 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Language Independent Neuro-Symbolic Semantic Parsing for Form Understanding
May 08, 2023
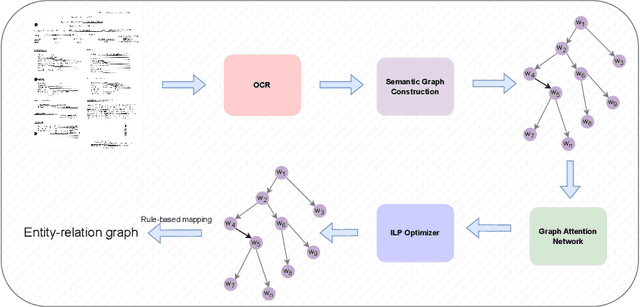
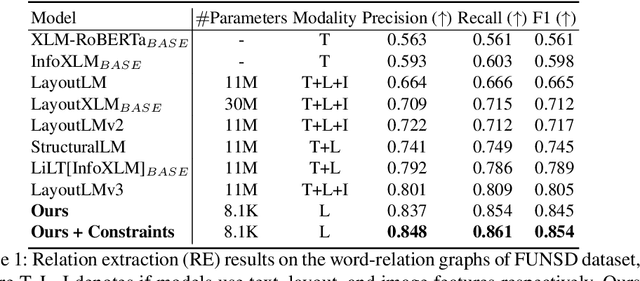
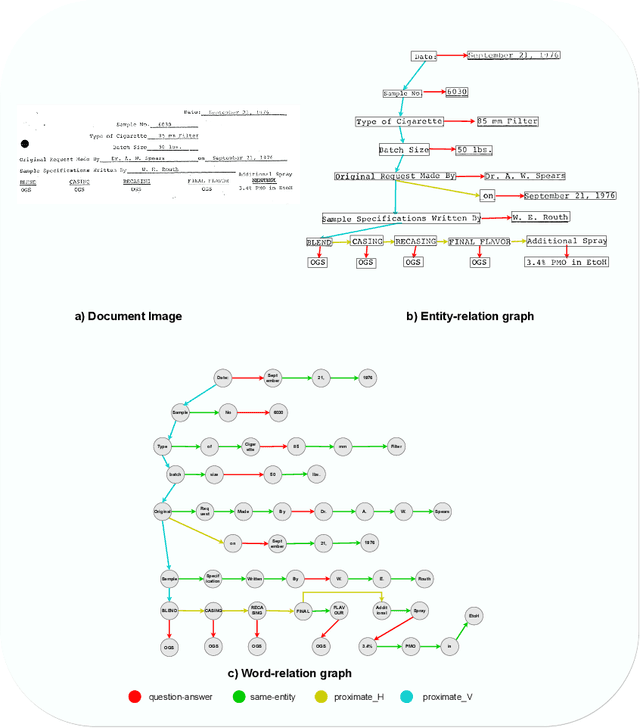
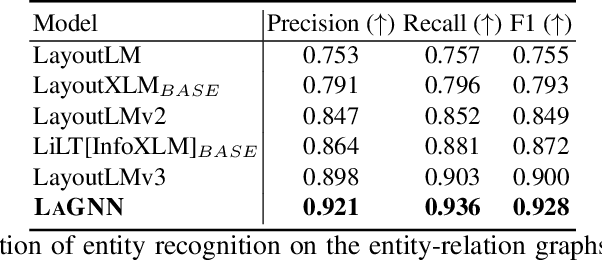
Recent works on form understanding mostly employ multimodal transformers or large-scale pre-trained language models. These models need ample data for pre-training. In contrast, humans can usually identify key-value pairings from a form only by looking at layouts, even if they don't comprehend the language used. No prior research has been conducted to investigate how helpful layout information alone is for form understanding. Hence, we propose a unique entity-relation graph parsing method for scanned forms called LAGNN, a language-independent Graph Neural Network model. Our model parses a form into a word-relation graph in order to identify entities and relations jointly and reduce the time complexity of inference. This graph is then transformed by deterministic rules into a fully connected entity-relation graph. Our model simply takes into account relative spacing between bounding boxes from layout information to facilitate easy transfer across languages. To further improve the performance of LAGNN, and achieve isomorphism between entity-relation graphs and word-relation graphs, we use integer linear programming (ILP) based inference. Code is publicly available at https://github.com/Bhanu068/LAGNN
Fully-Dynamic Approximate Decision Trees With Worst-Case Update Time Guarantees
Feb 08, 2023We give the first algorithm that maintains an approximate decision tree over an arbitrary sequence of insertions and deletions of labeled examples, with strong guarantees on the worst-case running time per update request. For instance, we show how to maintain a decision tree where every vertex has Gini gain within an additive $\alpha$ of the optimum by performing $O\Big(\frac{d\,(\log n)^4}{\alpha^3}\Big)$ elementary operations per update, where $d$ is the number of features and $n$ the maximum size of the active set (the net result of the update requests). We give similar bounds for the information gain and the variance gain. In fact, all these bounds are corollaries of a more general result, stated in terms of decision rules -- functions that, given a set $S$ of labeled examples, decide whether to split $S$ or predict a label. Decision rules give a unified view of greedy decision tree algorithms regardless of the example and label domains, and lead to a general notion of $\epsilon$-approximate decision trees that, for natural decision rules such as those used by ID3 or C4.5, implies the gain approximation guarantees above. The heart of our work provides a deterministic algorithm that, given any decision rule and any $\epsilon > 0$, maintains an $\epsilon$-approximate tree using $O\!\left(\frac{d\, f(n)}{n} \operatorname{poly}\frac{h}{\epsilon}\right)$ operations per update, where $f(n)$ is the complexity of evaluating the rule over a set of $n$ examples and $h$ is the maximum height of the maintained tree.
Long-term instabilities of deep learning-based digital twins of the climate system: The cause and a solution
Apr 14, 2023Long-term stability is a critical property for deep learning-based data-driven digital twins of the Earth system. Such data-driven digital twins enable sub-seasonal and seasonal predictions of extreme environmental events, probabilistic forecasts, that require a large number of ensemble members, and computationally tractable high-resolution Earth system models where expensive components of the models can be replaced with cheaper data-driven surrogates. Owing to computational cost, physics-based digital twins, though long-term stable, are intractable for real-time decision-making. Data-driven digital twins offer a cheaper alternative to them and can provide real-time predictions. However, such digital twins can only provide short-term forecasts accurately since they become unstable when time-integrated beyond 20 days. Currently, the cause of the instabilities is unknown, and the methods that are used to improve their stability horizons are ad-hoc and lack rigorous theory. In this paper, we reveal that the universal causal mechanism for these instabilities in any turbulent flow is due to \textit{spectral bias} wherein, \textit{any} deep learning architecture is biased to learn only the large-scale dynamics and ignores the small scales completely. We further elucidate how turbulence physics and the absence of convergence in deep learning-based time-integrators amplify this bias leading to unstable error propagation. Finally, using the quasigeostrophic flow and ECMWF Reanalysis data as test cases, we bridge the gap between deep learning theory and fundamental numerical analysis to propose one mitigative solution to such instabilities. We develop long-term stable data-driven digital twins for the climate system and demonstrate accurate short-term forecasts, and hundreds of years of long-term stable time-integration with accurate mean and variability.
Optical identification using physical unclonable functions
May 03, 2023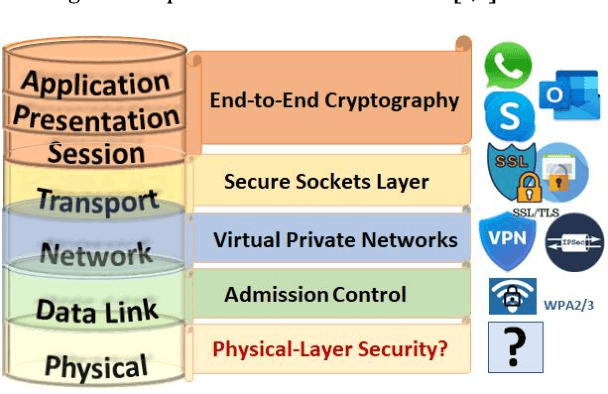
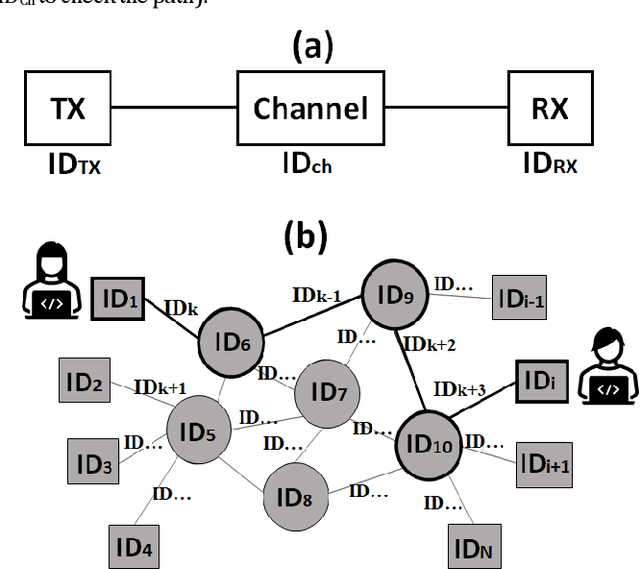
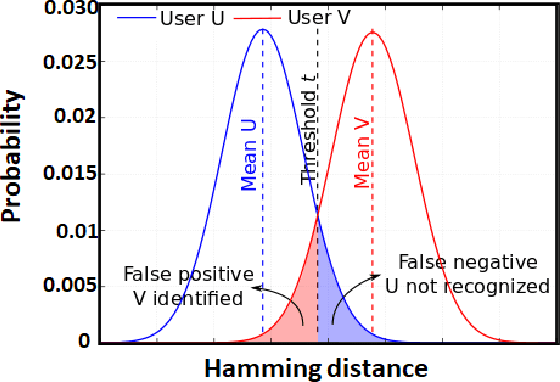
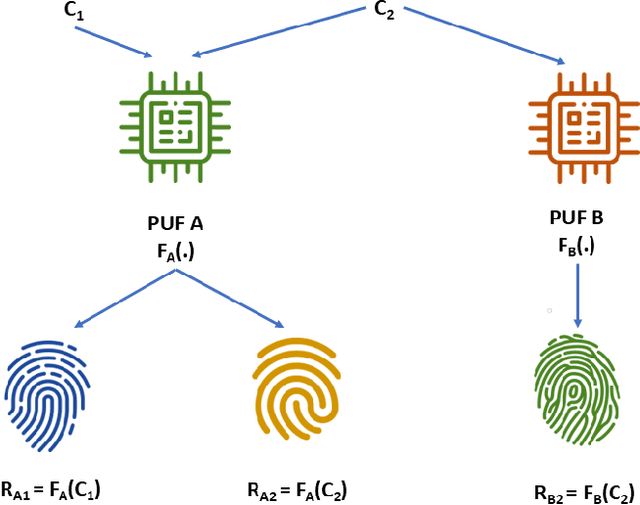
In this work, the concept of optical identification (OI) is introduced for the first time. The OI assigns an optical fingerprint and the corresponding digital signature to each sub-system of the network and estimates its reliability in different measures. We highlight the large potential applications of OI as a physical layer approach for security, identification, authentication, and monitoring purposes. To identify most of the sub-systems of a network, we propose to use the Rayleigh backscattering pattern, which is an optical physical unclonable function and allows to achieve OI with a simple procedure and without additional devices. The application of OI to fiber and path identification in a network, and to the authentication of the users in a quantum key distribution system are described.
An Adaptive Algorithm for Learning with Unknown Distribution Drift
May 03, 2023We develop and analyze a general technique for learning with an unknown distribution drift. Given a sequence of independent observations from the last $T$ steps of a drifting distribution, our algorithm agnostically learns a family of functions with respect to the current distribution at time $T$. Unlike previous work, our technique does not require prior knowledge about the magnitude of the drift. Instead, the algorithm adapts to the sample data. Without explicitly estimating the drift, the algorithm learns a family of functions with almost the same error as a learning algorithm that knows the magnitude of the drift in advance. Furthermore, since our algorithm adapts to the data, it can guarantee a better learning error than an algorithm that relies on loose bounds on the drift.
COUPA: An Industrial Recommender System for Online to Offline Service Platforms
Apr 25, 2023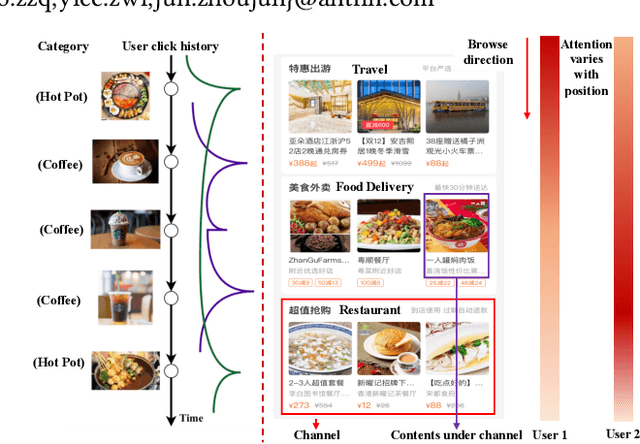
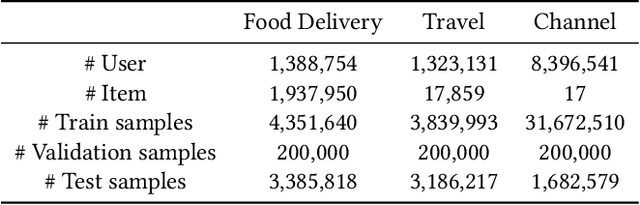
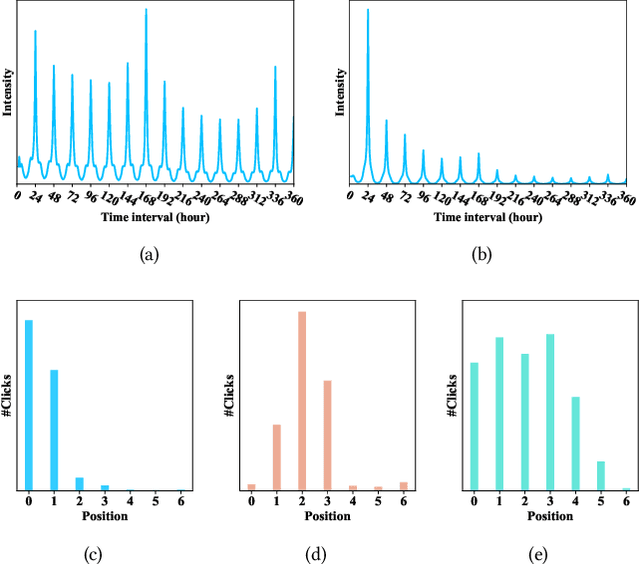
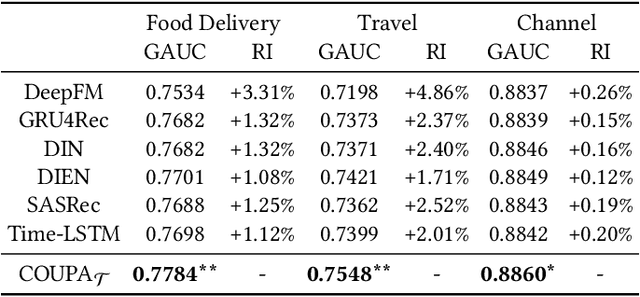
Aiming at helping users locally discovery retail services (e.g., entertainment and dinning), Online to Offline (O2O) service platforms have become popular in recent years, which greatly challenge current recommender systems. With the real data in Alipay, a feeds-like scenario for O2O services, we find that recurrence based temporal patterns and position biases commonly exist in our scenarios, which seriously threaten the recommendation effectiveness. To this end, we propose COUPA, an industrial system targeting for characterizing user preference with following two considerations: (1) Time aware preference: we employ the continuous time aware point process equipped with an attention mechanism to fully capture temporal patterns for recommendation. (2) Position aware preference: a position selector component equipped with a position personalization module is elaborately designed to mitigate position bias in a personalized manner. Finally, we carefully implement and deploy COUPA on Alipay with a cooperation of edge, streaming and batch computing, as well as a two-stage online serving mode, to support several popular recommendation scenarios. We conduct extensive experiments to demonstrate that COUPA consistently achieves superior performance and has potential to provide intuitive evidences for recommendation
Unsupervised Domain Transfer for Science: Exploring Deep Learning Methods for Translation between LArTPC Detector Simulations with Differing Response Models
Apr 25, 2023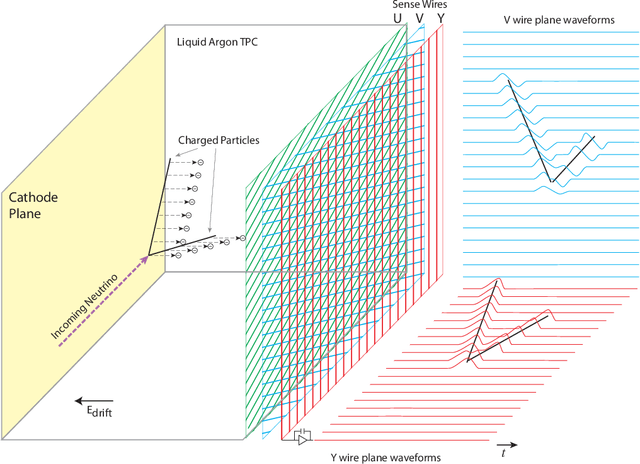
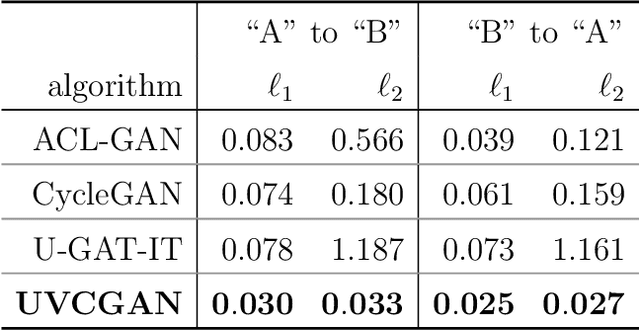
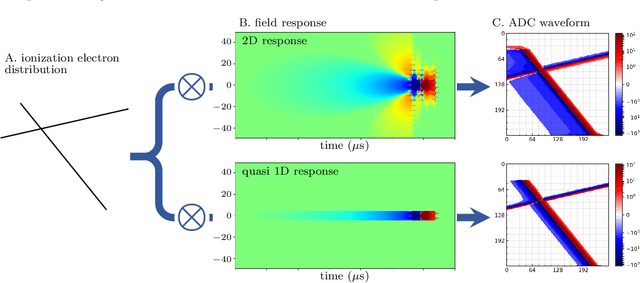
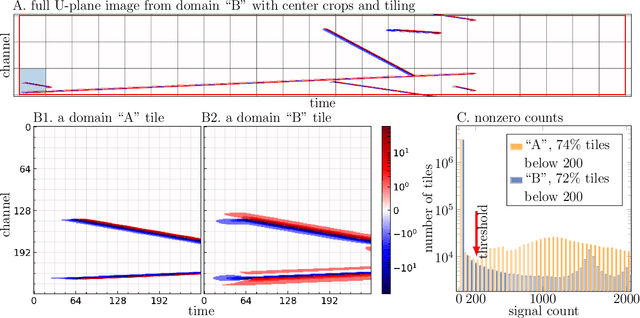
Deep learning (DL) techniques have broad applications in science, especially in seeking to streamline the pathway to potential solutions and discoveries. Frequently, however, DL models are trained on the results of simulation yet applied to real experimental data. As such, any systematic differences between the simulated and real data may degrade the model's performance -- an effect known as "domain shift." This work studies a toy model of the systematic differences between simulated and real data. It presents a fully unsupervised, task-agnostic method to reduce differences between two systematically different samples. The method is based on the recent advances in unpaired image-to-image translation techniques and is validated on two sets of samples of simulated Liquid Argon Time Projection Chamber (LArTPC) detector events, created to illustrate common systematic differences between the simulated and real data in a controlled way. LArTPC-based detectors represent the next-generation particle detectors, producing unique high-resolution particle track data. This work open-sources the generated LArTPC data set, called Simple Liquid-Argon Track Samples (or SLATS), allowing researchers from diverse domains to study the LArTPC-like data for the first time.
Get Back Here: Robust Imitation by Return-to-Distribution Planning
May 02, 2023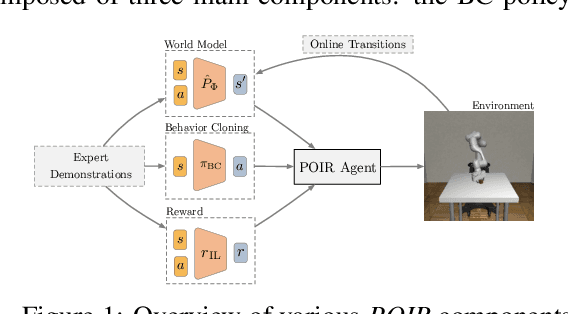
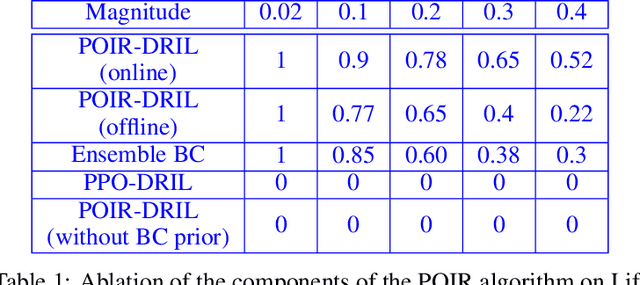

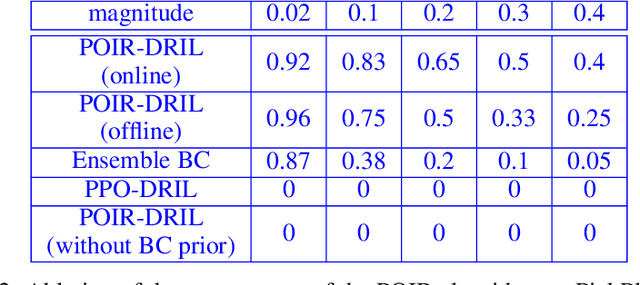
We consider the Imitation Learning (IL) setup where expert data are not collected on the actual deployment environment but on a different version. To address the resulting distribution shift, we combine behavior cloning (BC) with a planner that is tasked to bring the agent back to states visited by the expert whenever the agent deviates from the demonstration distribution. The resulting algorithm, POIR, can be trained offline, and leverages online interactions to efficiently fine-tune its planner to improve performance over time. We test POIR on a variety of human-generated manipulation demonstrations in a realistic robotic manipulation simulator and show robustness of the learned policy to different initial state distributions and noisy dynamics.
Can't Touch This: Real-Time, Safe Motion Planning and Control for Manipulators Under Uncertainty
Jan 30, 2023
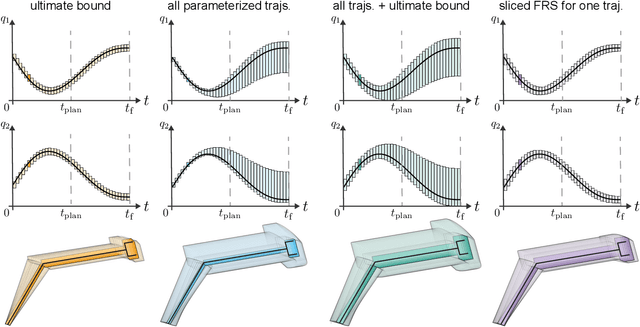
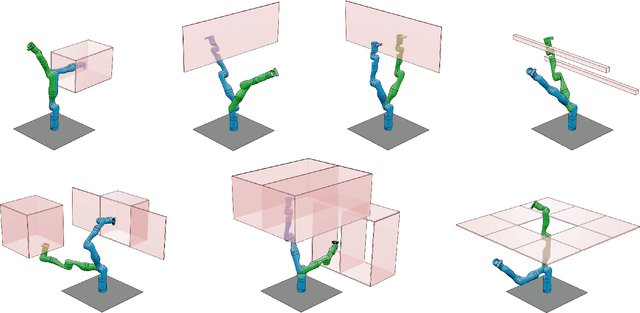
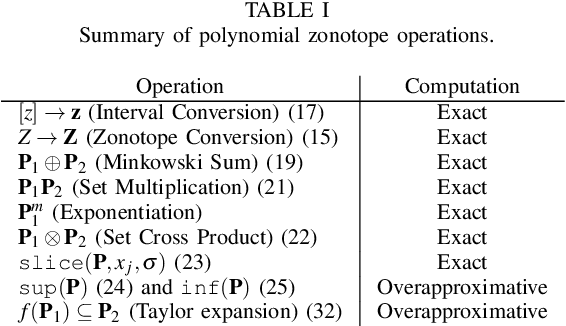
A key challenge to the widespread deployment of robotic manipulators is the need to ensure safety in arbitrary environments while generating new motion plans in real-time. In particular, one must ensure that a manipulator does not collide with obstacles, collide with itself, or exceed its joint torque limits. This challenge is compounded by the need to account for uncertainty in the mass and inertia of manipulated objects, and potentially the robot itself. The present work addresses this challenge by proposing Autonomous Robust Manipulation via Optimization with Uncertainty-aware Reachability (ARMOUR), a provably-safe, receding-horizon trajectory planner and tracking controller framework for serial link manipulators. ARMOUR works by first constructing a robust, passivity-based controller that is proven to enable a manipulator to track desired trajectories with bounded error despite uncertain dynamics. Next, ARMOUR uses a novel variation on the Recursive Newton-Euler Algorithm (RNEA) to compute the set of all possible inputs required to track any trajectory within a continuum of desired trajectories. Finally, the method computes an over-approximation to the swept volume of the manipulator; this enables one to formulate an optimization problem, which can be solved in real-time, to synthesize provably-safe motion. The proposed method is compared to state of the art methods and demonstrated on a variety of challenging manipulation examples in simulation and on real hardware, such as maneuvering a dumbbell with uncertain mass around obstacles.
Overload: Latency Attacks on Object Detection for Edge Devices
Apr 12, 2023
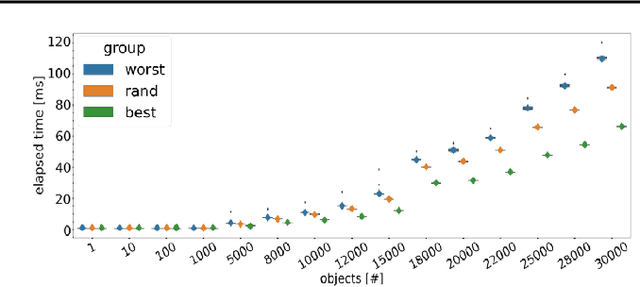
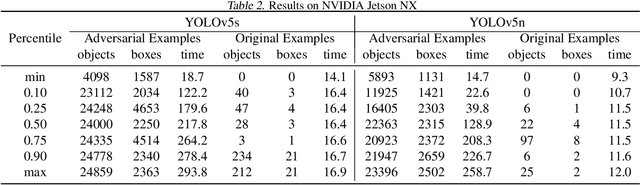

Nowadays, the deployment of deep learning based applications on edge devices is an essential task owing to the increasing demands on intelligent services. However, the limited computing resources on edge nodes make the models vulnerable to attacks, such that the predictions made by models are unreliable. In this paper, we investigate latency attacks on deep learning applications. Unlike common adversarial attacks for misclassification, the goal of latency attacks is to increase the inference time, which may stop applications from responding to the requests within a reasonable time. This kind of attack is ubiquitous for various applications, and we use object detection to demonstrate how such kind of attacks work. We also design a framework named Overload to generate latency attacks at scale. Our method is based on a newly formulated optimization problem and a novel technique, called spatial attention, to increase the inference time of object detection. We have conducted experiments using YOLOv5 models on Nvidia NX. The experimental results show that with latency attacks, the inference time of a single image can be increased ten times longer in reference to the normal setting. Moreover, comparing to existing methods, our attacking method is simpler and more effective.