 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Fast-StrucTexT: An Efficient Hourglass Transformer with Modality-guided Dynamic Token Merge for Document Understanding
May 19, 2023
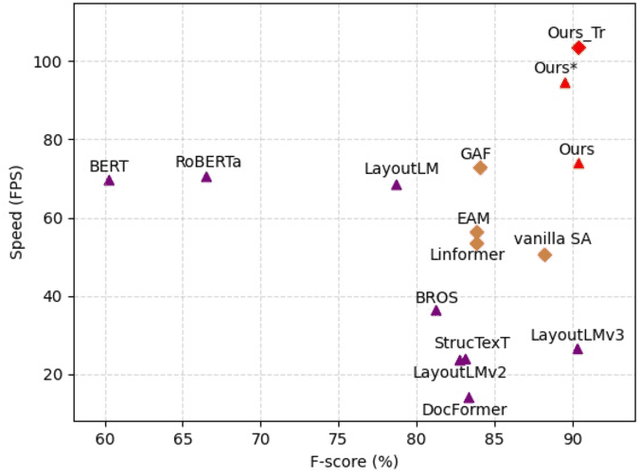
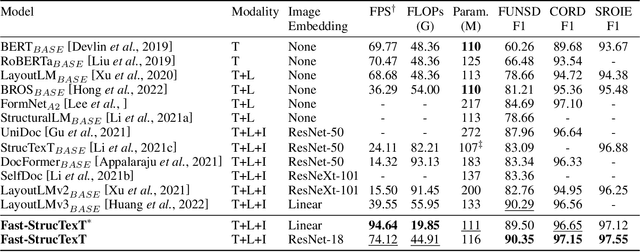
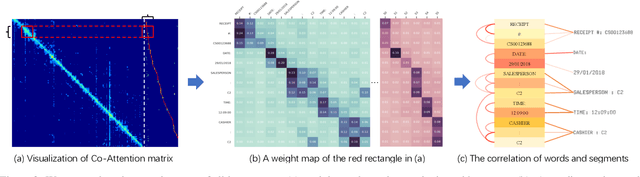

Transformers achieve promising performance in document understanding because of their high effectiveness and still suffer from quadratic computational complexity dependency on the sequence length. General efficient transformers are challenging to be directly adapted to model document. They are unable to handle the layout representation in documents, e.g. word, line and paragraph, on different granularity levels and seem hard to achieve a good trade-off between efficiency and performance. To tackle the concerns, we propose Fast-StrucTexT, an efficient multi-modal framework based on the StrucTexT algorithm with an hourglass transformer architecture, for visual document understanding. Specifically, we design a modality-guided dynamic token merging block to make the model learn multi-granularity representation and prunes redundant tokens. Additionally, we present a multi-modal interaction module called Symmetry Cross Attention (SCA) to consider multi-modal fusion and efficiently guide the token mergence. The SCA allows one modality input as query to calculate cross attention with another modality in a dual phase. Extensive experiments on FUNSD, SROIE, and CORD datasets demonstrate that our model achieves the state-of-the-art performance and almost 1.9X faster inference time than the state-of-the-art methods.
Risk-Sensitive Extended Kalman Filter
May 19, 2023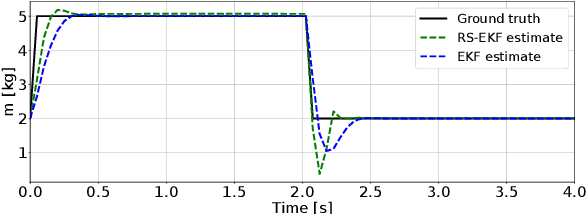
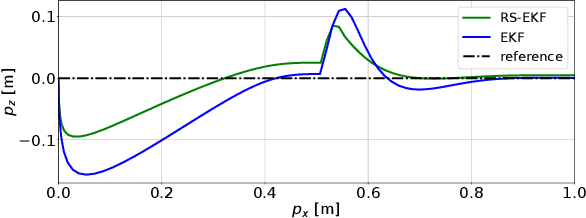
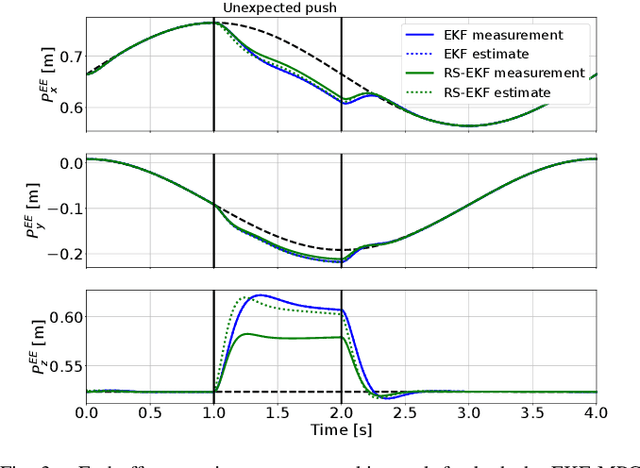
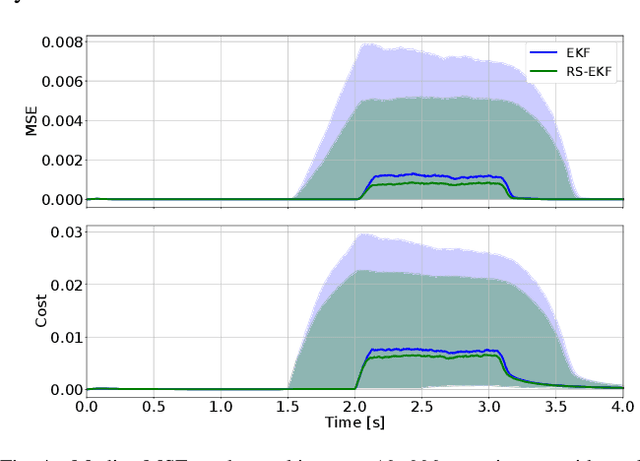
In robotics, designing robust algorithms in the face of estimation uncertainty is a challenging task. Indeed, controllers often do not consider the estimation uncertainty and only rely on the most likely estimated state. Consequently, sudden changes in the environment or the robot's dynamics can lead to catastrophic behaviors. In this work, we present a risk-sensitive Extended Kalman Filter that allows doing output-feedback Model Predictive Control (MPC) safely. This filter adapts its estimation to the control objective. By taking a pessimistic estimate concerning the value function resulting from the MPC controller, the filter provides increased robustness to the controller in phases of uncertainty as compared to a standard Extended Kalman Filter (EKF). Moreover, the filter has the same complexity as an EKF, so that it can be used for real-time model-predictive control. The paper evaluates the risk-sensitive behavior of the proposed filter when used in a nonlinear model-predictive control loop on a planar drone and industrial manipulator in simulation, as well as on an external force estimation task on a real quadruped robot. These experiments demonstrate the abilities of the approach to improve performance in the face of uncertainties significantly.
Learning for Open-World Calibration with Graph Neural Networks
May 19, 2023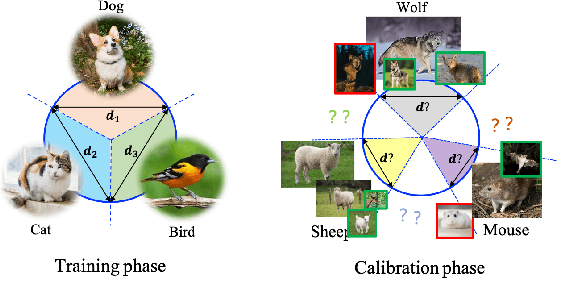
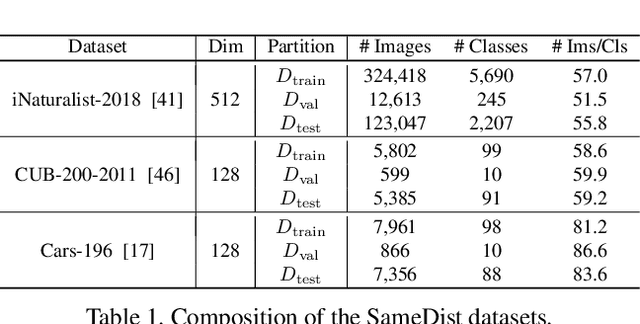
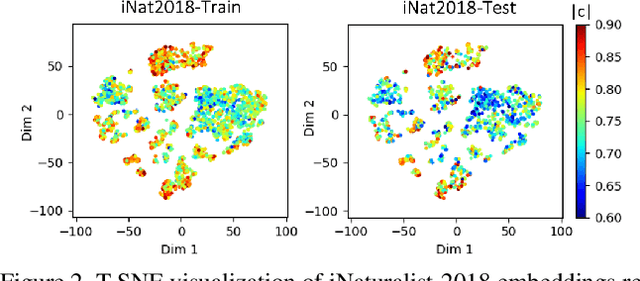
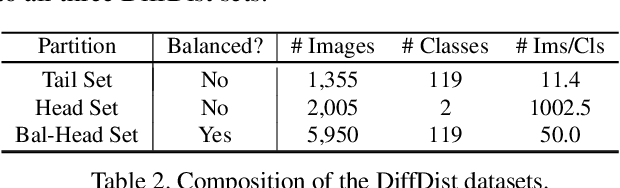
We tackle the problem of threshold calibration for open-world recognition by incorporating representation compactness measures into clustering. Unlike the open-set recognition which focuses on discovering and rejecting the unknown, open-world recognition learns robust representations that are generalizable to disjoint unknown classes at test time. Our proposed method is based on two key observations: (i) representation structures among neighbouring images in high dimensional visual embedding spaces have strong self-similarity which can be leveraged to encourage transferability to the open world, (ii) intra-class embedding structures can be modeled with the marginalized von Mises-Fisher (vMF) probability, whose correlation with the true positive rate is dataset-invariant. Motivated by these, we design a unified framework centered around a graph neural network (GNN) to jointly predict the pseudo-labels and the vMF concentrations which indicate the representation compactness. These predictions can be converted into statistical estimations for recognition accuracy, allowing more robust calibration of the distance threshold to achieve target utility for the open-world classes. Results on a variety of visual recognition benchmarks demonstrate the superiority of our method over traditional posthoc calibration methods for the open world, especially under distribution shift.
Implicit Bias of Gradient Descent for Logistic Regression at the Edge of Stability
May 19, 2023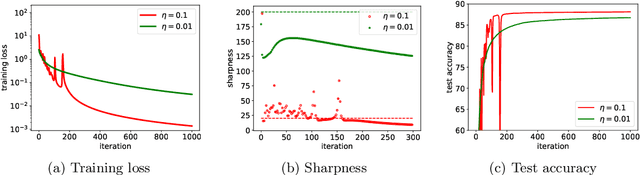
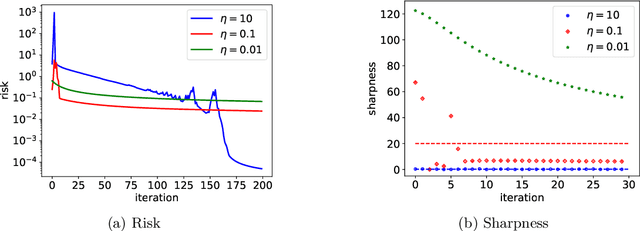
Recent research has observed that in machine learning optimization, gradient descent (GD) often operates at the edge of stability (EoS) [Cohen, et al., 2021], where the stepsizes are set to be large, resulting in non-monotonic losses induced by the GD iterates. This paper studies the convergence and implicit bias of constant-stepsize GD for logistic regression on linearly separable data in the EoS regime. Despite the presence of local oscillations, we prove that the logistic loss can be minimized by GD with any constant stepsize over a long time scale. Furthermore, we prove that with any constant stepsize, the GD iterates tend to infinity when projected to a max-margin direction (the hard-margin SVM direction) and converge to a fixed vector that minimizes a strongly convex potential when projected to the orthogonal complement of the max-margin direction. In contrast, we also show that in the EoS regime, GD iterates may diverge catastrophically under the exponential loss, highlighting the superiority of the logistic loss. These theoretical findings are in line with numerical simulations and complement existing theories on the convergence and implicit bias of GD, which are only applicable when the stepsizes are sufficiently small.
Tester-Learners for Halfspaces: Universal Algorithms
May 19, 2023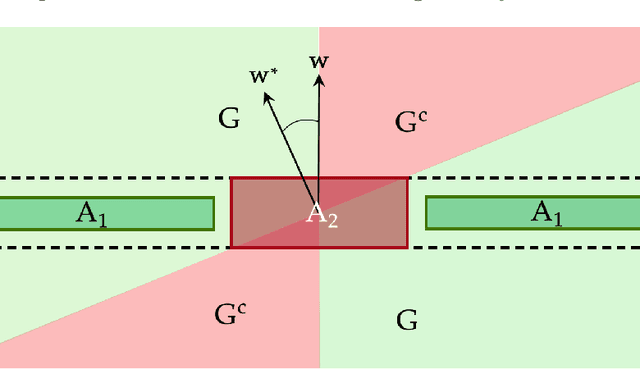
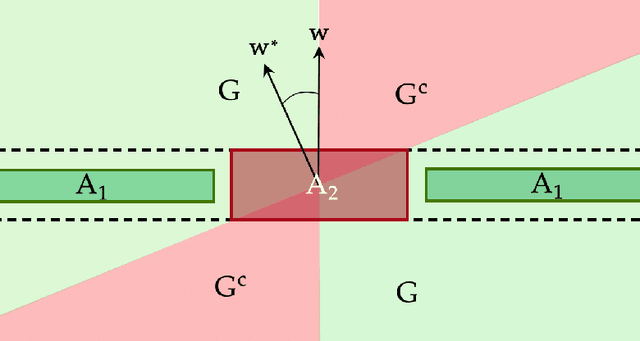
We give the first tester-learner for halfspaces that succeeds universally over a wide class of structured distributions. Our universal tester-learner runs in fully polynomial time and has the following guarantee: the learner achieves error $O(\mathrm{opt}) + \epsilon$ on any labeled distribution that the tester accepts, and moreover, the tester accepts whenever the marginal is any distribution that satisfies a Poincar\'e inequality. In contrast to prior work on testable learning, our tester is not tailored to any single target distribution but rather succeeds for an entire target class of distributions. The class of Poincar\'e distributions includes all strongly log-concave distributions, and, assuming the Kannan--L\'{o}vasz--Simonovits (KLS) conjecture, includes all log-concave distributions. In the special case where the label noise is known to be Massart, our tester-learner achieves error $\mathrm{opt} + \epsilon$ while accepting all log-concave distributions unconditionally (without assuming KLS). Our tests rely on checking hypercontractivity of the unknown distribution using a sum-of-squares (SOS) program, and crucially make use of the fact that Poincar\'e distributions are certifiably hypercontractive in the SOS framework.
Generalizing to new calorimeter geometries with Geometry-Aware Autoregressive Models (GAAMs) for fast calorimeter simulation
May 19, 2023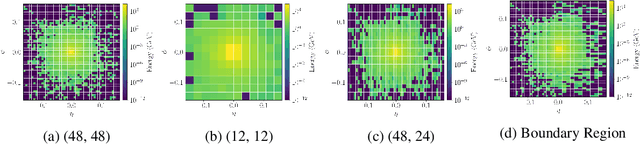
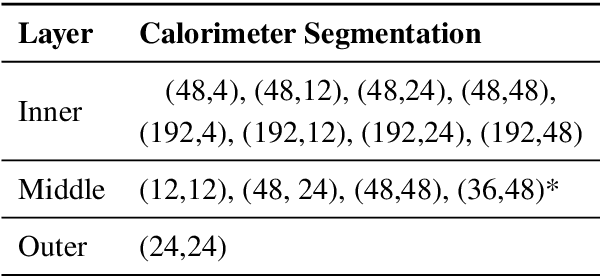
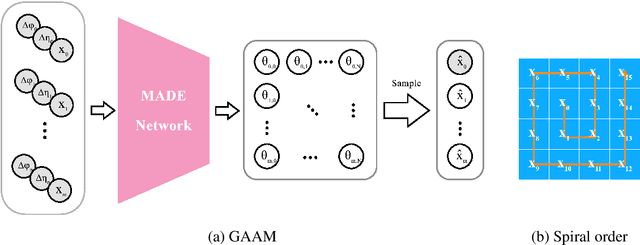
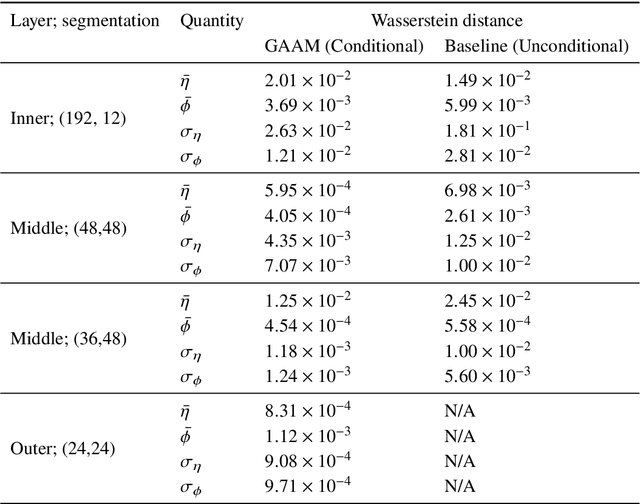
Generation of simulated detector response to collision products is crucial to data analysis in particle physics, but computationally very expensive. One subdetector, the calorimeter, dominates the computational time due to the high granularity of its cells and complexity of the interaction. Generative models can provide more rapid sample production, but currently require significant effort to optimize performance for specific detector geometries, often requiring many networks to describe the varying cell sizes and arrangements, which do not generalize to other geometries. We develop a {\it geometry-aware} autoregressive model, which learns how the calorimeter response varies with geometry, and is capable of generating simulated responses to unseen geometries without additional training. The geometry-aware model outperforms a baseline, unaware model by 50\% in metrics such as the Wasserstein distance between generated and true distributions of key quantities which summarize the simulated response. A single geometry-aware model could replace the hundreds of generative models currently designed for calorimeter simulation by physicists analyzing data collected at the Large Hadron Collider. For the study of future detectors, such a foundational model will be a crucial tool, dramatically reducing the large upfront investment usually needed to develop generative calorimeter models.
Backdoor Attacks on Time Series: A Generative Approach
Dec 07, 2022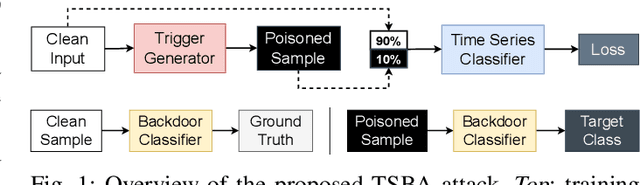
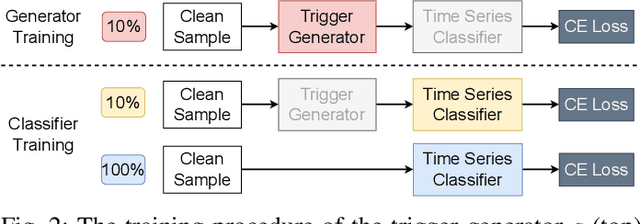

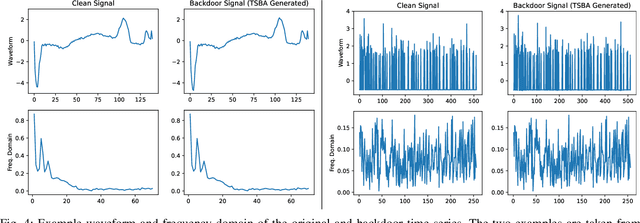
Backdoor attacks have emerged as one of the major security threats to deep learning models as they can easily control the model's test-time predictions by pre-injecting a backdoor trigger into the model at training time. While backdoor attacks have been extensively studied on images, few works have investigated the threat of backdoor attacks on time series data. To fill this gap, in this paper we present a novel generative approach for time series backdoor attacks against deep learning based time series classifiers. Backdoor attacks have two main goals: high stealthiness and high attack success rate. We find that, compared to images, it can be more challenging to achieve the two goals on time series. This is because time series have fewer input dimensions and lower degrees of freedom, making it hard to achieve a high attack success rate without compromising stealthiness. Our generative approach addresses this challenge by generating trigger patterns that are as realistic as real-time series patterns while achieving a high attack success rate without causing a significant drop in clean accuracy. We also show that our proposed attack is resistant to potential backdoor defenses. Furthermore, we propose a novel universal generator that can poison any type of time series with a single generator that allows universal attacks without the need to fine-tune the generative model for new time series datasets.
Local Gaussian Modifiers (LGMs): UAV dynamic trajectory generation for onboard computation
May 05, 2023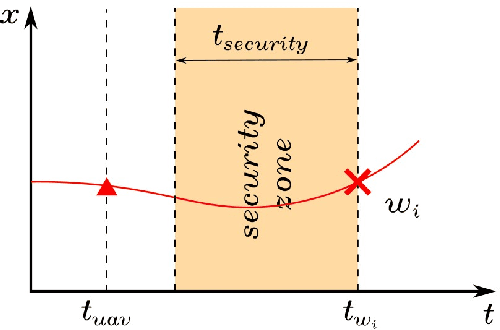
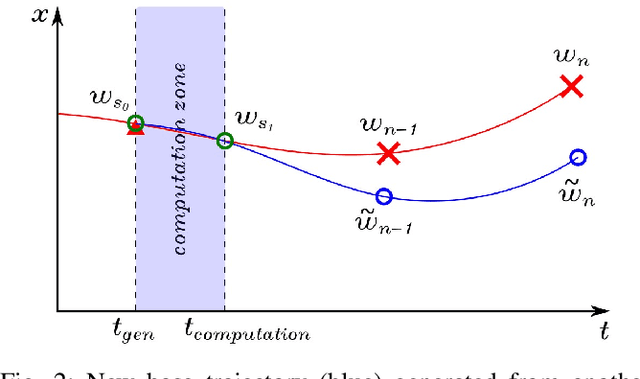
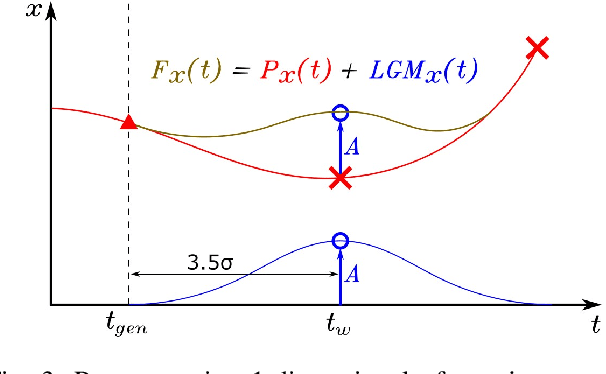
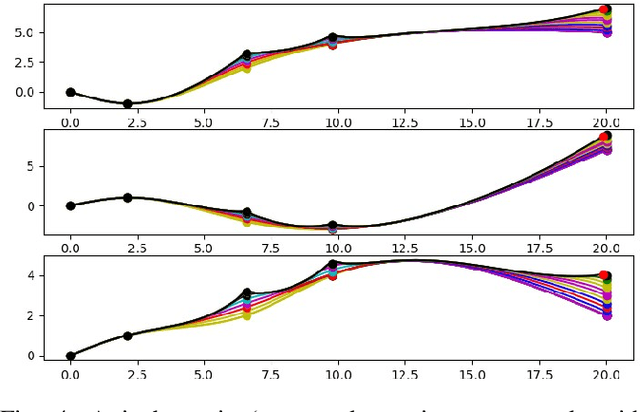
Agile autonomous drones are becoming increasingly popular in research due to the challenges they represent in fields like control, state estimation, or perception at high speeds. When all algorithms are computed onboard the uav, the computational limitations make the task of agile and robust flight even more difficult. One of the most computationally expensive tasks in agile flight is the generation of optimal trajectories that tackles the problem of planning a minimum time trajectory for a quadrotor over a sequence of specified waypoints. When these trajectories must be updated online due to changes in the environment or uncertainties, this high computational cost can leverage to not reach the desired waypoints or even crash in cluttered environments. In this paper, a fast lightweight dynamic trajectory modification approach is presented to allow modifying computational heavy trajectories using Local Gaussian Modifiers (LGMs), when recalculating a trajectory is not possible due to the time of computation. Our approach was validated in simulation, being able to pass through a race circuit with dynamic gates with top speeds up to 16.0 m/s, and was also validated in real flight reaching speeds up to 4.0 m/s in a fully autonomous onboard computing condition.
Dynamic DH-MBIR for Phase-Error Estimation from Streaming Digital-Holography Data
May 05, 2023
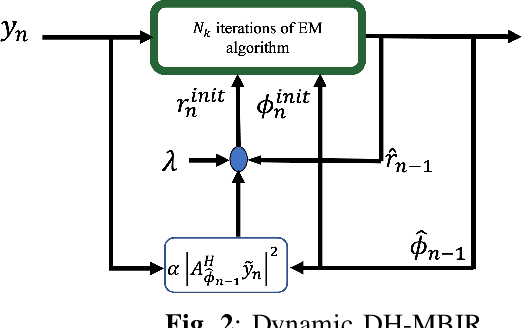
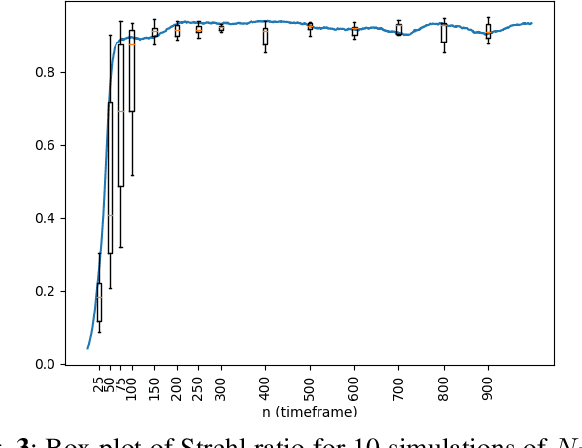
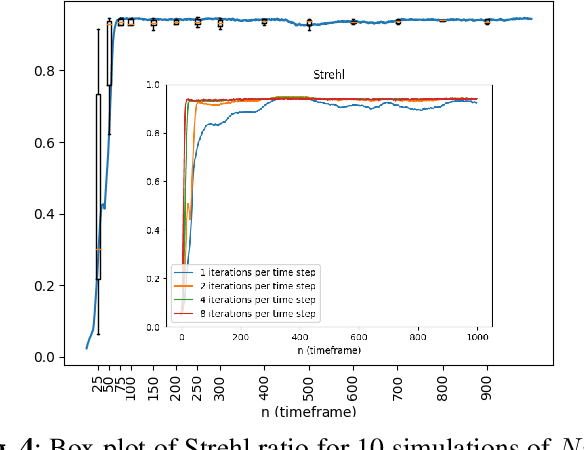
Directed energy applications require the estimation of digital-holographic (DH) phase errors due to atmospheric turbulence in order to accurately focus the outgoing beam. These phase error estimates must be computed with very low latency to keep pace with changing atmospheric parameters, which requires that phase errors be estimated in a single shot of DH data. The digital holography model-based iterative reconstruction (DH-MBIR) algorithm is capable of accurately estimating phase errors in a single shot using the expectation maximization (EM) algorithm. However, existing implementations of DH-MBIR require hundreds of iterations, which is not practical for real-time applications. In this paper, we present the Dynamic DH-MBIR (DDH-MBIR) algorithm for estimating isoplanatic phase errors from streaming single-shot data with extremely low latency. The Dynamic DH-MBIR algorithm reduces the computation and latency by orders of magnitude relative to conventional DH-MBIR, making real-time throughput and latency feasible in applications. Using simulated data that models frozen flow of atmospheric turbulence, we show that our algorithm can achieve a consistently high Strehl ratio with realistic simulation parameters using only 1 iteration per timestep.
RUPNet: Residual upsampling network for real-time polyp segmentation
Jan 06, 2023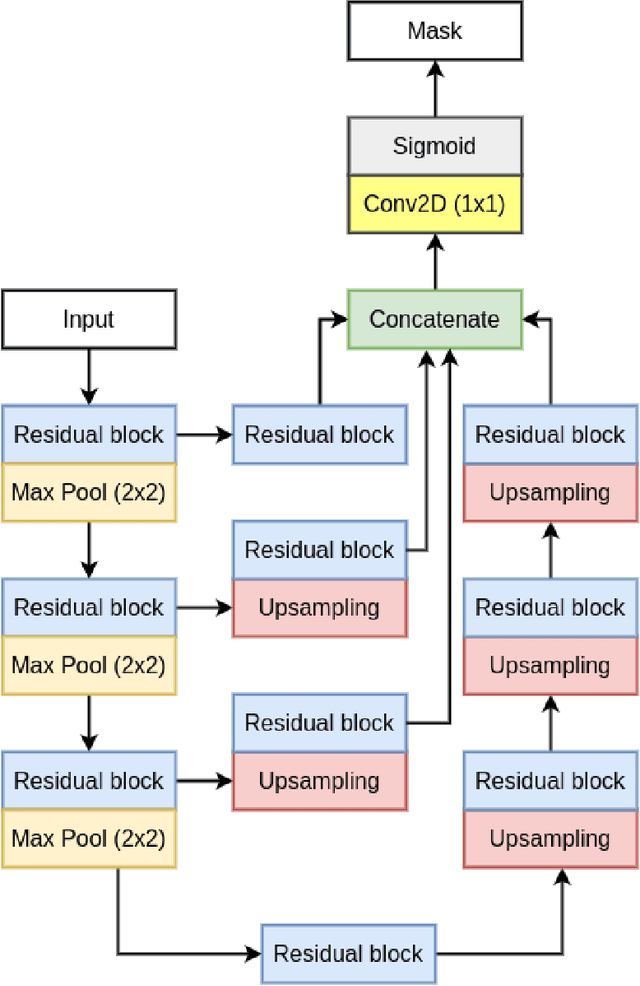
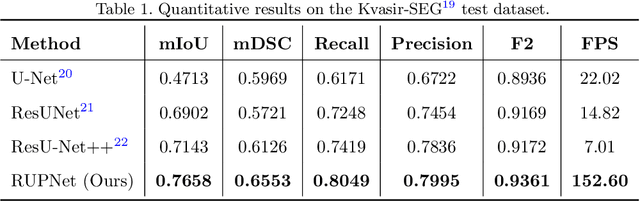
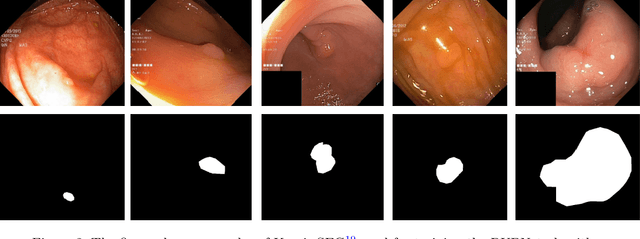
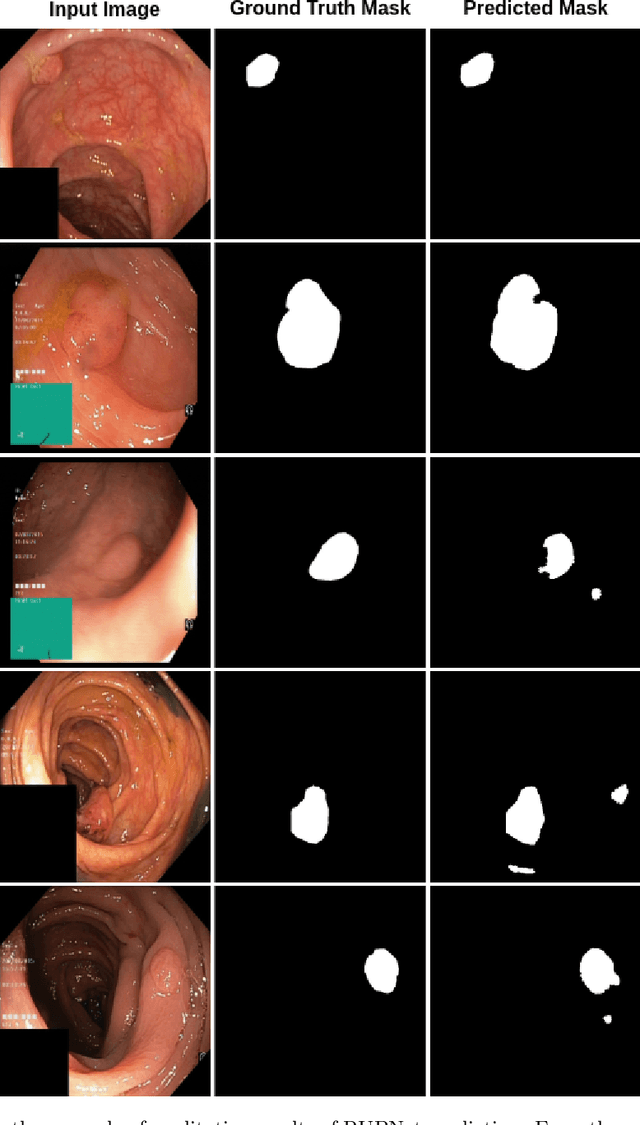
Colorectal cancer is among the most prevalent cause of cancer-related mortality worldwide. Detection and removal of polyps at an early stage can help reduce mortality and even help in spreading over adjacent organs. Early polyp detection could save the lives of millions of patients over the world as well as reduce the clinical burden. However, the detection polyp rate varies significantly among endoscopists. There is numerous deep learning-based method proposed, however, most of the studies improve accuracy. Here, we propose a novel architecture, Residual Upsampling Network (RUPNet) for colon polyp segmentation that can process in real-time and show high recall and precision. The proposed architecture, RUPNet, is an encoder-decoder network that consists of three encoders, three decoder blocks, and some additional upsampling blocks at the end of the network. With an image size of $512 \times 512$, the proposed method achieves an excellent real-time operation speed of 152.60 frames per second with an average dice coefficient of 0.7658, mean intersection of union of 0.6553, sensitivity of 0.8049, precision of 0.7995, and F2-score of 0.9361. The results suggest that RUPNet can give real-time feedback while retaining high accuracy indicating a good benchmark for early polyp detection.