 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Tackling Interpretability in Audio Classification Networks with Non-negative Matrix Factorization
May 11, 2023

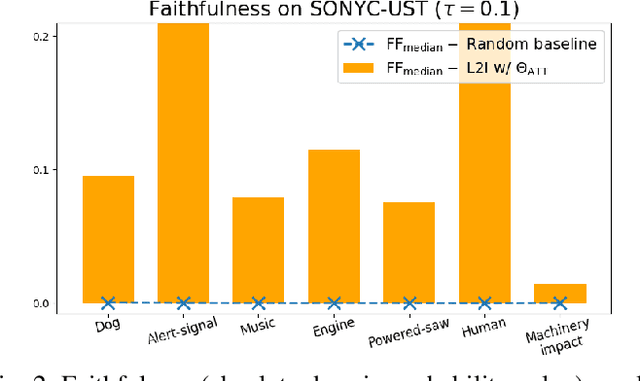
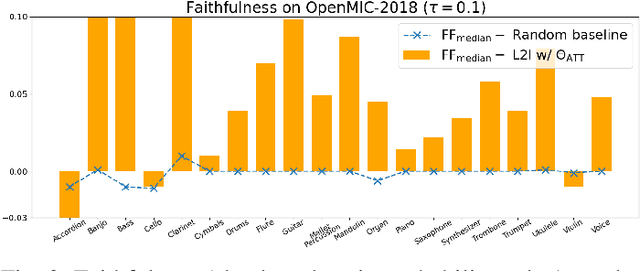
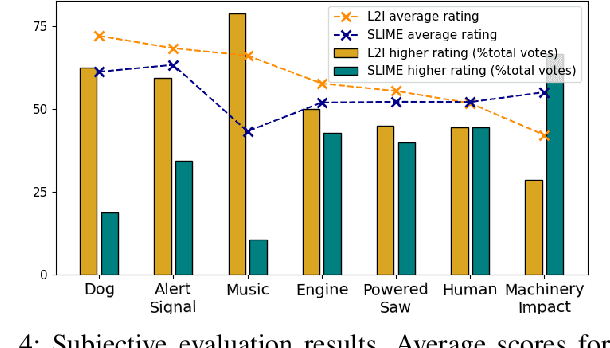
This paper tackles two major problem settings for interpretability of audio processing networks, post-hoc and by-design interpretation. For post-hoc interpretation, we aim to interpret decisions of a network in terms of high-level audio objects that are also listenable for the end-user. This is extended to present an inherently interpretable model with high performance. To this end, we propose a novel interpreter design that incorporates non-negative matrix factorization (NMF). In particular, an interpreter is trained to generate a regularized intermediate embedding from hidden layers of a target network, learnt as time-activations of a pre-learnt NMF dictionary. Our methodology allows us to generate intuitive audio-based interpretations that explicitly enhance parts of the input signal most relevant for a network's decision. We demonstrate our method's applicability on a variety of classification tasks, including multi-label data for real-world audio and music.
Embedded Feature Similarity Optimization with Specific Parameter Initialization for 2D/3D Registration
May 11, 2023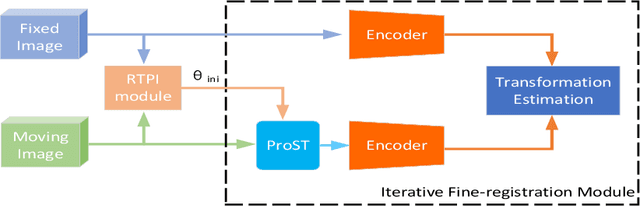
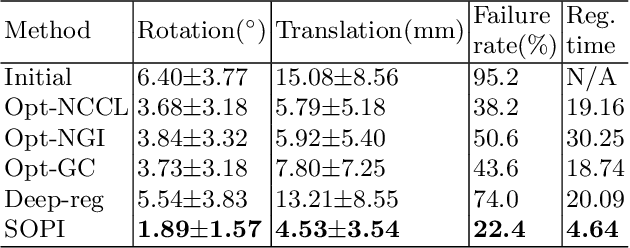
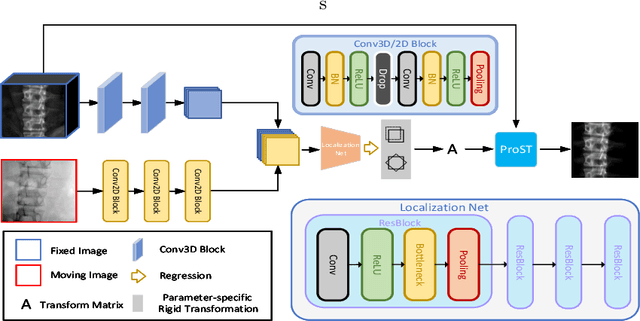
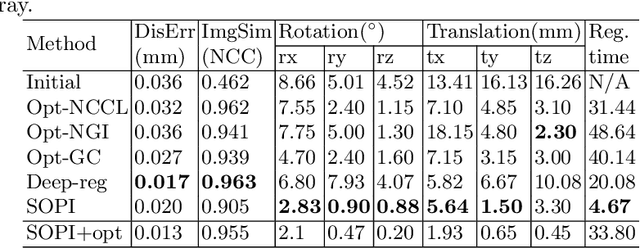
We present a novel deep learning-based framework: Embedded Feature Similarity Optimization with Specific Parameter Initialization (SOPI) for 2D/3D registration which is a most challenging problem due to the difficulty such as dimensional mismatch, heavy computation load and lack of golden evaluating standard. The framework we designed includes a parameter specification module to efficiently choose initialization pose parameter and a fine-registration network to align images. The proposed framework takes extracting multi-scale features into consideration using a novel composite connection encoder with special training techniques. The method is compared with both learning-based methods and optimization-based methods to further evaluate the performance. Our experiments demonstrate that the method in this paper has improved the registration performance, and thereby outperforms the existing methods in terms of accuracy and running time. We also show the potential of the proposed method as an initial pose estimator.
Efficient Ensemble Architecture for Multimodal Acoustic and Textual Embeddings in Punctuation Restoration using Time-Delay Neural Networks
Feb 26, 2023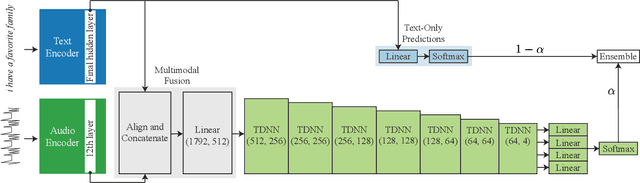

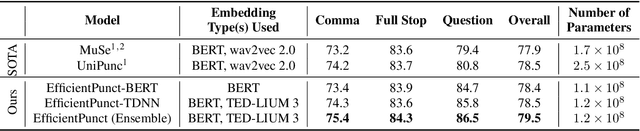
Punctuation restoration plays an essential role in the post-processing procedure of automatic speech recognition, but model efficiency is a key requirement for this task. To that end, we present EfficientPunct, an ensemble method with a multimodal time-delay neural network that outperforms the current best model by 1.0 F1 points, using less than a tenth of its parameters to process embeddings. We streamline a speech recognizer to efficiently output hidden layer latent vectors as audio embeddings for punctuation restoration, as well as BERT to extract meaningful text embeddings. By using forced alignment and temporal convolutions, we eliminate the need for multi-head attention-based fusion, greatly increasing computational efficiency but also raising performance. EfficientPunct sets a new state of the art, in terms of both performance and efficiency, with an ensemble that weights BERT's purely language-based predictions slightly more than the multimodal network's predictions.
Metric Temporal Equilibrium Logic over Timed Traces
Apr 28, 2023In temporal extensions of Answer Set Programming (ASP) based on linear-time, the behavior of dynamic systems is captured by sequences of states. While this representation reflects their relative order, it abstracts away the specific times associated with each state. However, timing constraints are important in many applications like, for instance, when planning and scheduling go hand in hand. We address this by developing a metric extension of linear-time temporal equilibrium logic, in which temporal operators are constrained by intervals over natural numbers. The resulting Metric Equilibrium Logic provides the foundation of an ASP-based approach for specifying qualitative and quantitative dynamic constraints. To this end, we define a translation of metric formulas into monadic first-order formulas and give a correspondence between their models in Metric Equilibrium Logic and Monadic Quantified Equilibrium Logic, respectively. Interestingly, our translation provides a blue print for implementation in terms of ASP modulo difference constraints.
DD-CISENet: Dual-Domain Cross-Iteration Squeeze and Excitation Network for Accelerated MRI Reconstruction
Apr 28, 2023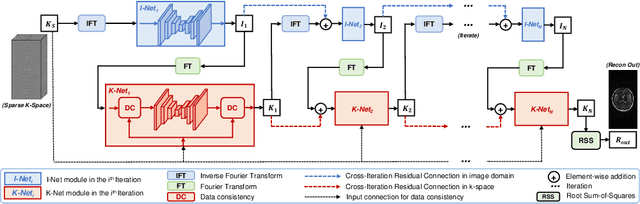
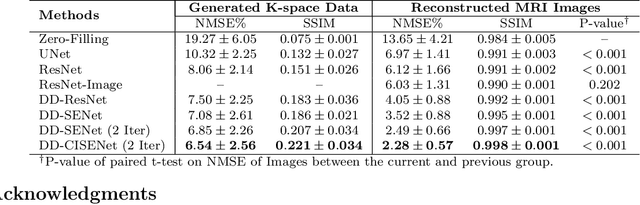
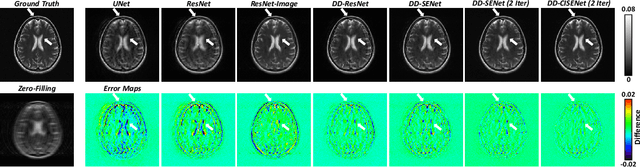
Magnetic resonance imaging (MRI) is widely employed for diagnostic tests in neurology. However, the utility of MRI is largely limited by its long acquisition time. Acquiring fewer k-space data in a sparse manner is a potential solution to reducing the acquisition time, but it can lead to severe aliasing reconstruction artifacts. In this paper, we present a novel Dual-Domain Cross-Iteration Squeeze and Excitation Network (DD-CISENet) for accelerated sparse MRI reconstruction. The information of k-spaces and MRI images can be iteratively fused and maintained using the Cross-Iteration Residual connection (CIR) structures. This study included 720 multi-coil brain MRI cases adopted from the open-source fastMRI Dataset. Results showed that the average reconstruction error by DD-CISENet was 2.28 $\pm$ 0.57%, which outperformed existing deep learning methods including image-domain prediction (6.03 $\pm$ 1.31, p < 0.001), k-space synthesis (6.12 $\pm$ 1.66, p < 0.001), and dual-domain feature fusion approaches (4.05 $\pm$ 0.88, p < 0.001).
Infomaxformer: Maximum Entropy Transformer for Long Time-Series Forecasting Problem
Jan 04, 2023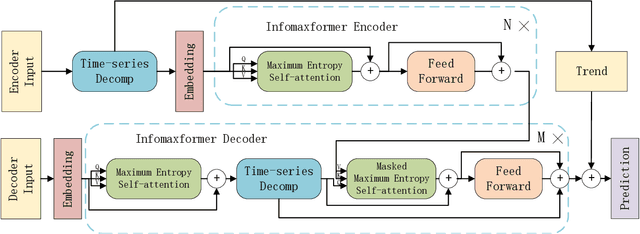
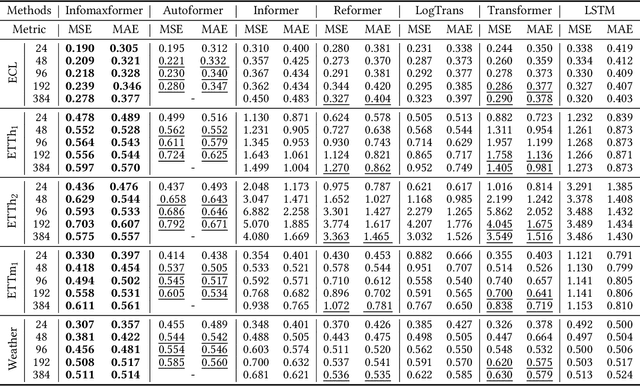
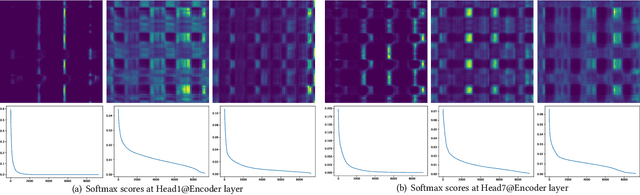
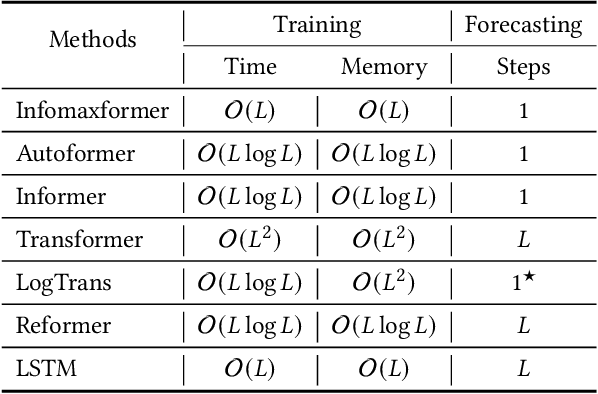
The Transformer architecture yields state-of-the-art results in many tasks such as natural language processing (NLP) and computer vision (CV), since the ability to efficiently capture the precise long-range dependency coupling between input sequences. With this advanced capability, however, the quadratic time complexity and high memory usage prevents the Transformer from dealing with long time-series forecasting problem (LTFP). To address these difficulties: (i) we revisit the learned attention patterns of the vanilla self-attention, redesigned the calculation method of self-attention based the Maximum Entropy Principle. (ii) we propose a new method to sparse the self-attention, which can prevent the loss of more important self-attention scores due to random sampling.(iii) We propose Keys/Values Distilling method motivated that a large amount of feature in the original self-attention map is redundant, which can further reduce the time and spatial complexity and make it possible to input longer time-series. Finally, we propose a method that combines the encoder-decoder architecture with seasonal-trend decomposition, i.e., using the encoder-decoder architecture to capture more specific seasonal parts. A large number of experiments on several large-scale datasets show that our Infomaxformer is obviously superior to the existing methods. We expect this to open up a new solution for Transformer to solve LTFP, and exploring the ability of the Transformer architecture to capture much longer temporal dependencies.
On Mini-Batch Training with Varying Length Time Series
Dec 13, 2022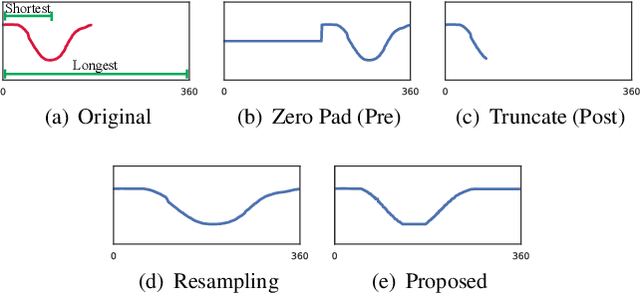
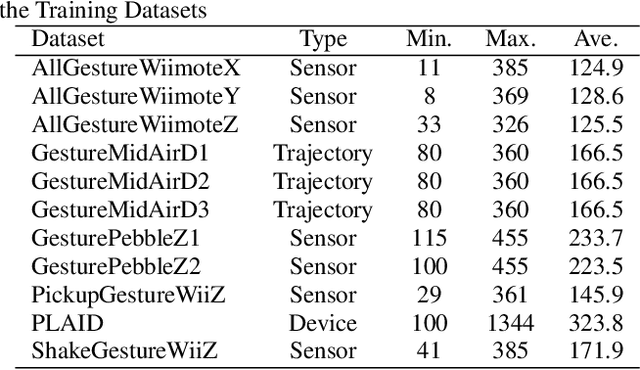
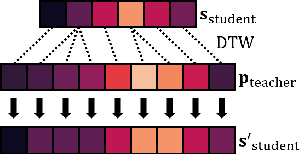
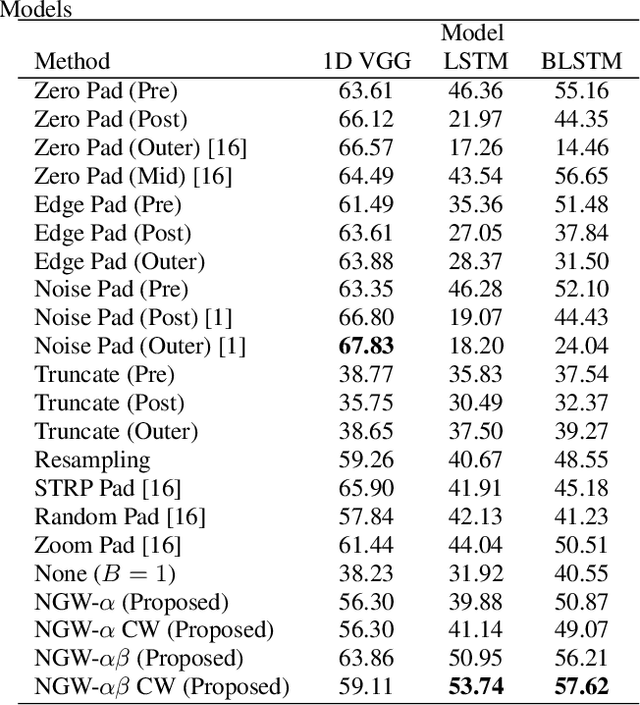
In real-world time series recognition applications, it is possible to have data with varying length patterns. However, when using artificial neural networks (ANN), it is standard practice to use fixed-sized mini-batches. To do this, time series data with varying lengths are typically normalized so that all the patterns are the same length. Normally, this is done using zero padding or truncation without much consideration. We propose a novel method of normalizing the lengths of the time series in a dataset by exploiting the dynamic matching ability of Dynamic Time Warping (DTW). In this way, the time series lengths in a dataset can be set to a fixed size while maintaining features typical to the dataset. In the experiments, all 11 datasets with varying length time series from the 2018 UCR Time Series Archive are used. We evaluate the proposed method by comparing it with 18 other length normalization methods on a Convolutional Neural Network (CNN), a Long-Short Term Memory network (LSTM), and a Bidirectional LSTM (BLSTM).
AER: Auto-Encoder with Regression for Time Series Anomaly Detection
Dec 27, 2022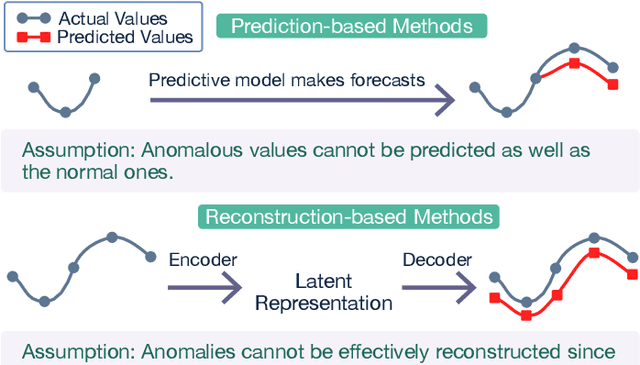
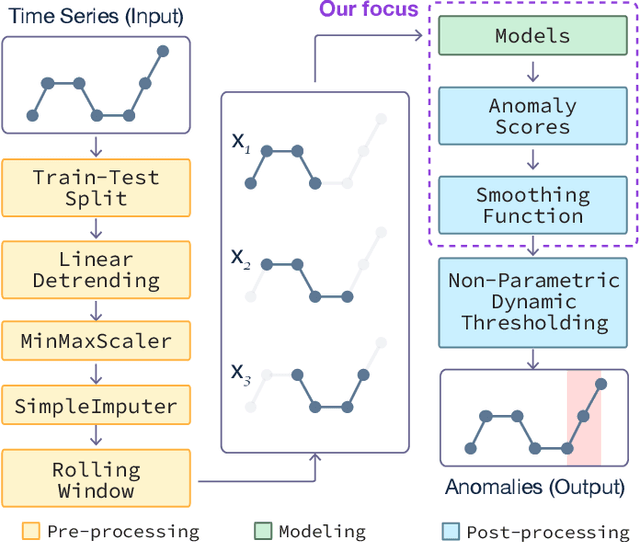
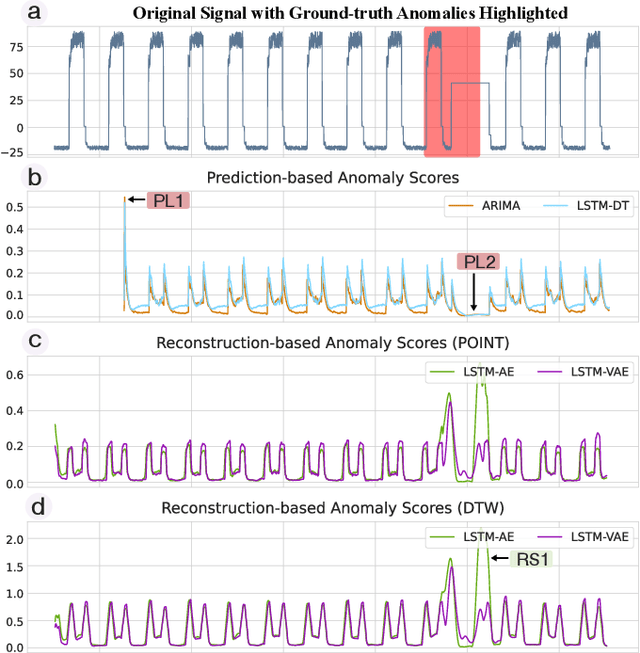
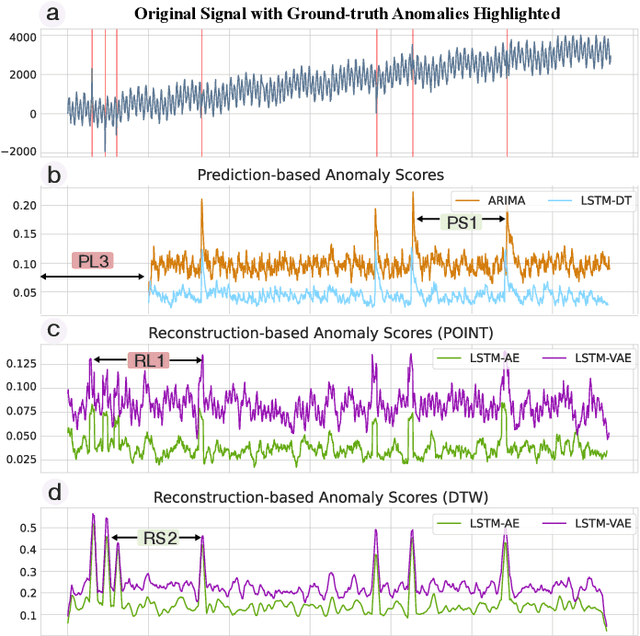
Anomaly detection on time series data is increasingly common across various industrial domains that monitor metrics in order to prevent potential accidents and economic losses. However, a scarcity of labeled data and ambiguous definitions of anomalies can complicate these efforts. Recent unsupervised machine learning methods have made remarkable progress in tackling this problem using either single-timestamp predictions or time series reconstructions. While traditionally considered separately, these methods are not mutually exclusive and can offer complementary perspectives on anomaly detection. This paper first highlights the successes and limitations of prediction-based and reconstruction-based methods with visualized time series signals and anomaly scores. We then propose AER (Auto-encoder with Regression), a joint model that combines a vanilla auto-encoder and an LSTM regressor to incorporate the successes and address the limitations of each method. Our model can produce bi-directional predictions while simultaneously reconstructing the original time series by optimizing a joint objective function. Furthermore, we propose several ways of combining the prediction and reconstruction errors through a series of ablation studies. Finally, we compare the performance of the AER architecture against two prediction-based methods and three reconstruction-based methods on 12 well-known univariate time series datasets from NASA, Yahoo, Numenta, and UCR. The results show that AER has the highest averaged F1 score across all datasets (a 23.5% improvement compared to ARIMA) while retaining a runtime similar to its vanilla auto-encoder and regressor components. Our model is available in Orion, an open-source benchmarking tool for time series anomaly detection.
Distilling Script Knowledge from Large Language Models for Constrained Language Planning
May 10, 2023
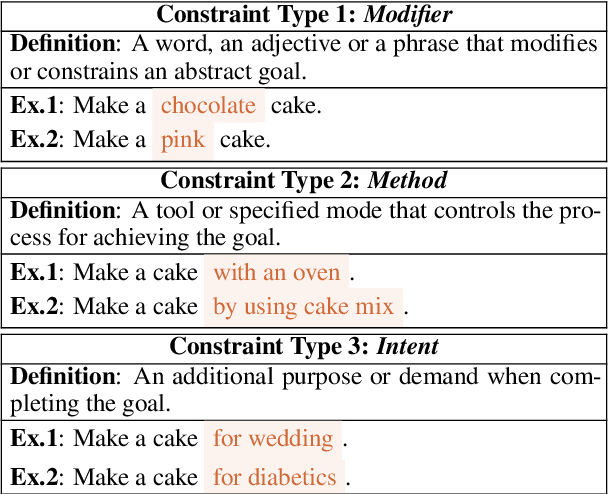
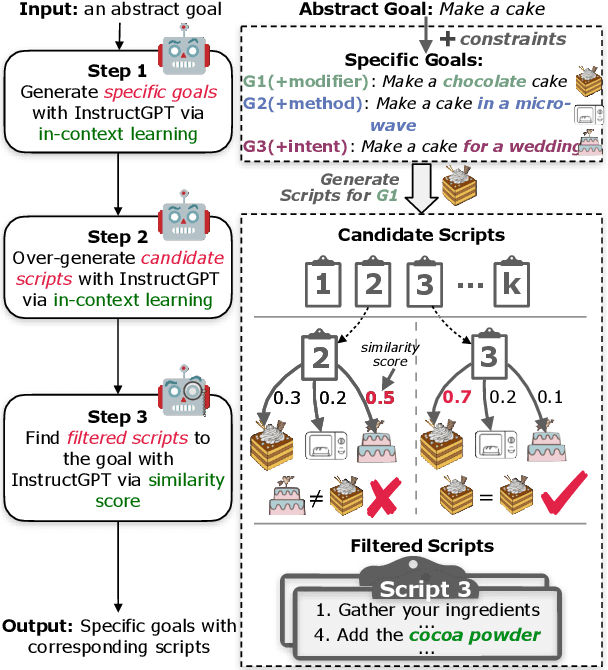

In everyday life, humans often plan their actions by following step-by-step instructions in the form of goal-oriented scripts. Previous work has exploited language models (LMs) to plan for abstract goals of stereotypical activities (e.g., "make a cake"), but leaves more specific goals with multi-facet constraints understudied (e.g., "make a cake for diabetics"). In this paper, we define the task of constrained language planning for the first time. We propose an overgenerate-then-filter approach to improve large language models (LLMs) on this task, and use it to distill a novel constrained language planning dataset, CoScript, which consists of 55,000 scripts. Empirical results demonstrate that our method significantly improves the constrained language planning ability of LLMs, especially on constraint faithfulness. Furthermore, CoScript is demonstrated to be quite effective in endowing smaller LMs with constrained language planning ability.
Reconstructing Animatable Categories from Videos
May 10, 2023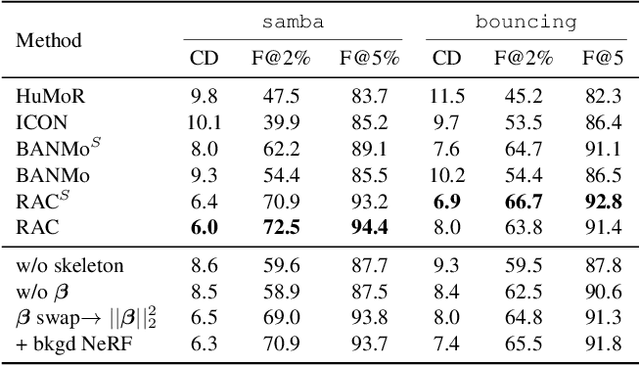



Building animatable 3D models is challenging due to the need for 3D scans, laborious registration, and manual rigging, which are difficult to scale to arbitrary categories. Recently, differentiable rendering provides a pathway to obtain high-quality 3D models from monocular videos, but these are limited to rigid categories or single instances. We present RAC that builds category 3D models from monocular videos while disentangling variations over instances and motion over time. Three key ideas are introduced to solve this problem: (1) specializing a skeleton to instances via optimization, (2) a method for latent space regularization that encourages shared structure across a category while maintaining instance details, and (3) using 3D background models to disentangle objects from the background. We show that 3D models of humans, cats, and dogs can be learned from 50-100 internet videos.