 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Iterative Forward Tuning Boosts In-context Learning in Language Models
May 22, 2023
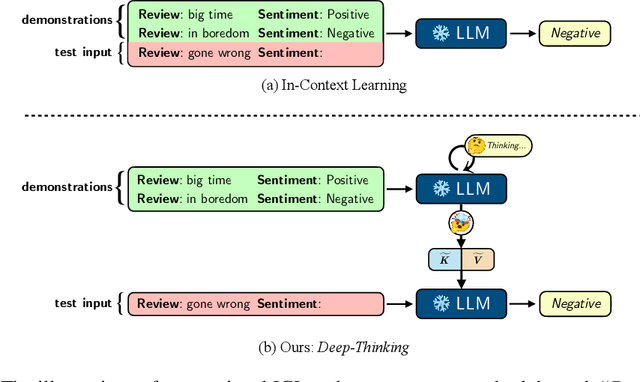
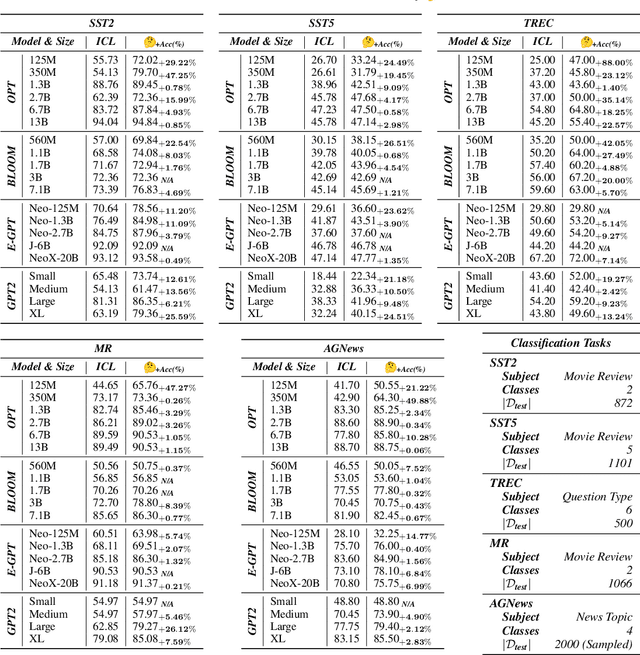
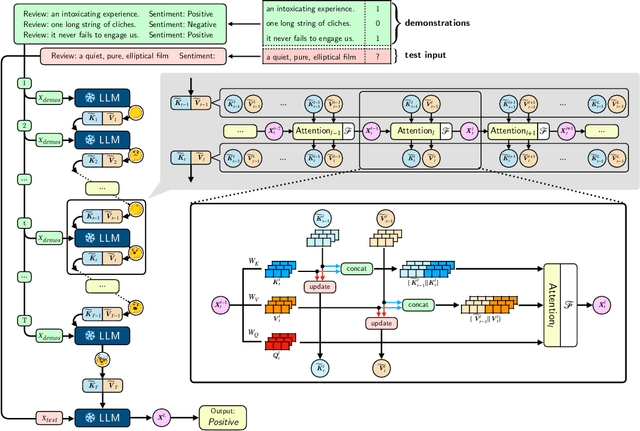
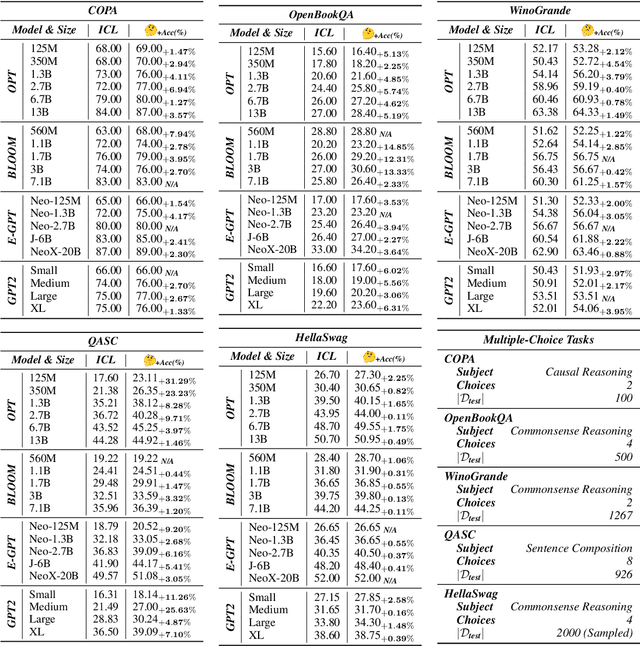
Large language models (LLMs) have exhibited an emergent in-context learning (ICL) ability. However, the ICL models that can solve ordinary cases are hardly extended to solve more complex tasks by processing the demonstration examples once. This single-turn ICL is incoordinate with the decision making process of humans by learning from analogy. In this paper, we propose an effective and efficient two-stage framework to boost ICL in LLMs by exploiting a dual form between Transformer attention and gradient descent-based optimization. Concretely, we divide the ICL process into "Deep-Thinking" and inference stages. The "Deep-Thinking" stage performs iterative forward optimization of demonstrations, which is expected to boost the reasoning abilities of LLMs at test time by "thinking" demonstrations multiple times. It produces accumulated meta-gradients by manipulating the Key-Value matrices in the self-attention modules of the Transformer. Then, the inference stage only takes the test query as input without concatenating demonstrations and applies the learned meta-gradients through attention for output prediction. In this way, demonstrations are not required during the inference stage since they are already learned and stored in the definitive meta-gradients. LLMs can be effectively and efficiently adapted to downstream tasks. Extensive experiments on ten classification and multiple-choice datasets show that our method achieves substantially better performance than standard ICL in terms of both accuracy and efficiency.
Hierarchical Partitioning Forecaster
May 22, 2023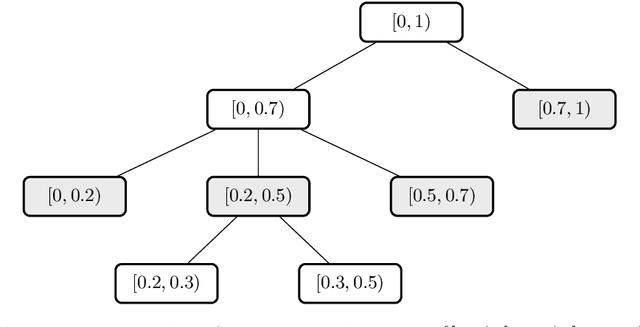
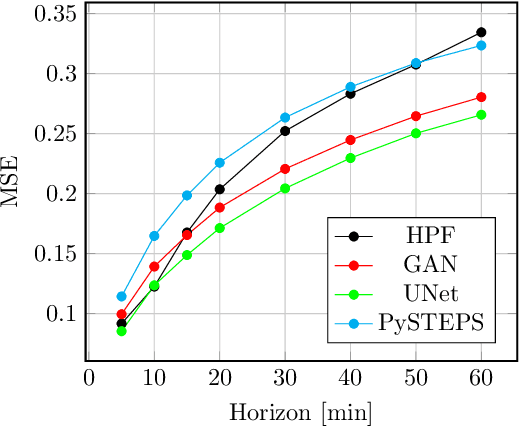
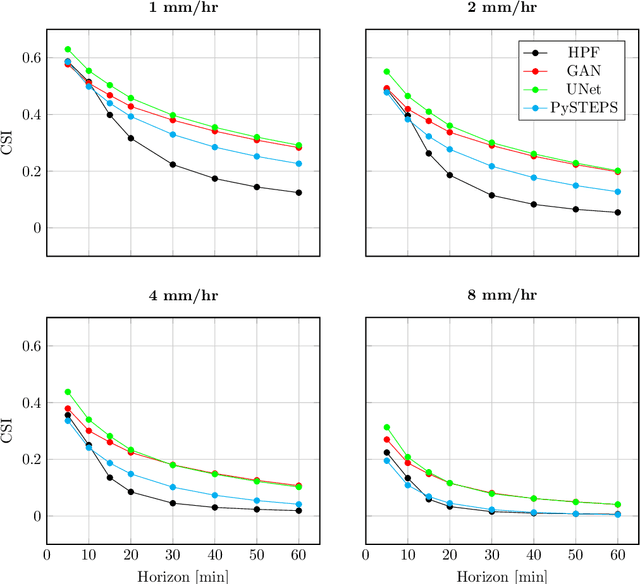
In this work we consider a new family of algorithms for sequential prediction, Hierarchical Partitioning Forecasters (HPFs). Our goal is to provide appealing theoretical - regret guarantees on a powerful model class - and practical - empirical performance comparable to deep networks - properties at the same time. We built upon three principles: hierarchically partitioning the feature space into sub-spaces, blending forecasters specialized to each sub-space and learning HPFs via local online learning applied to these individual forecasters. Following these principles allows us to obtain regret guarantees, where Constant Partitioning Forecasters (CPFs) serve as competitor. A CPF partitions the feature space into sub-spaces and predicts with a fixed forecaster per sub-space. Fixing a hierarchical partition $\mathcal H$ and considering any CPF with a partition that can be constructed using elements of $\mathcal H$ we provide two guarantees: first, a generic one that unveils how local online learning determines regret of learning the entire HPF online; second, a concrete instance that considers HPF with linear forecasters (LHPF) and exp-concave losses where we obtain $O(k \log T)$ regret for sequences of length $T$ where $k$ is a measure of complexity for the competing CPF. Finally, we provide experiments that compare LHPF to various baselines, including state of the art deep learning models, in precipitation nowcasting. Our results indicate that LHPF is competitive in various settings.
Keeping Up with the Language Models: Robustness-Bias Interplay in NLI Data and Models
May 22, 2023



Auditing unwanted social bias in language models (LMs) is inherently hard due to the multidisciplinary nature of the work. In addition, the rapid evolution of LMs can make benchmarks irrelevant in no time. Bias auditing is further complicated by LM brittleness: when a presumably biased outcome is observed, is it due to model bias or model brittleness? We propose enlisting the models themselves to help construct bias auditing datasets that remain challenging, and introduce bias measures that distinguish between types of model errors. First, we extend an existing bias benchmark for NLI (BBNLI) using a combination of LM-generated lexical variations, adversarial filtering, and human validation. We demonstrate that the newly created dataset (BBNLInext) is more challenging than BBNLI: on average, BBNLI-next reduces the accuracy of state-of-the-art NLI models from 95.3%, as observed by BBNLI, to 58.6%. Second, we employ BBNLI-next to showcase the interplay between robustness and bias, and the subtlety in differentiating between the two. Third, we point out shortcomings in current bias scores used in the literature and propose bias measures that take into account pro-/anti-stereotype bias and model brittleness. We will publicly release the BBNLI-next dataset to inspire research on rapidly expanding benchmarks to keep up with model evolution, along with research on the robustness-bias interplay in bias auditing. Note: This paper contains offensive text examples.
Distilling ChatGPT for Explainable Automated Student Answer Assessment
May 22, 2023

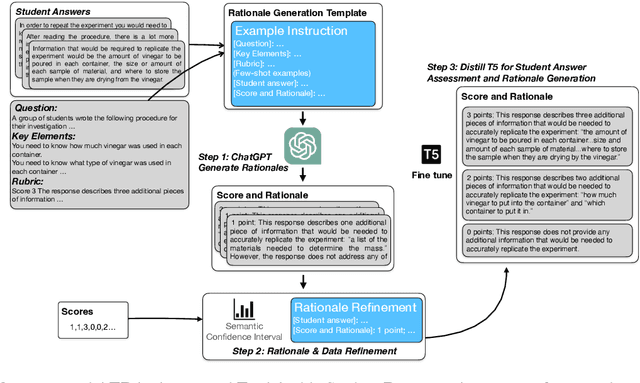
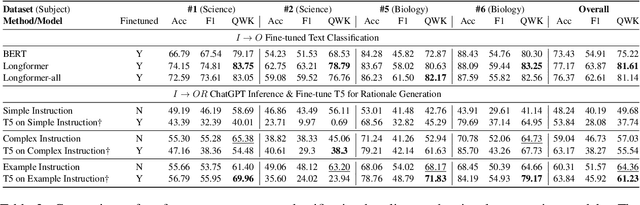
Assessing student answers and providing valuable feedback is crucial for effective learning, but it can be a time-consuming task. Traditional methods of automating student answer assessment through text classification often suffer from issues such as lack of trustworthiness, transparency, and the ability to provide a rationale for the automated assessment process. These limitations hinder their usefulness in practice. In this paper, we explore using ChatGPT, a cutting-edge large language model, for the concurrent tasks of student answer scoring and rationale generation under both the zero-shot and few-shot settings. We introduce a critic module which automatically filters incorrect outputs from ChatGPT and utilizes the remaining ChtaGPT outputs as noisy labelled data to fine-tune a smaller language model, enabling it to perform student answer scoring and rationale generation. Moreover, by drawing multiple samples from ChatGPT outputs, we are able to compute predictive confidence scores, which in turn can be used to identify corrupted data and human label errors in the training set. Our experimental results demonstrate that despite being a few orders of magnitude smaller than ChatGPT, the fine-tuned language model achieves better performance in student answer scoring. Furthermore, it generates more detailed and comprehensible assessments than traditional text classification methods. Our approach provides a viable solution to achieve explainable automated assessment in education.
Bandit Submodular Maximization for Multi-Robot Coordination in Unpredictable and Partially Observable Environments
May 22, 2023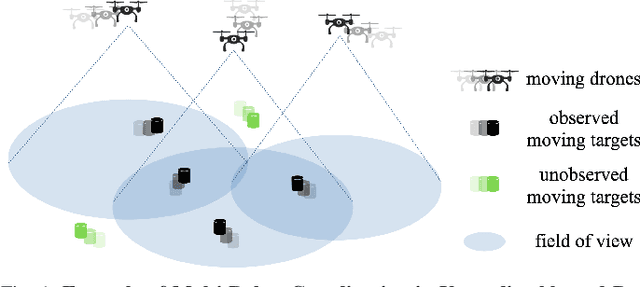
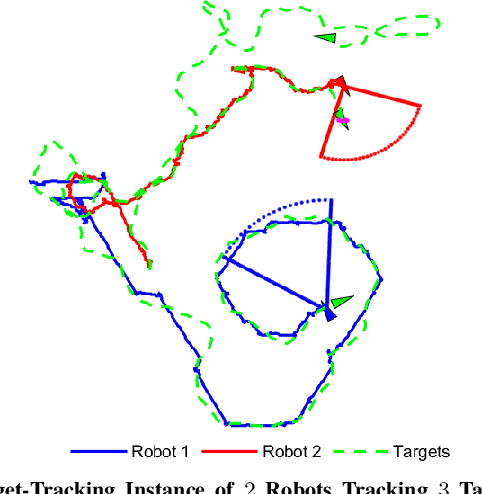
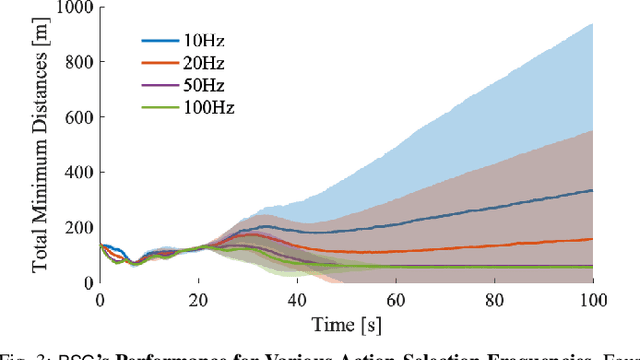
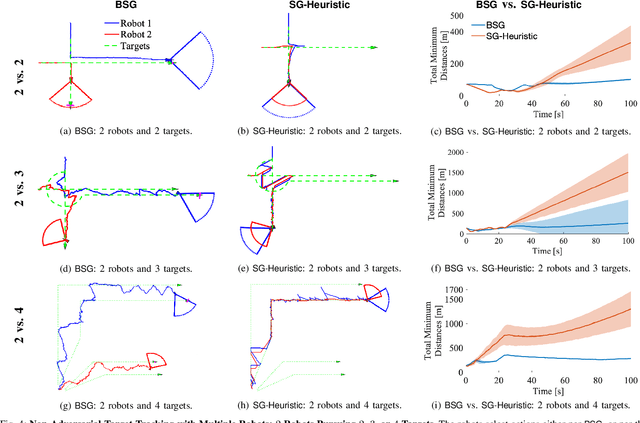
We study the problem of multi-agent coordination in unpredictable and partially observable environments, that is, environments whose future evolution is unknown a priori and that can only be partially observed. We are motivated by the future of autonomy that involves multiple robots coordinating actions in dynamic, unstructured, and partially observable environments to complete complex tasks such as target tracking, environmental mapping, and area monitoring. Such tasks are often modeled as submodular maximization coordination problems due to the information overlap among the robots. We introduce the first submodular coordination algorithm with bandit feedback and bounded tracking regret -- bandit feedback is the robots' ability to compute in hindsight only the effect of their chosen actions, instead of all the alternative actions that they could have chosen instead, due to the partial observability; and tracking regret is the algorithm's suboptimality with respect to the optimal time-varying actions that fully know the future a priori. The bound gracefully degrades with the environments' capacity to change adversarially, quantifying how often the robots should re-select actions to learn to coordinate as if they fully knew the future a priori. The algorithm generalizes the seminal Sequential Greedy algorithm by Fisher et al. to the bandit setting, by leveraging submodularity and algorithms for the problem of tracking the best action. We validate our algorithm in simulated scenarios of multi-target tracking.
ForestTrav: Accurate, Efficient and Deployable Forest Traversability Estimation for Autonomous Ground Vehicles
May 22, 2023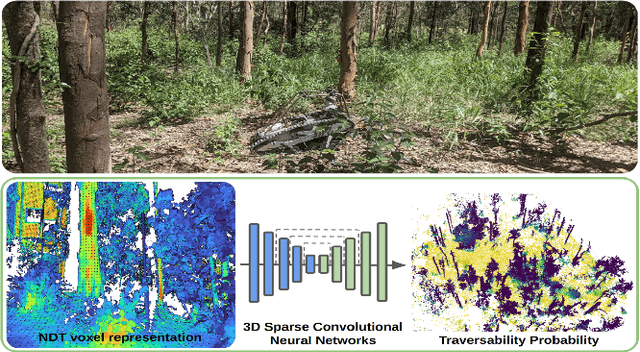
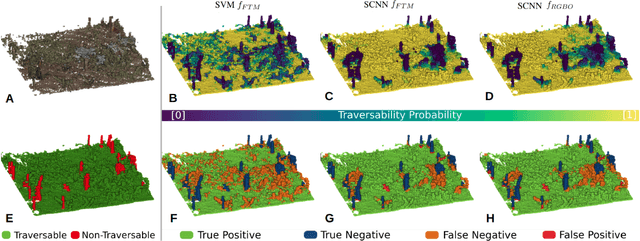
Autonomous navigation in unstructured vegetated environments remains an open challenge. To successfully operate in these settings, ground vehicles must assess the traversability of the environment and determine which vegetation is pliable enough to push through. In this work, we propose a novel method that combines a high-fidelity and feature-rich 3D voxel representation while leveraging the structural context and sparseness of \acfp{SCNN} to assess \ac{TE} in densely vegetated environments. The proposed method is thoroughly evaluated on an accurately-labeled real-world data set that we provide to the community. It is shown to outperform state-of-the-art methods by a significant margin (0.59 vs. 0.39 MCC score at 0.1m voxel resolution) in challenging scenes and to generalize to unseen environments. In addition, the method is economical in the amount of training data and training time required: a model is trained in minutes on a desktop computer. We show that by exploiting the context of the environment, our method can use different feature combinations with only limited performance variations. For example, our approach can be used with lidar-only features, whilst still assessing complex vegetated environments accurately, which was not demonstrated previously in the literature in such environments. In addition, we propose an approach to assess a traversability estimator's sensitivity to information quality and show our method's sensitivity is low.
A Lightweight CNN-Transformer Model for Learning Traveling Salesman Problems
May 03, 2023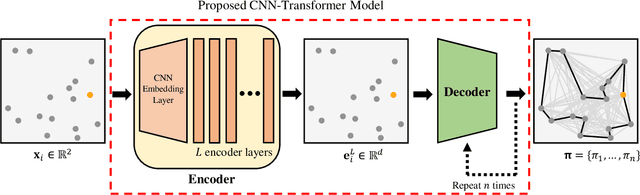

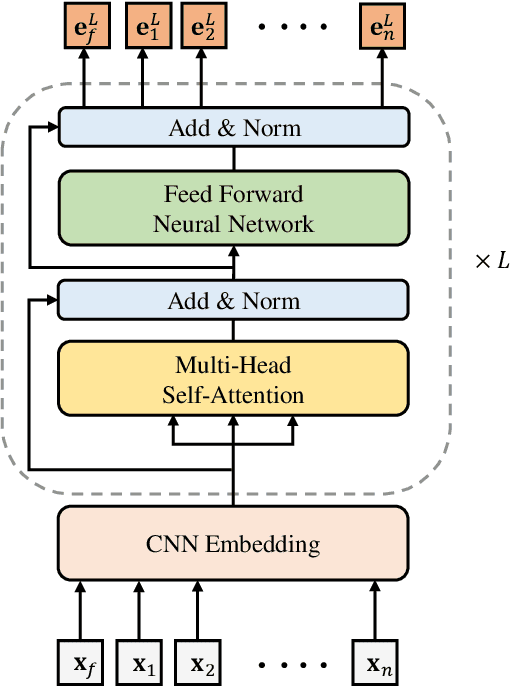
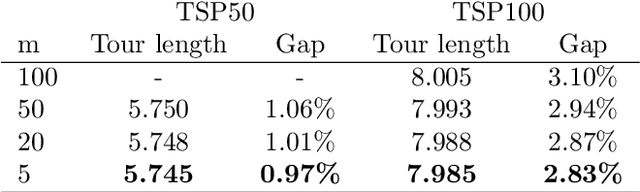
Transformer-based models show state-of-the-art performance even for large-scale Traveling Salesman Problems (TSPs). However, they are based on fully-connected attention models and suffer from large computational complexity and GPU memory usage. We propose a lightweight CNN-Transformer model based on a CNN embedding layer and partial self-attention. Our CNN-Transformer model is able to better learn spatial features from input data using a CNN embedding layer compared with the standard Transformer models. It also removes considerable redundancy in fully connected attention models using the proposed partial self-attention. Experiments show that the proposed model outperforms other state-of-the-art Transformer-based models in terms of TSP solution quality, GPU memory usage, and inference time. Our model consumes approximately 20% less GPU memory usage and has 45% faster inference time compared with other state-of-the-art Transformer-based models. Our code is publicly available at https://github.com/cm8908/CNN_Transformer3
A Time Series Approach to Parkinson's Disease Classification from EEG
Jan 20, 2023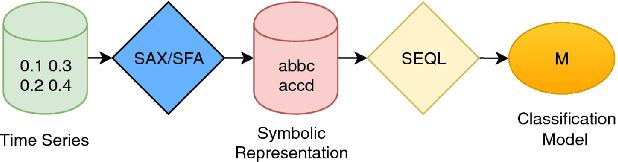
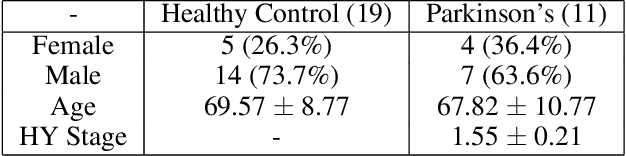
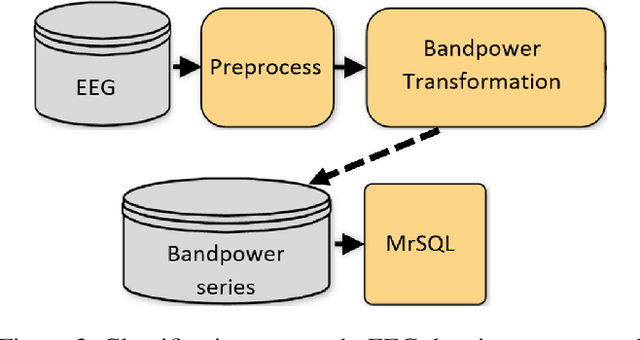
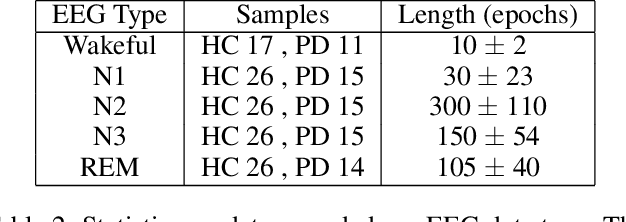
Firstly, we present a novel representation for EEG data, a 7-variate series of band power coefficients, which enables the use of (previously inaccessible) time series classification methods. Specifically, we implement the multi-resolution representation-based time series classification method MrSQL. This is deployed on a challenging early-stage Parkinson's dataset that includes wakeful and sleep EEG. Initial results are promising with over 90% accuracy achieved on all EEG data types used. Secondly, we present a framework that enables high-importance data types and brain regions for classification to be identified. Using our framework, we find that, across different EEG data types, it is the Prefrontal brain region that has the most predictive power for the presence of Parkinson's Disease. This outperformance was statistically significant versus ten of the twelve other brain regions (not significant versus adjacent Left Frontal and Right Frontal regions). The Prefrontal region of the brain is important for higher-order cognitive processes and our results align with studies that have shown neural dysfunction in the prefrontal cortex in Parkinson's Disease.
Efficient pattern-based anomaly detection in a network of multivariate devices
May 07, 2023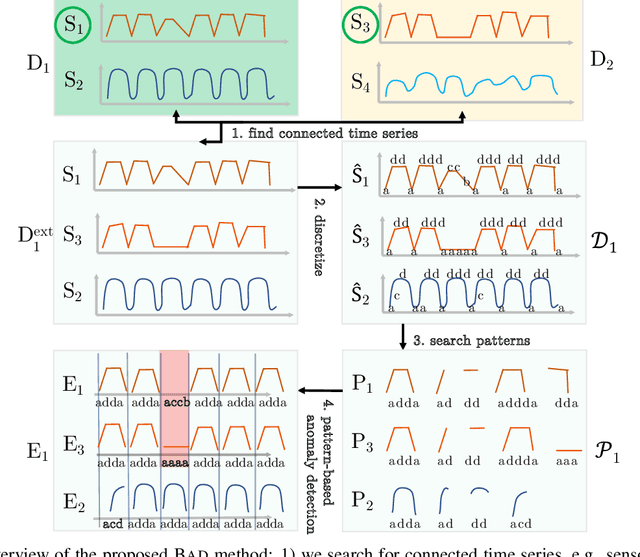
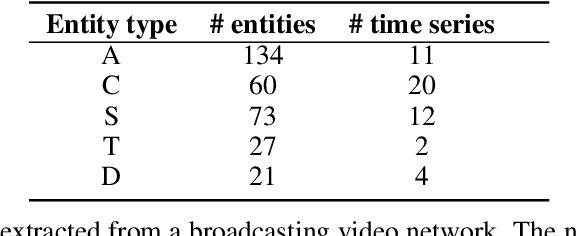
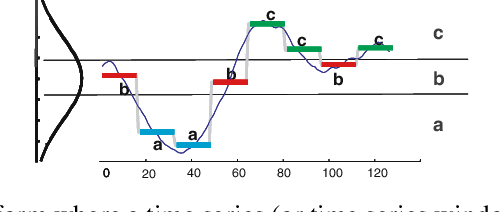

Many organisations manage service quality and monitor a large set devices and servers where each entity is associated with telemetry or physical sensor data series. Recently, various methods have been proposed to detect behavioural anomalies, however existing approaches focus on multivariate time series and ignore communication between entities. Moreover, we aim to support end-users in not only in locating entities and sensors causing an anomaly at a certain period, but also explain this decision. We propose a scalable approach to detect anomalies using a two-step approach. First, we recover relations between entities in the network, since relations are often dynamic in nature and caused by an unknown underlying process. Next, we report anomalies based on an embedding of sequential patterns. Pattern mining is efficient and supports interpretation, i.e. patterns represent frequent occurring behaviour in time series. We extend pattern mining to filter sequential patterns based on frequency, temporal constraints and minimum description length. We collect and release two public datasets for international broadcasting and X from an Internet company. \textit{BAD} achieves an overall F1-Score of 0.78 on 9 benchmark datasets, significantly outperforming the best baseline by 3\%. Additionally, \textit{BAD} is also an order-of-magnitude faster than state-of-the-art anomaly detection methods.
Simultaneous identification of models and parameters of scientific simulators
May 24, 2023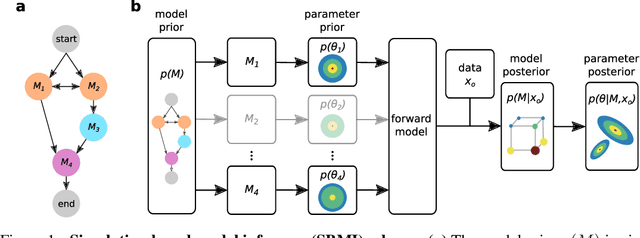

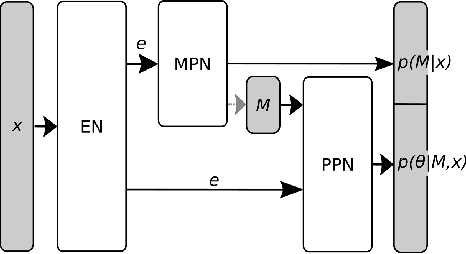
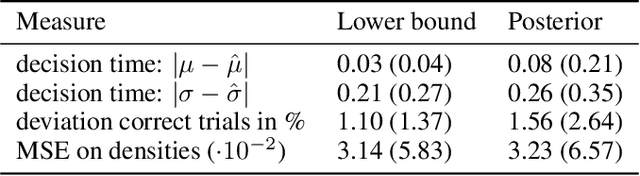
Many scientific models are composed of multiple discrete components, and scien tists often make heuristic decisions about which components to include. Bayesian inference provides a mathematical framework for systematically selecting model components, but defining prior distributions over model components and developing associated inference schemes has been challenging. We approach this problem in an amortized simulation-based inference framework: We define implicit model priors over a fixed set of candidate components and train neural networks to infer joint probability distributions over both, model components and associated parameters from simulations. To represent distributions over model components, we introduce a conditional mixture of multivariate binary distributions in the Grassmann formalism. Our approach can be applied to any compositional stochastic simulator without requiring access to likelihood evaluations. We first illustrate our method on a simple time series model with redundant components and show that it can retrieve joint posterior distribution over a set of symbolic expressions and their parameters while accurately capturing redundancy with strongly correlated posteriors. We then apply our approach to drift-diffusion models, a commonly used model class in cognitive neuroscience. After validating the method on synthetic data, we show that our approach explains experimental data as well as previous methods, but that our fully probabilistic approach can help to discover multiple data-consistent model configurations, as well as reveal non-identifiable model components and parameters. Our method provides a powerful tool for data-driven scientific inquiry which will allow scientists to systematically identify essential model components and make uncertainty-informed modelling decisions.