 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Angle-based SLAM on 5G mmWave Systems: Design, Implementation, and Measurement
May 22, 2023
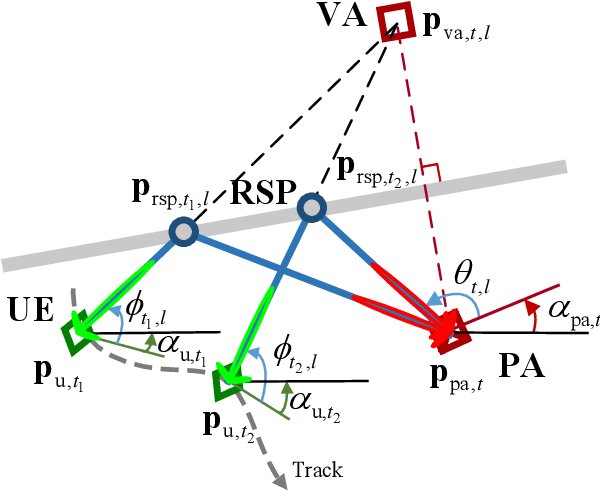
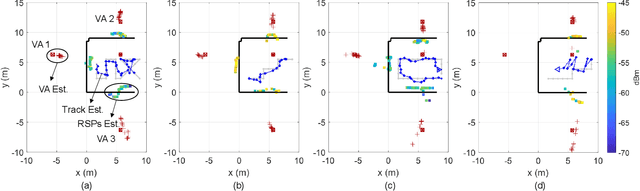
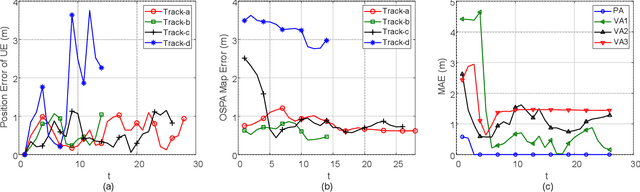
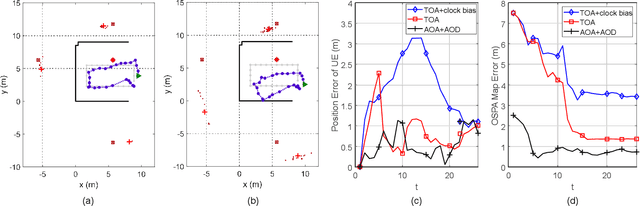
Simultaneous localization and mapping (SLAM) is a key technology that provides user equipment (UE) tracking and environment mapping services, enabling the deep integration of sensing and communication. The millimeter-wave (mmWave) communication, with its larger bandwidths and antenna arrays, inherently facilitates more accurate delay and angle measurements than sub-6 GHz communication, thereby providing opportunities for SLAM. However, none of the existing works have realized the SLAM function under the 5G New Radio (NR) standard due to specification and hardware constraints. In this study, we investigate how 5G mmWave communication systems can achieve situational awareness without changing the transceiver architecture and 5G NR standard. We implement 28 GHz mmWave transceivers that deploy OFDM-based 5G NR waveform with 160 MHz channel bandwidth, and we realize beam management following the 5G NR. Furthermore, we develop an efficient successive cancellation-based angle extraction approach to obtain angles of arrival and departure from the reference signal received power measurements. On the basis of angle measurements, we propose an angle-only SLAM algorithm to track UE and map features in the radio environment. Thorough experiments and ray tracing-based computer simulations verify that the proposed angle-based SLAM can achieve sub-meter level localization and mapping accuracy with a single base station and without the requirement of strict time synchronization. Our experiments also reveal many propagation properties critical to the success of SLAM in 5G mmWave communication systems.
Adaptive action supervision in reinforcement learning from real-world multi-agent demonstrations
May 22, 2023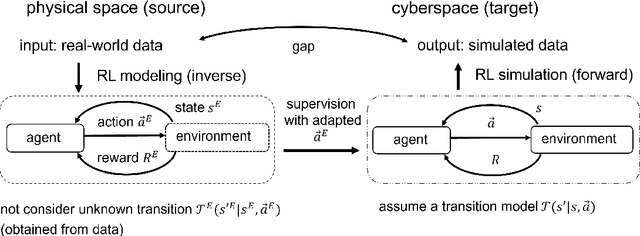
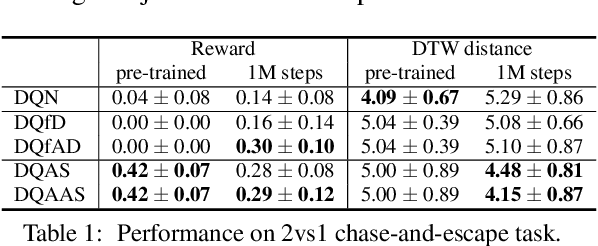
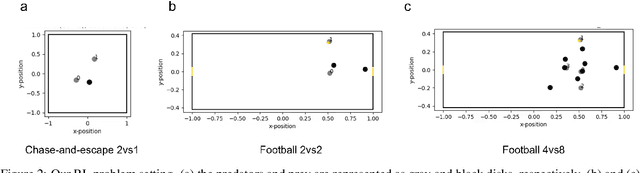
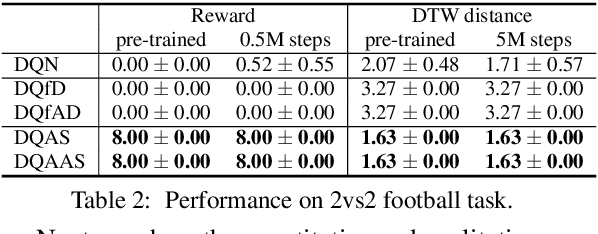
Modeling of real-world biological multi-agents is a fundamental problem in various scientific and engineering fields. Reinforcement learning (RL) is a powerful framework to generate flexible and diverse behaviors in cyberspace; however, when modeling real-world biological multi-agents, there is a domain gap between behaviors in the source (i.e., real-world data) and the target (i.e., cyberspace for RL), and the source environment parameters are usually unknown. In this paper, we propose a method for adaptive action supervision in RL from real-world demonstrations in multi-agent scenarios. We adopt an approach that combines RL and supervised learning by selecting actions of demonstrations in RL based on the minimum distance of dynamic time warping for utilizing the information of the unknown source dynamics. This approach can be easily applied to many existing neural network architectures and provide us with an RL model balanced between reproducibility as imitation and generalization ability to obtain rewards in cyberspace. In the experiments, using chase-and-escape and football tasks with the different dynamics between the unknown source and target environments, we show that our approach achieved a balance between the reproducibility and the generalization ability compared with the baselines. In particular, we used the tracking data of professional football players as expert demonstrations in football and show successful performances despite the larger gap between behaviors in the source and target environments than the chase-and-escape task.
Evaluating Prompt-based Question Answering for Object Prediction in the Open Research Knowledge Graph
May 22, 2023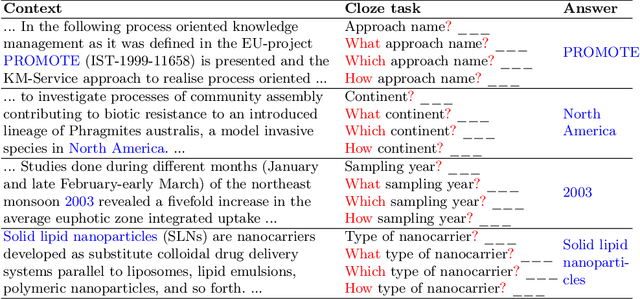

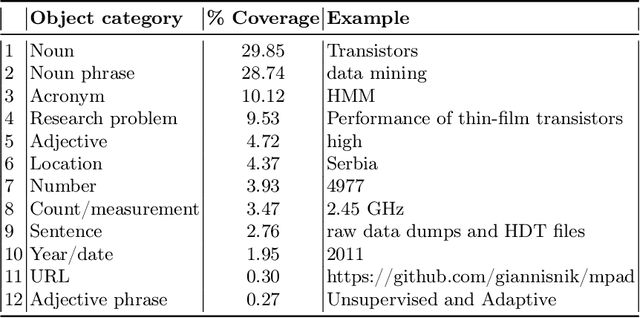
There have been many recent investigations into prompt-based training of transformer language models for new text genres in low-resource settings. The prompt-based training approach has been found to be effective in generalizing pre-trained or fine-tuned models for transfer to resource-scarce settings. This work, for the first time, reports results on adopting prompt-based training of transformers for \textit{scholarly knowledge graph object prediction}. The work is unique in the following two main aspects. 1) It deviates from the other works proposing entity and relation extraction pipelines for predicting objects of a scholarly knowledge graph. 2) While other works have tested the method on text genera relatively close to the general knowledge domain, we test the method for a significantly different domain, i.e. scholarly knowledge, in turn testing the linguistic, probabilistic, and factual generalizability of these large-scale transformer models. We find that (i) per expectations, transformer models when tested out-of-the-box underperform on a new domain of data, (ii) prompt-based training of the models achieve performance boosts of up to 40\% in a relaxed evaluation setting, and (iii) testing the models on a starkly different domain even with a clever training objective in a low resource setting makes evident the domain knowledge capture gap offering an empirically-verified incentive for investing more attention and resources to the scholarly domain in the context of transformer models.
LB-SimTSC: An Efficient Similarity-Aware Graph Neural Network for Semi-Supervised Time Series Classification
Jan 17, 2023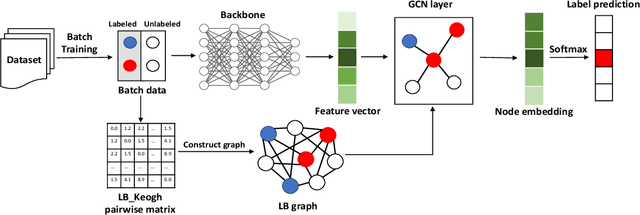
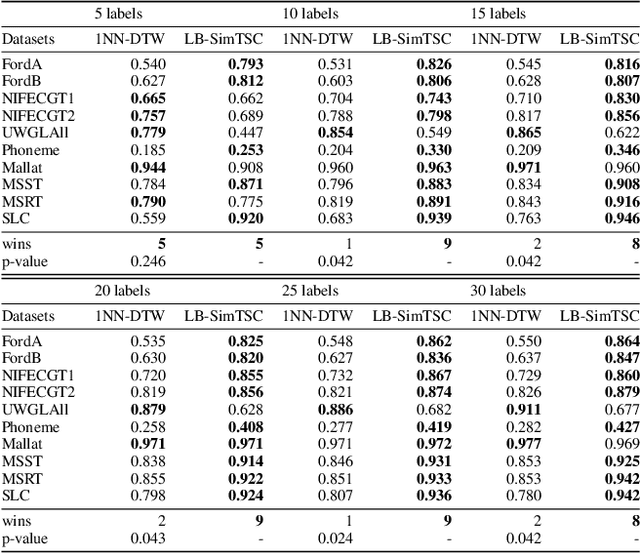
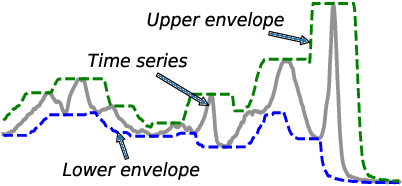
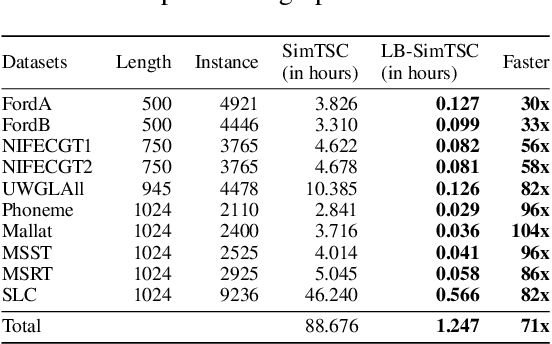
Time series classification is an important data mining task that has received a lot of interest in the past two decades. Due to the label scarcity in practice, semi-supervised time series classification with only a few labeled samples has become popular. Recently, Similarity-aware Time Series Classification (SimTSC) is proposed to address this problem by using a graph neural network classification model on the graph generated from pairwise Dynamic Time Warping (DTW) distance of batch data. It shows excellent accuracy and outperforms state-of-the-art deep learning models in several few-label settings. However, since SimTSC relies on pairwise DTW distances, the quadratic complexity of DTW limits its usability to only reasonably sized datasets. To address this challenge, we propose a new efficient semi-supervised time series classification technique, LB-SimTSC, with a new graph construction module. Instead of using DTW, we propose to utilize a lower bound of DTW, LB_Keogh, to approximate the dissimilarity between instances in linear time, while retaining the relative proximity relationships one would have obtained via computing DTW. We construct the pairwise distance matrix using LB_Keogh and build a graph for the graph neural network. We apply this approach to the ten largest datasets from the well-known UCR time series classification archive. The results demonstrate that this approach can be up to 104x faster than SimTSC when constructing the graph on large datasets without significantly decreasing classification accuracy.
Optimizing Group Utility in Itinerary Planning: A Strategic and Crowd-Aware Approach
Apr 20, 2023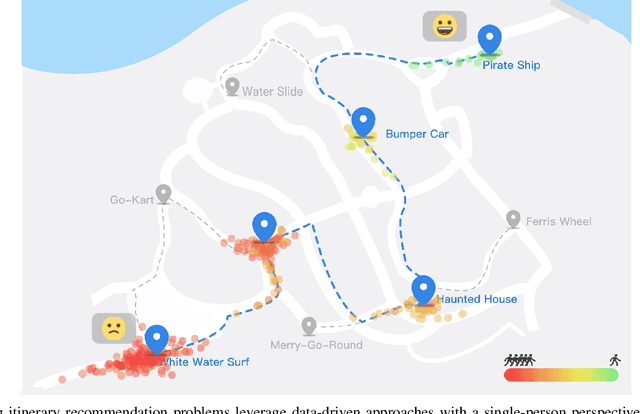
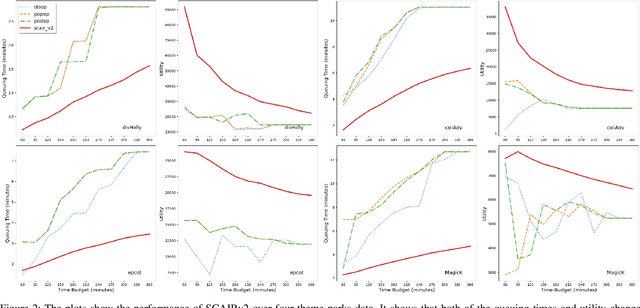
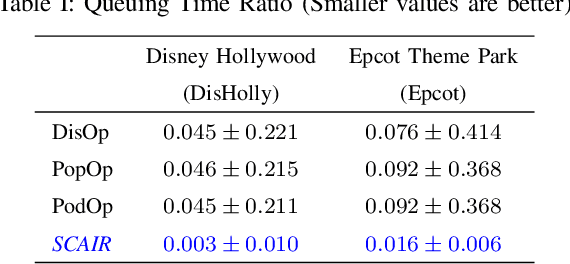
Itinerary recommendation is a complex sequence prediction problem with numerous real-world applications. This task becomes even more challenging when considering the optimization of multiple user queuing times and crowd levels, as well as numerous involved parameters, such as attraction popularity, queuing time, walking time, and operating hours. Existing solutions typically focus on single-person perspectives and fail to address real-world issues resulting from natural crowd behavior, like the Selfish Routing problem. In this paper, we introduce the Strategic and Crowd-Aware Itinerary Recommendation (SCAIR) algorithm, which optimizes group utility in real-world settings. We model the route recommendation strategy as a Markov Decision Process and propose a State Encoding mechanism that enables real-time planning and allocation in linear time. We evaluate our algorithm against various competitive and realistic baselines using a theme park dataset, demonstrating that SCAIR outperforms these baselines in addressing the Selfish Routing problem across four theme parks.
Deep Multi-Frame Filtering for Hearing Aids
May 14, 2023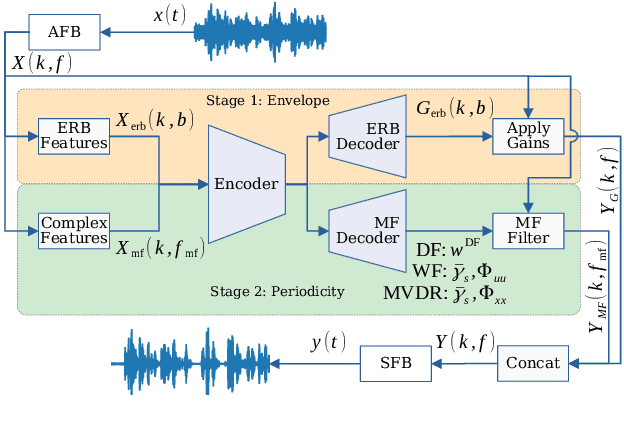

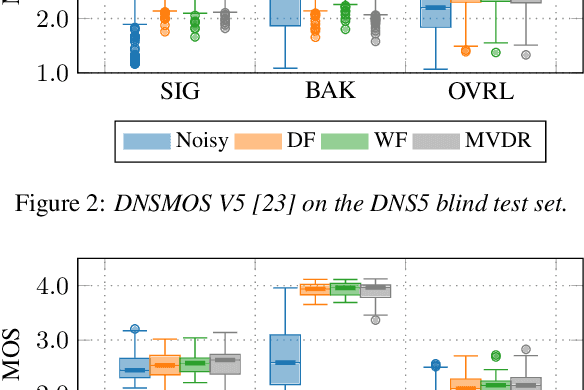
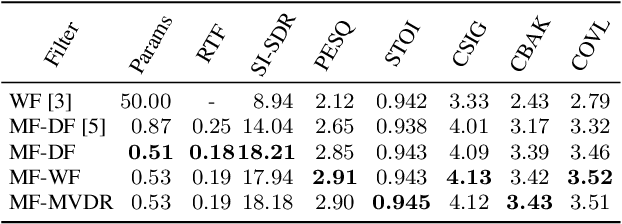
Multi-frame algorithms for single-channel speech enhancement are able to take advantage from short-time correlations within the speech signal. Deep filtering (DF) recently demonstrated its capabilities for low-latency scenarios like hearing aids with its complex multi-frame (MF) filter. Alternatively, the complex filter can be estimated via an MF minimum variance distortionless response (MVDR), or MF Wiener filter (WF). Previous studies have shown that incorporating algorithm domain knowledge using an MVDR filter might be beneficial compared to the direct filter estimation via DF. In this work, we compare the usage of various multi-frame filters such as DF, MF-MVDR, or MF-WF for HAs. We assess different covariance estimation methods for both MF-MVDR and MF-WF and objectively demonstrate an improved performance compared to direct DF estimation, significantly outperforming related work while improving the runtime performance.
Improving End-to-End SLU performance with Prosodic Attention and Distillation
May 14, 2023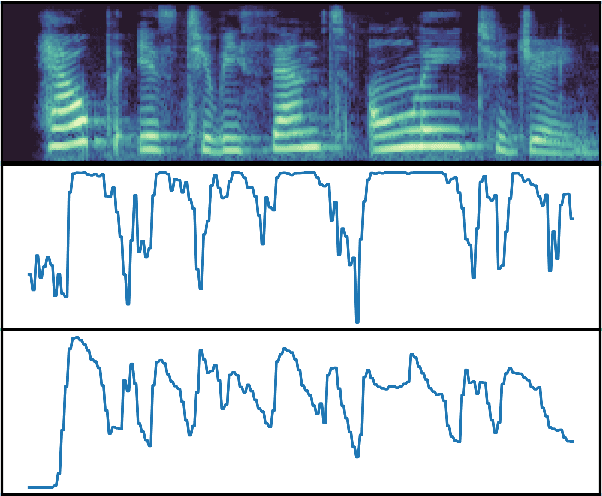
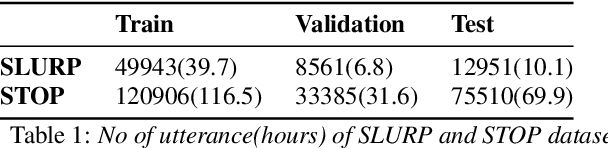
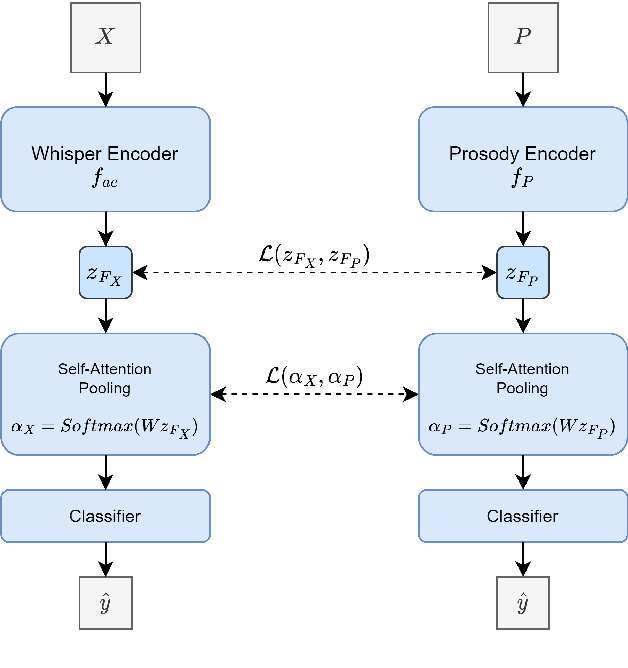
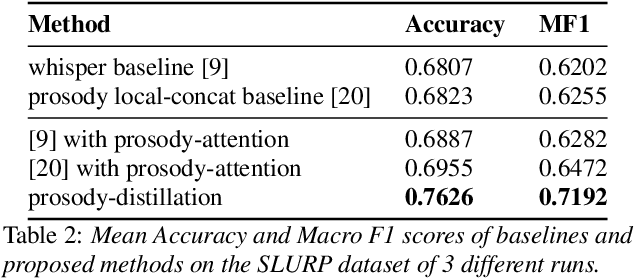
Most End-to-End SLU methods depend on the pretrained ASR or language model features for intent prediction. However, other essential information in speech, such as prosody, is often ignored. Recent research has shown improved results in classifying dialogue acts by incorporating prosodic information. The margins of improvement in these methods are minimal as the neural models ignore prosodic features. In this work, we propose prosody-attention, which uses the prosodic features differently to generate attention maps across time frames of the utterance. Then we propose prosody-distillation to explicitly learn the prosodic information in the acoustic encoder rather than concatenating the implicit prosodic features. Both the proposed methods improve the baseline results, and the prosody-distillation method gives an intent classification accuracy improvement of 8\% and 2\% on SLURP and STOP datasets over the prosody baseline.
Autoregressive models for biomedical signal processing
May 01, 2023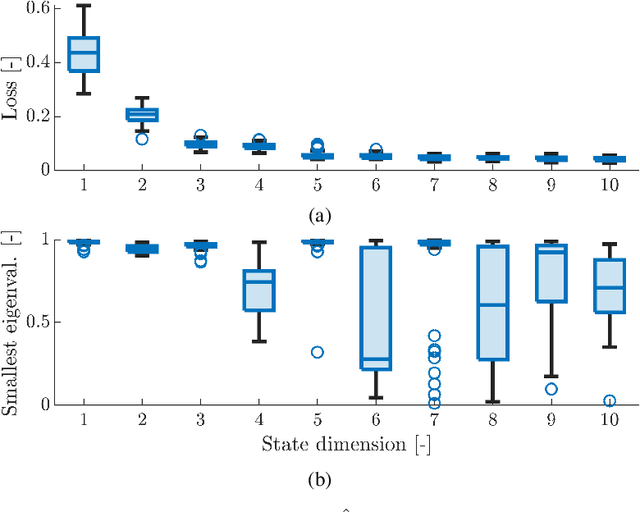
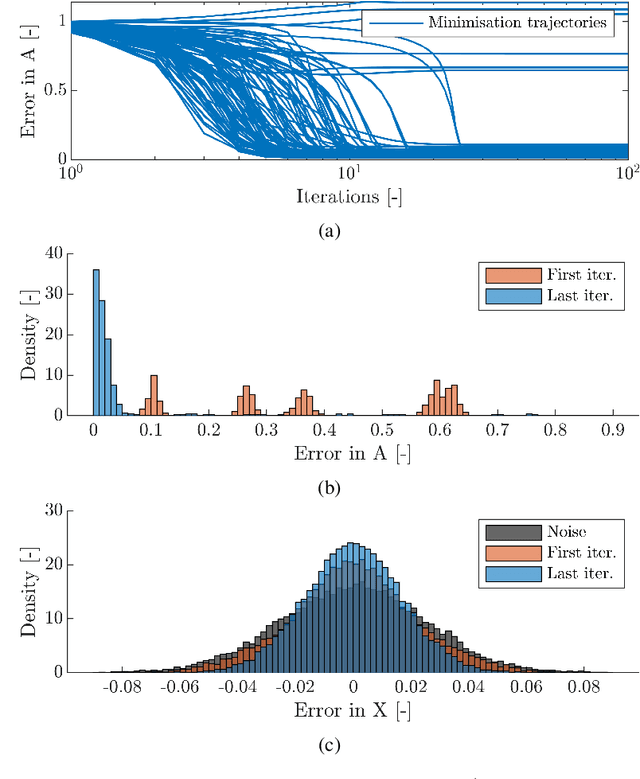
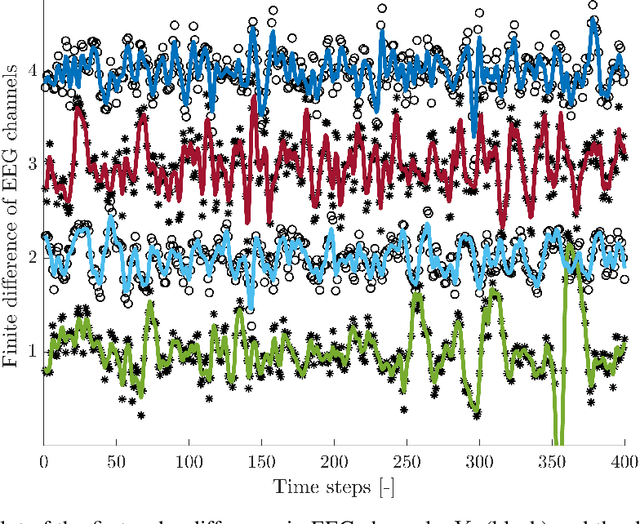
Autoregressive models are ubiquitous tools for the analysis of time series in many domains such as computational neuroscience and biomedical engineering. In these domains, data is, for example, collected from measurements of brain activity. Crucially, this data is subject to measurement errors as well as uncertainties in the underlying system model. As a result, standard signal processing using autoregressive model estimators may be biased. We present a framework for autoregressive modelling that incorporates these uncertainties explicitly via an overparameterised loss function. To optimise this loss, we derive an algorithm that alternates between state and parameter estimation. Our work shows that the procedure is able to successfully denoise time series and successfully reconstruct system parameters. This new paradigm can be used in a multitude of applications in neuroscience such as brain-computer interface data analysis and better understanding of brain dynamics in diseases such as epilepsy.
A Stable and Scalable Method for Solving Initial Value PDEs with Neural Networks
Apr 28, 2023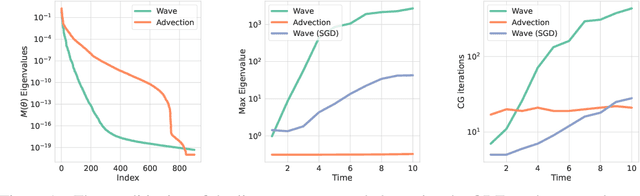
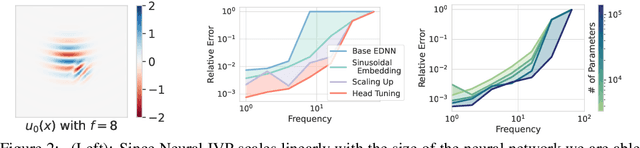
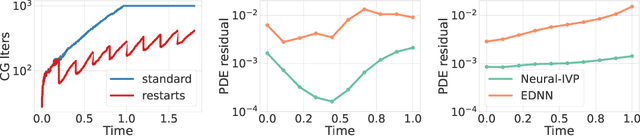
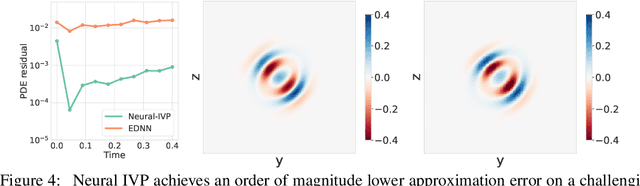
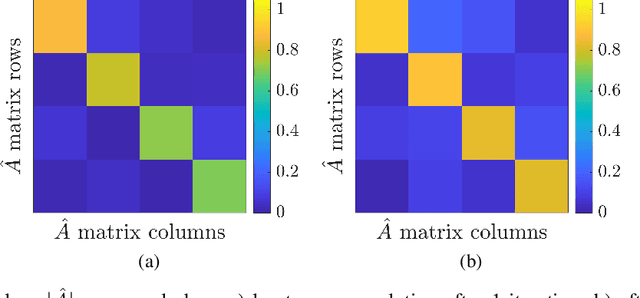
Unlike conventional grid and mesh based methods for solving partial differential equations (PDEs), neural networks have the potential to break the curse of dimensionality, providing approximate solutions to problems where using classical solvers is difficult or impossible. While global minimization of the PDE residual over the network parameters works well for boundary value problems, catastrophic forgetting impairs the applicability of this approach to initial value problems (IVPs). In an alternative local-in-time approach, the optimization problem can be converted into an ordinary differential equation (ODE) on the network parameters and the solution propagated forward in time; however, we demonstrate that current methods based on this approach suffer from two key issues. First, following the ODE produces an uncontrolled growth in the conditioning of the problem, ultimately leading to unacceptably large numerical errors. Second, as the ODE methods scale cubically with the number of model parameters, they are restricted to small neural networks, significantly limiting their ability to represent intricate PDE initial conditions and solutions. Building on these insights, we develop Neural IVP, an ODE based IVP solver which prevents the network from getting ill-conditioned and runs in time linear in the number of parameters, enabling us to evolve the dynamics of challenging PDEs with neural networks.
Language Model Tokenizers Introduce Unfairness Between Languages
May 17, 2023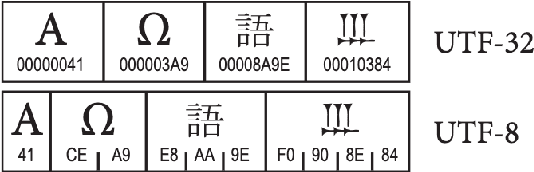
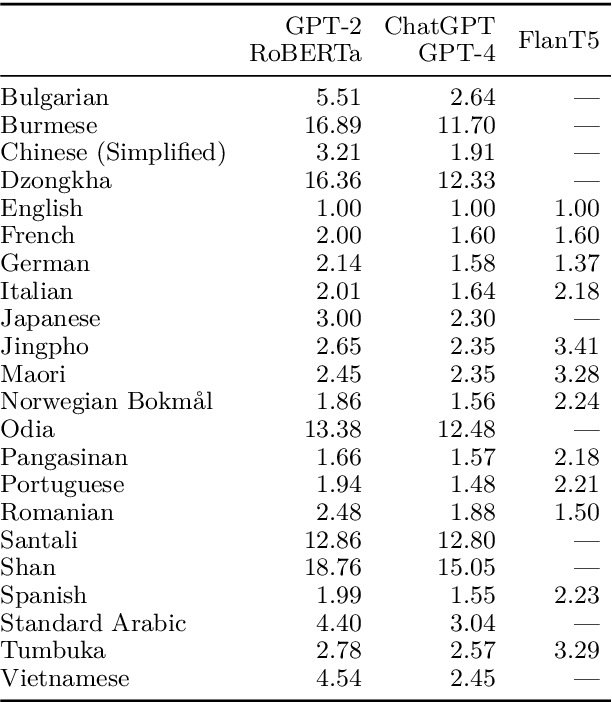
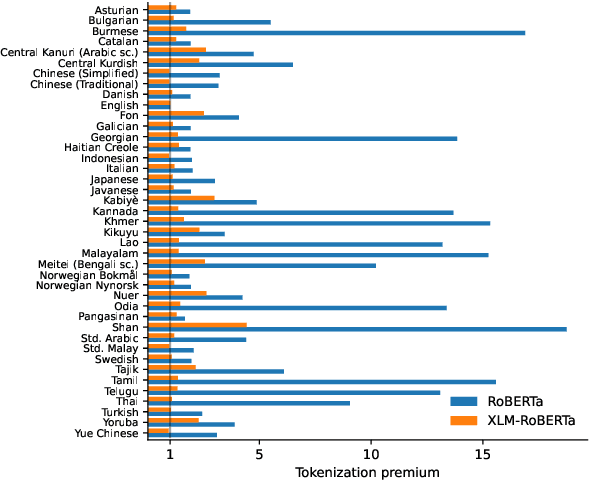
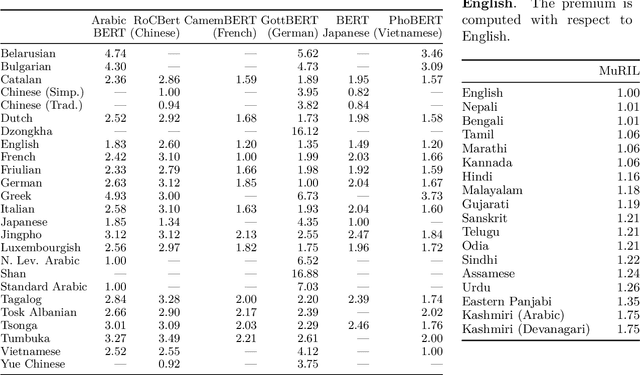
Recent language models have shown impressive multilingual performance, even when not explicitly trained for it. Despite this, concerns have been raised about the quality of their outputs across different languages. In this paper, we show how disparity in the treatment of different languages arises at the tokenization stage, well before a model is even invoked. The same text translated into different languages can have drastically different tokenization lengths, with differences up to 15 times in some cases. These disparities persist across the 17 tokenizers we evaluate, even if they are intentionally trained for multilingual support. Character-level and byte-level models also exhibit over 4 times the difference in the encoding length for some language pairs. This induces unfair treatment for some language communities in regard to the cost of accessing commercial language services, the processing time and latency, as well as the amount of content that can be provided as context to the models. Therefore, we make the case that we should train future language models using multilingually fair tokenizers.