 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Unsupervised Melody-Guided Lyrics Generation
May 12, 2023
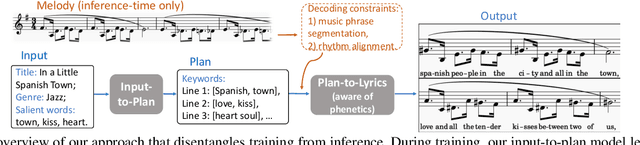

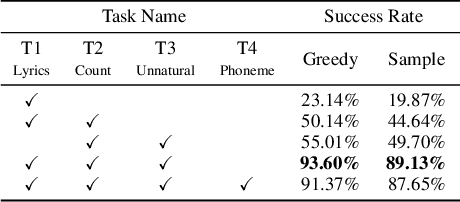
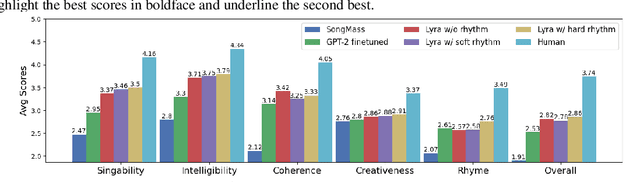
Automatic song writing is a topic of significant practical interest. However, its research is largely hindered by the lack of training data due to copyright concerns and challenged by its creative nature. Most noticeably, prior works often fall short of modeling the cross-modal correlation between melody and lyrics due to limited parallel data, hence generating lyrics that are less singable. Existing works also lack effective mechanisms for content control, a much desired feature for democratizing song creation for people with limited music background. In this work, we propose to generate pleasantly listenable lyrics without training on melody-lyric aligned data. Instead, we design a hierarchical lyric generation framework that disentangles training (based purely on text) from inference (melody-guided text generation). At inference time, we leverage the crucial alignments between melody and lyrics and compile the given melody into constraints to guide the generation process. Evaluation results show that our model can generate high-quality lyrics that are more singable, intelligible, coherent, and in rhyme than strong baselines including those supervised on parallel data.
Joint MR sequence optimization beats pure neural network approaches for spin-echo MRI super-resolution
May 12, 2023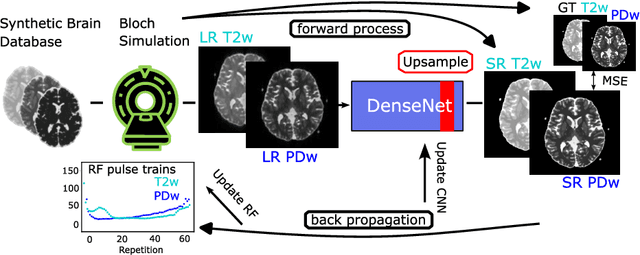
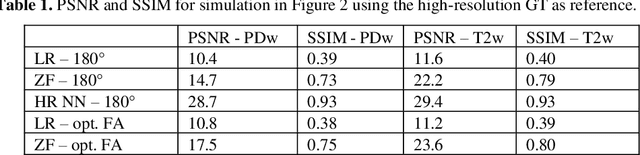
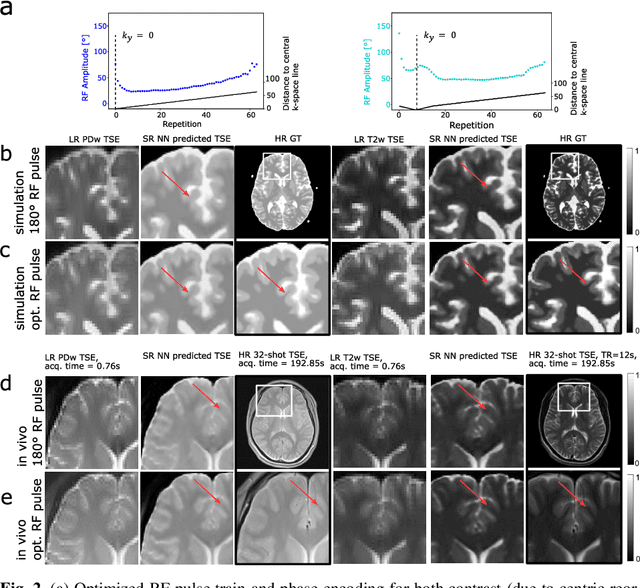
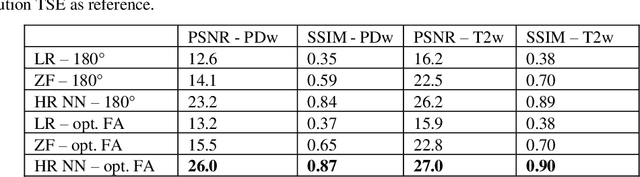
Current MRI super-resolution (SR) methods only use existing contrasts acquired from typical clinical sequences as input for the neural network (NN). In turbo spin echo sequences (TSE) the sequence parameters can have a strong influence on the actual resolution of the acquired image and have consequently a considera-ble impact on the performance of the NN. We propose a known-operator learning approach to perform an end-to-end optimization of MR sequence and neural net-work parameters for SR-TSE. This MR-physics-informed training procedure jointly optimizes the radiofrequency pulse train of a proton density- (PD-) and T2-weighted TSE and a subsequently applied convolutional neural network to predict the corresponding PDw and T2w super-resolution TSE images. The found radiofrequency pulse train designs generate an optimal signal for the NN to perform the SR task. Our method generalizes from the simulation-based optimi-zation to in vivo measurements and the acquired physics-informed SR images show higher correlation with a time-consuming segmented high-resolution TSE sequence compared to a pure network training approach.
Causal Structural Learning from Time Series: A Convex Optimization Approach
Jan 26, 2023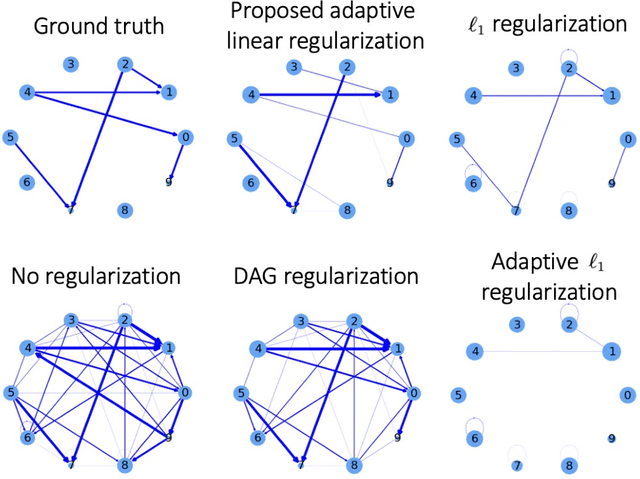
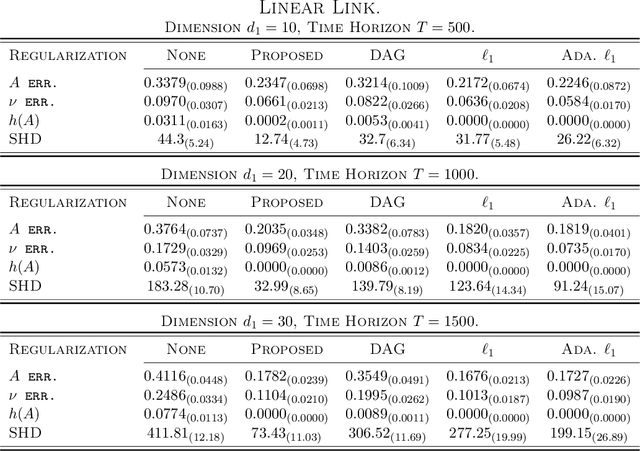
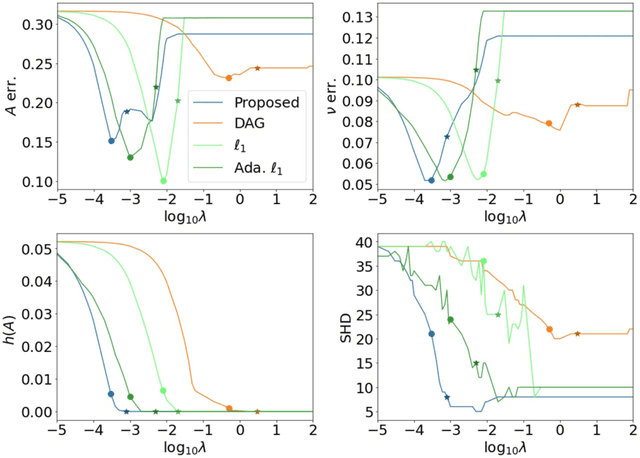
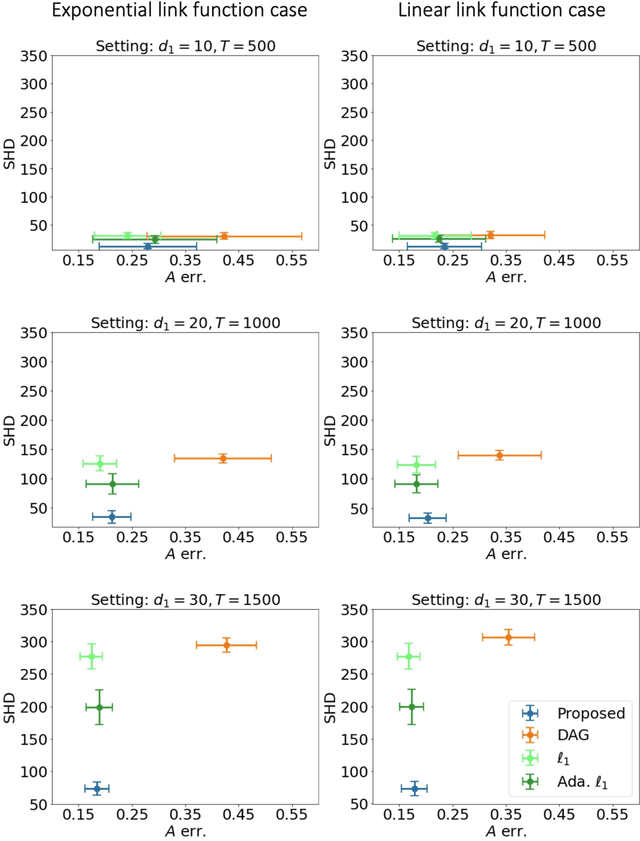
Structural learning, which aims to learn directed acyclic graphs (DAGs) from observational data, is foundational to causal reasoning and scientific discovery. Recent advancements formulate structural learning into a continuous optimization problem; however, DAG learning remains a highly non-convex problem, and there has not been much work on leveraging well-developed convex optimization techniques for causal structural learning. We fill this gap by proposing a data-adaptive linear approach for causal structural learning from time series data, which can be conveniently cast into a convex optimization problem using a recently developed monotone operator variational inequality (VI) formulation. Furthermore, we establish non-asymptotic recovery guarantee of the VI-based approach and show the superior performance of our proposed method on structure recovery over existing methods via extensive numerical experiments.
Scalable Optimal Margin Distribution Machine
May 08, 2023
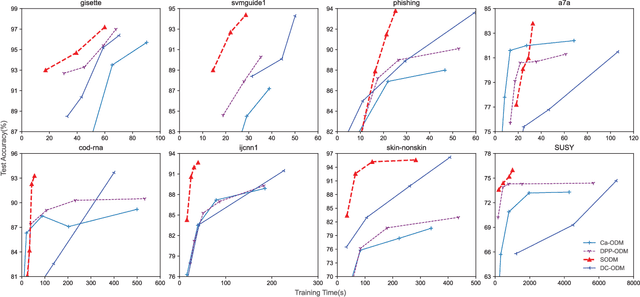
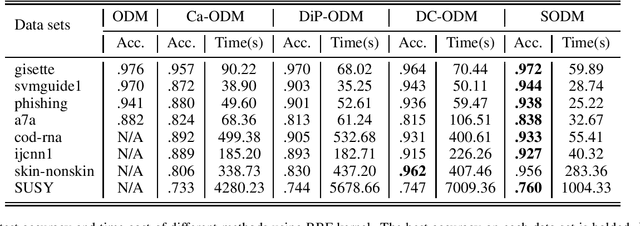
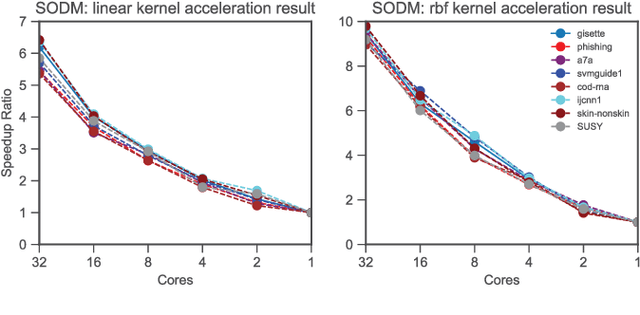
Optimal margin Distribution Machine (ODM) is a newly proposed statistical learning framework rooting in the novel margin theory, which demonstrates better generalization performance than the traditional large margin based counterparts. Nonetheless, it suffers from the ubiquitous scalability problem regarding both computation time and memory as other kernel methods. This paper proposes a scalable ODM, which can achieve nearly ten times speedup compared to the original ODM training method. For nonlinear kernels, we propose a novel distribution-aware partition method to make the local ODM trained on each partition be close and converge fast to the global one. When linear kernel is applied, we extend a communication efficient SVRG method to accelerate the training further. Extensive empirical studies validate that our proposed method is highly computational efficient and almost never worsen the generalization.
WWFedCBMIR: World-Wide Federated Content-Based Medical Image Retrieval
May 05, 2023
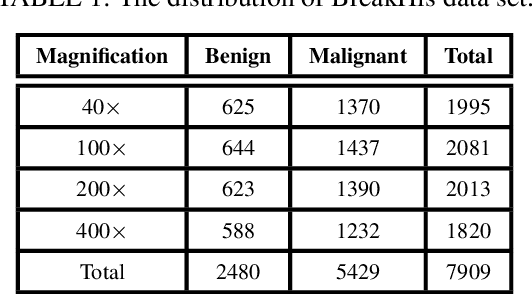
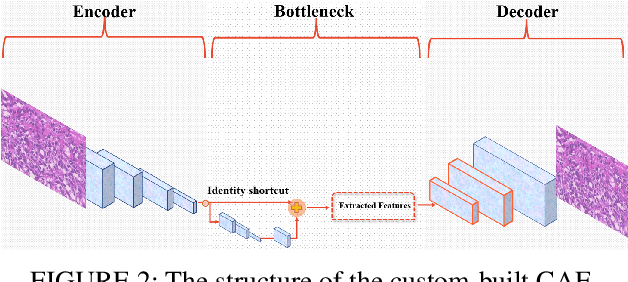

The paper proposes a Federated Content-Based Medical Image Retrieval (FedCBMIR) platform that utilizes Federated Learning (FL) to address the challenges of acquiring a diverse medical data set for training CBMIR models. CBMIR assists pathologists in diagnosing breast cancer more rapidly by identifying similar medical images and relevant patches in prior cases compared to traditional cancer detection methods. However, CBMIR in histopathology necessitates a pool of Whole Slide Images (WSIs) to train to extract an optimal embedding vector that leverages search engine performance, which may not be available in all centers. The strict regulations surrounding data sharing in medical data sets also hinder research and model development, making it difficult to collect a rich data set. The proposed FedCBMIR distributes the model to collaborative centers for training without sharing the data set, resulting in shorter training times than local training. FedCBMIR was evaluated in two experiments with three scenarios on BreaKHis and Camelyon17 (CAM17). The study shows that the FedCBMIR method increases the F1-Score (F1S) of each client to 98%, 96%, 94%, and 97% in the BreaKHis experiment with a generalized model of four magnifications and does so in 6.30 hours less time than total local training. FedCBMIR also achieves 98% accuracy with CAM17 in 2.49 hours less training time than local training, demonstrating that our FedCBMIR is both fast and accurate for both pathologists and engineers. In addition, our FedCBMIR provides similar images with higher magnification for non-developed countries where participate in the worldwide FedCBMIR with developed countries to facilitate mitosis measuring in breast cancer diagnosis. We evaluate this scenario by scattering BreaKHis into four centers with different magnifications.
Exogenous Data in Forecasting: FARM -- A New Measure for Relevance Evaluation
Apr 24, 2023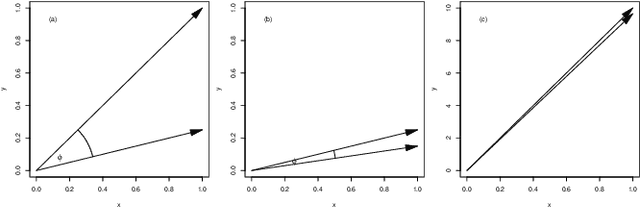
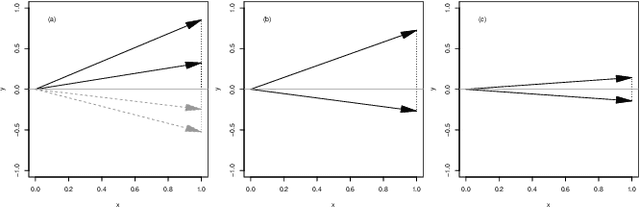
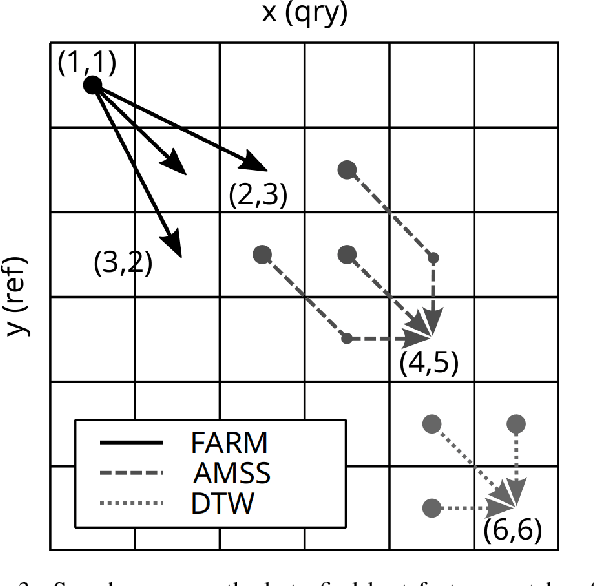
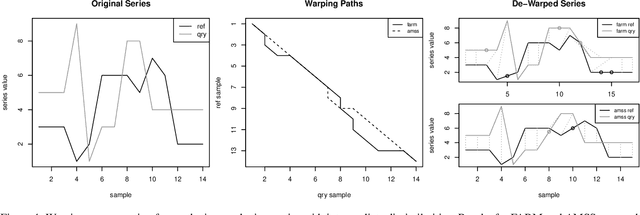
Evaluating the relevance of an exogenous data series is the first step in improving the prediction capabilities of a forecast algorithm. Inspired by existing metrics for time series similarity, we introduce a new approach named FARM - Forward Aligned Relevance Metric. Our forward method relies on an angular measure that compares changes in subsequent data points to align time-warped series in an efficient way. The proposed algorithm combines local and global measures to provide a balanced relevance metric. This results in considering also partial, intermediate matches as relevant indicators for exogenous data series significance. As a first validation step, we present the application of our FARM approach to synthetic but representative signals. While demonstrating the improved capabilities with respect to existing approaches, we also discuss existing constraints and limitations of our idea.
QuickVC: Many-to-any Voice Conversion Using Inverse Short-time Fourier Transform for Faster Conversion
Feb 17, 2023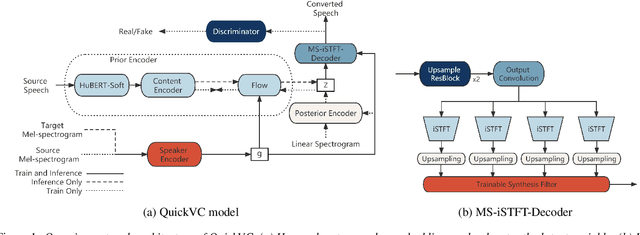
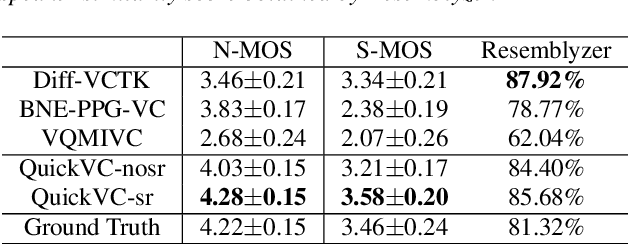

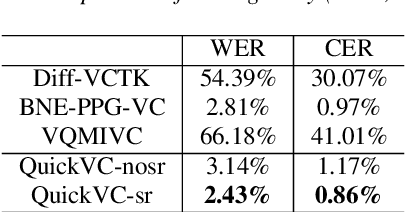
With the development of automatic speech recognition (ASR) and text-to-speech (TTS) technology, high-quality voice conversion (VC) can be achieved by extracting source content information and target speaker information to reconstruct waveforms. However, current methods still require improvement in terms of inference speed. In this study, we propose a lightweight VITS-based VC model that uses the HuBERT-Soft model to extract content information features without speaker information. Through subjective and objective experiments on synthesized speech, the proposed model demonstrates competitive results in terms of naturalness and similarity. Importantly, unlike the original VITS model, we use the inverse short-time Fourier transform (iSTFT) to replace the most computationally expensive part. Experimental results show that our model can generate samples at over 5000 kHz on the 3090 GPU and over 250 kHz on the i9-10900K CPU, achieving competitive speed for the same hardware configuration.
Explaining dark matter halo density profiles with neural networks
May 04, 2023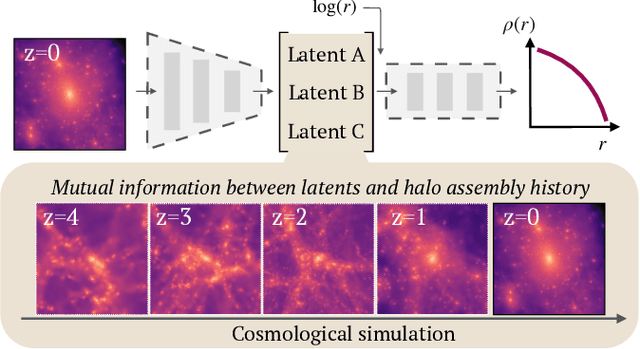
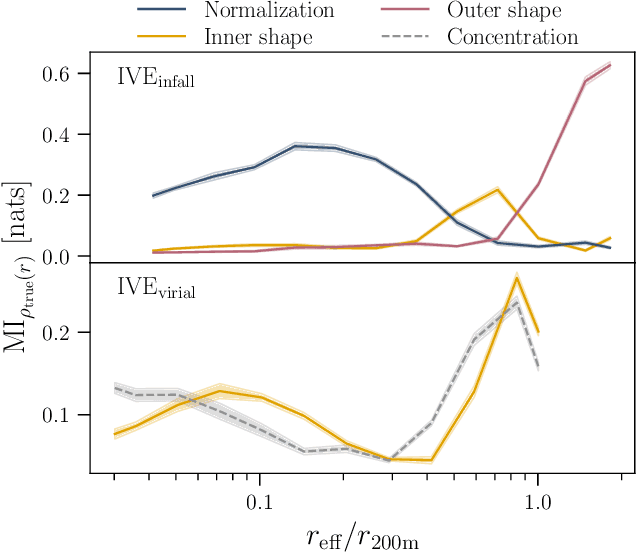
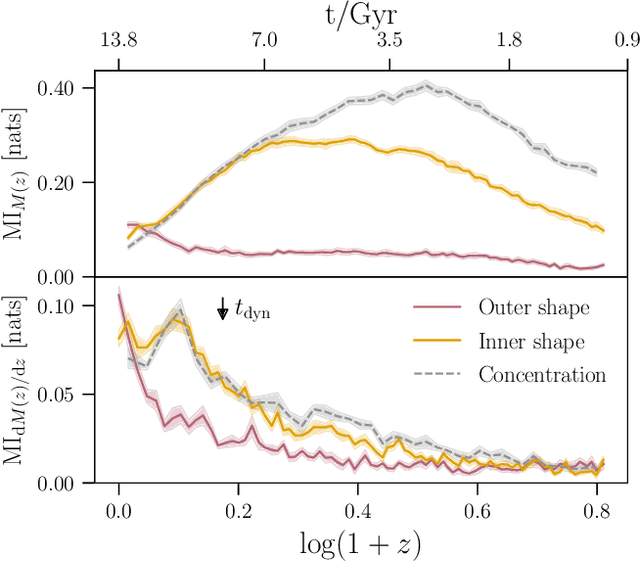
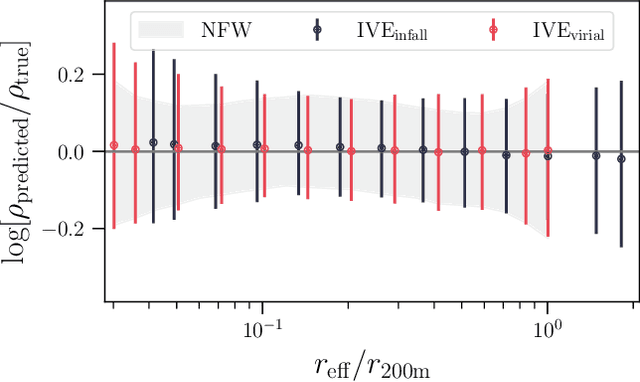
We use explainable neural networks to connect the evolutionary history of dark matter halos with their density profiles. The network captures independent factors of variation in the density profiles within a low-dimensional representation, which we physically interpret using mutual information. Without any prior knowledge of the halos' evolution, the network recovers the known relation between the early time assembly and the inner profile, and discovers that the profile beyond the virial radius is described by a single parameter capturing the most recent mass accretion rate. The results illustrate the potential for machine-assisted scientific discovery in complicated astrophysical datasets.
Towards Unified All-Neural Beamforming for Time and Frequency Domain Speech Separation
Dec 24, 2022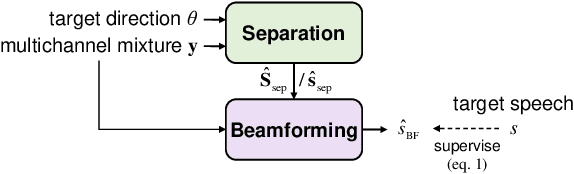
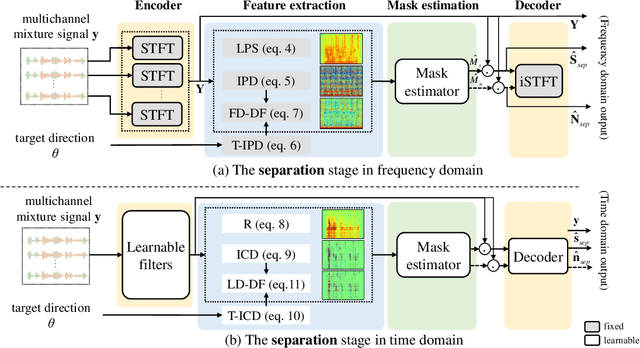
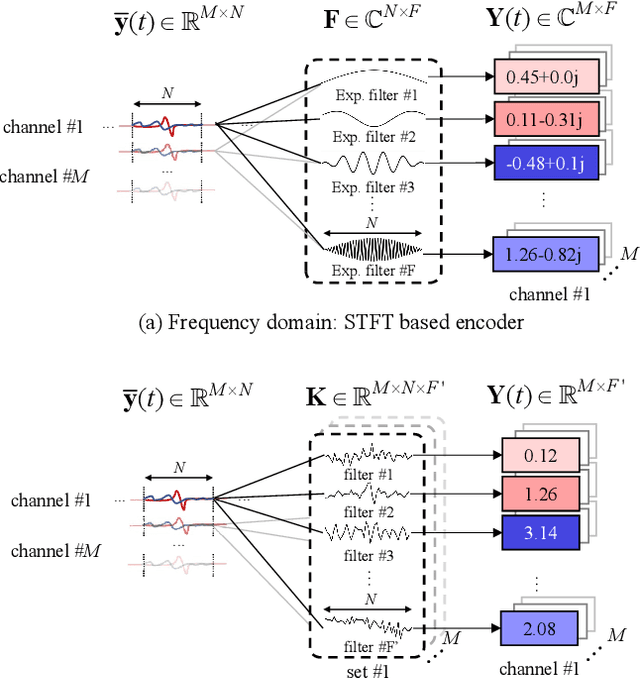
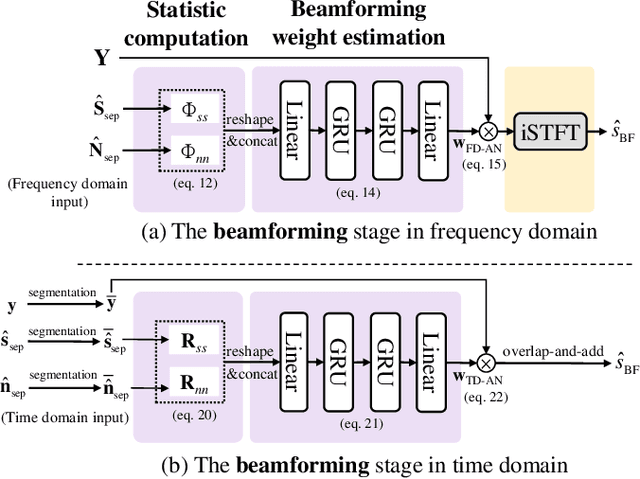
Recently, frequency domain all-neural beamforming methods have achieved remarkable progress for multichannel speech separation. In parallel, the integration of time domain network structure and beamforming also gains significant attention. This study proposes a novel all-neural beamforming method in time domain and makes an attempt to unify the all-neural beamforming pipelines for time domain and frequency domain multichannel speech separation. The proposed model consists of two modules: separation and beamforming. Both modules perform temporal-spectral-spatial modeling and are trained from end-to-end using a joint loss function. The novelty of this study lies in two folds. Firstly, a time domain directional feature conditioned on the direction of the target speaker is proposed, which can be jointly optimized within the time domain architecture to enhance target signal estimation. Secondly, an all-neural beamforming network in time domain is designed to refine the pre-separated results. This module features with parametric time-variant beamforming coefficient estimation, without explicitly following the derivation of optimal filters that may lead to an upper bound. The proposed method is evaluated on simulated reverberant overlapped speech data derived from the AISHELL-1 corpus. Experimental results demonstrate significant performance improvements over frequency domain state-of-the-arts, ideal magnitude masks and existing time domain neural beamforming methods.
Integrating Edge-AI in Structural Health Monitoring domain
Apr 07, 2023Structural health monitoring (SHM) tasks like damage detection are crucial for decision-making regarding maintenance and deterioration. For example, crack detection in SHM is crucial for bridge maintenance as crack progression can lead to structural instability. However, most AI/ML models in the literature have low latency and late inference time issues while performing in real-time environments. This study aims to explore the integration of edge-AI in the SHM domain for real-time bridge inspections. Based on edge-AI literature, its capabilities will be valuable integration for a real-time decision support system in SHM tasks such that real-time inferences can be performed on physical sites. This study will utilize commercial edge-AI platforms, such as Google Coral Dev Board or Kneron KL520, to develop and analyze the effectiveness of edge-AI devices. Thus, this study proposes an edge AI framework for the structural health monitoring domain. An edge-AI-compatible deep learning model is developed to validate the framework to perform real-time crack classification. The effectiveness of this model will be evaluated based on its accuracy, the confusion matrix generated, and the inference time observed in a real-time setting.