we have attempted to understand questions in a better way by using Quantum Machine Learning (QML). The properties of Quantum Computing (QC) have enabled classically intractable data processing. So, in this paper, we have performed question classification on questions from two classes of SelQA (Selection-based Question Answering) dataset using quantum-based classifier algorithms-quantum support vector machine (QSVM) and variational quantum classifier (VQC) from Qiskit (Quantum Information Science toolKIT) for Python. We perform classification with both classifiers in almost similar environments and study the effects of circuit depths while comparing the results of both classifiers. We also use these classification results with our own rule-based QA system and observe significant performance improvement. Hence, this experiment has helped in improving the quality of QA in general.
Gallery Sampling for Robust and Fast Face Identification
May 12, 2023
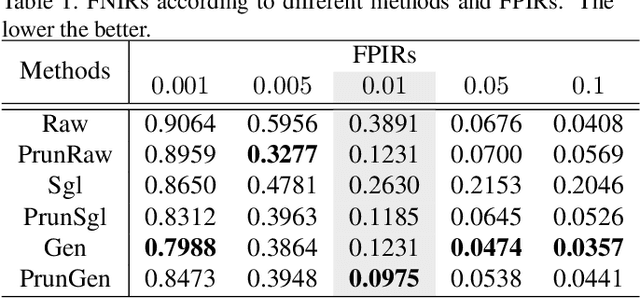
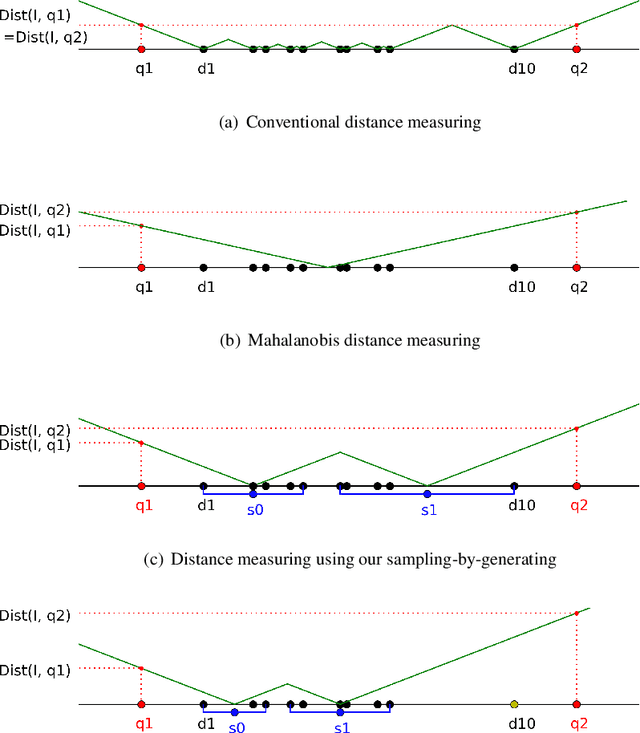
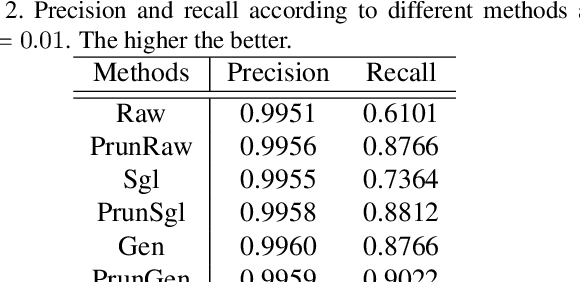
Deep learning methods have been achieved brilliant results in face recognition. One of the important tasks to improve the performance is to collect and label images as many as possible. However, labeling identities and checking qualities of large image data are difficult task and mistakes cannot be avoided in processing large data. Previous works have been trying to deal with the problem only in training domain, however it can cause much serious problem if the mistakes are in gallery data of face identification. We proposed gallery data sampling methods which are robust to outliers including wrong labeled, low quality, and less-informative images and reduce searching time. The proposed sampling-by-pruning and sampling-by-generating methods significantly improved face identification performance on our 5.4M web image dataset of celebrities. The proposed method achieved 0.0975 in terms of FNIR at FPIR=0.01, while conventional method showed 0.3891. The average number of feature vectors for each individual gallery was reduced to 17.1 from 115.9 and it can provide much faster search. We also made experiments on public datasets and our method achieved 0.1314 and 0.0668 FNIRs at FPIR=0.01 on the CASIA-WebFace and MS1MV2, while the convectional method did 0.5446, and 0.1327, respectively.
Efficient Search of Comprehensively Robust Neural Architectures via Multi-fidelity Evaluation
May 12, 2023
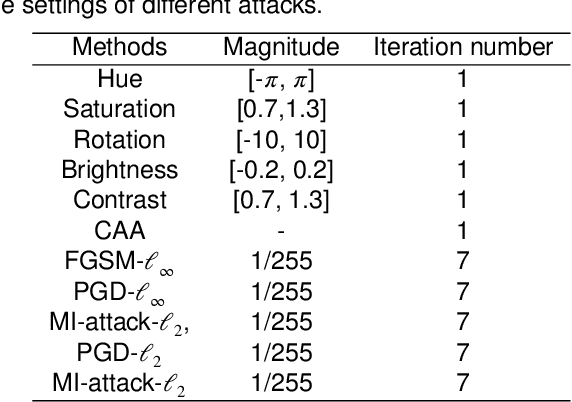
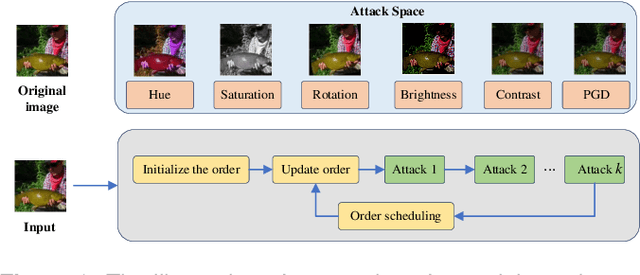
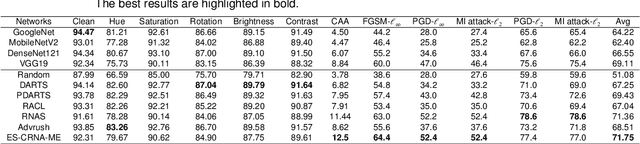
Neural architecture search (NAS) has emerged as one successful technique to find robust deep neural network (DNN) architectures. However, most existing robustness evaluations in NAS only consider $l_{\infty}$ norm-based adversarial noises. In order to improve the robustness of DNN models against multiple types of noises, it is necessary to consider a comprehensive evaluation in NAS for robust architectures. But with the increasing number of types of robustness evaluations, it also becomes more time-consuming to find comprehensively robust architectures. To alleviate this problem, we propose a novel efficient search of comprehensively robust neural architectures via multi-fidelity evaluation (ES-CRNA-ME). Specifically, we first search for comprehensively robust architectures under multiple types of evaluations using the weight-sharing-based NAS method, including different $l_{p}$ norm attacks, semantic adversarial attacks, and composite adversarial attacks. In addition, we reduce the number of robustness evaluations by the correlation analysis, which can incorporate similar evaluations and decrease the evaluation cost. Finally, we propose a multi-fidelity online surrogate during optimization to further decrease the search cost. On the basis of the surrogate constructed by low-fidelity data, the online high-fidelity data is utilized to finetune the surrogate. Experiments on CIFAR10 and CIFAR100 datasets show the effectiveness of our proposed method.
Identifying Appropriate Intellectual Property Protection Mechanisms for Machine Learning Models: A Systematization of Watermarking, Fingerprinting, Model Access, and Attacks
Apr 22, 2023
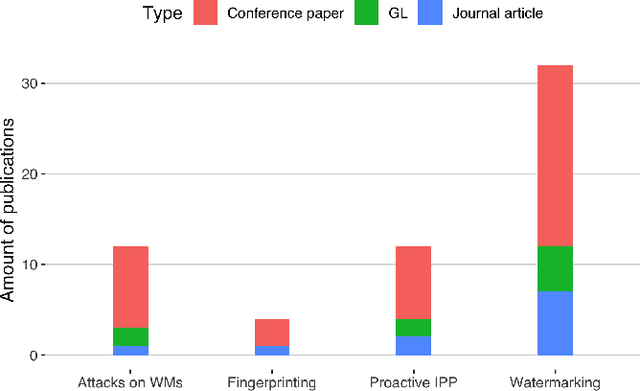
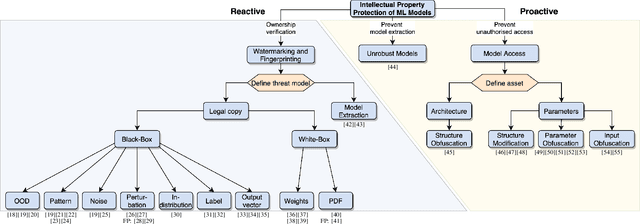
The commercial use of Machine Learning (ML) is spreading; at the same time, ML models are becoming more complex and more expensive to train, which makes Intellectual Property Protection (IPP) of trained models a pressing issue. Unlike other domains that can build on a solid understanding of the threats, attacks and defenses available to protect their IP, the ML-related research in this regard is still very fragmented. This is also due to a missing unified view as well as a common taxonomy of these aspects. In this paper, we systematize our findings on IPP in ML, while focusing on threats and attacks identified and defenses proposed at the time of writing. We develop a comprehensive threat model for IP in ML, categorizing attacks and defenses within a unified and consolidated taxonomy, thus bridging research from both the ML and security communities.
Gradient-Descent Based Optimization of Multi-Tone Sinusoidal Frequency Modulated Waveforms
Apr 22, 2023This paper describes a gradient-descent based optimization algorithm for synthesizing Multi-Tone Sinusoidal Frequency Modulated (MTSFM) waveforms with low Auto-Correlation Function (ACF) sidelobes in a specified region of time delays while preserving the ACF mainlobe width. The algorithm optimizes the Generalized Integrated Sidelobe Level (GISL) which controls the mainlobe and sidelobe structure of the waveform's ACF. This optimization is performed subject to nonlinear constraints on the waveform's RMS bandwidth which directly controls the ACF mainlobe width. Since almost all of the operations of the algorithm utilize the Fast Fourier Transform (FFT), it is substantially more computationally efficient than previous methods that synthesized MTSFM waveforms with low ACF sidelobes. The computational efficiency of this new algorithm facilitates the design of larger dimensional and correspondingly larger time-bandwidth product MTSFM waveform designs. The algorithm is demonstrated through several illustrative MTSFM design examples.
Blockchain Large Language Models
Apr 25, 2023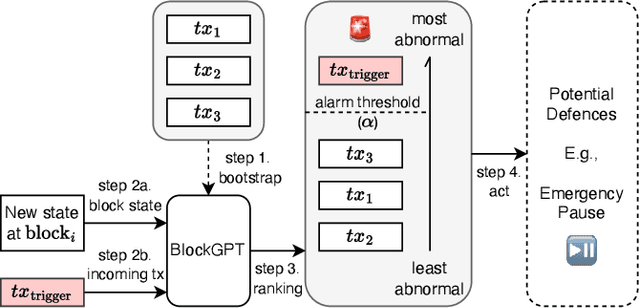
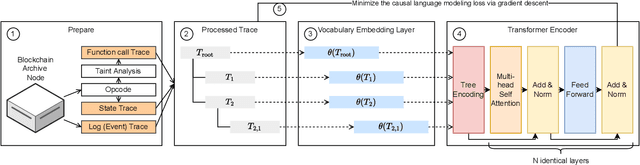
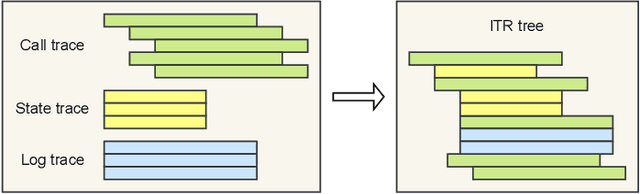
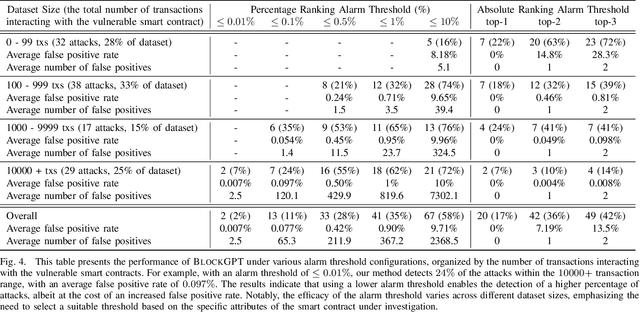
This paper presents a dynamic, real-time approach to detecting anomalous blockchain transactions. The proposed tool, TXRANK, generates tracing representations of blockchain activity and trains from scratch a large language model to act as a real-time Intrusion Detection System. Unlike traditional methods, TXRANK is designed to offer an unrestricted search space and does not rely on predefined rules or patterns, enabling it to detect a broader range of anomalies. We demonstrate the effectiveness of TXRANK through its use as an anomaly detection tool for Ethereum transactions. In our experiments, it effectively identifies abnormal transactions among a dataset of 68M transactions and has a batched throughput of 2284 transactions per second on average. Our results show that, TXRANK identifies abnormal transactions by ranking 49 out of 124 attacks among the top-3 most abnormal transactions interacting with their victim contracts. This work makes contributions to the field of blockchain transaction analysis by introducing a custom data encoding compatible with the transformer architecture, a domain-specific tokenization technique, and a tree encoding method specifically crafted for the Ethereum Virtual Machine (EVM) trace representation.
Patch Diffusion: Faster and More Data-Efficient Training of Diffusion Models
Apr 25, 2023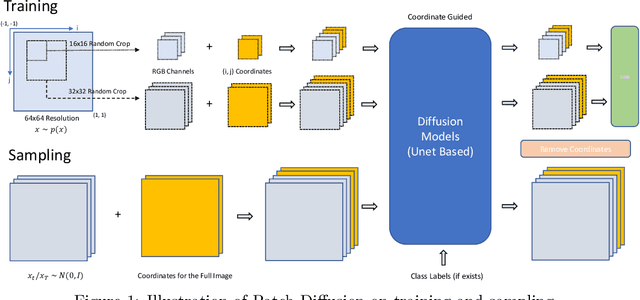
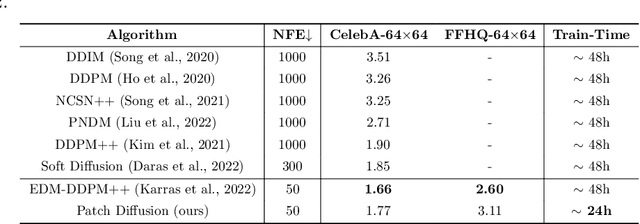
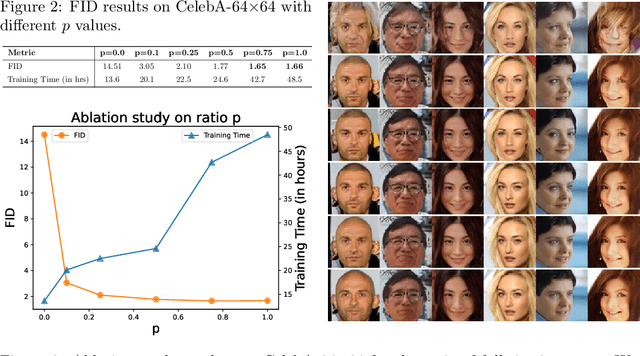

Diffusion models are powerful, but they require a lot of time and data to train. We propose Patch Diffusion, a generic patch-wise training framework, to significantly reduce the training time costs while improving data efficiency, which thus helps democratize diffusion model training to broader users. At the core of our innovations is a new conditional score function at the patch level, where the patch location in the original image is included as additional coordinate channels, while the patch size is randomized and diversified throughout training to encode the cross-region dependency at multiple scales. Sampling with our method is as easy as in the original diffusion model. Through Patch Diffusion, we could achieve $\mathbf{\ge 2\times}$ faster training, while maintaining comparable or better generation quality. Patch Diffusion meanwhile improves the performance of diffusion models trained on relatively small datasets, $e.g.$, as few as 5,000 images to train from scratch. We achieve state-of-the-art FID scores 1.77 on CelebA-64$\times$64 and 1.93 on AFHQv2-Wild-64$\times$64. We will share our code and pre-trained models soon.
Adaptive Path-Memory Network for Temporal Knowledge Graph Reasoning
Apr 25, 2023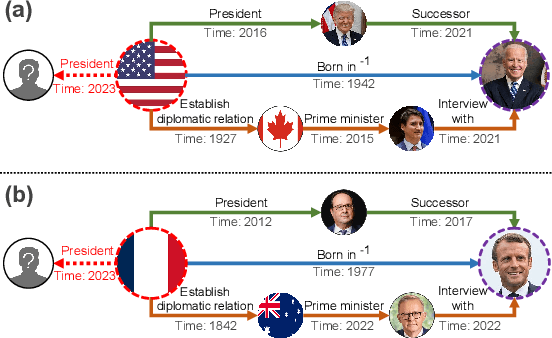
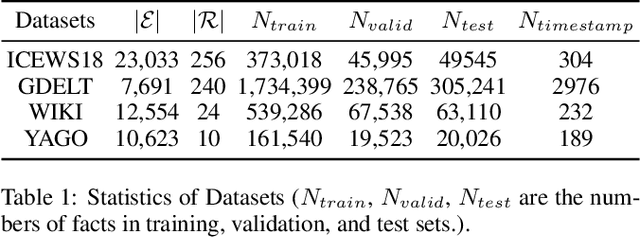
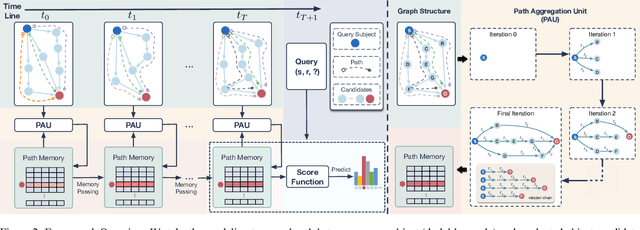
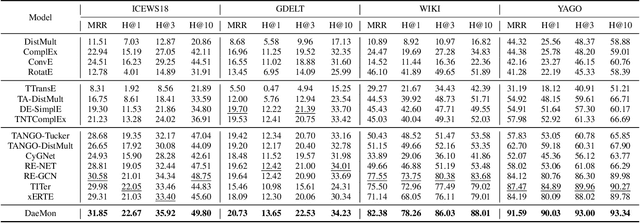
Temporal knowledge graph (TKG) reasoning aims to predict the future missing facts based on historical information and has gained increasing research interest recently. Lots of works have been made to model the historical structural and temporal characteristics for the reasoning task. Most existing works model the graph structure mainly depending on entity representation. However, the magnitude of TKG entities in real-world scenarios is considerable, and an increasing number of new entities will arise as time goes on. Therefore, we propose a novel architecture modeling with relation feature of TKG, namely aDAptivE path-MemOry Network (DaeMon), which adaptively models the temporal path information between query subject and each object candidate across history time. It models the historical information without depending on entity representation. Specifically, DaeMon uses path memory to record the temporal path information derived from path aggregation unit across timeline considering the memory passing strategy between adjacent timestamps. Extensive experiments conducted on four real-world TKG datasets demonstrate that our proposed model obtains substantial performance improvement and outperforms the state-of-the-art up to 4.8% absolute in MRR.