 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Signal Processing Grand Challenge 2023 -- e-Prevention: Sleep Behavior as an Indicator of Relapses in Psychotic Patients
Apr 17, 2023
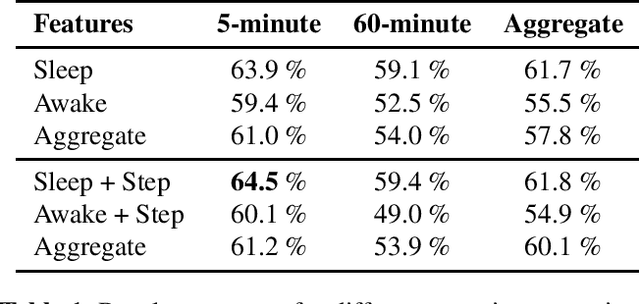
This paper presents the approach and results of USC SAIL's submission to the Signal Processing Grand Challenge 2023 - e-Prevention (Task 2), on detecting relapses in psychotic patients. Relapse prediction has proven to be challenging, primarily due to the heterogeneity of symptoms and responses to treatment between individuals. We address these challenges by investigating the use of sleep behavior features to estimate relapse days as outliers in an unsupervised machine learning setting. We extract informative features from human activity and heart rate data collected in the wild, and evaluate various combinations of feature types and time resolutions. We found that short-time sleep behavior features outperformed their awake counterparts and larger time intervals. Our submission was ranked 3rd in the Task's official leaderboard, demonstrating the potential of such features as an objective and non-invasive predictor of psychotic relapses.
Efficient Robot Skill Learning with Imitation from a Single Video for Contact-Rich Fabric Manipulation
Apr 24, 2023
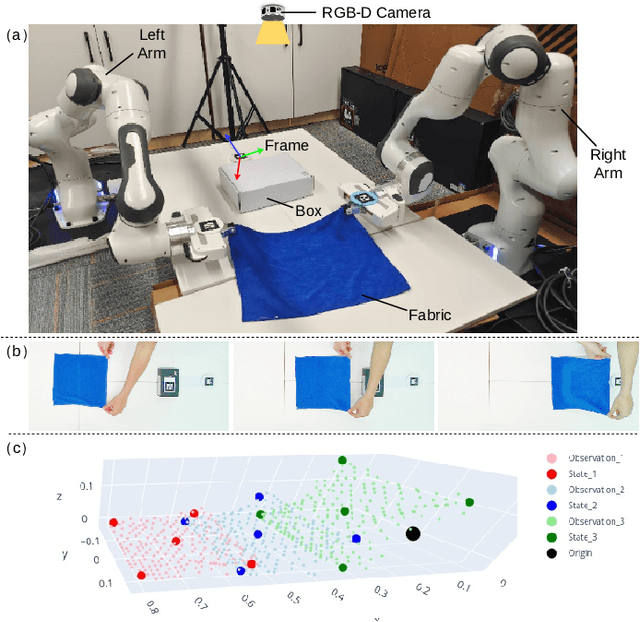


Classical policy search algorithms for robotics typically require performing extensive explorations, which are time-consuming and expensive to implement with real physical platforms. To facilitate the efficient learning of robot manipulation skills, in this work, we propose a new approach comprised of three modules: (1) learning of general prior knowledge with random explorations in simulation, including state representations, dynamic models, and the constrained action space of the task; (2) extraction of a state alignment-based reward function from a single demonstration video; (3) real-time optimization of the imitation policy under systematic safety constraints with sampling-based model predictive control. This solution results in an efficient one-shot imitation-from-video strategy that simplifies the learning and execution of robot skills in real applications. Specifically, we learn priors in a scene of a task family and then deploy the policy in a novel scene immediately following a single demonstration, preventing time-consuming and risky explorations in the environment. As we do not make a strong assumption of dynamic consistency between the scenes, learning priors can be conducted in simulation to avoid collecting data in real-world circumstances. We evaluate the effectiveness of our approach in the context of contact-rich fabric manipulation, which is a common scenario in industrial and domestic tasks. Detailed numerical simulations and real-world hardware experiments reveal that our method can achieve rapid skill acquisition for challenging manipulation tasks.
Label-free timing analysis of modularized nuclear detectors with physics-constrained deep learning
Apr 24, 2023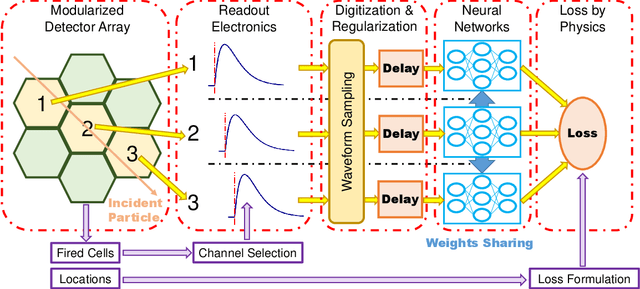
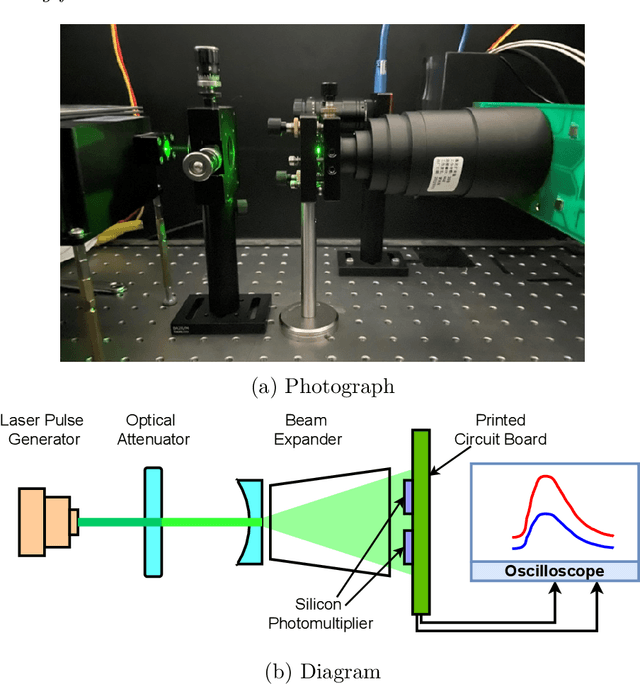
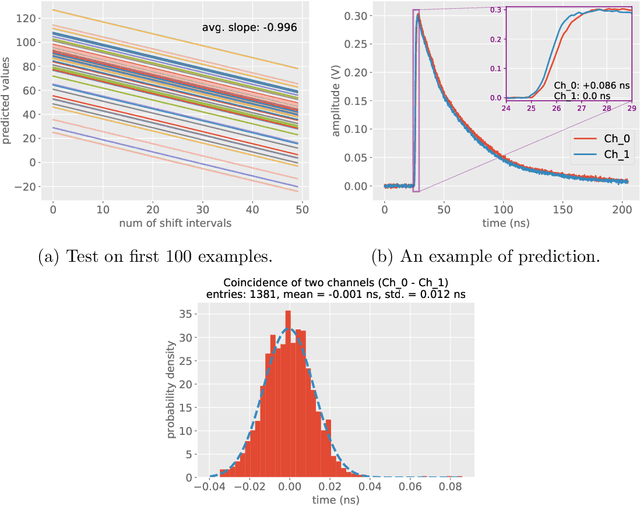
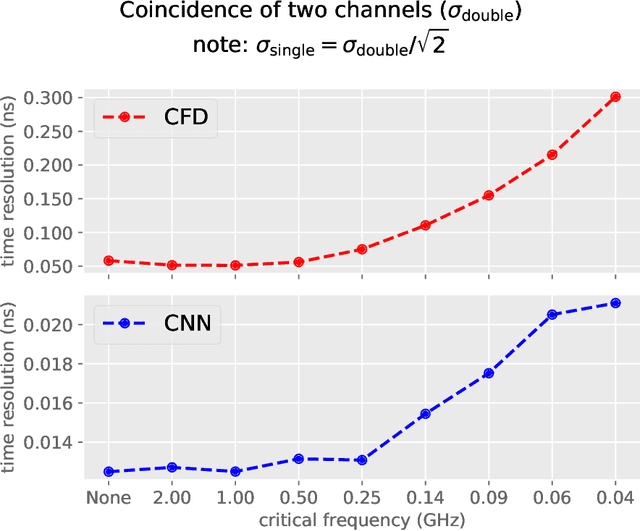
Pulse timing is an important topic in nuclear instrumentation, with far-reaching applications from high energy physics to radiation imaging. While high-speed analog-to-digital converters become more and more developed and accessible, their potential uses and merits in nuclear detector signal processing are still uncertain, partially due to associated timing algorithms which are not fully understood and utilized. In this paper, we propose a novel method based on deep learning for timing analysis of modularized nuclear detectors without explicit needs of labelling event data. By taking advantage of the inner time correlation of individual detectors, a label-free loss function with a specially designed regularizer is formed to supervise the training of neural networks towards a meaningful and accurate mapping function. We mathematically demonstrate the existence of the optimal function desired by the method, and give a systematic algorithm for training and calibration of the model. The proposed method is validated on two experimental datasets. In the toy experiment, the neural network model achieves the single-channel time resolution of 8.8 ps and exhibits robustness against concept drift in the dataset. In the electromagnetic calorimeter experiment, several neural network models (FC, CNN and LSTM) are tested to show their conformance to the underlying physical constraint and to judge their performance against traditional methods. In total, the proposed method works well in either ideal or noisy experimental condition and recovers the time information from waveform samples successfully and precisely.
Distributed Unconstrained Optimization with Time-varying Cost Functions
Dec 12, 2022
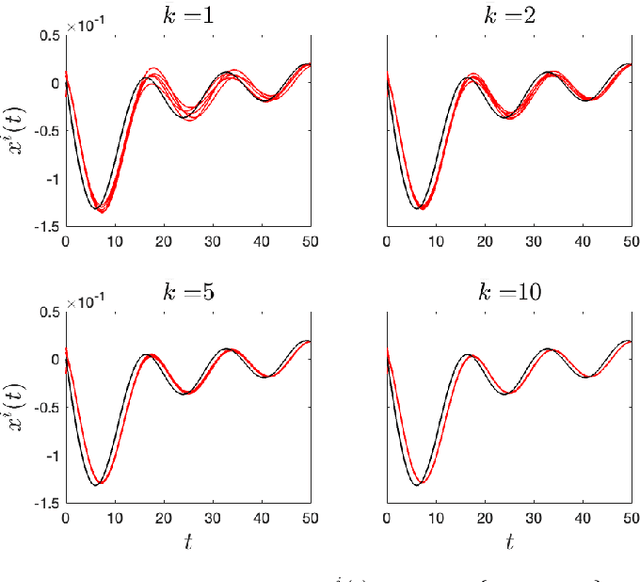
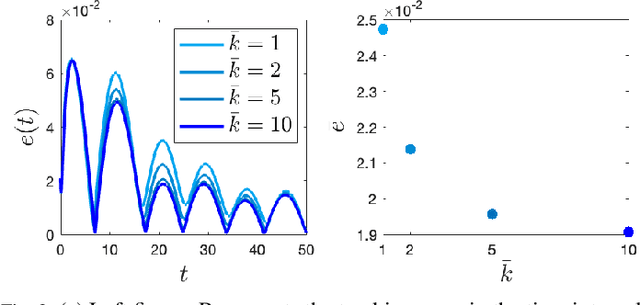
In this paper, we propose a novel solution for the distributed unconstrained optimization problem where the total cost is the summation of time-varying local cost functions of a group networked agents. The objective is to track the optimal trajectory that minimizes the total cost at each time instant. Our approach consists of a two-stage dynamics, where the first one samples the first and second derivatives of the local costs periodically to construct an estimate of the descent direction towards the optimal trajectory, and the second one uses this estimate and a consensus term to drive local states towards the time-varying solution while reaching consensus. The first part is carried out by the implementation of a weighted average consensus algorithm in the discrete-time framework and the second part is performed with a continuous-time dynamics. Using the Lyapunov stability analysis, an upper bound on the gradient of the total cost is obtained which is asymptotically reached. This bound is characterized by the properties of the local costs. To demonstrate the performance of the proposed method, a numerical example is conducted that studies tuning the algorithm's parameters and their effects on the convergence of local states to the optimal trajectory.
Wild-Time: A Benchmark of in-the-Wild Distribution Shift over Time
Nov 25, 2022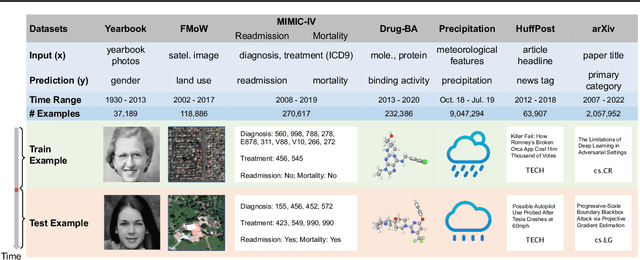
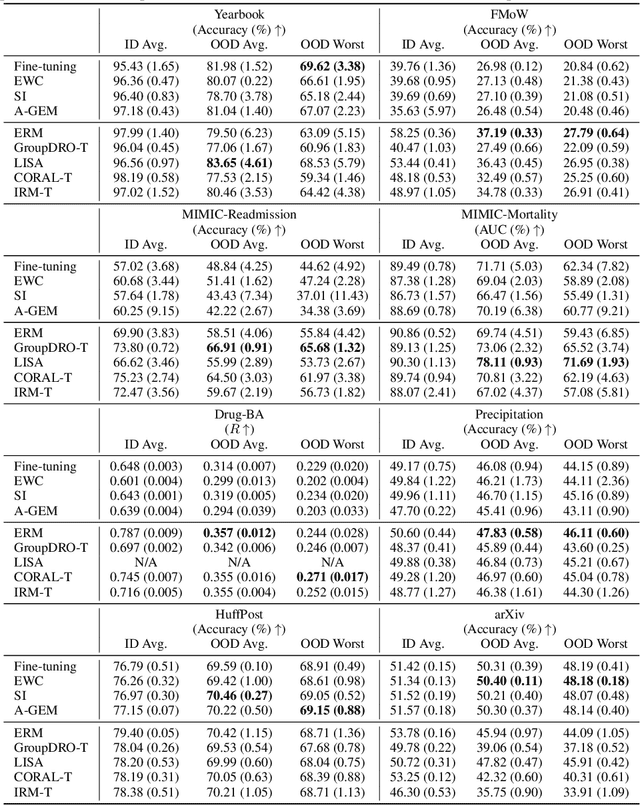
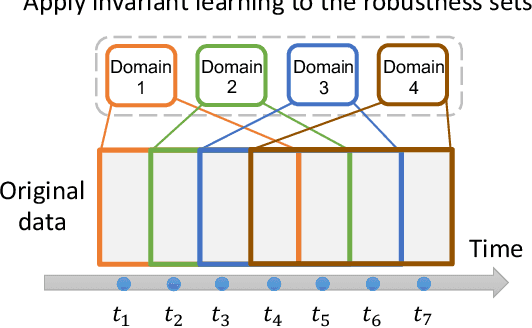
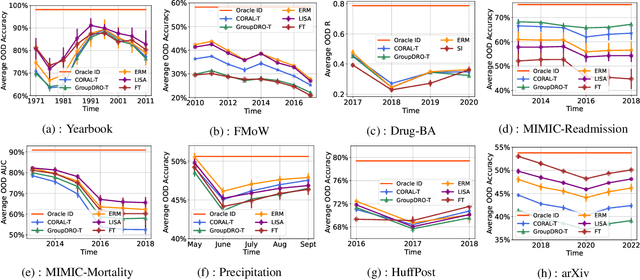
Distribution shift occurs when the test distribution differs from the training distribution, and it can considerably degrade performance of machine learning models deployed in the real world. Temporal shifts -- distribution shifts arising from the passage of time -- often occur gradually and have the additional structure of timestamp metadata. By leveraging timestamp metadata, models can potentially learn from trends in past distribution shifts and extrapolate into the future. While recent works have studied distribution shifts, temporal shifts remain underexplored. To address this gap, we curate Wild-Time, a benchmark of 5 datasets that reflect temporal distribution shifts arising in a variety of real-world applications, including patient prognosis and news classification. On these datasets, we systematically benchmark 13 prior approaches, including methods in domain generalization, continual learning, self-supervised learning, and ensemble learning. We use two evaluation strategies: evaluation with a fixed time split (Eval-Fix) and evaluation with a data stream (Eval-Stream). Eval-Fix, our primary evaluation strategy, aims to provide a simple evaluation protocol, while Eval-Stream is more realistic for certain real-world applications. Under both evaluation strategies, we observe an average performance drop of 20% from in-distribution to out-of-distribution data. Existing methods are unable to close this gap. Code is available at https://wild-time.github.io/.
Locosim: an Open-Source Cross-Platform Robotics Framework
May 03, 2023

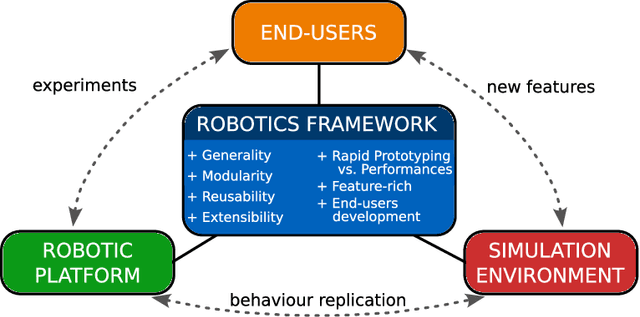

The architecture of a robotics software framework tremendously influences the effort and time it takes for end users to test new concepts in a simulation environment and to control real hardware. Many years of activity in the field allowed us to sort out crucial requirements for a framework tailored for robotics: modularity and extensibility, source code reusability, feature richness, and user-friendliness. We implemented these requirements and collected best practices in Locosim, a cross-platform framework for simulation and real hardware. In this paper, we describe the architecture of Locosim and illustrate some use cases that show its potential.
A transformer-based method for zero and few-shot biomedical named entity recognition
May 12, 2023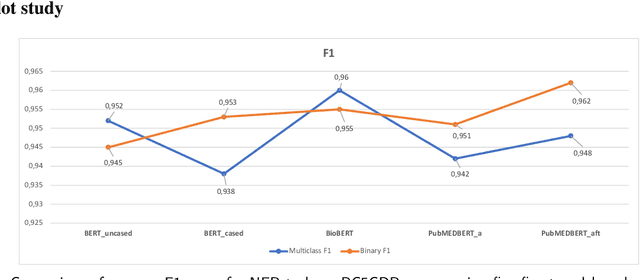
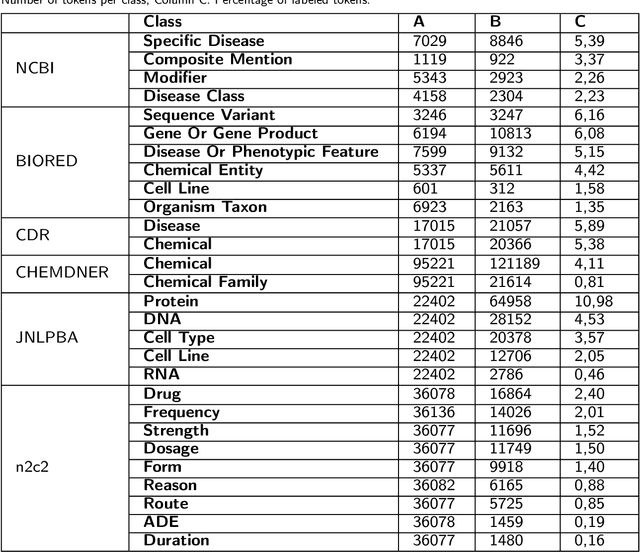

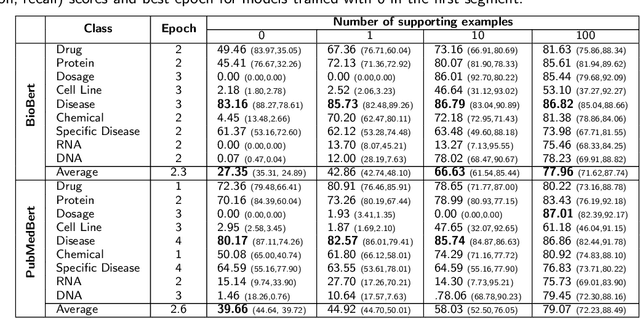
Supervised named entity recognition (NER) in the biomedical domain is dependent on large sets of annotated texts with the given named entities, whose creation can be time-consuming and expensive. Furthermore, the extraction of new entities often requires conducting additional annotation tasks and retraining the model. To address these challenges, this paper proposes a transformer-based method for zero- and few-shot NER in the biomedical domain. The method is based on transforming the task of multi-class token classification into binary token classification (token contains the searched entity or does not contain the searched entity) and pre-training on a larger amount of datasets and biomedical entities, from where the method can learn semantic relations between the given and potential classes. We have achieved average F1 scores of 35.44% for zero-shot NER, 50.10% for one-shot NER, 69.94% for 10-shot NER, and 79.51% for 100-shot NER on 9 diverse evaluated biomedical entities with PubMedBERT fine-tuned model. The results demonstrate the effectiveness of the proposed method for recognizing new entities with limited examples, with comparable or better results from the state-of-the-art zero- and few-shot NER methods.
A Central Asian Food Dataset for Personalized Dietary Interventions, Extended Abstract
May 12, 2023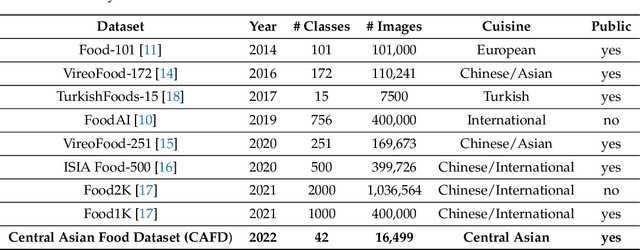

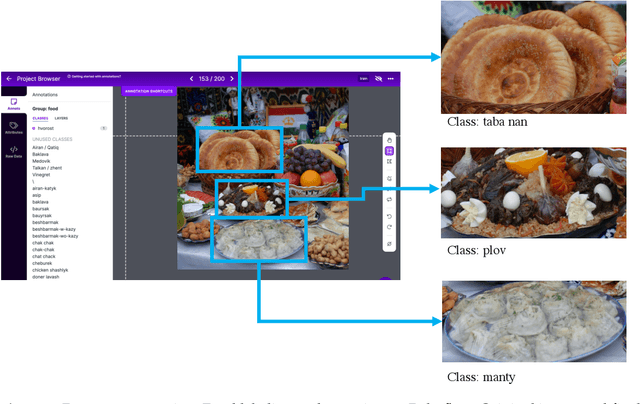

Nowadays, it is common for people to take photographs of every beverage, snack, or meal they eat and then post these photographs on social media platforms. Leveraging these social trends, real-time food recognition and reliable classification of these captured food images can potentially help replace some of the tedious recording and coding of food diaries to enable personalized dietary interventions. Although Central Asian cuisine is culturally and historically distinct, there has been little published data on the food and dietary habits of people in this region. To fill this gap, we aim to create a reliable dataset of regional foods that is easily accessible to both public consumers and researchers. To the best of our knowledge, this is the first work on creating a Central Asian Food Dataset (CAFD). The final dataset contains 42 food categories and over 16,000 images of national dishes unique to this region. We achieved a classification accuracy of 88.70\% (42 classes) on the CAFD using the ResNet152 neural network model. The food recognition models trained on the CAFD demonstrate computer vision's effectiveness and high accuracy for dietary assessment.
QuickVC: Many-to-any Voice Conversion Using Inverse Short-time Fourier Transform for Faster Conversion
Feb 17, 2023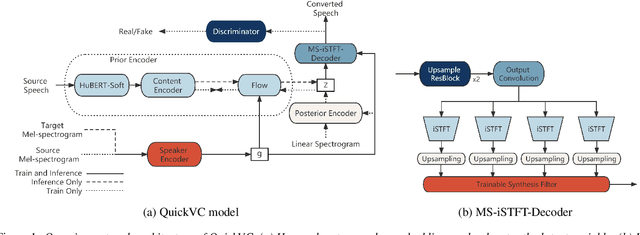
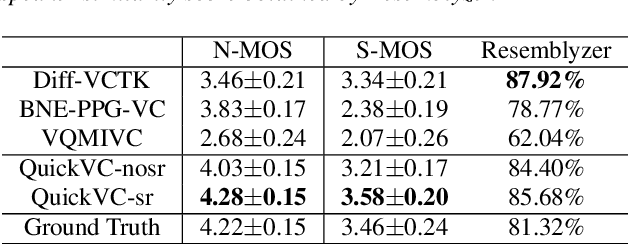

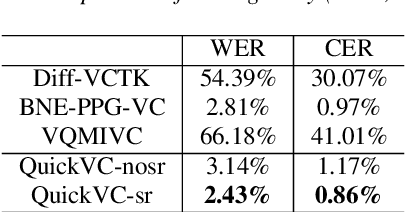
With the development of automatic speech recognition (ASR) and text-to-speech (TTS) technology, high-quality voice conversion (VC) can be achieved by extracting source content information and target speaker information to reconstruct waveforms. However, current methods still require improvement in terms of inference speed. In this study, we propose a lightweight VITS-based VC model that uses the HuBERT-Soft model to extract content information features without speaker information. Through subjective and objective experiments on synthesized speech, the proposed model demonstrates competitive results in terms of naturalness and similarity. Importantly, unlike the original VITS model, we use the inverse short-time Fourier transform (iSTFT) to replace the most computationally expensive part. Experimental results show that our model can generate samples at over 5000 kHz on the 3090 GPU and over 250 kHz on the i9-10900K CPU, achieving competitive speed for the same hardware configuration.
Neural Speech Enhancement with Very Low Algorithmic Latency and Complexity via Integrated Full- and Sub-Band Modeling
Apr 18, 2023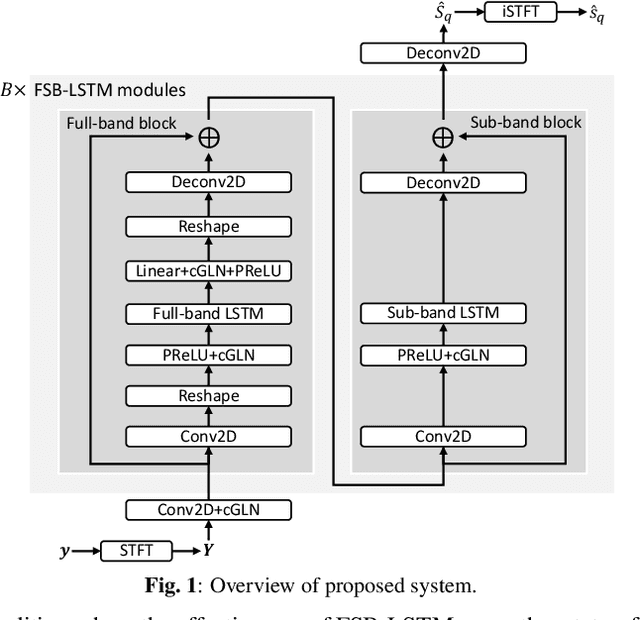

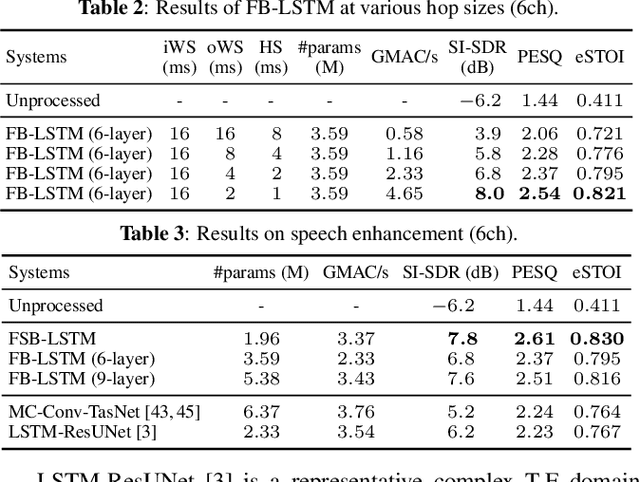
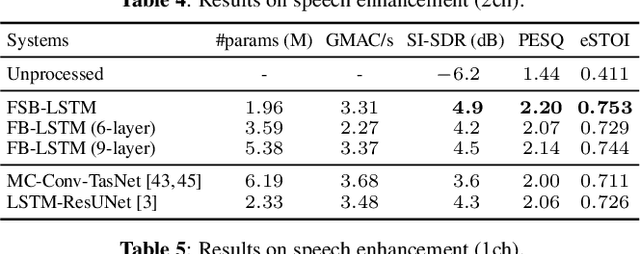
We propose FSB-LSTM, a novel long short-term memory (LSTM) based architecture that integrates full- and sub-band (FSB) modeling, for single- and multi-channel speech enhancement in the short-time Fourier transform (STFT) domain. The model maintains an information highway to flow an over-complete input representation through multiple FSB-LSTM modules. Each FSB-LSTM module consists of a full-band block to model spectro-temporal patterns at all frequencies and a sub-band block to model patterns within each sub-band, where each of the two blocks takes a down-sampled representation as input and returns an up-sampled discriminative representation to be added to the block input via a residual connection. The model is designed to have a low algorithmic complexity, a small run-time buffer and a very low algorithmic latency, at the same time producing a strong enhancement performance on a noisy-reverberant speech enhancement task even if the hop size is as low as $2$ ms.