 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
High-dimensional Bayesian Optimization via Semi-supervised Learning with Optimized Unlabeled Data Sampling
May 04, 2023

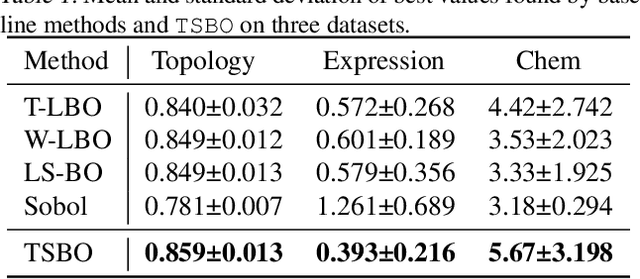
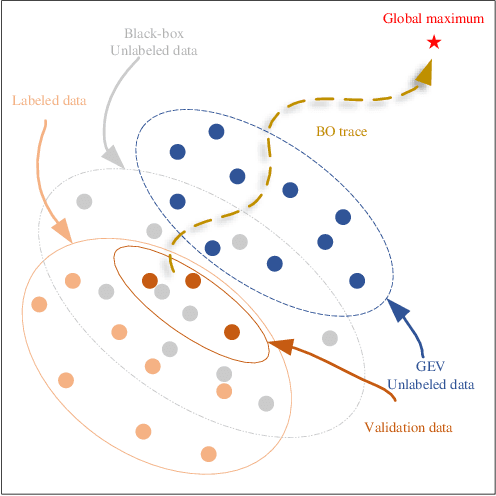
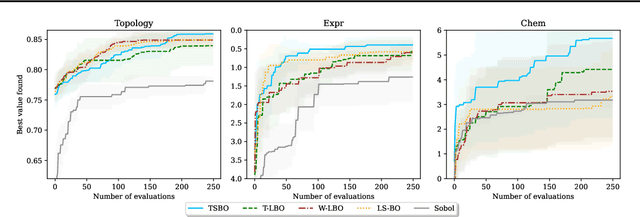
Bayesian optimization (BO) is a powerful tool for seeking the global optimum of black-box functions. While evaluations of the black-box functions can be highly costly, it is desirable to reduce the use of expensive labeled data. For the first time, we introduce a teacher-student model to exploit semi-supervised learning that can make use of large amounts of unlabelled data under the context of BO. Importantly, we show that the selection of the validation and unlabeled data is key to the performance of BO. To optimize the sampling of unlabeled data, we employ a black-box parameterized sampling distribution optimized as part of the employed bi-level optimization framework. Taking one step further, we demonstrate that the performance of BO can be further improved by selecting unlabeled data from a dynamically fitted extreme value distribution. Our BO method operates in a learned latent space with reduced dimensionality, making it scalable to high-dimensional problems. The proposed approach outperforms significantly the existing BO methods on several synthetic and real-world optimization tasks.
Critical heat flux diagnosis using conditional generative adversarial networks
May 04, 2023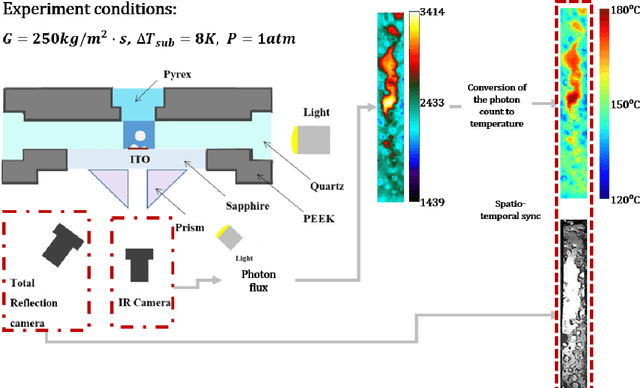
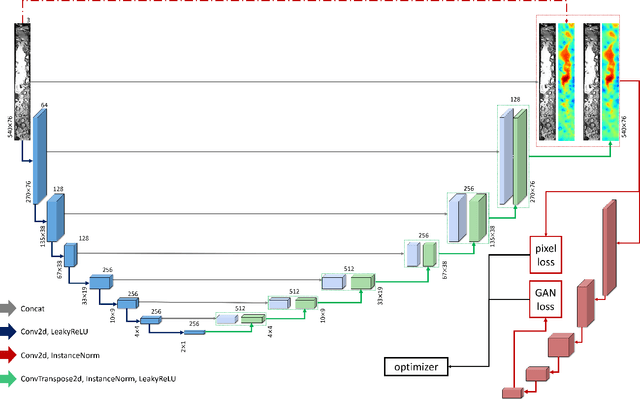

The critical heat flux (CHF) is an essential safety boundary in boiling heat transfer processes employed in high heat flux thermal-hydraulic systems. Identifying CHF is vital for preventing equipment damage and ensuring overall system safety, yet it is challenging due to the complexity of the phenomena. For an in-depth understanding of the complicated phenomena, various methodologies have been devised, but the acquisition of high-resolution data is limited by the substantial resource consumption required. This study presents a data-driven, image-to-image translation method for reconstructing thermal data of a boiling system at CHF using conditional generative adversarial networks (cGANs). The supervised learning process relies on paired images, which include total reflection visualizations and infrared thermometry measurements obtained from flow boiling experiments. Our proposed approach has the potential to not only provide evidence connecting phase interface dynamics with thermal distribution but also to simplify the laborious and time-consuming experimental setup and data-reduction procedures associated with infrared thermal imaging, thereby providing an effective solution for CHF diagnosis.
Masked Trajectory Models for Prediction, Representation, and Control
May 04, 2023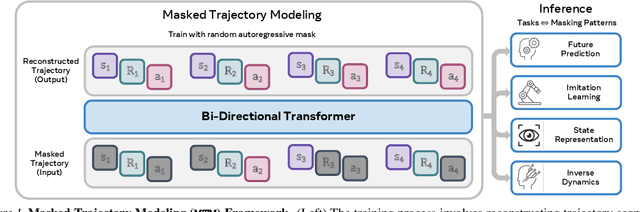
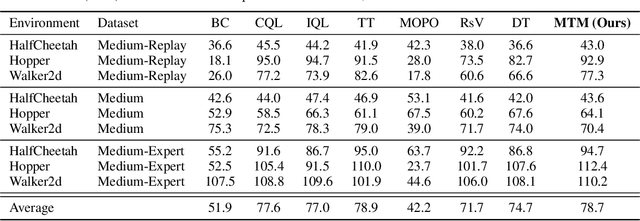
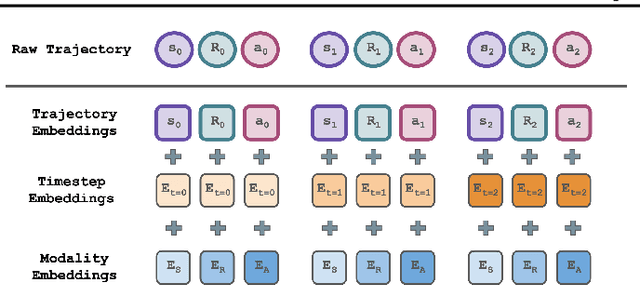
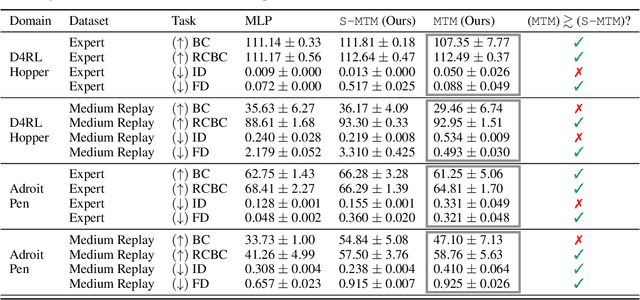
We introduce Masked Trajectory Models (MTM) as a generic abstraction for sequential decision making. MTM takes a trajectory, such as a state-action sequence, and aims to reconstruct the trajectory conditioned on random subsets of the same trajectory. By training with a highly randomized masking pattern, MTM learns versatile networks that can take on different roles or capabilities, by simply choosing appropriate masks at inference time. For example, the same MTM network can be used as a forward dynamics model, inverse dynamics model, or even an offline RL agent. Through extensive experiments in several continuous control tasks, we show that the same MTM network -- i.e. same weights -- can match or outperform specialized networks trained for the aforementioned capabilities. Additionally, we find that state representations learned by MTM can significantly accelerate the learning speed of traditional RL algorithms. Finally, in offline RL benchmarks, we find that MTM is competitive with specialized offline RL algorithms, despite MTM being a generic self-supervised learning method without any explicit RL components. Code is available at https://github.com/facebookresearch/mtm
A Strong and Reproducible Object Detector with Only Public Datasets
Apr 25, 2023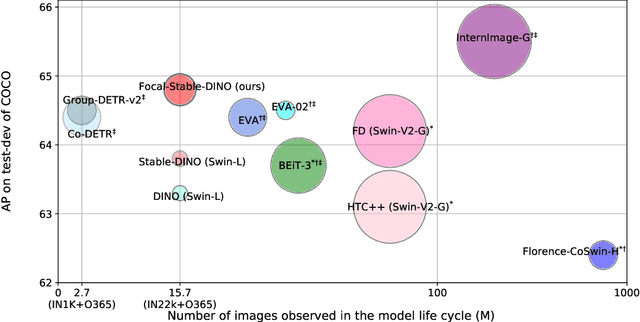

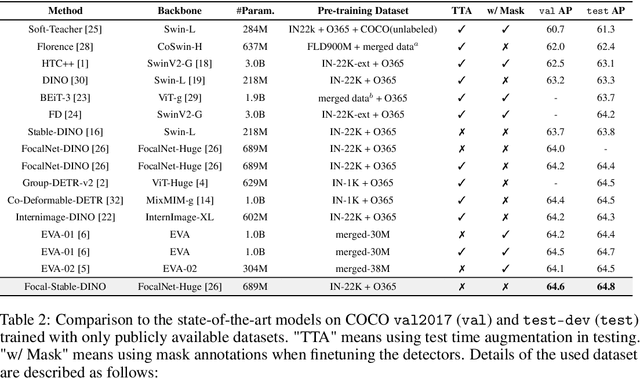
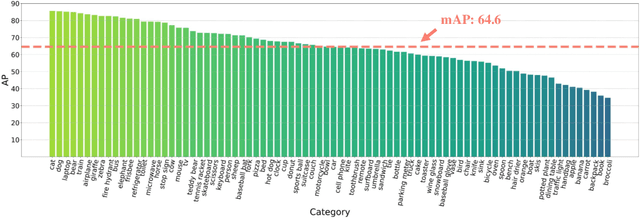
This work presents Focal-Stable-DINO, a strong and reproducible object detection model which achieves 64.6 AP on COCO val2017 and 64.8 AP on COCO test-dev using only 700M parameters without any test time augmentation. It explores the combination of the powerful FocalNet-Huge backbone with the effective Stable-DINO detector. Different from existing SOTA models that utilize an extensive number of parameters and complex training techniques on large-scale private data or merged data, our model is exclusively trained on the publicly available dataset Objects365, which ensures the reproducibility of our approach.
Once and for All: Scheduling Multiple Users Using Statistical CSI under Fixed Wireless Access
Apr 27, 2023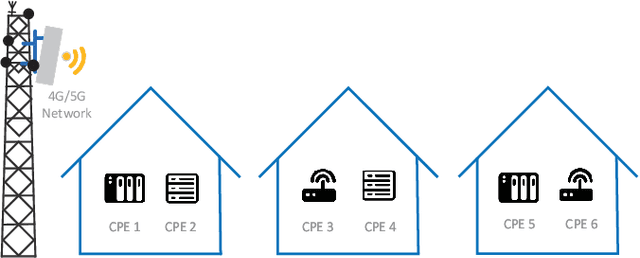
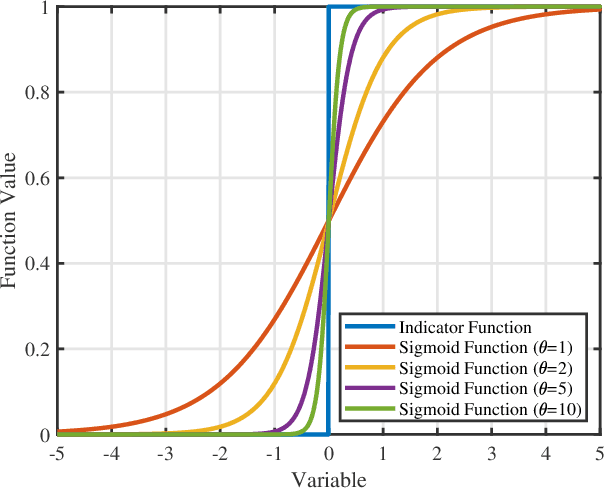
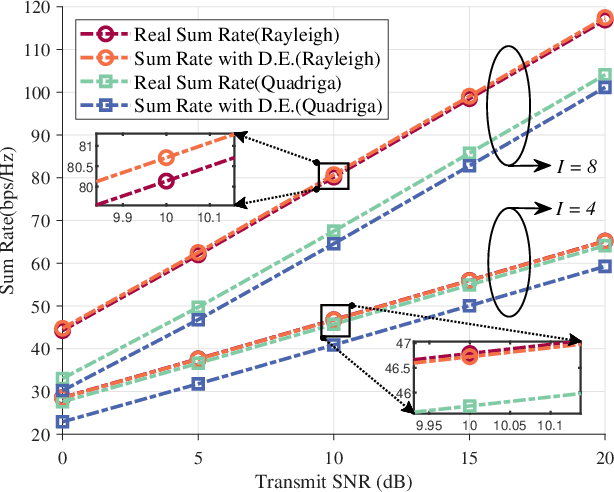
Conventional multi-user scheduling schemes are designed based on instantaneous channel state information (CSI), indicating that decisions must be made every transmission time interval (TTI) which lasts at most several milliseconds. Only quite simple approaches can be exploited under this stringent time constraint, resulting in less than satisfactory scheduling performance. In this paper, we investigate the scheduling problem of a fixed wireless access (FWA) network using only statistical CSI. Thanks to their fixed positions, user terminals in FWA can easily provide reliable large-scale CSI lasting tens or even hundreds of TTIs. Inspired by this appealing fact, we propose an \emph{`once-and-for-all'} scheduling approach, i.e. given multiple TTIs sharing identical statistical CSI, only a single high-quality scheduling decision lasting across all TTIs shall be taken rather than repeatedly making low-quality decisions every TTI. The proposed scheduling design is essentially a mixed-integer non-smooth non-convex stochastic problem with the objective of maximizing the weighted sum rate as well as the number of active users. We firstly replace the indicator functions in the considered problem by well-chosen sigmoid functions to tackle the non-smoothness. Via leveraging deterministic equivalent technique, we then convert the original stochastic problem into an approximated deterministic one, followed by linear relaxation of the integer constraints. However, the converted problem is still highly non-convex due to implicit equation constraints introduced by deterministic equivalent. To address this issue, we employ implicit optimization technique so that the gradient can be derived explicitly, with which we propose an algorithm design based on accelerated Frank-Wolfe method. Numerical results verify the effectiveness of our proposed scheduling scheme over state-of-the-art.
Dropout Injection at Test Time for Post Hoc Uncertainty Quantification in Neural Networks
Feb 06, 2023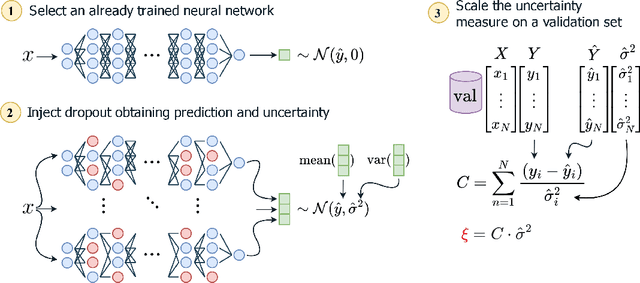
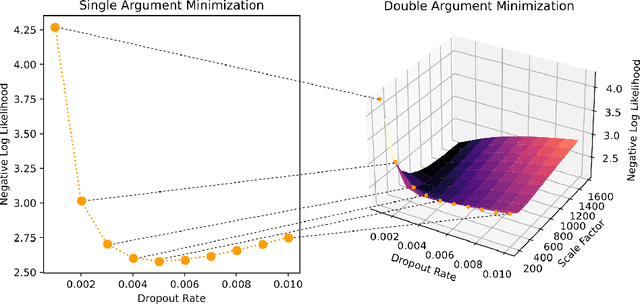
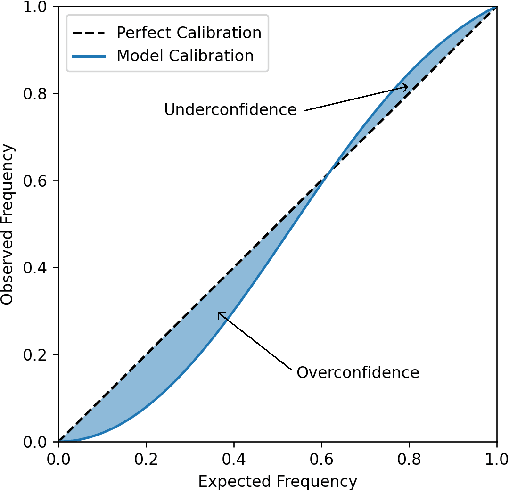
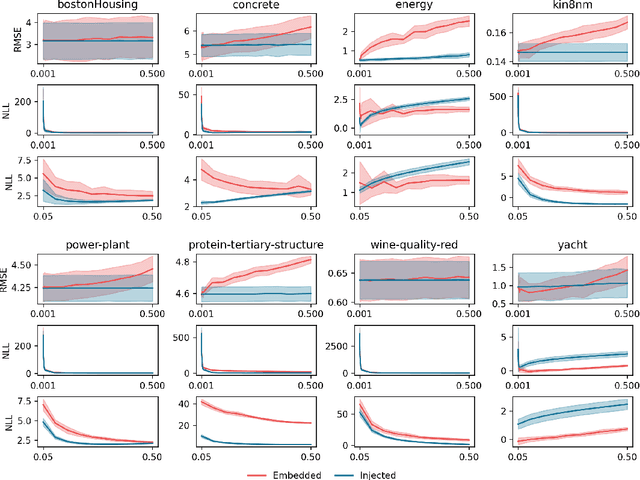
Among Bayesian methods, Monte-Carlo dropout provides principled tools for evaluating the epistemic uncertainty of neural networks. Its popularity recently led to seminal works that proposed activating the dropout layers only during inference for evaluating uncertainty. This approach, which we call dropout injection, provides clear benefits over its traditional counterpart (which we call embedded dropout) since it allows one to obtain a post hoc uncertainty measure for any existing network previously trained without dropout, avoiding an additional, time-consuming training process. Unfortunately, no previous work compared injected and embedded dropout; therefore, we provide the first thorough investigation, focusing on regression problems. The main contribution of our work is to provide guidelines on the effective use of injected dropout so that it can be a practical alternative to the current use of embedded dropout. In particular, we show that its effectiveness strongly relies on a suitable scaling of the corresponding uncertainty measure, and we discuss the trade-off between negative log-likelihood and calibration error as a function of the scale factor. Experimental results on UCI data sets and crowd counting benchmarks support our claim that dropout injection can effectively behave as a competitive post hoc uncertainty quantification technique.
A comparative study of statistical and machine learning models on near-real-time daily emissions prediction
Feb 02, 2023
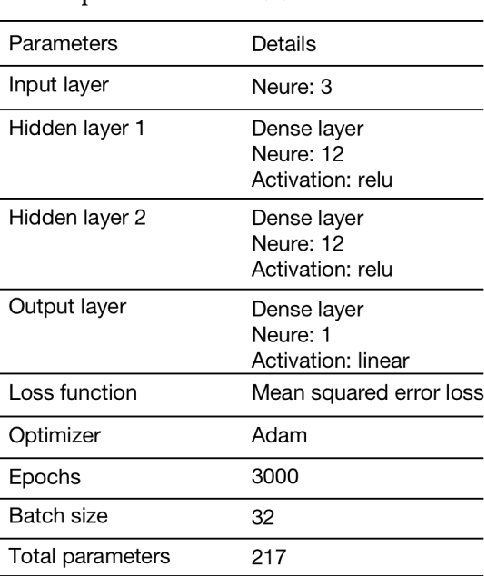
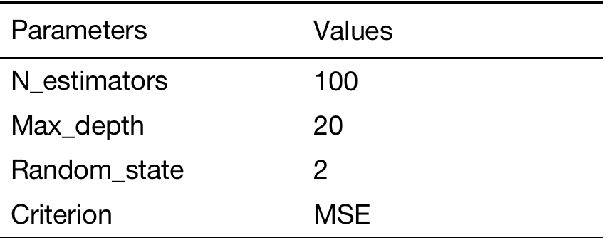
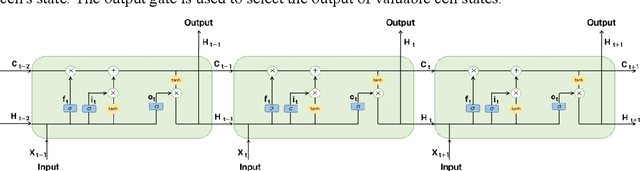
The rapid ascent in carbon dioxide emissions is a major cause of global warming and climate change, which pose a huge threat to human survival and impose far-reaching influence on the global ecosystem. Therefore, it is very necessary to effectively control carbon dioxide emissions by accurately predicting and analyzing the change trend timely, so as to provide a reference for carbon dioxide emissions mitigation measures. This paper is aiming to select a suitable model to predict the near-real-time daily emissions based on univariate daily time-series data from January 1st, 2020 to September 30st, 2022 of all sectors (Power, Industry, Ground Transport, Residential, Domestic Aviation, International Aviation) in China. We proposed six prediction models, which including three statistical models: Grey prediction (GM(1,1)), autoregressive integrated moving average (ARIMA) and seasonal autoregressive integrated moving average with exogenous factors (SARIMAX); three machine learning models: artificial neural network (ANN), random forest (RF) and long short term memory (LSTM). To evaluate the performance of these models, five criteria: Mean Squared Error (MSE), Root Mean Squared Error (RMSE), Mean Absolute Error (MAE), Mean Absolute Percentage Error (MAPE) and Coefficient of Determination () are imported and discussed in detail. In the results, three machine learning models perform better than that three statistical models, in which LSTM model performs the best on five criteria values for daily emissions prediction with the 3.5179e-04 MSE value, 0.0187 RMSE value, 0.0140 MAE value, 14.8291% MAPE value and 0.9844 value.
Preference Inference from Demonstration in Multi-objective Multi-agent Decision Making
Apr 27, 2023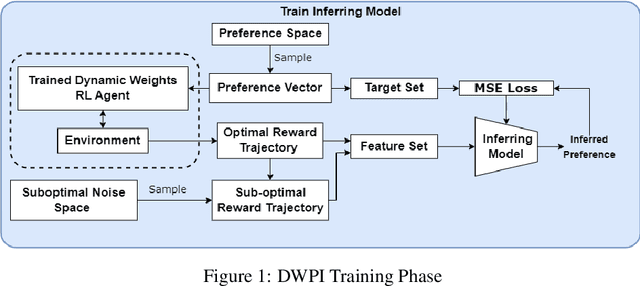
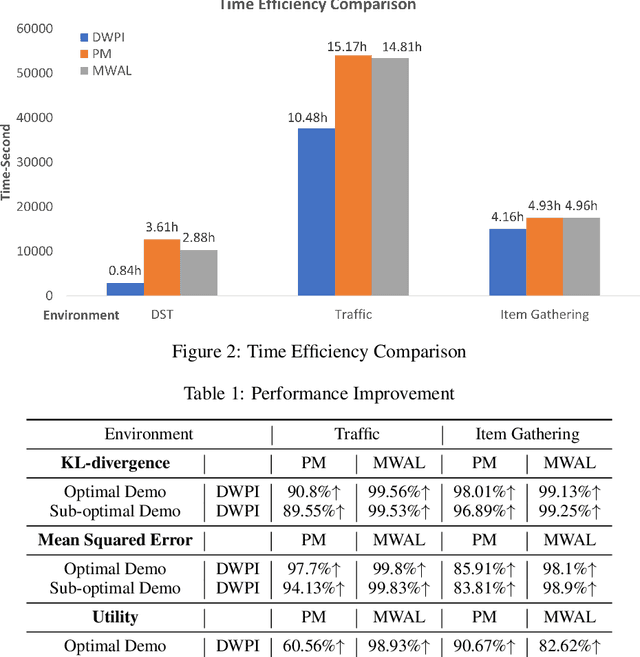
It is challenging to quantify numerical preferences for different objectives in a multi-objective decision-making problem. However, the demonstrations of a user are often accessible. We propose an algorithm to infer linear preference weights from either optimal or near-optimal demonstrations. The algorithm is evaluated in three environments with two baseline methods. Empirical results demonstrate significant improvements compared to the baseline algorithms, in terms of both time requirements and accuracy of the inferred preferences. In future work, we plan to evaluate the algorithm's effectiveness in a multi-agent system, where one of the agents is enabled to infer the preferences of an opponent using our preference inference algorithm.
Finding Front-Door Adjustment Sets in Linear Time
Nov 29, 2022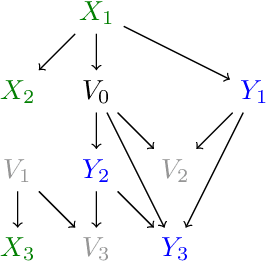
Front-door adjustment is a classic technique to estimate causal effects from a specified directed acyclic graph (DAG) and observed data. The advantage of this approach is that it uses observed mediators to identify causal effects, which is possible even in the presence of unobserved confounding. While the statistical properties of the front-door estimation are quite well understood, its algorithmic aspects remained unexplored for a long time. Recently, Jeong, Tian, and Barenboim [NeurIPS 2022] have presented the first polynomial-time algorithm for finding sets satisfying the front-door criterion in a given DAG, with an $O(n^3(n+m))$ run time, where $n$ denotes the number of variables and $m$ the number of edges of the graph. In our work, we give the first linear-time, i.e. $O(n+m)$, algorithm for this task, which thus reaches the asymptotically optimal time complexity, as the size of the input is $\Omega(n+m)$. We also provide an algorithm to enumerate all front-door adjustment sets in a given DAG with delay $O(n(n + m))$. These results improve the algorithms by Jeong et al. [2022] for the two tasks by a factor of $n^3$, respectively.
EVM-CNN: Real-Time Contactless Heart Rate Estimation from Facial Video
Dec 25, 2022
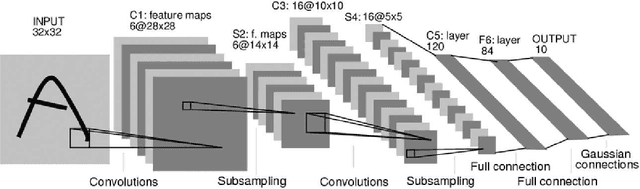
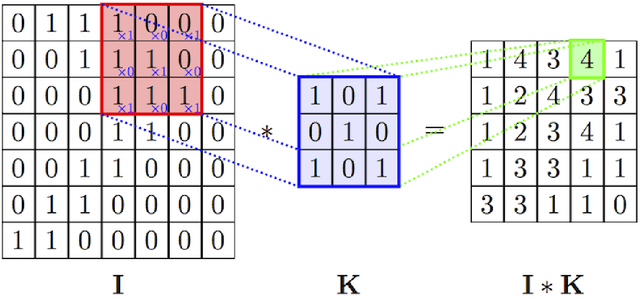
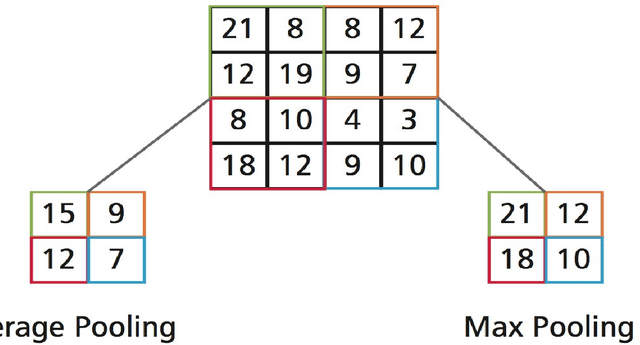
With the increase in health consciousness, noninvasive body monitoring has aroused interest among researchers. As one of the most important pieces of physiological information, researchers have remotely estimated the heart rate (HR) from facial videos in recent years. Although progress has been made over the past few years, there are still some limitations, like the processing time increasing with accuracy and the lack of comprehensive and challenging datasets for use and comparison. Recently, it was shown that HR information can be extracted from facial videos by spatial decomposition and temporal filtering. Inspired by this, a new framework is introduced in this paper to remotely estimate the HR under realistic conditions by combining spatial and temporal filtering and a convolutional neural network. Our proposed approach shows better performance compared with the benchmark on the MMSE-HR dataset in terms of both the average HR estimation and short-time HR estimation. High consistency in short-time HR estimation is observed between our method and the ground truth.