 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Fabrication of a Low-Cost Real-Time Mobile ECG System for Health Monitoring
Feb 13, 2023
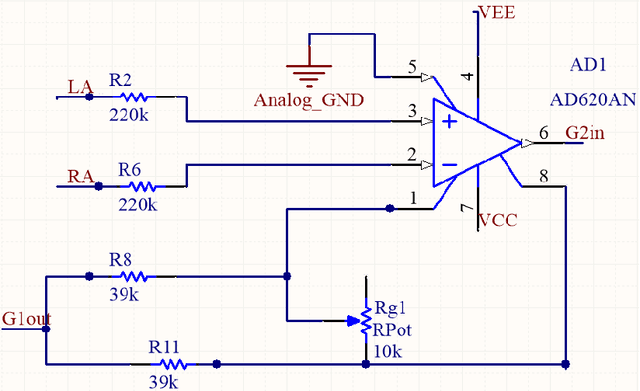
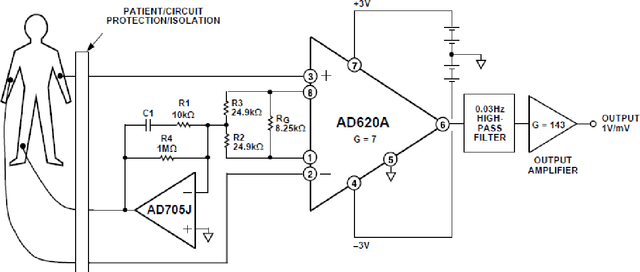
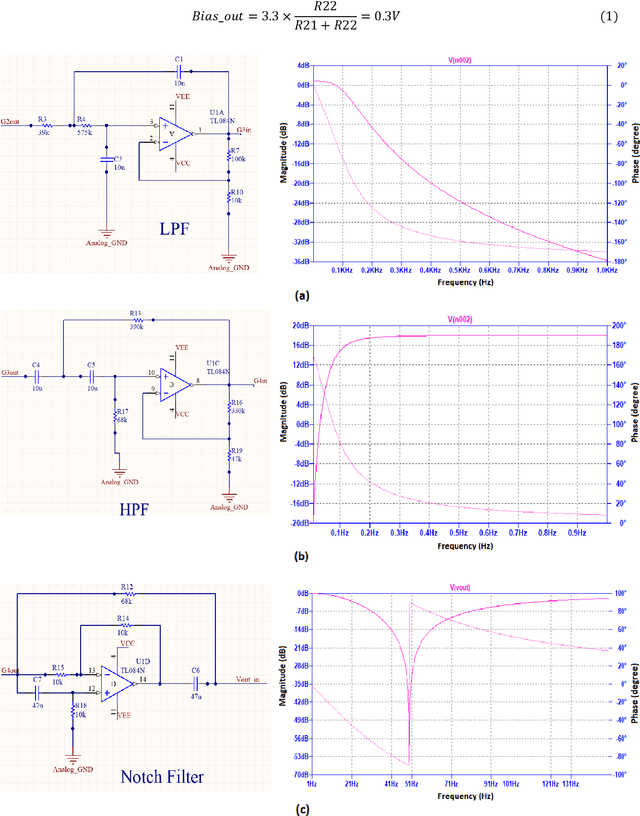
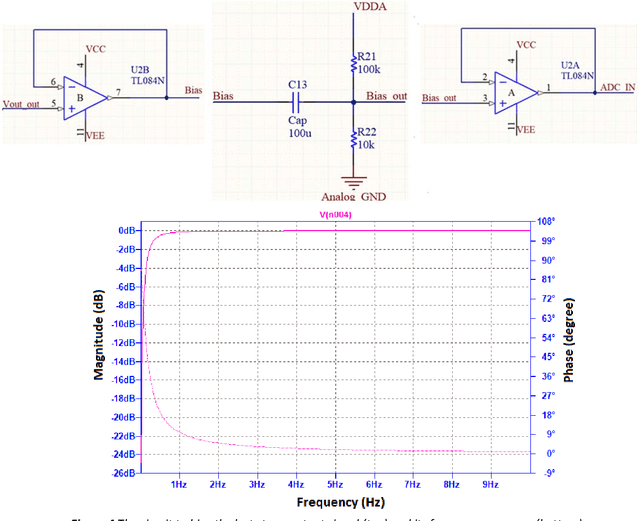
The electrocardiogram (ECG) signal is one of the most vital signals that can be used to investigate the performance of heart. Based on the ECG graph, we can identify different disorders and diseases. Therefore, monitoring this signal is of great importance. Many electrodes (usually 12) are employed to acquire this signal in clinics and hospitals; therefore, a nurse must install them on the body of the patient to record the signal. In this project, we built a device that can acquire the real-time ECG signal and display it on the mobile screen with the least number of electrodes (three electrodes) without requiring a nurse to install the electrodes using the simplest and cheapest type of ICs and transmitters including STM32F030F4P6 microcontroller, AD620 instrumentation amplifier, TL084 amplifier, TC7660 voltage converter, LM1117 regulator, and HC-05 Bluetooth module. Moreover, the device was designed in a way that could operate using a single 9V battery or power adaptor. First, to amplify the signal and remove a part of its noise, the ECG signal is given to the primary analog circuit. Then, in the digital section, using a microcontroller, the signal is discretized, processed, and finally transmitted to a mobile phone for final processing, information extraction, and displaying. In the mobile-written application, we developed a mathematical algorithm based on Pan-Tompkins algorithm to calculate the heartbeat rate, in which the signal peaks are determined after several processing steps using a threshold. In this regard, the ECG signals of 10 subjects were recorded and analyzed to calculate the optimum threshold. Finally, the power spectral density (PSD) and input referred noise were calculated and plotted to check the output signal quality. Based on the PSD and input referred noise amplitudes, we achieved a signal-to-noise ratio of 50dB.
You Only Crash Once: Improved Object Detection for Real-Time, Sim-to-Real Hazardous Terrain Detection and Classification for Autonomous Planetary Landings
Mar 08, 2023
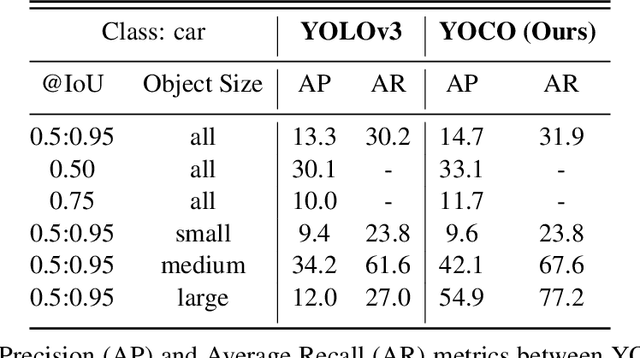
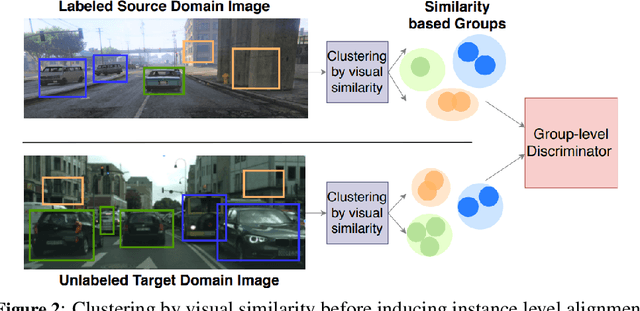
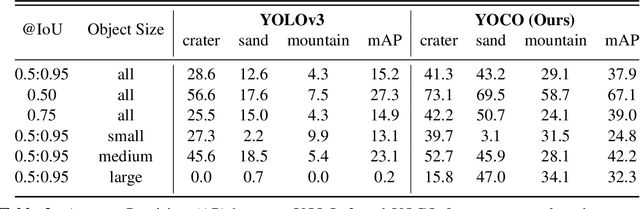
The detection of hazardous terrain during the planetary landing of spacecraft plays a critical role in assuring vehicle safety and mission success. A cheap and effective way of detecting hazardous terrain is through the use of visual cameras, which ensure operational ability from atmospheric entry through touchdown. Plagued by resource constraints and limited computational power, traditional techniques for visual hazardous terrain detection focus on template matching and registration to pre-built hazard maps. Although successful on previous missions, this approach is restricted to the specificity of the templates and limited by the fidelity of the underlying hazard map, which both require extensive pre-flight cost and effort to obtain and develop. Terrestrial systems that perform a similar task in applications such as autonomous driving utilize state-of-the-art deep learning techniques to successfully localize and classify navigation hazards. Advancements in spacecraft co-processors aimed at accelerating deep learning inference enable the application of these methods in space for the first time. In this work, we introduce You Only Crash Once (YOCO), a deep learning-based visual hazardous terrain detection and classification technique for autonomous spacecraft planetary landings. Through the use of unsupervised domain adaptation we tailor YOCO for training by simulation, removing the need for real-world annotated data and expensive mission surveying phases. We further improve the transfer of representative terrain knowledge between simulation and the real world through visual similarity clustering. We demonstrate the utility of YOCO through a series of terrestrial and extraterrestrial simulation-to-real experiments and show substantial improvements toward the ability to both detect and accurately classify instances of planetary terrain.
LSTM-based Preceding Vehicle Behaviour Prediction during Aggressive Lane Change for ACC Application
May 05, 2023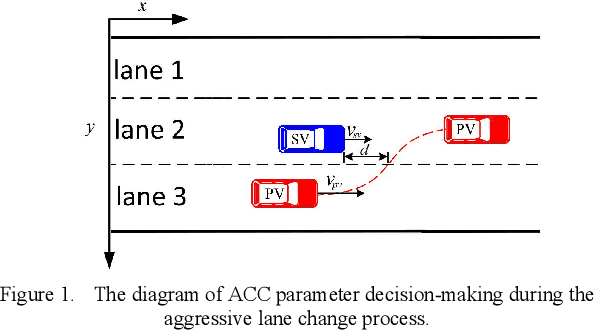
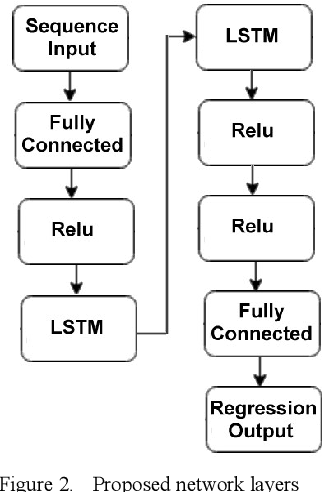
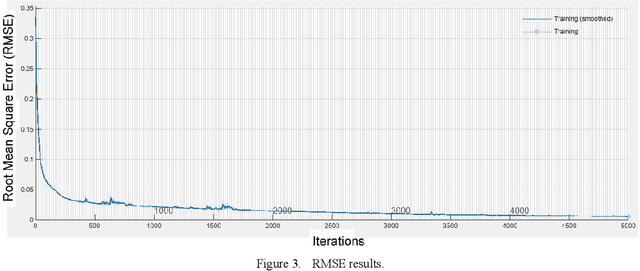
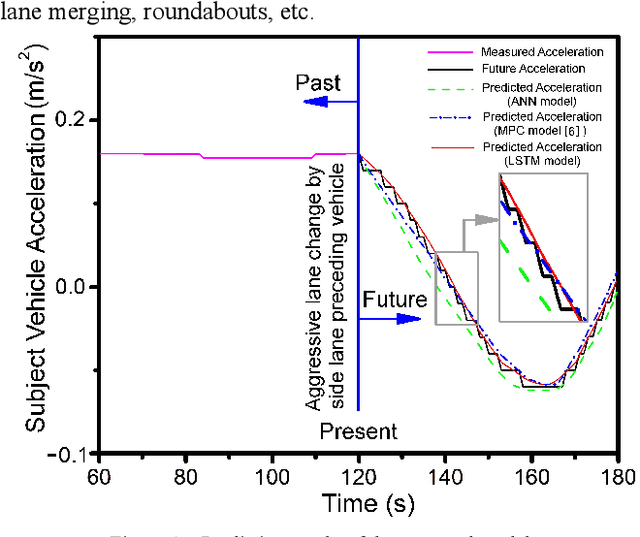
The development of Adaptive Cruise Control (ACC) systems aims to enhance the safety and comfort of vehicles by automatically regulating the speed of the vehicle to ensure a safe gap from the preceding vehicle. However, conventional ACC systems are unable to adapt themselves to changing driving conditions and drivers' behavior. To address this limitation, we propose a Long Short-Term Memory (LSTM) based ACC system that can learn from past driving experiences and adapt and predict new situations in real time. The model is constructed based on the real-world highD dataset, acquired from German highways with the assistance of camera-equipped drones. We evaluated the ACC system under aggressive lane changes when the side lane preceding vehicle cut off, forcing the targeted driver to reduce speed. To this end, the proposed system was assessed on a simulated driving environment and compared with a feedforward Artificial Neural Network (ANN) model and Model Predictive Control (MPC) model. The results show that the LSTM-based system is 19.25% more accurate than the ANN model and 5.9% more accurate than the MPC model in terms of predicting future values of subject vehicle acceleration. The simulation is done in Matlab/Simulink environment.
Breast Cancer Immunohistochemical Image Generation: a Benchmark Dataset and Challenge Review
May 05, 2023


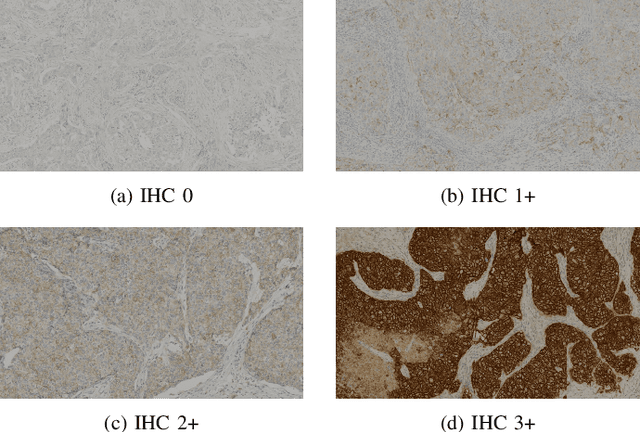
For invasive breast cancer, immunohistochemical (IHC) techniques are often used to detect the expression level of human epidermal growth factor receptor-2 (HER2) in breast tissue to formulate a precise treatment plan. From the perspective of saving manpower, material and time costs, directly generating IHC-stained images from hematoxylin and eosin (H&E) stained images is a valuable research direction. Therefore, we held the breast cancer immunohistochemical image generation challenge, aiming to explore novel ideas of deep learning technology in pathological image generation and promote research in this field. The challenge provided registered H&E and IHC-stained image pairs, and participants were required to use these images to train a model that can directly generate IHC-stained images from corresponding H&E-stained images. We selected and reviewed the five highest-ranking methods based on their PSNR and SSIM metrics, while also providing overviews of the corresponding pipelines and implementations. In this paper, we further analyze the current limitations in the field of breast cancer immunohistochemical image generation and forecast the future development of this field. We hope that the released dataset and the challenge will inspire more scholars to jointly study higher-quality IHC-stained image generation.
FAST: Feature Arrangement for Semantic Transmission
May 05, 2023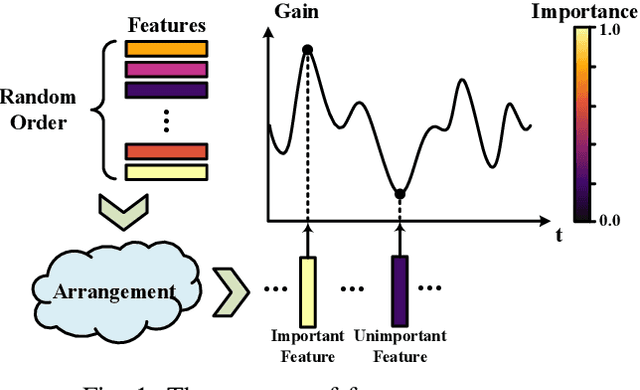
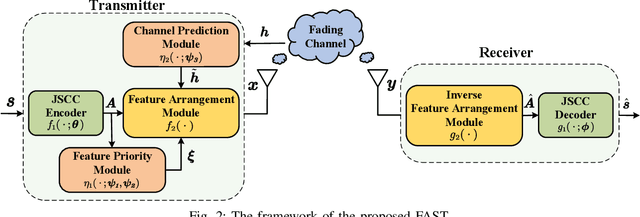
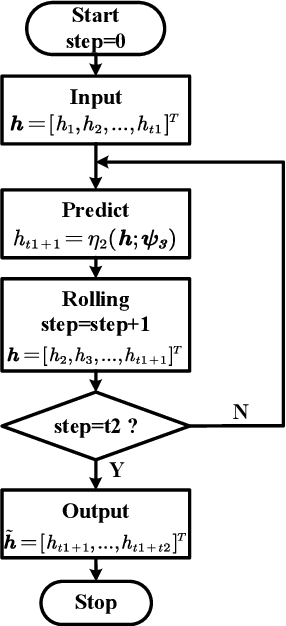
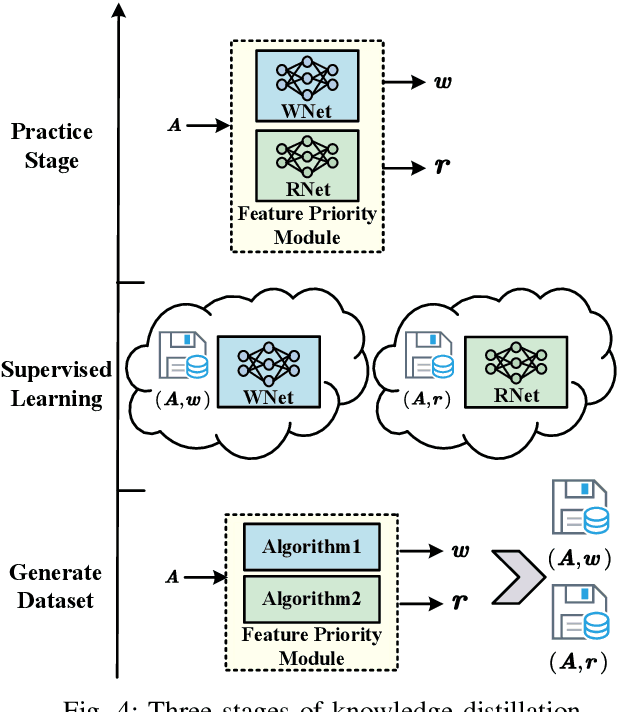
Although existing semantic communication systems have achieved great success, they have not considered that the channel is time-varying wherein deep fading occurs occasionally. Moreover, the importance of each semantic feature differs from each other. Consequently, the important features may be affected by channel fading and corrupted, resulting in performance degradation. Therefore, higher performance can be achieved by avoiding the transmission of important features when the channel state is poor. In this paper, we propose a scheme of Feature Arrangement for Semantic Transmission (FAST). In particular, we aim to schedule the transmission order of features and transmit important features when the channel state is good. To this end, we first propose a novel metric termed feature priority, which takes into consideration both feature importance and feature robustness. Then, we perform channel prediction at the transmitter side to obtain the future channel state information (CSI). Furthermore, the feature arrangement module is developed based on the proposed feature priority and the predicted CSI by transmitting the prior features under better CSI. Simulation results show that the proposed scheme significantly improves the performance of image transmission compared to existing semantic communication systems without feature arrangement.
PMP: Learning to Physically Interact with Environments using Part-wise Motion Priors
May 05, 2023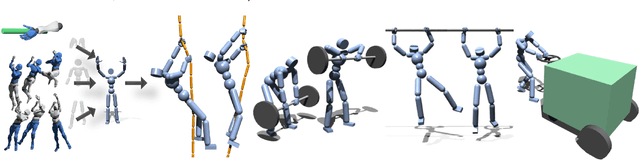

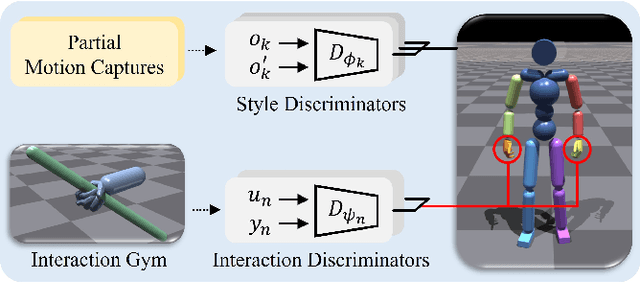
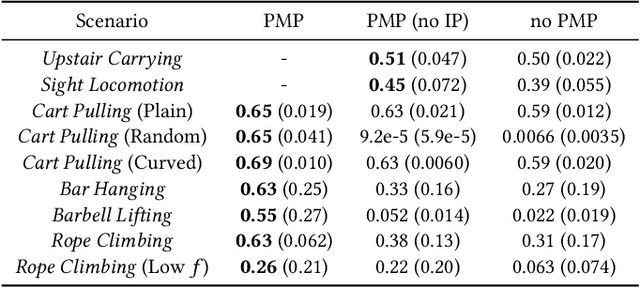
We present a method to animate a character incorporating multiple part-wise motion priors (PMP). While previous works allow creating realistic articulated motions from reference data, the range of motion is largely limited by the available samples. Especially for the interaction-rich scenarios, it is impractical to attempt acquiring every possible interacting motion, as the combination of physical parameters increases exponentially. The proposed PMP allows us to assemble multiple part skills to animate a character, creating a diverse set of motions with different combinations of existing data. In our pipeline, we can train an agent with a wide range of part-wise priors. Therefore, each body part can obtain a kinematic insight of the style from the motion captures, or at the same time extract dynamics-related information from the additional part-specific simulation. For example, we can first train a general interaction skill, e.g. grasping, only for the dexterous part, and then combine the expert trajectories from the pre-trained agent with the kinematic priors of other limbs. Eventually, our whole-body agent learns a novel physical interaction skill even with the absence of the object trajectories in the reference motion sequence.
Deep Learning-based Estimation for Multitarget Radar Detection
May 05, 2023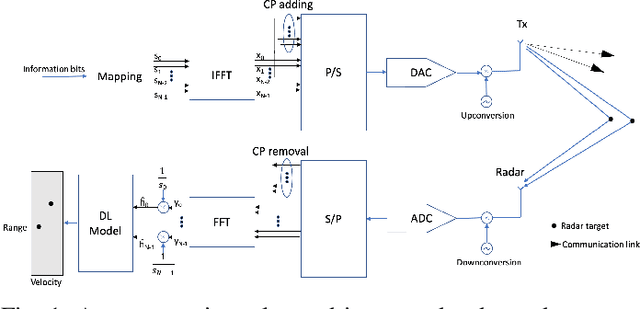
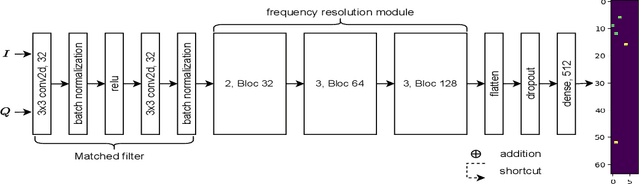
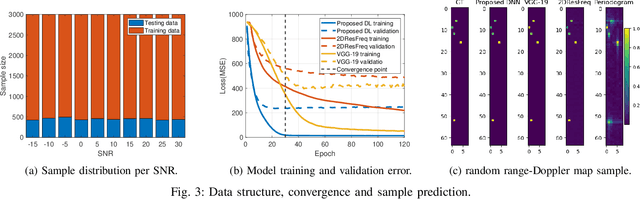
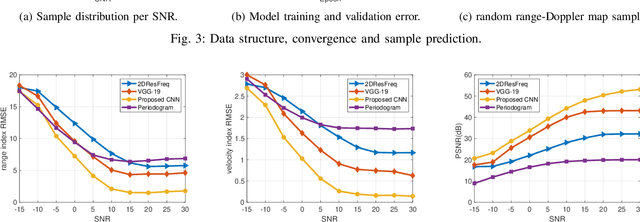
Target detection and recognition is a very challenging task in a wireless environment where a multitude of objects are located, whether to effectively determine their positions or to identify them and predict their moves. In this work, we propose a new method based on a convolutional neural network (CNN) to estimate the range and velocity of moving targets directly from the range-Doppler map of the detected signals. We compare the obtained results to the two dimensional (2D) periodogram, and to the similar state of the art methods, 2DResFreq and VGG-19 network and show that the estimation process performed with our model provides better estimation accuracy of range and velocity index in different signal to noise ratio (SNR) regimes along with a reduced prediction time. Afterwards, we assess the performance of our proposed algorithm using the peak signal to noise ratio (PSNR) which is a relevant metric to analyse the quality of an output image obtained from compression or noise reduction. Compared to the 2D-periodogram, 2DResFreq and VGG-19, we gain 33 dB, 21 dB and 10 dB, respectively, in terms of PSNR when SNR = 30 dB.
Time out of Mind: Generating Rate of Speech conditioned on emotion and speaker
Jan 31, 2023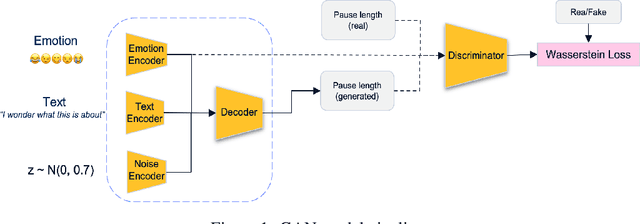
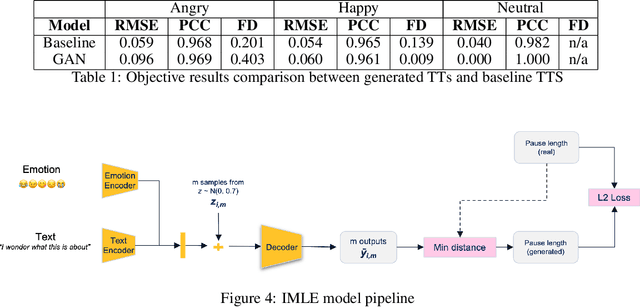
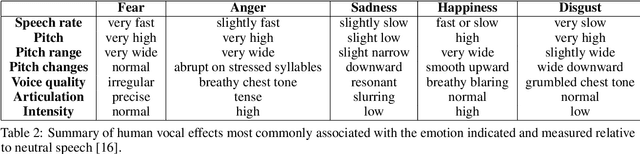
Voice synthesis has seen significant improvements in the past decade resulting in highly intelligible voices. Further investigations have resulted in models that can produce variable speech, including conditional emotional expression. The problem lies, however, in a focus on phrase-level modifications and prosodic vocal features. Using the CREMA-D dataset we have trained a GAN conditioned on emotion to generate worth lengths for a given input text. These word lengths are relative to neutral speech and can be provided, through speech synthesis markup language (SSML) to a text-to-speech (TTS) system to generate more expressive speech. Additionally, a generative model is also trained using implicit maximum likelihood estimation (IMLE) and a comparative analysis with GANs is included. We were able to achieve better performances on objective measures for neutral speech, and better time alignment for happy speech when compared to an out-of-box model. However, further investigation of subjective evaluation is required.
Model Evaluation in Medical Datasets Over Time
Nov 14, 2022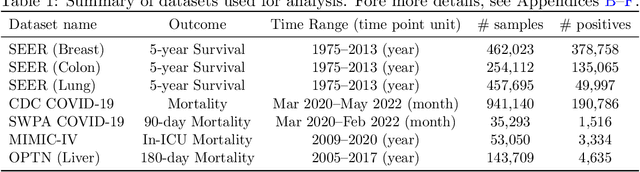
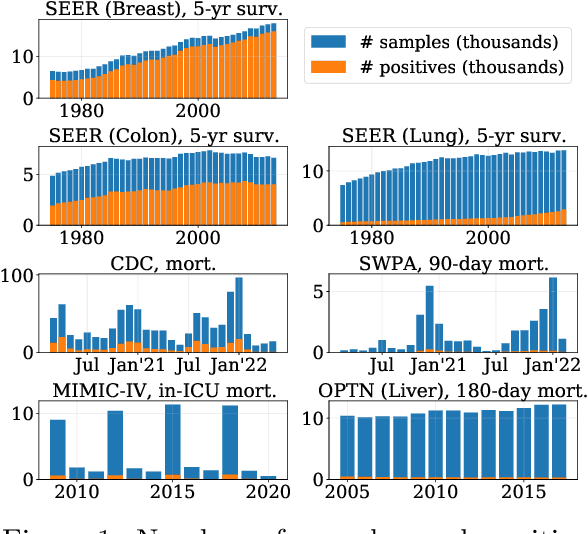
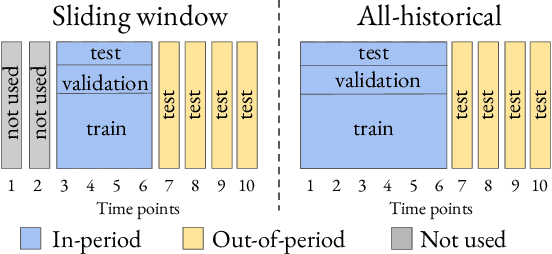
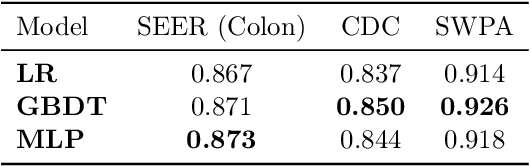
Machine learning models deployed in healthcare systems face data drawn from continually evolving environments. However, researchers proposing such models typically evaluate them in a time-agnostic manner, with train and test splits sampling patients throughout the entire study period. We introduce the Evaluation on Medical Datasets Over Time (EMDOT) framework and Python package, which evaluates the performance of a model class over time. Across five medical datasets and a variety of models, we compare two training strategies: (1) using all historical data, and (2) using a window of the most recent data. We note changes in performance over time, and identify possible explanations for these shocks.
Optimizing Guided Traversal for Fast Learned Sparse Retrieval
May 02, 2023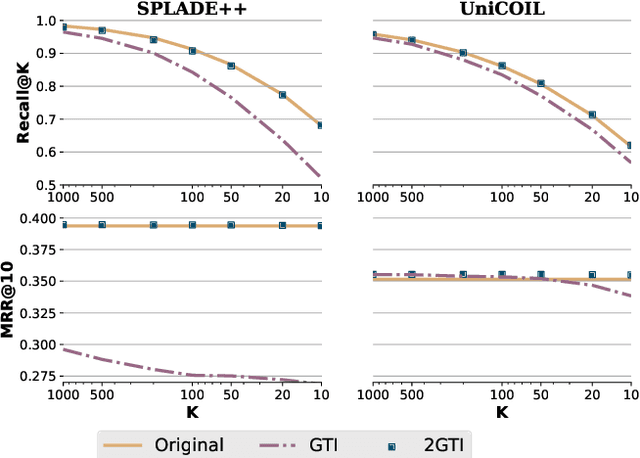
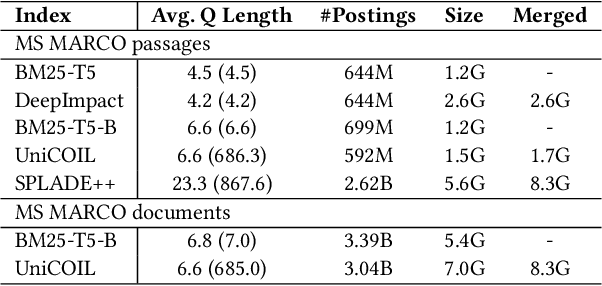
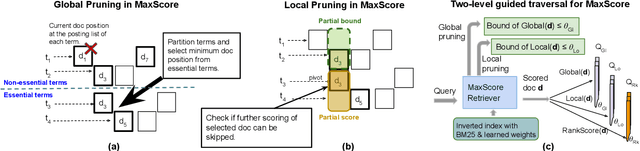
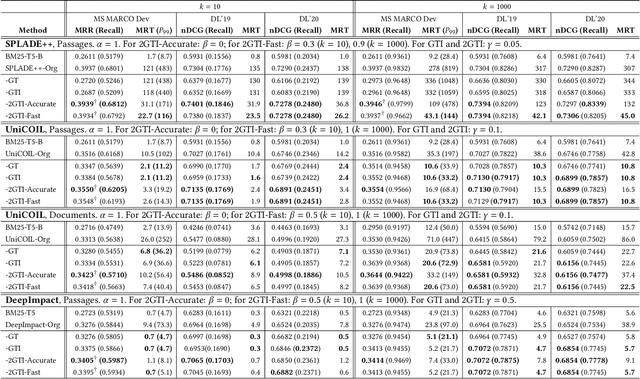
Recent studies show that BM25-driven dynamic index skipping can greatly accelerate MaxScore-based document retrieval based on the learned sparse representation derived by DeepImpact. This paper investigates the effectiveness of such a traversal guidance strategy during top k retrieval when using other models such as SPLADE and uniCOIL, and finds that unconstrained BM25-driven skipping could have a visible relevance degradation when the BM25 model is not well aligned with a learned weight model or when retrieval depth k is small. This paper generalizes the previous work and optimizes the BM25 guided index traversal with a two-level pruning control scheme and model alignment for fast retrieval using a sparse representation. Although there can be a cost of increased latency, the proposed scheme is much faster than the original MaxScore method without BM25 guidance while retaining the relevance effectiveness. This paper analyzes the competitiveness of this two-level pruning scheme, and evaluates its tradeoff in ranking relevance and time efficiency when searching several test datasets.
* This paper is published in WWW'23