 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Multi-Objective Evolutionary Neural Architecture Search for Recurrent Neural Networks
Mar 17, 2024
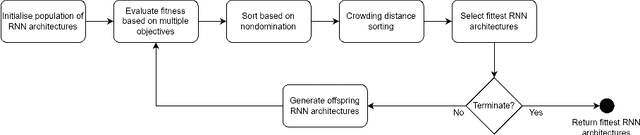
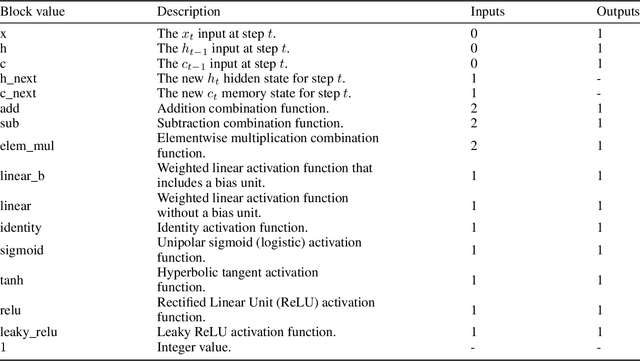
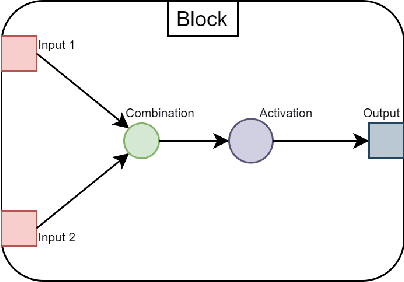
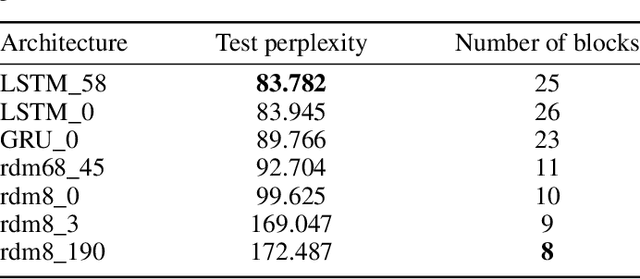
Artificial neural network (NN) architecture design is a nontrivial and time-consuming task that often requires a high level of human expertise. Neural architecture search (NAS) serves to automate the design of NN architectures and has proven to be successful in automatically finding NN architectures that outperform those manually designed by human experts. NN architecture performance can be quantified based on multiple objectives, which include model accuracy and some NN architecture complexity objectives, among others. The majority of modern NAS methods that consider multiple objectives for NN architecture performance evaluation are concerned with automated feed forward NN architecture design, which leaves multi-objective automated recurrent neural network (RNN) architecture design unexplored. RNNs are important for modeling sequential datasets, and prominent within the natural language processing domain. It is often the case in real world implementations of machine learning and NNs that a reasonable trade-off is accepted for marginally reduced model accuracy in favour of lower computational resources demanded by the model. This paper proposes a multi-objective evolutionary algorithm-based RNN architecture search method. The proposed method relies on approximate network morphisms for RNN architecture complexity optimisation during evolution. The results show that the proposed method is capable of finding novel RNN architectures with comparable performance to state-of-the-art manually designed RNN architectures, but with reduced computational demand.
Resilient Fleet Management for Energy-Aware Intra-Factory Logistics
Mar 16, 2024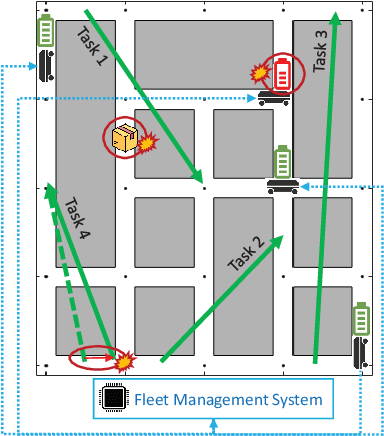
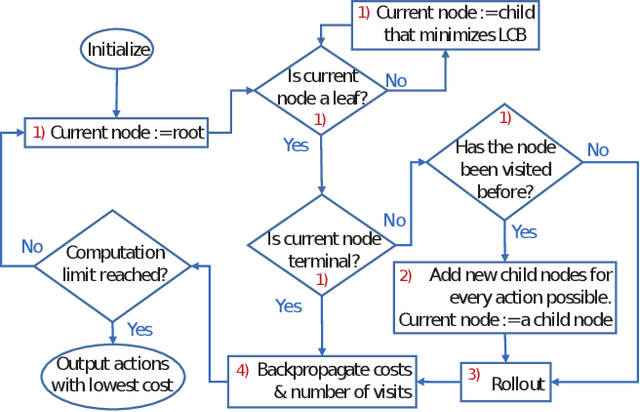
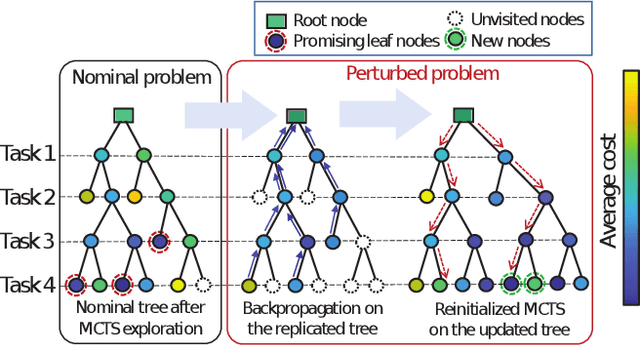
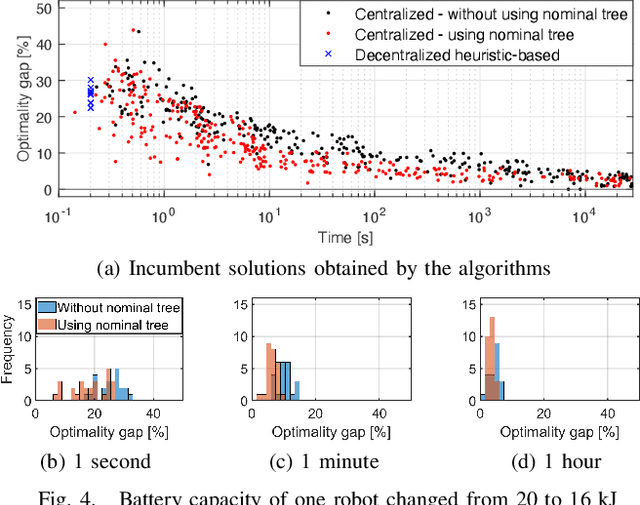
This paper presents a novel fleet management strategy for battery-powered robot fleets tasked with intra-factory logistics in an autonomous manufacturing facility. In this environment, repetitive material handling operations are subject to real-world uncertainties such as blocked passages, and equipment or robot malfunctions. In such cases, centralized approaches enhance resilience by immediately adjusting the task allocation between the robots. To overcome the computational expense, a two-step methodology is proposed where the nominal problem is solved a priori using a Monte Carlo Tree Search algorithm for task allocation, resulting in a nominal search tree. When a disruption occurs, the nominal search tree is rapidly updated a posteriori with costs to the new problem while simultaneously generating feasible solutions. Computational experiments prove the real-time capability of the proposed algorithm for various scenarios and compare it with the case where the search tree is not used and the decentralized approach that does not attempt task reassignment.
Pre-Trained Language Models Represent Some Geographic Populations Better Than Others
Mar 16, 2024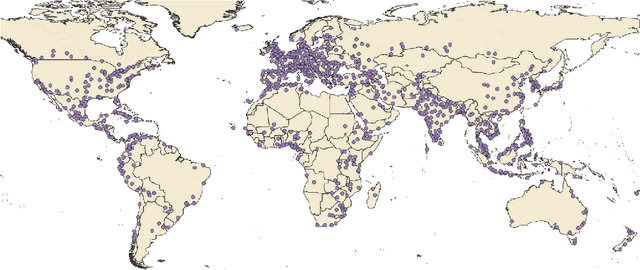
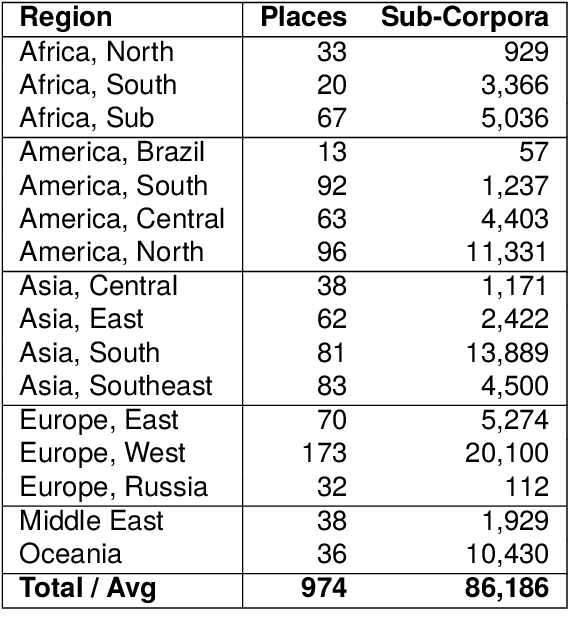
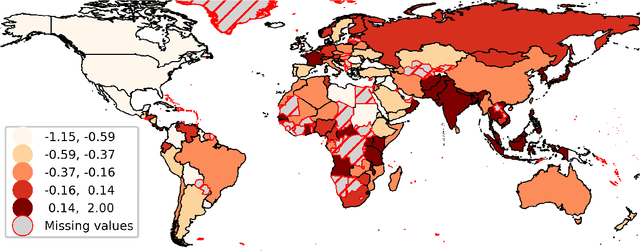
This paper measures the skew in how well two families of LLMs represent diverse geographic populations. A spatial probing task is used with geo-referenced corpora to measure the degree to which pre-trained language models from the OPT and BLOOM series represent diverse populations around the world. Results show that these models perform much better for some populations than others. In particular, populations across the US and the UK are represented quite well while those in South and Southeast Asia are poorly represented. Analysis shows that both families of models largely share the same skew across populations. At the same time, this skew cannot be fully explained by sociolinguistic factors, economic factors, or geographic factors. The basic conclusion from this analysis is that pre-trained models do not equally represent the world's population: there is a strong skew towards specific geographic populations. This finding challenges the idea that a single model can be used for all populations.
End-to-End Amp Modeling: From Data to Controllable Guitar Amplifier Models
Mar 13, 2024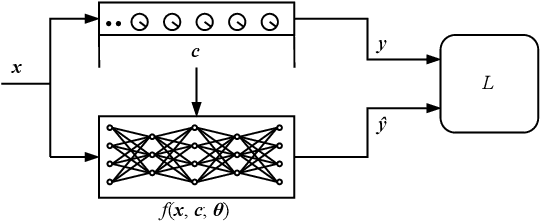
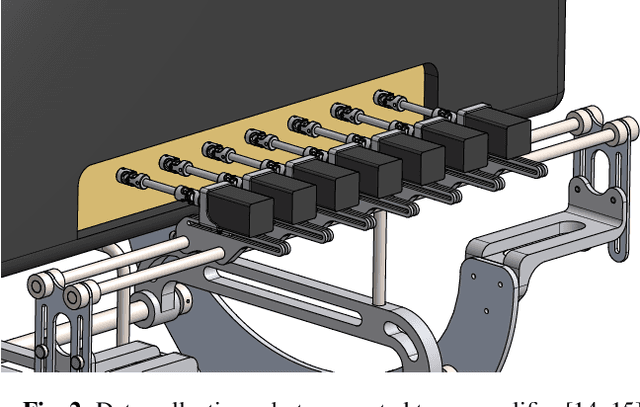
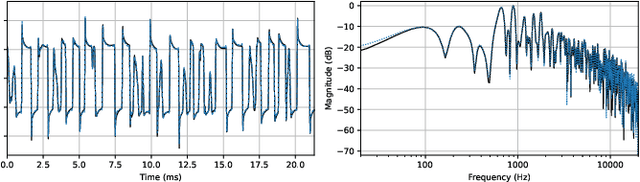
This paper describes a data-driven approach to creating real-time neural network models of guitar amplifiers, recreating the amplifiers' sonic response to arbitrary inputs at the full range of controls present on the physical device. While the focus on the paper is on the data collection pipeline, we demonstrate the effectiveness of this conditioned black-box approach by training an LSTM model to the task, and comparing its performance to an offline white-box SPICE circuit simulation. Our listening test results demonstrate that the neural amplifier modeling approach can match the subjective performance of a high-quality SPICE model, all while using an automated, non-intrusive data collection process, and an end-to-end trainable, real-time feasible neural network model.
Generalization of Scaled Deep ResNets in the Mean-Field Regime
Mar 14, 2024
Despite the widespread empirical success of ResNet, the generalization properties of deep ResNet are rarely explored beyond the lazy training regime. In this work, we investigate \emph{scaled} ResNet in the limit of infinitely deep and wide neural networks, of which the gradient flow is described by a partial differential equation in the large-neural network limit, i.e., the \emph{mean-field} regime. To derive the generalization bounds under this setting, our analysis necessitates a shift from the conventional time-invariant Gram matrix employed in the lazy training regime to a time-variant, distribution-dependent version. To this end, we provide a global lower bound on the minimum eigenvalue of the Gram matrix under the mean-field regime. Besides, for the traceability of the dynamic of Kullback-Leibler (KL) divergence, we establish the linear convergence of the empirical error and estimate the upper bound of the KL divergence over parameters distribution. Finally, we build the uniform convergence for generalization bound via Rademacher complexity. Our results offer new insights into the generalization ability of deep ResNet beyond the lazy training regime and contribute to advancing the understanding of the fundamental properties of deep neural networks.
Synchronisation-Oriented Design Approach for Adaptive Control
Mar 14, 2024
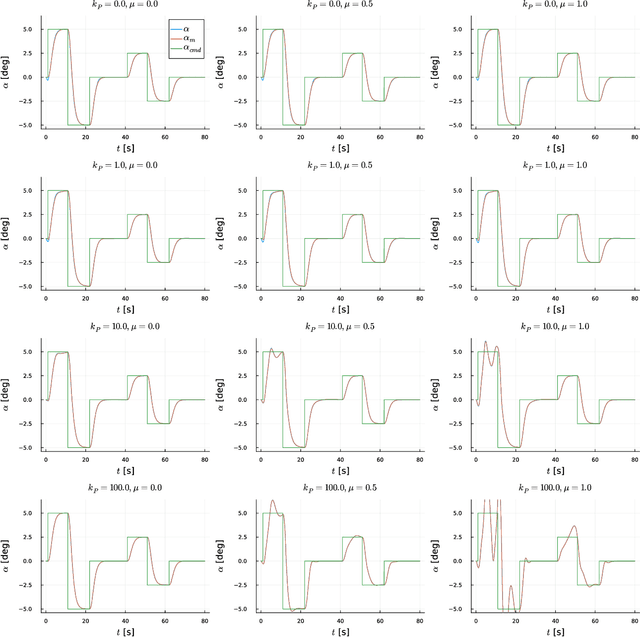
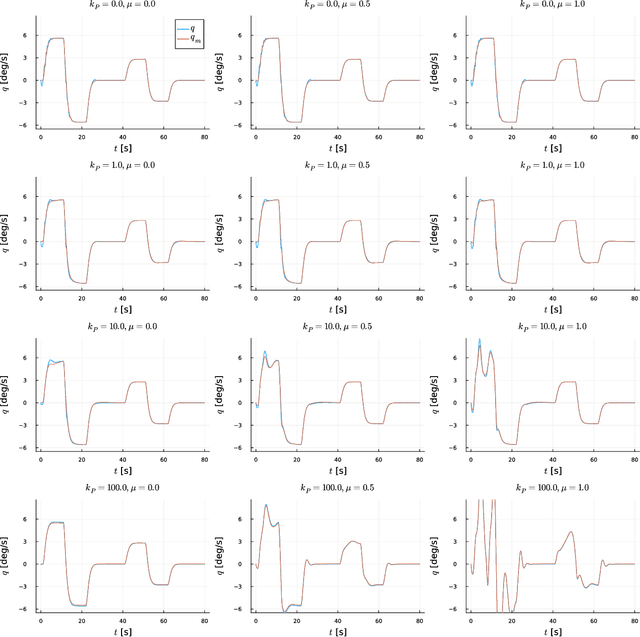
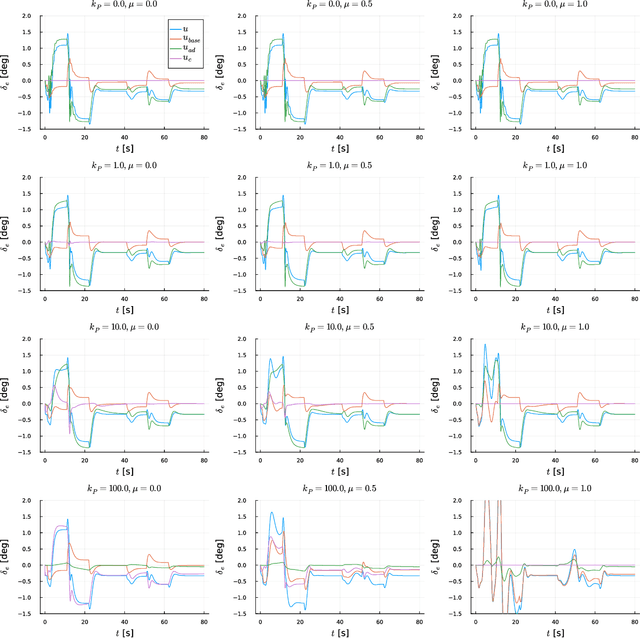
This study presents a synchronisation-oriented perspective towards adaptive control which views model-referenced adaptation as synchronisation between actual and virtual dynamic systems. In the context of adaptation, model reference adaptive control methods make the state response of the actual plant follow a reference model. In the context of synchronisation, consensus methods involving diffusive coupling induce a collective behaviour across multiple agents. We draw from the understanding about the two time-scale nature of synchronisation motivated by the study of blended dynamics. The synchronisation-oriented approach consists in the design of a coupling input to achieve desired closed-loop error dynamics followed by the input allocation process to shape the collective behaviour. We suggest that synchronisation can be a reasonable design principle allowing a more holistic and systematic approach to the design of adaptive control systems for improved transient characteristics. Most notably, the proposed approach enables not only constructive derivation but also substantial generalisation of the previously developed closed-loop reference model adaptive control method. Practical significance of the proposed generalisation lies at the capability to improve the transient response characteristics and mitigate the unwanted peaking phenomenon at the same time.
Optimistic Verifiable Training by Controlling Hardware Nondeterminism
Mar 14, 2024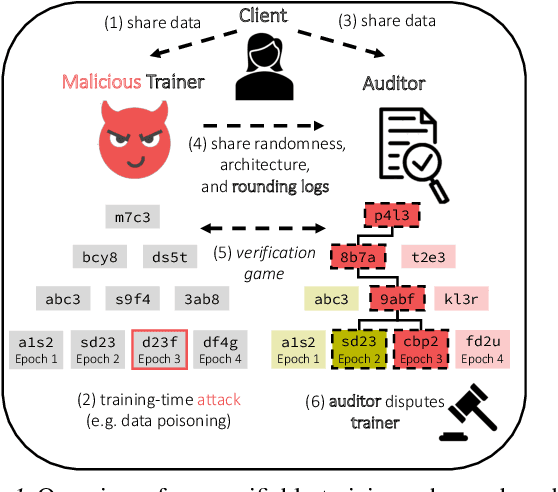



The increasing compute demands of AI systems has led to the emergence of services that train models on behalf of clients lacking necessary resources. However, ensuring correctness of training and guarding against potential training-time attacks, such as data poisoning, poses challenges. Existing works on verifiable training largely fall into two classes: proof-based systems, which struggle to scale due to requiring cryptographic techniques, and "optimistic" methods that consider a trusted third-party auditor who replicates the training process. A key challenge with the latter is that hardware nondeterminism between GPU types during training prevents an auditor from replicating the training process exactly, and such schemes are therefore non-robust. We propose a method that combines training in a higher precision than the target model, rounding after intermediate computation steps, and storing rounding decisions based on an adaptive thresholding procedure, to successfully control for nondeterminism. Across three different NVIDIA GPUs (A40, Titan XP, RTX 2080 Ti), we achieve exact training replication at FP32 precision for both full-training and fine-tuning of ResNet-50 (23M) and GPT-2 (117M) models. Our verifiable training scheme significantly decreases the storage and time costs compared to proof-based systems.
CDGP: Automatic Cloze Distractor Generation based on Pre-trained Language Model
Mar 15, 2024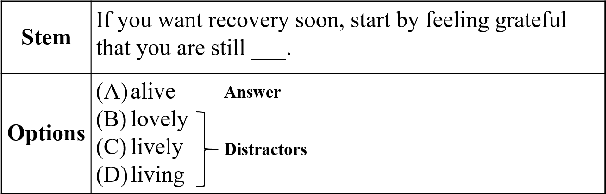
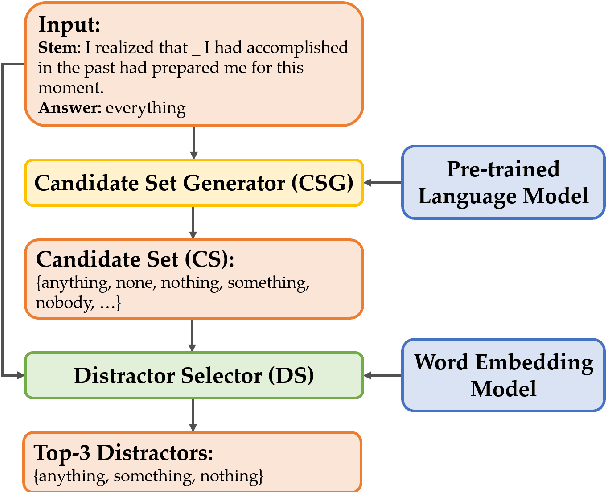
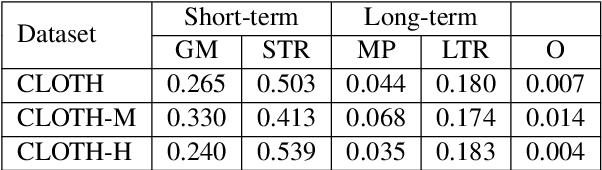
Manually designing cloze test consumes enormous time and efforts. The major challenge lies in wrong option (distractor) selection. Having carefully-design distractors improves the effectiveness of learner ability assessment. As a result, the idea of automatically generating cloze distractor is motivated. In this paper, we investigate cloze distractor generation by exploring the employment of pre-trained language models (PLMs) as an alternative for candidate distractor generation. Experiments show that the PLM-enhanced model brings a substantial performance improvement. Our best performing model advances the state-of-the-art result from 14.94 to 34.17 (NDCG@10 score). Our code and dataset is available at https://github.com/AndyChiangSH/CDGP.
* Findings of short paper, EMNLP 2022
Scalable Algorithms for Individual Preference Stable Clustering
Mar 15, 2024In this paper, we study the individual preference (IP) stability, which is an notion capturing individual fairness and stability in clustering. Within this setting, a clustering is $\alpha$-IP stable when each data point's average distance to its cluster is no more than $\alpha$ times its average distance to any other cluster. In this paper, we study the natural local search algorithm for IP stable clustering. Our analysis confirms a $O(\log n)$-IP stability guarantee for this algorithm, where $n$ denotes the number of points in the input. Furthermore, by refining the local search approach, we show it runs in an almost linear time, $\tilde{O}(nk)$.
Ariadne and Theseus: Exploration and Rendezvous with Two Mobile Agents in an Unknown Graph
Mar 12, 2024
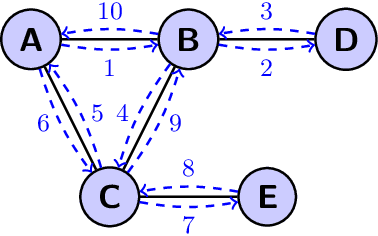
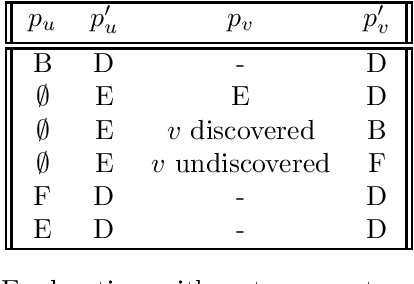
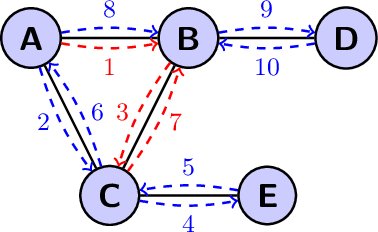
We investigate two fundamental problems in mobile computing: exploration and rendezvous, with two distinct mobile agents in an unknown graph. The agents can read and write information on whiteboards that are located at all nodes. They both move along one adjacent edge at every time-step. In the exploration problem, both agents start from the same node of the graph and must traverse all of its edges. We show that a simple variant of depth-first search achieves collective exploration in $m$ synchronous time-steps, where $m$ is the number of edges of the graph. This improves the competitive ratio of collective graph exploration. In the rendezvous problem, the agents start from different nodes of the graph and must meet as fast as possible. We introduce an algorithm guaranteeing rendezvous in at most $\frac{3}{2}m$ time-steps. This improves over the so-called `wait for Mommy' algorithm which requires $2m$ time-steps. All our guarantees are derived from a more general asynchronous setting in which the speeds of the agents are controlled by an adversary at all times. Our guarantees also generalize to weighted graphs, if the number of edges $m$ is replaced by the sum of all edge lengths.