 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Distilling Script Knowledge from Large Language Models for Constrained Language Planning
May 10, 2023

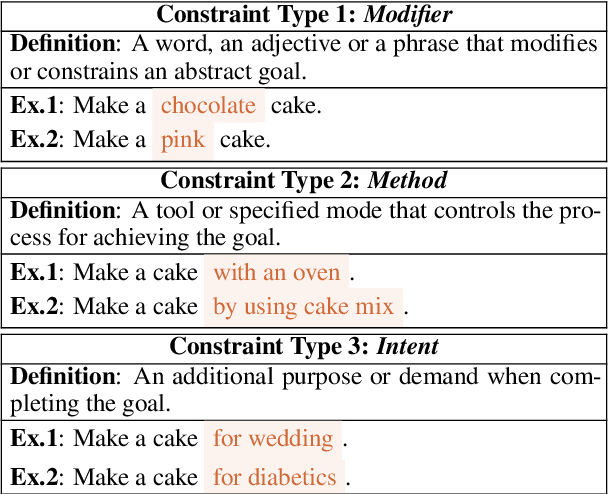
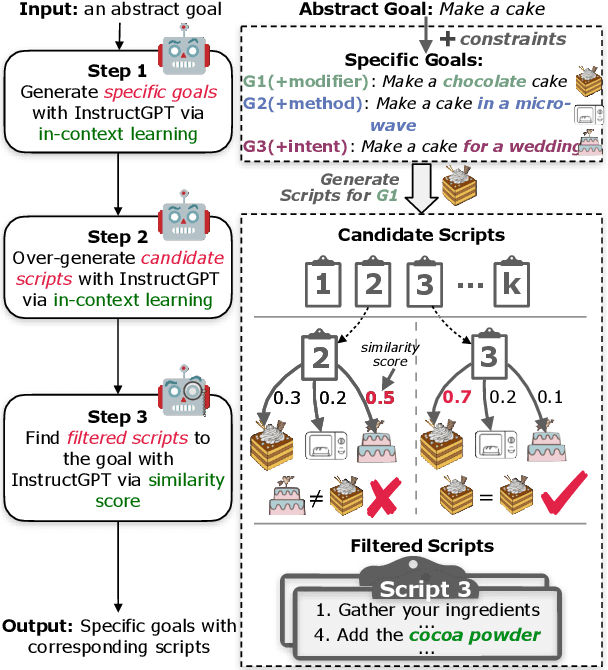

In everyday life, humans often plan their actions by following step-by-step instructions in the form of goal-oriented scripts. Previous work has exploited language models (LMs) to plan for abstract goals of stereotypical activities (e.g., "make a cake"), but leaves more specific goals with multi-facet constraints understudied (e.g., "make a cake for diabetics"). In this paper, we define the task of constrained language planning for the first time. We propose an overgenerate-then-filter approach to improve large language models (LLMs) on this task, and use it to distill a novel constrained language planning dataset, CoScript, which consists of 55,000 scripts. Empirical results demonstrate that our method significantly improves the constrained language planning ability of LLMs, especially on constraint faithfulness. Furthermore, CoScript is demonstrated to be quite effective in endowing smaller LMs with constrained language planning ability.
Reconstructing Animatable Categories from Videos
May 10, 2023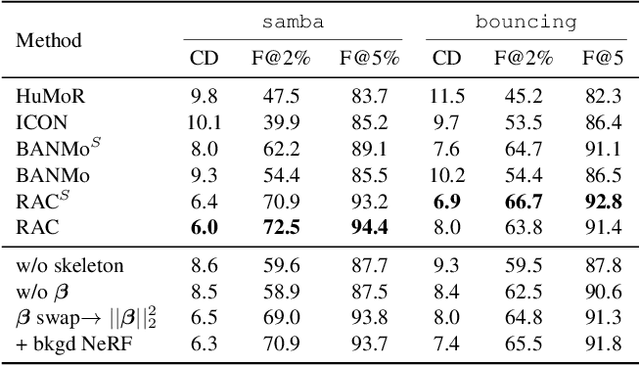



Building animatable 3D models is challenging due to the need for 3D scans, laborious registration, and manual rigging, which are difficult to scale to arbitrary categories. Recently, differentiable rendering provides a pathway to obtain high-quality 3D models from monocular videos, but these are limited to rigid categories or single instances. We present RAC that builds category 3D models from monocular videos while disentangling variations over instances and motion over time. Three key ideas are introduced to solve this problem: (1) specializing a skeleton to instances via optimization, (2) a method for latent space regularization that encourages shared structure across a category while maintaining instance details, and (3) using 3D background models to disentangle objects from the background. We show that 3D models of humans, cats, and dogs can be learned from 50-100 internet videos.
A survey of modularized backstepping control design approaches to nonlinear ODE systems
May 03, 2023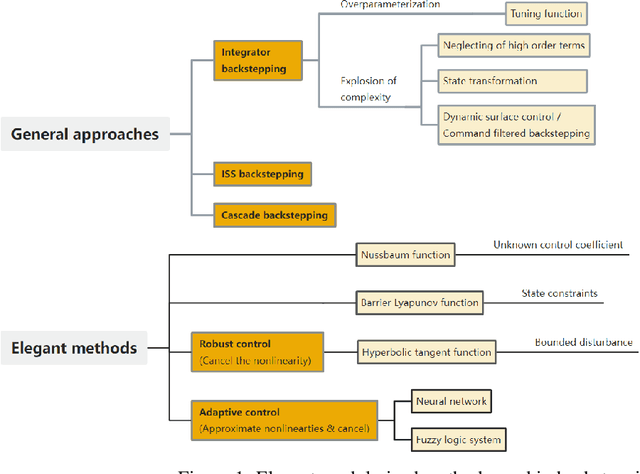
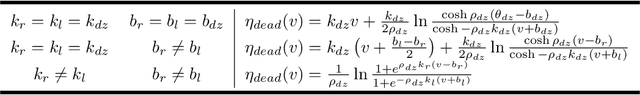
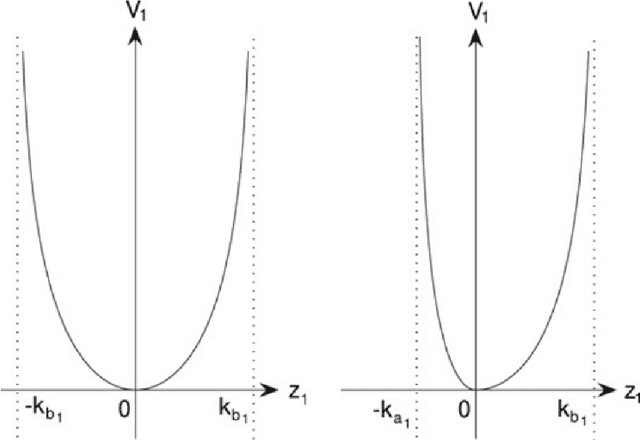
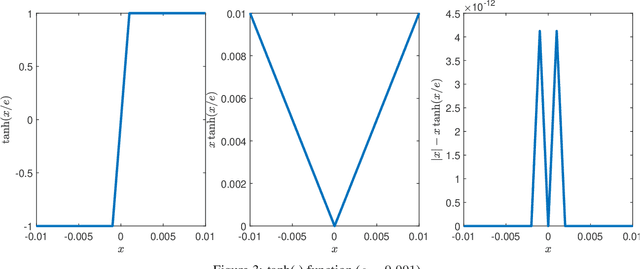
Backstepping is a mature and powerful Lyapunov-based design approach for a specific set of systems. Throughout the development over three decades, innovative theories and practices have extended backstepping to stabilization and tracking problems for nonlinear systems with growing complexity. The attractions of the backstepping-like approach are the recursive design processes and modularized design. A nonlinear system can be transferred into a group of simple problems and solved it by a sequential superposition of the corresponding approaches for each problem. To handle the complexities, backstepping designs always come up with adaptive control and robust control. The survey aims to review the milestone theoretical achievements among thousands of publications making the state-feedback backstepping designs of complex ODE systems to be systematic and modularized. Several selected elegant methods are reviewed, starting from the general designs, and then the finite-time control enhancing the convergence rate, the fuzzy logic system and neural network estimating the system unknowns, the Nussbaum function handling unknown control coefficients, barrier Lyapunov function solving state constraints, and the hyperbolic tangent function applying in robust designs. The associated assumptions and Lyapunov function candidates, inequalities, and the deduction key points are reviewed. The nonlinearity and complexities lay in state constraints, disturbance, input nonlinearities, time-delay effects, pure feedback systems, event-triggered systems, and stochastic systems. Instead of networked systems, the survey focuses on stand-alone systems.
CSDN: Combing Shallow and Deep Networks for Accurate Real-time Segmentation of High-definition Intravascular Ultrasound Images
Jan 30, 2023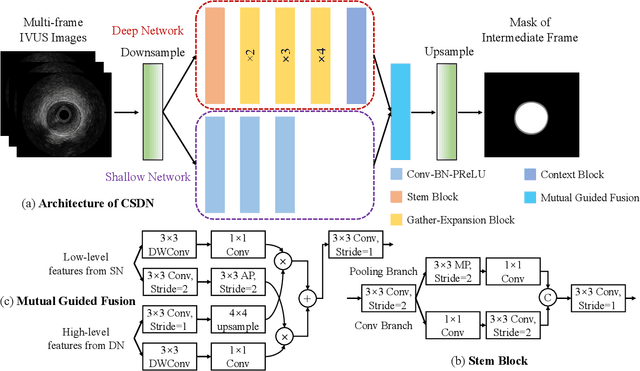
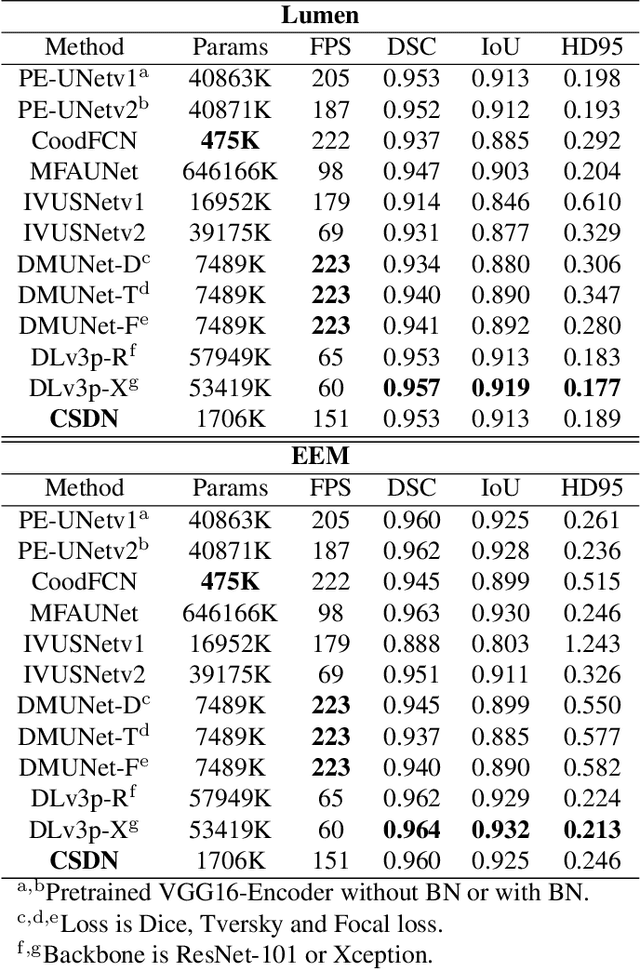

Intravascular ultrasound (IVUS) is the preferred modality for capturing real-time and high resolution cross-sectional images of the coronary arteries, and evaluating the stenosis. Accurate and real-time segmentation of IVUS images involves the delineation of lumen and external elastic membrane borders. In this paper, we propose a two-stream framework for efficient segmentation of 60 MHz high resolution IVUS images. It combines shallow and deep networks, namely, CSDN. The shallow network with thick channels focuses to extract low-level details. The deep network with thin channels takes charge of learning high-level semantics. Treating the above information separately enables learning a model to achieve high accuracy and high efficiency for accurate real-time segmentation. To further improve the segmentation performance, mutual guided fusion module is used to enhance and fuse both different types of feature representation. The experimental results show that our CSDN accomplishes a good trade-off between analysis speed and segmentation accuracy.
Learning Environment for the Air Domain (LEAD)
Apr 27, 2023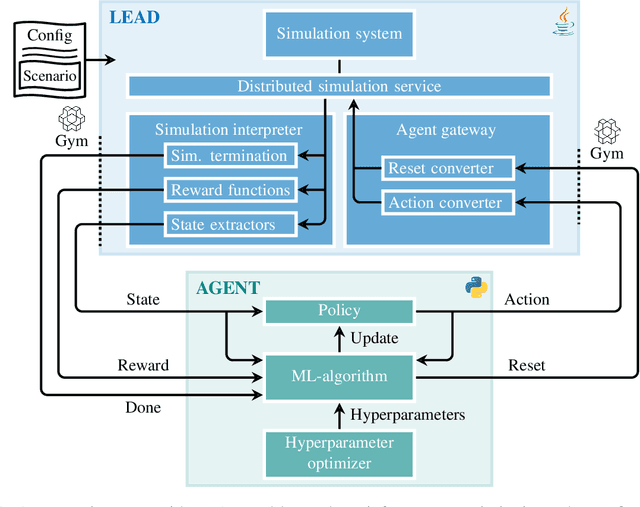


A substantial part of fighter pilot training is simulation-based and involves computer-generated forces controlled by predefined behavior models. The behavior models are typically manually created by eliciting knowledge from experienced pilots, which is a time-consuming process. Despite the work put in, the behavior models are often unsatisfactory due to their predictable nature and lack of adaptivity, forcing instructors to spend time manually monitoring and controlling them. Reinforcement and imitation learning pose as alternatives to handcrafted models. This paper presents the Learning Environment for the Air Domain (LEAD), a system for creating and integrating intelligent air combat behavior in military simulations. By incorporating the popular programming library and interface Gymnasium, LEAD allows users to apply readily available machine learning algorithms. Additionally, LEAD can communicate with third-party simulation software through distributed simulation protocols, which allows behavior models to be learned and employed using simulation systems of different fidelities.
LLT: An R package for Linear Law-based Feature Space Transformation
Apr 27, 2023
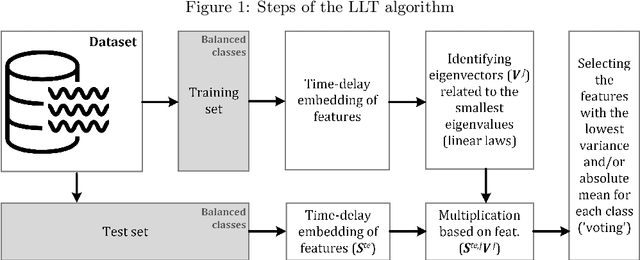
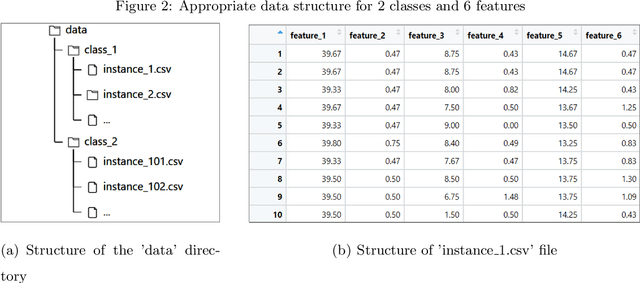
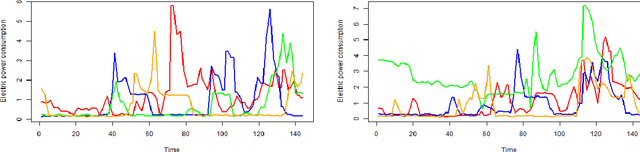
The goal of the linear law-based feature space transformation (LLT) algorithm is to assist with the classification of univariate and multivariate time series. The presented R package, called LLT, implements this algorithm in a flexible yet user-friendly way. This package first splits the instances into training and test sets. It then utilizes time-delay embedding and spectral decomposition techniques to identify the governing patterns (called linear laws) of each input sequence (initial feature) within the training set. Finally, it applies the linear laws of the training set to transform the initial features of the test set. These steps are performed by three separate functions called trainTest, trainLaw, and testTrans. Their application requires a predefined data structure; however, for fast calculation, they use only built-in functions. The LLT R package and a sample dataset with the appropriate data structure are publicly available on GitHub.
Open Continuum Robotics -- One Actuation Module to Create them All
Apr 24, 2023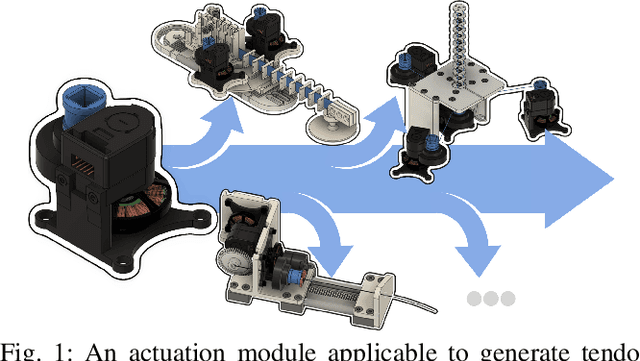

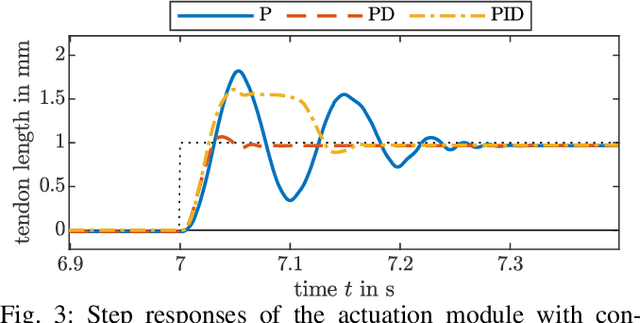
Experiments on physical continuum robot are the gold standard for evaluations. Currently, as no commercial continuum robot platform is available, a large variety of early-stage prototypes exists. These prototypes are developed by individual research groups and are often used for a single publication. Thus, a significant amount of time is devoted to creating proprietary hardware and software hindering the development of a common platform, and shifting away scarce time and efforts from the main research challenges. We address this problem by proposing an open-source actuation module, which can be used to build different types of continuum robots. It consists of a high-torque brushless electric motor, a high resolution optical encoder, and a low-gear-ratio transmission. For this letter, we create three different types of continuum robots. In addition, we illustrate, for the first time, that continuum robots built with our actuation module can proprioceptively detect external forces. Consequently, our approach opens untapped and under-investigated research directions related to the dynamics and advanced control of continuum robots, where sensing the generalized flow and effort is mandatory. Besides that, we democratize continuum robots research by providing open-source software and hardware with our initiative called the Open Continuum Robotics Project, to increase the accessibility and reproducibility of advanced methods.
Joint Graph Learning and Model Fitting in Laplacian Regularized Stratified Models
May 04, 2023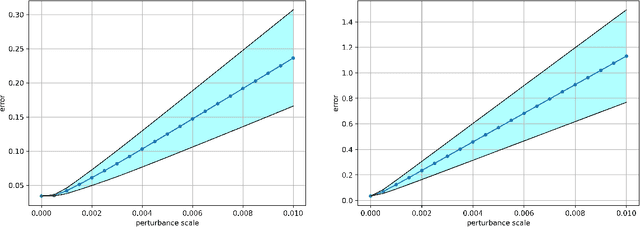
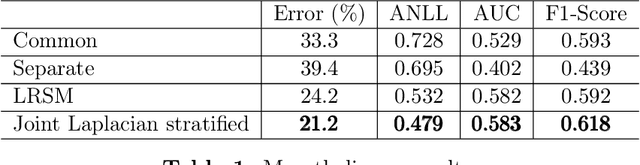
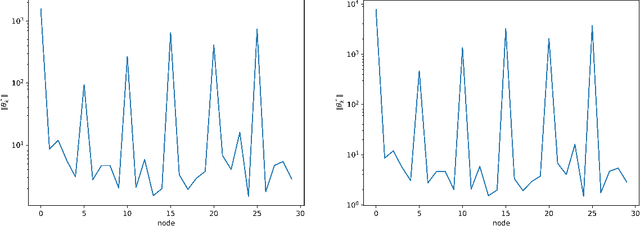
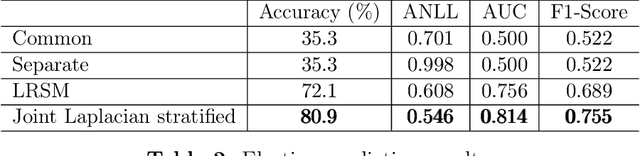
Laplacian regularized stratified models (LRSM) are models that utilize the explicit or implicit network structure of the sub-problems as defined by the categorical features called strata (e.g., age, region, time, forecast horizon, etc.), and draw upon data from neighboring strata to enhance the parameter learning of each sub-problem. They have been widely applied in machine learning and signal processing problems, including but not limited to time series forecasting, representation learning, graph clustering, max-margin classification, and general few-shot learning. Nevertheless, existing works on LRSM have either assumed a known graph or are restricted to specific applications. In this paper, we start by showing the importance and sensitivity of graph weights in LRSM, and provably show that the sensitivity can be arbitrarily large when the parameter scales and sample sizes are heavily imbalanced across nodes. We then propose a generic approach to jointly learn the graph while fitting the model parameters by solving a single optimization problem. We interpret the proposed formulation from both a graph connectivity viewpoint and an end-to-end Bayesian perspective, and propose an efficient algorithm to solve the problem. Convergence guarantees of the proposed optimization algorithm is also provided despite the lack of global strongly smoothness of the Laplacian regularization term typically required in the existing literature, which may be of independent interest. Finally, we illustrate the efficiency of our approach compared to existing methods by various real-world numerical examples.
Multilevel Sentence Embeddings for Personality Prediction
May 09, 2023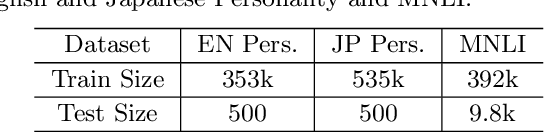
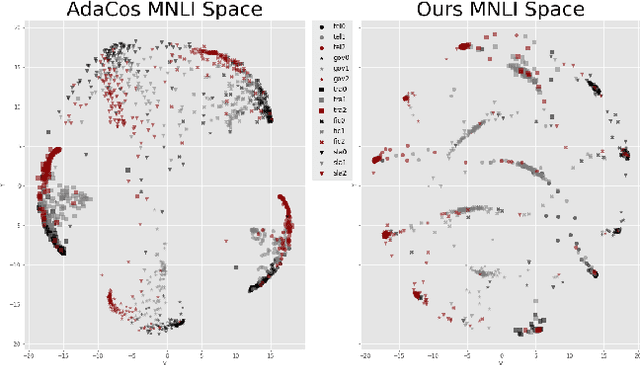
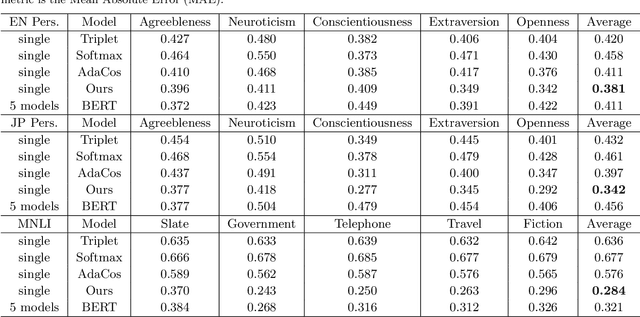
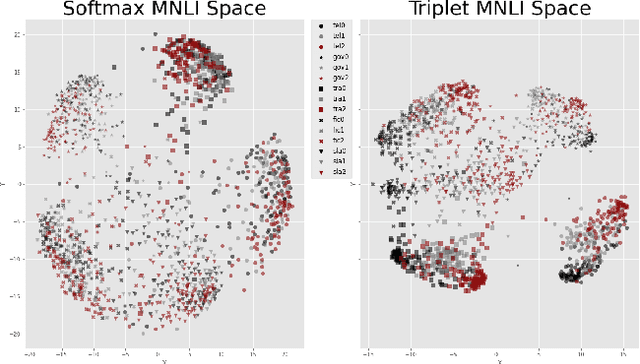
Representing text into a multidimensional space can be done with sentence embedding models such as Sentence-BERT (SBERT). However, training these models when the data has a complex multilevel structure requires individually trained class-specific models, which increases time and computing costs. We propose a two step approach which enables us to map sentences according to their hierarchical memberships and polarity. At first we teach the upper level sentence space through an AdaCos loss function and then finetune with a novel loss function mainly based on the cosine similarity of intra-level pairs. We apply this method to three different datasets: two weakly supervised Big Five personality dataset obtained from English and Japanese Twitter data and the benchmark MNLI dataset. We show that our single model approach performs better than multiple class-specific classification models.
* Copyright is owned by JSAI
Graph-Based Reductions for Parametric and Weighted MDPs
May 09, 2023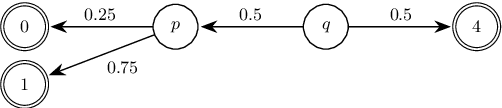
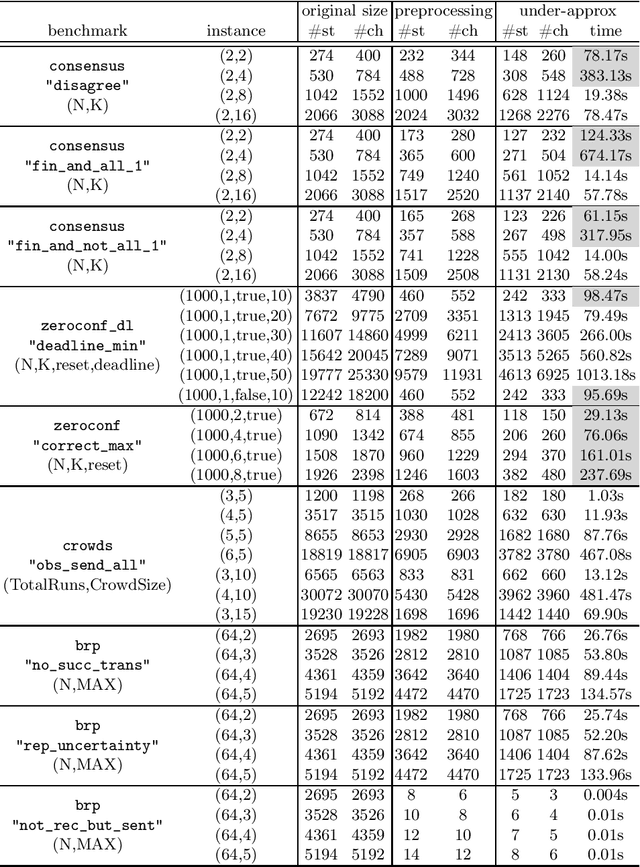
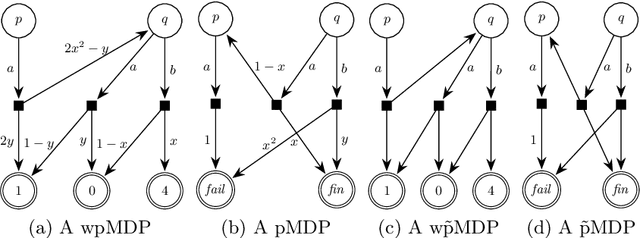
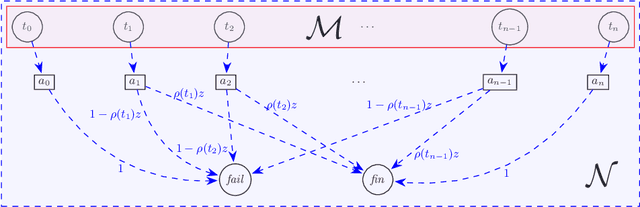
We study the complexity of reductions for weighted reachability in parametric Markov decision processes. That is, we say a state p is never worse than q if for all valuations of the polynomial indeterminates it is the case that the maximal expected weight that can be reached from p is greater than the same value from q. In terms of computational complexity, we establish that determining whether p is never worse than q is coETR-complete. On the positive side, we give a polynomial-time algorithm to compute the equivalence classes of the order we study for Markov chains. Additionally, we describe and implement two inference rules to under-approximate the never-worse relation and empirically show that it can be used as an efficient preprocessing step for the analysis of large Markov decision processes.