 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Uniform Sequence Better: Time Interval Aware Data Augmentation for Sequential Recommendation
Dec 16, 2022
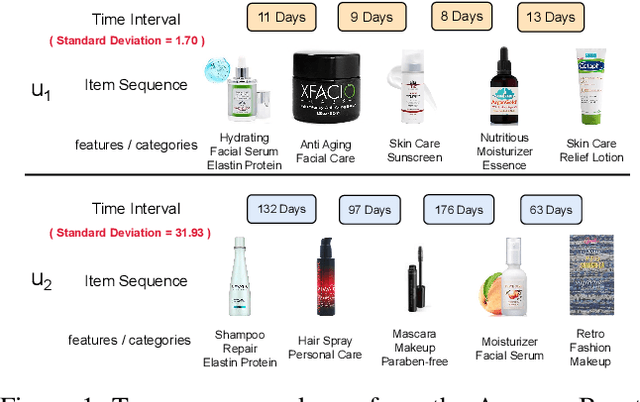
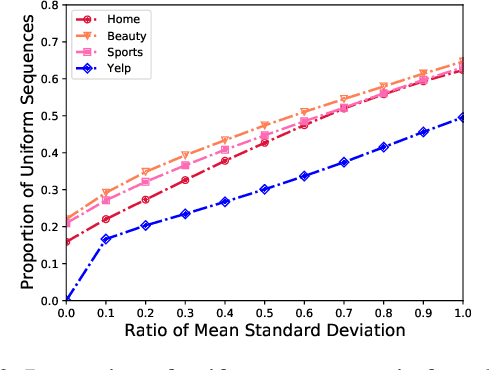
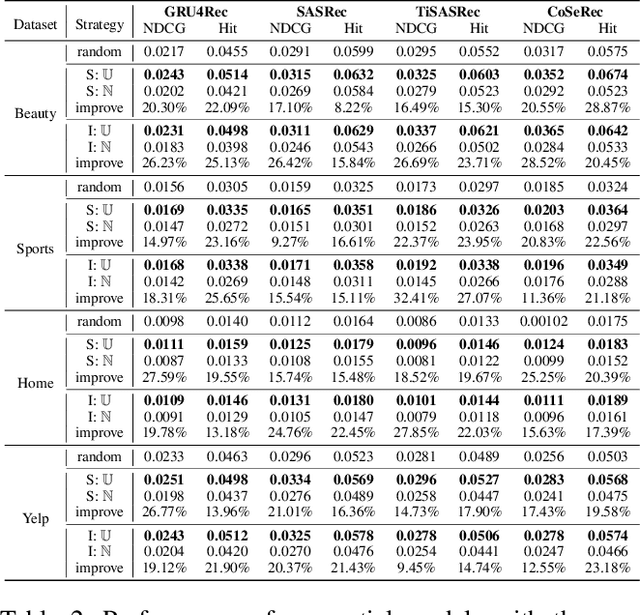
Sequential recommendation is an important task to predict the next-item to access based on a sequence of interacted items. Most existing works learn user preference as the transition pattern from the previous item to the next one, ignoring the time interval between these two items. However, we observe that the time interval in a sequence may vary significantly different, and thus result in the ineffectiveness of user modeling due to the issue of \emph{preference drift}. In fact, we conducted an empirical study to validate this observation, and found that a sequence with uniformly distributed time interval (denoted as uniform sequence) is more beneficial for performance improvement than that with greatly varying time interval. Therefore, we propose to augment sequence data from the perspective of time interval, which is not studied in the literature. Specifically, we design five operators (Ti-Crop, Ti-Reorder, Ti-Mask, Ti-Substitute, Ti-Insert) to transform the original non-uniform sequence to uniform sequence with the consideration of variance of time intervals. Then, we devise a control strategy to execute data augmentation on item sequences in different lengths. Finally, we implement these improvements on a state-of-the-art model CoSeRec and validate our approach on four real datasets. The experimental results show that our approach reaches significantly better performance than the other 11 competing methods. Our implementation is available: https://github.com/KingGugu/TiCoSeRec.
Fast Neural Scene Flow
Apr 20, 2023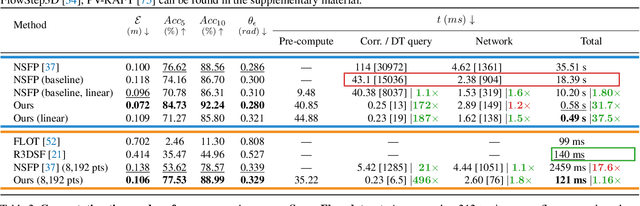

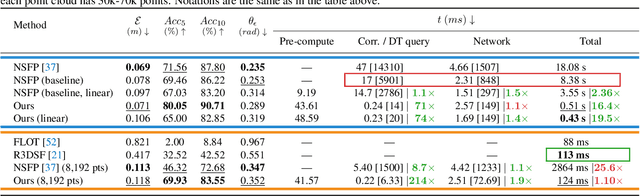
Neural Scene Flow Prior (NSFP) is of significant interest to the vision community due to its inherent robustness to out-of-distribution (OOD) effects and its ability to deal with dense lidar points. The approach utilizes a coordinate neural network to estimate scene flow at runtime, without any training. However, it is up to 100 times slower than current state-of-the-art learning methods. In other applications such as image, video, and radiance function reconstruction innovations in speeding up the runtime performance of coordinate networks have centered upon architectural changes. In this paper, we demonstrate that scene flow is different -- with the dominant computational bottleneck stemming from the loss function itself (i.e., Chamfer distance). Further, we rediscover the distance transform (DT) as an efficient, correspondence-free loss function that dramatically speeds up the runtime optimization. Our fast neural scene flow (FNSF) approach reports for the first time real-time performance comparable to learning methods, without any training or OOD bias on two of the largest open autonomous driving (AV) lidar datasets Waymo Open and Argoverse.
IOT based Smart Helmet for Hazard Detection in mining industry
Apr 20, 2023One of the most important parts of business, especially in the coal mining sector, is industrial safety. Suffocation, gas poisoning, object falls, roof collapses, and gas explosions are among the risks associated with underground mining. Therefore, air quality and the detection of hazardous events are crucial in the mining business. This technology offers a wireless sensor network so that base stations can keep an eye on the situation in underground mines in real time. It offers temperature and dangerous gases including CO, CH4, and LPG real-time monitoring. The main cause of mining deaths is that when they fall and lose consciousness for whatever reason, medical attention is not given to them in a timely manner. In order to solve this issue, the system sends an emergency notice to the supervisor in the event that a person falls down for any cause. Some employees are negligent when it comes to safety and don't wear helmets. Then, a miner's helmet removal status was successfully determined using a Limit switch.
The Dataset Multiplicity Problem: How Unreliable Data Impacts Predictions
Apr 20, 2023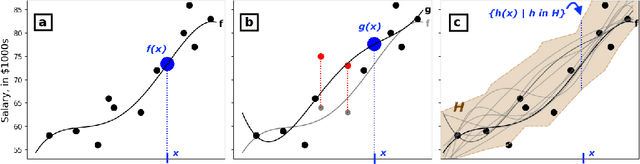

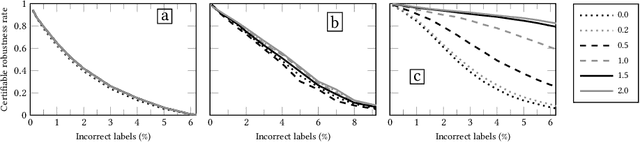
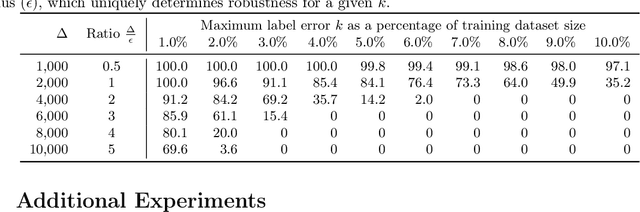
We introduce dataset multiplicity, a way to study how inaccuracies, uncertainty, and social bias in training datasets impact test-time predictions. The dataset multiplicity framework asks a counterfactual question of what the set of resultant models (and associated test-time predictions) would be if we could somehow access all hypothetical, unbiased versions of the dataset. We discuss how to use this framework to encapsulate various sources of uncertainty in datasets' factualness, including systemic social bias, data collection practices, and noisy labels or features. We show how to exactly analyze the impacts of dataset multiplicity for a specific model architecture and type of uncertainty: linear models with label errors. Our empirical analysis shows that real-world datasets, under reasonable assumptions, contain many test samples whose predictions are affected by dataset multiplicity. Furthermore, the choice of domain-specific dataset multiplicity definition determines what samples are affected, and whether different demographic groups are disparately impacted. Finally, we discuss implications of dataset multiplicity for machine learning practice and research, including considerations for when model outcomes should not be trusted.
Time Governors for Safe Path-Following Control
Dec 02, 2022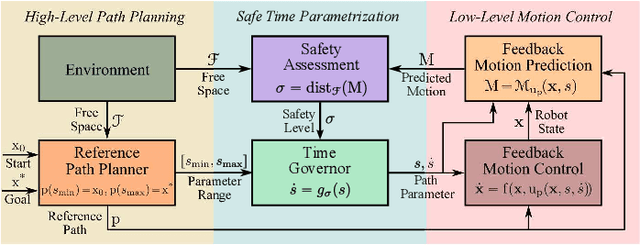
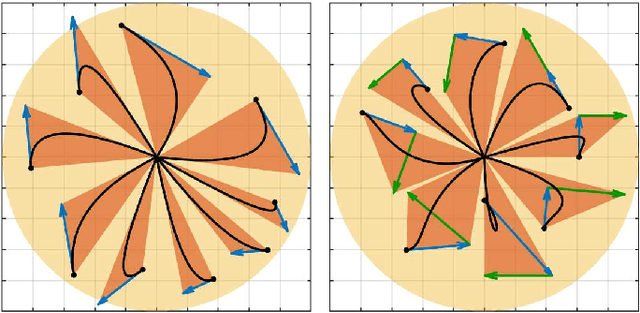
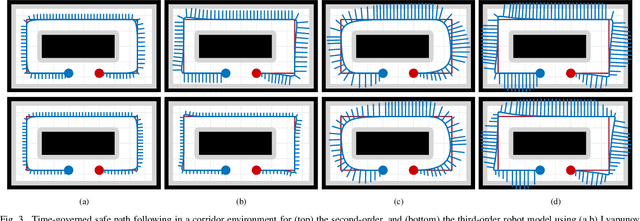
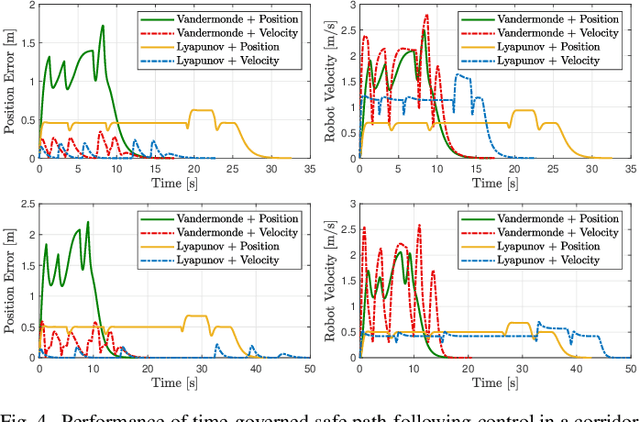
Safe and smooth robot motion around obstacles is an essential skill for autonomous robots, especially when operating around people and other robots. Conventionally, due to real-time operation requirements and onboard computation limitations, many robot motion planning and control methods follow a two-step approach: first construct a (e.g., piecewise linear) collision-free reference path for a simplified robot model, and then execute the reference plan via path-following control for a more accurate and complex robot model. A challenge of such a decoupled robot motion planning and control method for highly dynamic robotic systems is ensuring the safety of path-following control as well as the successful completion of the reference plan. In this paper, we introduce a novel dynamical systems approach for online closed-loop time parametrization, called $\textit{a time governor}$, of a reference path for provably correct and safe path-following control based on feedback motion prediction, where the safety of robot motion under path-following control is continuously monitored using predicted robot motion. After introducing the general framework of time governors for safe path following, we present an example application for the fully actuated high-order robot dynamics using proportional-and-higher-order-derivative (PhD) path-following control whose feedback motion prediction is performed by Lyapunov ellipsoids and Vandemonde simplexes. In numerical simulations, we investigate the role of reference position and velocity feedback, and motion prediction on path-following performance and robot motion.
Online Spatio-Temporal Learning with Target Projection
Apr 11, 2023
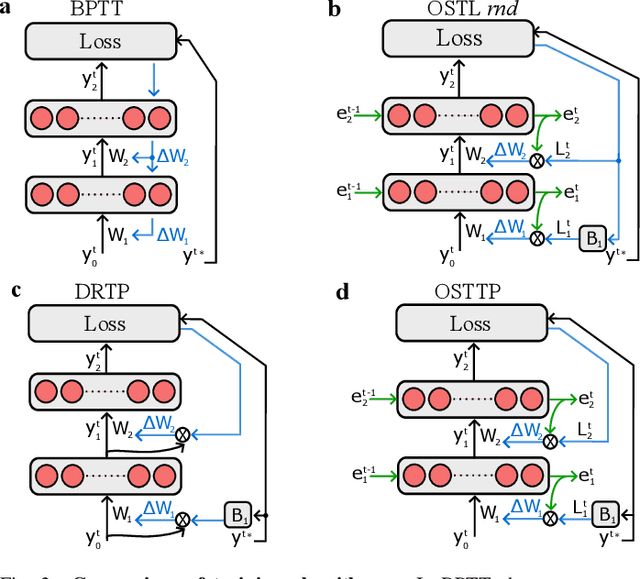
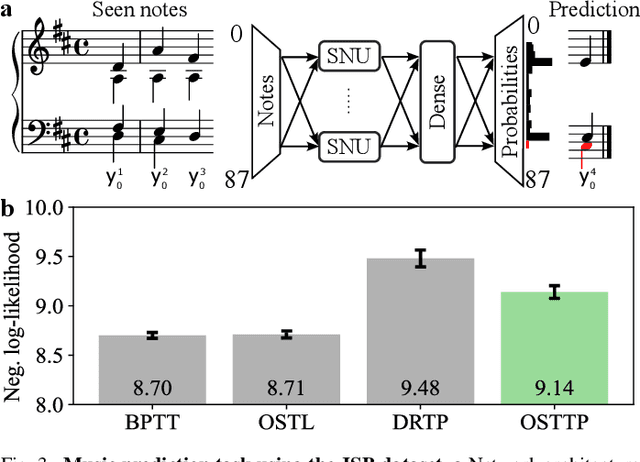
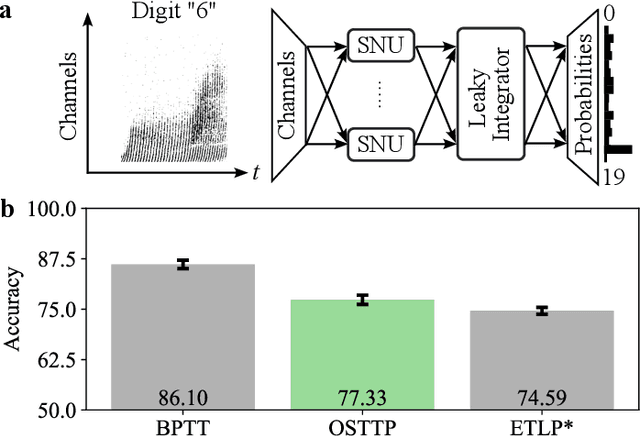
Recurrent neural networks trained with the backpropagation through time (BPTT) algorithm have led to astounding successes in various temporal tasks. However, BPTT introduces severe limitations, such as the requirement to propagate information backwards through time, the weight symmetry requirement, as well as update-locking in space and time. These problems become roadblocks for AI systems where online training capabilities are vital. Recently, researchers have developed biologically-inspired training algorithms, addressing a subset of those problems. In this work, we propose a novel learning algorithm called online spatio-temporal learning with target projection (OSTTP) that resolves all aforementioned issues of BPTT. In particular, OSTTP equips a network with the capability to simultaneously process and learn from new incoming data, alleviating the weight symmetry and update-locking problems. We evaluate OSTTP on two temporal tasks, showcasing competitive performance compared to BPTT. Moreover, we present a proof-of-concept implementation of OSTTP on a memristive neuromorphic hardware system, demonstrating its versatility and applicability to resource-constrained AI devices.
CGI-Stereo: Accurate and Real-Time Stereo Matching via Context and Geometry Interaction
Jan 07, 2023
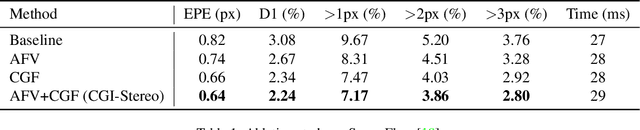
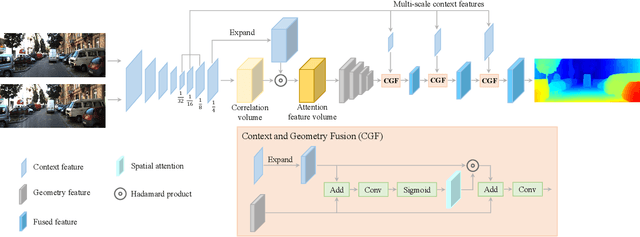
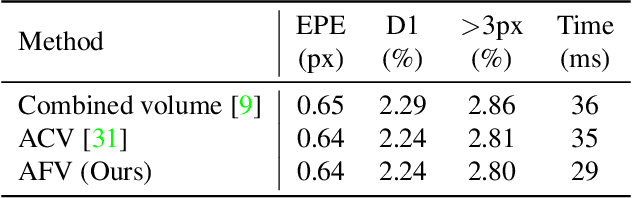
In this paper, we propose CGI-Stereo, a novel neural network architecture that can concurrently achieve real-time performance, state-of-the-art accuracy, and strong generalization ability. The core of our CGI-Stereo is a Context and Geometry Fusion (CGF) block which adaptively fuses context and geometry information for more accurate and efficient cost aggregation and meanwhile provides feedback to feature learning to guide more effective contextual feature extraction. The proposed CGF can be easily embedded into many existing stereo matching networks, such as PSMNet, GwcNet and ACVNet. The resulting networks are improved in accuracy by a large margin. Specially, the model which integrates our CGF with ACVNet could rank 1st on the KITTI 2012 leaderboard among all the published methods. We further propose an informative and concise cost volume, named Attention Feature Volume (AFV), which exploits a correlation volume as attention weights to filter a feature volume. Based on CGF and AFV, the proposed CGI-Stereo outperforms all other published real-time methods on KITTI benchmarks and shows better generalization ability than other real-time methods. The code is available at https://github.com/gangweiX/CGI-Stereo.
SECRETS: Subject-Efficient Clinical Randomized Controlled Trials using Synthetic Intervention
May 08, 2023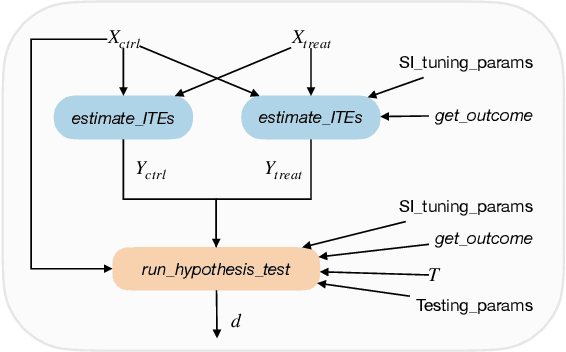


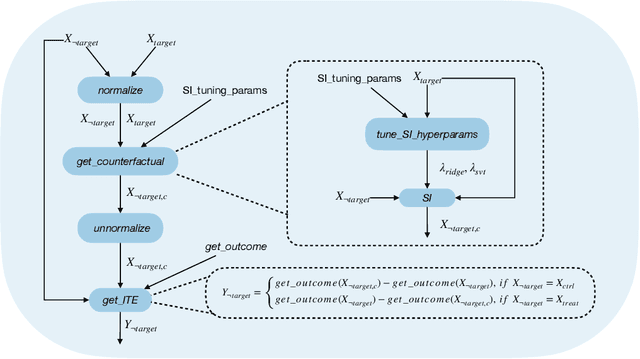
The randomized controlled trial (RCT) is the gold standard for estimating the average treatment effect (ATE) of a medical intervention but requires 100s-1000s of subjects, making it expensive and difficult to implement. While a cross-over trial can reduce sample size requirements by measuring the treatment effect per individual, it is only applicable to chronic conditions and interventions whose effects dissipate rapidly. Another approach is to replace or augment data collected from an RCT with external data from prospective studies or prior RCTs, but it is vulnerable to confounders in the external or augmented data. We propose to simulate the cross-over trial to overcome its practical limitations while exploiting its strengths. We propose a novel framework, SECRETS, which, for the first time, estimates the individual treatment effect (ITE) per patient in the RCT study without using any external data by leveraging a state-of-the-art counterfactual estimation algorithm, called synthetic intervention. It also uses a new hypothesis testing strategy to determine whether the treatment has a clinically significant ATE based on the estimated ITEs. We show that SECRETS can improve the power of an RCT while maintaining comparable significance levels; in particular, on three real-world clinical RCTs (Phase-3 trials), SECRETS increases power over the baseline method by $\boldsymbol{6}$-$\boldsymbol{54\%}$ (average: 21.5%, standard deviation: 15.8%).
KineticNet: Deep learning a transferable kinetic energy functional for orbital-free density functional theory
May 08, 2023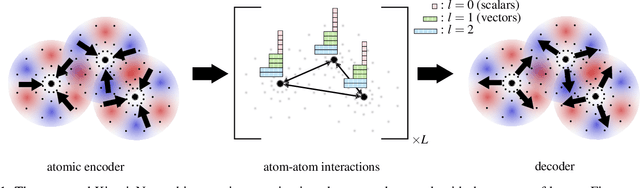
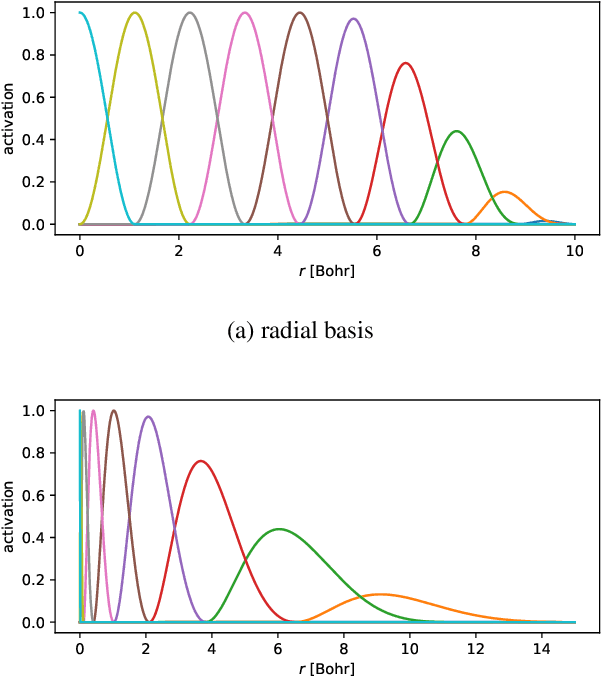
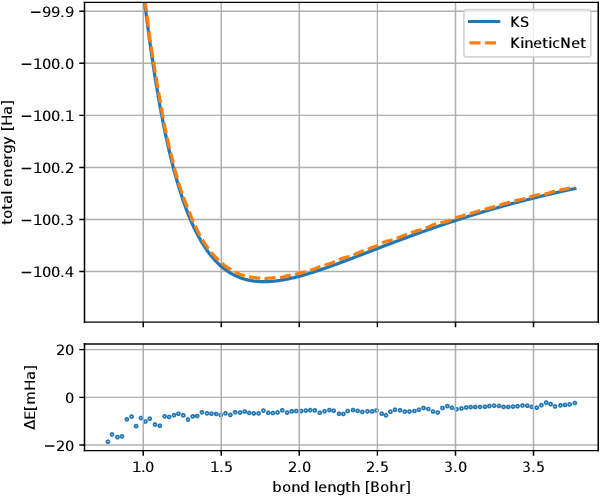
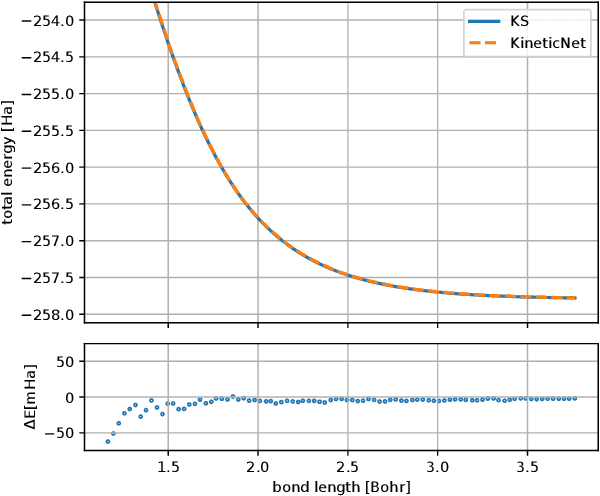
Orbital-free density functional theory (OF-DFT) holds the promise to compute ground state molecular properties at minimal cost. However, it has been held back by our inability to compute the kinetic energy as a functional of the electron density only. We here set out to learn the kinetic energy functional from ground truth provided by the more expensive Kohn-Sham density functional theory. Such learning is confronted with two key challenges: Giving the model sufficient expressivity and spatial context while limiting the memory footprint to afford computations on a GPU; and creating a sufficiently broad distribution of training data to enable iterative density optimization even when starting from a poor initial guess. In response, we introduce KineticNet, an equivariant deep neural network architecture based on point convolutions adapted to the prediction of quantities on molecular quadrature grids. Important contributions include convolution filters with sufficient spatial resolution in the vicinity of the nuclear cusp, an atom-centric sparse but expressive architecture that relays information across multiple bond lengths; and a new strategy to generate varied training data by finding ground state densities in the face of perturbations by a random external potential. KineticNet achieves, for the first time, chemical accuracy of the learned functionals across input densities and geometries of tiny molecules. For two electron systems, we additionally demonstrate OF-DFT density optimization with chemical accuracy.
Company classification using zero-shot learning
May 01, 2023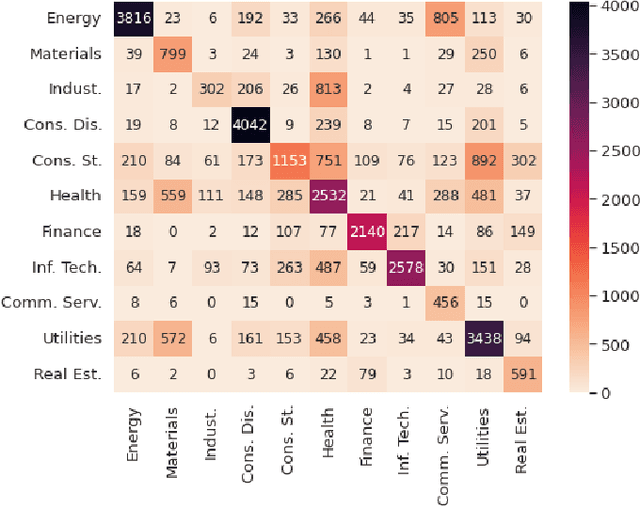
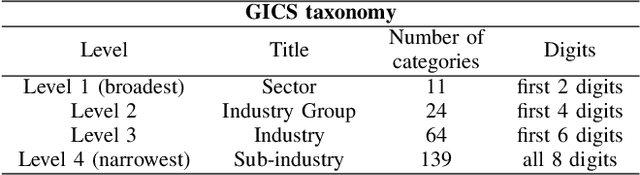
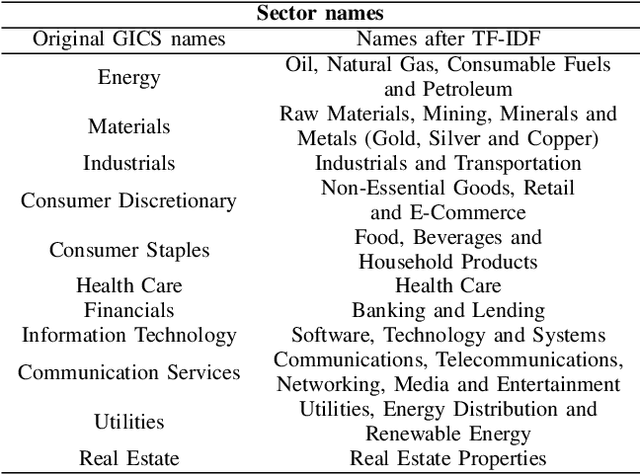
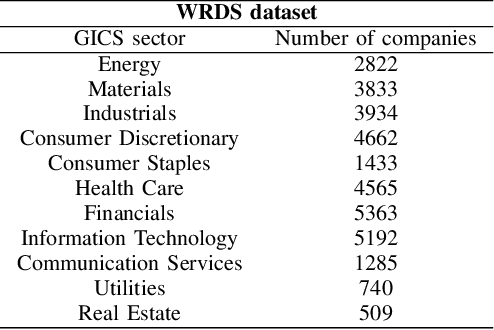
In recent years, natural language processing (NLP) has become increasingly important in a variety of business applications, including sentiment analysis, text classification, and named entity recognition. In this paper, we propose an approach for company classification using NLP and zero-shot learning. Our method utilizes pre-trained transformer models to extract features from company descriptions, and then applies zero-shot learning to classify companies into relevant categories without the need for specific training data for each category. We evaluate our approach on publicly available datasets of textual descriptions of companies, and demonstrate that it can streamline the process of company classification, thereby reducing the time and resources required in traditional approaches such as the Global Industry Classification Standard (GICS). The results show that this method has potential for automation of company classification, making it a promising avenue for future research in this area.