 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Explainable Knowledge Distillation for On-device Chest X-Ray Classification
May 10, 2023
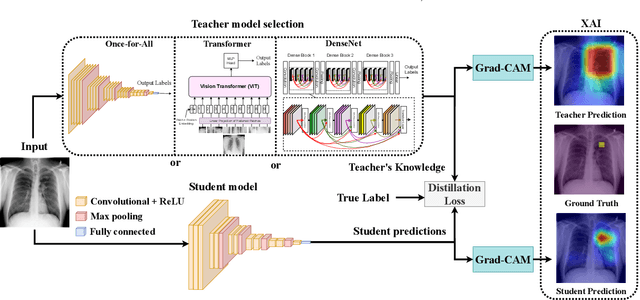

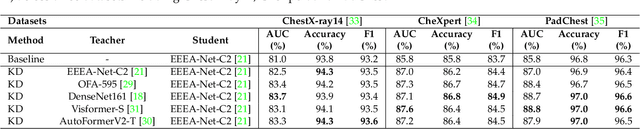
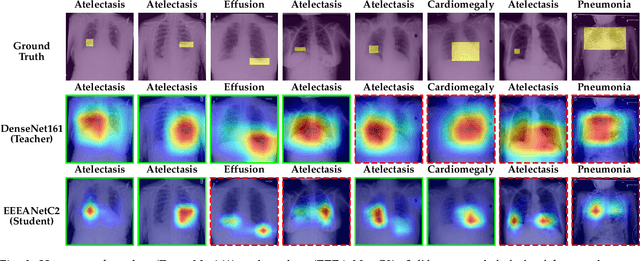
Automated multi-label chest X-rays (CXR) image classification has achieved substantial progress in clinical diagnosis via utilizing sophisticated deep learning approaches. However, most deep models have high computational demands, which makes them less feasible for compact devices with low computational requirements. To overcome this problem, we propose a knowledge distillation (KD) strategy to create the compact deep learning model for the real-time multi-label CXR image classification. We study different alternatives of CNNs and Transforms as the teacher to distill the knowledge to a smaller student. Then, we employed explainable artificial intelligence (XAI) to provide the visual explanation for the model decision improved by the KD. Our results on three benchmark CXR datasets show that our KD strategy provides the improved performance on the compact student model, thus being the feasible choice for many limited hardware platforms. For instance, when using DenseNet161 as the teacher network, EEEA-Net-C2 achieved an AUC of 83.7%, 87.1%, and 88.7% on the ChestX-ray14, CheXpert, and PadChest datasets, respectively, with fewer parameters of 4.7 million and computational cost of 0.3 billion FLOPS.
Learning in a Single Domain for Non-Stationary Multi-Texture Synthesis
May 10, 2023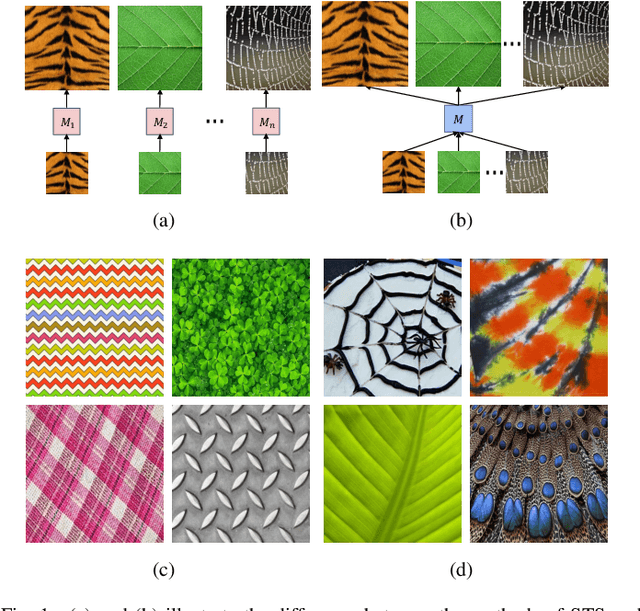

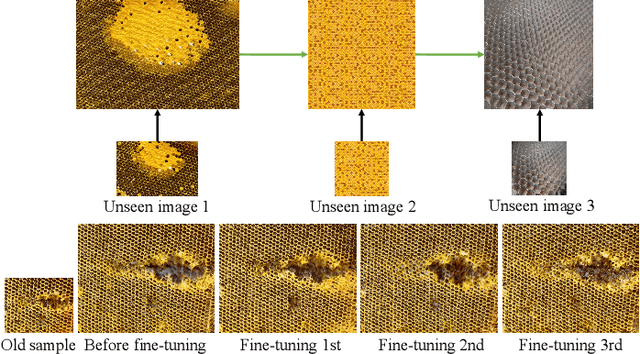

This paper aims for a new generation task: non-stationary multi-texture synthesis, which unifies synthesizing multiple non-stationary textures in a single model. Most non-stationary textures have large scale variance and can hardly be synthesized through one model. To combat this, we propose a multi-scale generator to capture structural patterns of various scales and effectively synthesize textures with a minor cost. However, it is still hard to handle textures of different categories with different texture patterns. Therefore, we present a category-specific training strategy to focus on learning texture pattern of a specific domain. Interestingly, once trained, our model is able to produce multi-pattern generations with dynamic variations without the need to finetune the model for different styles. Moreover, an objective evaluation metric is designed for evaluating the quality of texture expansion and global structure consistency. To our knowledge, ours is the first scheme for this challenging task, including model, training, and evaluation. Experimental results demonstrate the proposed method achieves superior performance and time efficiency. The code will be available after the publication.
ACTC: Active Threshold Calibration for Cold-Start Knowledge Graph Completion
May 10, 2023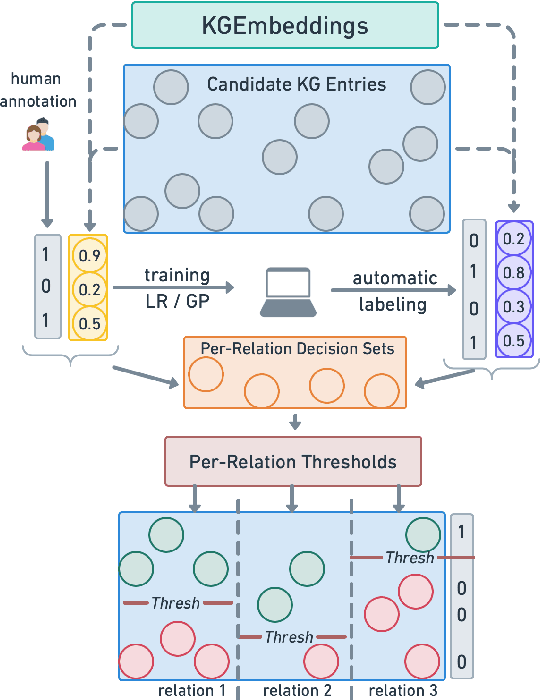
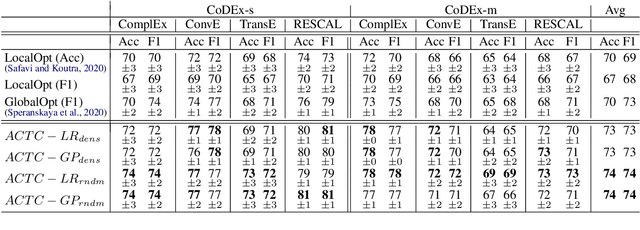
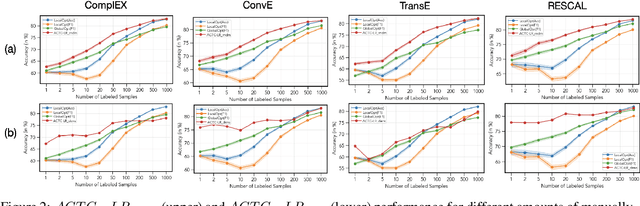
Self-supervised knowledge-graph completion (KGC) relies on estimating a scoring model over (entity, relation, entity)-tuples, for example, by embedding an initial knowledge graph. Prediction quality can be improved by calibrating the scoring model, typically by adjusting the prediction thresholds using manually annotated examples. In this paper, we attempt for the first time cold-start calibration for KGC, where no annotated examples exist initially for calibration, and only a limited number of tuples can be selected for annotation. Our new method ACTC finds good per-relation thresholds efficiently based on a limited set of annotated tuples. Additionally to a few annotated tuples, ACTC also leverages unlabeled tuples by estimating their correctness with Logistic Regression or Gaussian Process classifiers. We also experiment with different methods for selecting candidate tuples for annotation: density-based and random selection. Experiments with five scoring models and an oracle annotator show an improvement of 7% points when using ACTC in the challenging setting with an annotation budget of only 10 tuples, and an average improvement of 4% points over different budgets.
Context-dependent communication under environmental constraints
May 10, 2023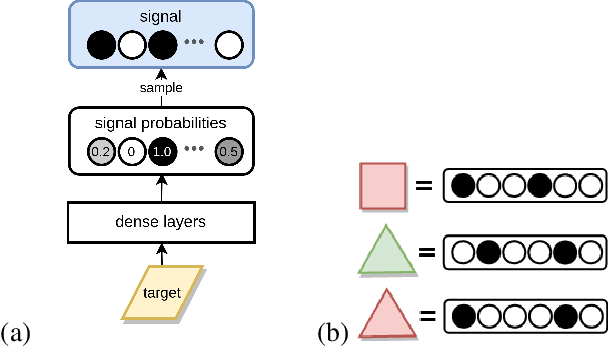
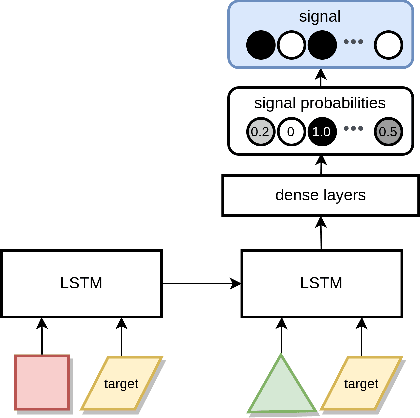
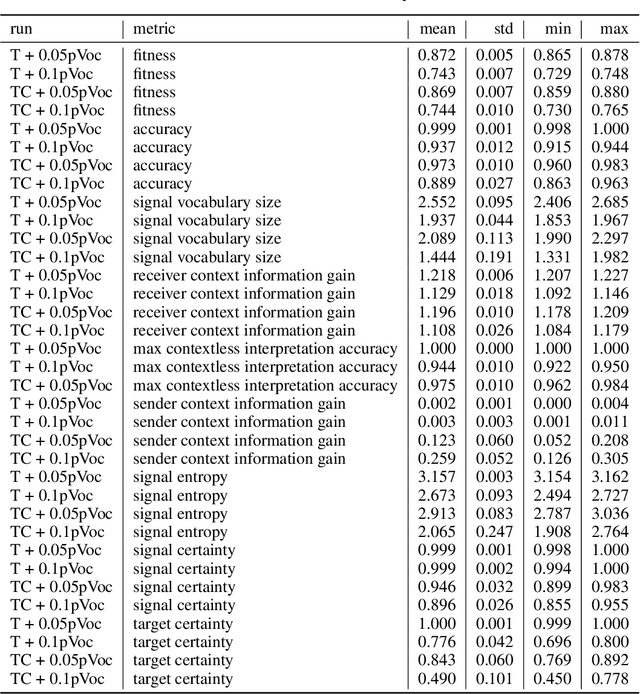
There is significant evidence that real-world communication cannot be reduced to sending signals with context-independent meaning. In this work, based on a variant of the classical Lewis (1969) signaling model, we explore the conditions for the emergence of context-dependent communication in a situated scenario. In particular, we demonstrate that pressure to minimise the vocabulary size is sufficient for such emergence. At the same time, we study the environmental conditions and cognitive capabilities that enable contextual disambiguation of symbol meanings. We show that environmental constraints on the receiver's referent choice can be unilaterally exploited by the sender, without disambiguation capabilities on the receiver's end. Consistent with common assumptions, the sender's awareness of the context appears to be required for contextual communication. We suggest that context-dependent communication is a situated multilayered phenomenon, crucially influenced by environment properties such as distribution of contexts. The model developed in this work is a demonstration of how signals may be ambiguous out of context, but still allow for near-perfect communication accuracy.
A Generalizable Physics-informed Learning Framework for Risk Probability Estimation
May 10, 2023Accurate estimates of long-term risk probabilities and their gradients are critical for many stochastic safe control methods. However, computing such risk probabilities in real-time and in unseen or changing environments is challenging. Monte Carlo (MC) methods cannot accurately evaluate the probabilities and their gradients as an infinitesimal devisor can amplify the sampling noise. In this paper, we develop an efficient method to evaluate the probabilities of long-term risk and their gradients. The proposed method exploits the fact that long-term risk probability satisfies certain partial differential equations (PDEs), which characterize the neighboring relations between the probabilities, to integrate MC methods and physics-informed neural networks. We provide theoretical guarantees of the estimation error given certain choices of training configurations. Numerical results show the proposed method has better sample efficiency, generalizes well to unseen regions, and can adapt to systems with changing parameters. The proposed method can also accurately estimate the gradients of risk probabilities, which enables first- and second-order techniques on risk probabilities to be used for learning and control.
Concentric Tube Robot Redundancy Resolution via Velocity/Compliance Manipulability Optimization
May 10, 2023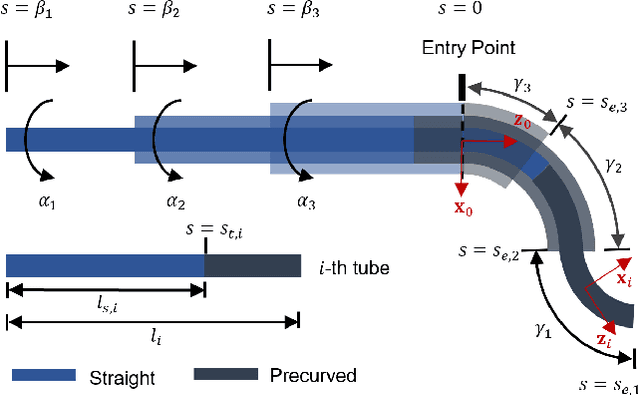
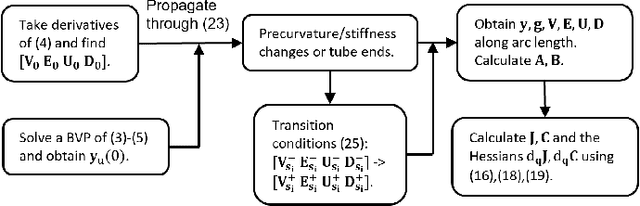
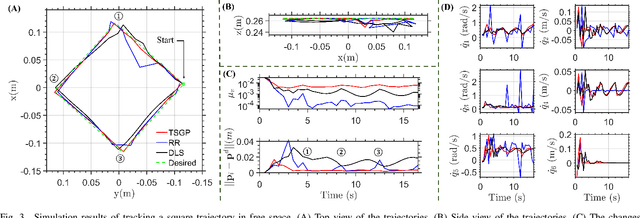
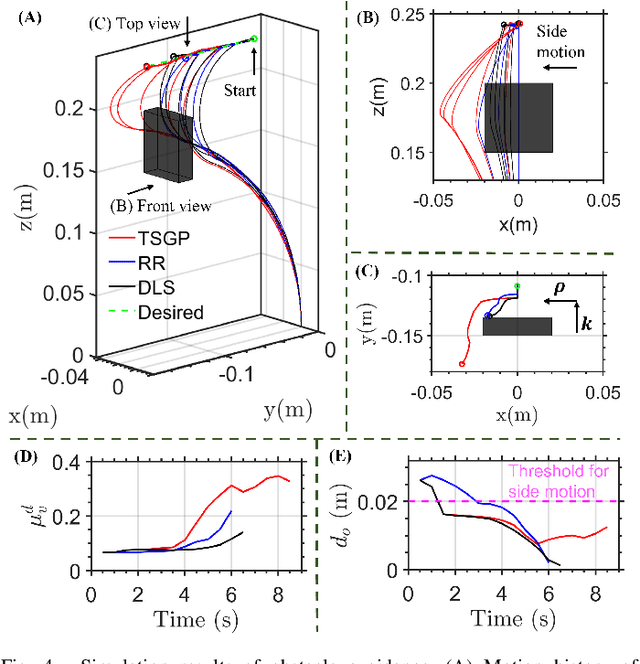
Concentric Tube Robots (CTR) have the potential to enable effective minimally invasive surgeries. While extensive modeling and control schemes have been proposed in the past decade, limited efforts have been made to improve the trajectory tracking performance from the perspective of manipulability , which can be critical to generate safe motion and feasible actuator commands. In this paper, we propose a gradient-based redundancy resolution framework that optimizes velocity/compliance manipulability-based performance indices during trajectory tracking for a kinematically redundant CTR. We efficiently calculate the gradients of manipulabilities by propagating the first- and second-order derivatives of state variables of the Cosserat rod model along the CTR arc length, reducing the gradient computation time by 68\% compared to finite difference method. Task-specific performance indices are optimized by projecting the gradient into the null-space of trajectory tracking. The proposed method is validated in three exemplary scenarios that involve trajectory tracking, obstacle avoidance, and external load compensation, respectively. Simulation results show that the proposed method is able to accomplish the required tasks while commonly used redundancy resolution approaches underperform or even fail.
Virtualization of Tiny Embedded Systems with a robust real-time capable and extensible Stack Virtual Machine REXAVM supporting Material-integrated Intelligent Systems and Tiny Machine Learning
Feb 17, 2023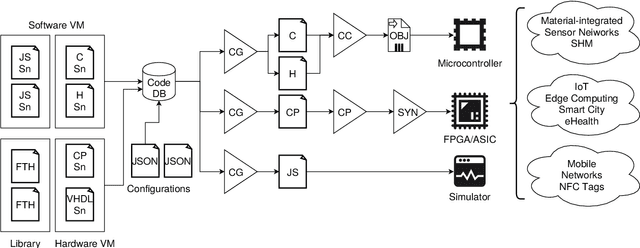
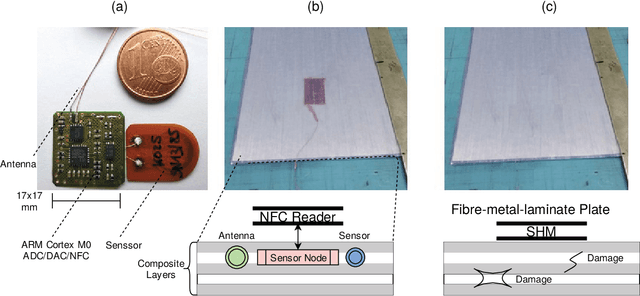

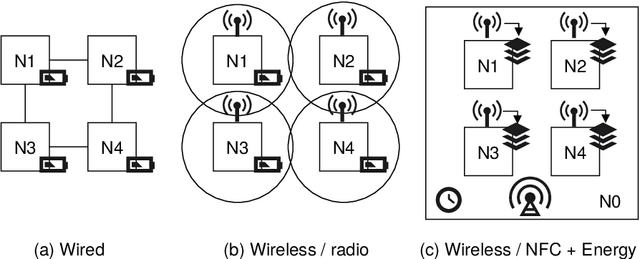
In the past decades, there has been a significant increase in sensor density and sensor deployment, driven by a significant miniaturization and decrease in size down to the chip level, addressing ubiquitous computing, edge computing, as well as distributed sensor networks. Material-integrated and intelligent systems (MIIS) provide the next integration and application level, but they create new challenges and introduce hard constraints (resources, energy supply, communication, resilience, and security). Commonly, low-resource systems are statically programmed processors with application-specific software or application-specific hardware (FPGA). This work demonstrates the need for and solution to virtualization in such low-resource and constrained systems towards resilient distributed sensor and cyber-physical networks using a unified low-resource, customizable, and real-time capable embedded and extensible stack virtual machine (REXAVM) that can be implemented and cooperate in both software and hardware. In a holistic architecture approach, the VM specifically addresses digital signal processing and tiny machine learning. The REXAVM is highly customizable through the use of VM program code generators at compile time and incremental code processing at run time. The VM uses an integrated, highly efficient just-in-time compiler to create Bytecode from text code. This paper shows and evaluates the suitability of the proposed VM architecture for operationally equivalent software and hardware (FPGA) implementations. Specific components supporting tiny ML and DSP using fixed-point arithmetic with respect to efficiency and accuracy are discussed. An extended use-case section demonstrates the usability of the introduced VM architecture for a broad range of applications.
Event Camera as Region Proposal Network
May 01, 2023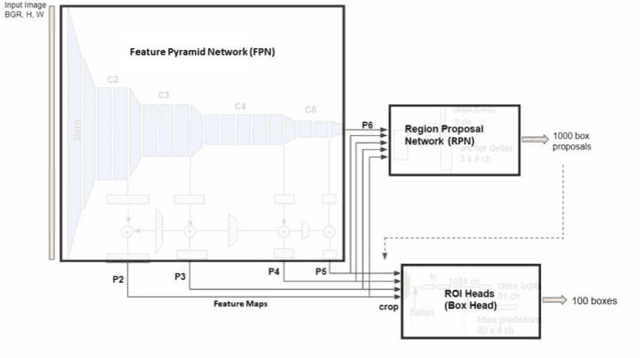
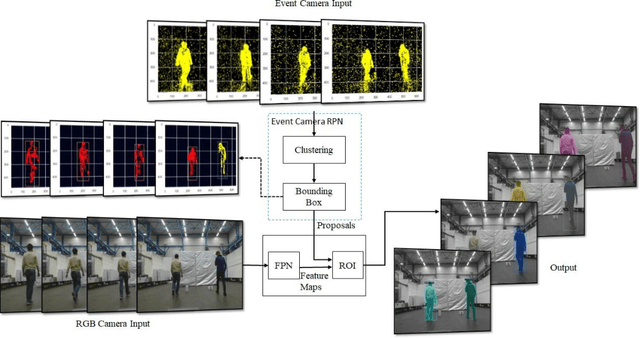


The human eye consists of two types of photoreceptors, rods and cones. Rods are responsible for monochrome vision, and cones for color vision. The number of rods is much higher than the cones, which means that most human vision processing is done in monochrome. An event camera reports the change in pixel intensity and is analogous to rods. Event and color cameras in computer vision are like rods and cones in human vision. Humans can notice objects moving in the peripheral vision (far right and left), but we cannot classify them (think of someone passing by on your far left or far right, this can trigger your attention without knowing who they are). Thus, rods act as a region proposal network (RPN) in human vision. Therefore, an event camera can act as a region proposal network in deep learning Two-stage object detectors in deep learning, such as Mask R-CNN, consist of a backbone for feature extraction and a RPN. Currently, RPN uses the brute force method by trying out all the possible bounding boxes to detect an object. This requires much computation time to generate region proposals making two-stage detectors inconvenient for fast applications. This work replaces the RPN in Mask-RCNN of detectron2 with an event camera for generating proposals for moving objects. Thus, saving time and being computationally less expensive. The proposed approach is faster than the two-stage detectors with comparable accuracy
Brazilian tailing dam collapse, retrospective precursory monitoring of InSAR data using spectral analysis of time series
Feb 01, 2023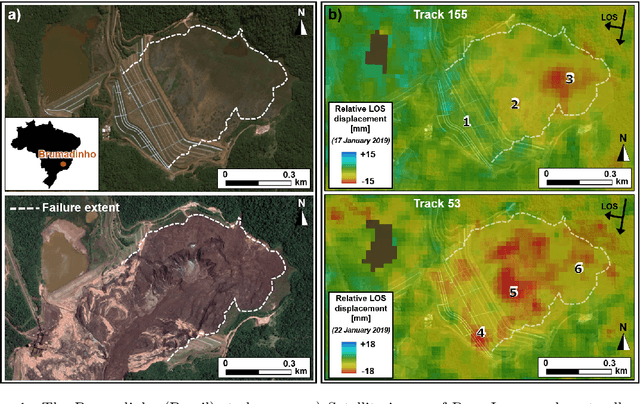
Slope failures possess destructive power that can cause significant damage to both life and infrastructure. Monitoring slopes prone to instabilities is therefore critical in mitigating the risk posed by their failure. The purpose of slope monitoring is to detect precursory signs of stability issues, such as changes in the rate of displacement with which a slope is deforming. This information can then be used to predict the timing or probability of an imminent failure in order to provide an early warning. In this study, a more objective, statistical-learning algorithm is proposed to detect and characterise the risk of a slope failure, based on spectral analysis of serially correlated displacement time series data. The algorithm is applied to satellite-based interferometric synthetic radar (InSAR) displacement time series data to retrospectively analyse the risk of the 2019 Brumadinho tailings dam collapse in Brazil. Two potential risk milestones are identified and signs of a definitive but emergent risk (27 February 2018 to 26 August 2018) and imminent risk of collapse of the tailings dam (27 June 2018 to 24 December 2018) are detected by the algorithm. Importantly, this precursory indication of risk of failure is detected as early as at least five months prior to the dam collapse on 25 January 2019. The results of this study demonstrate that the combination of spectral methods and second order statistical properties of InSAR displacement time series data can reveal signs of a transition into an unstable deformation regime, and that this algorithm can provide sufficient early warning that could help mitigate catastrophic slope failures.
A Security Verification Framework of Cryptographic Protocols Using Machine Learning
Apr 26, 2023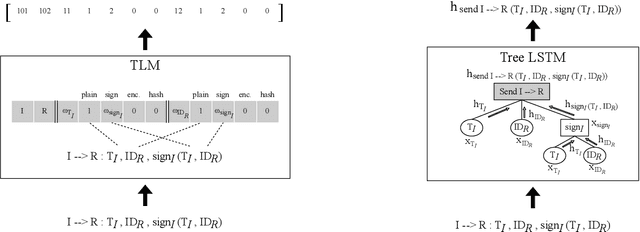



We propose a security verification framework for cryptographic protocols using machine learning. In recent years, as cryptographic protocols have become more complex, research on automatic verification techniques has been focused on. The main technique is formal verification. However, the formal verification has two problems: it requires a large amount of computational time and does not guarantee decidability. We propose a method that allows security verification with computational time on the order of linear with respect to the size of the protocol using machine learning. In training machine learning models for security verification of cryptographic protocols, a sufficient amount of data, i.e., a set of protocol data with security labels, is difficult to collect from academic papers and other sources. To overcome this issue, we propose a way to create arbitrarily large datasets by automatically generating random protocols and assigning security labels to them using formal verification tools. Furthermore, to exploit structural features of protocols, we construct a neural network that processes a protocol along its series and tree structures. We evaluate the proposed method by applying it to verification of practical cryptographic protocols.