 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Distribution Preserving Source Separation With Time Frequency Predictive Models
Mar 10, 2023
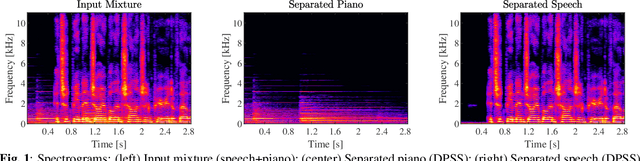
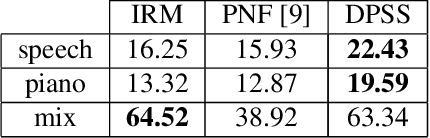
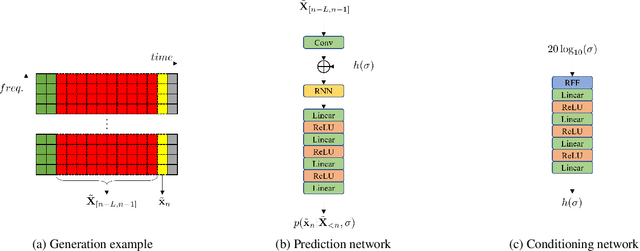
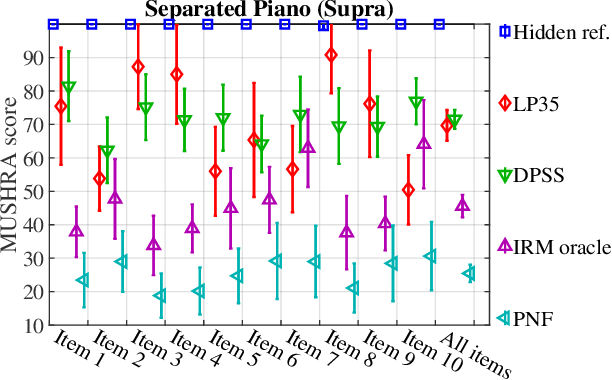
We provide an example of a distribution preserving source separation method, which aims at addressing perceptual shortcomings of state-of-the-art methods. Our approach uses unconditioned generative models of signal sources. Reconstruction is achieved by means of mix-consistent sampling from a distribution conditioned on a realization of a mix. The separated signals follow their respective source distributions, which provides an advantage when separation results are evaluated in a listening test.
System-status-aware Adaptive Network for Online Streaming Video Understanding
Apr 09, 2023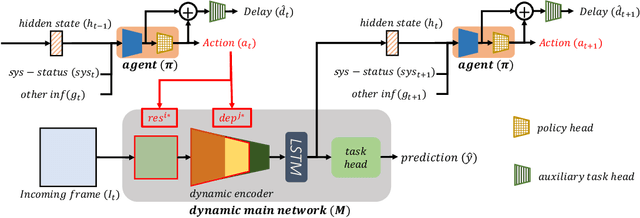
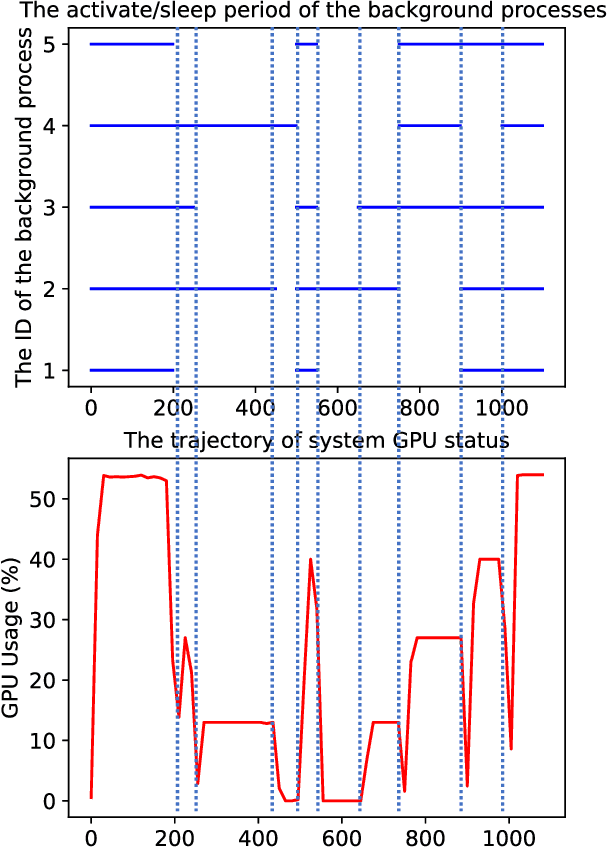
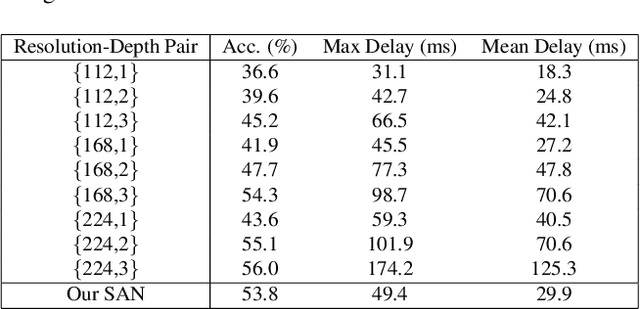
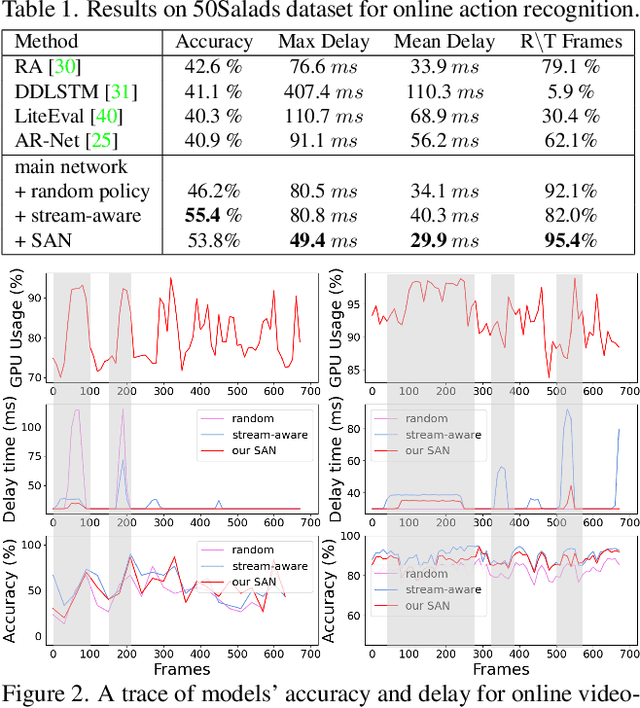
Recent years have witnessed great progress in deep neural networks for real-time applications. However, most existing works do not explicitly consider the general case where the device's state and the available resources fluctuate over time, and none of them investigate or address the impact of varying computational resources for online video understanding tasks. This paper proposes a System-status-aware Adaptive Network (SAN) that considers the device's real-time state to provide high-quality predictions with low delay. Usage of our agent's policy improves efficiency and robustness to fluctuations of the system status. On two widely used video understanding tasks, SAN obtains state-of-the-art performance while constantly keeping processing delays low. Moreover, training such an agent on various types of hardware configurations is not easy as the labeled training data might not be available, or can be computationally prohibitive. To address this challenging problem, we propose a Meta Self-supervised Adaptation (MSA) method that adapts the agent's policy to new hardware configurations at test-time, allowing for easy deployment of the model onto other unseen hardware platforms.
Pushing One Pair of Labels Apart Each Time in Multi-Label Learning: From Single Positive to Full Labels
Feb 28, 2023
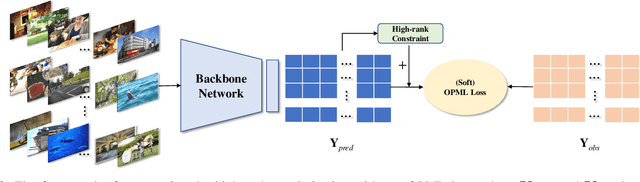
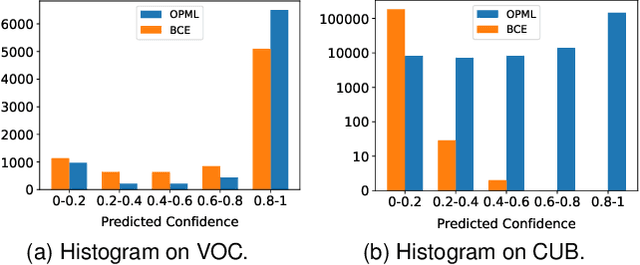
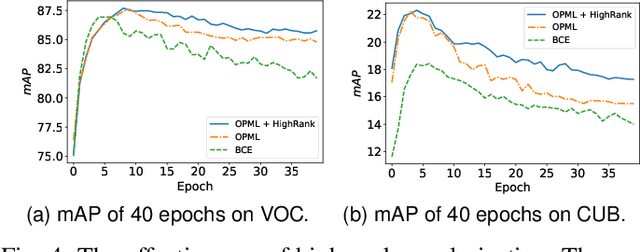
In Multi-Label Learning (MLL), it is extremely challenging to accurately annotate every appearing object due to expensive costs and limited knowledge. When facing such a challenge, a more practical and cheaper alternative should be Single Positive Multi-Label Learning (SPMLL), where only one positive label needs to be provided per sample. Existing SPMLL methods usually assume unknown labels as negatives, which inevitably introduces false negatives as noisy labels. More seriously, Binary Cross Entropy (BCE) loss is often used for training, which is notoriously not robust to noisy labels. To mitigate this issue, we customize an objective function for SPMLL by pushing only one pair of labels apart each time to prevent the domination of negative labels, which is the main culprit of fitting noisy labels in SPMLL. To further combat such noisy labels, we explore the high-rankness of label matrix, which can also push apart different labels. By directly extending from SPMLL to MLL with full labels, a unified loss applicable to both settings is derived. Experiments on real datasets demonstrate that the proposed loss not only performs more robustly to noisy labels for SPMLL but also works well for full labels. Besides, we empirically discover that high-rankness can mitigate the dramatic performance drop in SPMLL. Most surprisingly, even without any regularization or fine-tuned label correction, only adopting our loss defeats state-of-the-art SPMLL methods on CUB, a dataset that severely lacks labels.
The Conditional Cauchy-Schwarz Divergence with Applications to Time-Series Data and Sequential Decision Making
Jan 21, 2023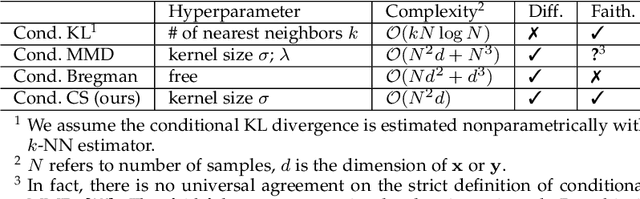
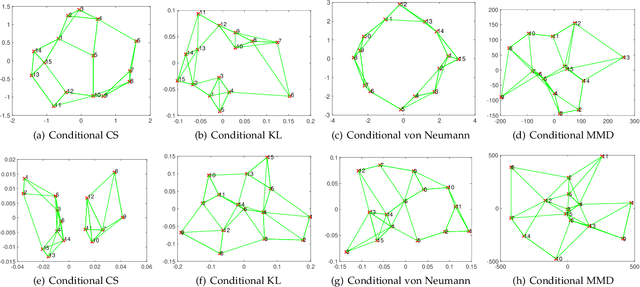

The Cauchy-Schwarz (CS) divergence was developed by Pr\'{i}ncipe et al. in 2000. In this paper, we extend the classic CS divergence to quantify the closeness between two conditional distributions and show that the developed conditional CS divergence can be simply estimated by a kernel density estimator from given samples. We illustrate the advantages (e.g., the rigorous faithfulness guarantee, the lower computational complexity, the higher statistical power, and the much more flexibility in a wide range of applications) of our conditional CS divergence over previous proposals, such as the conditional KL divergence and the conditional maximum mean discrepancy. We also demonstrate the compelling performance of conditional CS divergence in two machine learning tasks related to time series data and sequential inference, namely the time series clustering and the uncertainty-guided exploration for sequential decision making.
Fruit Picker Activity Recognition with Wearable Sensors and Machine Learning
Apr 20, 2023
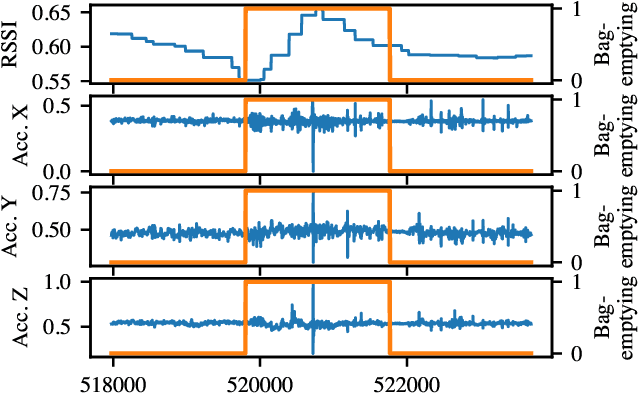
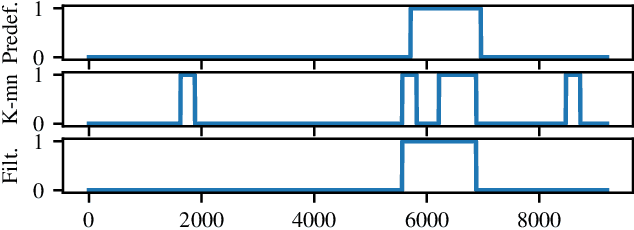
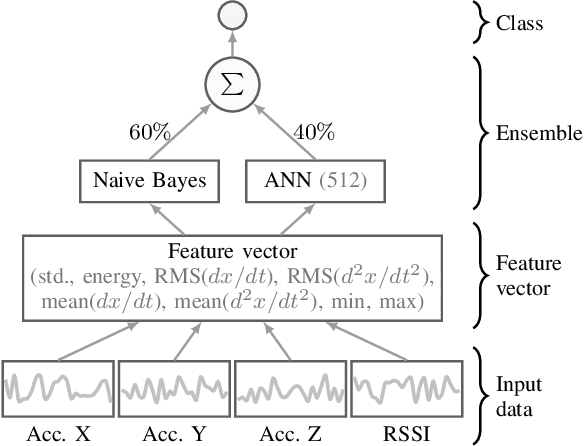
In this paper we present a novel application of detecting fruit picker activities based on time series data generated from wearable sensors. During harvesting, fruit pickers pick fruit into wearable bags and empty these bags into harvesting bins located in the orchard. Once full, these bins are quickly transported to a cooled pack house to improve the shelf life of picked fruits. For farmers and managers, the knowledge of when a picker bag is emptied is important for managing harvesting bins more effectively to minimise the time the picked fruit is left out in the heat (resulting in reduced shelf life). We propose a means to detect these bag-emptying events using human activity recognition with wearable sensors and machine learning methods. We develop a semi-supervised approach to labelling the data. A feature-based machine learning ensemble model and a deep recurrent convolutional neural network are developed and tested on a real-world dataset. When compared, the neural network achieves 86% detection accuracy.
TAAL: Test-time Augmentation for Active Learning in Medical Image Segmentation
Jan 16, 2023Deep learning methods typically depend on the availability of labeled data, which is expensive and time-consuming to obtain. Active learning addresses such effort by prioritizing which samples are best to annotate in order to maximize the performance of the task model. While frameworks for active learning have been widely explored in the context of classification of natural images, they have been only sparsely used in medical image segmentation. The challenge resides in obtaining an uncertainty measure that reveals the best candidate data for annotation. This paper proposes Test-time Augmentation for Active Learning (TAAL), a novel semi-supervised active learning approach for segmentation that exploits the uncertainty information offered by data transformations. Our method applies cross-augmentation consistency during training and inference to both improve model learning in a semi-supervised fashion and identify the most relevant unlabeled samples to annotate next. In addition, our consistency loss uses a modified version of the JSD to further improve model performance. By relying on data transformations rather than on external modules or simple heuristics typically used in uncertainty-based strategies, TAAL emerges as a simple, yet powerful task-agnostic semi-supervised active learning approach applicable to the medical domain. Our results on a publicly-available dataset of cardiac images show that TAAL outperforms existing baseline methods in both fully-supervised and semi-supervised settings. Our implementation is publicly available on https://github.com/melinphd/TAAL.
Cellular EXchange Imaging (CEXI): Evaluation of a diffusion model including water exchange in cells using numerical phantoms of permeable spheres
Apr 12, 2023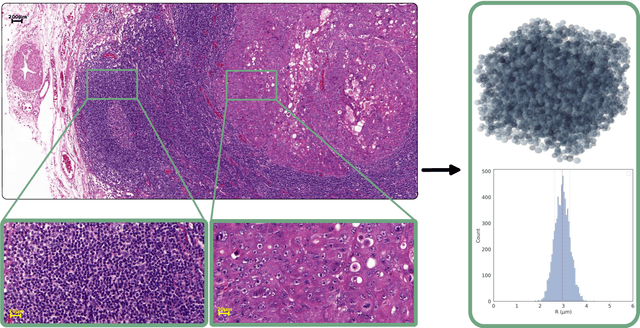

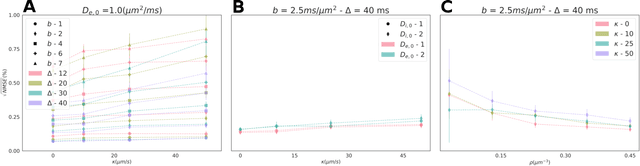
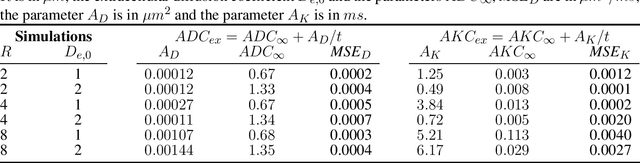
Purpose: Biophysical models of diffusion MRI have been developed to characterize microstructure in various tissues, but existing models are not suitable for tissue composed of permeable spherical cells. In this study we introduce Cellular Exchange Imaging (CEXI), a model tailored for permeable spherical cells, and compares its performance to a related Ball \& Sphere (BS) model that neglects permeability. Methods: We generated DW-MRI signals using Monte-Carlo simulations with a PGSE sequence in numerical substrates made of spherical cells and their extracellular space for a range of membrane permeability. From these signals, the properties of the substrates were inferred using both BS and CEXI models. Results: CEXI outperformed the impermeable model by providing more stable estimates cell size and intracellular volume fraction that were diffusion time-independent. Notably, CEXI accurately estimated the exchange time for low to moderate permeability levels previously reported in other studies ($\kappa<25\mu m/s$). However, in highly permeable substrates ($\kappa=50\mu m/s$), the estimated parameters were less stable, particularly the diffusion coefficients. Conclusion: This study highlights the importance of modeling the exchange time to accurately quantify microstructure properties in permeable cellular substrates. Future studies should evaluate CEXI in clinical applications such as lymph nodes, investigate exchange time as a potential biomarker of tumor severity, and develop more appropriate tissue models that account for anisotropic diffusion and highly permeable membranes.
Frame Error Rate Prediction for Non-Stationary Wireless Vehicular Communication Links
Apr 12, 2023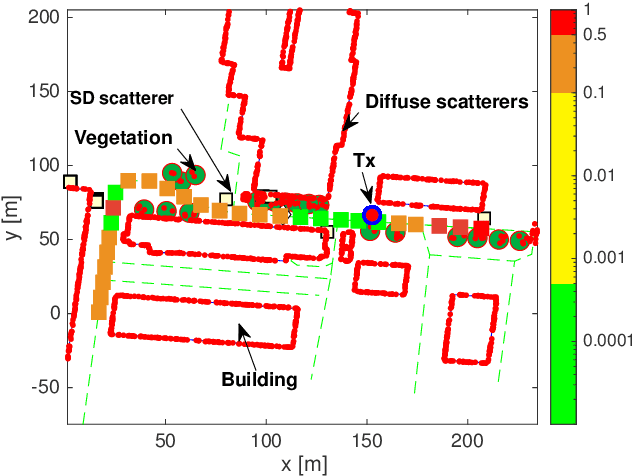
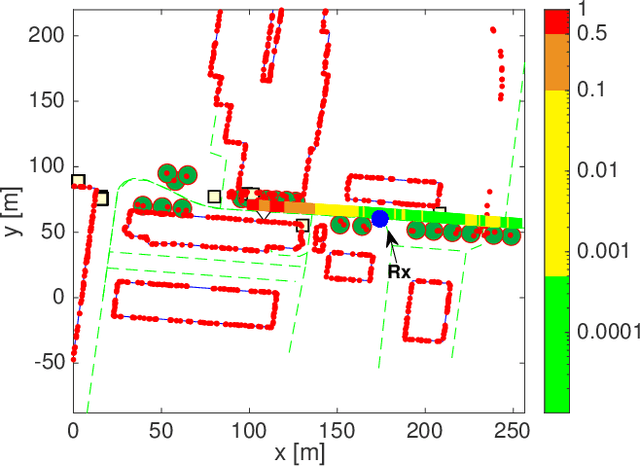
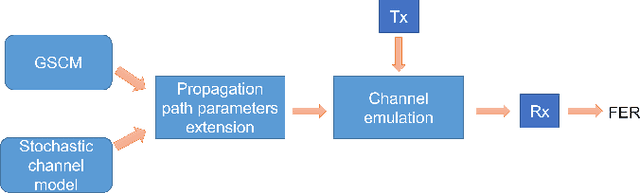
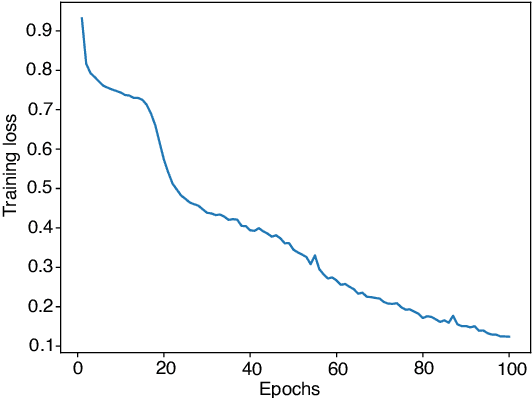
Wireless vehicular communication will increase the safety of road users. The reliability of vehicular communication links is of high importance as links with low reliability may diminish the advantage of having situational traffic information. The goal of our investigation is to obtain a reliable coverage area for non-stationary vehicular scenarios. Therefore we propose a deep neural network (DNN) for predicting the expected frame error rate (FER). The DNN is trained in a supervised fashion, where a time-limited sequence of channel frequency responses has been labeled with its corresponding FER values assuming an underlying wireless communication system, i.e. IEEE 802.11p. For generating the training dataset we use a geometry-based stochastic channel model (GSCM). We obtain the ground truth FER by emulating the time-varying frequency responses using a hardware-in-the-loop setup. Our GSCM provides the propagation path parameters which we use to fix the statistics of the fading process at one point in space for an arbitrary amount of time, enabling accurate FER estimation. Using this dataset we achieve an accuracy of 85% of the DNN. We use the trained model to predict the FER for measured time-varying channel transfer functions obtained during a measurement campaign. We compare the predicted output of the DNN to the measured FER on the road and obtain a prediction accuracy of 78%.
Uncoordinated Interference Avoidance Between Terrestrial and Non-Terrestrial Communications
Apr 14, 2023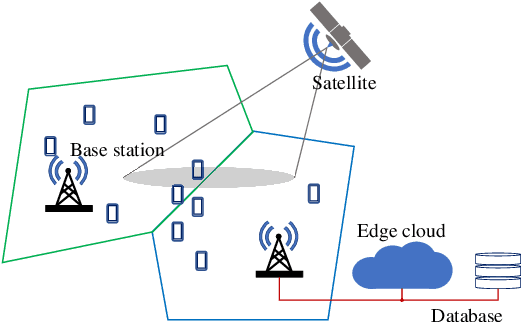

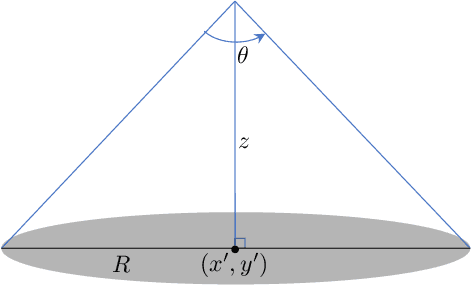
This paper proposes an algorithm that uses geospatial analytics and the muting of physical resources in next-generation base stations (BSs) to avoid interference between cellular (or terrestrial) and satellite communication systems as non-terrestrial systems. The information exchange between satellite and terrestrial links is very limited, but a hybrid edge cloud node with access to satellite trajectories can enable these BSs to take proactive measures. We show simulation results to validate the superiority of our proposed algorithm over a conventional method. Our algorithm runs in polynomial time, making it suitable for real-time interference avoidance.
VR Facial Animation for Immersive Telepresence Avatars
Apr 24, 2023

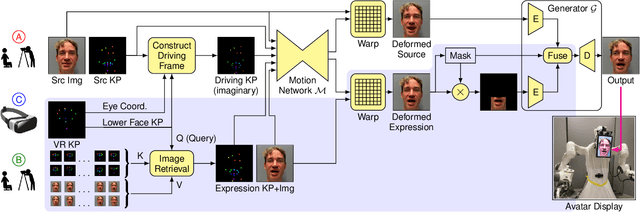
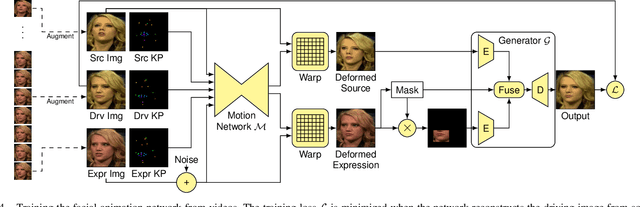
VR Facial Animation is necessary in applications requiring clear view of the face, even though a VR headset is worn. In our case, we aim to animate the face of an operator who is controlling our robotic avatar system. We propose a real-time capable pipeline with very fast adaptation for specific operators. In a quick enrollment step, we capture a sequence of source images from the operator without the VR headset which contain all the important operator-specific appearance information. During inference, we then use the operator keypoint information extracted from a mouth camera and two eye cameras to estimate the target expression and head pose, to which we map the appearance of a source still image. In order to enhance the mouth expression accuracy, we dynamically select an auxiliary expression frame from the captured sequence. This selection is done by learning to transform the current mouth keypoints into the source camera space, where the alignment can be determined accurately. We, furthermore, demonstrate an eye tracking pipeline that can be trained in less than a minute, a time efficient way to train the whole pipeline given a dataset that includes only complete faces, show exemplary results generated by our method, and discuss performance at the ANA Avatar XPRIZE semifinals.