 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Towards a real-time demand response framework for smart communities using clustering techniques
Mar 01, 2023
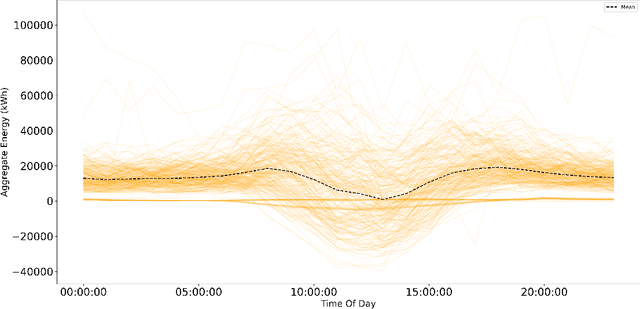
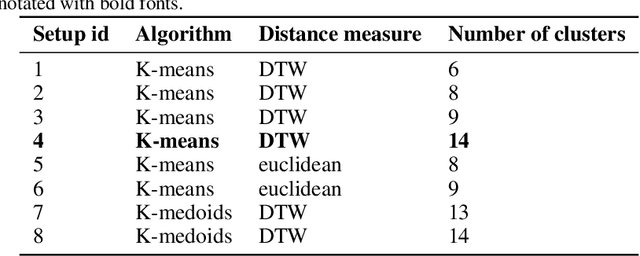
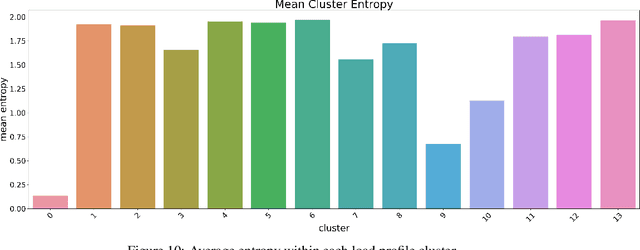
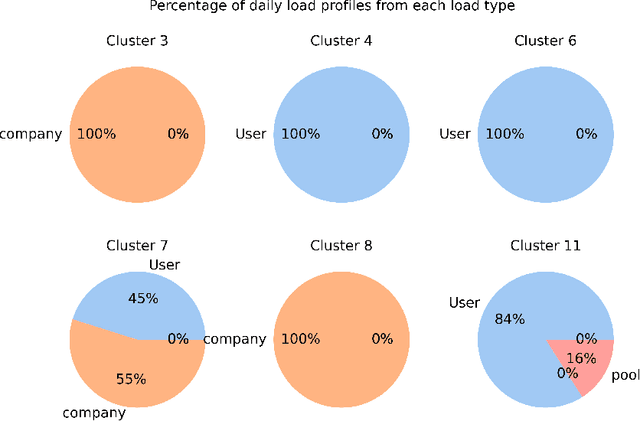
The present study explores the use of clustering techniques for the design and implementation of a demand response (DR) program for commercial and residential prosumers. The goal of the program is to shift the participants' consumption behavior to mitigate two issues a) the reverse power flow at the primary substation, that occurs when generation from solar panels in the local grid exceeds consumption and b) the system wide peak demand, that typically occurs during hours of the late afternoon. For the clustering stage, three popular algorithms for electrical load clustering are employed -- namely k-means, k-medoids and a hierarchical clustering algorithm -- alongside two different distance metrics -- namely euclidean and constrained Dynamic Time Warping (DTW). We evaluate the methods using different validation metrics including a novel metric -- namely peak performance score (PPS) -- that we propose in the context of this study. The best setup is employed to divide daily prosumer load profiles into clusters and each cluster is analyzed in terms of load shape, mean entropy and distribution of load profiles from each load type. These characteristics are then used to distinguish the clusters that would be most likely to aid with the DR schemes would fit each cluster. Finally, we conceptualize a DR system that combines forecasting, clustering and a price-based demand projection engine to produce daily individualized DR recommendations and pricing policies for prosumers participating in the program. The results of this study can be useful for network operators and utilities that aim to develop targeted DR programs for groups of prosumers within flexible energy communities.
A Time Series Approach to Parkinson's Disease Classification from EEG
Jan 20, 2023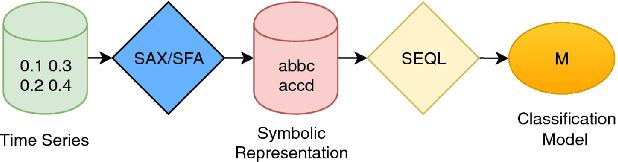
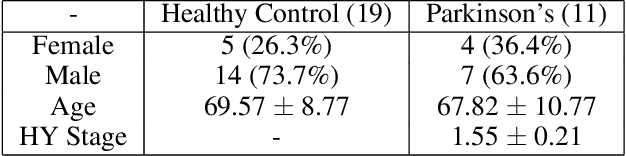
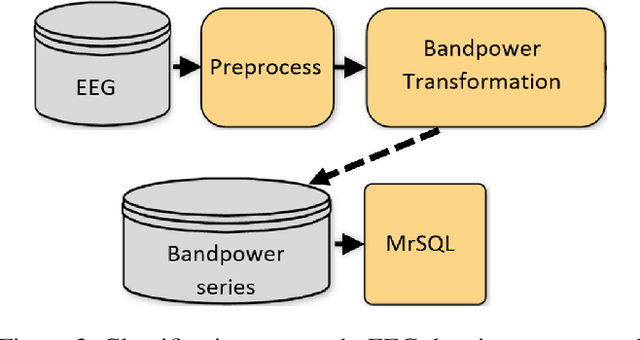
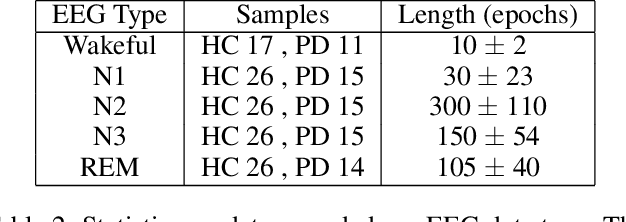
Firstly, we present a novel representation for EEG data, a 7-variate series of band power coefficients, which enables the use of (previously inaccessible) time series classification methods. Specifically, we implement the multi-resolution representation-based time series classification method MrSQL. This is deployed on a challenging early-stage Parkinson's dataset that includes wakeful and sleep EEG. Initial results are promising with over 90% accuracy achieved on all EEG data types used. Secondly, we present a framework that enables high-importance data types and brain regions for classification to be identified. Using our framework, we find that, across different EEG data types, it is the Prefrontal brain region that has the most predictive power for the presence of Parkinson's Disease. This outperformance was statistically significant versus ten of the twelve other brain regions (not significant versus adjacent Left Frontal and Right Frontal regions). The Prefrontal region of the brain is important for higher-order cognitive processes and our results align with studies that have shown neural dysfunction in the prefrontal cortex in Parkinson's Disease.
Bayesian Reparameterization of Reward-Conditioned Reinforcement Learning with Energy-based Models
May 18, 2023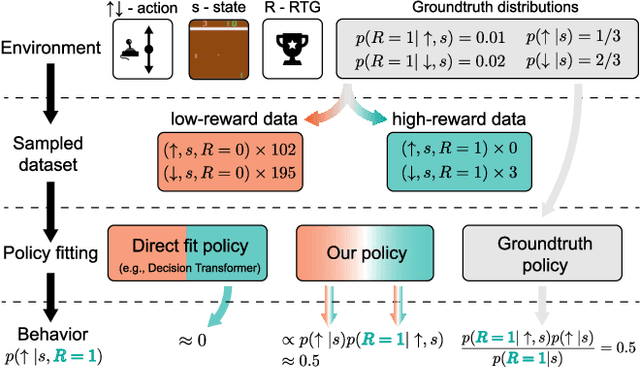
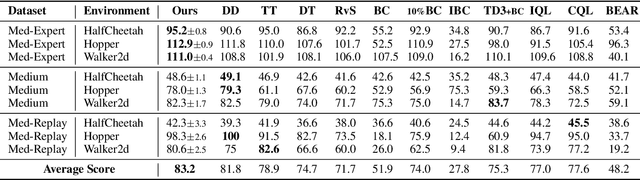
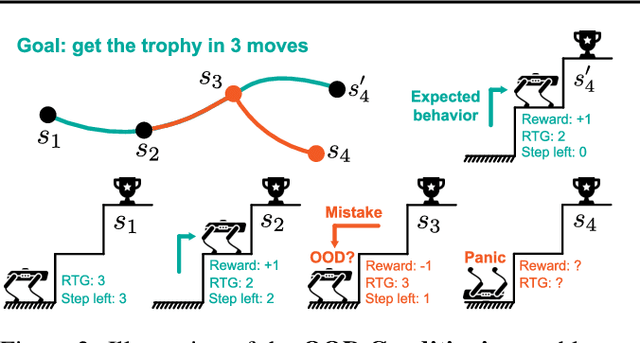
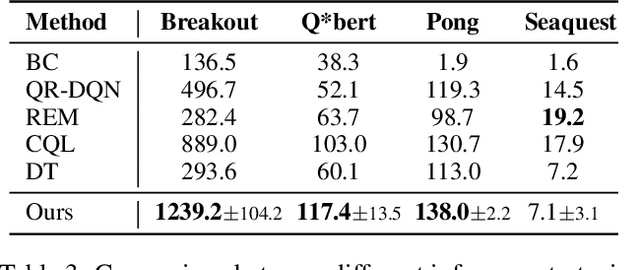
Recently, reward-conditioned reinforcement learning (RCRL) has gained popularity due to its simplicity, flexibility, and off-policy nature. However, we will show that current RCRL approaches are fundamentally limited and fail to address two critical challenges of RCRL -- improving generalization on high reward-to-go (RTG) inputs, and avoiding out-of-distribution (OOD) RTG queries during testing time. To address these challenges when training vanilla RCRL architectures, we propose Bayesian Reparameterized RCRL (BR-RCRL), a novel set of inductive biases for RCRL inspired by Bayes' theorem. BR-RCRL removes a core obstacle preventing vanilla RCRL from generalizing on high RTG inputs -- a tendency that the model treats different RTG inputs as independent values, which we term ``RTG Independence". BR-RCRL also allows us to design an accompanying adaptive inference method, which maximizes total returns while avoiding OOD queries that yield unpredictable behaviors in vanilla RCRL methods. We show that BR-RCRL achieves state-of-the-art performance on the Gym-Mujoco and Atari offline RL benchmarks, improving upon vanilla RCRL by up to 11%.
Attacks on Online Learners: a Teacher-Student Analysis
May 18, 2023Machine learning models are famously vulnerable to adversarial attacks: small ad-hoc perturbations of the data that can catastrophically alter the model predictions. While a large literature has studied the case of test-time attacks on pre-trained models, the important case of attacks in an online learning setting has received little attention so far. In this work, we use a control-theoretical perspective to study the scenario where an attacker may perturb data labels to manipulate the learning dynamics of an online learner. We perform a theoretical analysis of the problem in a teacher-student setup, considering different attack strategies, and obtaining analytical results for the steady state of simple linear learners. These results enable us to prove that a discontinuous transition in the learner's accuracy occurs when the attack strength exceeds a critical threshold. We then study empirically attacks on learners with complex architectures using real data, confirming the insights of our theoretical analysis. Our findings show that greedy attacks can be extremely efficient, especially when data stream in small batches.
XFormer: Fast and Accurate Monocular 3D Body Capture
May 18, 2023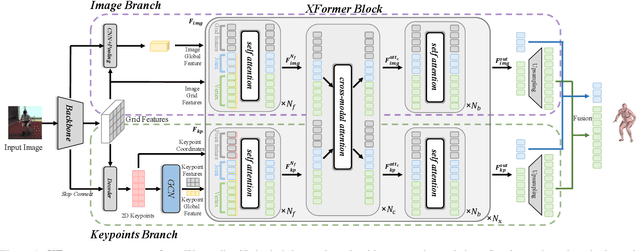
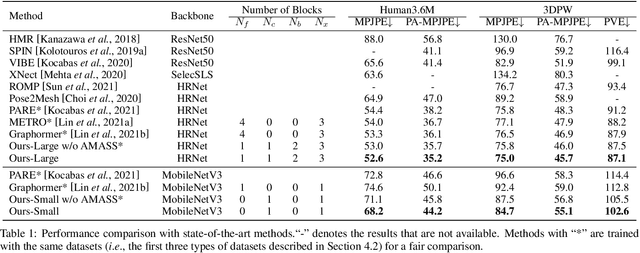
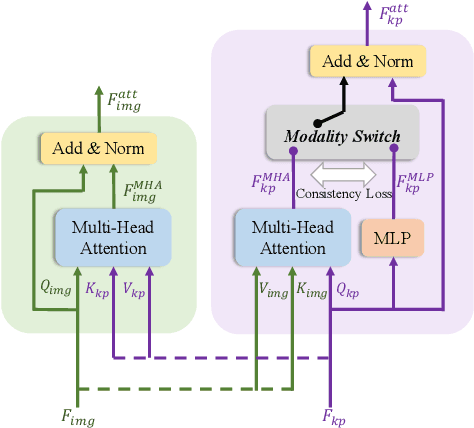
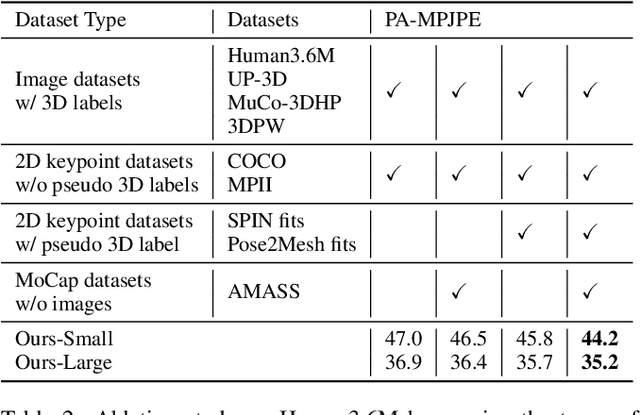
We present XFormer, a novel human mesh and motion capture method that achieves real-time performance on consumer CPUs given only monocular images as input. The proposed network architecture contains two branches: a keypoint branch that estimates 3D human mesh vertices given 2D keypoints, and an image branch that makes predictions directly from the RGB image features. At the core of our method is a cross-modal transformer block that allows information to flow across these two branches by modeling the attention between 2D keypoint coordinates and image spatial features. Our architecture is smartly designed, which enables us to train on various types of datasets including images with 2D/3D annotations, images with 3D pseudo labels, and motion capture datasets that do not have associated images. This effectively improves the accuracy and generalization ability of our system. Built on a lightweight backbone (MobileNetV3), our method runs blazing fast (over 30fps on a single CPU core) and still yields competitive accuracy. Furthermore, with an HRNet backbone, XFormer delivers state-of-the-art performance on Huamn3.6 and 3DPW datasets.
Dirichlet Diffusion Score Model for Biological Sequence Generation
May 18, 2023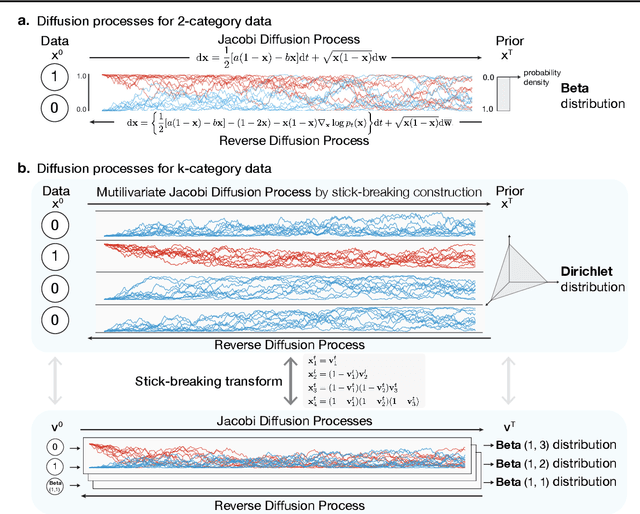
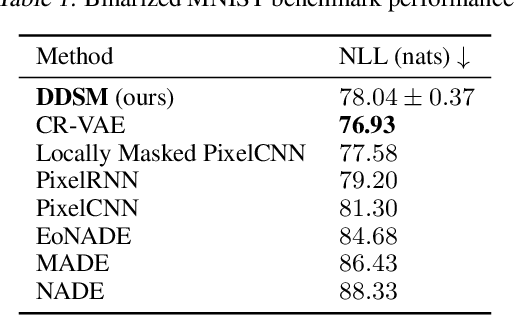
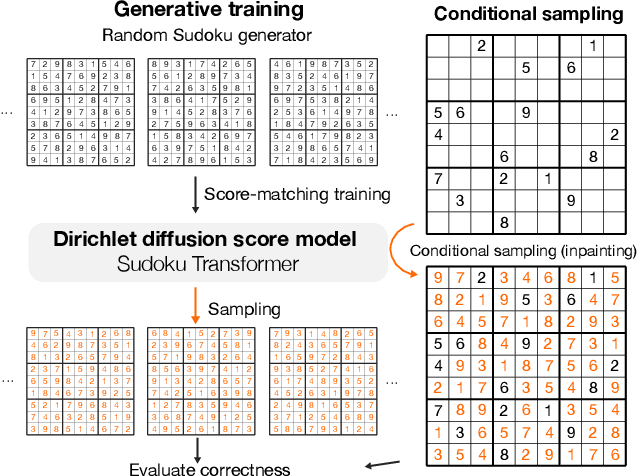
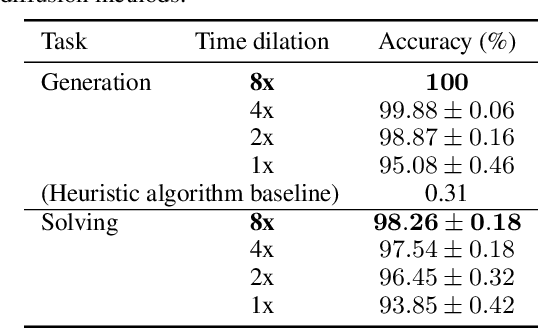
Designing biological sequences is an important challenge that requires satisfying complex constraints and thus is a natural problem to address with deep generative modeling. Diffusion generative models have achieved considerable success in many applications. Score-based generative stochastic differential equations (SDE) model is a continuous-time diffusion model framework that enjoys many benefits, but the originally proposed SDEs are not naturally designed for modeling discrete data. To develop generative SDE models for discrete data such as biological sequences, here we introduce a diffusion process defined in the probability simplex space with stationary distribution being the Dirichlet distribution. This makes diffusion in continuous space natural for modeling discrete data. We refer to this approach as Dirchlet diffusion score model. We demonstrate that this technique can generate samples that satisfy hard constraints using a Sudoku generation task. This generative model can also solve Sudoku, including hard puzzles, without additional training. Finally, we applied this approach to develop the first human promoter DNA sequence design model and showed that designed sequences share similar properties with natural promoter sequences.
Analyzing Norm Violations in Live-Stream Chat
May 18, 2023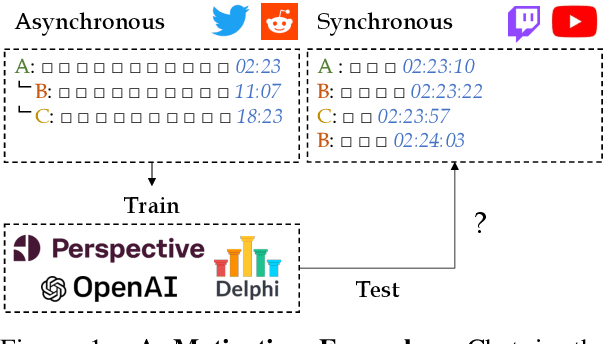
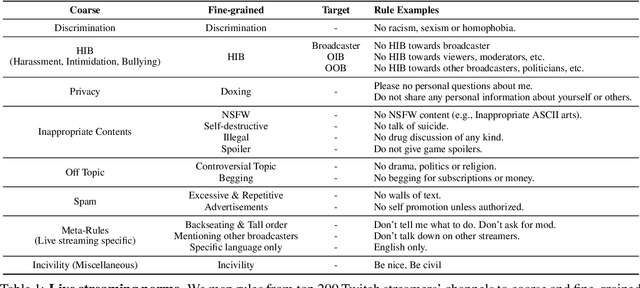
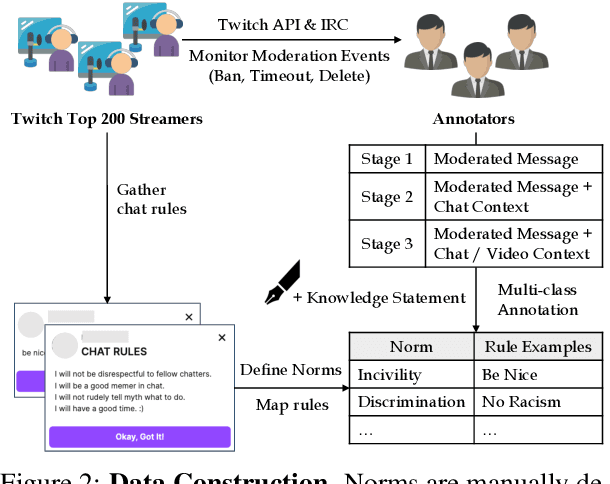

Toxic language, such as hate speech, can deter users from participating in online communities and enjoying popular platforms. Previous approaches to detecting toxic language and norm violations have been primarily concerned with conversations from online forums and social media, such as Reddit and Twitter. These approaches are less effective when applied to conversations on live-streaming platforms, such as Twitch and YouTube Live, as each comment is only visible for a limited time and lacks a thread structure that establishes its relationship with other comments. In this work, we share the first NLP study dedicated to detecting norm violations in conversations on live-streaming platforms. We define norm violation categories in live-stream chats and annotate 4,583 moderated comments from Twitch. We articulate several facets of live-stream data that differ from other forums, and demonstrate that existing models perform poorly in this setting. By conducting a user study, we identify the informational context humans use in live-stream moderation, and train models leveraging context to identify norm violations. Our results show that appropriate contextual information can boost moderation performance by 35\%.
Massively Parallel Reweighted Wake-Sleep
May 18, 2023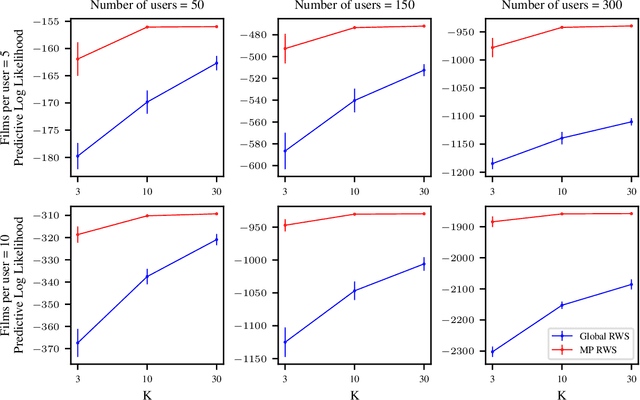
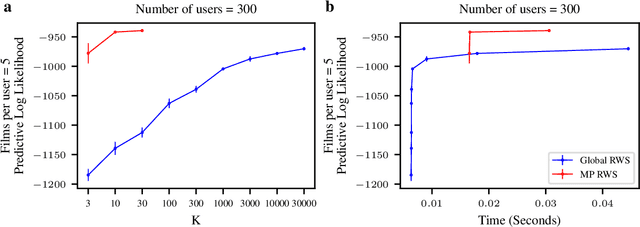
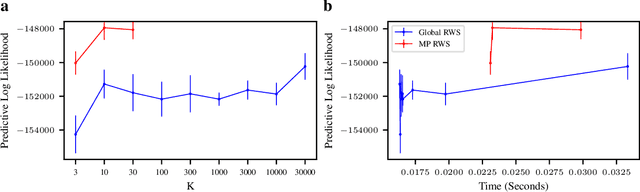
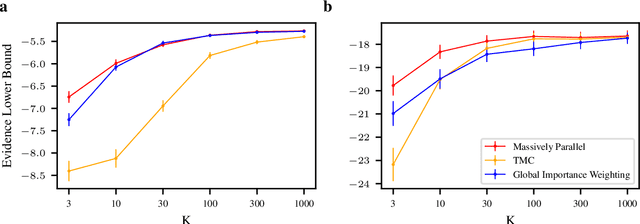
Reweighted wake-sleep (RWS) is a machine learning method for performing Bayesian inference in a very general class of models. RWS draws $K$ samples from an underlying approximate posterior, then uses importance weighting to provide a better estimate of the true posterior. RWS then updates its approximate posterior towards the importance-weighted estimate of the true posterior. However, recent work [Chattergee and Diaconis, 2018] indicates that the number of samples required for effective importance weighting is exponential in the number of latent variables. Attaining such a large number of importance samples is intractable in all but the smallest models. Here, we develop massively parallel RWS, which circumvents this issue by drawing $K$ samples of all $n$ latent variables, and individually reasoning about all $K^n$ possible combinations of samples. While reasoning about $K^n$ combinations might seem intractable, the required computations can be performed in polynomial time by exploiting conditional independencies in the generative model. We show considerable improvements over standard "global" RWS, which draws $K$ samples from the full joint.
TAPIR: Learning Adaptive Revision for Incremental Natural Language Understanding with a Two-Pass Model
May 18, 2023
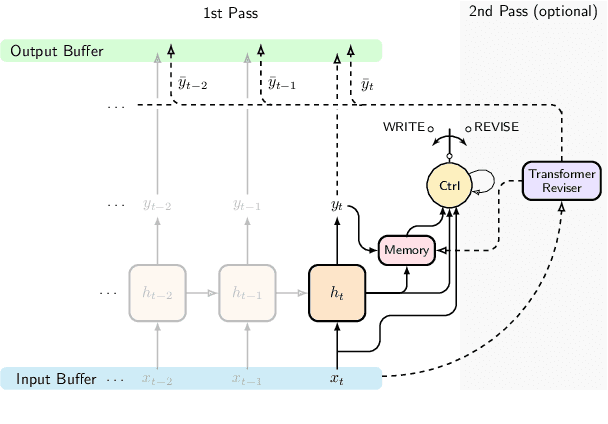
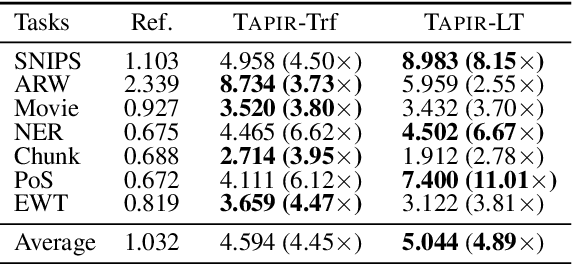
Language is by its very nature incremental in how it is produced and processed. This property can be exploited by NLP systems to produce fast responses, which has been shown to be beneficial for real-time interactive applications. Recent neural network-based approaches for incremental processing mainly use RNNs or Transformers. RNNs are fast but monotonic (cannot correct earlier output, which can be necessary in incremental processing). Transformers, on the other hand, consume whole sequences, and hence are by nature non-incremental. A restart-incremental interface that repeatedly passes longer input prefixes can be used to obtain partial outputs, while providing the ability to revise. However, this method becomes costly as the sentence grows longer. In this work, we propose the Two-pass model for AdaPtIve Revision (TAPIR) and introduce a method to obtain an incremental supervision signal for learning an adaptive revision policy. Experimental results on sequence labelling show that our model has better incremental performance and faster inference speed compared to restart-incremental Transformers, while showing little degradation on full sequences.
Validation of massively-parallel adaptive testing using dynamic control matching
May 02, 2023
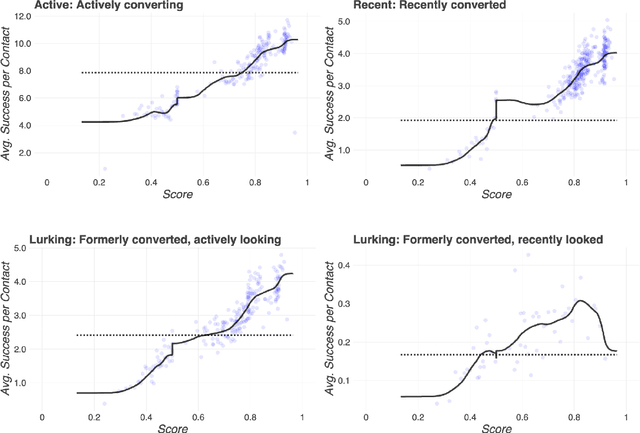
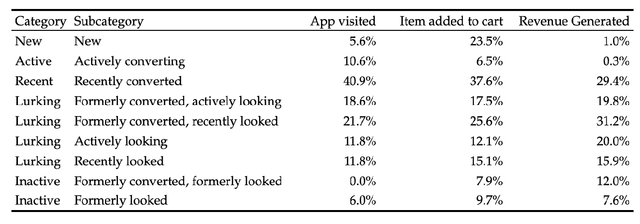
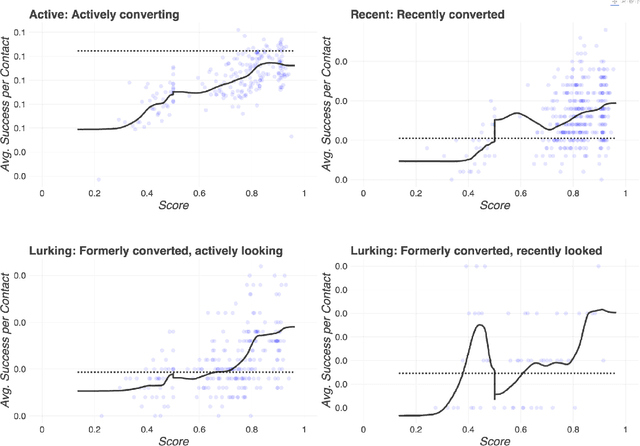
A/B testing is a widely-used paradigm within marketing optimization because it promises identification of causal effects and because it is implemented out of the box in most messaging delivery software platforms. Modern businesses, however, often run many A/B/n tests at the same time and in parallel, and package many content variations into the same messages, not all of which are part of an explicit test. Whether as the result of many teams testing at the same time, or as part of a more sophisticated reinforcement learning (RL) approach that continuously adapts tests and test condition assignment based on previous results, dynamic parallel testing cannot be evaluated the same way traditional A/B tests are evaluated. This paper presents a method for disentangling the causal effects of the various tests under conditions of continuous test adaptation, using a matched-synthetic control group that adapts alongside the tests.