 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Unified Evaluation Framework for Novelty Detection and Accommodation in NLP with an Instantiation in Authorship Attribution
May 08, 2023
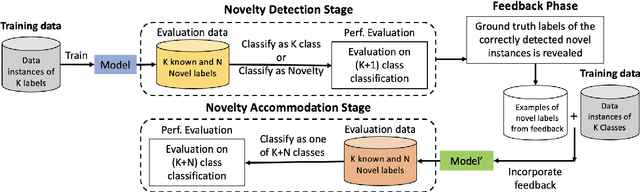
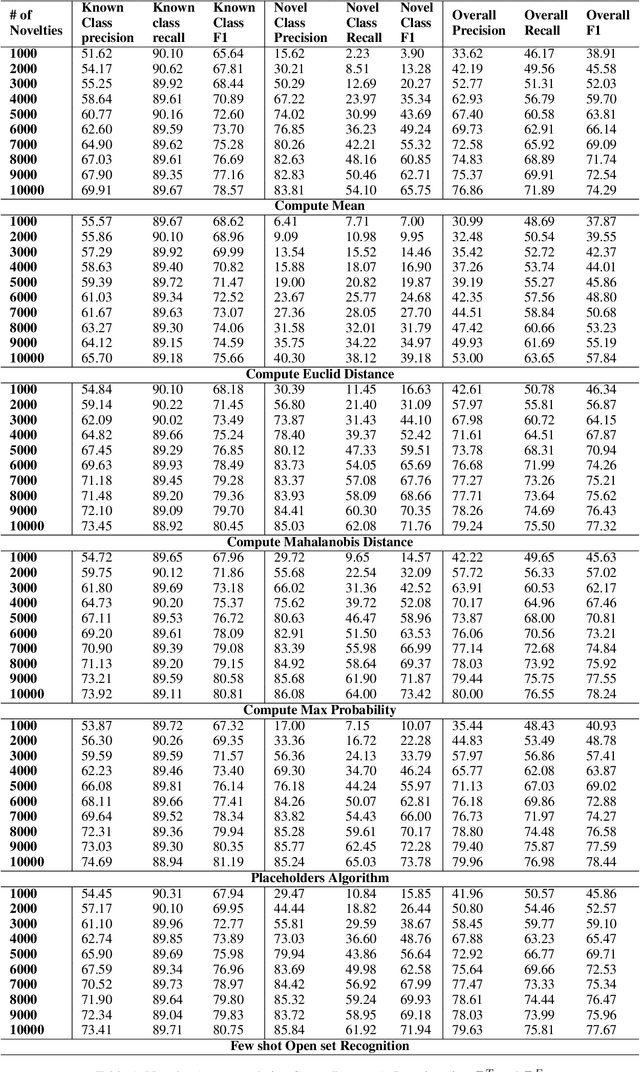
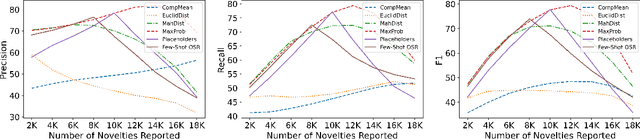
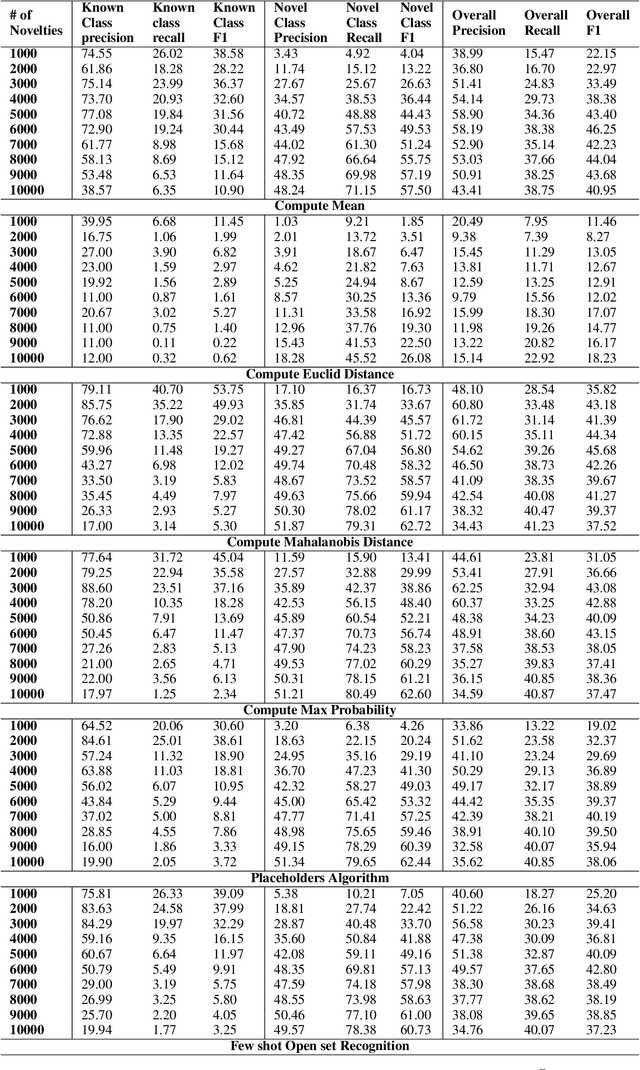
State-of-the-art natural language processing models have been shown to achieve remarkable performance in 'closed-world' settings where all the labels in the evaluation set are known at training time. However, in real-world settings, 'novel' instances that do not belong to any known class are often observed. This renders the ability to deal with novelties crucial. To initiate a systematic research in this important area of 'dealing with novelties', we introduce 'NoveltyTask', a multi-stage task to evaluate a system's performance on pipelined novelty 'detection' and 'accommodation' tasks. We provide mathematical formulation of NoveltyTask and instantiate it with the authorship attribution task that pertains to identifying the correct author of a given text. We use Amazon reviews corpus and compile a large dataset (consisting of 250k instances across 200 authors/labels) for NoveltyTask. We conduct comprehensive experiments and explore several baseline methods for the task. Our results show that the methods achieve considerably low performance making the task challenging and leaving sufficient room for improvement. Finally, we believe our work will encourage research in this underexplored area of dealing with novelties, an important step en route to developing robust systems.
Deep Learning and Image Super-Resolution-Guided Beam and Power Allocation for mmWave Networks
May 08, 2023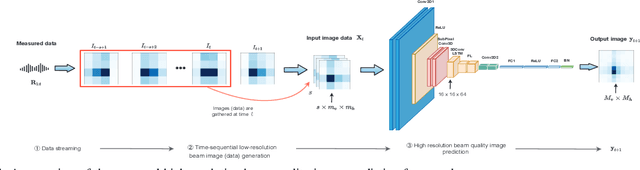
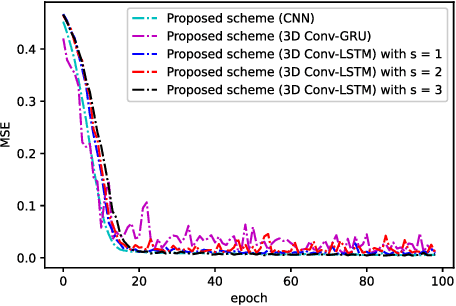
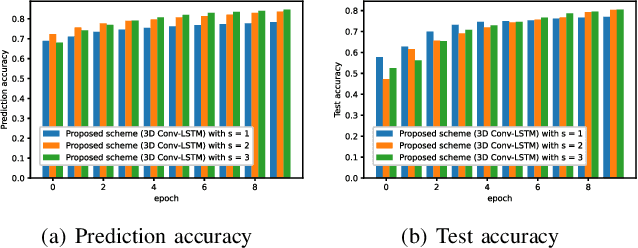
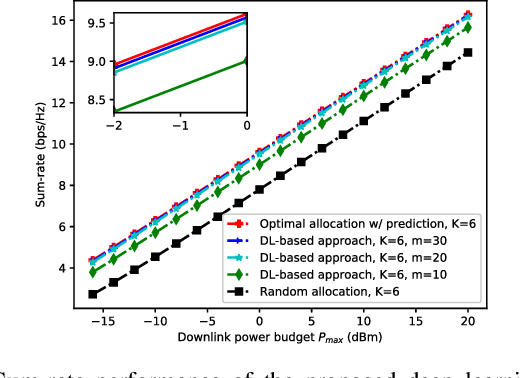
In this paper, we develop a deep learning (DL)-guided hybrid beam and power allocation approach for multiuser millimeter-wave (mmWave) networks, which facilitates swift beamforming at the base station (BS). The following persisting challenges motivated our research: (i) User and vehicular mobility, as well as redundant beam-reselections in mmWave networks, degrade the efficiency; (ii) Due to the large beamforming dimension at the BS, the beamforming weights predicted by the cutting-edge DL-based methods often do not suit the channel distributions; (iii) Co-located user devices may cause a severe beam conflict, thus deteriorating system performance. To address the aforementioned challenges, we exploit the synergy of supervised learning and super-resolution technology to enable low-overhead beam- and power allocation. In the first step, we propose a method for beam-quality prediction. It is based on deep learning and explores the relationship between high- and low-resolution beam images (energy). Afterward, we develop a DL-based allocation approach, which enables high-accuracy beam and power allocation with only a portion of the available time-sequential low-resolution images. Theoretical and numerical results verify the effectiveness of our proposed
Can't Touch This: Real-Time, Safe Motion Planning and Control for Manipulators Under Uncertainty
Jan 30, 2023
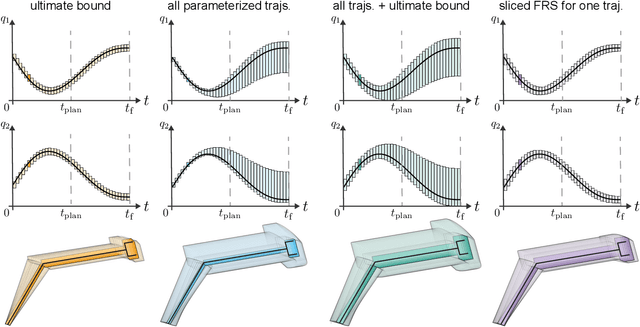
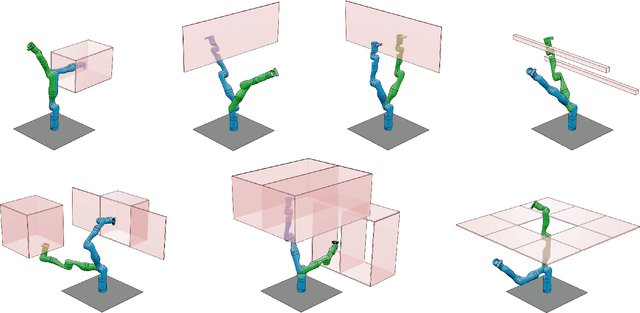
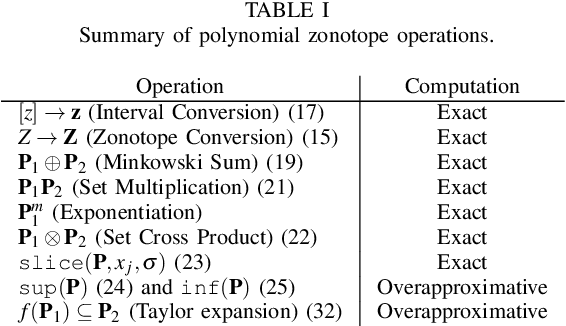
A key challenge to the widespread deployment of robotic manipulators is the need to ensure safety in arbitrary environments while generating new motion plans in real-time. In particular, one must ensure that a manipulator does not collide with obstacles, collide with itself, or exceed its joint torque limits. This challenge is compounded by the need to account for uncertainty in the mass and inertia of manipulated objects, and potentially the robot itself. The present work addresses this challenge by proposing Autonomous Robust Manipulation via Optimization with Uncertainty-aware Reachability (ARMOUR), a provably-safe, receding-horizon trajectory planner and tracking controller framework for serial link manipulators. ARMOUR works by first constructing a robust, passivity-based controller that is proven to enable a manipulator to track desired trajectories with bounded error despite uncertain dynamics. Next, ARMOUR uses a novel variation on the Recursive Newton-Euler Algorithm (RNEA) to compute the set of all possible inputs required to track any trajectory within a continuum of desired trajectories. Finally, the method computes an over-approximation to the swept volume of the manipulator; this enables one to formulate an optimization problem, which can be solved in real-time, to synthesize provably-safe motion. The proposed method is compared to state of the art methods and demonstrated on a variety of challenging manipulation examples in simulation and on real hardware, such as maneuvering a dumbbell with uncertain mass around obstacles.
Unadjusted Hamiltonian MCMC with Stratified Monte Carlo Time Integration
Dec 15, 2022
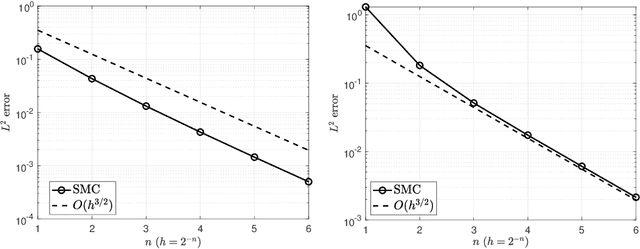
A novel randomized time integrator is suggested for unadjusted Hamiltonian Monte Carlo (uHMC) in place of the usual Verlet integrator; namely, a stratified Monte Carlo (sMC) integrator which involves a minor modification to Verlet, and hence, is easy to implement. For target distributions of the form $\mu(dx) \propto e^{-U(x)} dx$ where $U: \mathbb{R}^d \to \mathbb{R}_{\ge 0}$ is both $K$-strongly convex and $L$-gradient Lipschitz, and initial distributions $\nu$ with finite second moment, coupling proofs reveal that an $\varepsilon$-accurate approximation of the target distribution $\mu$ in $L^2$-Wasserstein distance $\boldsymbol{\mathcal{W}}^2$ can be achieved by the uHMC algorithm with sMC time integration using $O\left((d/K)^{1/3} (L/K)^{5/3} \varepsilon^{-2/3} \log( \boldsymbol{\mathcal{W}}^2(\mu, \nu) / \varepsilon)^+\right)$ gradient evaluations; whereas without additional assumptions the corresponding complexity of the uHMC algorithm with Verlet time integration is in general $O\left((d/K)^{1/2} (L/K)^2 \varepsilon^{-1} \log( \boldsymbol{\mathcal{W}}^2(\mu, \nu) / \varepsilon)^+ \right)$. Duration randomization, which has a similar effect as partial momentum refreshment, is also treated. In this case, without additional assumptions on the target distribution, the complexity of duration-randomized uHMC with sMC time integration improves to $O\left(\max\left((d/K)^{1/4} (L/K)^{3/2} \varepsilon^{-1/2},(d/K)^{1/3} (L/K)^{4/3} \varepsilon^{-2/3} \right) \right)$ up to logarithmic factors. The improvement due to duration randomization turns out to be analogous to that of time integrator randomization.
Inverse Universal Traffic Quality -- a Criticality Metric for Crowded Urban Traffic Scenes
Apr 21, 2023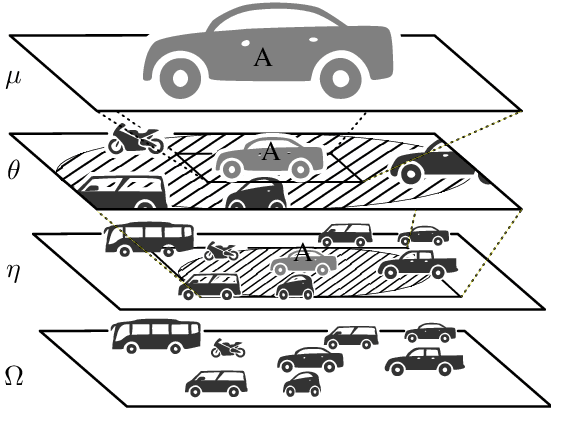
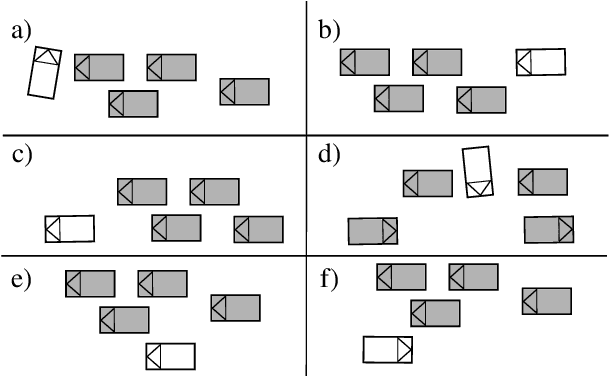
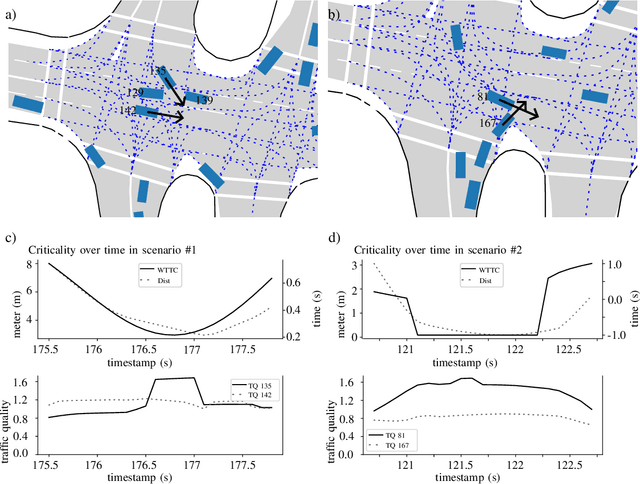
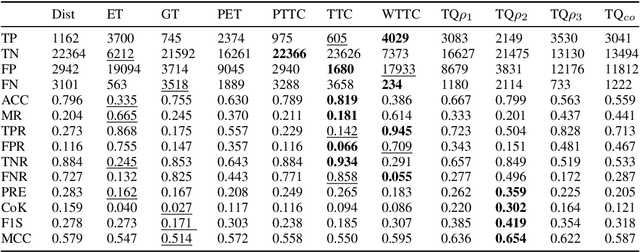
An essential requirement for scenario-based testing the identification of critical scenes and their associated scenarios. However, critical scenes, such as collisions, occur comparatively rarely. Accordingly, large amounts of data must be examined. A further issue is that recorded real-world traffic often consists of scenes with a high number of vehicles, and it can be challenging to determine which are the most critical vehicles regarding the safety of an ego vehicle. Therefore, we present the inverse universal traffic quality, a criticality metric for urban traffic independent of predefined adversary vehicles and vehicle constellations such as intersection trajectories or car-following scenarios. Our metric is universally applicable for different urban traffic situations, e.g., intersections or roundabouts, and can be adjusted to certain situations if needed. Additionally, in this paper, we evaluate the proposed metric and compares its result to other well-known criticality metrics of this field, such as time-to-collision or post-encroachment time.
A Supervisory Learning Control Framework for Autonomous & Real-time Task Planning for an Underactuated Cooperative Robotic task
Feb 22, 2023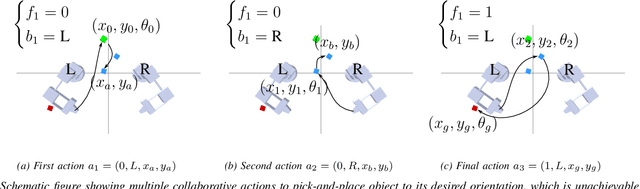
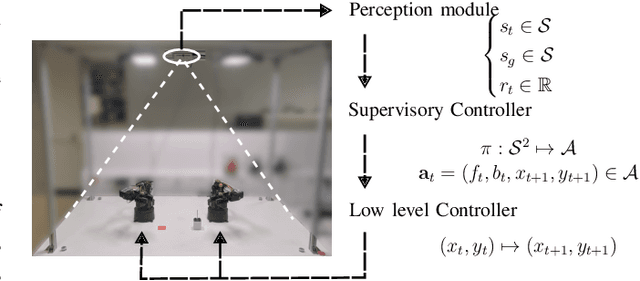
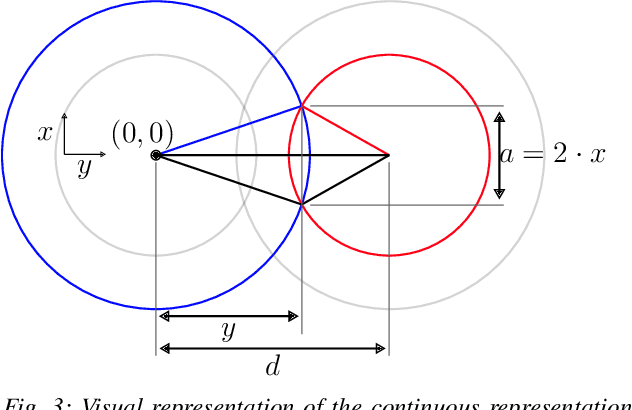
We introduce a framework for cooperative manipulation, applied on an underactuated manipulation problem. Two stationary robotic manipulators are required to cooperate in order to reposition an object within their shared work space. Control of multi-agent systems for manipulation tasks cannot rely on individual control strategies with little to no communication between the agents that serve the common objective through swarming. Instead a coordination strategy is required that queries subtasks to the individual agents. We formulate the problem in a Task And Motion Planning (TAMP) setting, while considering a decomposition strategy that allows us to treat the task and motion planning problems separately. We solve the supervisory planning problem offline using deep Reinforcement Learning techniques resulting into a supervisory policy capable of coordinating the two manipulators into a successful execution of the pick-and-place task. Additionally, a benefit of solving the task planning problem offline is the possibility of real-time (re)planning, demonstrating robustness in the event of subtask execution failure or on-the-fly task changes. The framework achieved zero-shot deployment on the real setup with a success rate that is higher than 90%.
Physics-Informed Localized Learning for Advection-Diffusion-Reaction Systems
May 05, 2023

The global push for new energy solutions, such as Geothermal, and Carbon Capture and Sequestration initiatives has thrust new demands upon the current state-of the-art subsurface fluid simulators. The requirement to be able to simulate a large order of reservoir states simultaneously in a short period of time has opened the door of opportunity for the application of machine learning techniques for surrogate modelling. We propose a novel physics-informed and boundary conditions-aware Localized Learning method which extends the Embed-to-Control (E2C) and Embed-to-Control and Observed (E2CO) models to learn local representations of global state variables in an Advection-Diffusion Reaction system. We show that our model trained on reservoir simulation data is able to predict future states of the system, given a set of controls, to a great deal of accuracy with only a fraction of the available information, while also reducing training times significantly compared to the original E2C and E2CO models.
Video alignment using unsupervised learning of local and global features
Apr 13, 2023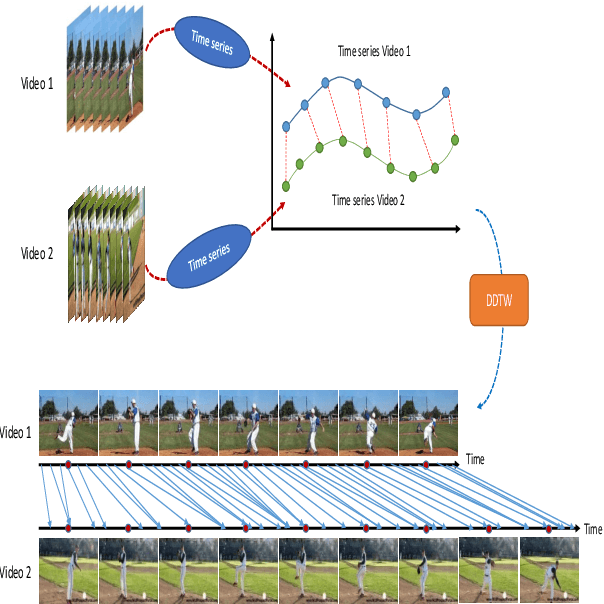
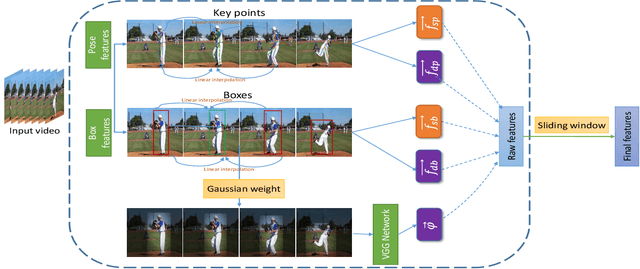
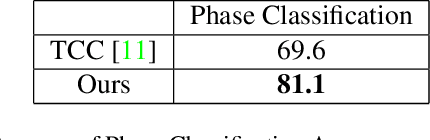
In this paper, we tackle the problem of video alignment, the process of matching the frames of a pair of videos containing similar actions. The main challenge in video alignment is that accurate correspondence should be established despite the differences in the execution processes and appearances between the two videos. We introduce an unsupervised method for alignment that uses global and local features of the frames. In particular, we introduce effective features for each video frame by means of three machine vision tools: person detection, pose estimation, and VGG network. Then the features are processed and combined to construct a multidimensional time series that represent the video. The resulting time series are used to align videos of the same actions using a novel version of dynamic time warping named Diagonalized Dynamic Time Warping(DDTW). The main advantage of our approach is that no training is required, which makes it applicable for any new type of action without any need to collect training samples for it. For evaluation, we considered video synchronization and phase classification tasks on the Penn action dataset. Also, for an effective evaluation of the video synchronization task, we present a new metric called Enclosed Area Error(EAE). The results show that our method outperforms previous state-of-the-art methods, such as TCC and other self-supervised and supervised methods.
Deep reinforcement learning applied to an assembly sequence planning problem with user preferences
Apr 13, 2023Deep reinforcement learning (DRL) has demonstrated its potential in solving complex manufacturing decision-making problems, especially in a context where the system learns over time with actual operation in the absence of training data. One interesting and challenging application for such methods is the assembly sequence planning (ASP) problem. In this paper, we propose an approach to the implementation of DRL methods in ASP. The proposed approach introduces in the RL environment parametric actions to improve training time and sample efficiency and uses two different reward signals: (1) user's preferences and (2) total assembly time duration. The user's preferences signal addresses the difficulties and non-ergonomic properties of the assembly faced by the human and the total assembly time signal enforces the optimization of the assembly. Three of the most powerful deep RL methods were studied, Advantage Actor-Critic (A2C), Deep Q-Learning (DQN), and Rainbow, in two different scenarios: a stochastic and a deterministic one. Finally, the performance of the DRL algorithms was compared to tabular Q-Learnings performance. After 10,000 episodes, the system achieved near optimal behaviour for the algorithms tabular Q-Learning, A2C, and Rainbow. Though, for more complex scenarios, the algorithm tabular Q-Learning is expected to underperform in comparison to the other 2 algorithms. The results support the potential for the application of deep reinforcement learning in assembly sequence planning problems with human interaction.
T-SciQ: Teaching Multimodal Chain-of-Thought Reasoning via Large Language Model Signals for Science Question Answering
May 09, 2023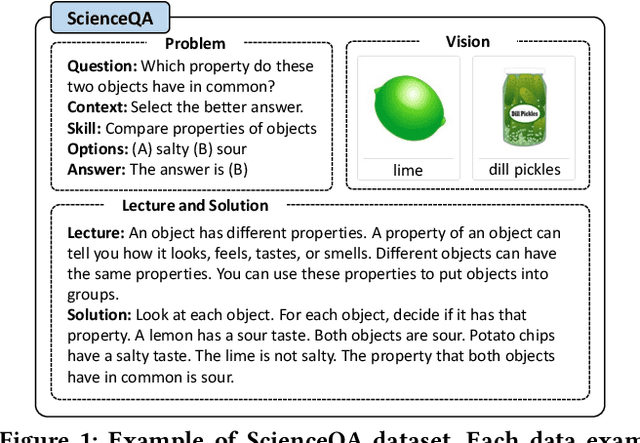
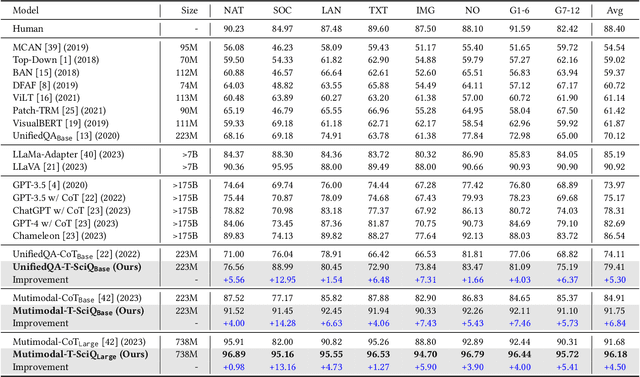
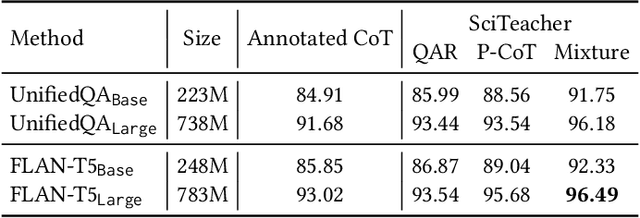
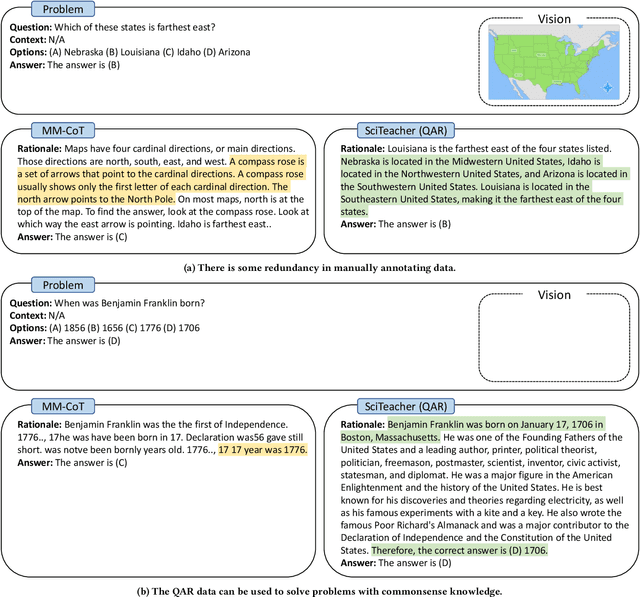
Large Language Models (LLMs) have recently demonstrated exceptional performance in various Natural Language Processing (NLP) tasks. They have also shown the ability to perform chain-of-thought (CoT) reasoning to solve complex problems. Recent studies have explored CoT reasoning in complex multimodal scenarios, such as the science question answering task, by fine-tuning multimodal models with high-quality human-annotated CoT rationales. However, collecting high-quality COT rationales is usually time-consuming and costly. Besides, the annotated rationales are hardly accurate due to the redundant information involved or the essential information missed. To address these issues, we propose a novel method termed \emph{T-SciQ} that aims at teaching science question answering with LLM signals. The T-SciQ approach generates high-quality CoT rationales as teaching signals and is advanced to train much smaller models to perform CoT reasoning in complex modalities. Additionally, we introduce a novel data mixing strategy to produce more effective teaching data samples for simple and complex science question answer problems. Extensive experimental results show that our T-SciQ method achieves a new state-of-the-art performance on the ScienceQA benchmark, with an accuracy of 96.18%. Moreover, our approach outperforms the most powerful fine-tuned baseline by 4.5%.