 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Structured Sentiment Analysis as Transition-based Dependency Parsing
May 09, 2023
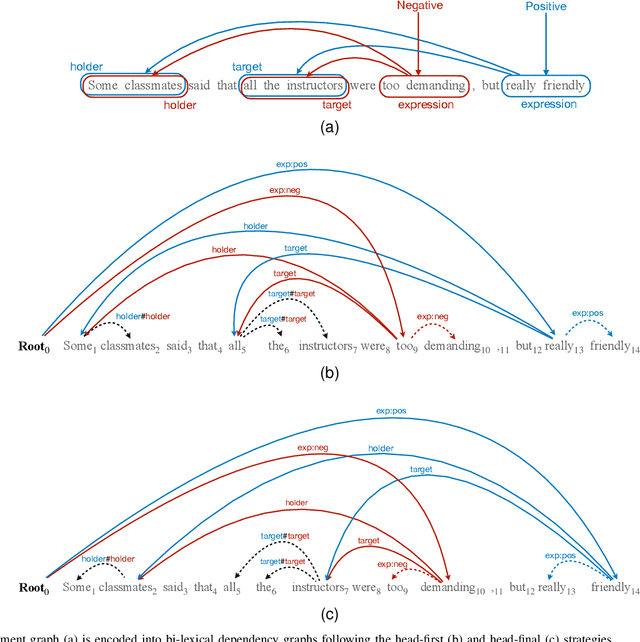

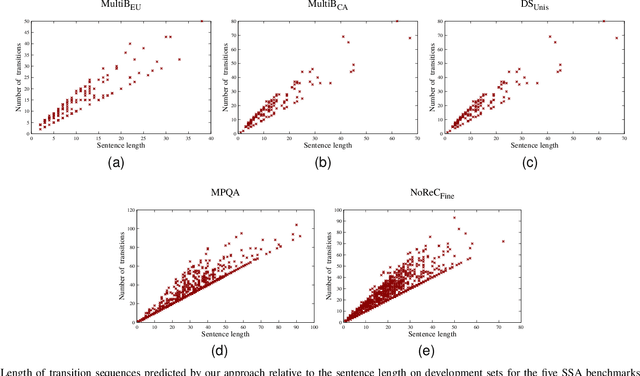
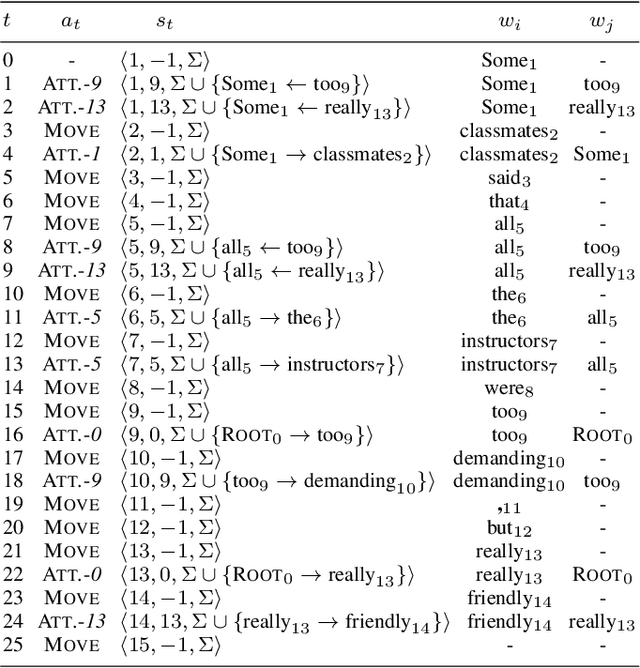
Structured sentiment analysis (SSA) aims to automatically extract people's opinions from a text in natural language and adequately represent that information in a graph structure. One of the most accurate methods for performing SSA was recently proposed and consists of approaching it as a dependency parsing task. Although we can find in the literature how transition-based algorithms excel in dependency parsing in terms of accuracy and efficiency, all proposed attempts to tackle SSA following that approach were based on graph-based models. In this article, we present the first transition-based method to address SSA as dependency parsing. Specifically, we design a transition system that processes the input text in a left-to-right pass, incrementally generating the graph structure containing all identified opinions. To effectively implement our final transition-based model, we resort to a Pointer Network architecture as a backbone. From an extensive evaluation, we demonstrate that our model offers the best performance to date in practically all cases among prior dependency-based methods, and surpass recent task-specific techniques on the most challenging datasets. We additionally include an in-depth analysis and empirically prove that the overall time-complexity cost of our approach is quadratic in the sentence length, being more efficient than top-performing graph-based parsers.
State Machine-based Waveforms for Channels With 1-Bit Quantization and Oversampling With Time-Instance Zero-Crossing Modulation
Feb 04, 2023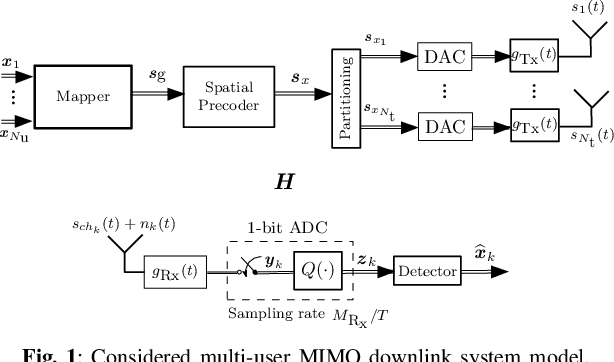
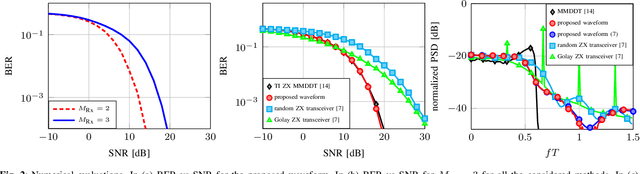
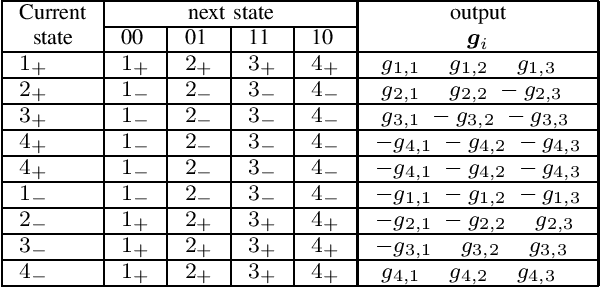

Systems with 1-bit quantization and oversampling are promising for the Internet of Things (IoT) devices in order to reduce the power consumption of the analog-to-digital-converters. The novel time-instance zero-crossing (TI ZX) modulation is a promising approach for this kind of channels but existing studies rely on optimization problems with high computational complexity and delay. In this work, we propose a practical waveform design based on the established TI ZX modulation for a multiuser multi-input multi-output (MIMO) downlink scenario with 1-bit quantization and temporal oversampling at the receivers. In this sense, the proposed temporal transmit signals are constructed by concatenating segments of coefficients which convey the information into the time-instances of zero-crossings according to the TI ZX mapping rules. The proposed waveform design is compared with other methods from the literature. The methods are compared in terms of bit error rate and normalized power spectral density. Numerical results show that the proposed technique is suitable for multiuser MIMO system with 1-bit quantization while tolerating some small amount of out-of-band radiation.
Interpreting Vision and Language Generative Models with Semantic Visual Priors
May 04, 2023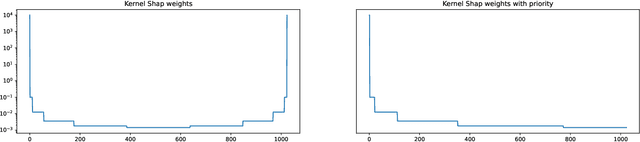

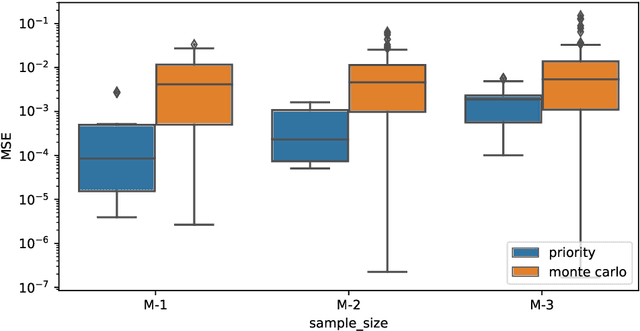
When applied to Image-to-text models, interpretability methods often provide token-by-token explanations namely, they compute a visual explanation for each token of the generated sequence. Those explanations are expensive to compute and unable to comprehensively explain the model's output. Therefore, these models often require some sort of approximation that eventually leads to misleading explanations. We develop a framework based on SHAP, that allows for generating comprehensive, meaningful explanations leveraging the meaning representation of the output sequence as a whole. Moreover, by exploiting semantic priors in the visual backbone, we extract an arbitrary number of features that allows the efficient computation of Shapley values on large-scale models, generating at the same time highly meaningful visual explanations. We demonstrate that our method generates semantically more expressive explanations than traditional methods at a lower compute cost and that it can be generalized over other explainability methods.
Deep Learning Aided Beamforming for Downlink Non Orthogonal Multiple Access Systems
May 04, 2023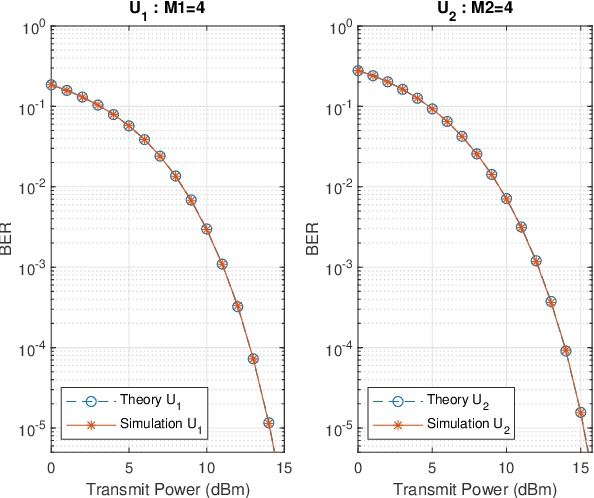
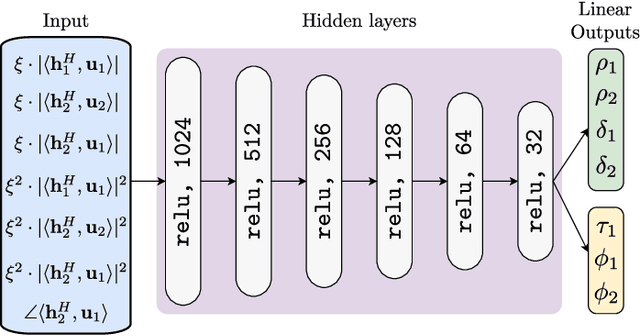
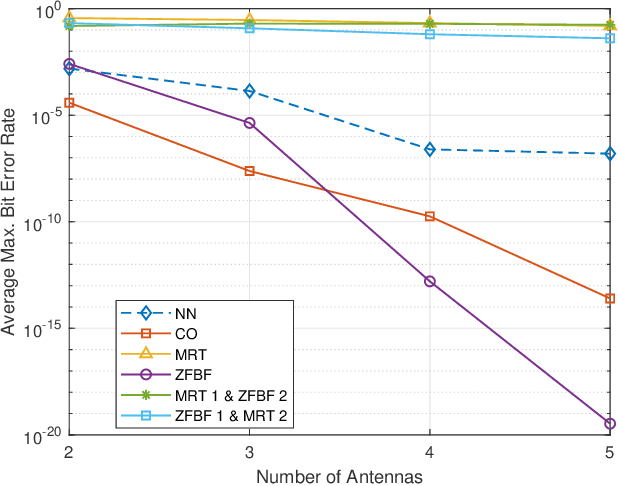
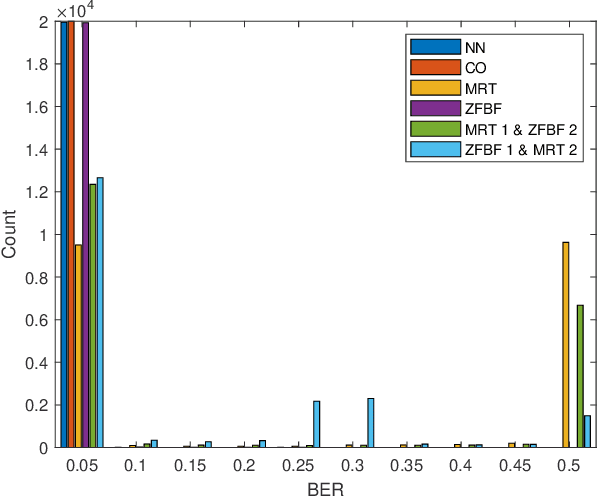
We investigate the problem of optimal beamformer design for the downlink of Multi Input Single Output (MISO) Non-Orthogonal Multiple Access (NOMA). In more detail, focusing on the two-user scenario, we first derive a closed from expression for the Bit Error Rate (BER) experienced by both user. Using the derived expression, in an effort to introduce fairness in our system design, we introduce the problem of optimal, with respect to minimizing the maximum of the BER values experienced by the two users, beamforming and propose a Machine Learning (ML) based solution for this problem. Finally, we conduct simulations which allow us to verify that our proposed algorithm outperforms other existing benchmarks as well as that in a variety of cases, it may result to BER performance close to the one obtained by the use of time consuming constrained optimization methods, such as to solve the given optimization problem.
Emulation Learning for Neuromimetic Systems
May 04, 2023
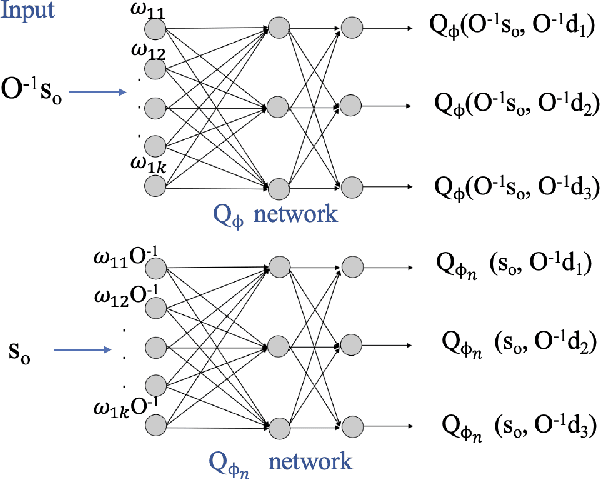
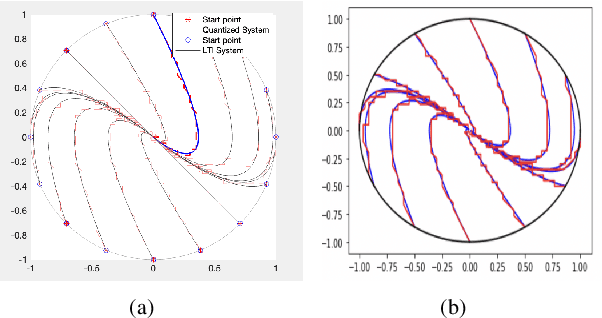
Building on our recent research on neural heuristic quantization systems, results on learning quantized motions and resilience to channel dropouts are reported. We propose a general emulation problem consistent with the neuromimetic paradigm. This optimal quantization problem can be solved by model predictive control (MPC), but because the optimization step involves integer programming, the approach suffers from combinatorial complexity when the number of input channels becomes large. Even if we collect data points to train a neural network simultaneously, collection of training data and the training itself are still time-consuming. Therefore, we propose a general Deep Q Network (DQN) algorithm that can not only learn the trajectory but also exhibit the advantages of resilience to channel dropout. Furthermore, to transfer the model to other emulation problems, a mapping-based transfer learning approach can be used directly on the current model to obtain the optimal direction for the new emulation problems.
Software-defined Optoacoustic Tomography
May 04, 2023
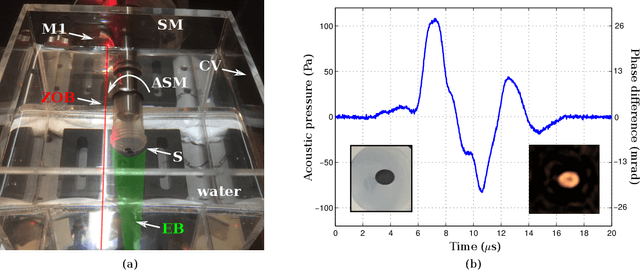
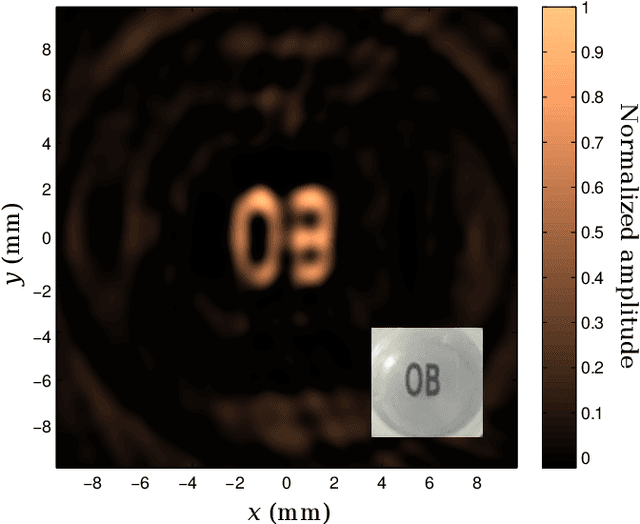
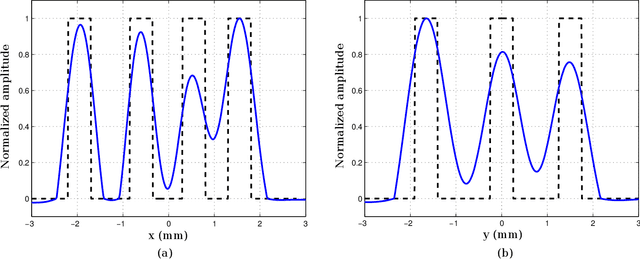
In this work we present the first application of software-defined optoelectronics (SDO) for bidimensional optoacoustic tomography (OAT). The SDO concept refers to optoelectronic systems where the functionality associated with the conditioning and processing of optical and electrical signals are digitally implemented and controlled by software. This paradigm takes advantage of the flexibility of software-defined hardware platforms to develop adaptive instrumentation systems. We implement an OAT system based on a heterodyne interferometer in a Mach-Zehnder configuration and a commercial software-defined radio platform (SDR). Here the SDR serves as a function generator and oscilloscope at the same time providing perfect carrier synchronization between its transmitter and receiver in a coherent baseband modulator scheme. Therefore, the carrier synchronization enables us to have a much better phase recovery. We study the performance of the OAT SDO system by means of different bidimensional phantoms and the analysis of the reconstructed images.
* Published in Applied Optics
Edge-aware Consistent Stereo Video Depth Estimation
May 04, 2023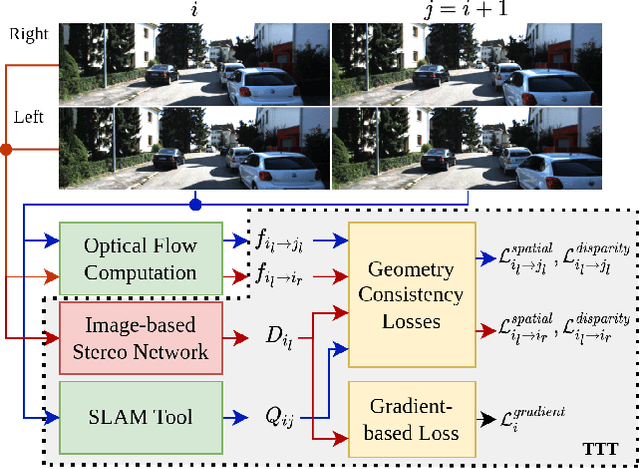
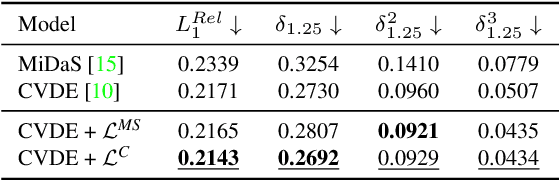
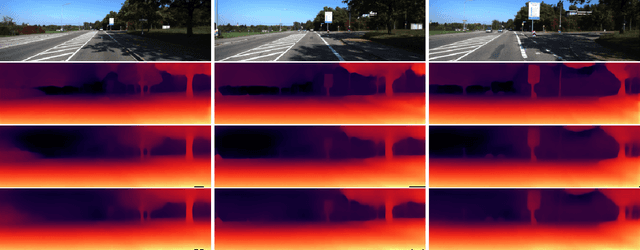

Video depth estimation is crucial in various applications, such as scene reconstruction and augmented reality. In contrast to the naive method of estimating depths from images, a more sophisticated approach uses temporal information, thereby eliminating flickering and geometrical inconsistencies. We propose a consistent method for dense video depth estimation; however, unlike the existing monocular methods, ours relates to stereo videos. This technique overcomes the limitations arising from the monocular input. As a benefit of using stereo inputs, a left-right consistency loss is introduced to improve the performance. Besides, we use SLAM-based camera pose estimation in the process. To address the problem of depth blurriness during test-time training (TTT), we present an edge-preserving loss function that improves the visibility of fine details while preserving geometrical consistency. We show that our edge-aware stereo video model can accurately estimate the dense depth maps.
Uncertainty-Aware Semi-Supervised Learning for Prostate MRI Zonal Segmentation
May 10, 2023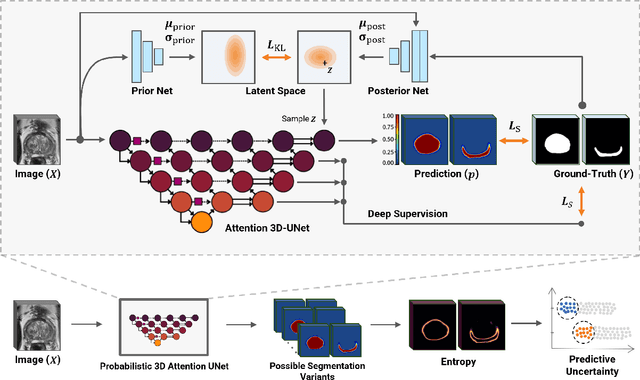
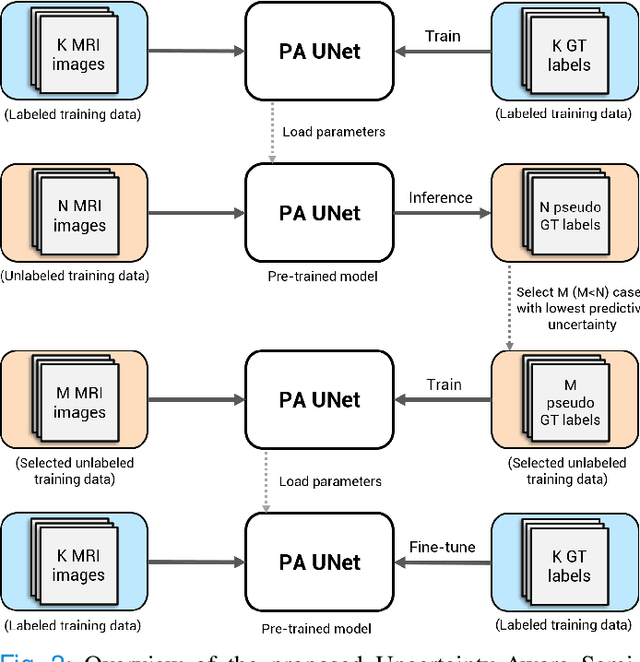
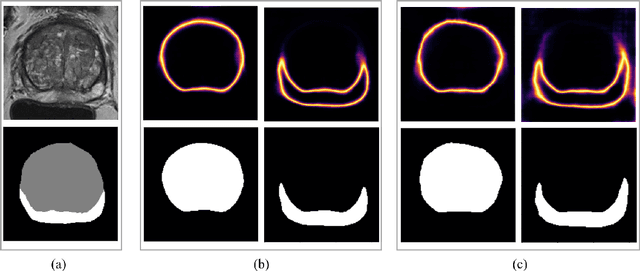
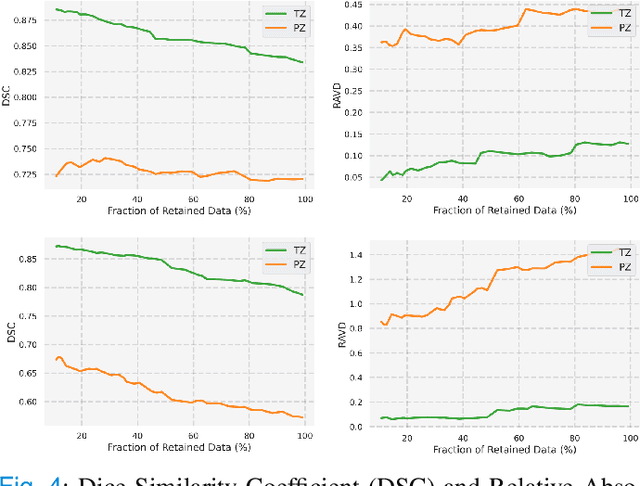
Quality of deep convolutional neural network predictions strongly depends on the size of the training dataset and the quality of the annotations. Creating annotations, especially for 3D medical image segmentation, is time-consuming and requires expert knowledge. We propose a novel semi-supervised learning (SSL) approach that requires only a relatively small number of annotations while being able to use the remaining unlabeled data to improve model performance. Our method uses a pseudo-labeling technique that employs recent deep learning uncertainty estimation models. By using the estimated uncertainty, we were able to rank pseudo-labels and automatically select the best pseudo-annotations generated by the supervised model. We applied this to prostate zonal segmentation in T2-weighted MRI scans. Our proposed model outperformed the semi-supervised model in experiments with the ProstateX dataset and an external test set, by leveraging only a subset of unlabeled data rather than the full collection of 4953 cases, our proposed model demonstrated improved performance. The segmentation dice similarity coefficient in the transition zone and peripheral zone increased from 0.835 and 0.727 to 0.852 and 0.751, respectively, for fully supervised model and the uncertainty-aware semi-supervised learning model (USSL). Our USSL model demonstrates the potential to allow deep learning models to be trained on large datasets without requiring full annotation. Our code is available at https://github.com/DIAGNijmegen/prostateMR-USSL.
Relightify: Relightable 3D Faces from a Single Image via Diffusion Models
May 10, 2023
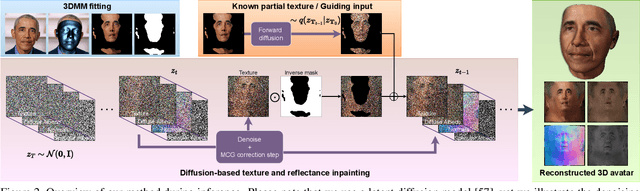


Following the remarkable success of diffusion models on image generation, recent works have also demonstrated their impressive ability to address a number of inverse problems in an unsupervised way, by properly constraining the sampling process based on a conditioning input. Motivated by this, in this paper, we present the first approach to use diffusion models as a prior for highly accurate 3D facial BRDF reconstruction from a single image. We start by leveraging a high-quality UV dataset of facial reflectance (diffuse and specular albedo and normals), which we render under varying illumination settings to simulate natural RGB textures and, then, train an unconditional diffusion model on concatenated pairs of rendered textures and reflectance components. At test time, we fit a 3D morphable model to the given image and unwrap the face in a partial UV texture. By sampling from the diffusion model, while retaining the observed texture part intact, the model inpaints not only the self-occluded areas but also the unknown reflectance components, in a single sequence of denoising steps. In contrast to existing methods, we directly acquire the observed texture from the input image, thus, resulting in more faithful and consistent reflectance estimation. Through a series of qualitative and quantitative comparisons, we demonstrate superior performance in both texture completion as well as reflectance reconstruction tasks.
Incorporating Structured Representations into Pretrained Vision & Language Models Using Scene Graphs
May 10, 2023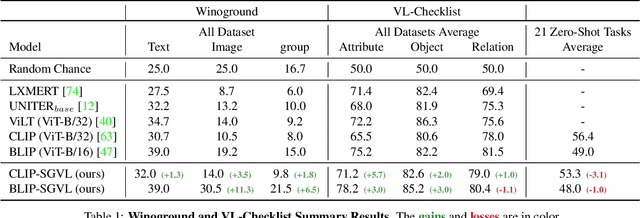
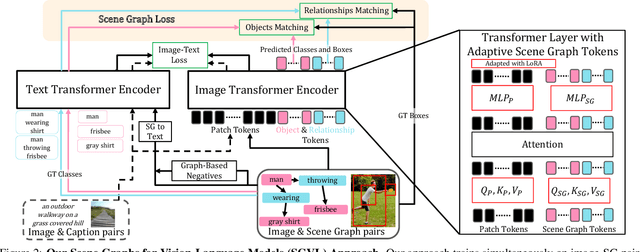
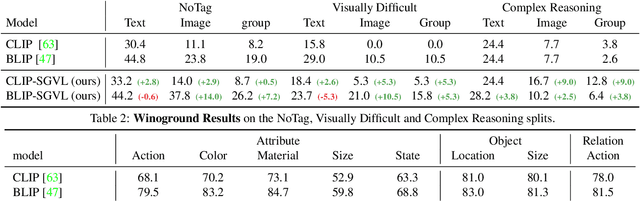

Vision and Language (VL) models have demonstrated remarkable zero-shot performance in a variety of tasks. However, recent studies have shown that even the best VL models struggle to capture aspects of scene understanding, such as object attributes, relationships, and action states. In contrast, obtaining structured annotations, e.g., scene graphs (SGs) that could improve these models is time-consuming, costly, and tedious, and thus cannot be used on a large scale. Here we ask, can small datasets containing SG annotations provide sufficient information for enhancing structured understanding of VL models? We show that it is indeed possible to improve VL models using such data by utilizing a specialized model architecture and a new training paradigm. Our approach captures structure-related information for both the visual and textual encoders by directly supervising both components when learning from SG labels. We use scene graph supervision to generate fine-grained captions based on various graph augmentations highlighting different compositional aspects of the scene, and to predict SG information using an open vocabulary approach by adding special ``Adaptive SG tokens'' to the visual encoder. Moreover, we design a new adaptation technique tailored specifically to the SG tokens that allows better learning of the graph prediction task while still maintaining zero-shot capabilities. Our model shows strong performance improvements on the Winoground and VL-checklist datasets with only a mild degradation in zero-shot performance.