 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Base Placement Optimization for Coverage Mobile Manipulation Tasks
Apr 17, 2023

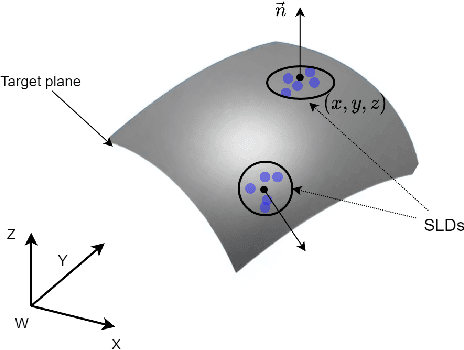
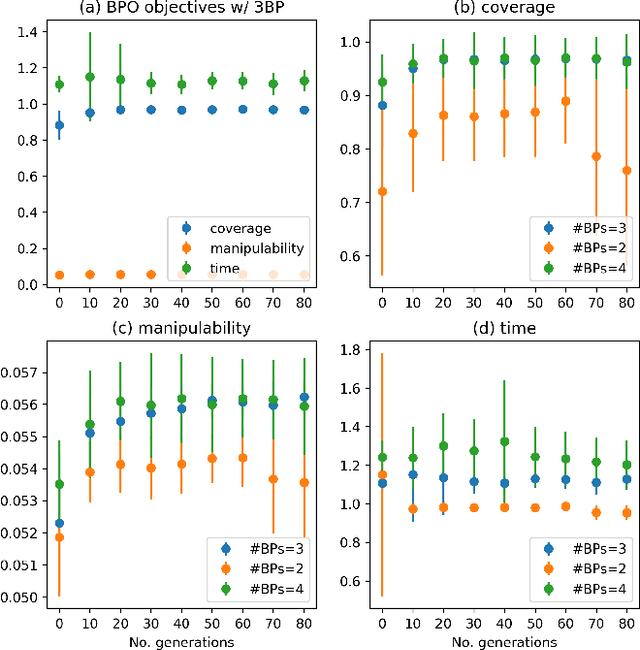
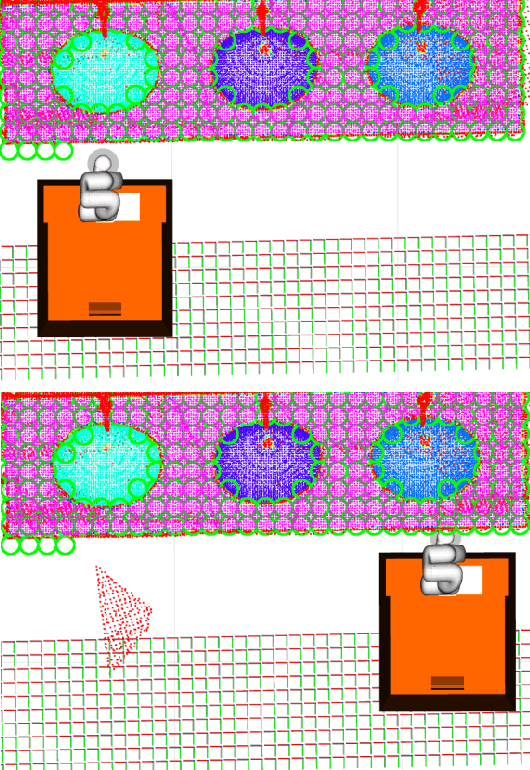
Base placement optimization (BPO) is a fundamental capability for mobile manipulation and has been researched for decades. However, it is still very challenging for some reasons. First, compared with humans, current robots are extremely inflexible, and therefore have higher requirements on the accuracy of base placements (BPs). Second, the BP and task constraints are coupled with each other. The optimal BP depends on the task constraints, and in BP will affect task constraints in turn. More tricky is that some task constraints are flexible and non-deterministic. Third, except for fulfilling tasks, some other performance metrics such as optimal energy consumption and minimal execution time need to be considered, which makes the BPO problem even more complicated. In this paper, a Scale-like disc (SLD) representation of the workspace is used to decouple task constraints and BPs. To evaluate reachability and return optimal working pose over SLDs, a reachability map (RM) is constructed offline. In order to optimize the objectives of coverage, manipulability, and time cost simultaneously, this paper formulates the BPO as a multi-objective optimization problem (MOOP). Among them, the time optimal objective is modeled as a traveling salesman problem (TSP), which is more in line with the actual situation. The evolutionary method is used to solve the MOOP. Besides, to ensure the validity and optimality of the solution, collision detection is performed on the candidate BPs, and solutions from BPO are further fine-tuned according to the specific given task. Finally, the proposed method is used to solve a real-world toilet coverage cleaning task. Experiments show that the optimized BPs can significantly improve the coverage and efficiency of the task.
Fast Neural Scene Flow
Apr 18, 2023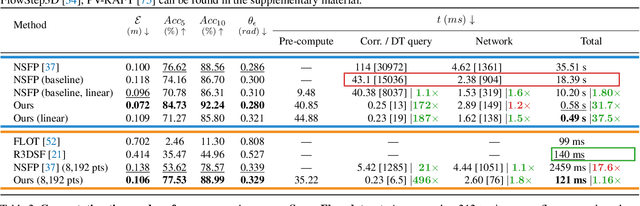

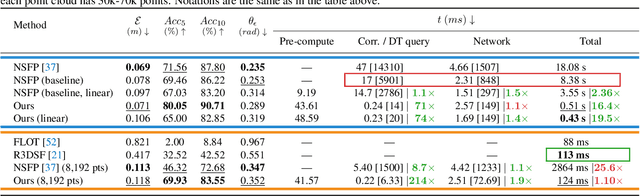
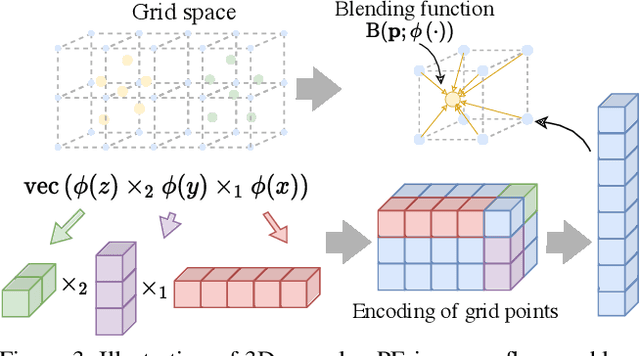
Scene flow is an important problem as it provides low-level motion cues for many downstream tasks. State-of-the-art learning methods are usually fast and can achieve impressive performance on in-domain data, but usually fail to generalize to out-of-the-distribution (OOD) data or handle dense point clouds. In this paper, we focus on a runtime optimization-based neural scene flow pipeline. In (a) one can see its application in the densification of lidar. However, in (c) one sees that the major drawback is the extensive computation time. We identify that the common speedup strategy in network architectures for coordinate networks has little effect on scene flow acceleration [see green (b)] unlike image reconstruction [see pink (b)]. With the dominant computational burden stemming instead from the Chamfer loss function, we propose to use a distance transform-based loss function to accelerate [see purple (b)], which achieves up to 30x speedup and on-par estimation performance compared to NSFP [see (c)]. When tested on 8k points, it is as efficient [see (c)] as leading learning methods, achieving real-time performance.
T-SciQ: Teaching Multimodal Chain-of-Thought Reasoning via Large Language Model Signals for Science Question Answering
May 05, 2023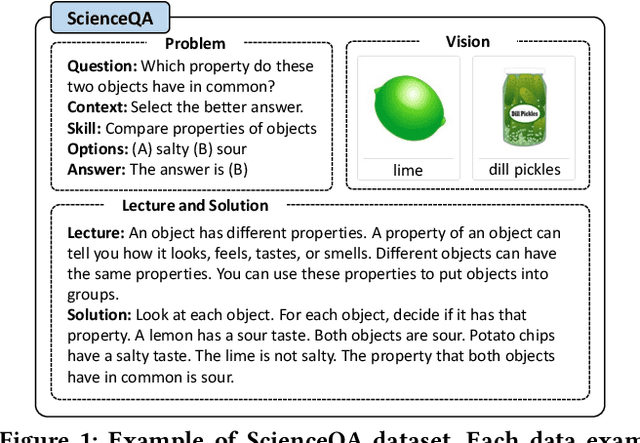
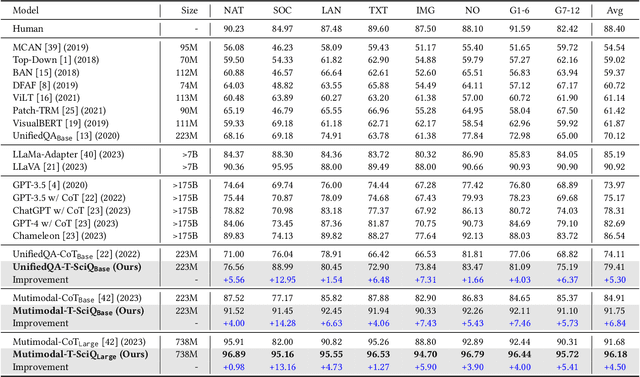
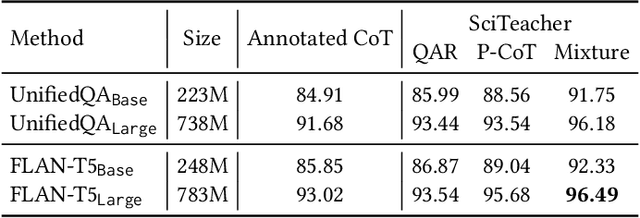
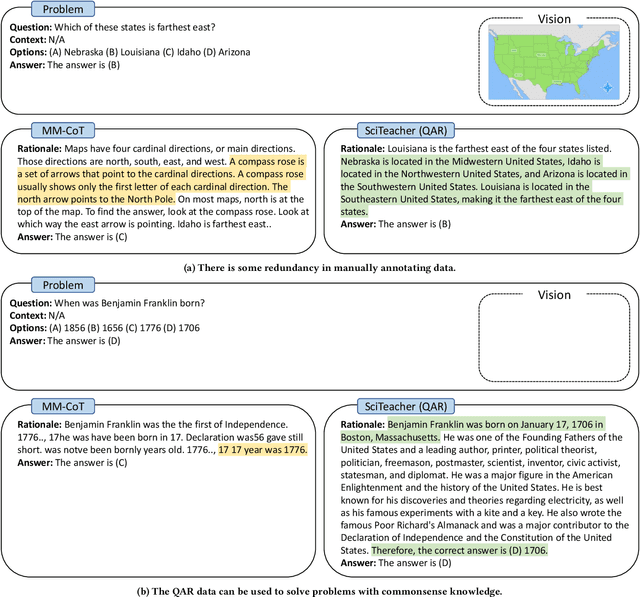
Large Language Models (LLMs) have recently demonstrated exceptional performance in various Natural Language Processing (NLP) tasks. They have also shown the ability to perform chain-of-thought (CoT) reasoning to solve complex problems. Recent studies have explored CoT reasoning in complex multimodal scenarios, such as the science question answering task, by fine-tuning multimodal models with high-quality human-annotated CoT rationales. However, collecting high-quality COT rationales is usually time-consuming and costly. Besides, the annotated rationales are hardly accurate due to the redundant information involved or the essential information missed. To address these issues, we propose a novel method termed \emph{T-SciQ} that aims at teaching science question answering with LLM signals. The T-SciQ approach generates high-quality CoT rationales as teaching signals and is advanced to train much smaller models to perform CoT reasoning in complex modalities. Additionally, we introduce a novel data mixing strategy to produce more effective teaching data samples for simple and complex science question answer problems. Extensive experimental results show that our T-SciQ method achieves a new state-of-the-art performance on the ScienceQA benchmark, with an accuracy of 96.18%. Moreover, our approach outperforms the most powerful fine-tuned baseline by 4.5%.
LOGO-Former: Local-Global Spatio-Temporal Transformer for Dynamic Facial Expression Recognition
May 05, 2023
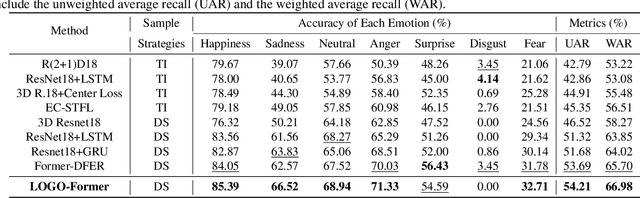
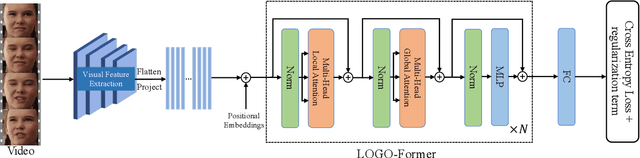
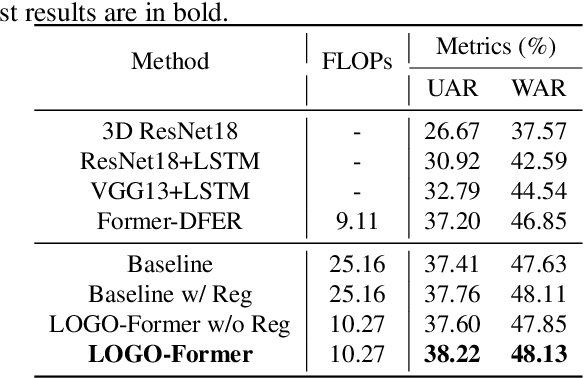
Previous methods for dynamic facial expression recognition (DFER) in the wild are mainly based on Convolutional Neural Networks (CNNs), whose local operations ignore the long-range dependencies in videos. Transformer-based methods for DFER can achieve better performances but result in higher FLOPs and computational costs. To solve these problems, the local-global spatio-temporal Transformer (LOGO-Former) is proposed to capture discriminative features within each frame and model contextual relationships among frames while balancing the complexity. Based on the priors that facial muscles move locally and facial expressions gradually change, we first restrict both the space attention and the time attention to a local window to capture local interactions among feature tokens. Furthermore, we perform the global attention by querying a token with features from each local window iteratively to obtain long-range information of the whole video sequence. In addition, we propose the compact loss regularization term to further encourage the learned features have the minimum intra-class distance and the maximum inter-class distance. Experiments on two in-the-wild dynamic facial expression datasets (i.e., DFEW and FERV39K) indicate that our method provides an effective way to make use of the spatial and temporal dependencies for DFER.
Sequential Predictive Conformal Inference for Time Series
Dec 07, 2022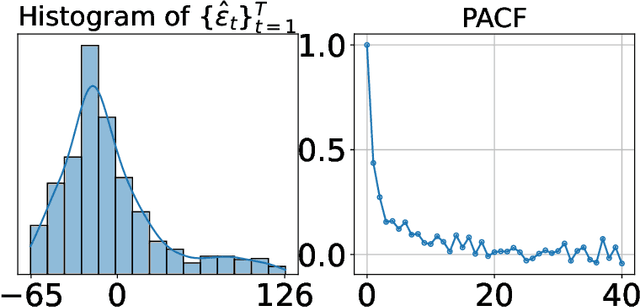
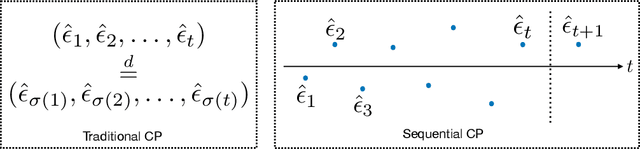

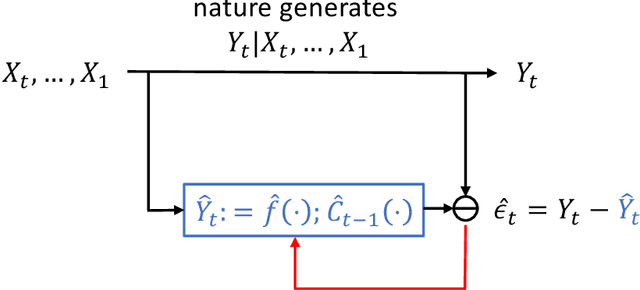
We present a new distribution-free conformal prediction algorithm for sequential data (e.g., time series), called the \textit{sequential predictive conformal inference} (\texttt{SPCI}). We specifically account for the nature that the time series data are non-exchangeable, and thus many existing conformal prediction algorithms based on temporal residuals are not applicable. The main idea is to exploit the temporal dependence of conformity scores; thus, the past conformity scores contain information about future ones. Then we cast the problem of conformal prediction interval as predicting the quantile of a future residual, given a prediction algorithm. Theoretically, we establish asymptotic valid conditional coverage upon extending consistency analyses in quantile regression. Using simulation and real-data experiments, we demonstrate a significant reduction in interval width of \texttt{SPCI} compared to other existing methods under the desired empirical coverage.
Augmenting Passage Representations with Query Generation for Enhanced Cross-Lingual Dense Retrieval
May 06, 2023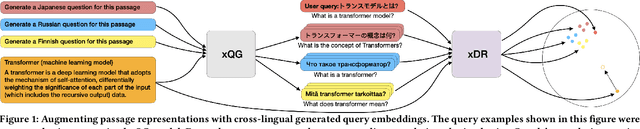
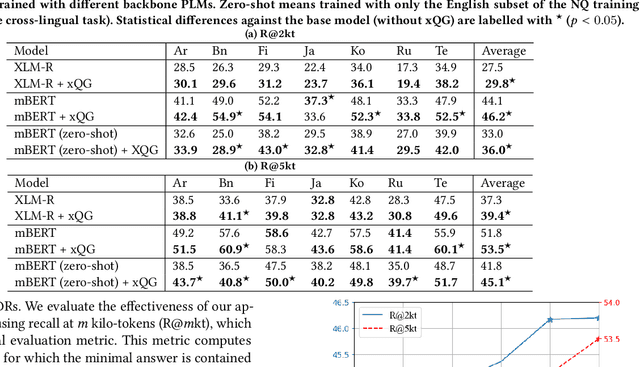
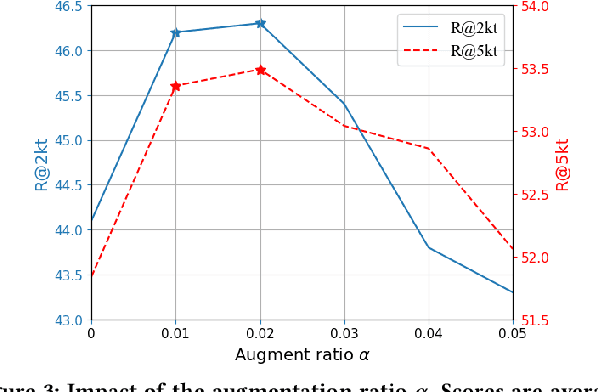
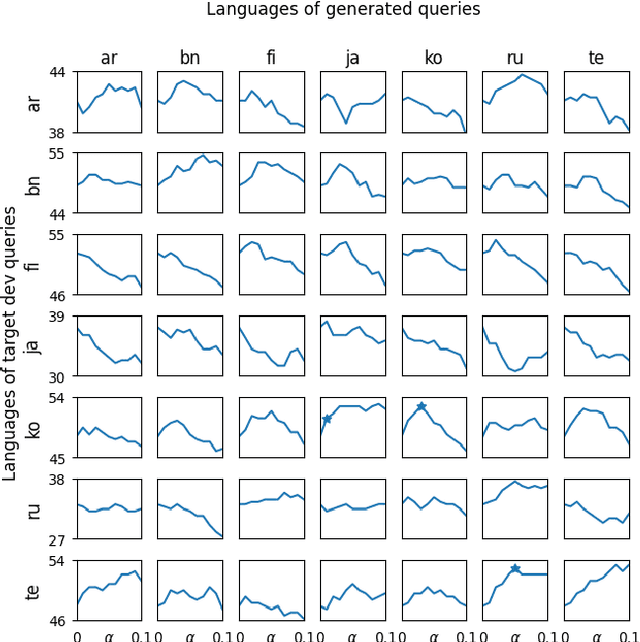
Effective cross-lingual dense retrieval methods that rely on multilingual pre-trained language models (PLMs) need to be trained to encompass both the relevance matching task and the cross-language alignment task. However, cross-lingual data for training is often scarcely available. In this paper, rather than using more cross-lingual data for training, we propose to use cross-lingual query generation to augment passage representations with queries in languages other than the original passage language. These augmented representations are used at inference time so that the representation can encode more information across the different target languages. Training of a cross-lingual query generator does not require additional training data to that used for the dense retriever. The query generator training is also effective because the pre-training task for the generator (T5 text-to-text training) is very similar to the fine-tuning task (generation of a query). The use of the generator does not increase query latency at inference and can be combined with any cross-lingual dense retrieval method. Results from experiments on a benchmark cross-lingual information retrieval dataset show that our approach can improve the effectiveness of existing cross-lingual dense retrieval methods. Implementation of our methods, along with all generated query files are made publicly available at https://github.com/ielab/xQG4xDR.
Symbolic Regression on FPGAs for Fast Machine Learning Inference
May 06, 2023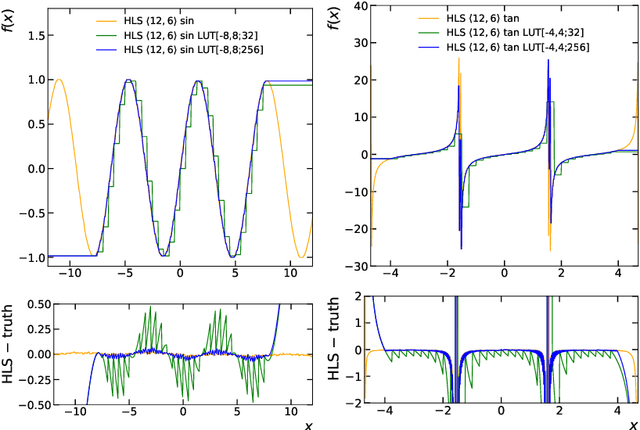


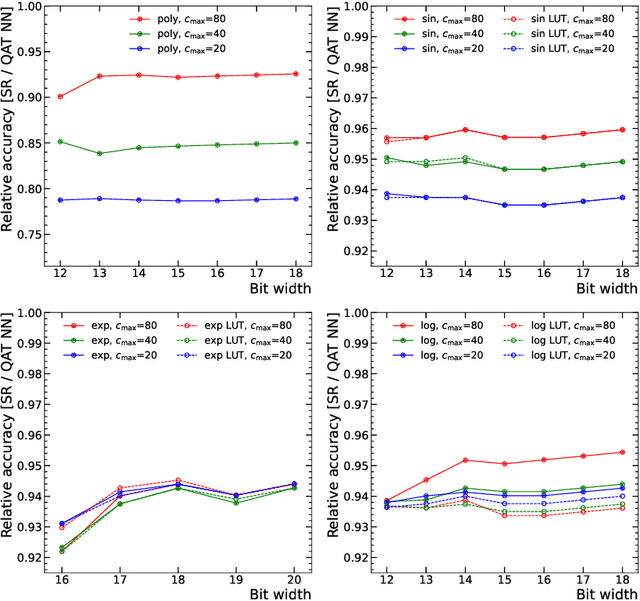
The high-energy physics community is investigating the feasibility of deploying machine-learning-based solutions on Field-Programmable Gate Arrays (FPGAs) to improve physics sensitivity while meeting data processing latency limitations. In this contribution, we introduce a novel end-to-end procedure that utilizes a machine learning technique called symbolic regression (SR). It searches equation space to discover algebraic relations approximating a dataset. We use PySR (software for uncovering these expressions based on evolutionary algorithm) and extend the functionality of hls4ml (a package for machine learning inference in FPGAs) to support PySR-generated expressions for resource-constrained production environments. Deep learning models often optimise the top metric by pinning the network size because vast hyperparameter space prevents extensive neural architecture search. Conversely, SR selects a set of models on the Pareto front, which allows for optimising the performance-resource tradeoff directly. By embedding symbolic forms, our implementation can dramatically reduce the computational resources needed to perform critical tasks. We validate our procedure on a physics benchmark: multiclass classification of jets produced in simulated proton-proton collisions at the CERN Large Hadron Collider, and show that we approximate a 3-layer neural network with an inference model that has as low as 5 ns execution time (a reduction by a factor of 13) and over 90% approximation accuracy.
Variational Nonlinear Kalman Filtering with Unknown Process Noise Covariance
May 06, 2023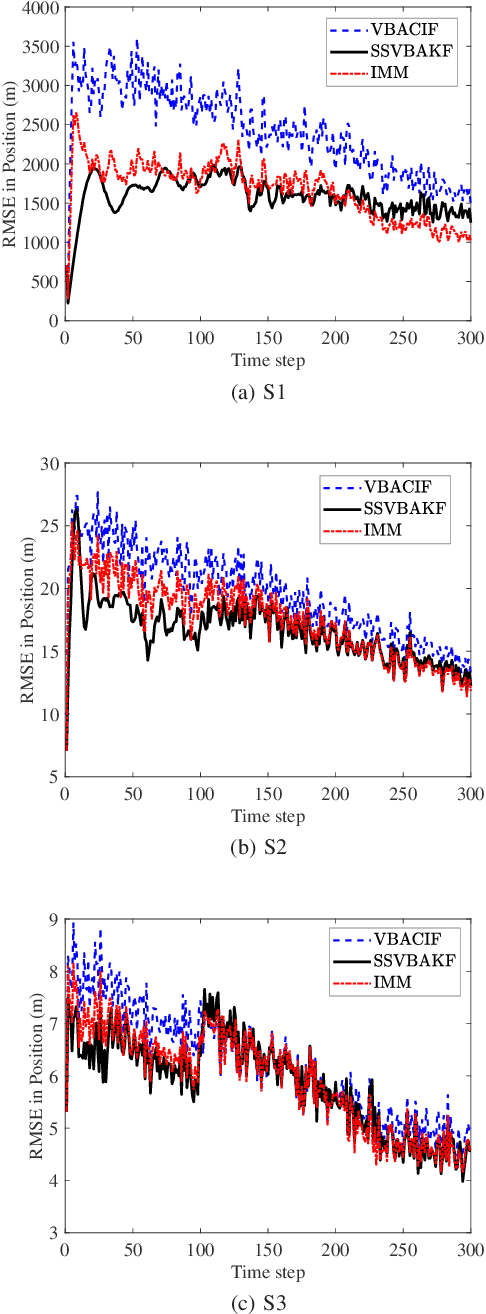
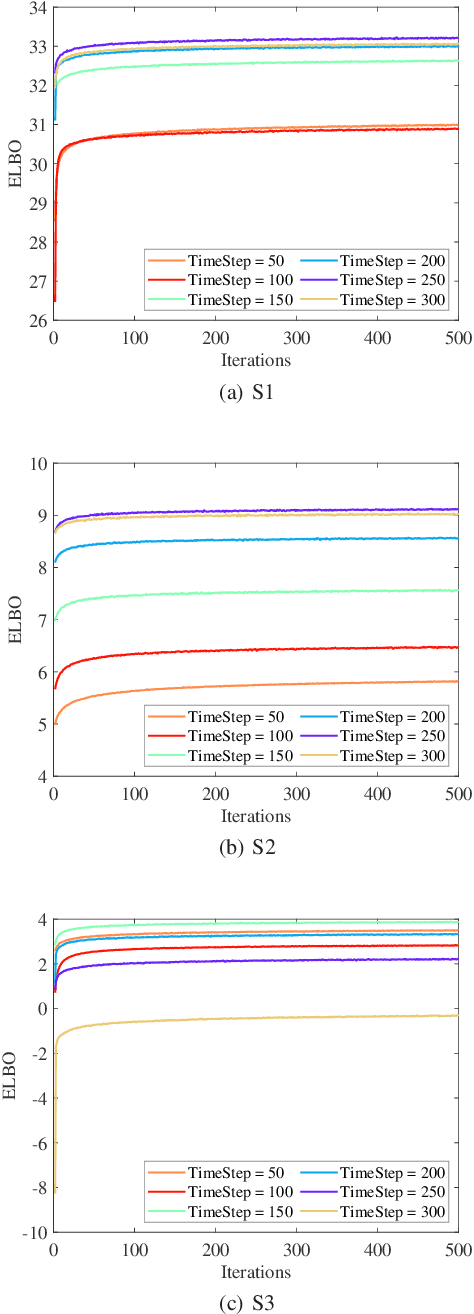
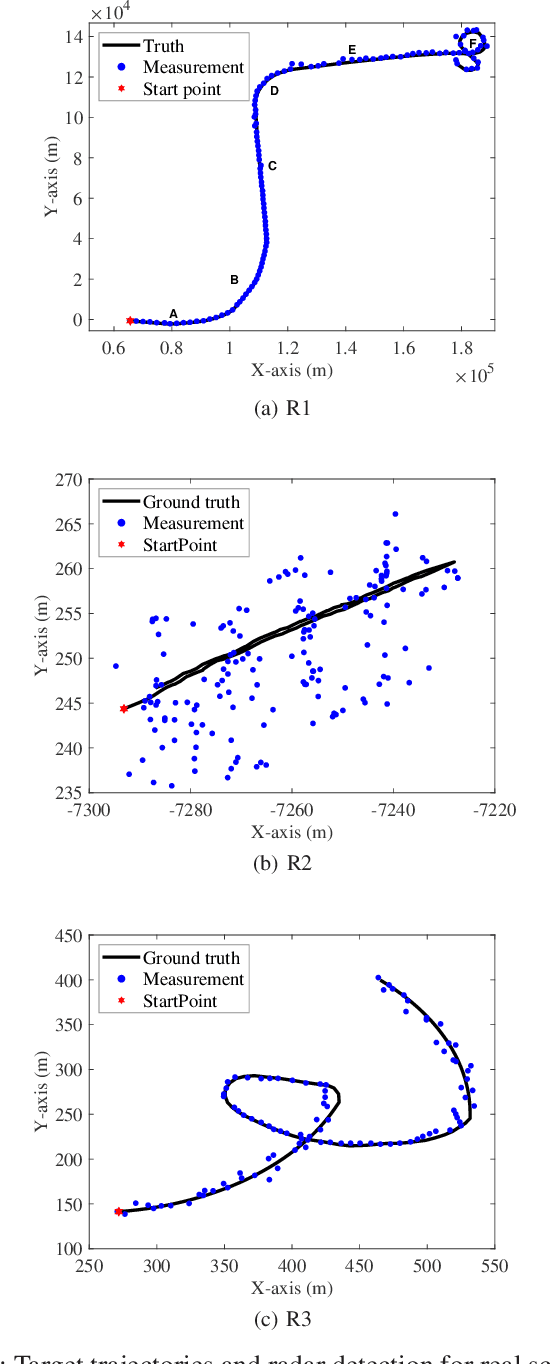
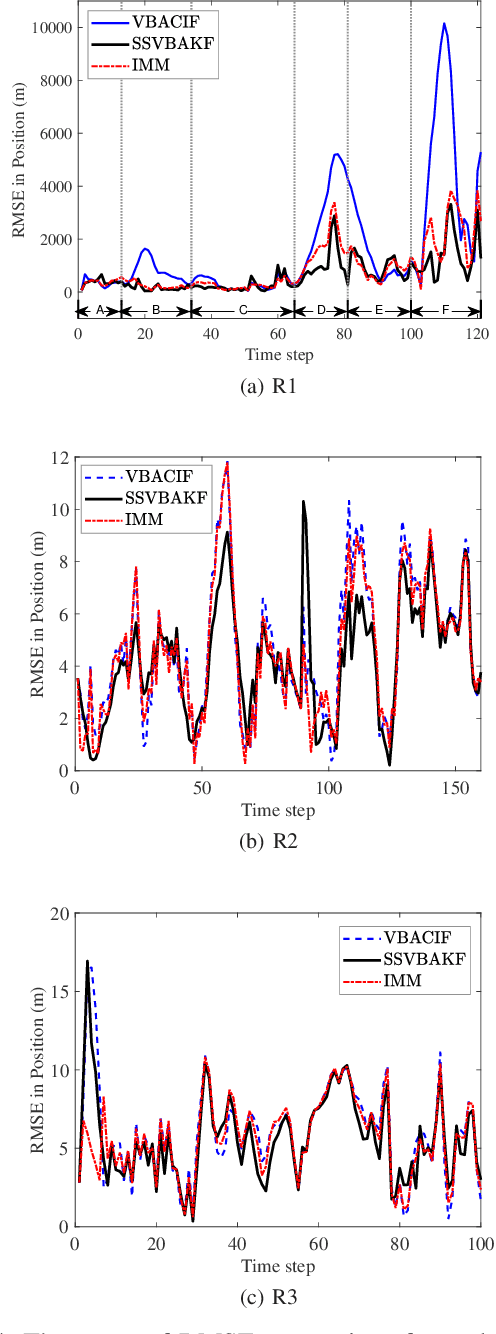
Motivated by the maneuvering target tracking with sensors such as radar and sonar, this paper considers the joint and recursive estimation of the dynamic state and the time-varying process noise covariance in nonlinear state space models. Due to the nonlinearity of the models and the non-conjugate prior, the state estimation problem is generally intractable as it involves integrals of general nonlinear functions and unknown process noise covariance, resulting in the posterior probability distribution functions lacking closed-form solutions. This paper presents a recursive solution for joint nonlinear state estimation and model parameters identification based on the approximate Bayesian inference principle. The stochastic search variational inference is adopted to offer a flexible, accurate, and effective approximation of the posterior distributions. We make two contributions compared to existing variational inference-based noise adaptive filtering methods. First, we introduce an auxiliary latent variable to decouple the latent variables of dynamic state and process noise covariance, thereby improving the flexibility of the posterior inference. Second, we split the variational lower bound optimization into conjugate and non-conjugate parts, whereas the conjugate terms are directly optimized that admit a closed-form solution and the non-conjugate terms are optimized by natural gradients, achieving the trade-off between inference speed and accuracy. The performance of the proposed method is verified on radar target tracking applications by both simulated and real-world data.
Maintaining Stability and Plasticity for Predictive Churn Reduction
May 06, 2023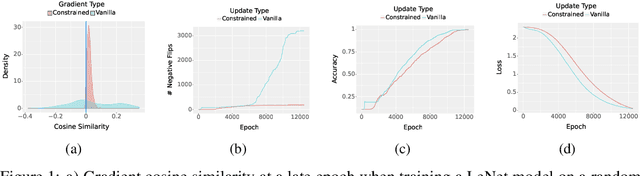
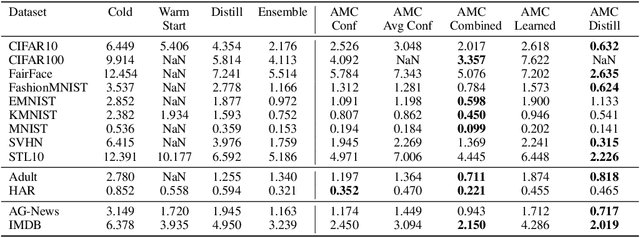
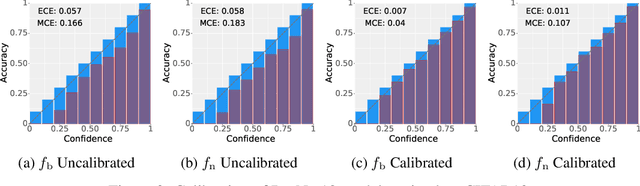

Deployed machine learning models should be updated to take advantage of a larger sample size to improve performance, as more data is gathered over time. Unfortunately, even when model updates improve aggregate metrics such as accuracy, they can lead to errors on samples that were correctly predicted by the previous model causing per-sample regression in performance known as predictive churn. Such prediction flips erode user trust thereby reducing the effectiveness of the human-AI team as a whole. We propose a solution called Accumulated Model Combination (AMC) based keeping the previous and current model version, and generating a meta-output using the prediction of the two models. AMC is a general technique and we propose several instances of it, each having their own advantages depending on the model and data properties. AMC requires minimal additional computation and changes to training procedures. We motivate the need for AMC by showing the difficulty of making a single model consistent with its own predictions throughout training thereby revealing an implicit stability-plasticity tradeoff when training a single model. We demonstrate the effectiveness of AMC on a variety of modalities including computer vision, text, and tabular datasets comparing against state-of-the-art churn reduction methods, and showing superior churn reduction ability compared to all existing methods while being more efficient than ensembles.
Continual Learning of Hand Gestures for Human-Robot Interaction
Apr 13, 2023
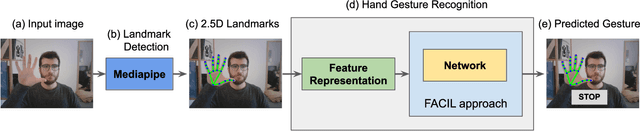
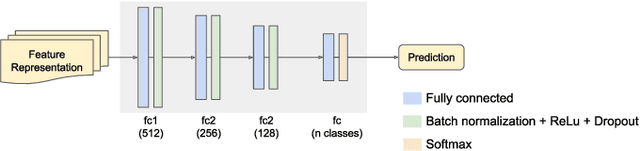

In this paper, we present an efficient method to incrementally learn to classify static hand gestures. This method allows users to teach a robot to recognize new symbols in an incremental manner. Contrary to other works which use special sensors or external devices such as color or data gloves, our proposed approach makes use of a single RGB camera to perform static hand gesture recognition from 2D images. Furthermore, our system is able to incrementally learn up to 38 new symbols using only 5 samples for each old class, achieving a final average accuracy of over 90\%. In addition to that, the incremental training time can be reduced to a 10\% of the time required when using all data available.