 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Benchmarking UWB-Based Infrastructure-Free Positioning and Multi-Robot Relative Localization: Dataset and Characterization
May 15, 2023


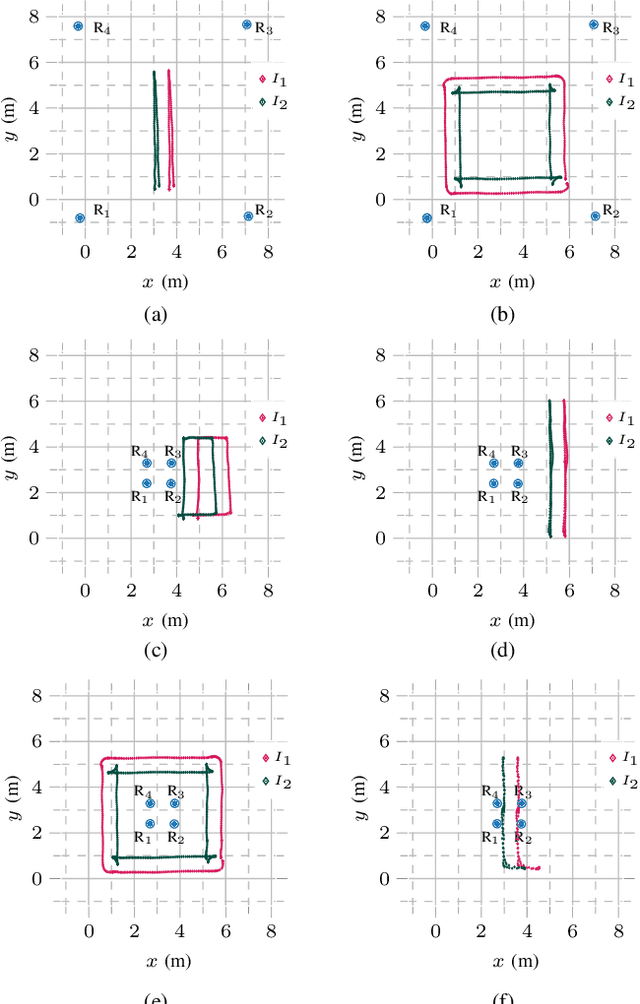
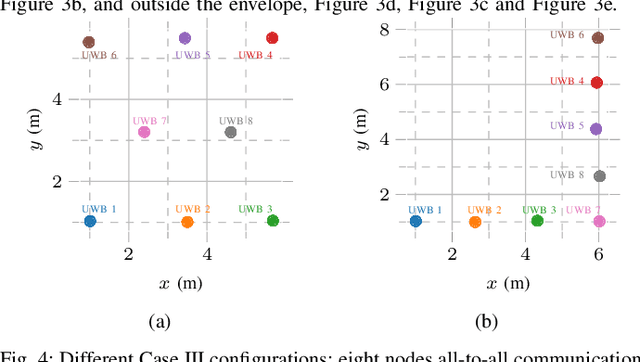
Ultra-wideband (UWB) positioning has emerged as a low-cost and dependable localization solution for multiple use cases, from mobile robots to asset tracking within the Industrial IoT. The technology is mature and the scientific literature contains multiple datasets and methods for localization based on fixed UWB nodes. At the same time, research in UWB-based relative localization and infrastructure-free localization is gaining traction, further domains. tools and datasets in this domain are scarce. Therefore, we introduce in this paper a novel dataset for benchmarking infrastructure-free relative localization targeting the domain of multi-robot systems. Compared to previous datasets, we analyze the performance of different relative localization approaches for a much wider variety of scenarios with varying numbers of fixed and mobile nodes. A motion capture system provides ground truth data, are multi-modal and include inertial or odometry measurements for benchmarking sensor fusion methods. Additionally, the dataset contains measurements of ranging accuracy based on the relative orientation of antennas and a comprehensive set of measurements for ranging between a single pair of nodes. Our experimental analysis shows that high accuracy can be localization, but the variability of the ranging error is significant across different settings and setups.
Deep Visual-Genetic Biometrics for Taxonomic Classification of Rare Species
May 20, 2023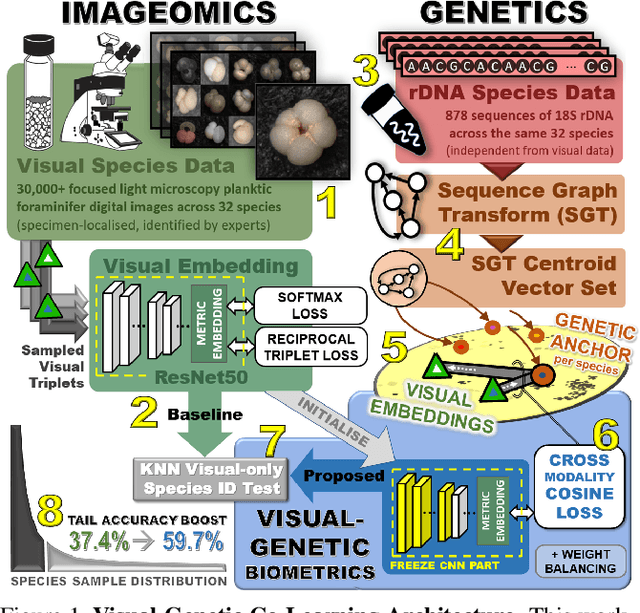
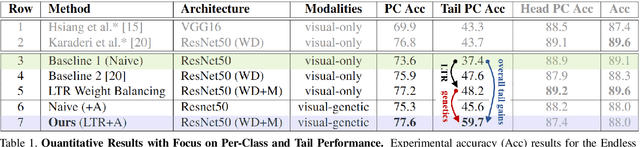
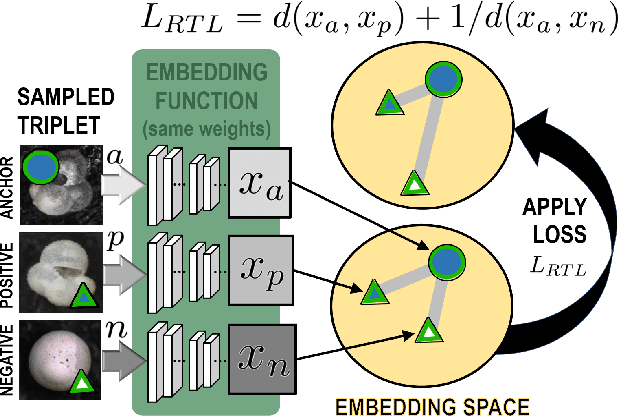
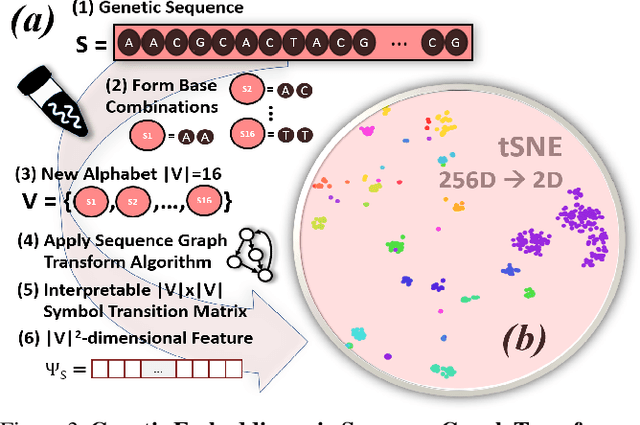
Visual as well as genetic biometrics are routinely employed to identify species and individuals in biological applications. However, no attempts have been made in this domain to computationally enhance visual classification of rare classes with little image data via genetics. In this paper, we thus propose aligned visual-genetic inference spaces with the aim to implicitly encode cross-domain associations for improved performance. We demonstrate for the first time that such alignment can be achieved via deep embedding models and that the approach is directly applicable to boosting long-tailed recognition (LTR) particularly for rare species. We experimentally demonstrate the efficacy of the concept via application to microscopic imagery of 30k+ planktic foraminifer shells across 32 species when used together with independent genetic data samples. Most importantly for practitioners, we show that visual-genetic alignment can significantly benefit visual-only recognition of the rarest species. Technically, we pre-train a visual ResNet50 deep learning model using triplet loss formulations to create an initial embedding space. We re-structure this space based on genetic anchors embedded via a Sequence Graph Transform (SGT) and linked to visual data by cross-domain cosine alignment. We show that an LTR approach improves the state-of-the-art across all benchmarks and that adding our visual-genetic alignment improves per-class and particularly rare tail class benchmarks significantly further. We conclude that visual-genetic alignment can be a highly effective tool for complementing visual biological data containing rare classes. The concept proposed may serve as an important future tool for integrating genetics and imageomics towards a more complete scientific representation of taxonomic spaces and life itself. Code, weights, and data splits are published for full reproducibility.
Safely Learning Dynamical Systems
May 20, 2023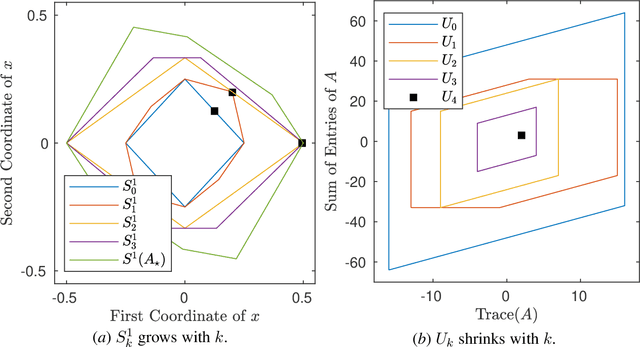
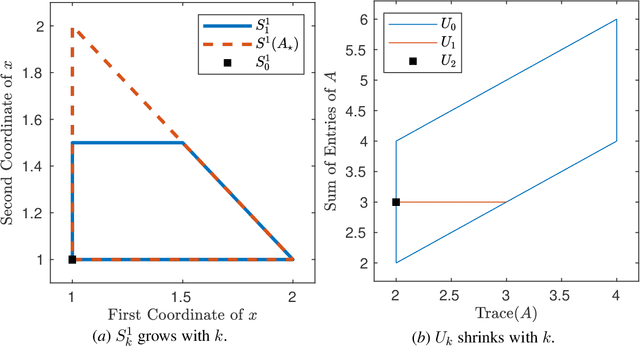
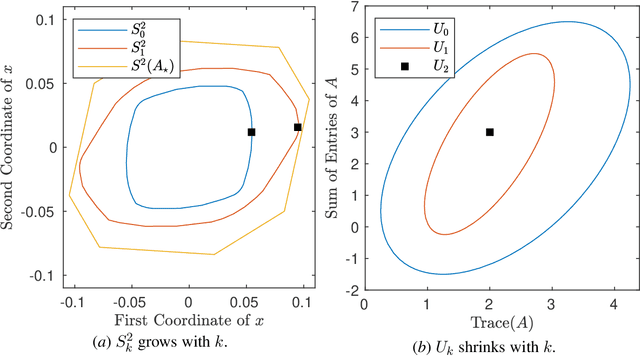
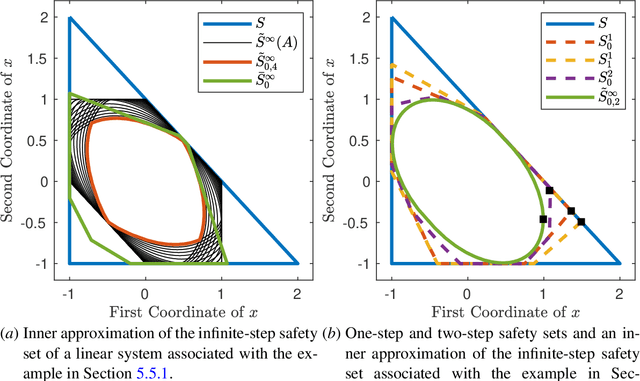
A fundamental challenge in learning an unknown dynamical system is to reduce model uncertainty by making measurements while maintaining safety. In this work, we formulate a mathematical definition of what it means to safely learn a dynamical system by sequentially deciding where to initialize the next trajectory. In our framework, the state of the system is required to stay within a safety region for a horizon of $T$ time steps under the action of all dynamical systems that (i) belong to a given initial uncertainty set, and (ii) are consistent with the information gathered so far. For our first set of results, we consider the setting of safely learning a linear dynamical system involving $n$ states. For the case $T=1$, we present a linear programming-based algorithm that either safely recovers the true dynamics from at most $n$ trajectories, or certifies that safe learning is impossible. For $T=2$, we give a semidefinite representation of the set of safe initial conditions and show that $\lceil n/2 \rceil$ trajectories generically suffice for safe learning. Finally, for $T = \infty$, we provide semidefinite representable inner approximations of the set of safe initial conditions and show that one trajectory generically suffices for safe learning. Our second set of results concerns the problem of safely learning a general class of nonlinear dynamical systems. For the case $T=1$, we give a second-order cone programming based representation of the set of safe initial conditions. For $T=\infty$, we provide semidefinite representable inner approximations to the set of safe initial conditions. We show how one can safely collect trajectories and fit a polynomial model of the nonlinear dynamics that is consistent with the initial uncertainty set and best agrees with the observations.
Weakly-supervised ROI extraction method based on contrastive learning for remote sensing images
May 10, 2023

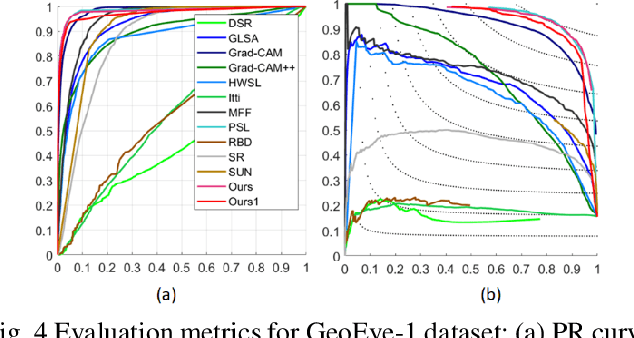

ROI extraction is an active but challenging task in remote sensing because of the complicated landform, the complex boundaries and the requirement of annotations. Weakly supervised learning (WSL) aims at learning a mapping from input image to pixel-wise prediction under image-wise labels, which can dramatically decrease the labor cost. However, due to the imprecision of labels, the accuracy and time consumption of WSL methods are relatively unsatisfactory. In this paper, we propose a two-step ROI extraction based on contractive learning. Firstly, we present to integrate multiscale Grad-CAM to obtain pseudo pixelwise annotations with well boundaries. Then, to reduce the compact of misjudgments in pseudo annotations, we construct a contrastive learning strategy to encourage the features inside ROI as close as possible and separate background features from foreground features. Comprehensive experiments demonstrate the superiority of our proposal. Code is available at https://github.com/HE-Lingfeng/ROI-Extraction
Dual flow fusion model for concrete surface crack segmentation
May 16, 2023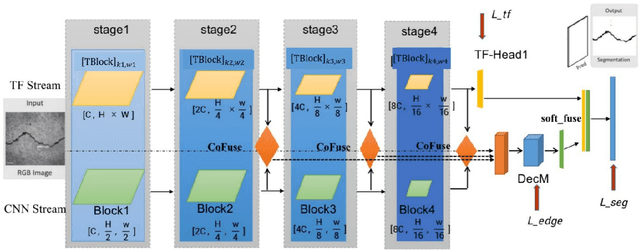
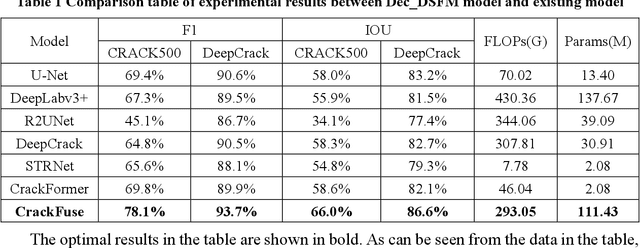
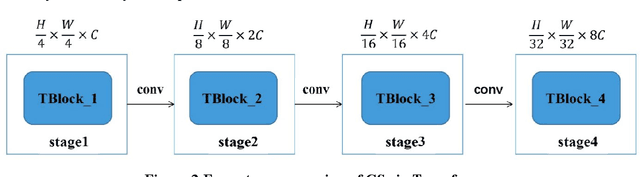
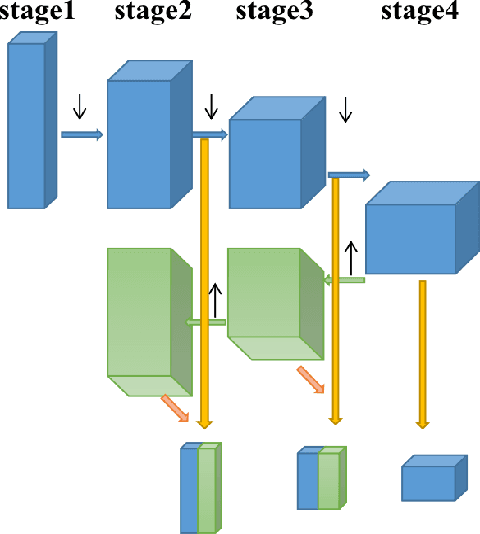
The existence of cracks and other damages pose a significant threat to the safe operation of transportation infrastructure. Traditional manual detection and ultrasound equipment testing consume a lot of time and resources. With the development of deep learning technology, many deep learning models have been widely applied to practical visual segmentation tasks. The detection method based on deep learning models has the advantages of high detection accuracy, fast detection speed, and simple operation. However, deep learning-based crack segmentation models are sensitive to background noise, have rough edges, and lack robustness. Therefore, this paper proposes a crack segmentation model based on the fusion of dual streams. The image is inputted simultaneously into two designed processing streams to independently extract long-distance dependence and local detail features. The adaptive prediction is achieved through the dual-headed mechanism. Meanwhile, a novel interaction fusion mechanism is proposed to guide the complementary of different feature layers to achieve crack location and recognition in complex backgrounds. Finally, an edge optimization method is proposed to improve the accuracy of segmentation. Experiments show that the F1 value of segmentation results on the DeepCrack[1] public dataset is 93.7% and the IOU value is 86.6%. The F1 value of segmentation results on the CRACK500[2] dataset is 78.1%, and the IOU value is 66.0%.
Leveraging Large Language Models in Conversational Recommender Systems
May 16, 2023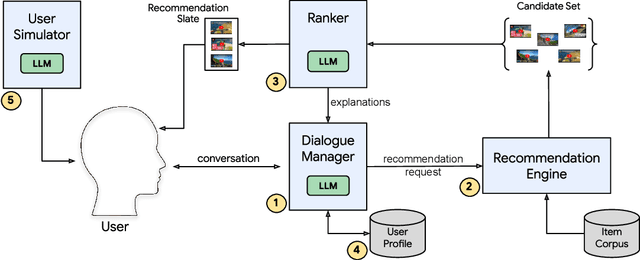



A Conversational Recommender System (CRS) offers increased transparency and control to users by enabling them to engage with the system through a real-time multi-turn dialogue. Recently, Large Language Models (LLMs) have exhibited an unprecedented ability to converse naturally and incorporate world knowledge and common-sense reasoning into language understanding, unlocking the potential of this paradigm. However, effectively leveraging LLMs within a CRS introduces new technical challenges, including properly understanding and controlling a complex conversation and retrieving from external sources of information. These issues are exacerbated by a large, evolving item corpus and a lack of conversational data for training. In this paper, we provide a roadmap for building an end-to-end large-scale CRS using LLMs. In particular, we propose new implementations for user preference understanding, flexible dialogue management and explainable recommendations as part of an integrated architecture powered by LLMs. For improved personalization, we describe how an LLM can consume interpretable natural language user profiles and use them to modulate session-level context. To overcome conversational data limitations in the absence of an existing production CRS, we propose techniques for building a controllable LLM-based user simulator to generate synthetic conversations. As a proof of concept we introduce RecLLM, a large-scale CRS for YouTube videos built on LaMDA, and demonstrate its fluency and diverse functionality through some illustrative example conversations.
New Linear-time Algorithm for SubTree Kernel Computation based on Root-Weighted Tree Automata
Feb 02, 2023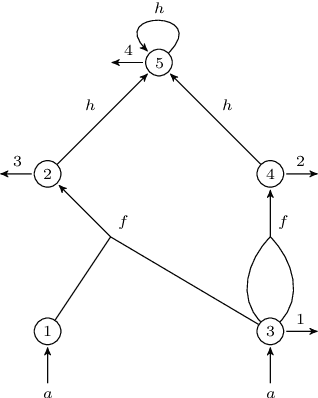

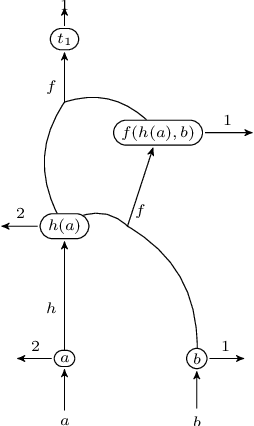
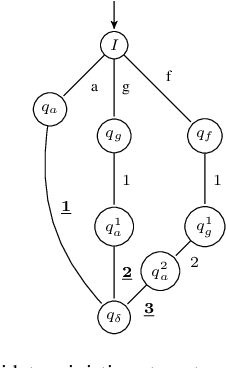
Tree kernels have been proposed to be used in many areas as the automatic learning of natural language applications. In this paper, we propose a new linear time algorithm based on the concept of weighted tree automata for SubTree kernel computation. First, we introduce a new class of weighted tree automata, called Root-Weighted Tree Automata, and their associated formal tree series. Then we define, from this class, the SubTree automata that represent compact computational models for finite tree languages. This allows us to design a theoretically guaranteed linear-time algorithm for computing the SubTree Kernel based on weighted tree automata intersection. The key idea behind the proposed algorithm is to replace DAG reduction and nodes sorting steps used in previous approaches by states equivalence classes computation allowed in the weighted tree automata approach. Our approach has three major advantages: it is output-sensitive, it is free sensitive from the tree types (ordered trees versus unordered trees), and it is well adapted to any incremental tree kernel based learning methods. Finally, we conduct a variety of comparative experiments on a wide range of synthetic tree languages datasets adapted for a deep algorithm analysis. The obtained results show that the proposed algorithm outperforms state-of-the-art methods.
Comfort Foods and Community Connectedness: Investigating Diet Change during COVID-19 Using YouTube Videos on Twitter
May 19, 2023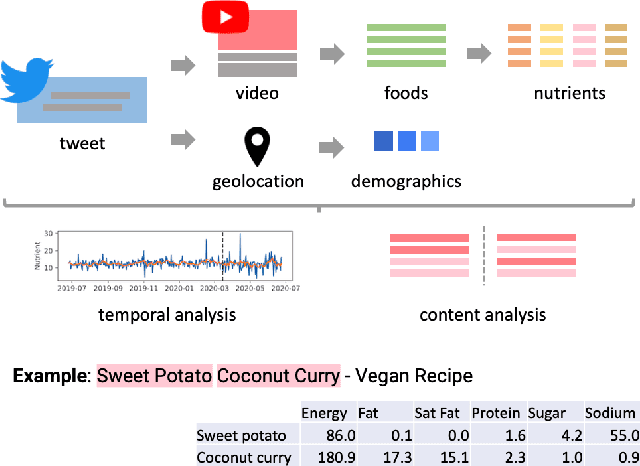

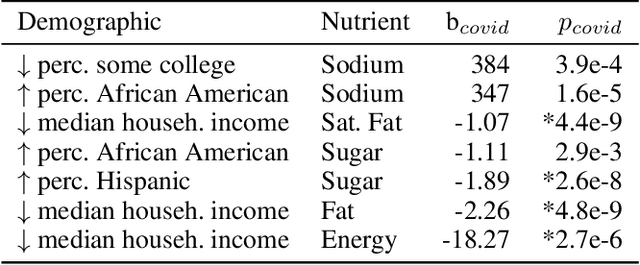
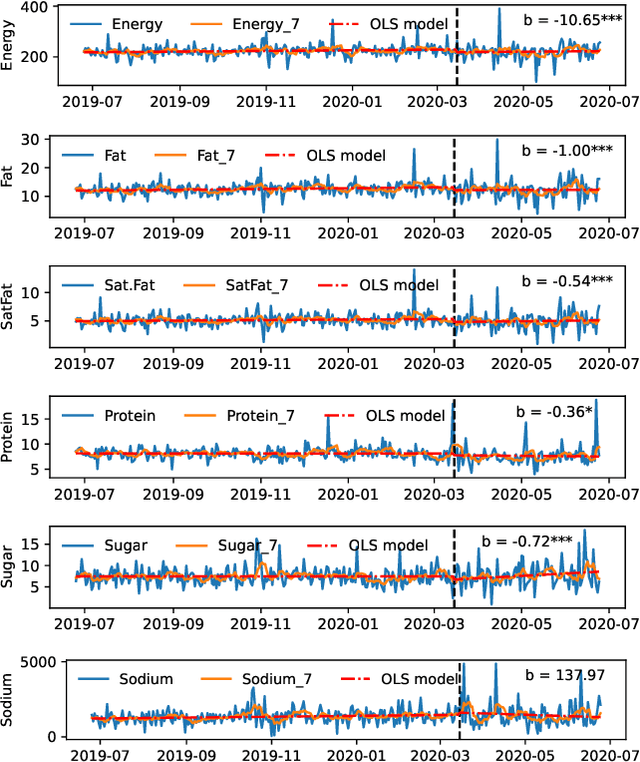
Unprecedented lockdowns at the start of the COVID-19 pandemic have drastically changed the routines of millions of people, potentially impacting important health-related behaviors. In this study, we use YouTube videos embedded in tweets about diet, exercise and fitness posted before and during COVID-19 to investigate the influence of the pandemic lockdowns on diet and nutrition. In particular, we examine the nutritional profile of the foods mentioned in the transcript, description and title of each video in terms of six macronutrients (protein, energy, fat, sodium, sugar, and saturated fat). These macronutrient values were further linked to demographics to assess if there are specific effects on those potentially having insufficient access to healthy sources of food. Interrupted time series analysis revealed a considerable shift in the aggregated macronutrient scores before and during COVID-19. In particular, whereas areas with lower incomes showed decrease in energy, fat, and saturated fat, those with higher percentage of African Americans showed an elevation in sodium. Word2Vec word similarities and odds ratio analysis suggested a shift from popular diets and lifestyle bloggers before the lockdowns to the interest in a variety of healthy foods, communal sharing of quick and easy recipes, as well as a new emphasis on comfort foods. To the best of our knowledge, this work is novel in terms of linking attention signals in tweets, content of videos, their nutrients profile, and aggregate demographics of the users. The insights made possible by this combination of resources are important for monitoring the secondary health effects of social distancing, and informing social programs designed to alleviate these effects.
Survey of Automatic Plankton Image Recognition: Challenges, Existing Solutions and Future Perspectives
May 19, 2023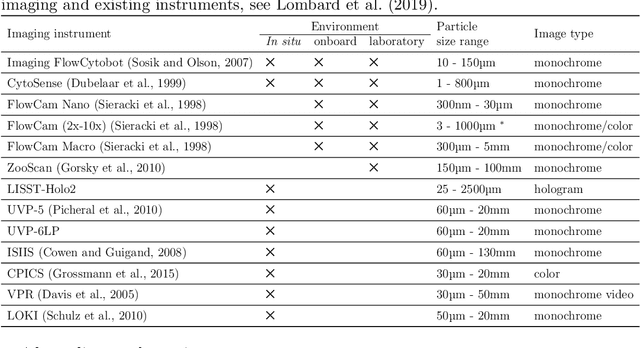
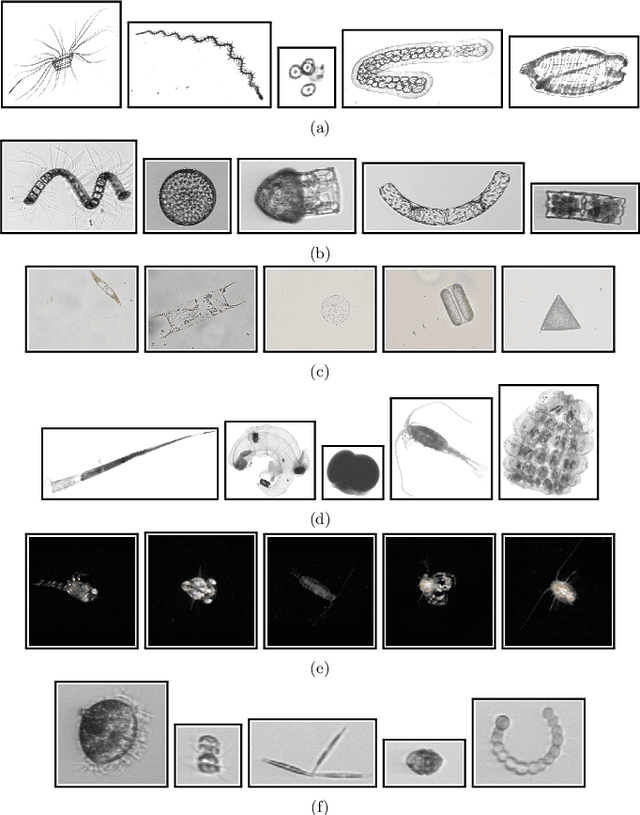
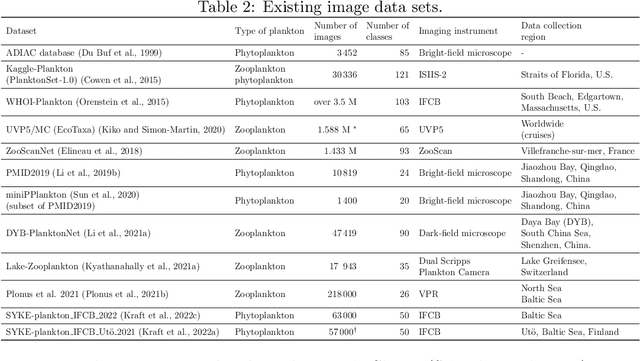
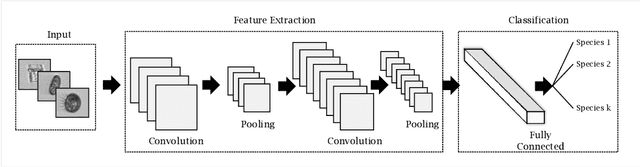
Planktonic organisms are key components of aquatic ecosystems and respond quickly to changes in the environment, therefore their monitoring is vital to understand the changes in the environment. Yet, monitoring plankton at appropriate scales still remains a challenge, limiting our understanding of functioning of aquatic systems and their response to changes. Modern plankton imaging instruments can be utilized to sample at high frequencies, enabling novel possibilities to study plankton populations. However, manual analysis of the data is costly, time consuming and expert based, making such approach unsuitable for large-scale application and urging for automatic solutions. The key problem related to the utilization of plankton datasets through image analysis is plankton recognition. Despite the large amount of research done, automatic methods have not been widely adopted for operational use. In this paper, a comprehensive survey on existing solutions for automatic plankton recognition is presented. First, we identify the most notable challenges that that make the development of plankton recognition systems difficult. Then, we provide a detailed description of solutions for these challenges proposed in plankton recognition literature. Finally, we propose a workflow to identify the specific challenges in new datasets and the recommended approaches to address them. For many of the challenges, applicable solutions exist. However, important challenges remain unsolved: 1) the domain shift between the datasets hindering the development of a general plankton recognition system that would work across different imaging instruments, 2) the difficulty to identify and process the images of previously unseen classes, and 3) the uncertainty in expert annotations that affects the training of the machine learning models for recognition. These challenges should be addressed in the future research.
SFP: Spurious Feature-targeted Pruning for Out-of-Distribution Generalization
May 19, 2023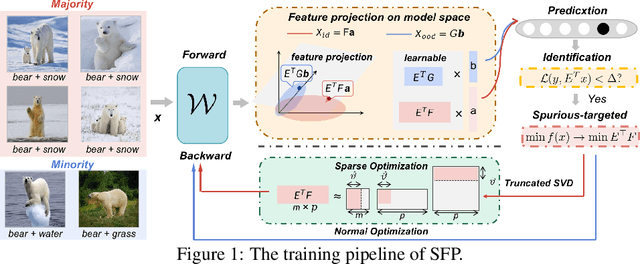
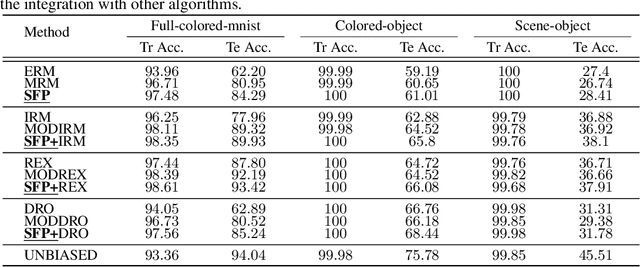

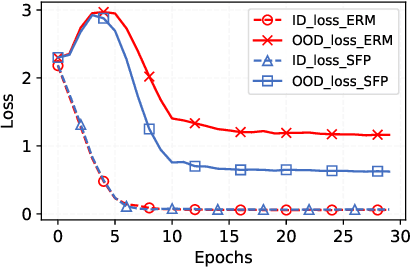
Model substructure learning aims to find an invariant network substructure that can have better out-of-distribution (OOD) generalization than the original full structure. Existing works usually search the invariant substructure using modular risk minimization (MRM) with fully exposed out-domain data, which may bring about two drawbacks: 1) Unfairness, due to the dependence of the full exposure of out-domain data; and 2) Sub-optimal OOD generalization, due to the equally feature-untargeted pruning on the whole data distribution. Based on the idea that in-distribution (ID) data with spurious features may have a lower experience risk, in this paper, we propose a novel Spurious Feature-targeted model Pruning framework, dubbed SFP, to automatically explore invariant substructures without referring to the above drawbacks. Specifically, SFP identifies spurious features within ID instances during training using our theoretically verified task loss, upon which, SFP attenuates the corresponding feature projections in model space to achieve the so-called spurious feature-targeted pruning. This is typically done by removing network branches with strong dependencies on identified spurious features, thus SFP can push the model learning toward invariant features and pull that out of spurious features and devise optimal OOD generalization. Moreover, we also conduct detailed theoretical analysis to provide the rationality guarantee and a proof framework for OOD structures via model sparsity, and for the first time, reveal how a highly biased data distribution affects the model's OOD generalization. Experiments on various OOD datasets show that SFP can significantly outperform both structure-based and non-structure-based OOD generalization SOTAs, with accuracy improvement up to 4.72% and 23.35%, respectively