 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
M-L2O: Towards Generalizable Learning-to-Optimize by Test-Time Fast Self-Adaptation
Feb 28, 2023
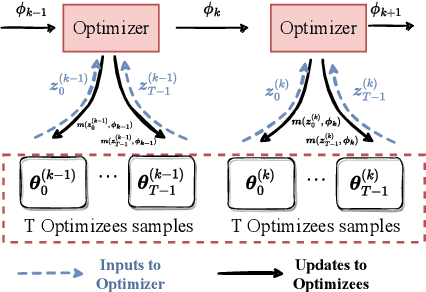
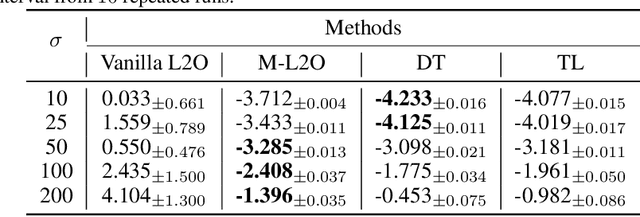
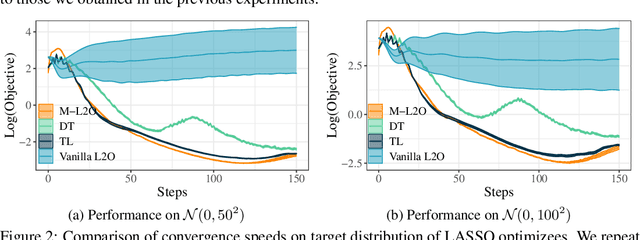
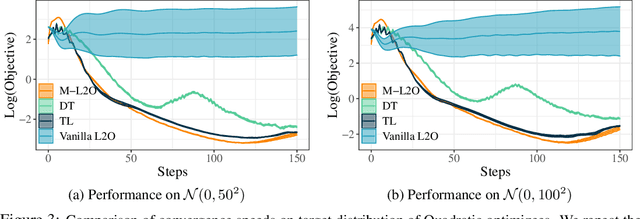
Learning to Optimize (L2O) has drawn increasing attention as it often remarkably accelerates the optimization procedure of complex tasks by ``overfitting" specific task type, leading to enhanced performance compared to analytical optimizers. Generally, L2O develops a parameterized optimization method (i.e., ``optimizer") by learning from solving sample problems. This data-driven procedure yields L2O that can efficiently solve problems similar to those seen in training, that is, drawn from the same ``task distribution". However, such learned optimizers often struggle when new test problems come with a substantially deviation from the training task distribution. This paper investigates a potential solution to this open challenge, by meta-training an L2O optimizer that can perform fast test-time self-adaptation to an out-of-distribution task, in only a few steps. We theoretically characterize the generalization of L2O, and further show that our proposed framework (termed as M-L2O) provably facilitates rapid task adaptation by locating well-adapted initial points for the optimizer weight. Empirical observations on several classic tasks like LASSO and Quadratic, demonstrate that M-L2O converges significantly faster than vanilla L2O with only $5$ steps of adaptation, echoing our theoretical results. Codes are available in https://github.com/VITA-Group/M-L2O.
Using Received Power in Microphone Arrays to Estimate Direction of Arrival
May 04, 2023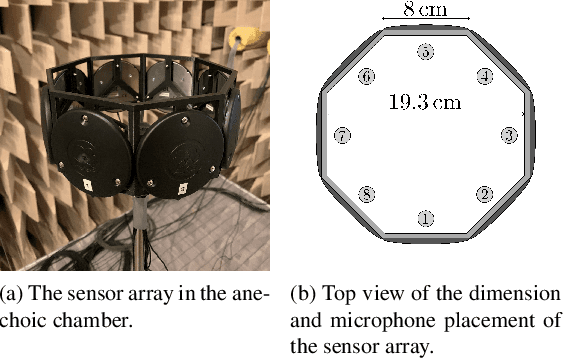
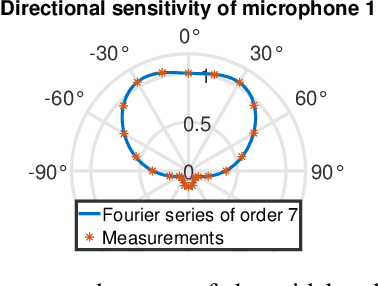
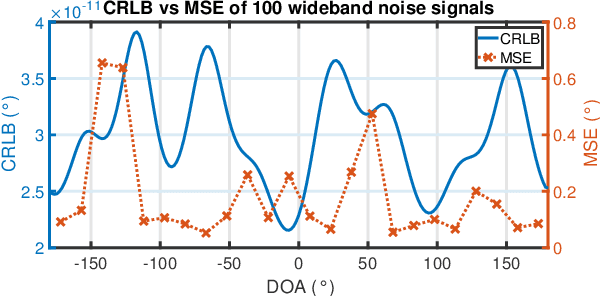
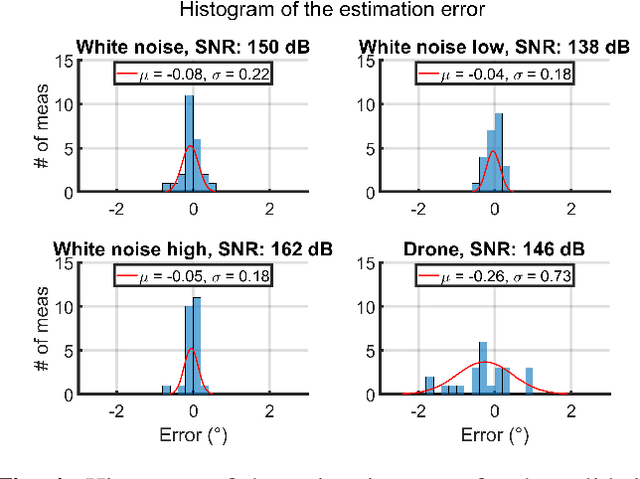
Conventional direction of arrival (DOA) estimators are based on array processing using either time differences or beamforming. The proposed approach is based on the received power at each microphone, which enables simple hardware, low sampling frequency and small arrays. The problem is recast into a linear regression framework where the least squares method applies, and the main drawback is that different sound sources are not readily separable. Our proposed approach is based on a training phase where the directional sensitivity of each microphone element is estimated. This model is then used as a fingerprint of the observed power vector in a real-time estimator. The learned power vector is here modeled by a Fourier series expansion, which enables Cram\'er-Rao lower bound computations. We demonstrate the performance using a circular array with eight microphones with promising results.
Incipient Fault Detection in Power Distribution System: A Time-Frequency Embedded Deep Learning Based Approach
Feb 18, 2023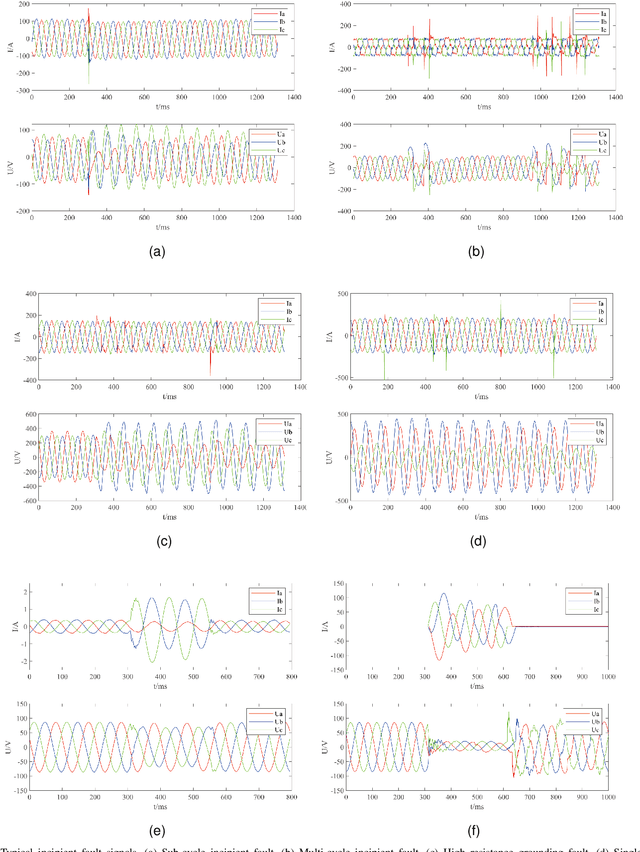
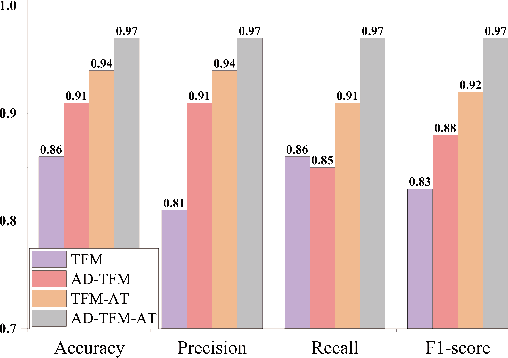
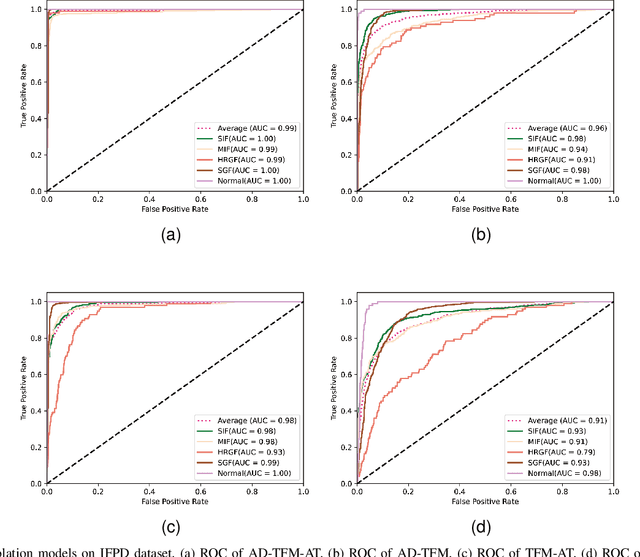
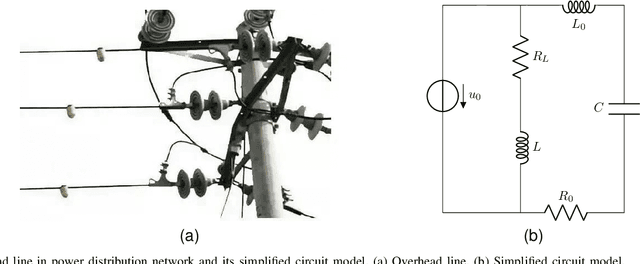
Incipient fault detection in power distribution systems is crucial to improve the reliability of the grid. However, the non-stationary nature and the inadequacy of the training dataset due to the self-recovery of the incipient fault signal, make the incipient fault detection in power distribution systems a great challenge. In this paper, we focus on incipient fault detection in power distribution systems and address the above challenges. In particular, we propose an ADaptive Time-Frequency Memory(AD-TFM) cell by embedding wavelet transform into the Long Short-Term Memory (LSTM), to extract features in time and frequency domain from the non-stationary incipient fault signals.We make scale parameters and translation parameters of wavelet transform learnable to adapt to the dynamic input signals. Based on the stacked AD-TFM cells, we design a recurrent neural network with ATtention mechanism, named AD-TFM-AT model, to detect incipient fault with multi-resolution and multi-dimension analysis. In addition, we propose two data augmentation methods, namely phase switching and temporal sliding, to effectively enlarge the training datasets. Experimental results on two open datasets show that our proposed AD-TFM-AT model and data augmentation methods achieve state-of-the-art (SOTA) performance of incipient fault detection in power distribution system. We also disclose one used dataset logged at State Grid Corporation of China to facilitate future research.
Selective Pre-training for Private Fine-tuning
May 23, 2023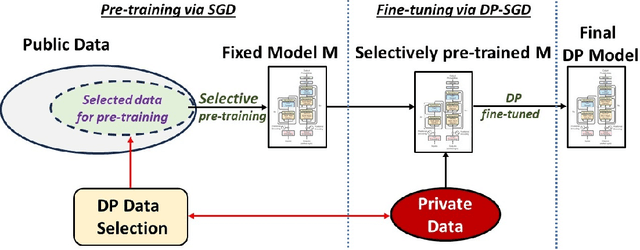
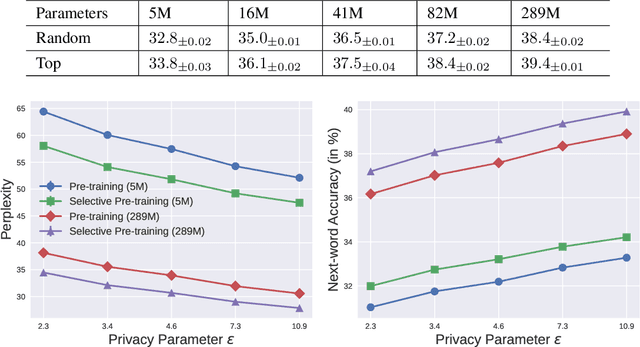
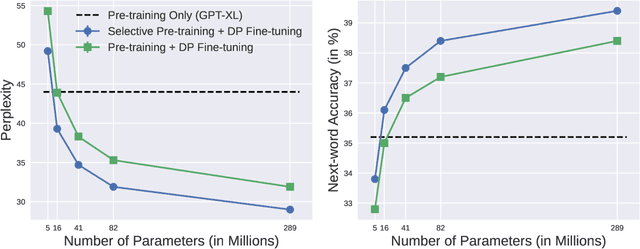
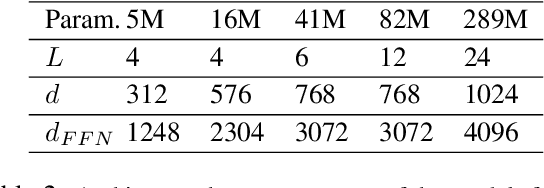
Suppose we want to train text prediction models in email clients or word processors. The models must preserve the privacy of user data and adhere to a specific fixed size to meet memory and inference time requirements. We introduce a generic framework to solve this problem. Specifically, we are given a public dataset $D_\text{pub}$ and a private dataset $D_\text{priv}$ corresponding to a downstream task $T$. How should we pre-train a fixed-size model $M$ on $D_\text{pub}$ and fine-tune it on $D_\text{priv}$ such that performance of $M$ with respect to $T$ is maximized and $M$ satisfies differential privacy with respect to $D_\text{priv}$? We show that pre-training on a {\em subset} of dataset $D_\text{pub}$ that brings the public distribution closer to the private distribution is a crucial ingredient to maximize the transfer learning abilities of $M$ after pre-training, especially in the regimes where model sizes are relatively small. Besides performance improvements, our framework also shows that with careful pre-training and private fine-tuning, {\em smaller models} can match the performance of much larger models, highlighting the promise of differentially private training as a tool for model compression and efficiency.
FActScore: Fine-grained Atomic Evaluation of Factual Precision in Long Form Text Generation
May 23, 2023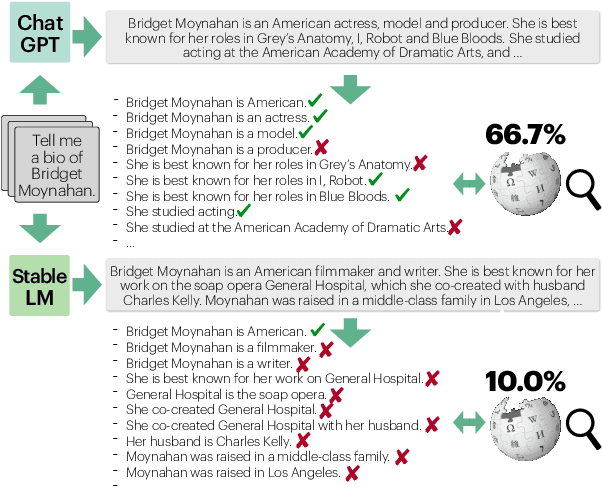

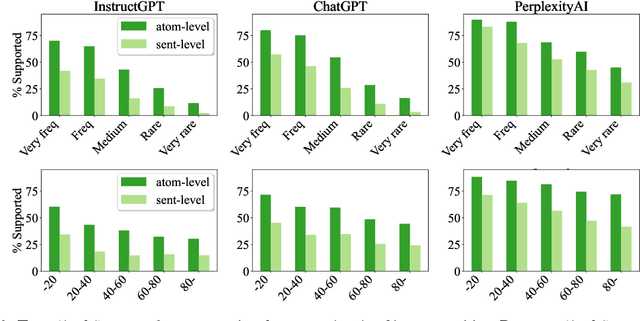
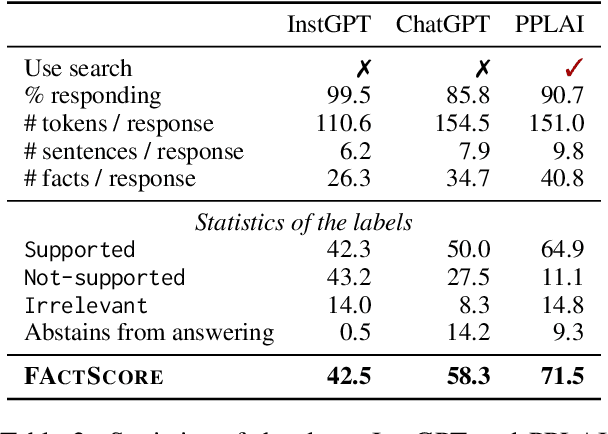
Evaluating the factuality of long-form text generated by large language models (LMs) is non-trivial because (1) generations often contain a mixture of supported and unsupported pieces of information, making binary judgments of quality inadequate, and (2) human evaluation is time-consuming and costly. In this paper, we introduce FActScore (Factual precision in Atomicity Score), a new evaluation that breaks a generation into a series of atomic facts and computes the percentage of atomic facts supported by a reliable knowledge source. We conduct an extensive human evaluation to obtain FActScores of people biographies generated by several state-of-the-art commercial LMs -- InstructGPT, ChatGPT, and the retrieval-augmented PerplexityAI -- and report new analysis demonstrating the need for such a fine-grained score (e.g., ChatGPT only achieves 58%). Since human evaluation is costly, we also introduce an automated model that estimates FActScore, using retrieval and a strong language model, with less than a 2% error rate. Finally, we use this automated metric to evaluate 6,500 generations from a new set of 13 recent LMs that would have cost $26K if evaluated by humans, with various findings: GPT-4 and ChatGPT are more factual than public models, and Vicuna and Alpaca are some of the best public models.
An Improved Variational Approximate Posterior for the Deep Wishart Process
May 23, 2023
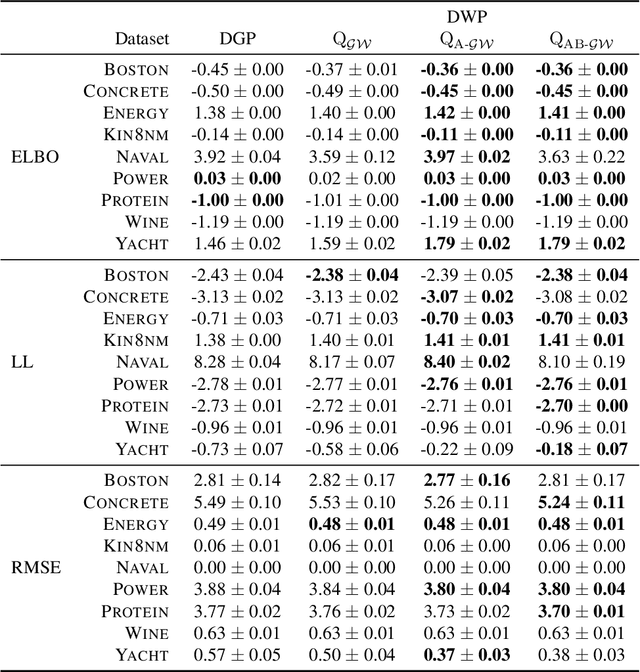
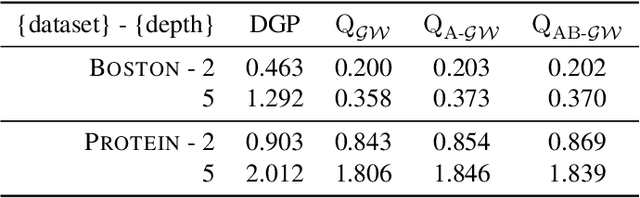
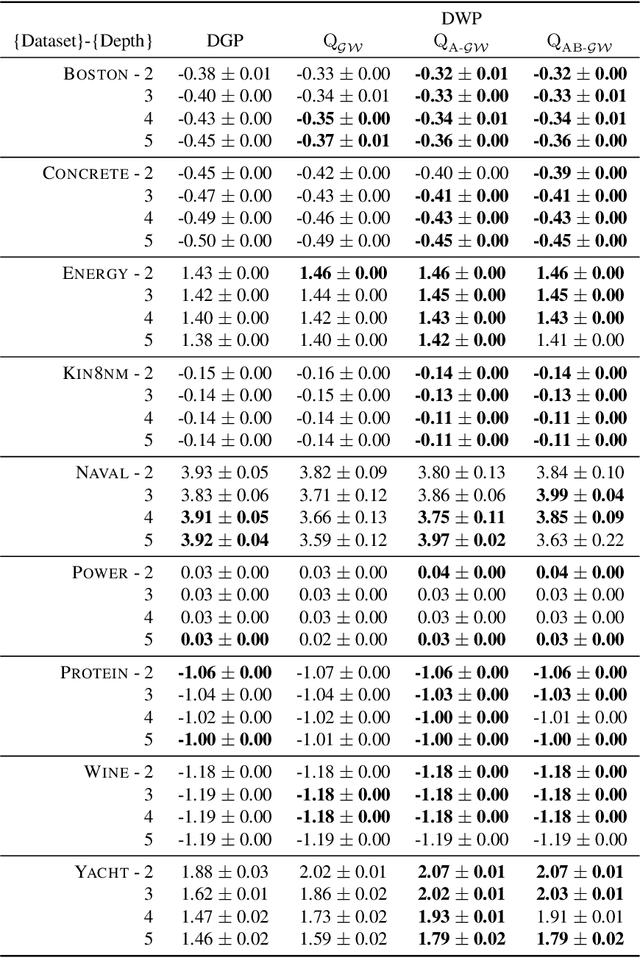
Deep kernel processes are a recently introduced class of deep Bayesian models that have the flexibility of neural networks, but work entirely with Gram matrices. They operate by alternately sampling a Gram matrix from a distribution over positive semi-definite matrices, and applying a deterministic transformation. When the distribution is chosen to be Wishart, the model is called a deep Wishart process (DWP). This particular model is of interest because its prior is equivalent to a deep Gaussian process (DGP) prior, but at the same time it is invariant to rotational symmetries, leading to a simpler posterior distribution. Practical inference in the DWP was made possible in recent work ("A variational approximate posterior for the deep Wishart process" Ober and Aitchison 2021a) where the authors used a generalisation of the Bartlett decomposition of the Wishart distribution as the variational approximate posterior. However, predictive performance in that paper was less impressive than one might expect, with the DWP only beating a DGP on a few of the UCI datasets used for comparison. In this paper, we show that further generalising their distribution to allow linear combinations of rows and columns in the Bartlett decomposition results in better predictive performance, while incurring negligible additional computation cost.
R2H: Building Multimodal Navigation Helpers that Respond to Help
May 23, 2023
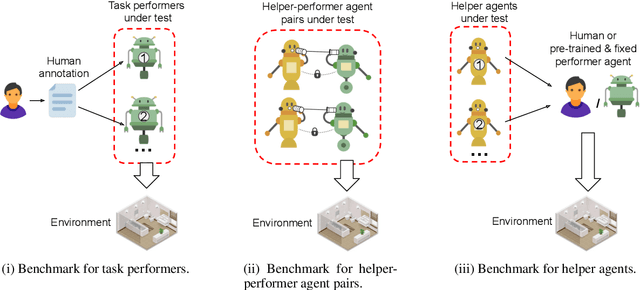
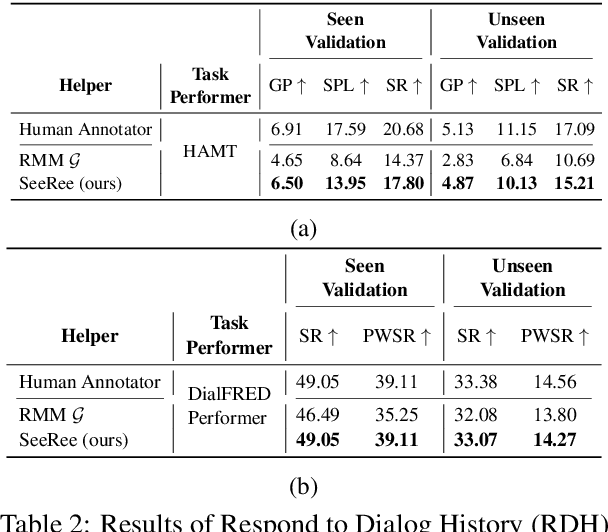
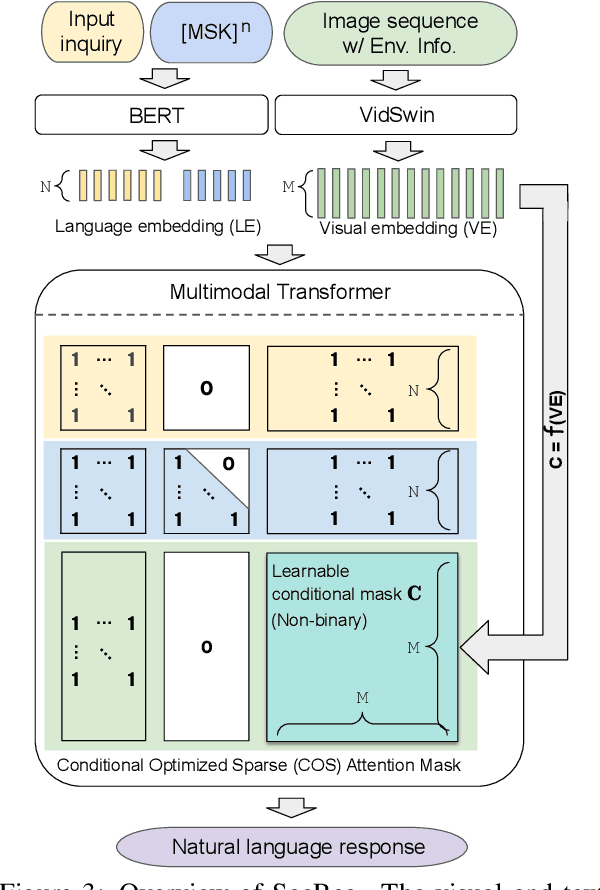
The ability to assist humans during a navigation task in a supportive role is crucial for intelligent agents. Such agents, equipped with environment knowledge and conversational abilities, can guide individuals through unfamiliar terrains by generating natural language responses to their inquiries, grounded in the visual information of their surroundings. However, these multimodal conversational navigation helpers are still underdeveloped. This paper proposes a new benchmark, Respond to Help (R2H), to build multimodal navigation helpers that can respond to help, based on existing dialog-based embodied datasets. R2H mainly includes two tasks: (1) Respond to Dialog History (RDH), which assesses the helper agent's ability to generate informative responses based on a given dialog history, and (2) Respond during Interaction (RdI), which evaluates the helper agent's ability to maintain effective and consistent cooperation with a task performer agent during navigation in real-time. Furthermore, we propose a novel task-oriented multimodal response generation model that can see and respond, named SeeRee, as the navigation helper to guide the task performer in embodied tasks. Through both automatic and human evaluations, we show that SeeRee produces more effective and informative responses than baseline methods in assisting the task performer with different navigation tasks. Project website: https://sites.google.com/view/respond2help/home.
FluentSpeech: Stutter-Oriented Automatic Speech Editing with Context-Aware Diffusion Models
May 23, 2023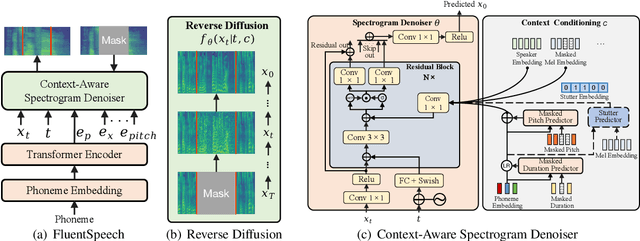
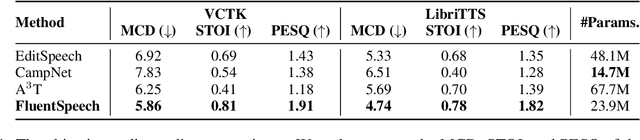
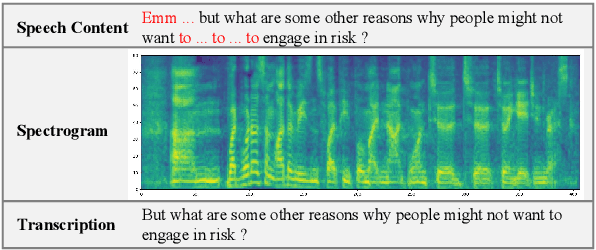
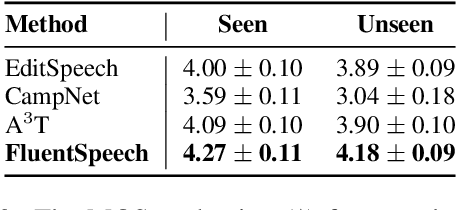
Stutter removal is an essential scenario in the field of speech editing. However, when the speech recording contains stutters, the existing text-based speech editing approaches still suffer from: 1) the over-smoothing problem in the edited speech; 2) lack of robustness due to the noise introduced by stutter; 3) to remove the stutters, users are required to determine the edited region manually. To tackle the challenges in stutter removal, we propose FluentSpeech, a stutter-oriented automatic speech editing model. Specifically, 1) we propose a context-aware diffusion model that iteratively refines the modified mel-spectrogram with the guidance of context features; 2) we introduce a stutter predictor module to inject the stutter information into the hidden sequence; 3) we also propose a stutter-oriented automatic speech editing (SASE) dataset that contains spontaneous speech recordings with time-aligned stutter labels to train the automatic stutter localization model. Experimental results on VCTK and LibriTTS datasets demonstrate that our model achieves state-of-the-art performance on speech editing. Further experiments on our SASE dataset show that FluentSpeech can effectively improve the fluency of stuttering speech in terms of objective and subjective metrics. Code and audio samples can be found at https://github.com/Zain-Jiang/Speech-Editing-Toolkit.
Learning from demonstrations: An intuitive VR environment for imitation learning of construction robots
May 23, 2023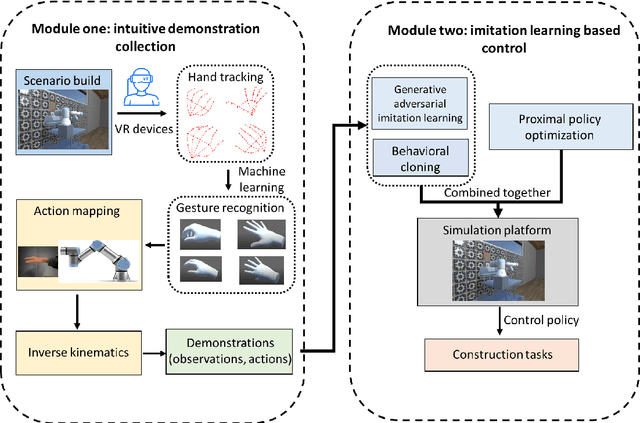

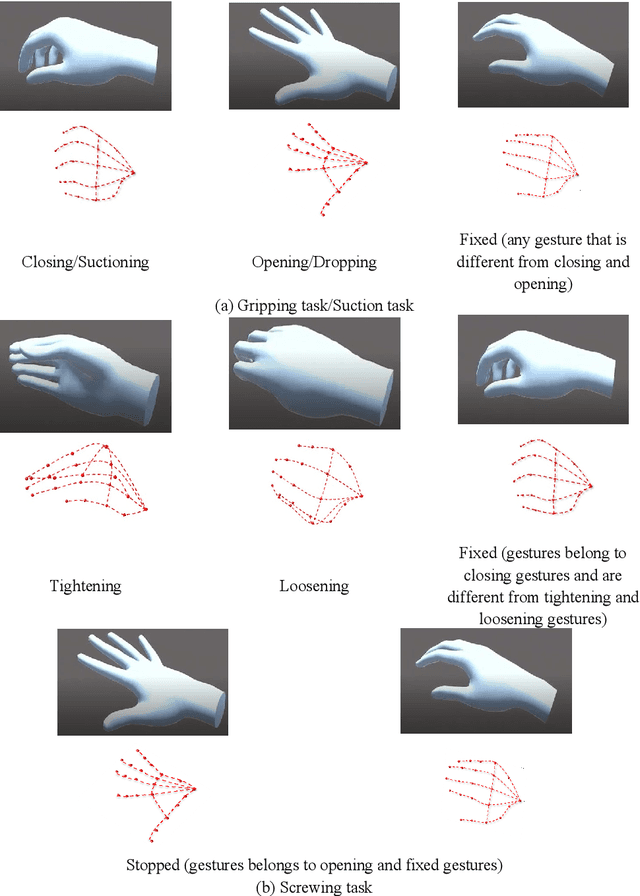
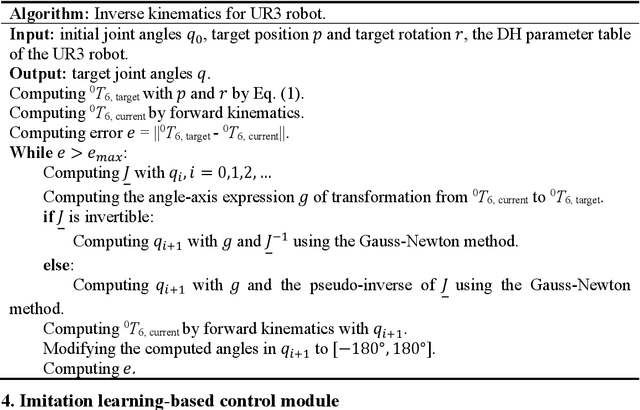
Construction robots are challenging the traditional paradigm of labor intensive and repetitive construction tasks. Present concerns regarding construction robots are focused on their abilities in performing complex tasks consisting of several subtasks and their adaptability to work in unstructured and dynamic construction environments. Imitation learning (IL) has shown advantages in training a robot to imitate expert actions in complex tasks and the policy thereafter generated by reinforcement learning (RL) is more adaptive in comparison with pre-programmed robots. In this paper, we proposed a framework composed of two modules for imitation learning of construction robots. The first module provides an intuitive expert demonstration collection Virtual Reality (VR) platform where a robot will automatically follow the position, rotation, and actions of the expert's hand in real-time, instead of requiring an expert to control the robot via controllers. The second module provides a template for imitation learning using observations and actions recorded in the first module. In the second module, Behavior Cloning (BC) is utilized for pre-training, Generative Adversarial Imitation Learning (GAIL) and Proximal Policy Optimization (PPO) are combined to achieve a trade-off between the strength of imitation vs. exploration. Results show that imitation learning, especially when combined with PPO, could significantly accelerate training in limited training steps and improve policy performance.
IfQA: A Dataset for Open-domain Question Answering under Counterfactual Presuppositions
May 23, 2023
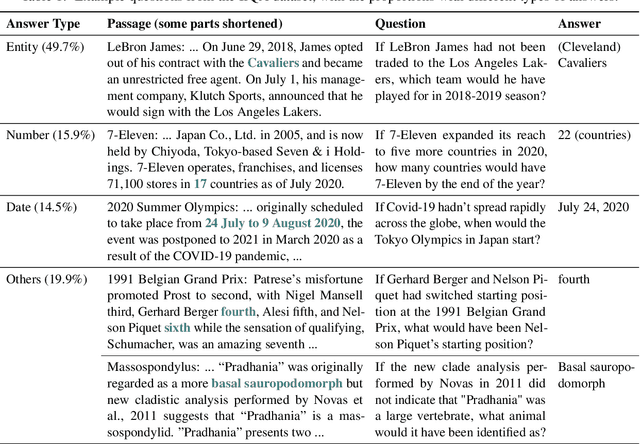

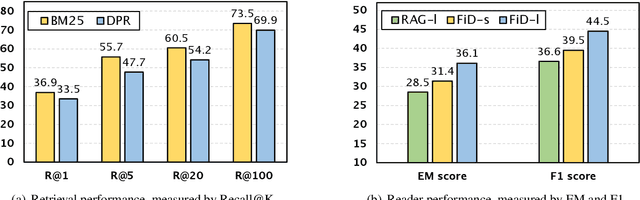
Although counterfactual reasoning is a fundamental aspect of intelligence, the lack of large-scale counterfactual open-domain question-answering (QA) benchmarks makes it difficult to evaluate and improve models on this ability. To address this void, we introduce the first such dataset, named IfQA, where each question is based on a counterfactual presupposition via an "if" clause. For example, if Los Angeles was on the east coast of the U.S., what would be the time difference between Los Angeles and Paris? Such questions require models to go beyond retrieving direct factual knowledge from the Web: they must identify the right information to retrieve and reason about an imagined situation that may even go against the facts built into their parameters. The IfQA dataset contains over 3,800 questions that were annotated annotated by crowdworkers on relevant Wikipedia passages. Empirical analysis reveals that the IfQA dataset is highly challenging for existing open-domain QA methods, including supervised retrieve-then-read pipeline methods (EM score 36.2), as well as recent few-shot approaches such as chain-of-thought prompting with GPT-3 (EM score 27.4). The unique challenges posed by the IfQA benchmark will push open-domain QA research on both retrieval and counterfactual reasoning fronts.