 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Ariadne and Theseus: Exploration and Rendezvous with Two Mobile Agents in an Unknown Graph
Mar 12, 2024

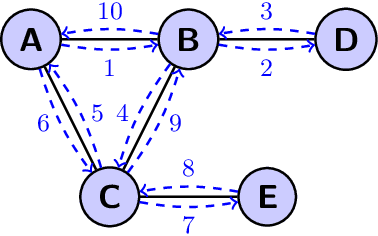
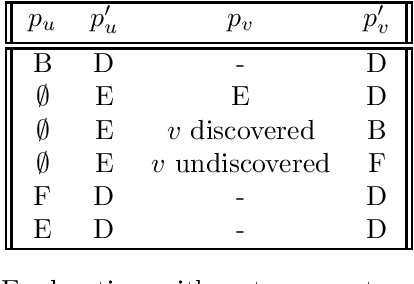
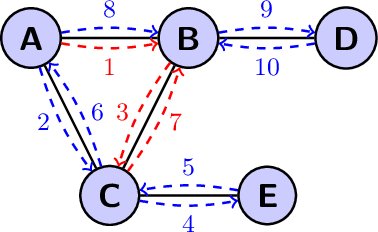
We investigate two fundamental problems in mobile computing: exploration and rendezvous, with two distinct mobile agents in an unknown graph. The agents can read and write information on whiteboards that are located at all nodes. They both move along one adjacent edge at every time-step. In the exploration problem, both agents start from the same node of the graph and must traverse all of its edges. We show that a simple variant of depth-first search achieves collective exploration in $m$ synchronous time-steps, where $m$ is the number of edges of the graph. This improves the competitive ratio of collective graph exploration. In the rendezvous problem, the agents start from different nodes of the graph and must meet as fast as possible. We introduce an algorithm guaranteeing rendezvous in at most $\frac{3}{2}m$ time-steps. This improves over the so-called `wait for Mommy' algorithm which requires $2m$ time-steps. All our guarantees are derived from a more general asynchronous setting in which the speeds of the agents are controlled by an adversary at all times. Our guarantees also generalize to weighted graphs, if the number of edges $m$ is replaced by the sum of all edge lengths.
Rollover Prevention for Mobile Robots with Control Barrier Functions: Differentiator-Based Adaptation and Projection-to-State Safety
Mar 13, 2024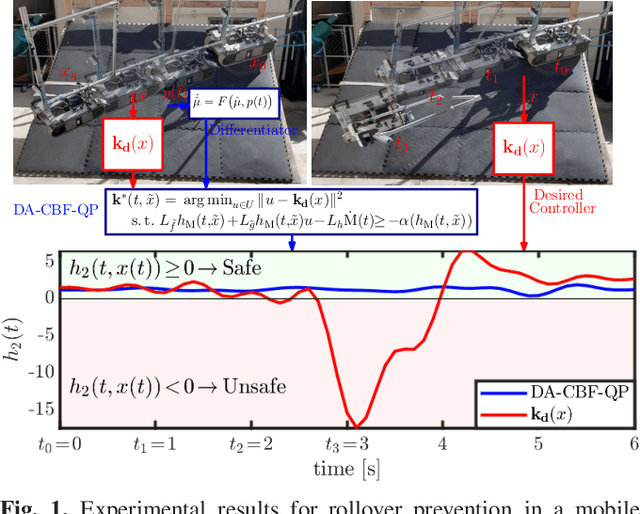
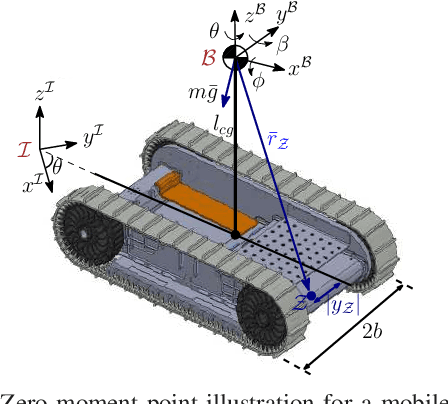
This paper develops rollover prevention guarantees for mobile robots using control barrier function (CBF) theory, and demonstrates these formal results experimentally. To this end, we consider a safety measure based on the zero moment point to provide conditions on the control input through the lens of CBFs. However, these conditions depend on time-varying and noisy parameters. To address this, we present a differentiator-based safety-critical controller that estimates these parameters and pairs Input-to-State Stable (ISS) differentiator dynamics with CBFs to achieve rigorous guarantees of safety. Additionally, to ensure safety in the presence of disturbance, we utilize a time-varying extension of Projection-to-State Safety (PSSf). The effectiveness of the proposed method is demonstrated through experiments on a tracked robot with a rollover potential on steep slopes.
EventRPG: Event Data Augmentation with Relevance Propagation Guidance
Mar 14, 2024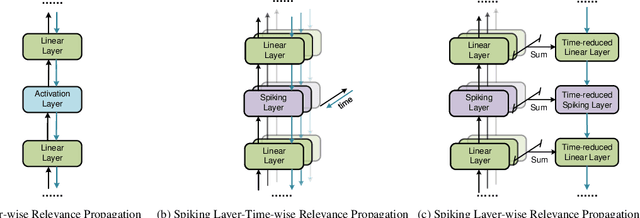
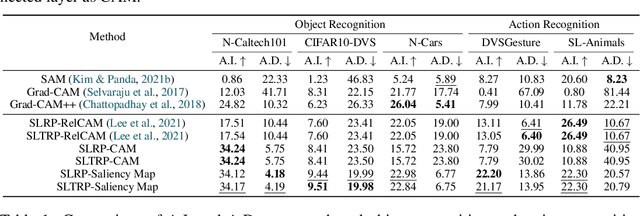
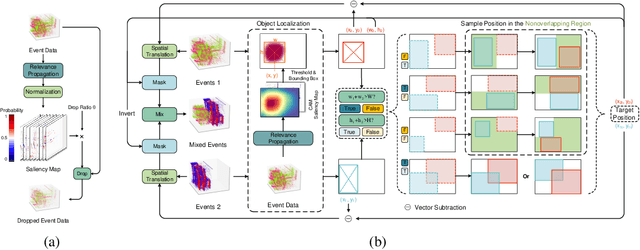

Event camera, a novel bio-inspired vision sensor, has drawn a lot of attention for its low latency, low power consumption, and high dynamic range. Currently, overfitting remains a critical problem in event-based classification tasks for Spiking Neural Network (SNN) due to its relatively weak spatial representation capability. Data augmentation is a simple but efficient method to alleviate overfitting and improve the generalization ability of neural networks, and saliency-based augmentation methods are proven to be effective in the image processing field. However, there is no approach available for extracting saliency maps from SNNs. Therefore, for the first time, we present Spiking Layer-Time-wise Relevance Propagation rule (SLTRP) and Spiking Layer-wise Relevance Propagation rule (SLRP) in order for SNN to generate stable and accurate CAMs and saliency maps. Based on this, we propose EventRPG, which leverages relevance propagation on the spiking neural network for more efficient augmentation. Our proposed method has been evaluated on several SNN structures, achieving state-of-the-art performance in object recognition tasks including N-Caltech101, CIFAR10-DVS, with accuracies of 85.62% and 85.55%, as well as action recognition task SL-Animals with an accuracy of 91.59%. Our code is available at https://github.com/myuansun/EventRPG.
Cellular-enabled Collaborative Robots Planning and Operations for Search-and-Rescue Scenarios
Mar 14, 2024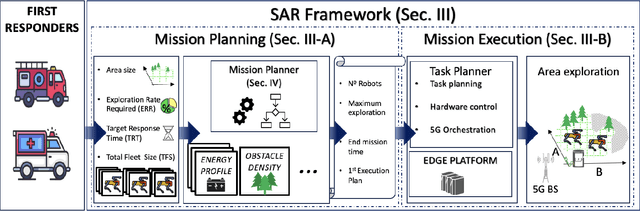
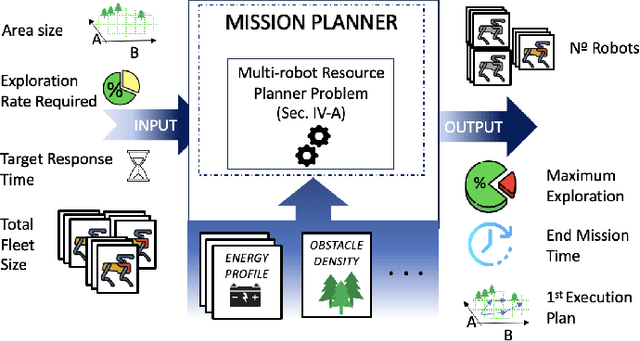
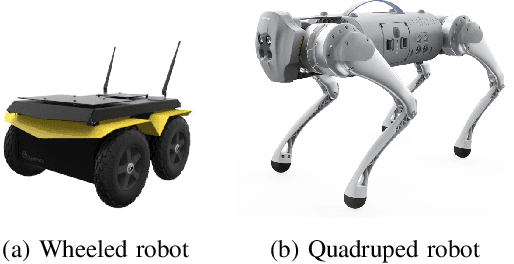
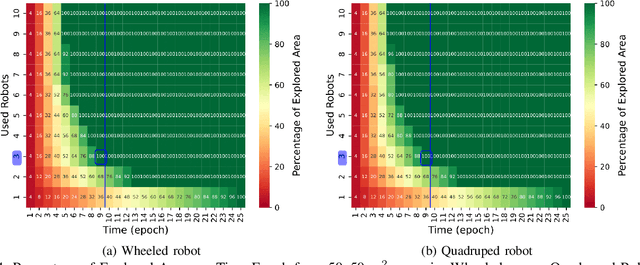
Mission-critical operations, particularly in the context of Search-and-Rescue (SAR) and emergency response situations, demand optimal performance and efficiency from every component involved to maximize the success probability of such operations. In these settings, cellular-enabled collaborative robotic systems have emerged as invaluable assets, assisting first responders in several tasks, ranging from victim localization to hazardous area exploration. However, a critical limitation in the deployment of cellular-enabled collaborative robots in SAR missions is their energy budget, primarily supplied by batteries, which directly impacts their task execution and mobility. This paper tackles this problem, and proposes a search-and-rescue framework for cellular-enabled collaborative robots use cases that, taking as input the area size to be explored, the robots fleet size, their energy profile, exploration rate required and target response time, finds the minimum number of robots able to meet the SAR mission goals and the path they should follow to explore the area. Our results, i) show that first responders can rely on a SAR cellular-enabled robotics framework when planning mission-critical operations to take informed decisions with limited resources, and, ii) illustrate the number of robots versus explored area and response time trade-off depending on the type of robot: wheeled vs quadruped.
Towards Diverse Perspective Learning with Selection over Multiple Temporal Poolings
Mar 14, 2024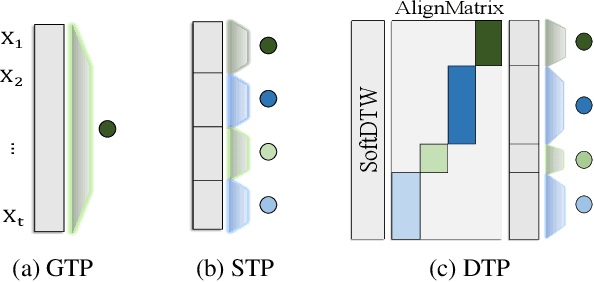
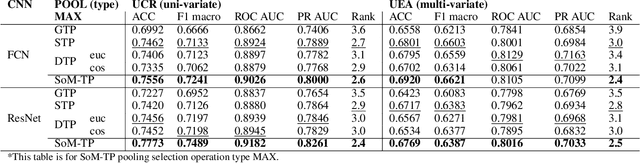
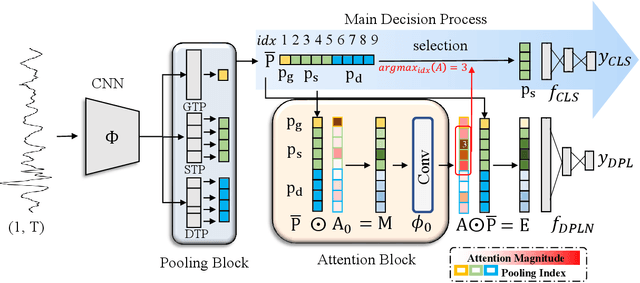
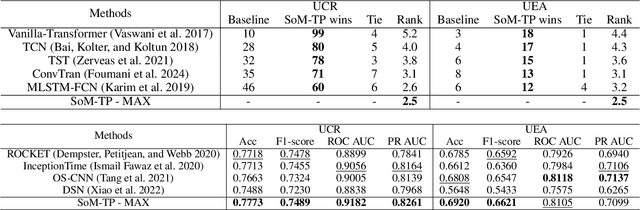
In Time Series Classification (TSC), temporal pooling methods that consider sequential information have been proposed. However, we found that each temporal pooling has a distinct mechanism, and can perform better or worse depending on time series data. We term this fixed pooling mechanism a single perspective of temporal poolings. In this paper, we propose a novel temporal pooling method with diverse perspective learning: Selection over Multiple Temporal Poolings (SoM-TP). SoM-TP dynamically selects the optimal temporal pooling among multiple methods for each data by attention. The dynamic pooling selection is motivated by the ensemble concept of Multiple Choice Learning (MCL), which selects the best among multiple outputs. The pooling selection by SoM-TP's attention enables a non-iterative pooling ensemble within a single classifier. Additionally, we define a perspective loss and Diverse Perspective Learning Network (DPLN). The loss works as a regularizer to reflect all the pooling perspectives from DPLN. Our perspective analysis using Layer-wise Relevance Propagation (LRP) reveals the limitation of a single perspective and ultimately demonstrates diverse perspective learning of SoM-TP. We also show that SoM-TP outperforms CNN models based on other temporal poolings and state-of-the-art models in TSC with extensive UCR/UEA repositories.
* 17 pages, 9 figures
Data is all you need: Finetuning LLMs for Chip Design via an Automated design-data augmentation framework
Mar 17, 2024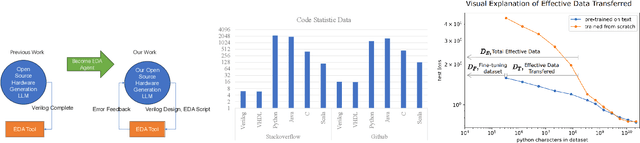
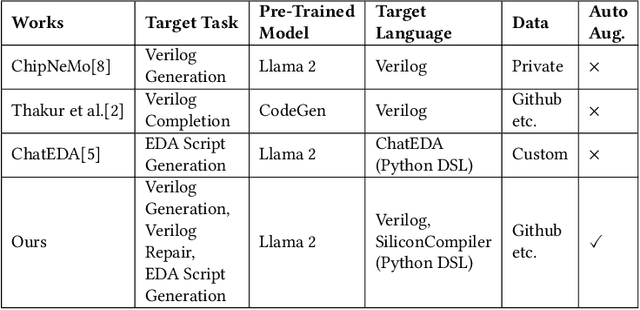
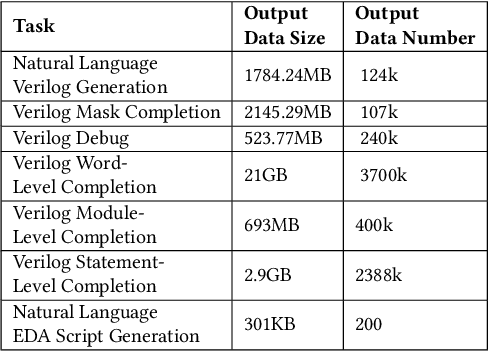
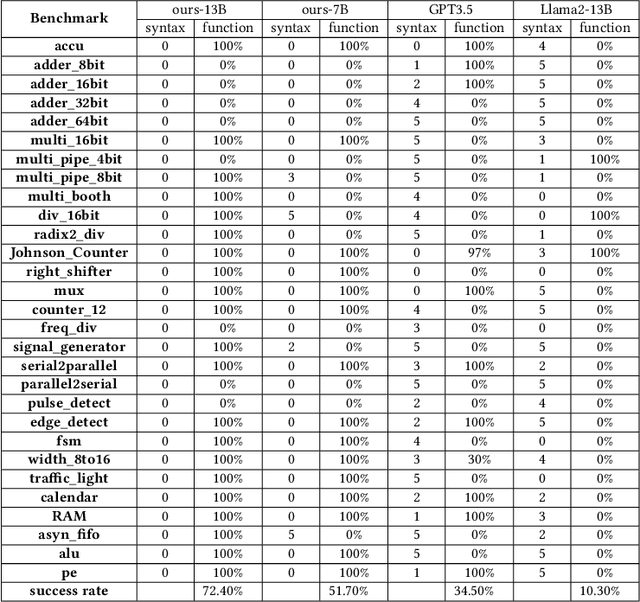
Recent advances in large language models have demonstrated their potential for automated generation of hardware description language (HDL) code from high-level prompts. Researchers have utilized fine-tuning to enhance the ability of these large language models (LLMs) in the field of Chip Design. However, the lack of Verilog data hinders further improvement in the quality of Verilog generation by LLMs. Additionally, the absence of a Verilog and Electronic Design Automation (EDA) script data augmentation framework significantly increases the time required to prepare the training dataset for LLM trainers. This paper proposes an automated design-data augmentation framework, which generates high-volume and high-quality natural language aligned with Verilog and EDA scripts. For Verilog generation, it translates Verilog files to an abstract syntax tree and then maps nodes to natural language with a predefined template. For Verilog repair, it uses predefined rules to generate the wrong verilog file and then pairs EDA Tool feedback with the right and wrong verilog file. For EDA Script generation, it uses existing LLM(GPT-3.5) to obtain the description of the Script. To evaluate the effectiveness of our data augmentation method, we finetune Llama2-13B and Llama2-7B models using the dataset generated by our augmentation framework. The results demonstrate a significant improvement in the Verilog generation tasks with LLMs. Moreover, the accuracy of Verilog generation surpasses that of the current state-of-the-art open-source Verilog generation model, increasing from 58.8% to 70.6% with the same benchmark. Our 13B model (ChipGPT-FT) has a pass rate improvement compared with GPT-3.5 in Verilog generation and outperforms in EDA script (i.e., SiliconCompiler) generation with only 200 EDA script data.
A learning-based solution approach to the application placement problem in mobile edge computing under uncertainty
Mar 17, 2024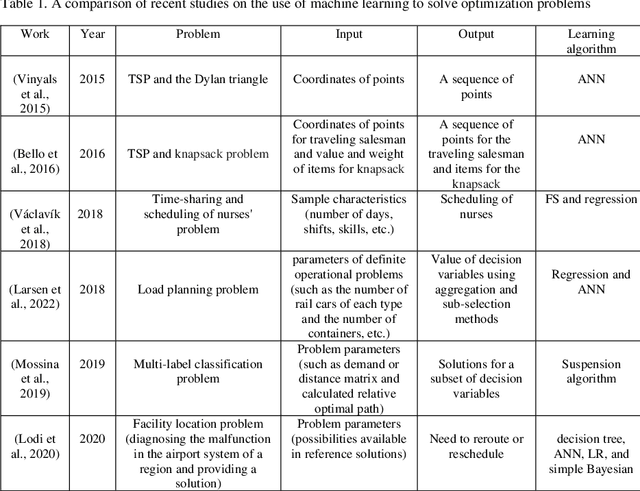

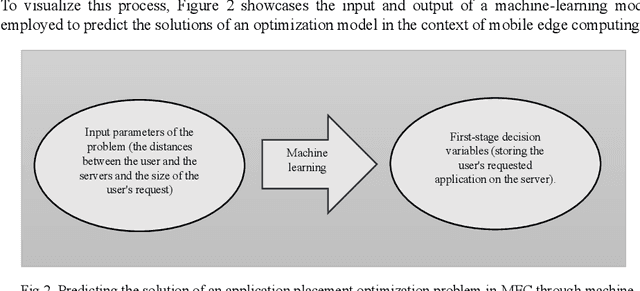
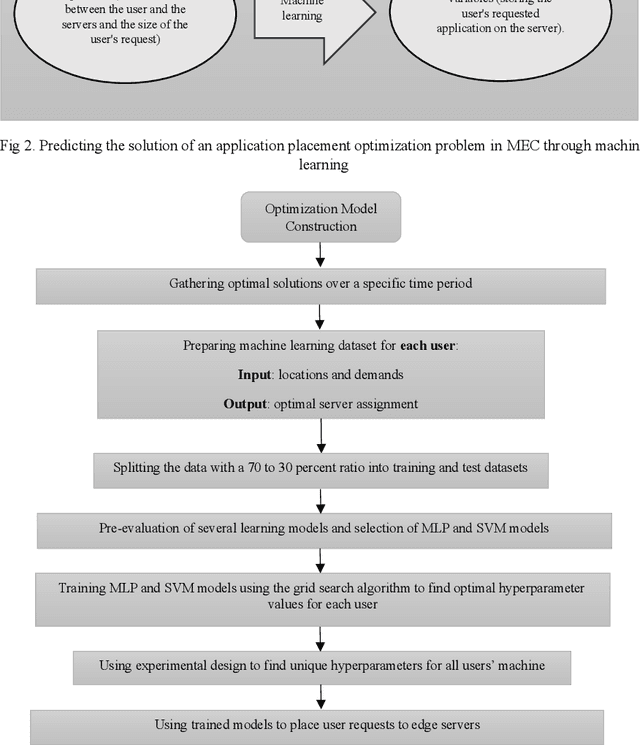
Placing applications in mobile edge computing servers presents a complex challenge involving many servers, users, and their requests. Existing algorithms take a long time to solve high-dimensional problems with significant uncertainty scenarios. Therefore, an efficient approach is required to maximize the quality of service while considering all technical constraints. One of these approaches is machine learning, which emulates optimal solutions for application placement in edge servers. Machine learning models are expected to learn how to allocate user requests to servers based on the spatial positions of users and servers. In this study, the problem is formulated as a two-stage stochastic programming. A sufficient amount of training records is generated by varying parameters such as user locations, their request rates, and solving the optimization model. Then, based on the distance features of each user from the available servers and their request rates, machine learning models generate decision variables for the first stage of the stochastic optimization model, which is the user-to-server request allocation, and are employed as independent decision agents that reliably mimic the optimization model. Support Vector Machines (SVM) and Multi-layer Perceptron (MLP) are used in this research to achieve practical decisions from the stochastic optimization models. The performance of each model has shown an execution effectiveness of over 80%. This research aims to provide a more efficient approach for tackling high-dimensional problems and scenarios with uncertainties in mobile edge computing by leveraging machine learning models for optimal decision-making in request allocation to edge servers. These results suggest that machine-learning models can significantly improve solution times compared to conventional approaches.
Brain-on-Switch: Towards Advanced Intelligent Network Data Plane via NN-Driven Traffic Analysis at Line-Speed
Mar 17, 2024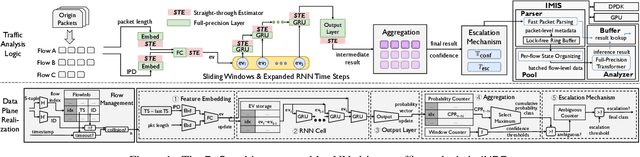
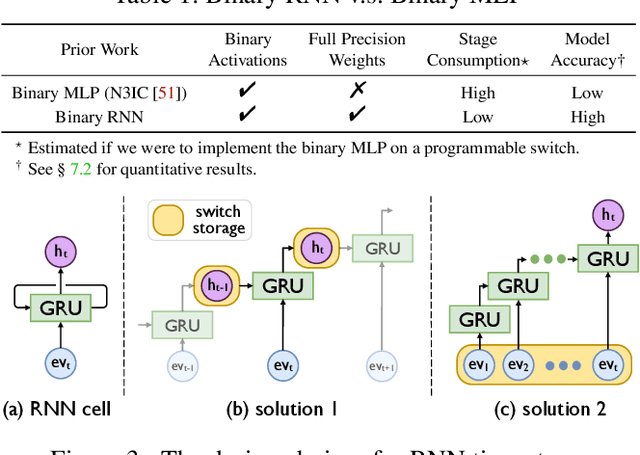
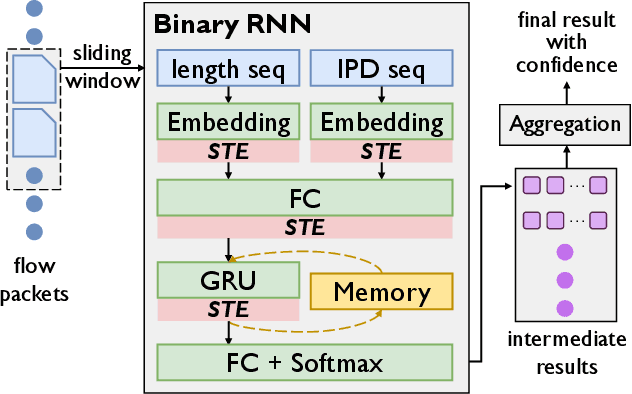
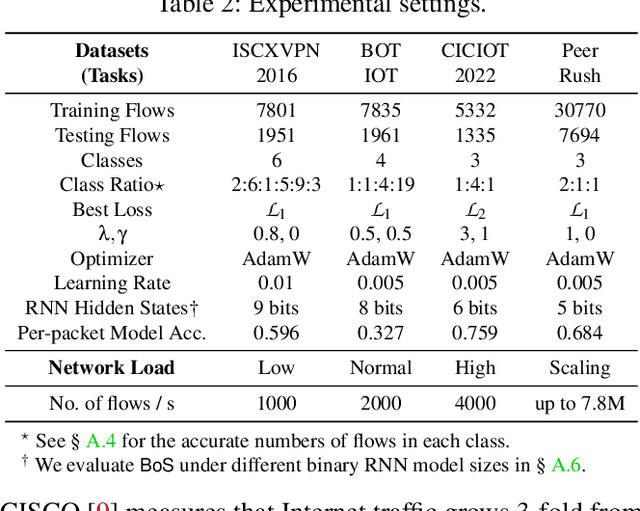
The emerging programmable networks sparked significant research on Intelligent Network Data Plane (INDP), which achieves learning-based traffic analysis at line-speed. Prior art in INDP focus on deploying tree/forest models on the data plane. We observe a fundamental limitation in tree-based INDP approaches: although it is possible to represent even larger tree/forest tables on the data plane, the flow features that are computable on the data plane are fundamentally limited by hardware constraints. In this paper, we present BoS to push the boundaries of INDP by enabling Neural Network (NN) driven traffic analysis at line-speed. Many types of NNs (such as Recurrent Neural Network (RNN), and transformers) that are designed to work with sequential data have advantages over tree-based models, because they can take raw network data as input without complex feature computations on the fly. However, the challenge is significant: the recurrent computation scheme used in RNN inference is fundamentally different from the match-action paradigm used on the network data plane. BoS addresses this challenge by (i) designing a novel data plane friendly RNN architecture that can execute unlimited RNN time steps with limited data plane stages, effectively achieving line-speed RNN inference; and (ii) complementing the on-switch RNN model with an off-switch transformer-based traffic analysis module to further boost the overall performance. We implement a prototype of BoS using a P4 programmable switch as our data plane, and extensively evaluate it over multiple traffic analysis tasks. The results show that BoS outperforms state-of-the-art in both analysis accuracy and scalability.
Flow-Based Visual Stream Compression for Event Cameras
Mar 12, 2024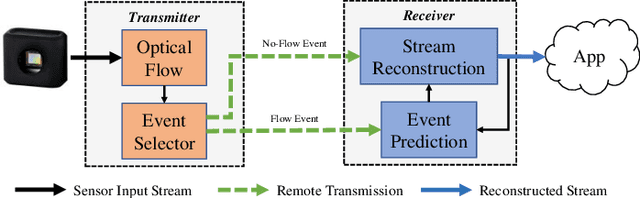
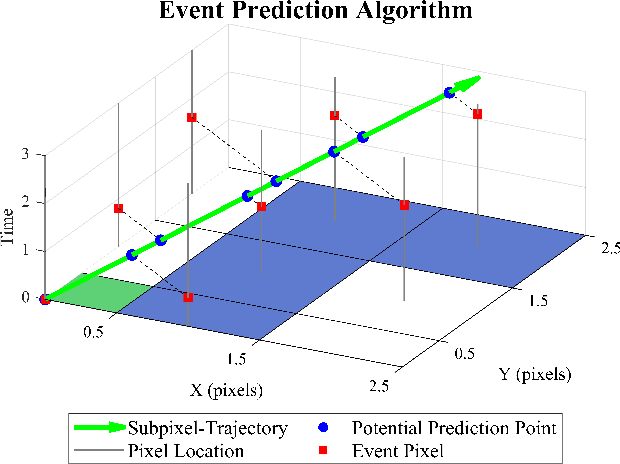
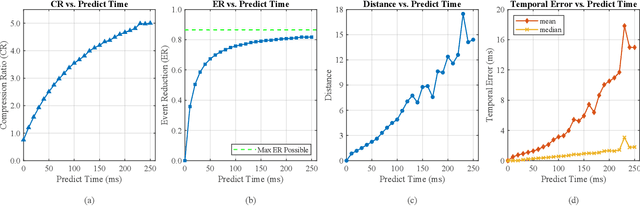
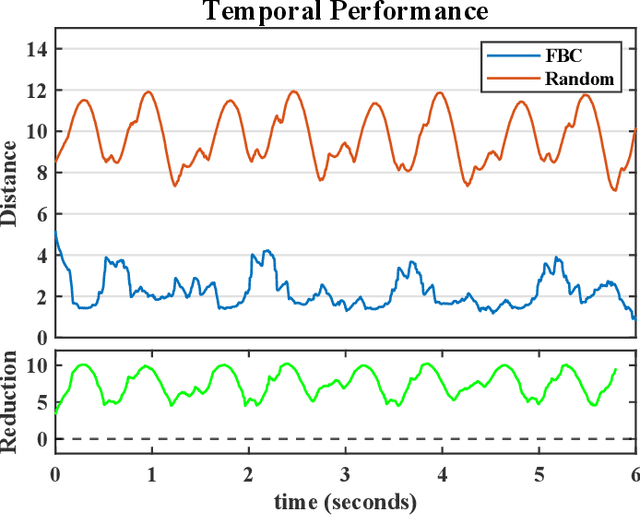
As the use of neuromorphic, event-based vision sensors expands, the need for compression of their output streams has increased. While their operational principle ensures event streams are spatially sparse, the high temporal resolution of the sensors can result in high data rates from the sensor depending on scene dynamics. For systems operating in communication-bandwidth-constrained and power-constrained environments, it is essential to compress these streams before transmitting them to a remote receiver. Therefore, we introduce a flow-based method for the real-time asynchronous compression of event streams as they are generated. This method leverages real-time optical flow estimates to predict future events without needing to transmit them, therefore, drastically reducing the amount of data transmitted. The flow-based compression introduced is evaluated using a variety of methods including spatiotemporal distance between event streams. The introduced method itself is shown to achieve an average compression ratio of 2.81 on a variety of event-camera datasets with the evaluation configuration used. That compression is achieved with a median temporal error of 0.48 ms and an average spatiotemporal event-stream distance of 3.07. When combined with LZMA compression for non-real-time applications, our method can achieve state-of-the-art average compression ratios ranging from 10.45 to 17.24. Additionally, we demonstrate that the proposed prediction algorithm is capable of performing real-time, low-latency event prediction.
Reinforcement Learning with Elastic Time Steps
Feb 22, 2024Traditional Reinforcement Learning (RL) algorithms are usually applied in robotics to learn controllers that act with a fixed control rate. Given the discrete nature of RL algorithms, they are oblivious to the effects of the choice of control rate: finding the correct control rate can be difficult and mistakes often result in excessive use of computing resources or even lack of convergence. We propose Soft Elastic Actor-Critic (SEAC), a novel off-policy actor-critic algorithm to address this issue. SEAC implements elastic time steps, time steps with a known, variable duration, which allow the agent to change its control frequency to adapt to the situation. In practice, SEAC applies control only when necessary, minimizing computational resources and data usage. We evaluate SEAC's capabilities in simulation in a Newtonian kinematics maze navigation task and on a 3D racing video game, Trackmania. SEAC outperforms the SAC baseline in terms of energy efficiency and overall time management, and most importantly without the need to identify a control frequency for the learned controller. SEAC demonstrated faster and more stable training speeds than SAC, especially at control rates where SAC struggled to converge. We also compared SEAC with a similar approach, the Continuous-Time Continuous-Options (CTCO) model, and SEAC resulted in better task performance. These findings highlight the potential of SEAC for practical, real-world RL applications in robotics.