 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Test-Time Amendment with a Coarse Classifier for Fine-Grained Classification
Feb 01, 2023

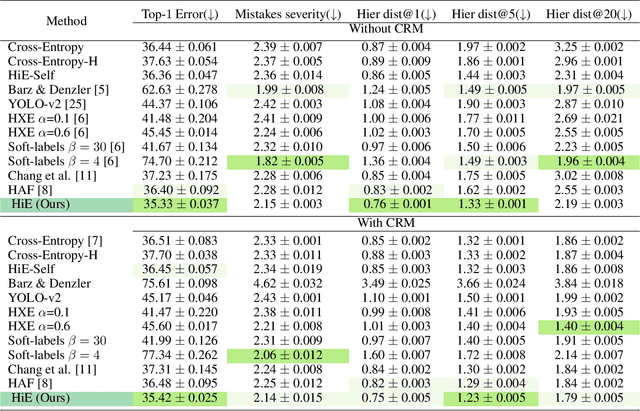
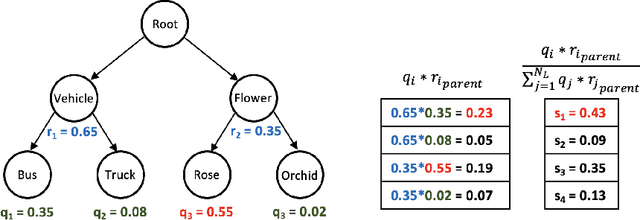
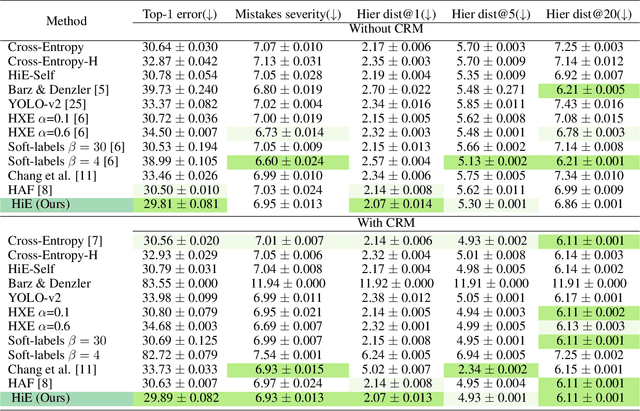
We investigate the problem of reducing mistake severity for fine-grained classification. Fine-grained classification can be challenging, mainly due to the requirement of knowledge or domain expertise for accurate annotation. However, humans are particularly adept at performing coarse classification as it requires relatively low levels of expertise. To this end, we present a novel approach for Post-Hoc Correction called Hierarchical Ensembles (HiE) that utilizes label hierarchy to improve the performance of fine-grained classification at test-time using the coarse-grained predictions. By only requiring the parents of leaf nodes, our method significantly reduces avg. mistake severity while improving top-1 accuracy on the iNaturalist-19 and tieredImageNet-H datasets, achieving a new state-of-the-art on both benchmarks. We also investigate the efficacy of our approach in the semi-supervised setting. Our approach brings notable gains in top-1 accuracy while significantly decreasing the severity of mistakes as training data decreases for the fine-grained classes. The simplicity and post-hoc nature of HiE render it practical to be used with any off-the-shelf trained model to improve its predictions further.
Stationarity Evaluation of High-mobility sub-6 GHz and mmWave non-WSSUS Channels
Apr 03, 2023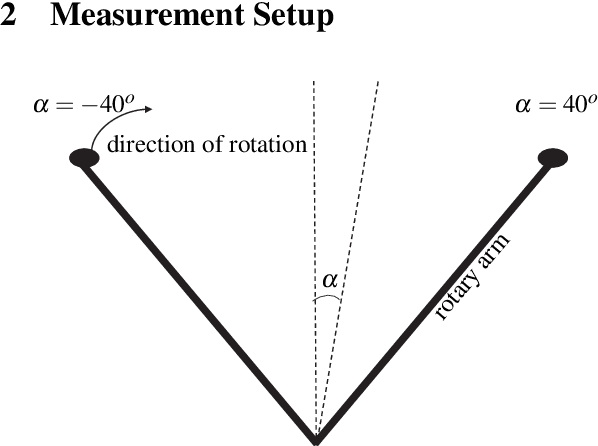
Analysis and modeling of wireless communication systems are dependent on the validity of the wide-sense stationarity uncorrelated scattering (WSSUS) assumption. However, in high-mobility scenarios, the WSSUS assumption is approximately fulfilled just over a short time period. This paper focuses on the stationarity evaluation of high-mobility multi-band channels. We evaluate the stationarity time, the time over which WSSUS is fulfilled approximately. The investigation is performed over real, measured high-mobility channels for two frequency bands, 2.55 and 25.5 GHz. Furthermore, we demonstrate the influence of the user velocity on the stationarity time. We show that the stationarity time decreases with increased relative velocity between the transmitter and the receiver. Furthermore, we show the similarity of the stationarity regions between sub-6 GHz and mmWave channels. Finally, we demonstrate that the sub-6 GHz channels are characterized by longer stationarity time.
Don't worry about mistakes! Glass Segmentation Network via Mistake Correction
Apr 21, 2023
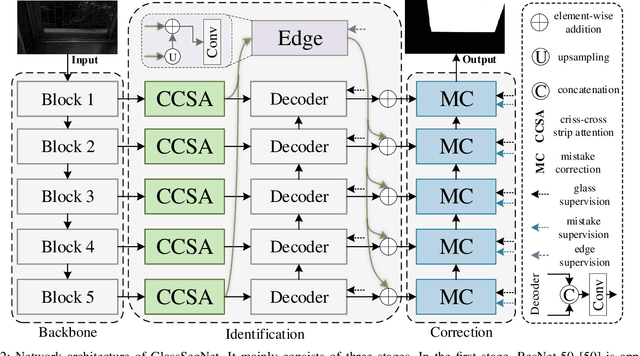
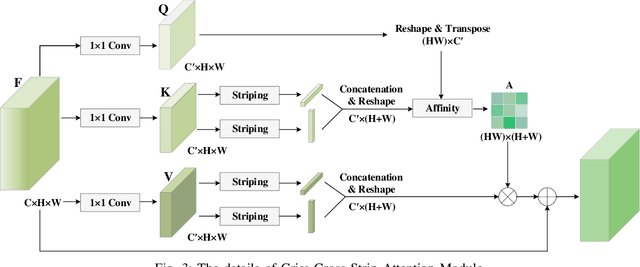
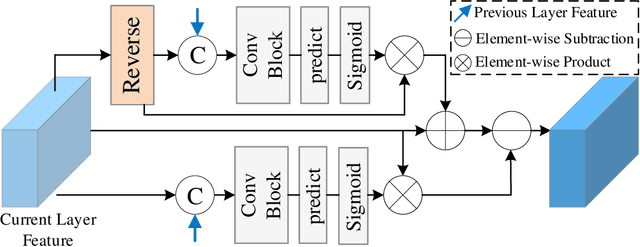
Recall one time when we were in an unfamiliar mall. We might mistakenly think that there exists or does not exist a piece of glass in front of us. Such mistakes will remind us to walk more safely and freely at the same or a similar place next time. To absorb the human mistake correction wisdom, we propose a novel glass segmentation network to detect transparent glass, dubbed GlassSegNet. Motivated by this human behavior, GlassSegNet utilizes two key stages: the identification stage (IS) and the correction stage (CS). The IS is designed to simulate the detection procedure of human recognition for identifying transparent glass by global context and edge information. The CS then progressively refines the coarse prediction by correcting mistake regions based on gained experience. Extensive experiments show clear improvements of our GlassSegNet over thirty-four state-of-the-art methods on three benchmark datasets.
Incremental 3D Semantic Scene Graph Prediction from RGB Sequences
May 06, 2023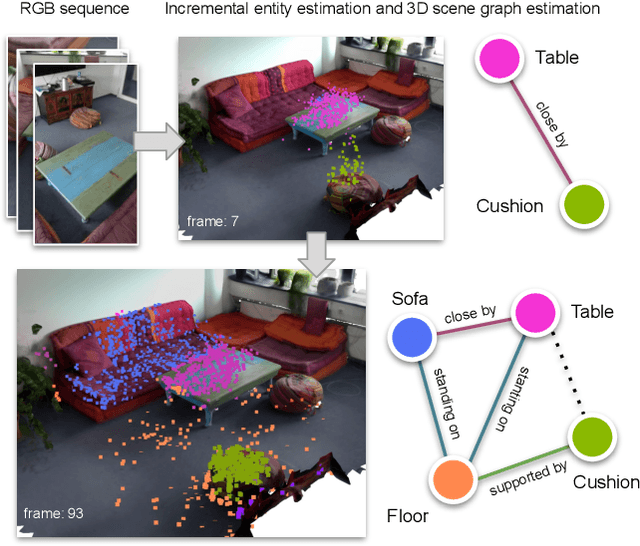
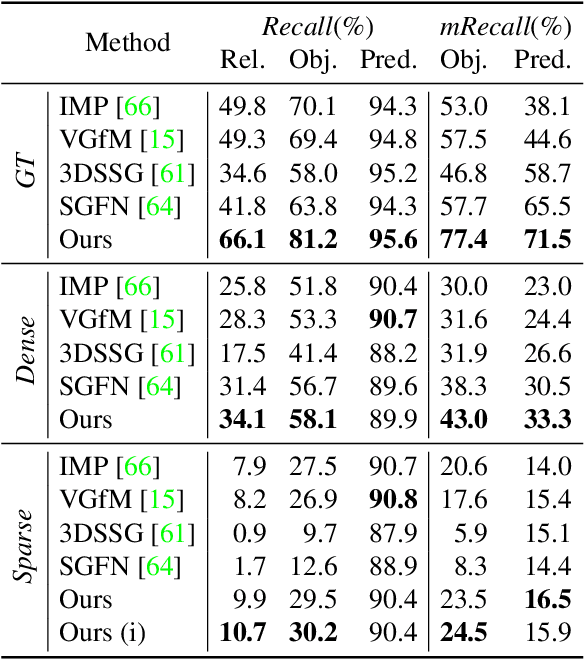
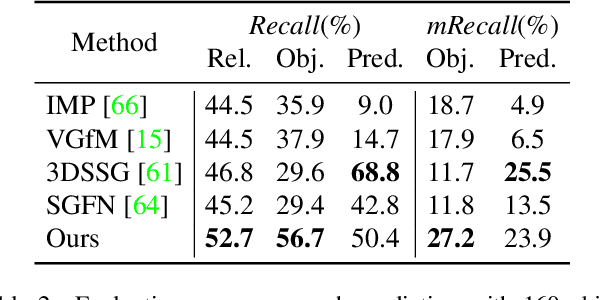
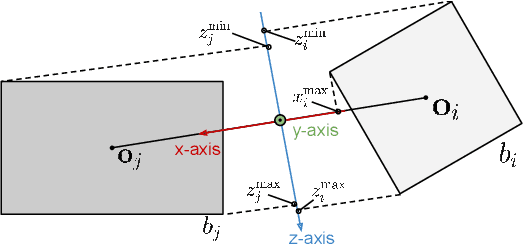
3D semantic scene graphs are a powerful holistic representation as they describe the individual objects and depict the relation between them. They are compact high-level graphs that enable many tasks requiring scene reasoning. In real-world settings, existing 3D estimation methods produce robust predictions that mostly rely on dense inputs. In this work, we propose a real-time framework that incrementally builds a consistent 3D semantic scene graph of a scene given an RGB image sequence. Our method consists of a novel incremental entity estimation pipeline and a scene graph prediction network. The proposed pipeline simultaneously reconstructs a sparse point map and fuses entity estimation from the input images. The proposed network estimates 3D semantic scene graphs with iterative message passing using multi-view and geometric features extracted from the scene entities. Extensive experiments on the 3RScan dataset show the effectiveness of the proposed method in this challenging task, outperforming state-of-the-art approaches.
Semi-Asynchronous Federated Edge Learning Mechanism via Over-the-air Computation
May 06, 2023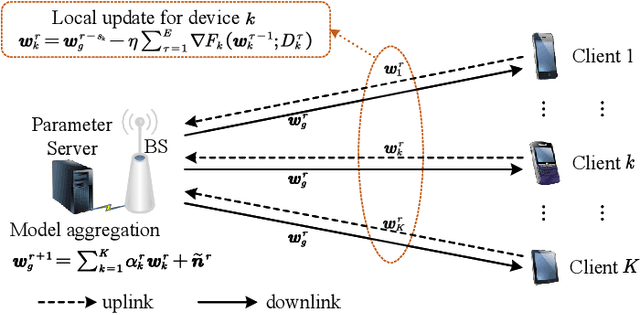
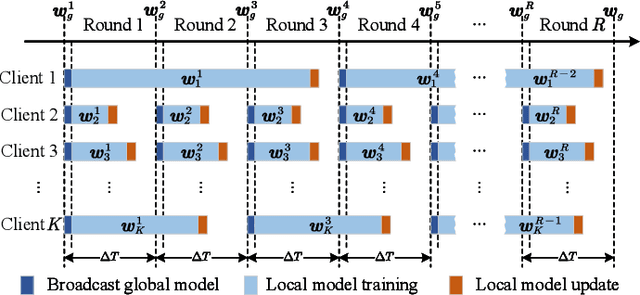
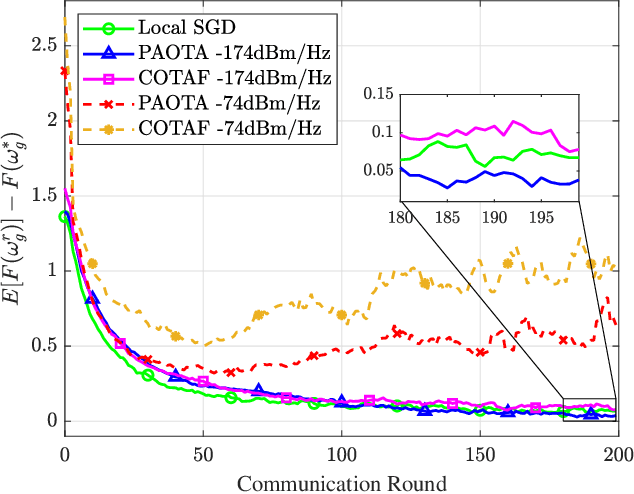
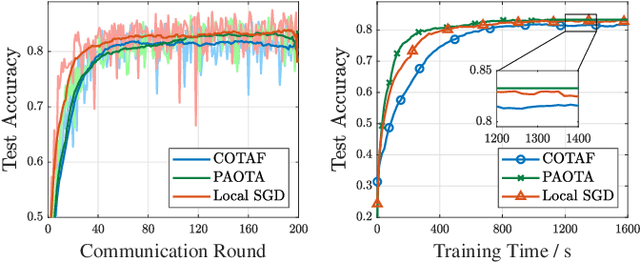
Over-the-air Computation (AirComp) has been demonstrated as an effective transmission scheme to boost the efficiency of federated edge learning (FEEL). However, existing FEEL systems with AirComp scheme often employ traditional synchronous aggregation mechanisms for local model aggregation in each global round, which suffer from the stragglers issues. In this paper, we propose a semi-asynchronous aggregation FEEL mechanism with AirComp scheme (PAOTA) to improve the training efficiency of the FEEL system in the case of significant heterogeneity in data and devices. Taking the staleness and divergence of model updates from edge devices into consideration, we minimize the convergence upper bound of the FEEL global model by adjusting the uplink transmit power of edge devices at each aggregation period. The simulation results demonstrate that our proposed algorithm achieves convergence performance close to that of the ideal Local SGD. Furthermore, with the same target accuracy, the training time required for PAOTA is less than that of the ideal Local SGD and the synchronous FEEL algorithm via AirComp.
Twin support vector quantile regression
May 06, 2023We propose a twin support vector quantile regression (TSVQR) to capture the heterogeneous and asymmetric information in modern data. Using a quantile parameter, TSVQR effectively depicts the heterogeneous distribution information with respect to all portions of data points. Correspondingly, TSVQR constructs two smaller sized quadratic programming problems (QPPs) to generate two nonparallel planes to measure the distributional asymmetry between the lower and upper bounds at each quantile level. The QPPs in TSVQR are smaller and easier to solve than those in previous quantile regression methods. Moreover, the dual coordinate descent algorithm for TSVQR also accelerates the training speed. Experimental results on six artiffcial data sets, ffve benchmark data sets, two large scale data sets, two time-series data sets, and two imbalanced data sets indicate that the TSVQR outperforms previous quantile regression methods in terms of the effectiveness of completely capturing the heterogeneous and asymmetric information and the efffciency of the learning process.
A Supervisory Learning Control Framework for Autonomous & Real-time Task Planning for an Underactuated Cooperative Robotic task
Feb 22, 2023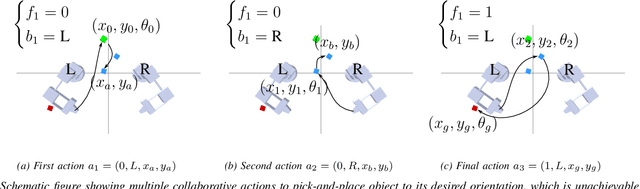
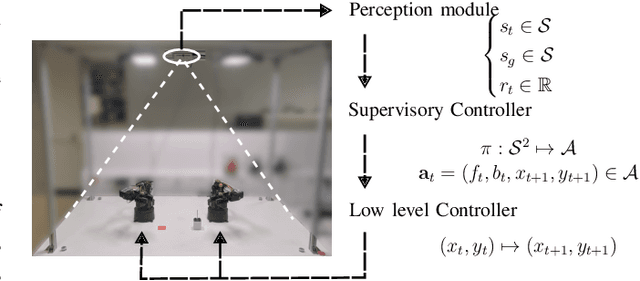
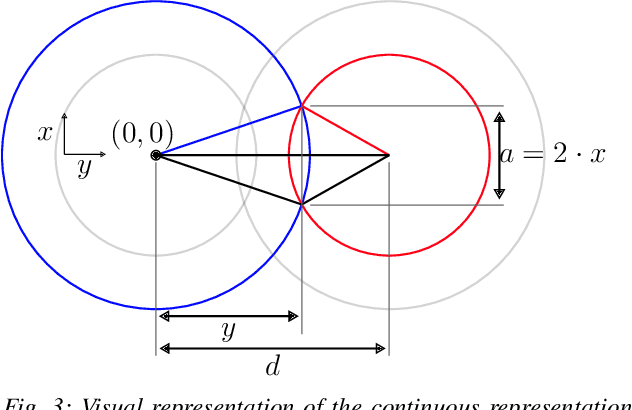
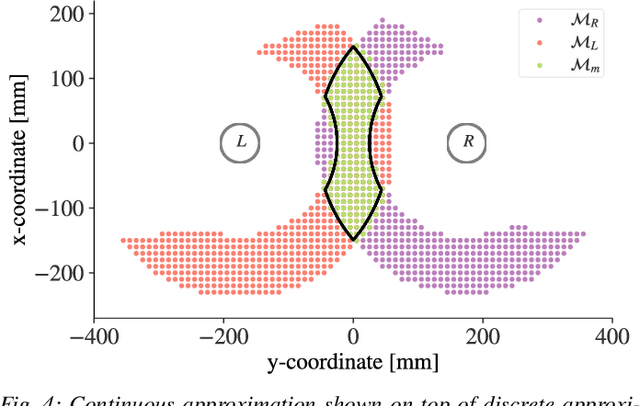
We introduce a framework for cooperative manipulation, applied on an underactuated manipulation problem. Two stationary robotic manipulators are required to cooperate in order to reposition an object within their shared work space. Control of multi-agent systems for manipulation tasks cannot rely on individual control strategies with little to no communication between the agents that serve the common objective through swarming. Instead a coordination strategy is required that queries subtasks to the individual agents. We formulate the problem in a Task And Motion Planning (TAMP) setting, while considering a decomposition strategy that allows us to treat the task and motion planning problems separately. We solve the supervisory planning problem offline using deep Reinforcement Learning techniques resulting into a supervisory policy capable of coordinating the two manipulators into a successful execution of the pick-and-place task. Additionally, a benefit of solving the task planning problem offline is the possibility of real-time (re)planning, demonstrating robustness in the event of subtask execution failure or on-the-fly task changes. The framework achieved zero-shot deployment on the real setup with a success rate that is higher than 90%.
LAPTNet-FPN: Multi-scale LiDAR-aided Projective Transform Network for Real Time Semantic Grid Prediction
Feb 10, 2023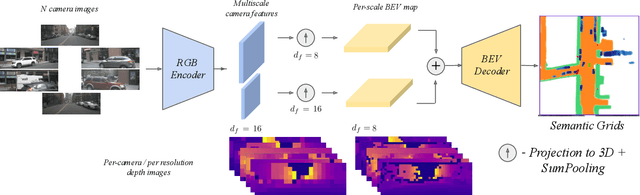

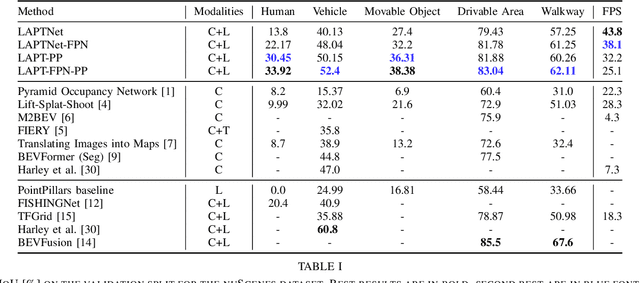
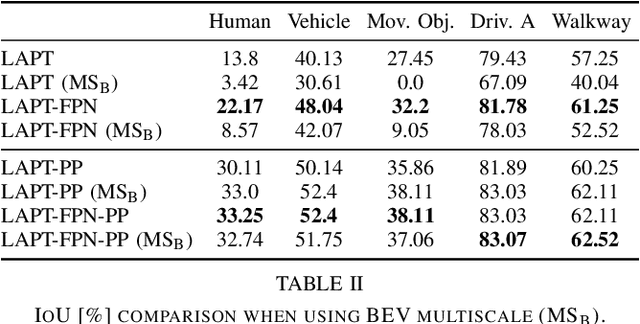
Semantic grids can be useful representations of the scene around an autonomous system. By having information about the layout of the space around itself, a robot can leverage this type of representation for crucial tasks such as navigation or tracking. By fusing information from multiple sensors, robustness can be increased and the computational load for the task can be lowered, achieving real time performance. Our multi-scale LiDAR-Aided Perspective Transform network uses information available in point clouds to guide the projection of image features to a top-view representation, resulting in a relative improvement in the state of the art for semantic grid generation for human (+8.67%) and movable object (+49.07%) classes in the nuScenes dataset, as well as achieving results close to the state of the art for the vehicle, drivable area and walkway classes, while performing inference at 25 FPS.
Laplacian Convolutional Representation for Traffic Time Series Imputation
Dec 03, 2022
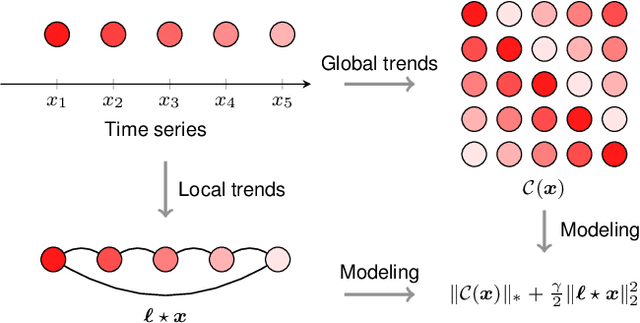
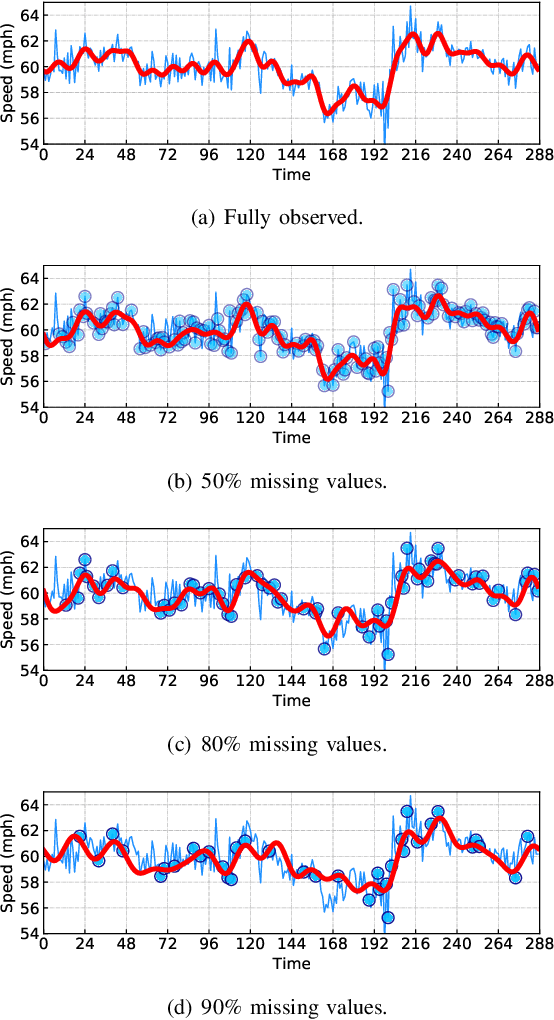
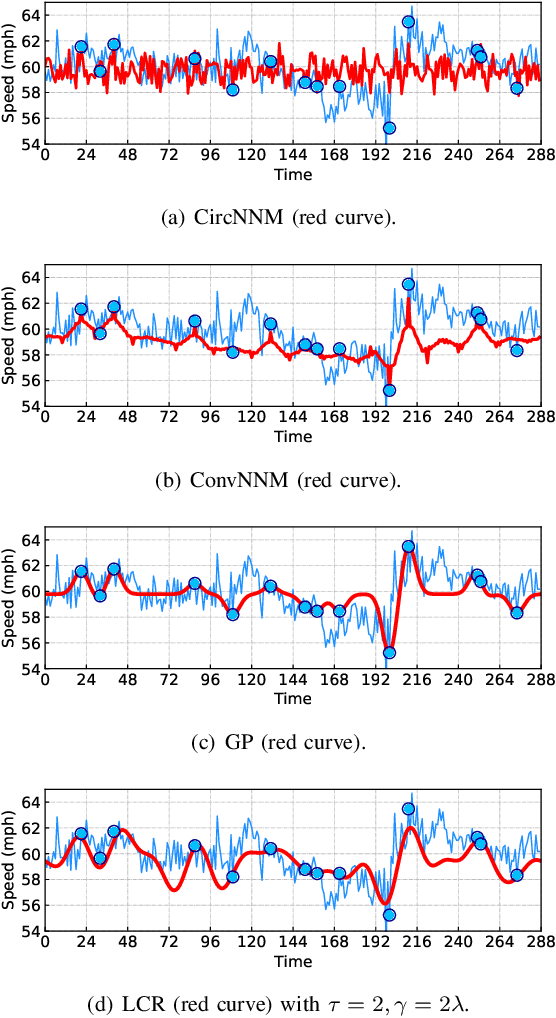
Spatiotemporal traffic data imputation is of great significance in intelligent transportation systems and data-driven decision-making processes. To make an accurate reconstruction on partially observed traffic data, we assert the importance of characterizing both global and local trends in traffic time series. In the literature, substantial prior works have demonstrated the effectiveness of utilizing low-rankness property of traffic data by matrix/tensor completion models. In this study, we first introduce a Laplacian kernel to temporal regularization for characterizing local trends in traffic time series, which can be formulated in the form of circular convolution. Then, we develop a low-rank Laplacian convolutional representation (LCR) model by putting the nuclear norm of a circulant matrix and the Laplacian temporal regularization together, which is proved to meet a unified framework that takes a fast Fourier transform solution in a relatively low time complexity. Through extensive experiments on some traffic datasets, we demonstrate the superiority of LCR for imputing traffic time series of various time series behaviors (e.g., data noises and strong/weak periodicity). The proposed LCR model is an efficient and effective solution to large-scale traffic data imputation over the existing baseline models. The adapted datasets and Python implementation are publicly available at https://github.com/xinychen/transdim.
Provably Stabilizing Global-Position Tracking Control for Hybrid Models of Multi-Domain Bipedal Walking via Multiple Lyapunov Analysis
Apr 27, 2023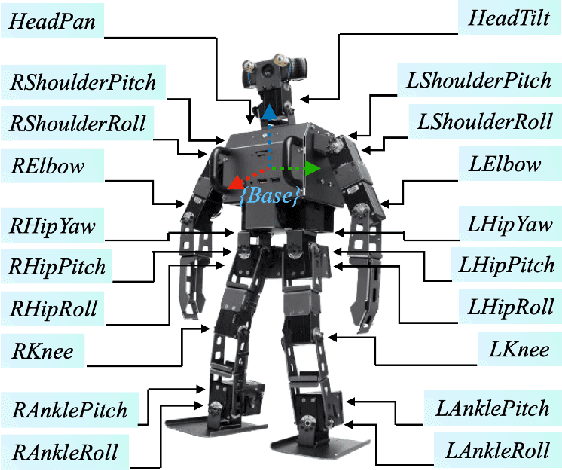
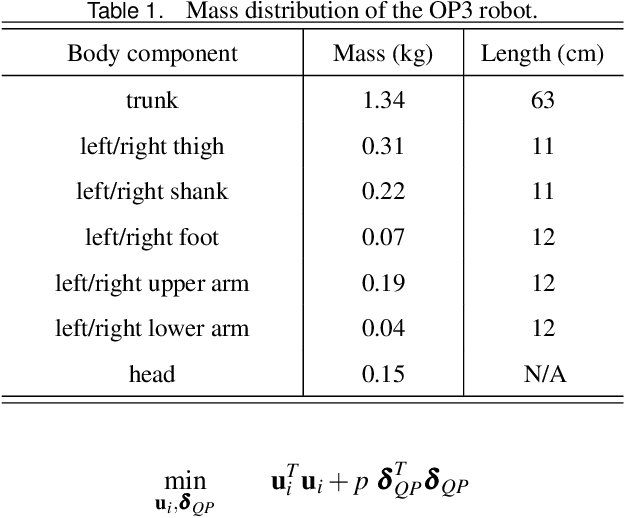
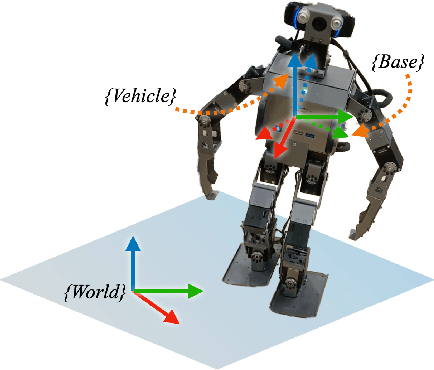
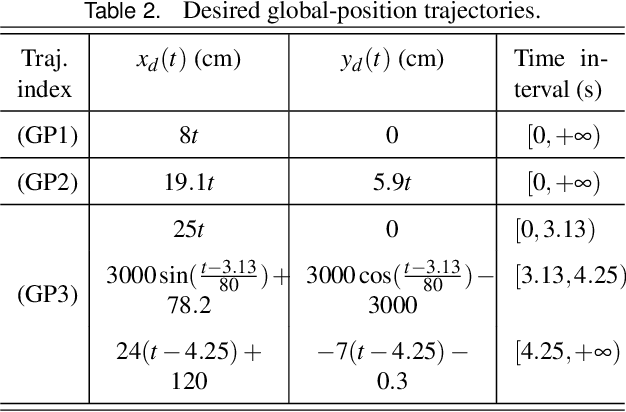
Accurate control of a humanoid robot's global position (i.e., its three-dimensional position in the world) is critical to the reliable execution of high-risk tasks such as avoiding collision with pedestrians in a crowded environment. This paper introduces a time-based nonlinear control method that achieves accurate global-position tracking (GPT) for multi-domain bipedal walking. Deriving a tracking controller for bipedal robots is challenging due to the highly complex robot dynamics that are time-varying and hybrid, especially for multi-domain walking that involves multiple phases/domains of full actuation, over actuation, and underactuation. To tackle this challenge, we introduce a continuous-phase GPT control law for multi-domain walking, which provably ensures the exponential convergence of the entire error state within the full and over actuation domains and that of the directly regulated error state within the underactuation domain. We then construct sufficient multiple-Lyapunov stability conditions for the hybrid multi-domain tracking error system under the proposed GPT control law. We illustrate the proposed controller design through both three-domain walking with all motors activated and two-domain gait with inactive ankle motors. Simulations of a ROBOTIS OP3 bipedal humanoid robot demonstrate the satisfactory accuracy and convergence rate of the proposed control approach under two different cases of multi-domain walking as well as various walking speeds and desired paths.