 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Predicting Generalization of AI Colonoscopy Models to Unseen Data
Mar 18, 2024
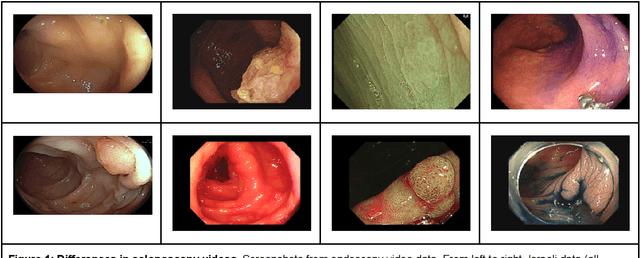
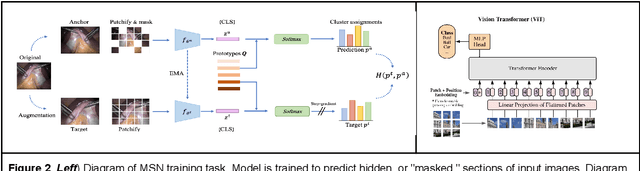
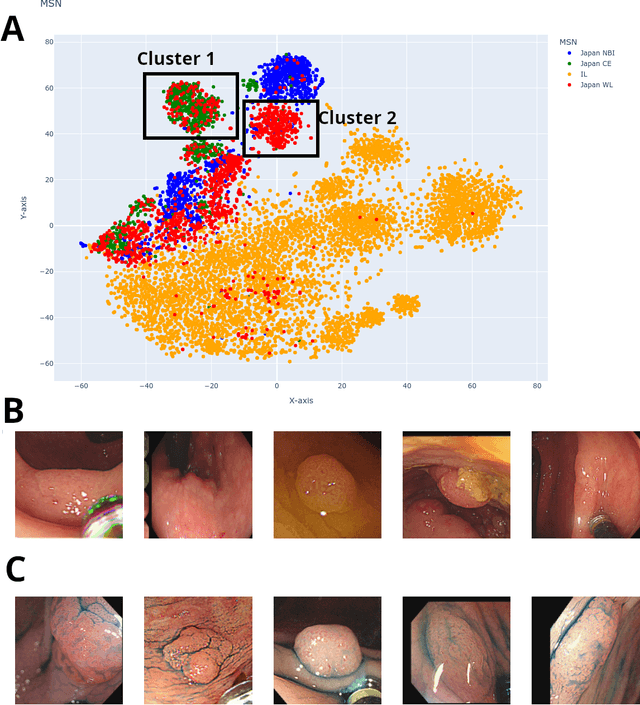
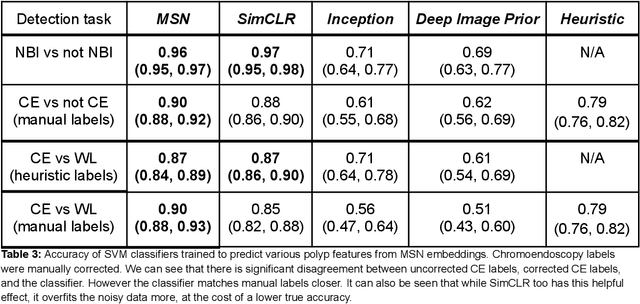
Background: Generalizability of AI colonoscopy algorithms is important for wider adoption in clinical practice. However, current techniques for evaluating performance on unseen data require expensive and time-intensive labels. Methods: We use a "Masked Siamese Network" (MSN) to identify novel phenomena in unseen data and predict polyp detector performance. MSN is trained to predict masked out regions of polyp images, without any labels. We test MSN's ability to be trained on data only from Israel and detect unseen techniques, narrow-band imaging (NBI) and chromendoscoy (CE), on colonoscopes from Japan (354 videos, 128 hours). We also test MSN's ability to predict performance of Computer Aided Detection (CADe) of polyps on colonoscopies from both countries, even though MSN is not trained on data from Japan. Results: MSN correctly identifies NBI and CE as less similar to Israel whitelight than Japan whitelight (bootstrapped z-test, |z| > 496, p < 10^-8 for both) using the label-free Frechet distance. MSN detects NBI with 99% accuracy, predicts CE better than our heuristic (90% vs 79% accuracy) despite being trained only on whitelight, and is the only method that is robust to noisy labels. MSN predicts CADe polyp detector performance on in-domain Israel and out-of-domain Japan colonoscopies (r=0.79, 0.37 respectively). With few examples of Japan detector performance to train on, MSN prediction of Japan performance improves (r=0.56). Conclusion: Our technique can identify distribution shifts in clinical data and can predict CADe detector performance on unseen data, without labels. Our self-supervised approach can aid in detecting when data in practice is different from training, such as between hospitals or data has meaningfully shifted from training. MSN has potential for application to medical image domains beyond colonoscopy.
CCC++: Optimized Color Classified Colorization with Segment Anything Model (SAM) Empowered Object Selective Color Harmonization
Mar 18, 2024
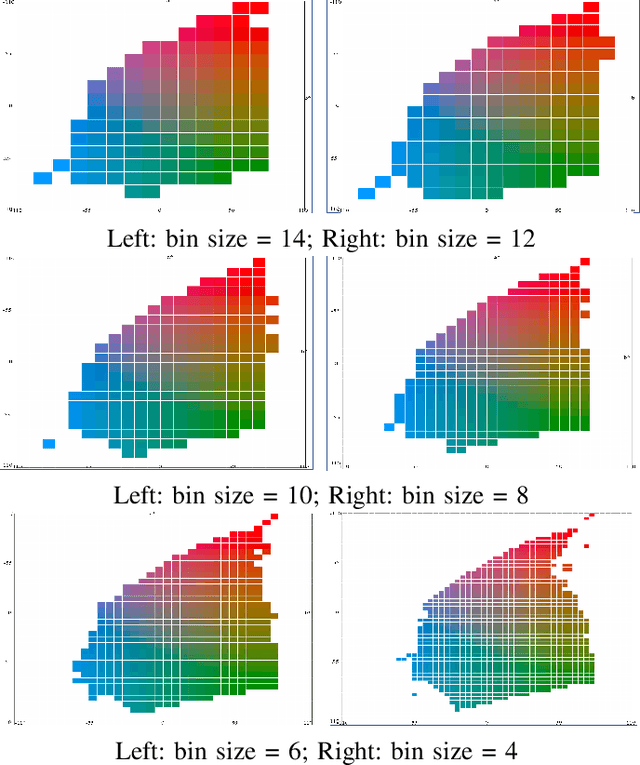
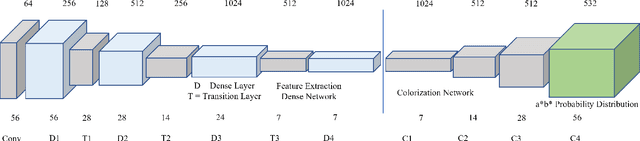
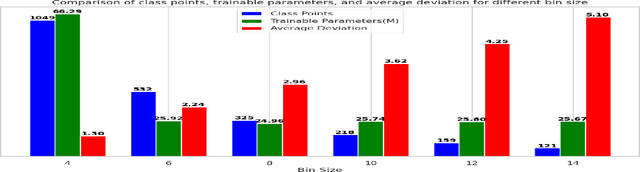
In this paper, we formulate the colorization problem into a multinomial classification problem and then apply a weighted function to classes. We propose a set of formulas to transform color values into color classes and vice versa. To optimize the classes, we experiment with different bin sizes for color class transformation. Observing class appearance, standard deviation, and model parameters on various extremely large-scale real-time images in practice we propose 532 color classes for our classification task. During training, we propose a class-weighted function based on true class appearance in each batch to ensure proper saturation of individual objects. We adjust the weights of the major classes, which are more frequently observed, by lowering them, while escalating the weights of the minor classes, which are less commonly observed. In our class re-weight formula, we propose a hyper-parameter for finding the optimal trade-off between the major and minor appeared classes. As we apply regularization to enhance the stability of the minor class, occasional minor noise may appear at the object's edges. We propose a novel object-selective color harmonization method empowered by the Segment Anything Model (SAM) to refine and enhance these edges. We propose two new color image evaluation metrics, the Color Class Activation Ratio (CCAR), and the True Activation Ratio (TAR), to quantify the richness of color components. We compare our proposed model with state-of-the-art models using six different dataset: Place, ADE, Celeba, COCO, Oxford 102 Flower, and ImageNet, in qualitative and quantitative approaches. The experimental results show that our proposed model outstrips other models in visualization, CNR and in our proposed CCAR and TAR measurement criteria while maintaining satisfactory performance in regression (MSE, PSNR), similarity (SSIM, LPIPS, UIUI), and generative criteria (FID).
Investigating Markers and Drivers of Gender Bias in Machine Translations
Mar 18, 2024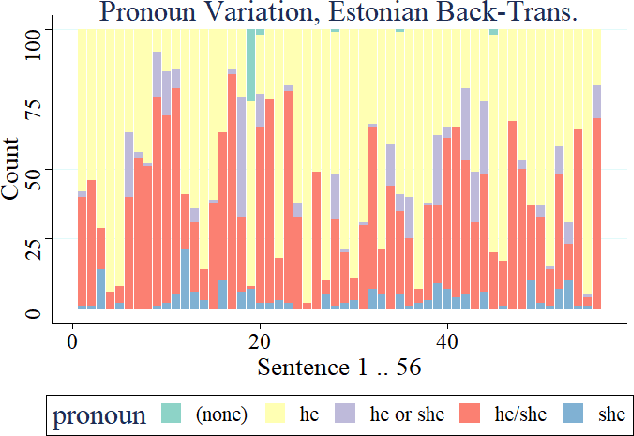
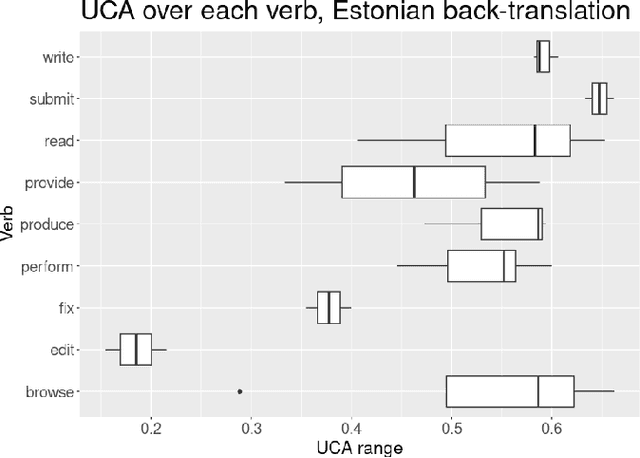
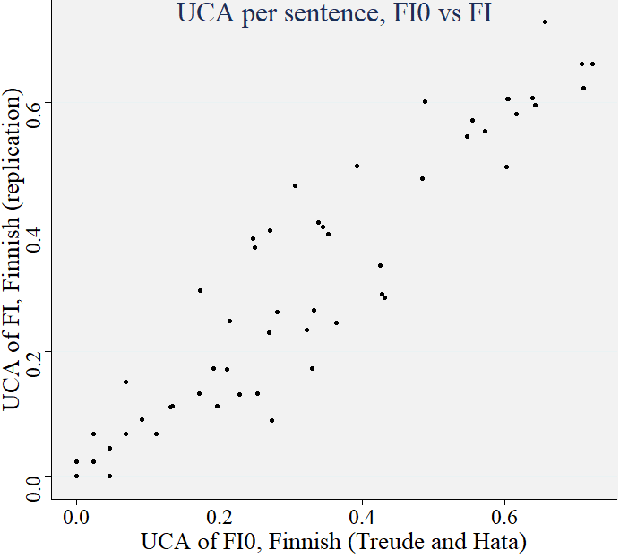
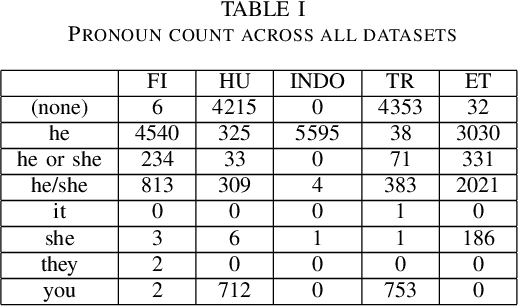
Implicit gender bias in Large Language Models (LLMs) is a well-documented problem, and implications of gender introduced into automatic translations can perpetuate real-world biases. However, some LLMs use heuristics or post-processing to mask such bias, making investigation difficult. Here, we examine bias in LLMss via back-translation, using the DeepL translation API to investigate the bias evinced when repeatedly translating a set of 56 Software Engineering tasks used in a previous study. Each statement starts with 'she', and is translated first into a 'genderless' intermediate language then back into English; we then examine pronoun-choice in the back-translated texts. We expand prior research in the following ways: (1) by comparing results across five intermediate languages, namely Finnish, Indonesian, Estonian, Turkish and Hungarian; (2) by proposing a novel metric for assessing the variation in gender implied in the repeated translations, avoiding the over-interpretation of individual pronouns, apparent in earlier work; (3) by investigating sentence features that drive bias; (4) and by comparing results from three time-lapsed datasets to establish the reproducibility of the approach. We found that some languages display similar patterns of pronoun use, falling into three loose groups, but that patterns vary between groups; this underlines the need to work with multiple languages. We also identify the main verb appearing in a sentence as a likely significant driver of implied gender in the translations. Moreover, we see a good level of replicability in the results, and establish that our variation metric proves robust despite an obvious change in the behaviour of the DeepL translation API during the course of the study. These results show that the back-translation method can provide further insights into bias in language models.
EnvGen: Generating and Adapting Environments via LLMs for Training Embodied Agents
Mar 18, 2024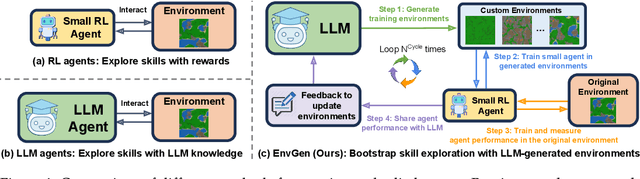

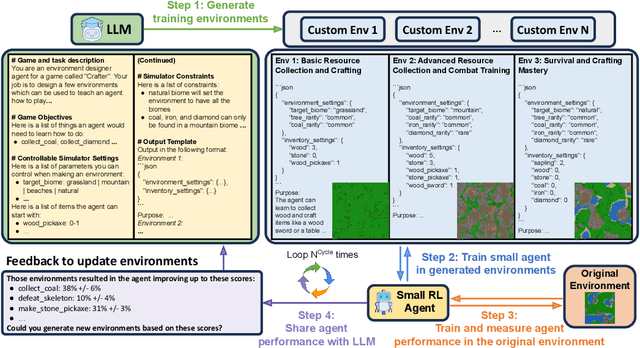

Recent SOTA approaches for embodied learning via interaction directly employ large language models (LLMs) as agents to determine the next steps in an environment. Due to their world knowledge and reasoning capabilities, LLM agents achieve stronger performance than previous smaller agents based on reinforcement learning (RL); however, frequently calling LLMs is slow and expensive. Instead of directly employing LLMs as agents, can we use LLMs' reasoning capabilities to adaptively create training environments to help smaller embodied RL agents learn useful skills that they are weak at? We propose EnvGen, a novel framework to address this question. First, we prompt an LLM to generate training environments that allow agents to quickly learn different tasks in parallel. Concretely, the LLM is given the task description and simulator objectives that the agents should learn and is then asked to generate a set of environment configurations (e.g., different terrains, items given to agents, etc.). Next, we train a small RL agent in a mixture of the original and LLM-generated environments. Then, we enable the LLM to continuously adapt the generated environments to progressively improve the skills that the agent is weak at, by providing feedback to the LLM in the form of the agent's performance. We demonstrate the usefulness of EnvGen with comprehensive experiments in Crafter and Heist environments. We find that a small RL agent trained with EnvGen can outperform SOTA methods, including a GPT-4 agent, and learns long-horizon tasks significantly faster. We show qualitatively how the LLM adapts training environments to help improve RL agents' weaker skills over time. Additionally, EnvGen is substantially more efficient as it only uses a small number of LLM calls (e.g., 4 in total), whereas LLM agents require thousands of LLM calls. Lastly, we present detailed ablation studies for our design choices.
STAR-RIS Aided Integrated Sensing and Communication over High Mobility Scenario
Mar 18, 2024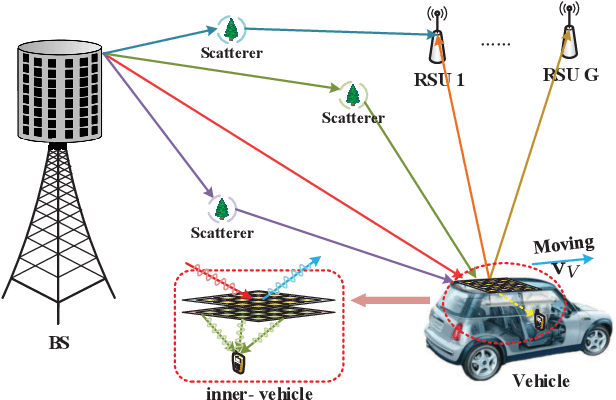
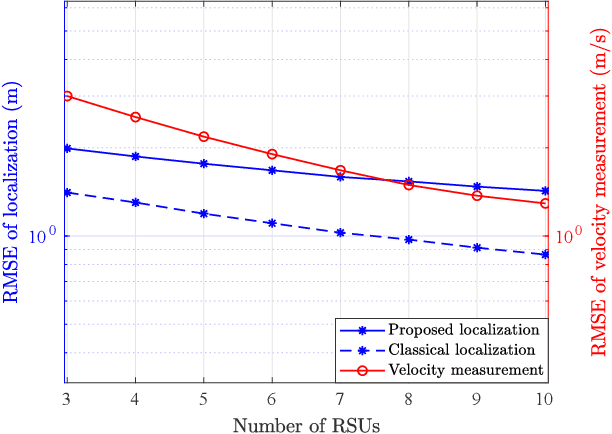
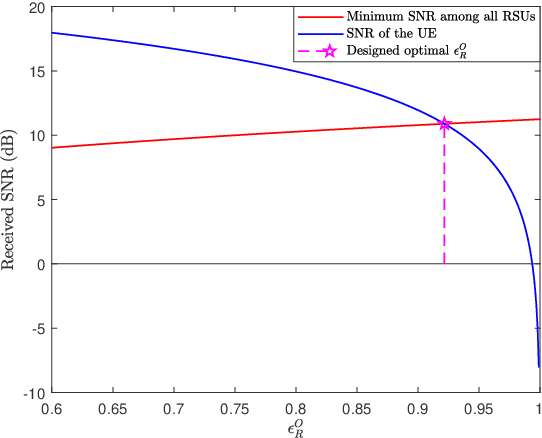
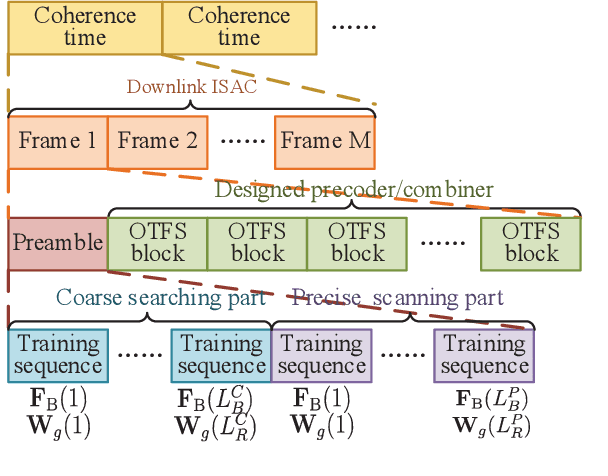
Integrated sensing and communication (ISAC) has become a promising technology for future communication system. In this paper, we consider a millimeter wave system over high mobility scenario, and propose a novel simultaneous transmission and reflection reconfigurable intelligent surface (STAR-RIS) aided ISAC scheme. To improve the communication service of the in-vehicle user equipment (UE) and simultaneously track and sense the vehicle with the help of nearby roadside units (RSUs), a STAR-RIS is equipped on the outside surface of the vehicle. Firstly, an efficient transmission structure is developed, where a number of training sequences with orthogonal precoders and combiners are respectively utilized at BS and RSUs for channel parameter extraction. Then, the near-field static channel model between the STAR-RIS and in-vehicle UE as well as the far-field time-frequency selective BS-RIS-RSUs channel model are characterized. By utilizing the multidimensional orthogonal matching pursuit (MOMP) algorithm, the cascaded channel parameters of the BS-RIS-RSUs links can be obtained at the RSUs. Thus, the vehicle localization and its velocity measurement can be acquired by jointly utilizing these extracted cascaded channel parameters of all RSUs. Note that the MOMP algorithm can be further utilized to extract the channel parameters of the BS-RIS-UE link for communication. With the help of sensing results, the phase shifts of the STAR-RIS are delicately designed, which can significantly improve the received signal strength for both the RSUs and the in-vehicle UE, and can finally enhance the sensing and communication performance. Moreover, the trade-off for sensing and communication is designed by optimizing the energy splitting factors of the STAR-RIS. Finally, simulation results are provided to validate the feasibility and effectiveness of our proposed STAR-RIS aided ISAC scheme.
Leveraging Foundation Model Automatic Data Augmentation Strategies and Skeletal Points for Hands Action Recognition in Industrial Assembly Lines
Mar 14, 2024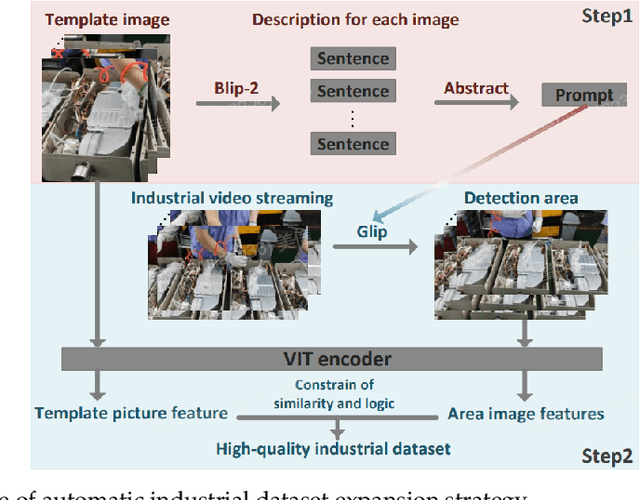

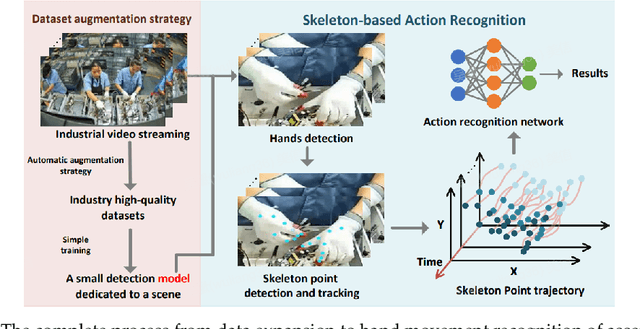

On modern industrial assembly lines, many intelligent algorithms have been developed to replace or supervise workers. However, we found that there were bottlenecks in both training datasets and real-time performance when deploying algorithms on actual assembly line. Therefore, we developed a promising strategy for expanding industrial datasets, which utilized large models with strong generalization abilities to achieve efficient, high-quality, and large-scale dataset expansion, solving the problem of insufficient and low-quality industrial datasets. We also applied this strategy to video action recognition. We proposed a method of converting hand action recognition problems into hand skeletal trajectory classification problems, which solved the real-time performance problem of industrial algorithms. In the "hand movements during wire insertion" scenarios on the actual assembly line, the accuracy of hand action recognition reached 98.8\%. We conducted detailed experimental analysis to demonstrate the effectiveness and superiority of the method, and deployed the entire process on Midea's actual assembly line.
Learning from straggler clients in federated learning
Mar 14, 2024
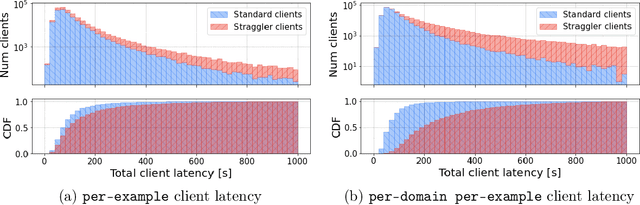

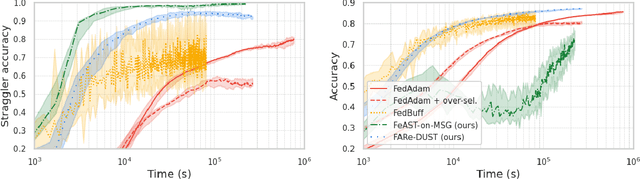
How well do existing federated learning algorithms learn from client devices that return model updates with a significant time delay? Is it even possible to learn effectively from clients that report back minutes, hours, or days after being scheduled? We answer these questions by developing Monte Carlo simulations of client latency that are guided by real-world applications. We study synchronous optimization algorithms like FedAvg and FedAdam as well as the asynchronous FedBuff algorithm, and observe that all these existing approaches struggle to learn from severely delayed clients. To improve upon this situation, we experiment with modifications, including distillation regularization and exponential moving averages of model weights. Finally, we introduce two new algorithms, FARe-DUST and FeAST-on-MSG, based on distillation and averaging, respectively. Experiments with the EMNIST, CIFAR-100, and StackOverflow benchmark federated learning tasks demonstrate that our new algorithms outperform existing ones in terms of accuracy for straggler clients, while also providing better trade-offs between training time and total accuracy.
Markovletics: Methods and A Novel Application for Learning Continuous-Time Markov Chain Mixtures
Feb 27, 2024Sequential data naturally arises from user engagement on digital platforms like social media, music streaming services, and web navigation, encapsulating evolving user preferences and behaviors through continuous information streams. A notable unresolved query in stochastic processes is learning mixtures of continuous-time Markov chains (CTMCs). While there is progress in learning mixtures of discrete-time Markov chains with recovery guarantees [GKV16,ST23,KTT2023], the continuous scenario uncovers unique unexplored challenges. The intrigue in CTMC mixtures stems from their potential to model intricate continuous-time stochastic processes prevalent in various fields including social media, finance, and biology. In this study, we introduce a novel framework for exploring CTMCs, emphasizing the influence of observed trails' length and mixture parameters on problem regimes, which demands specific algorithms. Through thorough experimentation, we examine the impact of discretizing continuous-time trails on the learnability of the continuous-time mixture, given that these processes are often observed via discrete, resource-demanding observations. Our comparative analysis with leading methods explores sample complexity and the trade-off between the number of trails and their lengths, offering crucial insights for method selection in different problem instances. We apply our algorithms on an extensive collection of Lastfm's user-generated trails spanning three years, demonstrating the capability of our algorithms to differentiate diverse user preferences. We pioneer the use of CTMC mixtures on a basketball passing dataset to unveil intricate offensive tactics of NBA teams. This underscores the pragmatic utility and versatility of our proposed framework. All results presented in this study are replicable, and we provide the implementations to facilitate reproducibility.
Reinforcement Learning with Elastic Time Steps
Feb 22, 2024Traditional Reinforcement Learning (RL) algorithms are usually applied in robotics to learn controllers that act with a fixed control rate. Given the discrete nature of RL algorithms, they are oblivious to the effects of the choice of control rate: finding the correct control rate can be difficult and mistakes often result in excessive use of computing resources or even lack of convergence. We propose Soft Elastic Actor-Critic (SEAC), a novel off-policy actor-critic algorithm to address this issue. SEAC implements elastic time steps, time steps with a known, variable duration, which allow the agent to change its control frequency to adapt to the situation. In practice, SEAC applies control only when necessary, minimizing computational resources and data usage. We evaluate SEAC's capabilities in simulation in a Newtonian kinematics maze navigation task and on a 3D racing video game, Trackmania. SEAC outperforms the SAC baseline in terms of energy efficiency and overall time management, and most importantly without the need to identify a control frequency for the learned controller. SEAC demonstrated faster and more stable training speeds than SAC, especially at control rates where SAC struggled to converge. We also compared SEAC with a similar approach, the Continuous-Time Continuous-Options (CTCO) model, and SEAC resulted in better task performance. These findings highlight the potential of SEAC for practical, real-world RL applications in robotics.
ContiFormer: Continuous-Time Transformer for Irregular Time Series Modeling
Feb 16, 2024Modeling continuous-time dynamics on irregular time series is critical to account for data evolution and correlations that occur continuously. Traditional methods including recurrent neural networks or Transformer models leverage inductive bias via powerful neural architectures to capture complex patterns. However, due to their discrete characteristic, they have limitations in generalizing to continuous-time data paradigms. Though neural ordinary differential equations (Neural ODEs) and their variants have shown promising results in dealing with irregular time series, they often fail to capture the intricate correlations within these sequences. It is challenging yet demanding to concurrently model the relationship between input data points and capture the dynamic changes of the continuous-time system. To tackle this problem, we propose ContiFormer that extends the relation modeling of vanilla Transformer to the continuous-time domain, which explicitly incorporates the modeling abilities of continuous dynamics of Neural ODEs with the attention mechanism of Transformers. We mathematically characterize the expressive power of ContiFormer and illustrate that, by curated designs of function hypothesis, many Transformer variants specialized in irregular time series modeling can be covered as a special case of ContiFormer. A wide range of experiments on both synthetic and real-world datasets have illustrated the superior modeling capacities and prediction performance of ContiFormer on irregular time series data. The project link is https://seqml.github.io/contiformer/.