 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Direct Estimation of Pupil Parameters Using Deep Learning for Visible Light Pupillometry
May 10, 2023
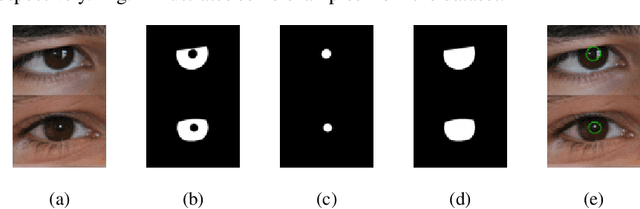

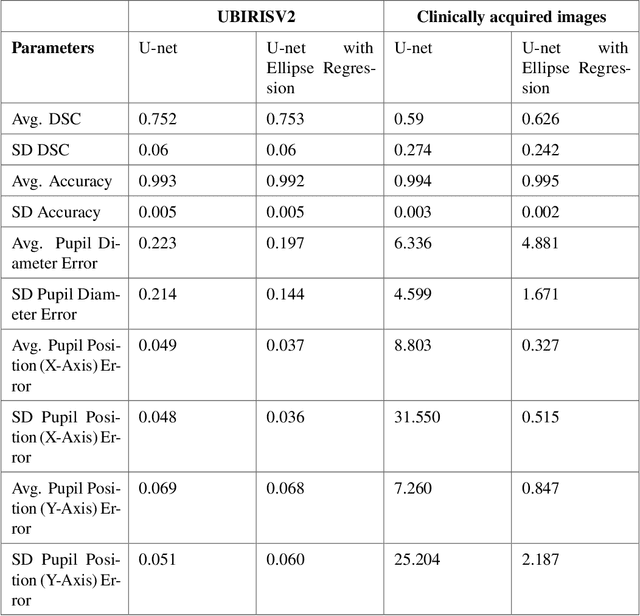
Pupil reflex to variations in illumination and associated dynamics are of importance in neurology and ophthalmology. This is typically measured using a near Infrared (IR) pupillometer to avoid Purkinje reflections that appear when strong Visible Light (VL) illumination is present. Previously we demonstrated the use of deep learning techniques to accurately detect the pupil pixels (segmentation mask) in case of VL images for performing VL pupillometry. Here, we present a method to obtain the parameters of the elliptical pupil boundary along with the segmentation mask is presented. This eliminates the need for an additional, computationally expensive post-processing step of ellipse fitting and also improves segmentation accuracy. Using the time-varying ellipse parameters of pupil, we can compute the dynamics of the Pupillary Light Reflex (PLR). We also present preliminary evaluations of our deep-learning algorithms on clinical data. This work is a significant push in our goal to develop and validate a VL pupillometer based on a smartphone that can be used in the field.
Causal Graph Discovery from Self and Mutually Exciting Time Series
Jan 27, 2023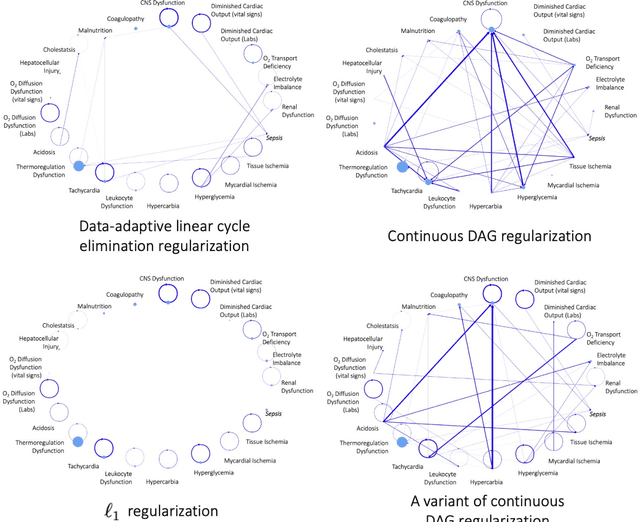
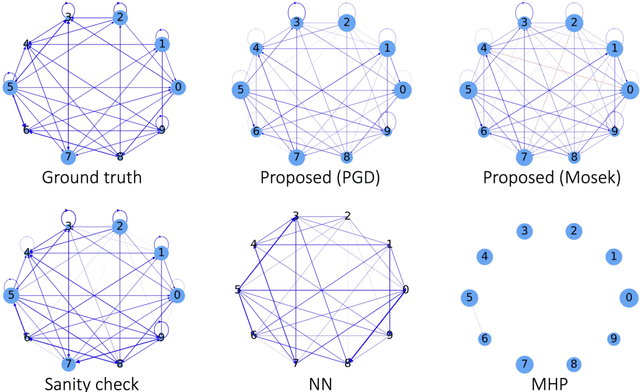

We present a generalized linear structural causal model, coupled with a novel data-adaptive linear regularization, to recover causal directed acyclic graphs (DAGs) from time series. By leveraging a recently developed stochastic monotone Variational Inequality (VI) formulation, we cast the causal discovery problem as a general convex optimization. Furthermore, we develop a non-asymptotic recovery guarantee and quantifiable uncertainty by solving a linear program to establish confidence intervals for a wide range of non-linear monotone link functions. We validate our theoretical results and show the competitive performance of our method via extensive numerical experiments. Most importantly, we demonstrate the effectiveness of our approach in recovering highly interpretable causal DAGs over Sepsis Associated Derangements (SADs) while achieving comparable prediction performance to powerful ``black-box'' models such as XGBoost. Thus, the future adoption of our proposed method to conduct continuous surveillance of high-risk patients by clinicians is much more likely.
Path Planning for Air-Ground Robot Considering Modal Switching Point Optimization
May 14, 2023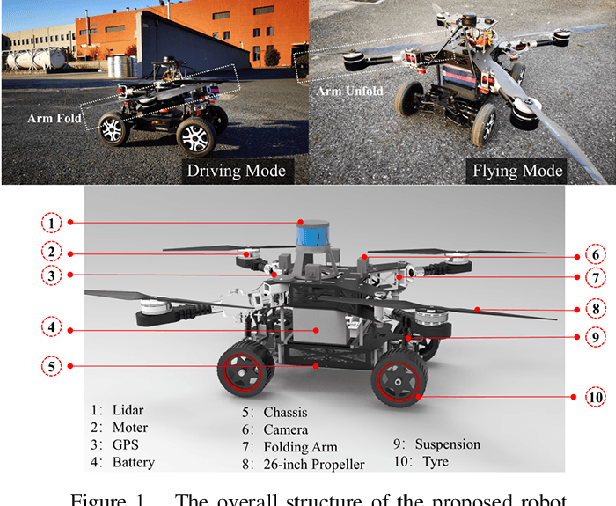
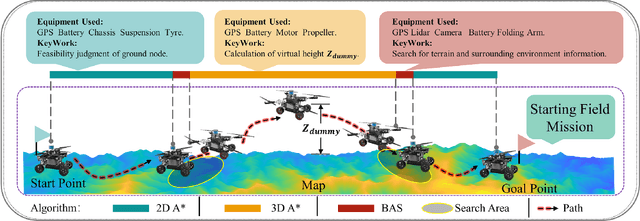
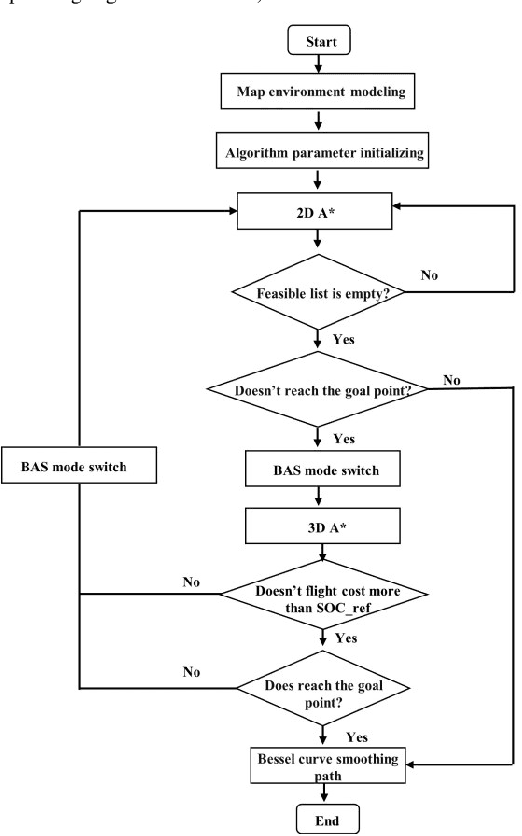
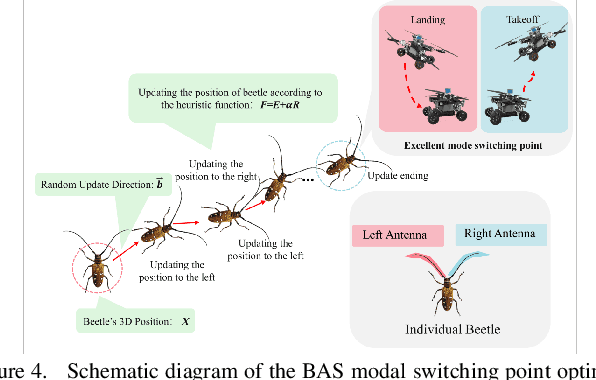
An innovative sort of mobility platform that can both drive and fly is the air-ground robot. The need for an agile flight cannot be satisfied by traditional path planning techniques for air-ground robots. Prior studies had mostly focused on improving the energy efficiency of paths, seldom taking the seeking speed and optimizing take-off and landing places into account. A robot for the field application environment was proposed, and a lightweight global spatial planning technique for the robot based on the graph-search algorithm taking mode switching point optimization into account, with an emphasis on energy efficiency, searching speed, and the viability of real deployment. The fundamental concept is to lower the computational burden by employing an interchangeable search approach that combines planar and spatial search. Furthermore, to safeguard the health of the power battery and the integrity of the mission execution, a trap escape approach was also provided. Simulations are run to test the effectiveness of the suggested model based on the field DEM map. The simulation results show that our technology is capable of producing finished, plausible 3D paths with a high degree of believability. Additionally, the mode-switching point optimization method efficiently identifies additional acceptable places for mode switching, and the improved paths use less time and energy.
Temporal Convolution Network Based Onset Detection and Query by Humming System Design
May 09, 2023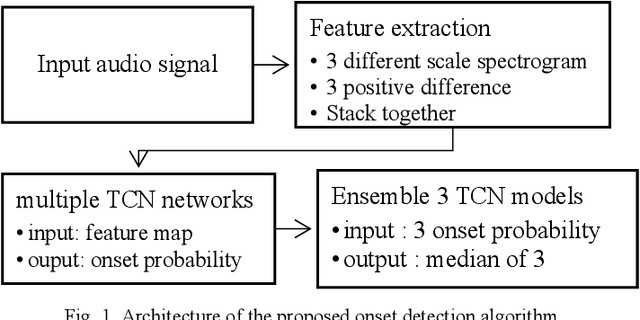
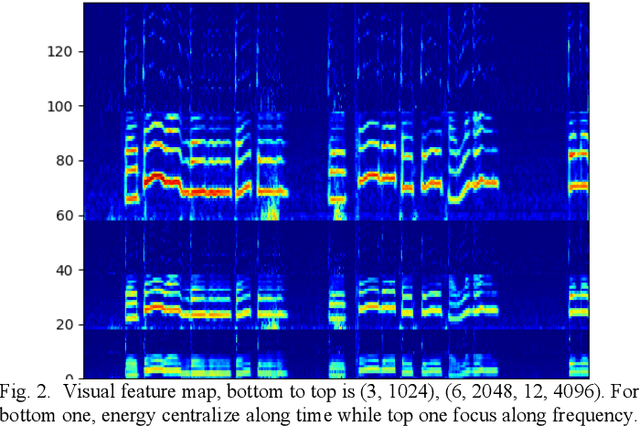
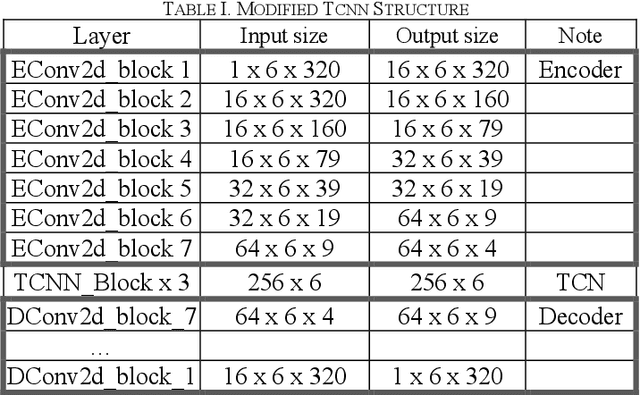
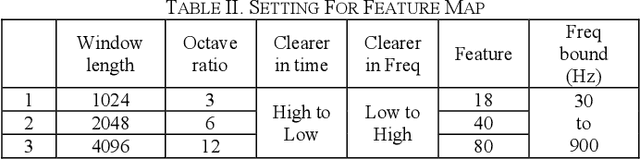
Onsets are a key factor to split audio into several notes. In this paper, we ensemble multiple temporal convolution network (TCN) based model and utilize a restricted frequency range spectrogram to achieve more robust onset detection. Different from the present onset detection of QBH system which is only available in a clean scenario, our proposal of onset detection and speech enhancement can prevent noise from affecting onset detection function (ODF). Compared to the CNN model which exploits spatial features of the spectrogram, the TCN model exploits both spatial and temporal features of the spectrogram. As the usage of QBH in noisy scenarios, we apply the TCN-based speech enhancement as a preprocessor of QBH. With the combinations of TCN-based speech enhancement and onset detection, simulations show that the proposal can enable the QBH system in both noisy and clean circumstances with short response time.
PLM-GNN: A Webpage Classification Method based on Joint Pre-trained Language Model and Graph Neural Network
May 09, 2023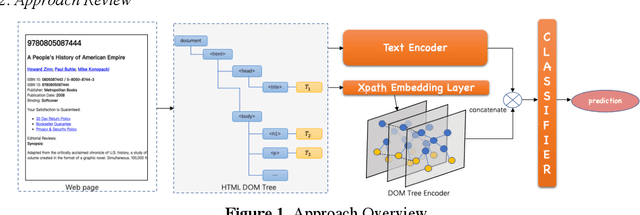

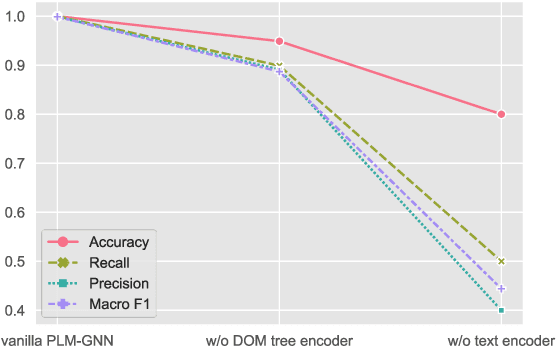
The number of web pages is growing at an exponential rate, accumulating massive amounts of data on the web. It is one of the key processes to classify webpages in web information mining. Some classical methods are based on manually building features of web pages and training classifiers based on machine learning or deep learning. However, building features manually requires specific domain knowledge and usually takes a long time to validate the validity of features. Considering webpages generated by the combination of text and HTML Document Object Model(DOM) trees, we propose a representation and classification method based on a pre-trained language model and graph neural network, named PLM-GNN. It is based on the joint encoding of text and HTML DOM trees in the web pages. It performs well on the KI-04 and SWDE datasets and on practical dataset AHS for the project of scholar's homepage crawling.
Efficient Robot Skill Learning with Imitation from a Single Video for Contact-Rich Fabric Manipulation
Apr 24, 2023
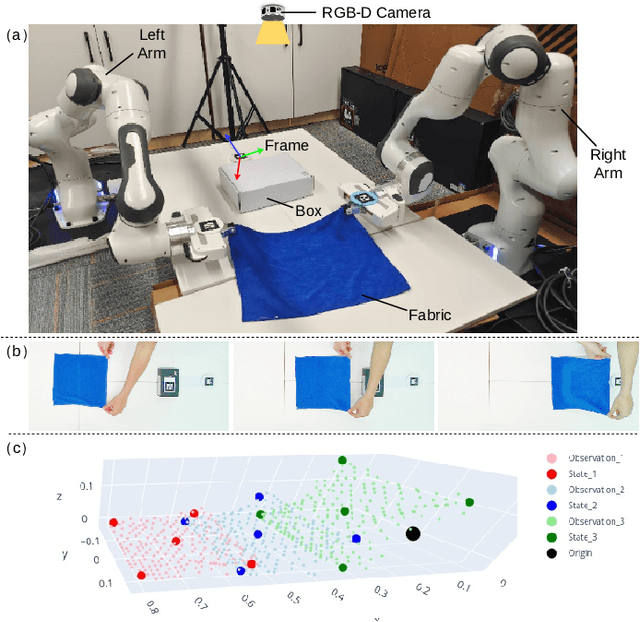


Classical policy search algorithms for robotics typically require performing extensive explorations, which are time-consuming and expensive to implement with real physical platforms. To facilitate the efficient learning of robot manipulation skills, in this work, we propose a new approach comprised of three modules: (1) learning of general prior knowledge with random explorations in simulation, including state representations, dynamic models, and the constrained action space of the task; (2) extraction of a state alignment-based reward function from a single demonstration video; (3) real-time optimization of the imitation policy under systematic safety constraints with sampling-based model predictive control. This solution results in an efficient one-shot imitation-from-video strategy that simplifies the learning and execution of robot skills in real applications. Specifically, we learn priors in a scene of a task family and then deploy the policy in a novel scene immediately following a single demonstration, preventing time-consuming and risky explorations in the environment. As we do not make a strong assumption of dynamic consistency between the scenes, learning priors can be conducted in simulation to avoid collecting data in real-world circumstances. We evaluate the effectiveness of our approach in the context of contact-rich fabric manipulation, which is a common scenario in industrial and domestic tasks. Detailed numerical simulations and real-world hardware experiments reveal that our method can achieve rapid skill acquisition for challenging manipulation tasks.
Label-free timing analysis of modularized nuclear detectors with physics-constrained deep learning
Apr 24, 2023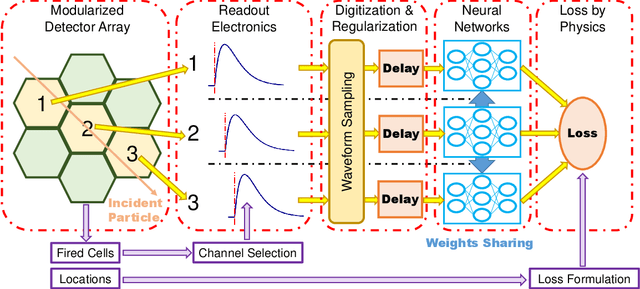
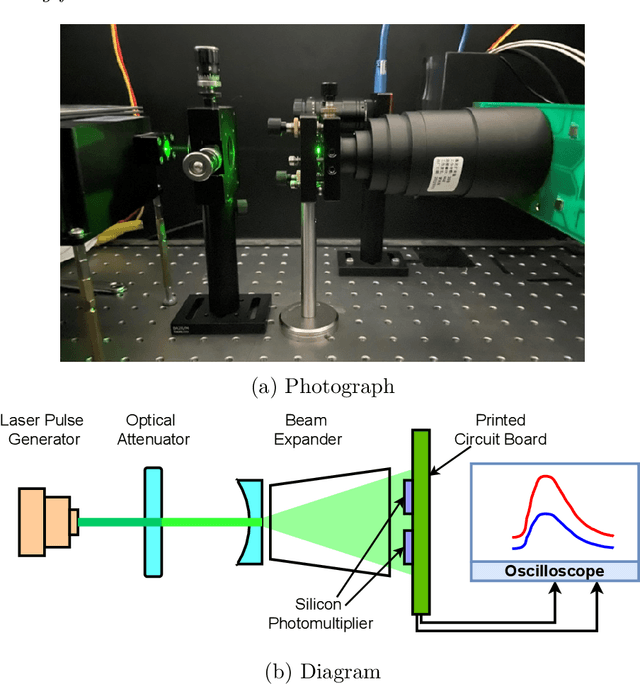
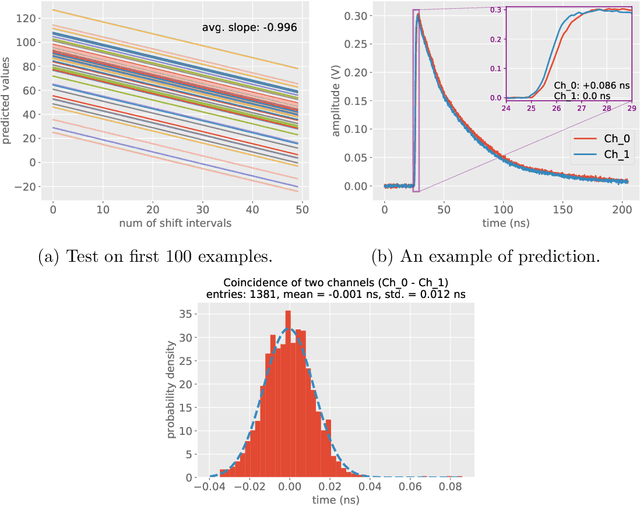
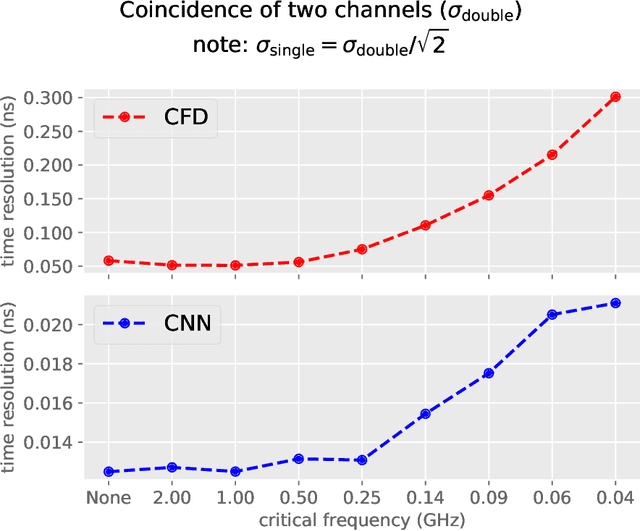
Pulse timing is an important topic in nuclear instrumentation, with far-reaching applications from high energy physics to radiation imaging. While high-speed analog-to-digital converters become more and more developed and accessible, their potential uses and merits in nuclear detector signal processing are still uncertain, partially due to associated timing algorithms which are not fully understood and utilized. In this paper, we propose a novel method based on deep learning for timing analysis of modularized nuclear detectors without explicit needs of labelling event data. By taking advantage of the inner time correlation of individual detectors, a label-free loss function with a specially designed regularizer is formed to supervise the training of neural networks towards a meaningful and accurate mapping function. We mathematically demonstrate the existence of the optimal function desired by the method, and give a systematic algorithm for training and calibration of the model. The proposed method is validated on two experimental datasets. In the toy experiment, the neural network model achieves the single-channel time resolution of 8.8 ps and exhibits robustness against concept drift in the dataset. In the electromagnetic calorimeter experiment, several neural network models (FC, CNN and LSTM) are tested to show their conformance to the underlying physical constraint and to judge their performance against traditional methods. In total, the proposed method works well in either ideal or noisy experimental condition and recovers the time information from waveform samples successfully and precisely.
Surgical-VQLA: Transformer with Gated Vision-Language Embedding for Visual Question Localized-Answering in Robotic Surgery
May 19, 2023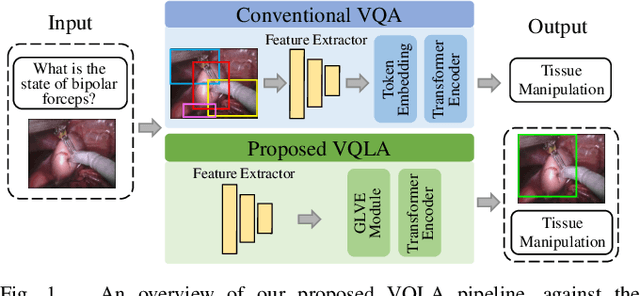
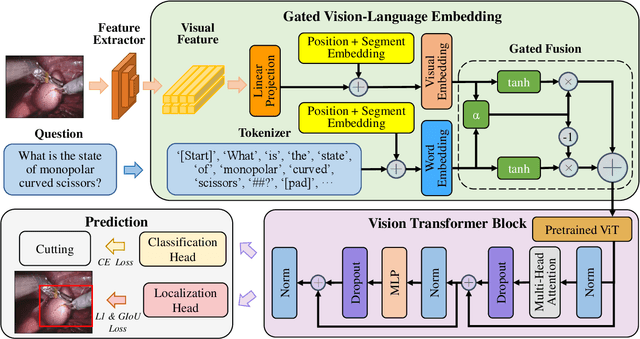
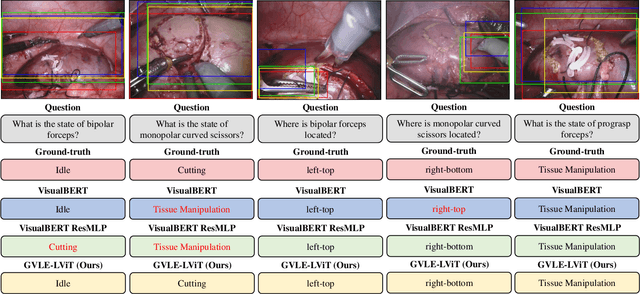
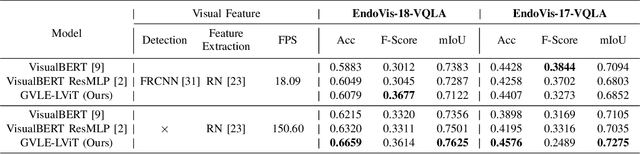
Despite the availability of computer-aided simulators and recorded videos of surgical procedures, junior residents still heavily rely on experts to answer their queries. However, expert surgeons are often overloaded with clinical and academic workloads and limit their time in answering. For this purpose, we develop a surgical question-answering system to facilitate robot-assisted surgical scene and activity understanding from recorded videos. Most of the existing VQA methods require an object detector and regions based feature extractor to extract visual features and fuse them with the embedded text of the question for answer generation. However, (1) surgical object detection model is scarce due to smaller datasets and lack of bounding box annotation; (2) current fusion strategy of heterogeneous modalities like text and image is naive; (3) the localized answering is missing, which is crucial in complex surgical scenarios. In this paper, we propose Visual Question Localized-Answering in Robotic Surgery (Surgical-VQLA) to localize the specific surgical area during the answer prediction. To deal with the fusion of the heterogeneous modalities, we design gated vision-language embedding (GVLE) to build input patches for the Language Vision Transformer (LViT) to predict the answer. To get localization, we add the detection head in parallel with the prediction head of the LViT. We also integrate GIoU loss to boost localization performance by preserving the accuracy of the question-answering model. We annotate two datasets of VQLA by utilizing publicly available surgical videos from MICCAI challenges EndoVis-17 and 18. Our validation results suggest that Surgical-VQLA can better understand the surgical scene and localize the specific area related to the question-answering. GVLE presents an efficient language-vision embedding technique by showing superior performance over the existing benchmarks.
AutoCoreset: An Automatic Practical Coreset Construction Framework
May 19, 2023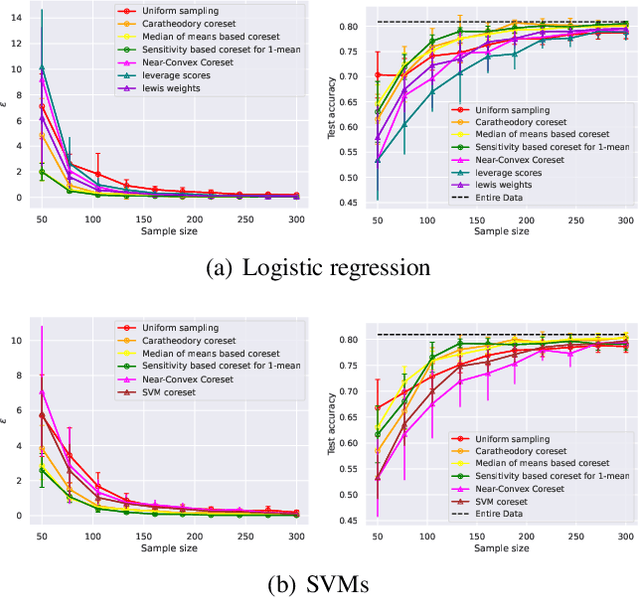
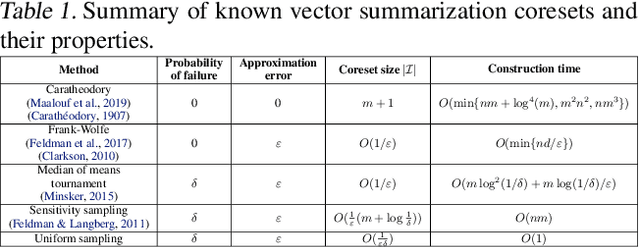
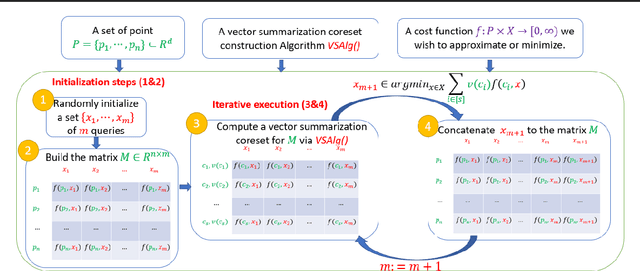

A coreset is a tiny weighted subset of an input set, that closely resembles the loss function, with respect to a certain set of queries. Coresets became prevalent in machine learning as they have shown to be advantageous for many applications. While coreset research is an active research area, unfortunately, coresets are constructed in a problem-dependent manner, where for each problem, a new coreset construction algorithm is usually suggested, a process that may take time or may be hard for new researchers in the field. Even the generic frameworks require additional (problem-dependent) computations or proofs to be done by the user. Besides, many problems do not have (provable) small coresets, limiting their applicability. To this end, we suggest an automatic practical framework for constructing coresets, which requires (only) the input data and the desired cost function from the user, without the need for any other task-related computation to be done by the user. To do so, we reduce the problem of approximating a loss function to an instance of vector summation approximation, where the vectors we aim to sum are loss vectors of a specific subset of the queries, such that we aim to approximate the image of the function on this subset. We show that while this set is limited, the coreset is quite general. An extensive experimental study on various machine learning applications is also conducted. Finally, we provide a ``plug and play" style implementation, proposing a user-friendly system that can be easily used to apply coresets for many problems. Full open source code can be found at \href{https://github.com/alaamaalouf/AutoCoreset}{\text{https://github.com/alaamaalouf/AutoCoreset}}. We believe that these contributions enable future research and easier use and applications of coresets.
Neural Speech Enhancement with Very Low Algorithmic Latency and Complexity via Integrated Full- and Sub-Band Modeling
Apr 18, 2023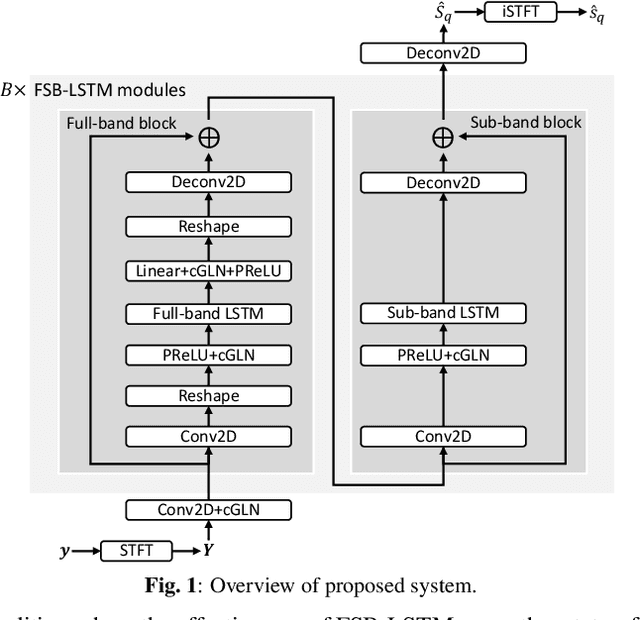

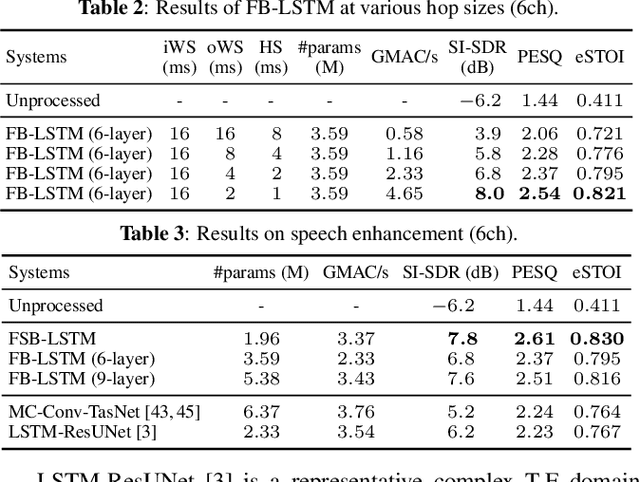
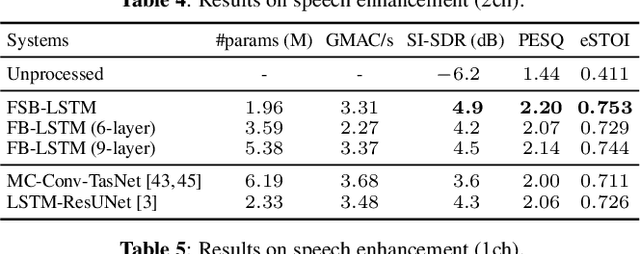
We propose FSB-LSTM, a novel long short-term memory (LSTM) based architecture that integrates full- and sub-band (FSB) modeling, for single- and multi-channel speech enhancement in the short-time Fourier transform (STFT) domain. The model maintains an information highway to flow an over-complete input representation through multiple FSB-LSTM modules. Each FSB-LSTM module consists of a full-band block to model spectro-temporal patterns at all frequencies and a sub-band block to model patterns within each sub-band, where each of the two blocks takes a down-sampled representation as input and returns an up-sampled discriminative representation to be added to the block input via a residual connection. The model is designed to have a low algorithmic complexity, a small run-time buffer and a very low algorithmic latency, at the same time producing a strong enhancement performance on a noisy-reverberant speech enhancement task even if the hop size is as low as $2$ ms.