 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Text-to-image Editing by Image Information Removal
May 27, 2023
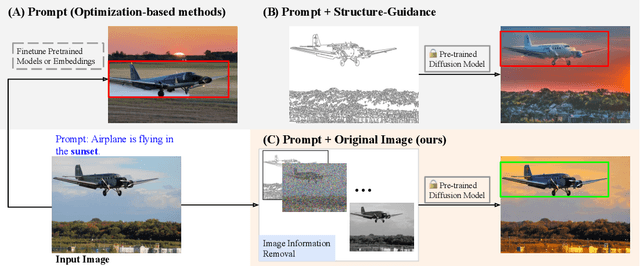
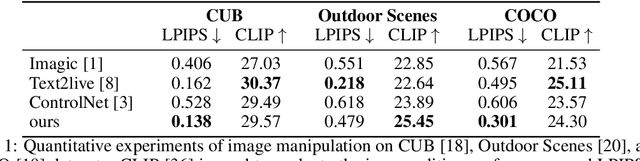
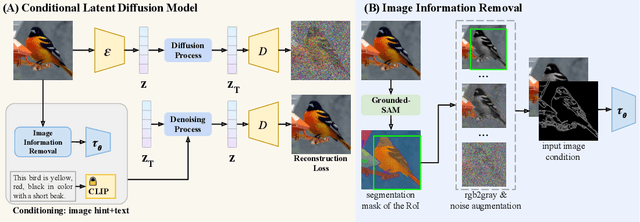

Diffusion models have demonstrated impressive performance in text-guided image generation. To leverage the knowledge of text-guided image generation models in image editing, current approaches either fine-tune the pretrained models using the input image (e.g., Imagic) or incorporate structure information as additional constraints into the pretrained models (e.g., ControlNet). However, fine-tuning large-scale diffusion models on a single image can lead to severe overfitting issues and lengthy inference time. The information leakage from pretrained models makes it challenging to preserve the text-irrelevant content of the input image while generating new features guided by language descriptions. On the other hand, methods that incorporate structural guidance (e.g., edge maps, semantic maps, keypoints) as additional constraints face limitations in preserving other attributes of the original image, such as colors or textures. A straightforward way to incorporate the original image is to directly use it as an additional control. However, since image editing methods are typically trained on the image reconstruction task, the incorporation can lead to the identical mapping issue, where the model learns to output an image identical to the input, resulting in limited editing capabilities. To address these challenges, we propose a text-to-image editing model with Image Information Removal module (IIR) to selectively erase color-related and texture-related information from the original image, allowing us to better preserve the text-irrelevant content and avoid the identical mapping issue. We evaluate our model on three benchmark datasets: CUB, Outdoor Scenes, and COCO. Our approach achieves the best editability-fidelity trade-off, and our edited images are approximately 35% more preferred by annotators than the prior-arts on COCO.
Barkour: Benchmarking Animal-level Agility with Quadruped Robots
May 24, 2023
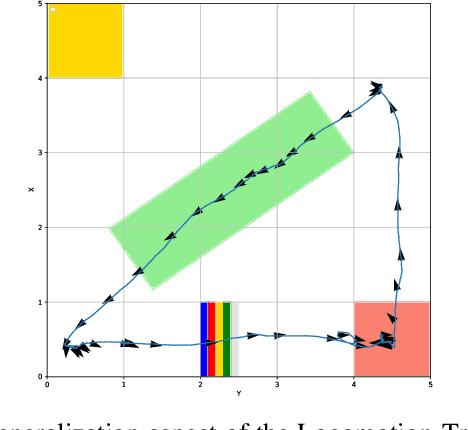
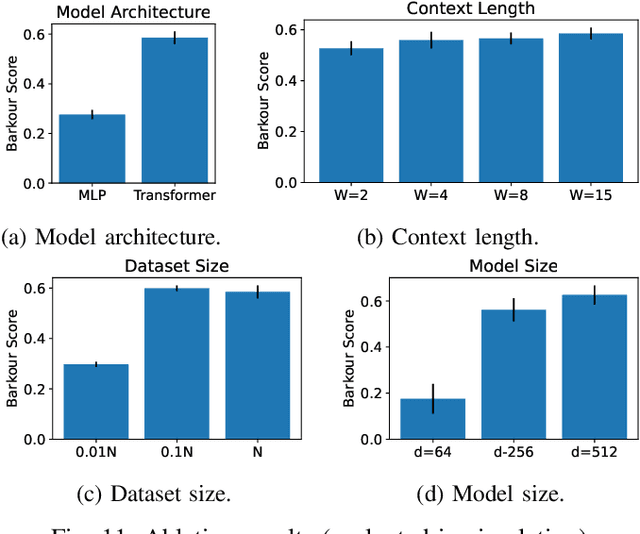

Animals have evolved various agile locomotion strategies, such as sprinting, leaping, and jumping. There is a growing interest in developing legged robots that move like their biological counterparts and show various agile skills to navigate complex environments quickly. Despite the interest, the field lacks systematic benchmarks to measure the performance of control policies and hardware in agility. We introduce the Barkour benchmark, an obstacle course to quantify agility for legged robots. Inspired by dog agility competitions, it consists of diverse obstacles and a time based scoring mechanism. This encourages researchers to develop controllers that not only move fast, but do so in a controllable and versatile way. To set strong baselines, we present two methods for tackling the benchmark. In the first approach, we train specialist locomotion skills using on-policy reinforcement learning methods and combine them with a high-level navigation controller. In the second approach, we distill the specialist skills into a Transformer-based generalist locomotion policy, named Locomotion-Transformer, that can handle various terrains and adjust the robot's gait based on the perceived environment and robot states. Using a custom-built quadruped robot, we demonstrate that our method can complete the course at half the speed of a dog. We hope that our work represents a step towards creating controllers that enable robots to reach animal-level agility.
Solving Diffusion ODEs with Optimal Boundary Conditions for Better Image Super-Resolution
May 24, 2023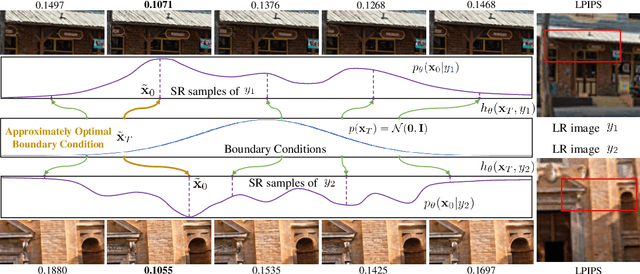
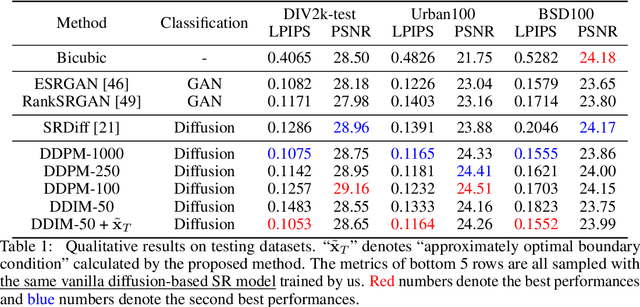
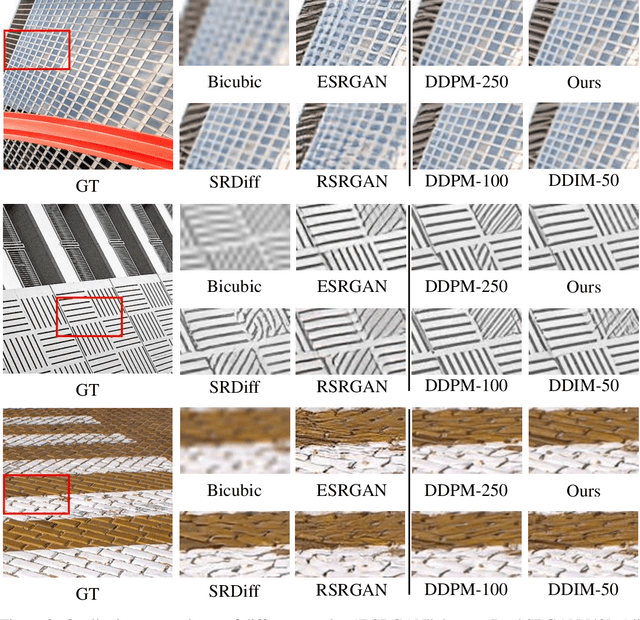
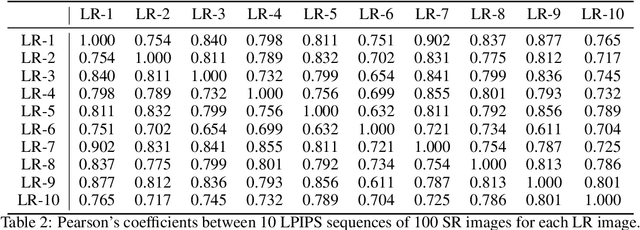
Diffusion models, as a kind of powerful generative model, have given impressive results on image super-resolution (SR) tasks. However, due to the randomness introduced in the reverse process of diffusion models, the performances of diffusion-based SR models are fluctuating at every time of sampling, especially for samplers with few resampled steps. This inherent randomness of diffusion models results in ineffectiveness and instability, making it challenging for users to guarantee the quality of SR results. However, our work takes this randomness as an opportunity: fully analyzing and leveraging it leads to the construction of an effective plug-and-play sampling method that owns the potential to benefit a series of diffusion-based SR methods. More in detail, we propose to steadily sample high-quality SR images from pretrained diffusion-based SR models by solving diffusion ordinary differential equations (diffusion ODEs) with optimal boundary conditions (BCs) and analyze the characteristics between the choices of BCs and their corresponding SR results. Our analysis shows the route to obtain an approximately optimal BC via an efficient exploration in the whole space. The quality of SR results sampled by the proposed method with fewer steps outperforms the quality of results sampled by current methods with randomness from the same pretrained diffusion-based SR model, which means that our sampling method ``boosts'' current diffusion-based SR models without any additional training.
Statistical post-processing of visibility ensemble forecasts
May 24, 2023

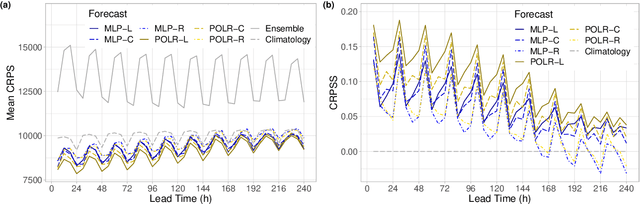
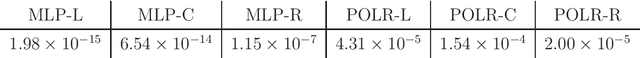
To be able to produce accurate and reliable predictions of visibility has crucial importance in aviation meteorology, as well as in water- and road transportation. Nowadays, several meteorological services provide ensemble forecasts of visibility; however, the skill, and reliability of visibility predictions are far reduced compared to other variables, such as temperature or wind speed. Hence, some form of calibration is strongly advised, which usually means estimation of the predictive distribution of the weather quantity at hand either by parametric or non-parametric approaches, including also machine learning-based techniques. As visibility observations - according to the suggestion of the World Meteorological Organization - are usually reported in discrete values, the predictive distribution for this particular variable is a discrete probability law, hence calibration can be reduced to a classification problem. Based on visibility ensemble forecasts of the European Centre for Medium-Range Weather Forecasts covering two slightly overlapping domains in Central and Western Europe and two different time periods, we investigate the predictive performance of locally, semi-locally and regionally trained proportional odds logistic regression (POLR) and multilayer perceptron (MLP) neural network classifiers. We show that while climatological forecasts outperform the raw ensemble by a wide margin, post-processing results in further substantial improvement in forecast skill and in general, POLR models are superior to their MLP counterparts.
HARD: Hard Augmentations for Robust Distillation
May 24, 2023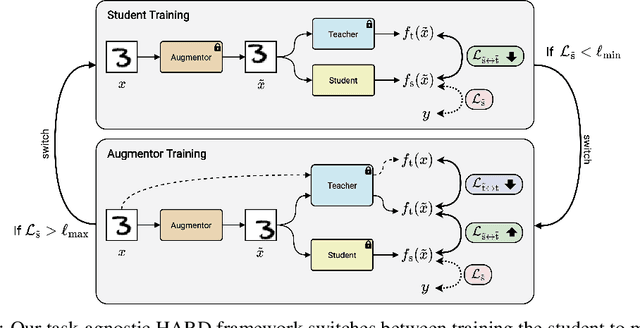
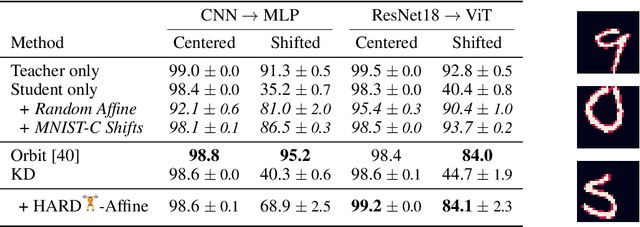
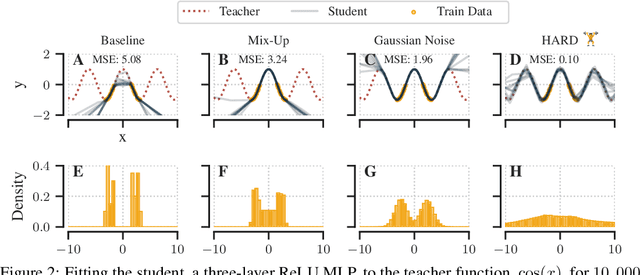
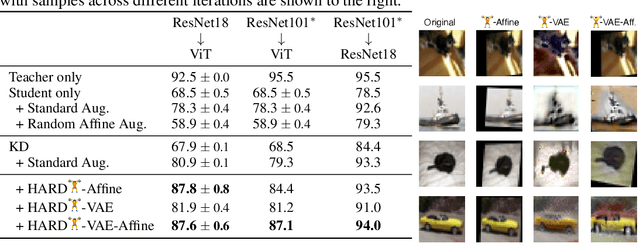
Knowledge distillation (KD) is a simple and successful method to transfer knowledge from a teacher to a student model solely based on functional activity. However, current KD has a few shortcomings: it has recently been shown that this method is unsuitable to transfer simple inductive biases like shift equivariance, struggles to transfer out of domain generalization, and optimization time is magnitudes longer compared to default non-KD model training. To improve these aspects of KD, we propose Hard Augmentations for Robust Distillation (HARD), a generally applicable data augmentation framework, that generates synthetic data points for which the teacher and the student disagree. We show in a simple toy example that our augmentation framework solves the problem of transferring simple equivariances with KD. We then apply our framework in real-world tasks for a variety of augmentation models, ranging from simple spatial transformations to unconstrained image manipulations with a pretrained variational autoencoder. We find that our learned augmentations significantly improve KD performance on in-domain and out-of-domain evaluation. Moreover, our method outperforms even state-of-the-art data augmentations and since the augmented training inputs can be visualized, they offer a qualitative insight into the properties that are transferred from the teacher to the student. Thus HARD represents a generally applicable, dynamically optimized data augmentation technique tailored to improve the generalization and convergence speed of models trained with KD.
Robust Sparse Mean Estimation via Incremental Learning
May 24, 2023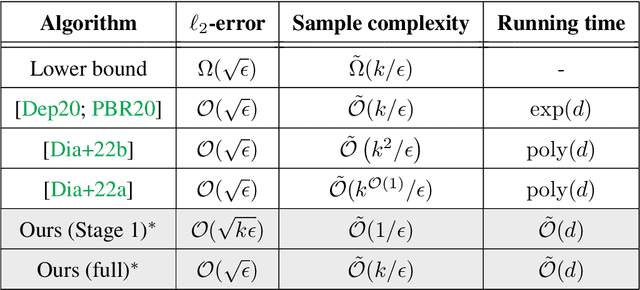
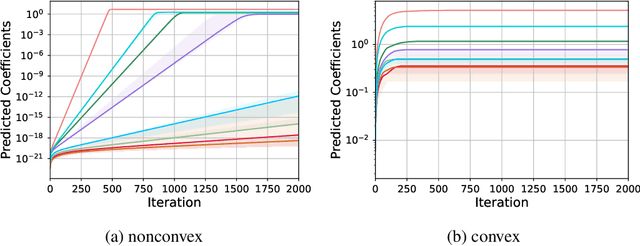
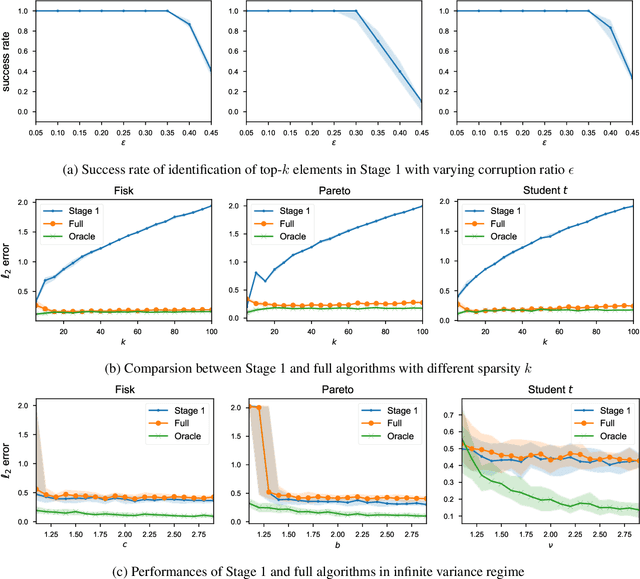
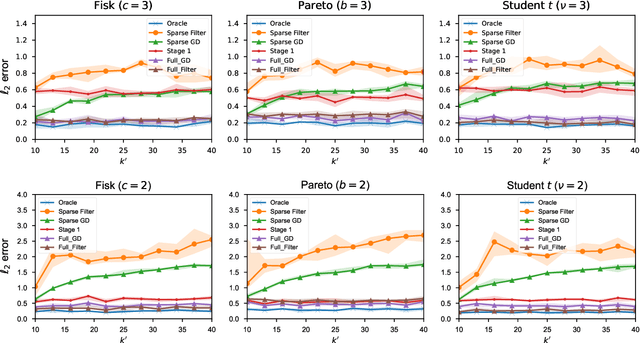
In this paper, we study the problem of robust sparse mean estimation, where the goal is to estimate a $k$-sparse mean from a collection of partially corrupted samples drawn from a heavy-tailed distribution. Existing estimators face two critical challenges in this setting. First, they are limited by a conjectured computational-statistical tradeoff, implying that any computationally efficient algorithm needs $\tilde\Omega(k^2)$ samples, while its statistically-optimal counterpart only requires $\tilde O(k)$ samples. Second, the existing estimators fall short of practical use as they scale poorly with the ambient dimension. This paper presents a simple mean estimator that overcomes both challenges under moderate conditions: it runs in near-linear time and memory (both with respect to the ambient dimension) while requiring only $\tilde O(k)$ samples to recover the true mean. At the core of our method lies an incremental learning phenomenon: we introduce a simple nonconvex framework that can incrementally learn the top-$k$ nonzero elements of the mean while keeping the zero elements arbitrarily small. Unlike existing estimators, our method does not need any prior knowledge of the sparsity level $k$. We prove the optimality of our estimator by providing a matching information-theoretic lower bound. Finally, we conduct a series of simulations to corroborate our theoretical findings. Our code is available at https://github.com/huihui0902/Robust_mean_estimation.
On Correlated Knowledge Distillation for Monitoring Human Pose with Radios
May 24, 2023


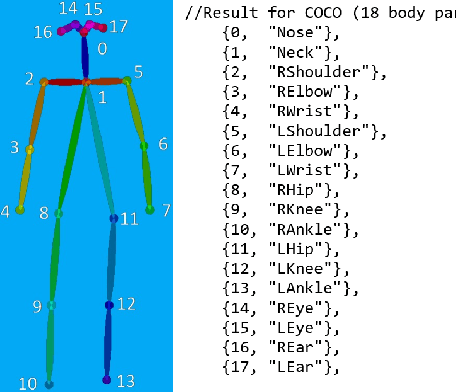
In this work, we propose and develop a simple experimental testbed to study the feasibility of a novel idea by coupling radio frequency (RF) sensing technology with Correlated Knowledge Distillation (CKD) theory towards designing lightweight, near real-time and precise human pose monitoring systems. The proposed CKD framework transfers and fuses pose knowledge from a robust "Teacher" model to a parameterized "Student" model, which can be a promising technique for obtaining accurate yet lightweight pose estimates. To assure its efficacy, we implemented CKD for distilling logits in our integrated Software Defined Radio (SDR)-based experimental setup and investigated the RF-visual signal correlation. Our CKD-RF sensing technique is characterized by two modes -- a camera-fed Teacher Class Network (e.g., images, videos) with an SDR-fed Student Class Network (e.g., RF signals). Specifically, our CKD model trains a dual multi-branch teacher and student network by distilling and fusing knowledge bases. The resulting CKD models are then subsequently used to identify the multimodal correlation and teach the student branch in reverse. Instead of simply aggregating their learnings, CKD training comprised multiple parallel transformations with the two domains, i.e., visual images and RF signals. Once trained, our CKD model can efficiently preserve privacy and utilize the multimodal correlated logits from the two different neural networks for estimating poses without using visual signals/video frames (by using only the RF signals).
KNN-LM Does Not Improve Open-ended Text Generation
May 24, 2023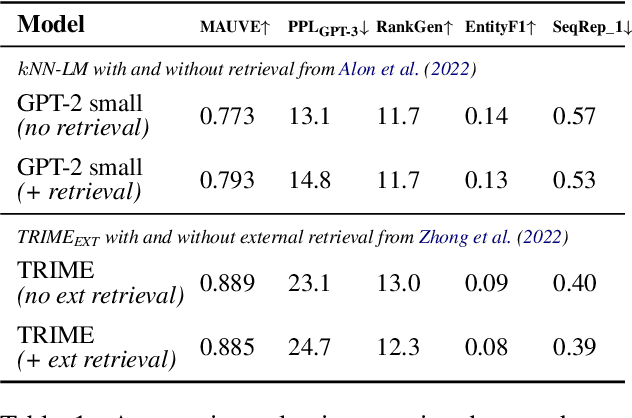
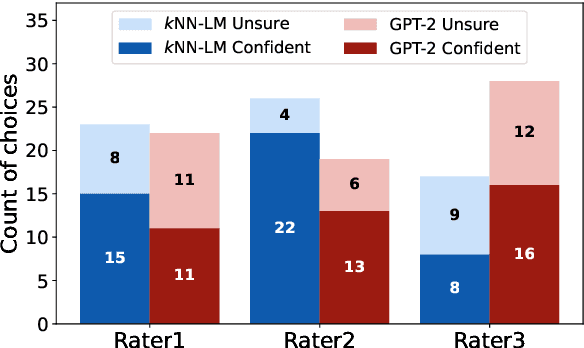
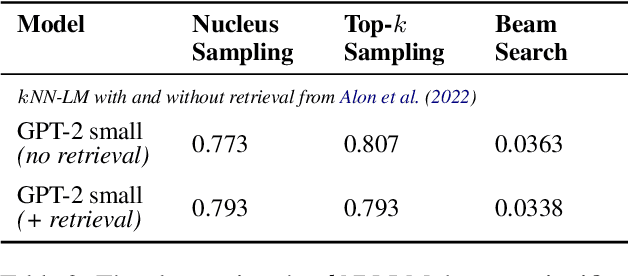
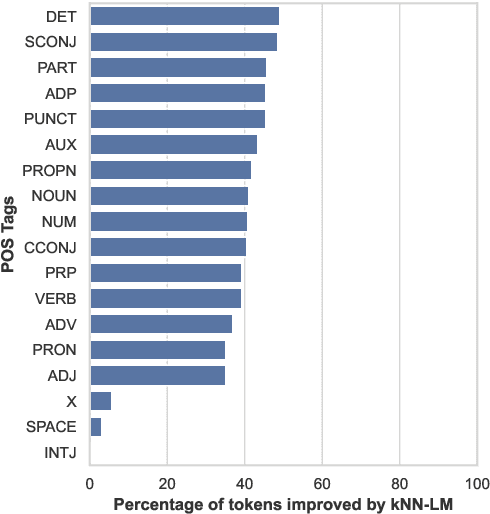
In this paper, we study the generation quality of interpolation-based retrieval-augmented language models (LMs). These methods, best exemplified by the KNN-LM, interpolate the LM's predicted distribution of the next word with a distribution formed from the most relevant retrievals for a given prefix. While the KNN-LM and related methods yield impressive decreases in perplexity, we discover that they do not exhibit corresponding improvements in open-ended generation quality, as measured by both automatic evaluation metrics (e.g., MAUVE) and human evaluations. Digging deeper, we find that interpolating with a retrieval distribution actually increases perplexity compared to a baseline Transformer LM for the majority of tokens in the WikiText-103 test set, even though the overall perplexity is lower due to a smaller number of tokens for which perplexity dramatically decreases after interpolation. However, when decoding a long sequence at inference time, significant improvements on this smaller subset of tokens are washed out by slightly worse predictions on most tokens. Furthermore, we discover that the entropy of the retrieval distribution increases faster than that of the base LM as the generated sequence becomes longer, which indicates that retrieval is less reliable when using model-generated text as queries (i.e., is subject to exposure bias). We hope that our analysis spurs future work on improved decoding algorithms and interpolation strategies for retrieval-augmented language models.
AaKOS: Aspect-adaptive Knowledge-based Opinion Summarization
May 26, 2023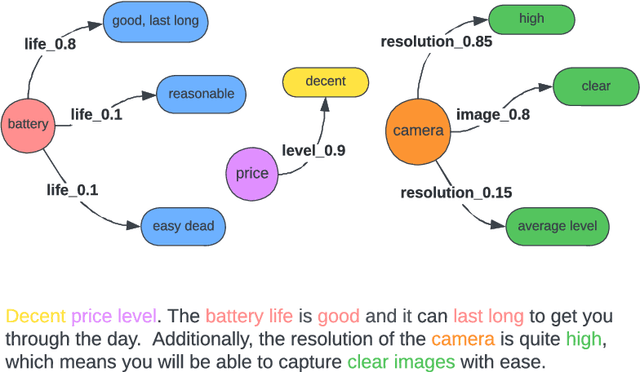

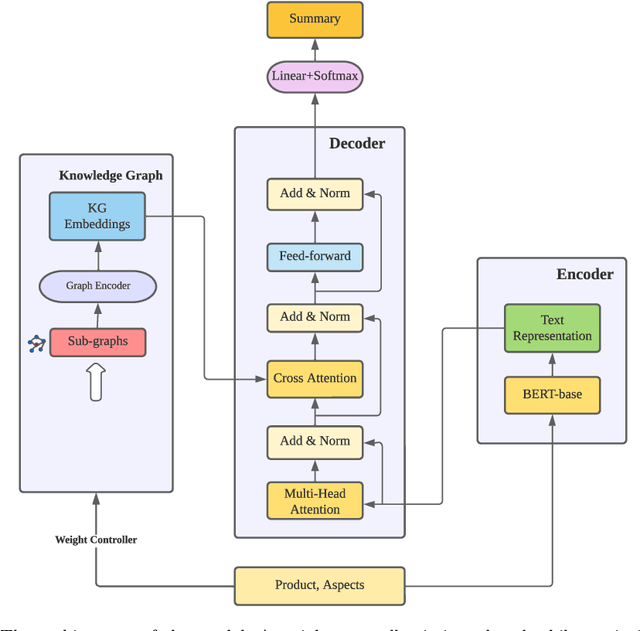
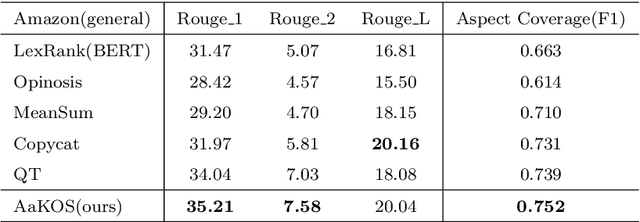
The rapid growth of information on the Internet has led to an overwhelming amount of opinions and comments on various activities, products, and services. This makes it difficult and time-consuming for users to process all the available information when making decisions. Text summarization, a Natural Language Processing (NLP) task, has been widely explored to help users quickly retrieve relevant information by generating short and salient content from long or multiple documents. Recent advances in pre-trained language models, such as ChatGPT, have demonstrated the potential of Large Language Models (LLMs) in text generation. However, LLMs require massive amounts of data and resources and are challenging to implement as offline applications. Furthermore, existing text summarization approaches often lack the ``adaptive" nature required to capture diverse aspects in opinion summarization, which is particularly detrimental to users with specific requirements or preferences. In this paper, we propose an Aspect-adaptive Knowledge-based Opinion Summarization model for product reviews, which effectively captures the adaptive nature required for opinion summarization. The model generates aspect-oriented summaries given a set of reviews for a particular product, efficiently providing users with useful information on specific aspects they are interested in, ensuring the generated summaries are more personalized and informative. Extensive experiments have been conducted using real-world datasets to evaluate the proposed model. The results demonstrate that our model outperforms state-of-the-art approaches and is adaptive and efficient in generating summaries that focus on particular aspects, enabling users to make well-informed decisions and catering to their diverse interests and preferences.
Robust Lane Detection through Self Pre-training with Masked Sequential Autoencoders and Fine-tuning with Customized PolyLoss
May 26, 2023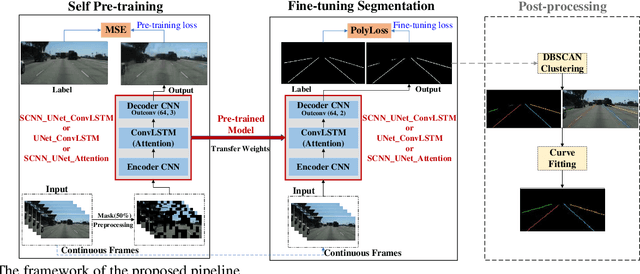
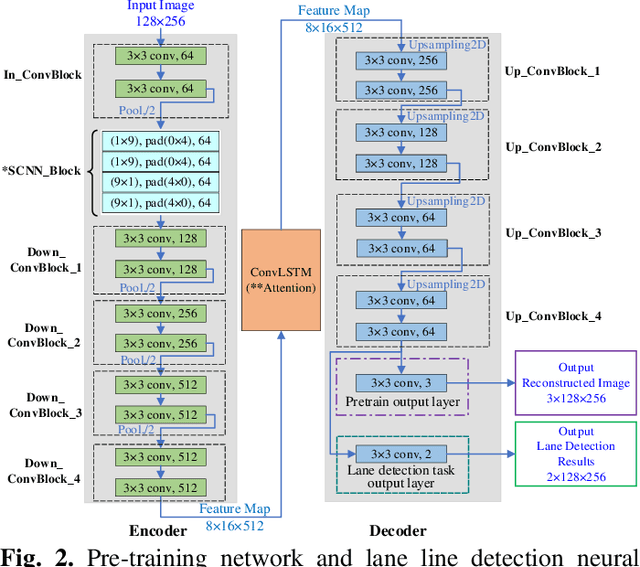

Lane detection is crucial for vehicle localization which makes it the foundation for automated driving and many intelligent and advanced driving assistant systems. Available vision-based lane detection methods do not make full use of the valuable features and aggregate contextual information, especially the interrelationships between lane lines and other regions of the images in continuous frames. To fill this research gap and upgrade lane detection performance, this paper proposes a pipeline consisting of self pre-training with masked sequential autoencoders and fine-tuning with customized PolyLoss for the end-to-end neural network models using multi-continuous image frames. The masked sequential autoencoders are adopted to pre-train the neural network models with reconstructing the missing pixels from a random masked image as the objective. Then, in the fine-tuning segmentation phase where lane detection segmentation is performed, the continuous image frames are served as the inputs, and the pre-trained model weights are transferred and further updated using the backpropagation mechanism with customized PolyLoss calculating the weighted errors between the output lane detection results and the labeled ground truth. Extensive experiment results demonstrate that, with the proposed pipeline, the lane detection model performance on both normal and challenging scenes can be advanced beyond the state-of-the-art, delivering the best testing accuracy (98.38%), precision (0.937), and F1-measure (0.924) on the normal scene testing set, together with the best overall accuracy (98.36%) and precision (0.844) in the challenging scene test set, while the training time can be substantially shortened.