 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Analyzing the Variations in Emergency Department Boarding and Testing the Transferability of Forecasting Models across COVID-19 Pandemic Waves in Hong Kong: Hybrid CNN-LSTM approach to quantifying building-level socioecological risk
Mar 17, 2024
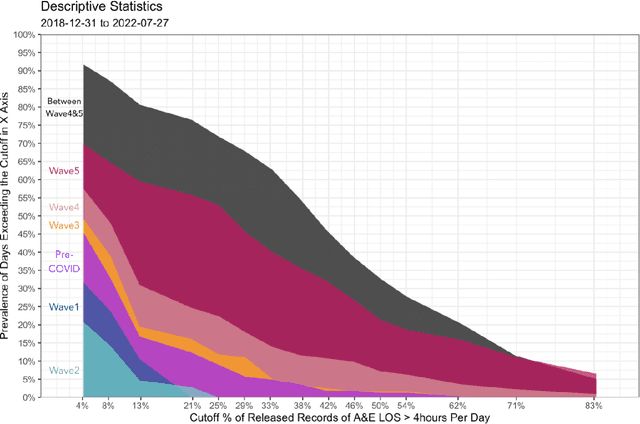
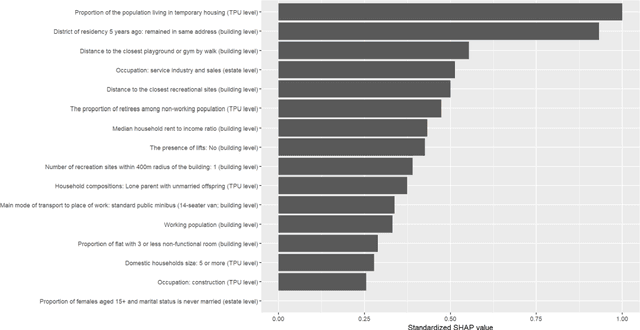
Emergency department's (ED) boarding (defined as ED waiting time greater than four hours) has been linked to poor patient outcomes and health system performance. Yet, effective forecasting models is rare before COVID-19, lacking during the peri-COVID era. Here, a hybrid convolutional neural network (CNN)-Long short-term memory (LSTM) model was applied to public-domain data sourced from Hong Kong's Hospital Authority, Department of Health, and Housing Authority. In addition, we sought to identify the phase of the COVID-19 pandemic that most significantly perturbed our complex adaptive healthcare system, thereby revealing a stable pattern of interconnectedness among its components, using deep transfer learning methodology. Our result shows that 1) the greatest proportion of days with ED boarding was found between waves four and five; 2) the best-performing model for forecasting ED boarding was observed between waves four and five, which was based on features representing time-invariant residential buildings' built environment and sociodemographic profiles and the historical time series of ED boarding and case counts, compared to during the waves when best-performing forecasting is based on time-series features alone; and 3) when the model built from the period between waves four and five was applied to data from other waves via deep transfer learning, the transferred model enhanced the performance of indigenous models.
Multiple-Input Auto-Encoder Guided Feature Selection for IoT Intrusion Detection Systems
Mar 22, 2024While intrusion detection systems (IDSs) benefit from the diversity and generalization of IoT data features, the data diversity (e.g., the heterogeneity and high dimensions of data) also makes it difficult to train effective machine learning models in IoT IDSs. This also leads to potentially redundant/noisy features that may decrease the accuracy of the detection engine in IDSs. This paper first introduces a novel neural network architecture called Multiple-Input Auto-Encoder (MIAE). MIAE consists of multiple sub-encoders that can process inputs from different sources with different characteristics. The MIAE model is trained in an unsupervised learning mode to transform the heterogeneous inputs into lower-dimensional representation, which helps classifiers distinguish between normal behaviour and different types of attacks. To distil and retain more relevant features but remove less important/redundant ones during the training process, we further design and embed a feature selection layer right after the representation layer of MIAE resulting in a new model called MIAEFS. This layer learns the importance of features in the representation vector, facilitating the selection of informative features from the representation vector. The results on three IDS datasets, i.e., NSLKDD, UNSW-NB15, and IDS2017, show the superior performance of MIAE and MIAEFS compared to other methods, e.g., conventional classifiers, dimensionality reduction models, unsupervised representation learning methods with different input dimensions, and unsupervised feature selection models. Moreover, MIAE and MIAEFS combined with the Random Forest (RF) classifier achieve accuracy of 96.5% in detecting sophisticated attacks, e.g., Slowloris. The average running time for detecting an attack sample using RF with the representation of MIAE and MIAEFS is approximate 1.7E-6 seconds, whilst the model size is lower than 1 MB.
Private graphon estimation via sum-of-squares
Mar 18, 2024We develop the first pure node-differentially-private algorithms for learning stochastic block models and for graphon estimation with polynomial running time for any constant number of blocks. The statistical utility guarantees match those of the previous best information-theoretic (exponential-time) node-private mechanisms for these problems. The algorithm is based on an exponential mechanism for a score function defined in terms of a sum-of-squares relaxation whose level depends on the number of blocks. The key ingredients of our results are (1) a characterization of the distance between the block graphons in terms of a quadratic optimization over the polytope of doubly stochastic matrices, (2) a general sum-of-squares convergence result for polynomial optimization over arbitrary polytopes, and (3) a general approach to perform Lipschitz extensions of score functions as part of the sum-of-squares algorithmic paradigm.
Generalized Multi-Source Inference for Text Conditioned Music Diffusion Models
Mar 18, 2024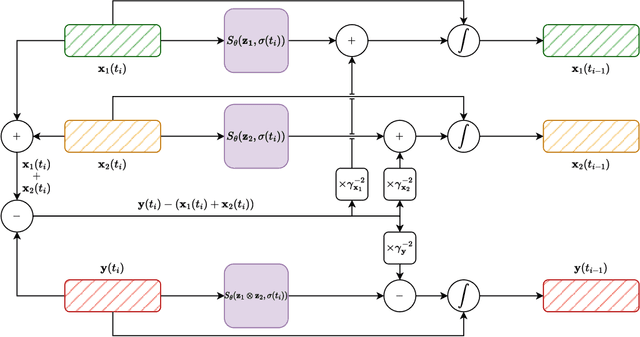
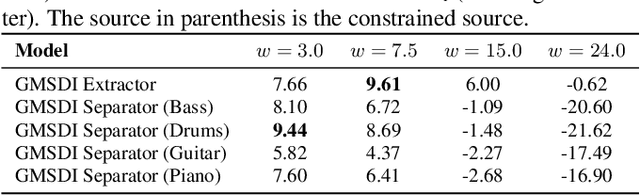
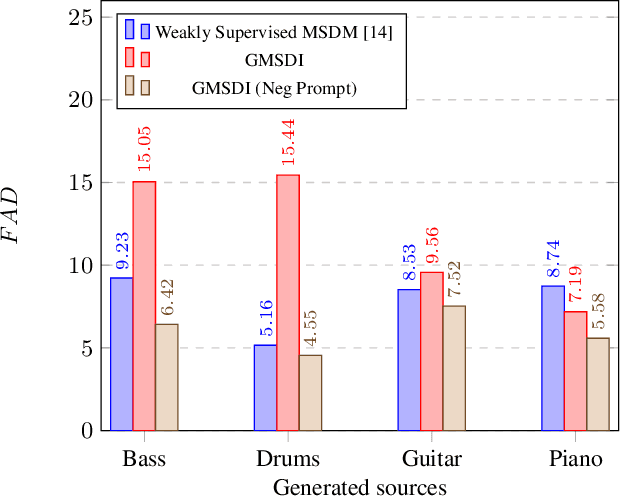
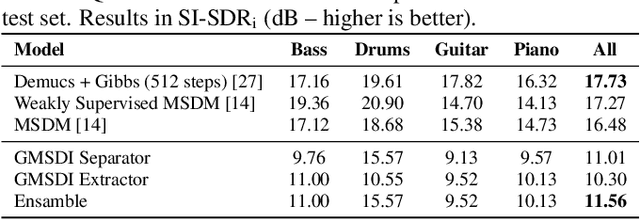
Multi-Source Diffusion Models (MSDM) allow for compositional musical generation tasks: generating a set of coherent sources, creating accompaniments, and performing source separation. Despite their versatility, they require estimating the joint distribution over the sources, necessitating pre-separated musical data, which is rarely available, and fixing the number and type of sources at training time. This paper generalizes MSDM to arbitrary time-domain diffusion models conditioned on text embeddings. These models do not require separated data as they are trained on mixtures, can parameterize an arbitrary number of sources, and allow for rich semantic control. We propose an inference procedure enabling the coherent generation of sources and accompaniments. Additionally, we adapt the Dirac separator of MSDM to perform source separation. We experiment with diffusion models trained on Slakh2100 and MTG-Jamendo, showcasing competitive generation and separation results in a relaxed data setting.
DD-VNB: A Depth-based Dual-Loop Framework for Real-time Visually Navigated Bronchoscopy
Mar 04, 2024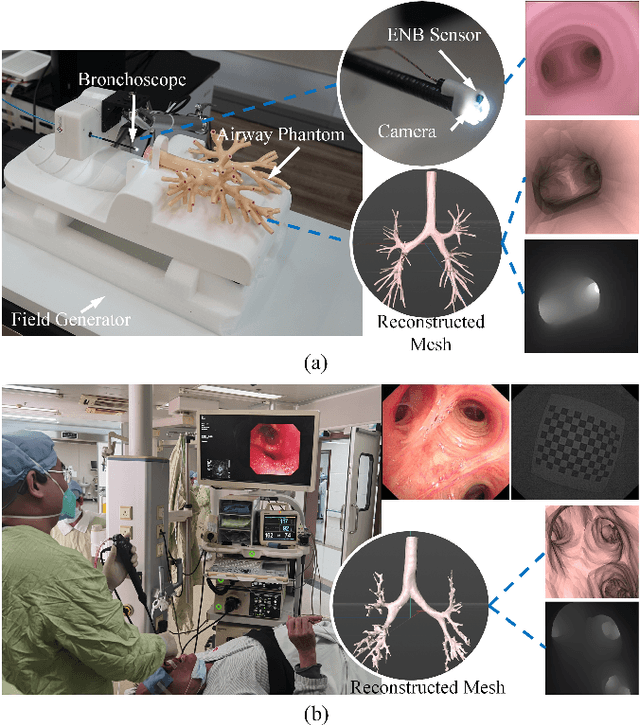
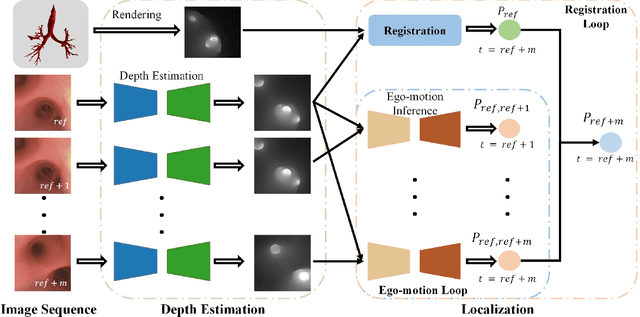
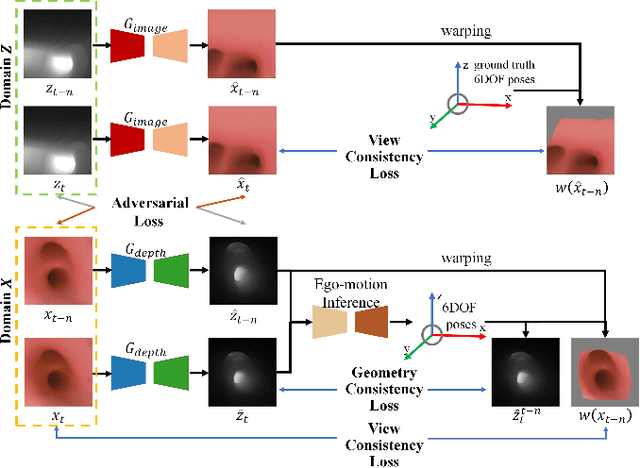
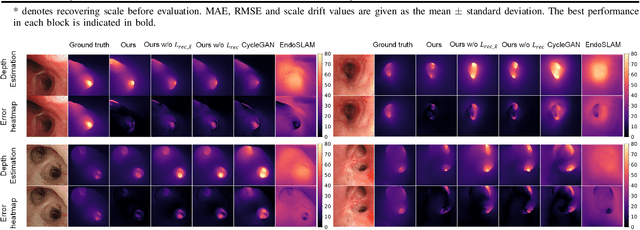
Real-time 6 DOF localization of bronchoscopes is crucial for enhancing intervention quality. However, current vision-based technologies struggle to balance between generalization to unseen data and computational speed. In this study, we propose a Depth-based Dual-Loop framework for real-time Visually Navigated Bronchoscopy (DD-VNB) that can generalize across patient cases without the need of re-training. The DD-VNB framework integrates two key modules: depth estimation and dual-loop localization. To address the domain gap among patients, we propose a knowledge-embedded depth estimation network that maps endoscope frames to depth, ensuring generalization by eliminating patient-specific textures. The network embeds view synthesis knowledge into a cycle adversarial architecture for scale-constrained monocular depth estimation. For real-time performance, our localization module embeds a fast ego-motion estimation network into the loop of depth registration. The ego-motion inference network estimates the pose change of the bronchoscope in high frequency while depth registration against the pre-operative 3D model provides absolute pose periodically. Specifically, the relative pose changes are fed into the registration process as the initial guess to boost its accuracy and speed. Experiments on phantom and in-vivo data from patients demonstrate the effectiveness of our framework: 1) monocular depth estimation outperforms SOTA, 2) localization achieves an accuracy of Absolute Tracking Error (ATE) of 4.7 $\pm$ 3.17 mm in phantom and 6.49 $\pm$ 3.88 mm in patient data, 3) with a frame-rate approaching video capture speed, 4) without the necessity of case-wise network retraining. The framework's superior speed and accuracy demonstrate its promising clinical potential for real-time bronchoscopic navigation.
Zero-Shot Multi-Object Shape Completion
Mar 21, 2024
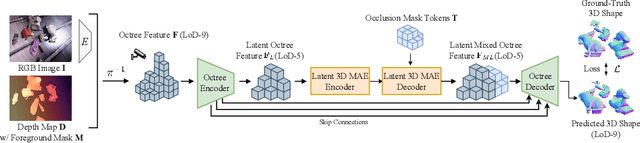
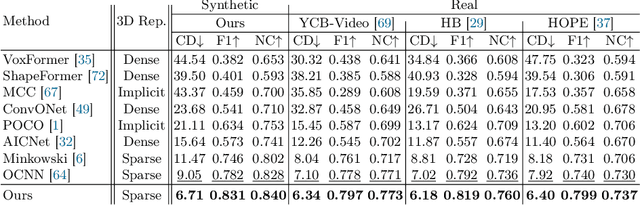

We present a 3D shape completion method that recovers the complete geometry of multiple objects in complex scenes from a single RGB-D image. Despite notable advancements in single object 3D shape completion, high-quality reconstructions in highly cluttered real-world multi-object scenes remains a challenge. To address this issue, we propose OctMAE, an architecture that leverages an Octree U-Net and a latent 3D MAE to achieve high-quality and near real-time multi-object shape completion through both local and global geometric reasoning. Because a na\"ive 3D MAE can be computationally intractable and memory intensive even in the latent space, we introduce a novel occlusion masking strategy and adopt 3D rotary embeddings, which significantly improves the runtime and shape completion quality. To generalize to a wide range of objects in diverse scenes, we create a large-scale photorealistic dataset, featuring a diverse set of 12K 3D object models from the Objaverse dataset which are rendered in multi-object scenes with physics-based positioning. Our method outperforms the current state-of-the-art on both synthetic and real-world datasets and demonstrates a strong zero-shot capability.
Early Flood Warning Using Satellite-Derived Convective System and Precipitation Data -- A Retrospective Case Study of Central Vietnam
Mar 21, 2024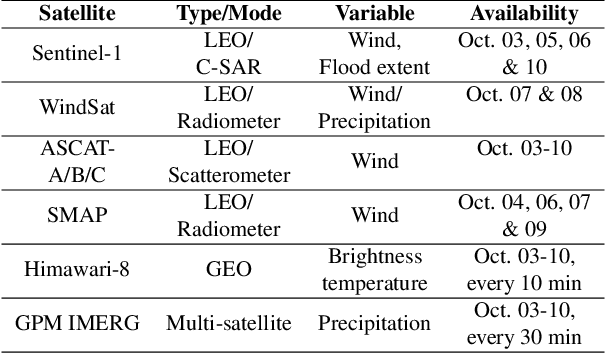
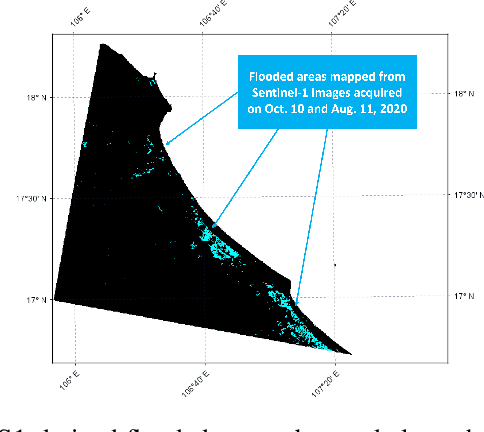
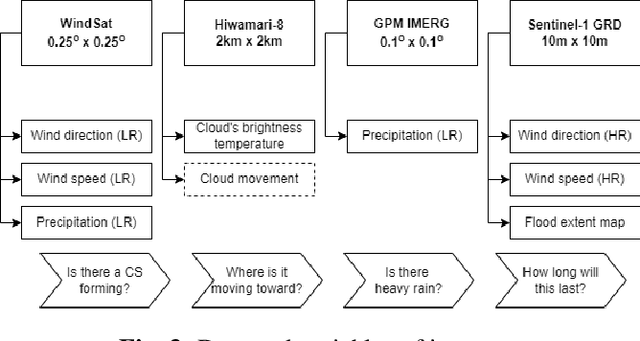
This paper addresses the challenges of an early flood warning caused by complex convective systems (CSs), by using Low-Earth Orbit and Geostationary satellite data. We focus on a sequence of extreme events that took place in central Vietnam during October 2020, with a specific emphasis on the events leading up to the floods, i.e., those occurring before October 10th, 2020. In this critical phase, several hydrometeorological indicators could be identified thanks to an increasingly advanced and dense observation network composed of Earth Observation satellites, in particular those enabling the characterization and monitoring of a CS, in terms of low-temperature clouds and heavy rainfall. Himawari-8 images, both individually and in time-series, allow identifying and tracking convective clouds. This is complemented by the observation of heavy/violent rainfall through GPM IMERG data, as well as the detection of strong winds using radiometers and scatterometers. Collectively, these datasets, along with the estimated intensity and duration of the event from each source, form a comprehensive dataset detailing the intricate behaviors of CSs. All of these factors are significant contributors to the magnitude of flooding and the short-term dynamics anticipated in the studied region.
WikiFactDiff: A Large, Realistic, and Temporally Adaptable Dataset for Atomic Factual Knowledge Update in Causal Language Models
Mar 21, 2024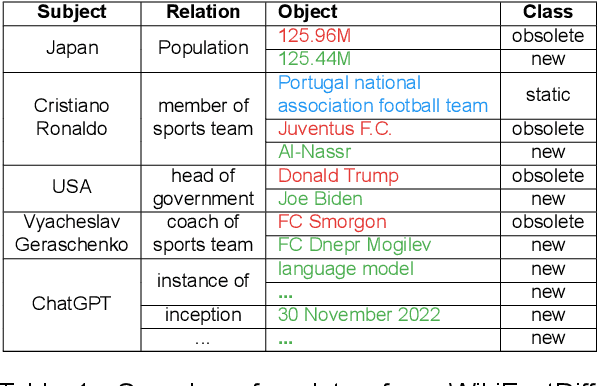
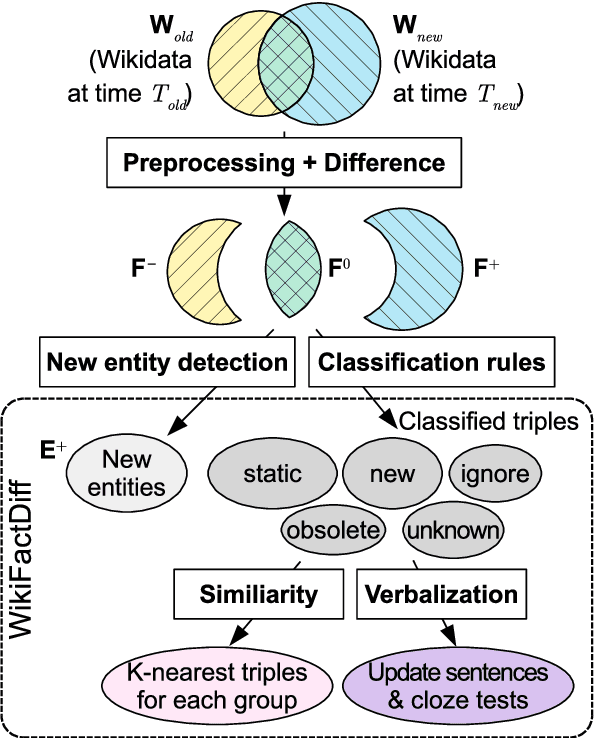
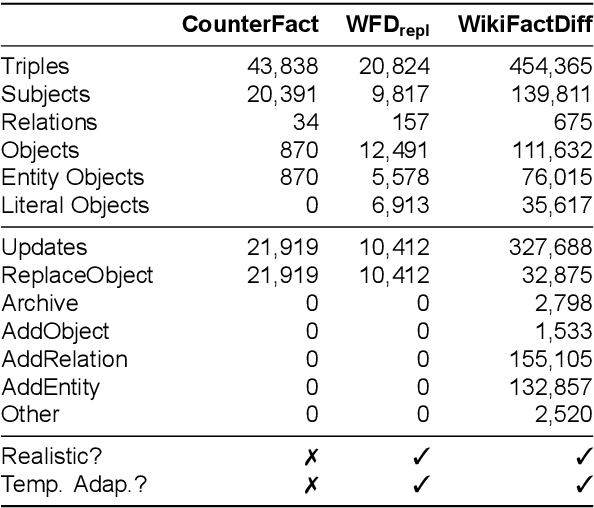
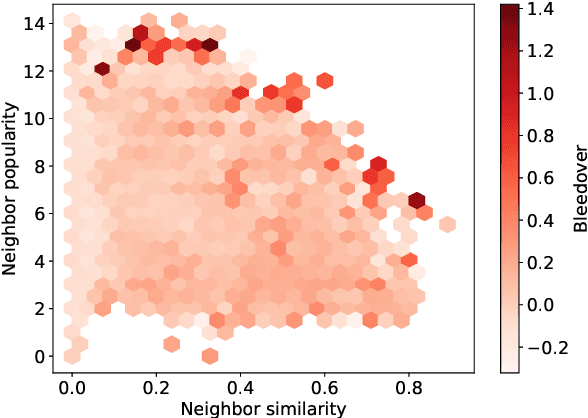
The factuality of large language model (LLMs) tends to decay over time since events posterior to their training are "unknown" to them. One way to keep models up-to-date could be factual update: the task of inserting, replacing, or removing certain simple (atomic) facts within the model. To study this task, we present WikiFactDiff, a dataset that describes the evolution of factual knowledge between two dates as a collection of simple facts divided into three categories: new, obsolete, and static. We describe several update scenarios arising from various combinations of these three types of basic update. The facts are represented by subject-relation-object triples; indeed, WikiFactDiff was constructed by comparing the state of the Wikidata knowledge base at 4 January 2021 and 27 February 2023. Those fact are accompanied by verbalization templates and cloze tests that enable running update algorithms and their evaluation metrics. Contrary to other datasets, such as zsRE and CounterFact, WikiFactDiff constitutes a realistic update setting that involves various update scenarios, including replacements, archival, and new entity insertions. We also present an evaluation of existing update algorithms on WikiFactDiff.
Efficient Model Learning and Adaptive Tracking Control of Magnetic Micro-Robots for Non-Contact Manipulation
Mar 21, 2024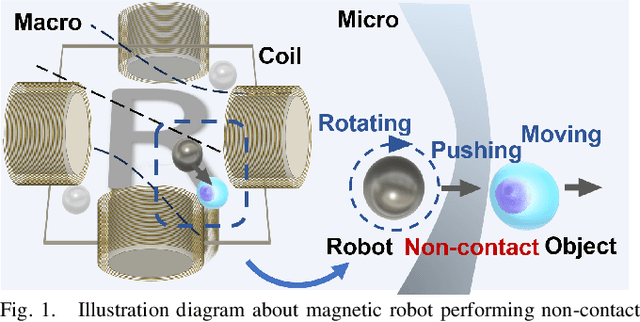
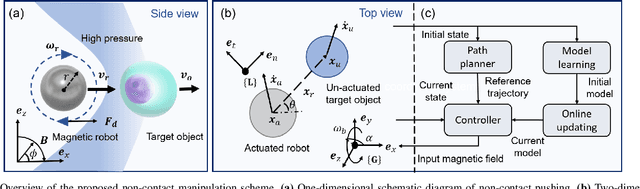
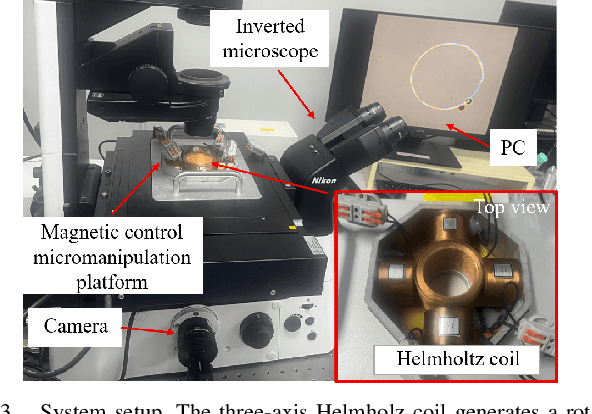
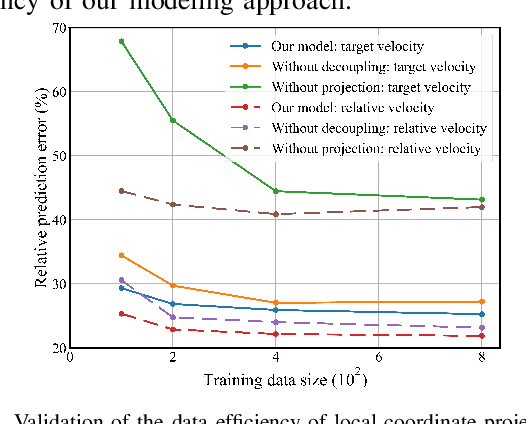
Magnetic microrobots can be navigated by an external magnetic field to autonomously move within living organisms with complex and unstructured environments. Potential applications include drug delivery, diagnostics, and therapeutic interventions. Existing techniques commonly impart magnetic properties to the target object,or drive the robot to contact and then manipulate the object, both probably inducing physical damage. This paper considers a non-contact formulation, where the robot spins to generate a repulsive field to push the object without physical contact. Under such a formulation, the main challenge is that the motion model between the input of the magnetic field and the output velocity of the target object is commonly unknown and difficult to analyze. To deal with it, this paper proposes a data-driven-based solution. A neural network is constructed to efficiently estimate the motion model. Then, an approximate model-based optimal control scheme is developed to push the object to track a time-varying trajectory, maintaining the non-contact with distance constraints. Furthermore, a straightforward planner is introduced to assess the adaptability of non-contact manipulation in a cluttered unstructured environment. Experimental results are presented to show the tracking and navigation performance of the proposed scheme.
Training point-based deep learning networks for forest segmentation with synthetic data
Mar 21, 2024
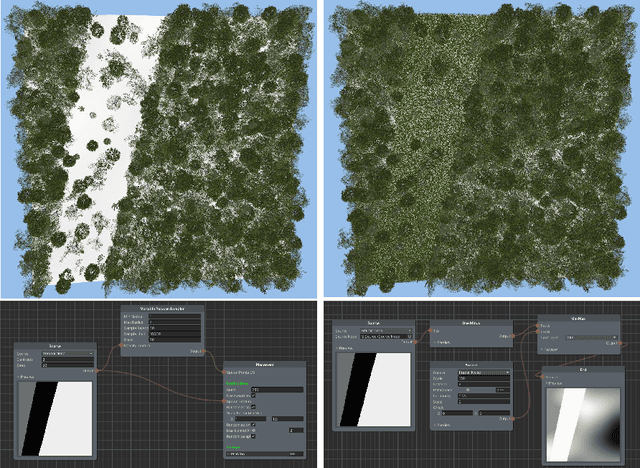


Remote sensing through unmanned aerial systems (UAS) has been increasing in forestry in recent years, along with using machine learning for data processing. Deep learning architectures, extensively applied in natural language and image processing, have recently been extended to the point cloud domain. However, the availability of point cloud datasets for training and testing remains limited. Creating forested environment point cloud datasets is expensive, requires high-precision sensors, and is time-consuming as manual point classification is required. Moreover, forest areas could be inaccessible or dangerous for humans, further complicating data collection. Then, a question arises whether it is possible to use synthetic data to train deep learning networks without the need to rely on large volumes of real forest data. To answer this question, we developed a realistic simulator that procedurally generates synthetic forest scenes. Thanks to this, we have conducted a comparative study of different state-of-the-art point-based deep learning networks for forest segmentation. Using created datasets, we determined the feasibility of using synthetic data to train deep learning networks to classify point clouds from real forest datasets. Both the simulator and the datasets are released as part of this work.