 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Capturing Emerging Complexity in Lenia
May 16, 2023


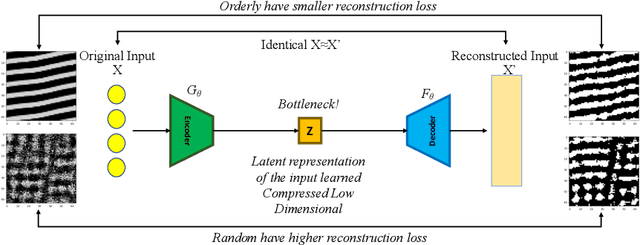
This research project investigates Lenia, an artificial life platform that simulates ecosystems of digital creatures. Lenia's ecosystem consists of simple, artificial organisms that can move, consume, grow, and reproduce. The platform is important as a tool for studying artificial life and evolution, as it provides a scalable and flexible environment for creating a diverse range of organisms with varying abilities and behaviors. Measuring complexity in Lenia is a key aspect of the study, which identifies the metrics for measuring long-term complex emerging behavior of rules, with the aim of evolving better Lenia behaviors which are yet not discovered. The Genetic Algorithm uses neighborhoods or kernels as genotype while keeping the rest of the parameters of Lenia as fixed, for example growth function, to produce different behaviors respective to the population and then measures fitness value to decide the complexity of the resulting behavior. First, we use Variation over Time as a fitness function where higher variance between the frames are rewarded. Second, we use Auto-encoder based fitness where variation of the list of reconstruction loss for the frames is rewarded. Third, we perform combined fitness where higher variation of the pixel density of reconstructed frames is rewarded. All three experiments are tweaked with pixel alive threshold and frames used. Finally, after performing nine experiments of each fitness for 500 generations, we pick configurations from all experiments such that there is a scope of further evolution, and run it for 2500 generations. Results show that the kernel's center of mass increases with a specific set of pixels and together with borders the kernel try to achieve a Gaussian distribution.
On Practical Robust Reinforcement Learning: Practical Uncertainty Set and Double-Agent Algorithm
May 14, 2023
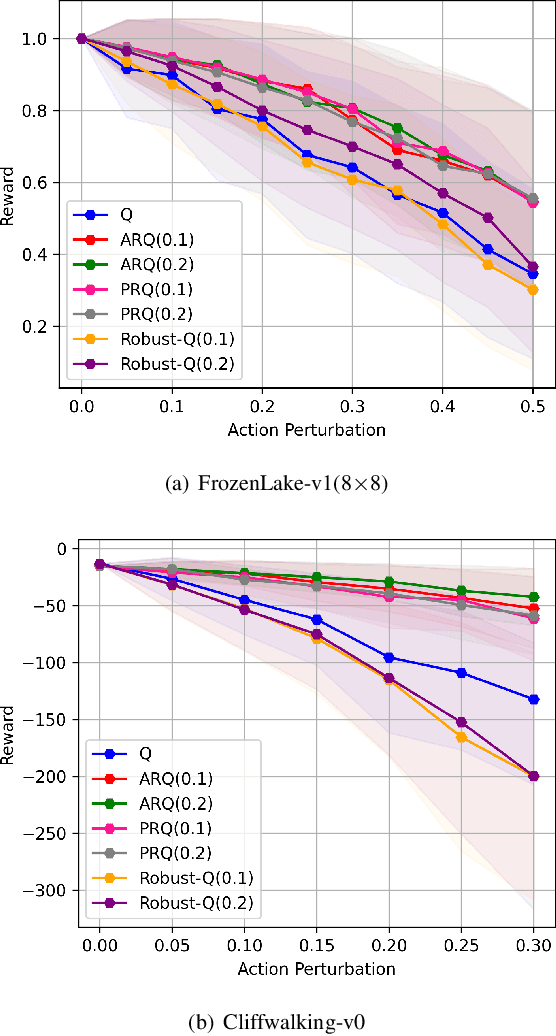
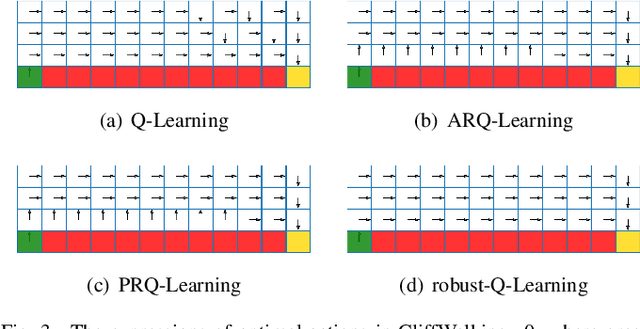
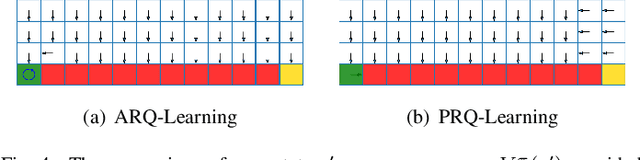
We study a robust reinforcement learning (RL) with model uncertainty. Given nominal Markov decision process (N-MDP) that generate samples for training, an uncertainty set is defined, which contains some perturbed MDPs from N-MDP for the purpose of reflecting potential mismatched between training (i.e., N-MDP) and testing environments. The objective of robust RL is to learn a robust policy that optimizes the worst-case performance over an uncertainty set. In this paper, we propose a new uncertainty set containing more realistic MDPs than the existing ones. For this uncertainty set, we present a robust RL algorithm (named ARQ-Learning) for tabular case and characterize its finite-time error bound. Also, it is proved that ARQ-Learning converges as fast as Q-Learning and the state-of-the-art robust Q-Learning while ensuring better robustness to real-world applications. Next, we propose {\em pessimistic} agent that efficiently tackles the key bottleneck for the extension of ARQ-Learning into the case with larger or continuous state spaces. Incorporating the idea of pessimistic agents into the famous RL algorithms such as Q-Learning, deep-Q network (DQN), and deep deterministic policy gradient (DDPG), we present PRQ-Learning, PR-DQN, and PR-DDPG, respectively. Noticeably, the proposed idea can be immediately applied to other model-free RL algorithms (e.g., soft actor critic). Via experiments, we demonstrate the superiority of our algorithms on various RL applications with model uncertainty.
Wooden Sleeper Deterioration Detection for Rural Railway Prognostics Using Unsupervised Deeper FCDDs
May 14, 2023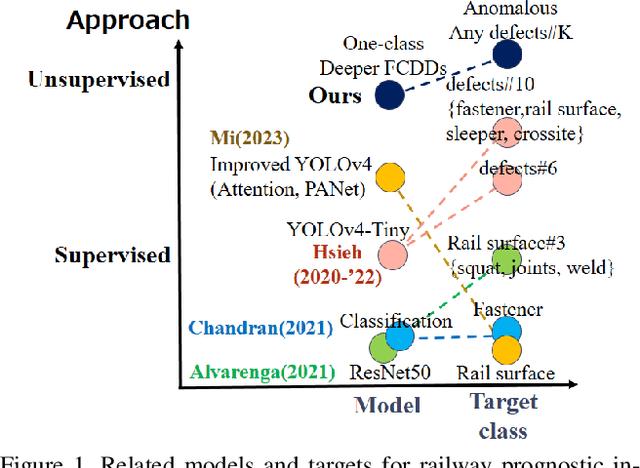
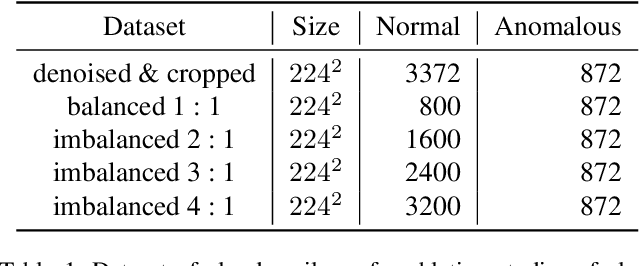
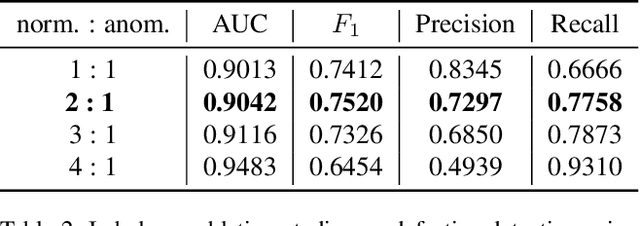
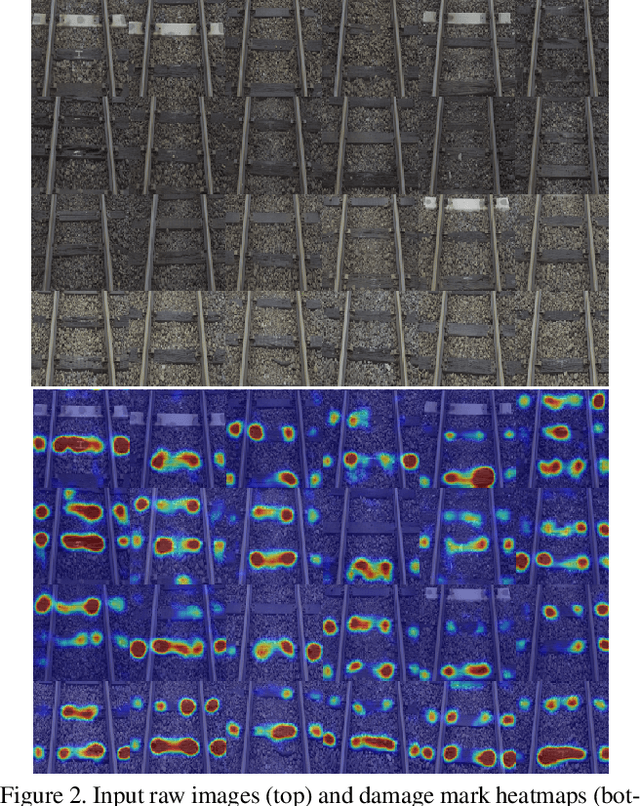
Maintaining high standards for user safety during daily railway operations is crucial for railway managers. To aid in this endeavor, top- or side-view cameras and GPS positioning systems have facilitated progress toward automating periodic inspections of defective features and assessing the deteriorating status of railway components. However, collecting data on deteriorated status can be time-consuming and requires repeated data acquisition because of the extreme temporal occurrence imbalance. In supervised learning, thousands of paired data sets containing defective raw images and annotated labels are required. However, the one-class classification approach offers the advantage of requiring fewer images to optimize parameters for training normal and anomalous features. The deeper fully-convolutional data descriptions (FCDDs) were applicable to several damage data sets of concrete/steel components in structures, and fallen tree, and wooden building collapse in disasters. However, it is not yet known to feasible to railway components. In this study, we devised a prognostic discriminator pipeline to automate one-class damage classification using the deeper FCDDs for defective railway components. We also performed sensitivity analysis of the deeper backbone and receptive field based on convolutional neural networks (CNNs). Furthermore, we visualized defective railway features by using transposed Gaussian upsampling. We demonstrated our application to railway inspection using a video acquisition dataset of railway track in forward view that contains wooden sleeper deterioration in rural railways. Finally, we examined the usability of our approach for prognostic monitoring and future work on railway component inspection.
Ship-D: Ship Hull Dataset for Design Optimization using Machine Learning
May 14, 2023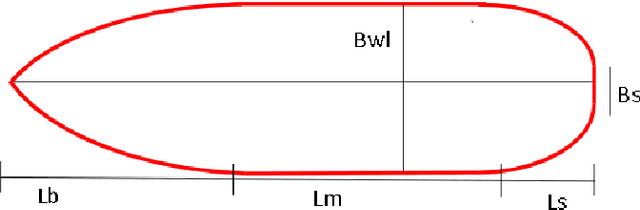


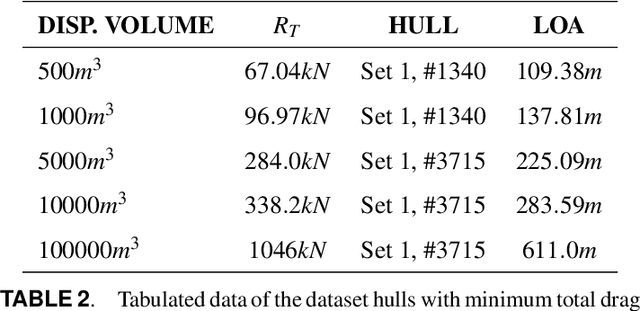
Machine learning has recently made significant strides in reducing design cycle time for complex products. Ship design, which currently involves years long cycles and small batch production, could greatly benefit from these advancements. By developing a machine learning tool for ship design that learns from the design of many different types of ships, tradeoffs in ship design could be identified and optimized. However, the lack of publicly available ship design datasets currently limits the potential for leveraging machine learning in generalized ship design. To address this gap, this paper presents a large dataset of thirty thousand ship hulls, each with design and functional performance information, including parameterization, mesh, point cloud, and image representations, as well as thirty two hydrodynamic drag measures under different operating conditions. The dataset is structured to allow human input and is also designed for computational methods. Additionally, the paper introduces a set of twelve ship hulls from publicly available CAD repositories to showcase the proposed parameterizations ability to accurately reconstruct existing hulls. A surrogate model was developed to predict the thirty two wave drag coefficients, which was then implemented in a genetic algorithm case study to reduce the total drag of a hull by sixty percent while maintaining the shape of the hulls cross section and the length of the parallel midbody. Our work provides a comprehensive dataset and application examples for other researchers to use in advancing data driven ship design.
DA-LSTM: A Dynamic Drift-Adaptive Learning Framework for Interval Load Forecasting with LSTM Networks
May 15, 2023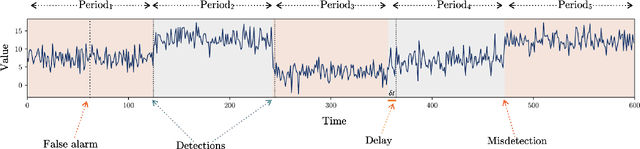
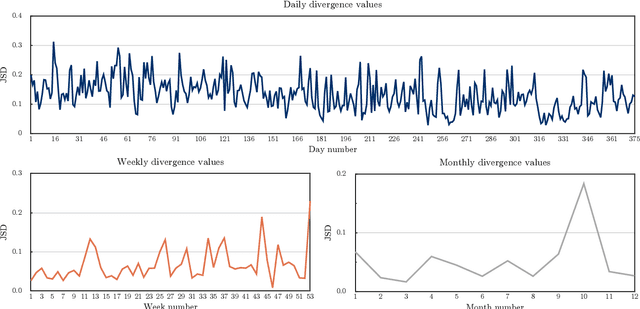
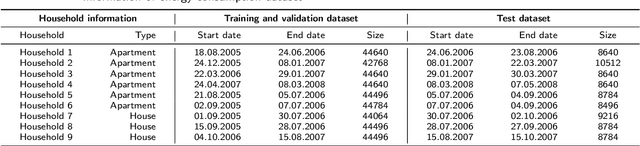
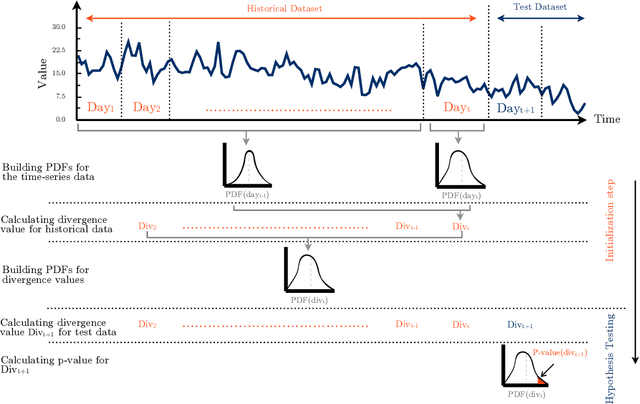
Load forecasting is a crucial topic in energy management systems (EMS) due to its vital role in optimizing energy scheduling and enabling more flexible and intelligent power grid systems. As a result, these systems allow power utility companies to respond promptly to demands in the electricity market. Deep learning (DL) models have been commonly employed in load forecasting problems supported by adaptation mechanisms to cope with the changing pattern of consumption by customers, known as concept drift. A drift magnitude threshold should be defined to design change detection methods to identify drifts. While the drift magnitude in load forecasting problems can vary significantly over time, existing literature often assumes a fixed drift magnitude threshold, which should be dynamically adjusted rather than fixed during system evolution. To address this gap, in this paper, we propose a dynamic drift-adaptive Long Short-Term Memory (DA-LSTM) framework that can improve the performance of load forecasting models without requiring a drift threshold setting. We integrate several strategies into the framework based on active and passive adaptation approaches. To evaluate DA-LSTM in real-life settings, we thoroughly analyze the proposed framework and deploy it in a real-world problem through a cloud-based environment. Efficiency is evaluated in terms of the prediction performance of each approach and computational cost. The experiments show performance improvements on multiple evaluation metrics achieved by our framework compared to baseline methods from the literature. Finally, we present a trade-off analysis between prediction performance and computational costs.
DopUS-Net: Quality-Aware Robotic Ultrasound Imaging based on Doppler Signal
May 15, 2023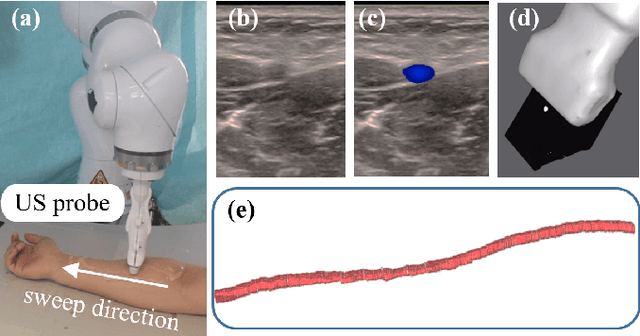
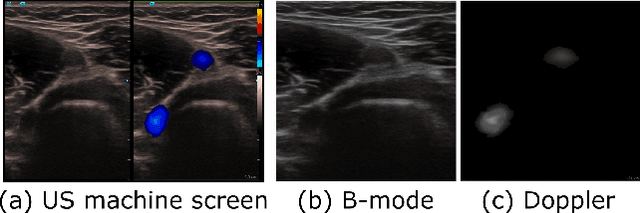
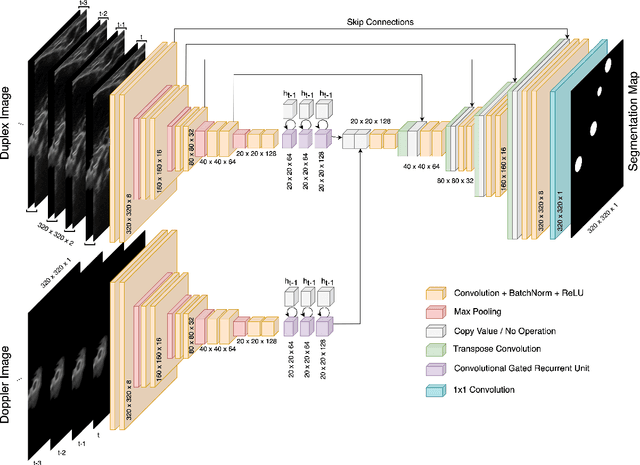

Medical ultrasound (US) is widely used to evaluate and stage vascular diseases, in particular for the preliminary screening program, due to the advantage of being radiation-free. However, automatic segmentation of small tubular structures (e.g., the ulnar artery) from cross-sectional US images is still challenging. To address this challenge, this paper proposes the DopUS-Net and a vessel re-identification module that leverage the Doppler effect to enhance the final segmentation result. Firstly, the DopUS-Net combines the Doppler images with B-mode images to increase the segmentation accuracy and robustness of small blood vessels. It incorporates two encoders to exploit the maximum potential of the Doppler signal and recurrent neural network modules to preserve sequential information. Input to the first encoder is a two-channel duplex image representing the combination of the grey-scale Doppler and B-mode images to ensure anatomical spatial correctness. The second encoder operates on the pure Doppler images to provide a region proposal. Secondly, benefiting from the Doppler signal, this work first introduces an online artery re-identification module to qualitatively evaluate the real-time segmentation results and automatically optimize the probe pose for enhanced Doppler images. This quality-aware module enables the closed-loop control of robotic screening to further improve the confidence and robustness of image segmentation. The experimental results demonstrate that the proposed approach with the re-identification process can significantly improve the accuracy and robustness of the segmentation results (dice score: from 0:54 to 0:86; intersection over union: from 0:47 to 0:78).
Tracking an Underwater Target with Unknown Measurement Noise Statistics Using Variational Bayesian Filters
May 15, 2023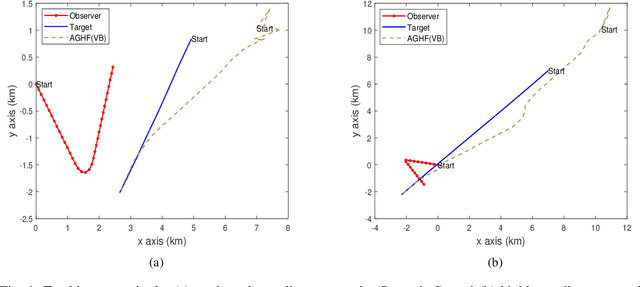
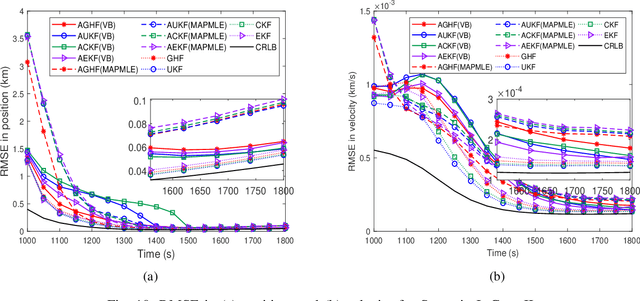
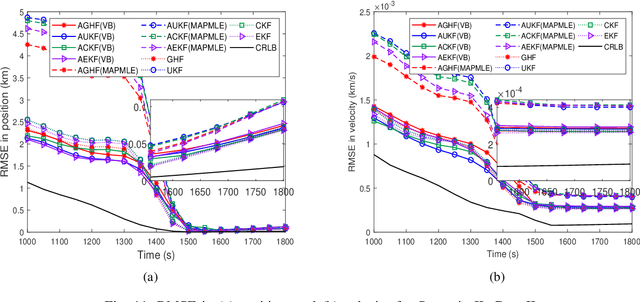
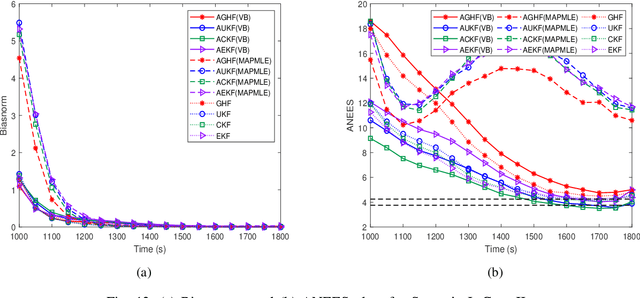
This paper considers a bearings-only tracking problem using noisy measurements of unknown noise statistics from a passive sensor. It is assumed that the process and measurement noise follows the Gaussian distribution where the measurement noise has an unknown non-zero mean and unknown covariance. Here an adaptive nonlinear filtering technique is proposed where the joint distribution of the measurement noise mean and its covariance are considered to be following normal inverse Wishart distribution (NIW). Using the variational Bayesian (VB) method the estimation technique is derived with optimized tuning parameters i.e, the confidence parameter and the initial degree of freedom of the measurement noise mean and the covariance, respectively. The proposed filtering technique is compared with the adaptive filtering techniques based on maximum likelihood and maximum aposteriori in terms of root mean square error in position and velocity, bias norm, average normalized estimation error squared, percentage of track loss, and relative execution time. Both adaptive filtering techniques are implemented using the traditional Gaussian approximate filters and are applied to a bearings-only tracking problem illustrated with moderately nonlinear and highly nonlinear scenarios to track a target following a nearly straight line path. Two cases are considered for each scenario, one when the measurement noise covariance is static and another when the measurement noise covariance is varying linearly with the distance between the target and the ownship. In this work, the proposed adaptive filters using the VB approach are found to be superior to their corresponding adaptive filters based on the maximum aposteriori and the maximum likelihood at the expense of higher computation cost.
Contrastive Learning for Sleep Staging based on Inter Subject Correlation
May 05, 2023In recent years, multitudes of researches have applied deep learning to automatic sleep stage classification. Whereas actually, these works have paid less attention to the issue of cross-subject in sleep staging. At the same time, emerging neuroscience theories on inter-subject correlations can provide new insights for cross-subject analysis. This paper presents the MViTime model that have been used in sleep staging study. And we implement the inter-subject correlation theory through contrastive learning, providing a feasible solution to address the cross-subject problem in sleep stage classification. Finally, experimental results and conclusions are presented, demonstrating that the developed method has achieved state-of-the-art performance on sleep staging. The results of the ablation experiment also demonstrate the effectiveness of the cross-subject approach based on contrastive learning.
Neural Implicit Dense Semantic SLAM
May 09, 2023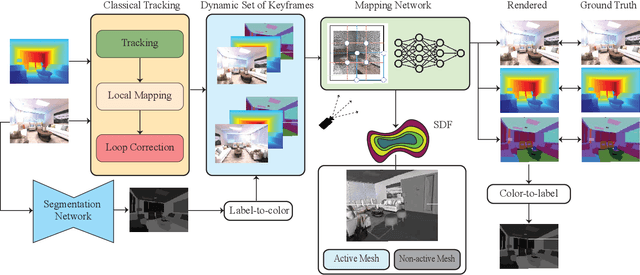
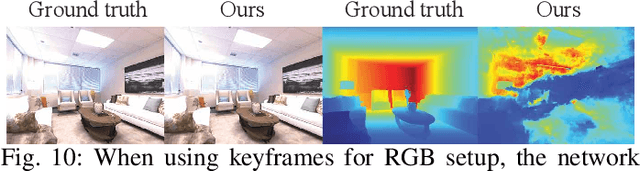
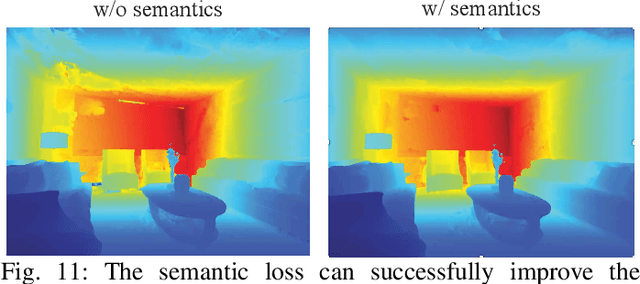

Visual Simultaneous Localization and Mapping (vSLAM) is a widely used technique in robotics and computer vision that enables a robot to create a map of an unfamiliar environment using a camera sensor while simultaneously tracking its position over time. In this paper, we propose a novel RGBD vSLAM algorithm that can learn a memory-efficient, dense 3D geometry, and semantic segmentation of an indoor scene in an online manner. Our pipeline combines classical 3D vision-based tracking and loop closing with neural fields-based mapping. The mapping network learns the SDF of the scene as well as RGB, depth, and semantic maps of any novel view using only a set of keyframes. Additionally, we extend our pipeline to large scenes by using multiple local mapping networks. Extensive experiments on well-known benchmark datasets confirm that our approach provides robust tracking, mapping, and semantic labeling even with noisy, sparse, or no input depth. Overall, our proposed algorithm can greatly enhance scene perception and assist with a range of robot control problems.
The Elephant in the Room: Analyzing the Presence of Big Tech in Natural Language Processing Research
May 09, 2023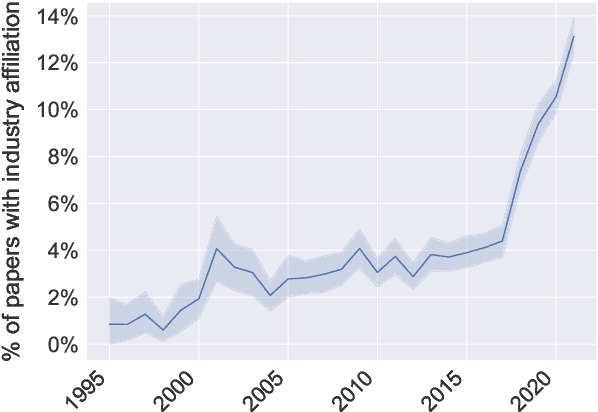

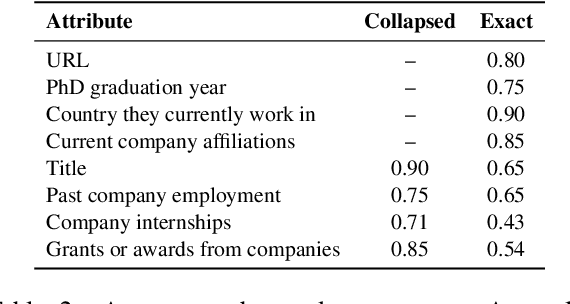
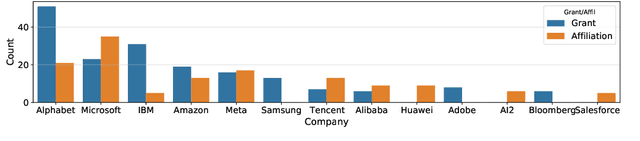
Recent advances in deep learning methods for natural language processing (NLP) have created new business opportunities and made NLP research critical for industry development. As one of the big players in the field of NLP, together with governments and universities, it is important to track the influence of industry on research. In this study, we seek to quantify and characterize industry presence in the NLP community over time. Using a corpus with comprehensive metadata of 78,187 NLP publications and 701 resumes of NLP publication authors, we explore the industry presence in the field since the early 90s. We find that industry presence among NLP authors has been steady before a steep increase over the past five years (180% growth from 2017 to 2022). A few companies account for most of the publications and provide funding to academic researchers through grants and internships. Our study shows that the presence and impact of the industry on natural language processing research are significant and fast-growing. This work calls for increased transparency of industry influence in the field.