 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
TR3D: Towards Real-Time Indoor 3D Object Detection
Feb 06, 2023
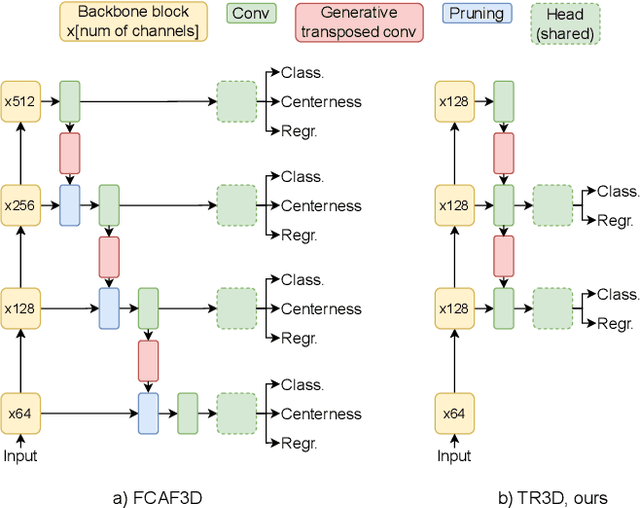
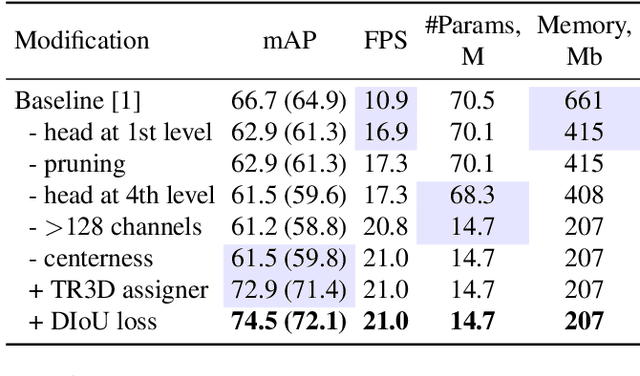

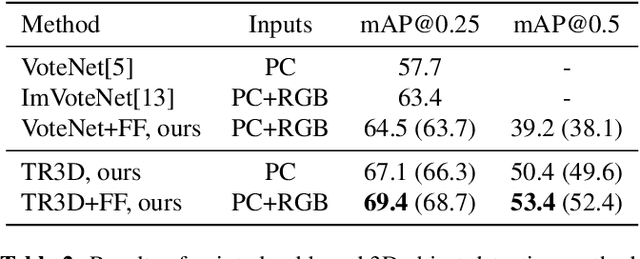
Recently, sparse 3D convolutions have changed 3D object detection. Performing on par with the voting-based approaches, 3D CNNs are memory-efficient and scale to large scenes better. However, there is still room for improvement. With a conscious, practice-oriented approach to problem-solving, we analyze the performance of such methods and localize the weaknesses. Applying modifications that resolve the found issues one by one, we end up with TR3D: a fast fully-convolutional 3D object detection model trained end-to-end, that achieves state-of-the-art results on the standard benchmarks, ScanNet v2, SUN RGB-D, and S3DIS. Moreover, to take advantage of both point cloud and RGB inputs, we introduce an early fusion of 2D and 3D features. We employ our fusion module to make conventional 3D object detection methods multimodal and demonstrate an impressive boost in performance. Our model with early feature fusion, which we refer to as TR3D+FF, outperforms existing 3D object detection approaches on the SUN RGB-D dataset. Overall, besides being accurate, both TR3D and TR3D+FF models are lightweight, memory-efficient, and fast, thereby marking another milestone on the way toward real-time 3D object detection. Code is available at https://github.com/SamsungLabs/tr3d .
Bringing AI to the edge: A formal M&S specification to deploy effective IoT architectures
May 11, 2023The Internet of Things is transforming our society, providing new services that improve the quality of life and resource management. These applications are based on ubiquitous networks of multiple distributed devices, with limited computing resources and power, capable of collecting and storing data from heterogeneous sources in real-time. To avoid network saturation and high delays, new architectures such as fog computing are emerging to bring computing infrastructure closer to data sources. Additionally, new data centers are needed to provide real-time Big Data and data analytics capabilities at the edge of the network, where energy efficiency needs to be considered to ensure a sustainable and effective deployment in areas of human activity. In this research, we present an IoT model based on the principles of Model-Based Systems Engineering defined using the Discrete Event System Specification formalism. The provided mathematical formalism covers the description of the entire architecture, from IoT devices to the processing units in edge data centers. Our work includes the location-awareness of user equipment, network, and computing infrastructures to optimize federated resource management in terms of delay and power consumption. We present an effective framework to assist the dimensioning and the dynamic operation of IoT data stream analytics applications, demonstrating our contributions through a driving assistance use case based on real traces and data.
Covariate-guided Bayesian mixture model for multivariate time series
Jan 03, 2023With rapid development of techniques to measure brain activity and structure, statistical methods for analyzing modern brain-imaging play an important role in the advancement of science. Imaging data that measure brain function are usually multivariate time series and are heterogeneous across both imaging sources and subjects, which lead to various statistical and computational challenges. In this paper, we propose a group-based method to cluster a collection of multivariate time series via a Bayesian mixture of smoothing splines. Our method assumes each multivariate time series is a mixture of multiple components with different mixing weights. Time-independent covariates are assumed to be associated with the mixture components and are incorporated via logistic weights of a mixture-of-experts model. We formulate this approach under a fully Bayesian framework using Gibbs sampling where the number of components is selected based on a deviance information criterion. The proposed method is compared to existing methods via simulation studies and is applied to a study on functional near-infrared spectroscopy (fNIRS), which aims to understand infant emotional reactivity and recovery from stress. The results reveal distinct patterns of brain activity, as well as associations between these patterns and selected covariates.
Analysing Biomedical Knowledge Graphs using Prime Adjacency Matrices
May 17, 2023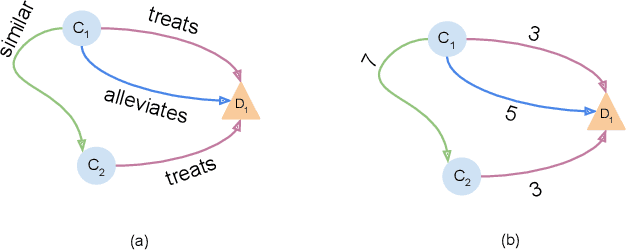
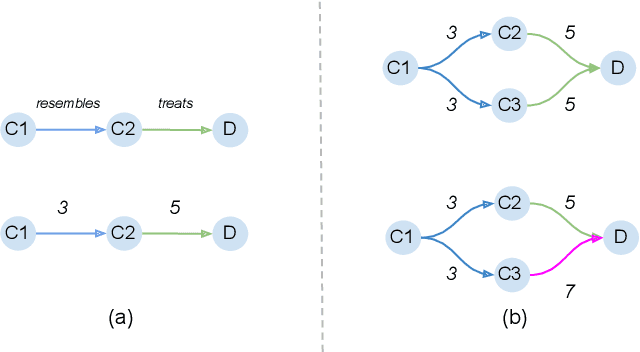
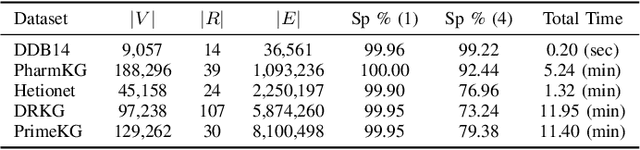
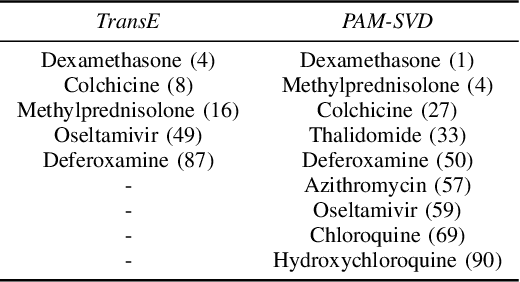
Most phenomena related to biomedical tasks are inherently complex, and in many cases, are expressed as signals on biomedical Knowledge Graphs (KGs). In this work, we introduce the use of a new representation framework, the Prime Adjacency Matrix (PAM) for biomedical KGs, which allows for very efficient network analysis. PAM utilizes prime numbers to enable representing the whole KG with a single adjacency matrix and the fast computation of multiple properties of the network. We illustrate the applicability of the framework in the biomedical domain by working on different biomedical knowledge graphs and by providing two case studies: one on drug-repurposing for COVID-19 and one on important metapath extraction. We show that we achieve better results than the original proposed workflows, using very simple methods that require no training, in considerably less time.
Low Complexity Detection of Spatial Modulation Aided OTFS in Doubly-Selective Channels
May 17, 2023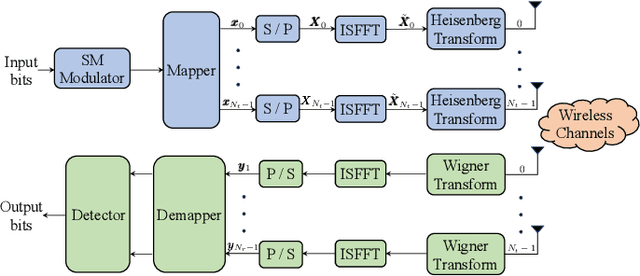
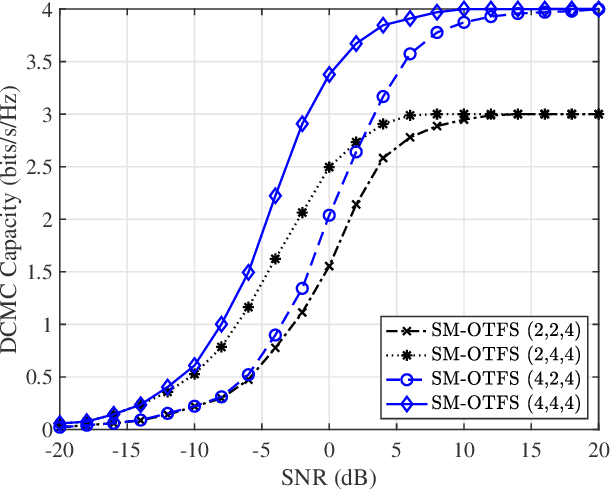
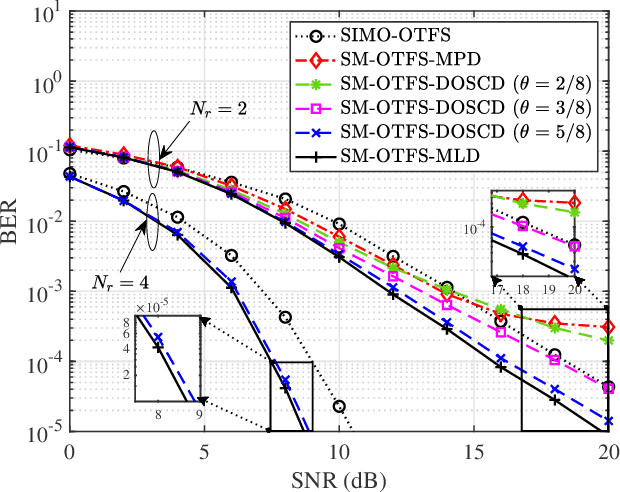
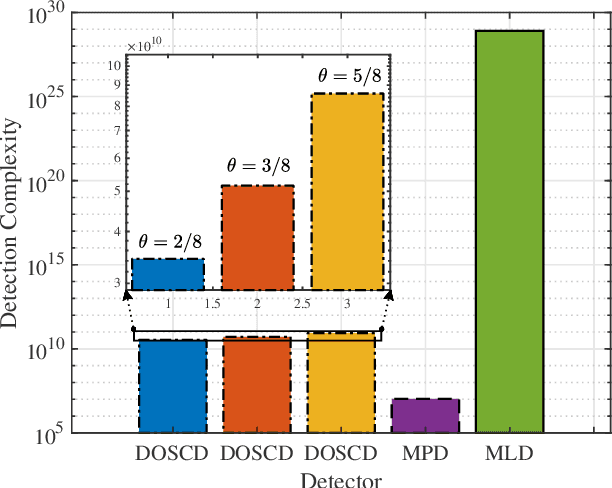
A spatial modulation-aided orthogonal time frequency space (SM-OTFS) scheme is proposed for high-Doppler scenarios, which relies on a low-complexity distance-based detection algorithm. We first derive the delay-Doppler (DD) domain input-output relationship of our SM-OTFS system by exploiting an SM mapper, followed by characterizing the doubly-selective channels considered. Then we propose a distance-based ordering subspace check detector (DOSCD) exploiting the \emph{a priori} information of the transmit symbol vector. Moreover, we derive the discrete-input continuous-output memoryless channel (DCMC) capacity of the system. Finally, our simulation results demonstrate that the proposed SM-OTFS system outperforms the conventional single-input-multiple-output (SIMO)-OTFS system, and that the DOSCD conceived is capable of striking an attractive bit error ratio (BER) vs. complexity trade-off.
Learning to Reason and Memorize with Self-Notes
May 01, 2023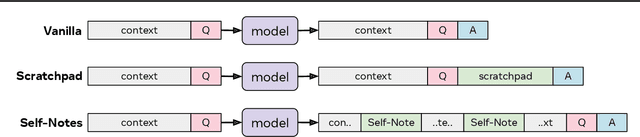
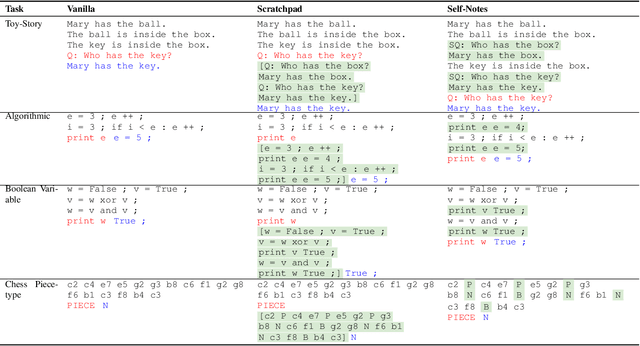
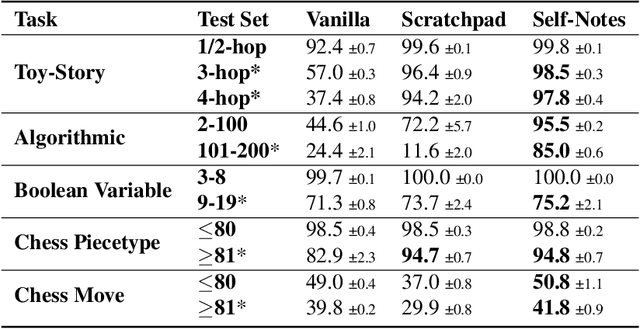
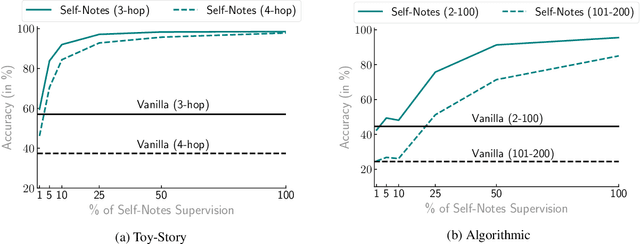
Large language models have been shown to struggle with limited context memory and multi-step reasoning. We propose a simple method for solving both of these problems by allowing the model to take Self-Notes. Unlike recent scratchpad approaches, the model can deviate from the input context at any time to explicitly think. This allows the model to recall information and perform reasoning on the fly as it reads the context, thus extending its memory and enabling multi-step reasoning. Our experiments on multiple tasks demonstrate that our method can successfully generalize to longer and more complicated instances from their training setup by taking Self-Notes at inference time.
Data Encoding For Healthcare Data Democratisation and Information Leakage Prevention
May 05, 2023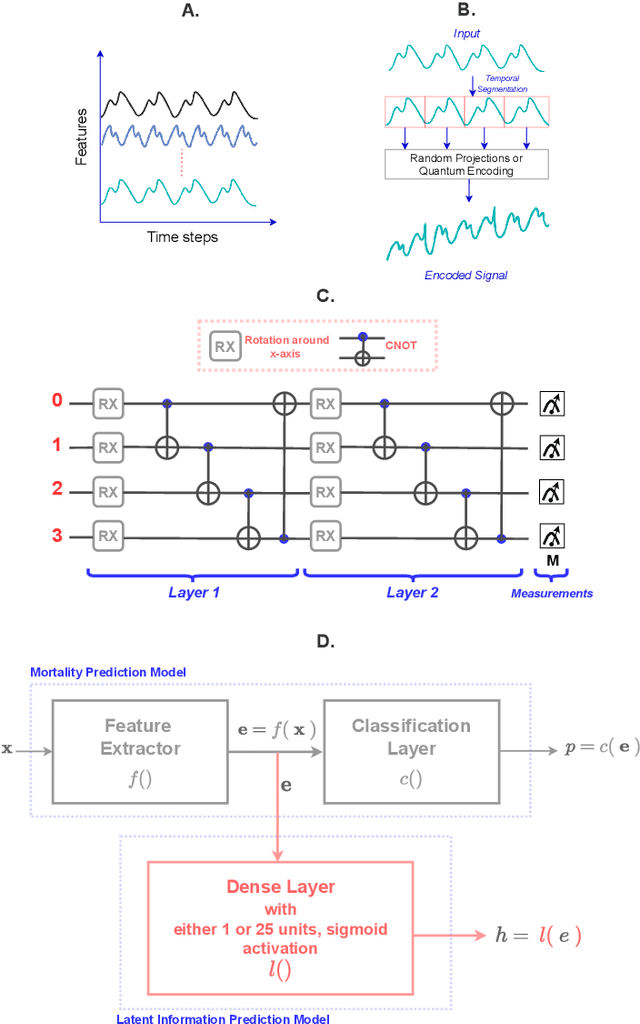

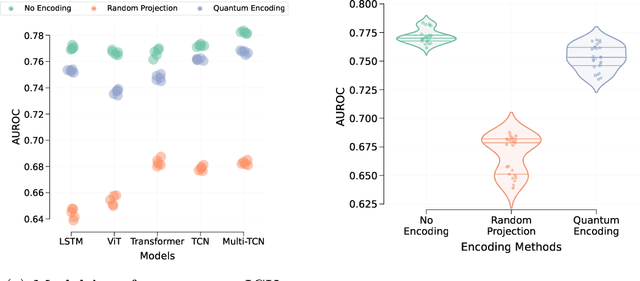
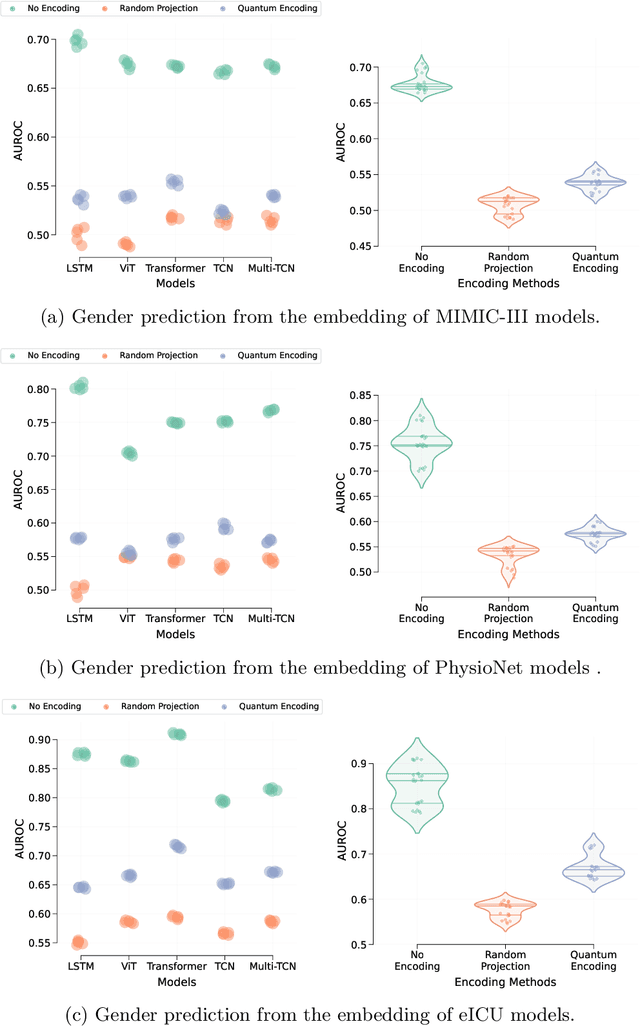
The lack of data democratization and information leakage from trained models hinder the development and acceptance of robust deep learning-based healthcare solutions. This paper argues that irreversible data encoding can provide an effective solution to achieve data democratization without violating the privacy constraints imposed on healthcare data and clinical models. An ideal encoding framework transforms the data into a new space where it is imperceptible to a manual or computational inspection. However, encoded data should preserve the semantics of the original data such that deep learning models can be trained effectively. This paper hypothesizes the characteristics of the desired encoding framework and then exploits random projections and random quantum encoding to realize this framework for dense and longitudinal or time-series data. Experimental evaluation highlights that models trained on encoded time-series data effectively uphold the information bottleneck principle and hence, exhibit lesser information leakage from trained models.
ML-Based Teaching Systems: A Conceptual Framework
May 12, 2023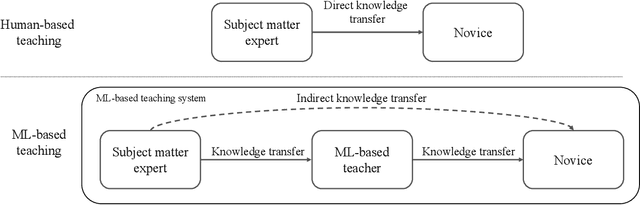
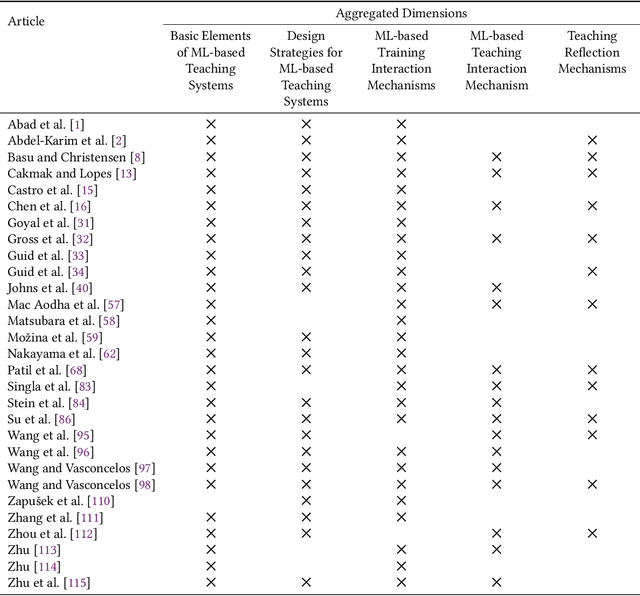
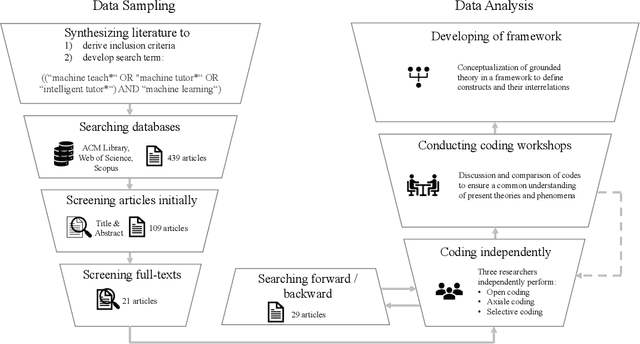
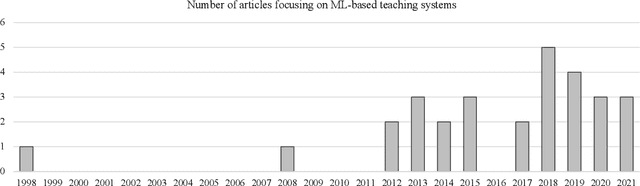
As the shortage of skilled workers continues to be a pressing issue, exacerbated by demographic change, it is becoming a critical challenge for organizations to preserve the knowledge of retiring experts and to pass it on to novices. While this knowledge transfer has traditionally taken place through personal interaction, it lacks scalability and requires significant resources and time. IT-based teaching systems have addressed this scalability issue, but their development is still tedious and time-consuming. In this work, we investigate the potential of machine learning (ML) models to facilitate knowledge transfer in an organizational context, leading to more cost-effective IT-based teaching systems. Through a systematic literature review, we examine key concepts, themes, and dimensions to better understand and design ML-based teaching systems. To do so, we capture and consolidate the capabilities of ML models in IT-based teaching systems, inductively analyze relevant concepts in this context, and determine their interrelationships. We present our findings in the form of a review of the key concepts, themes, and dimensions to understand and inform on ML-based teaching systems. Building on these results, our work contributes to research on computer-supported cooperative work by conceptualizing how ML-based teaching systems can preserve expert knowledge and facilitate its transfer from SMEs to human novices. In this way, we shed light on this emerging subfield of human-computer interaction and serve to build an interdisciplinary research agenda.
Pseudo channel reciprocity in FDD satellite channels
May 02, 2023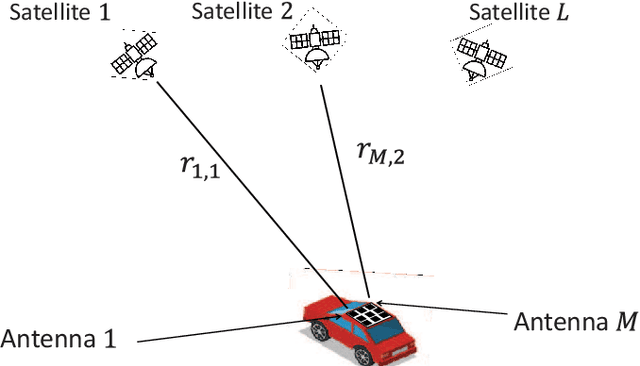
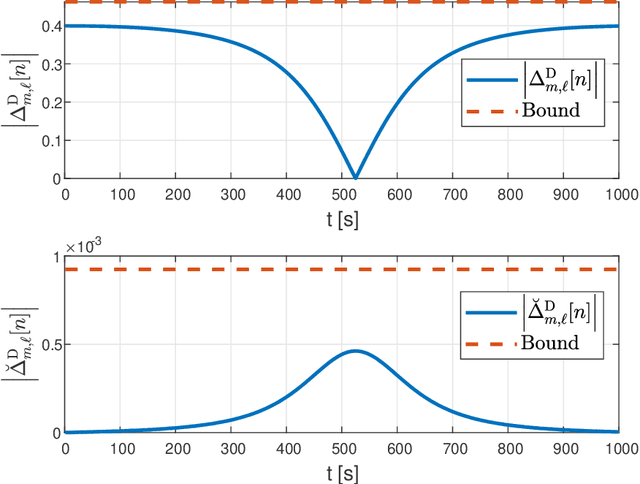
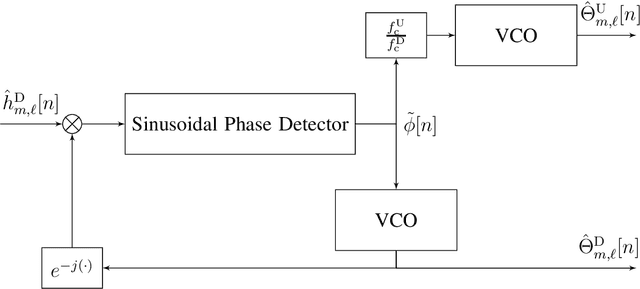
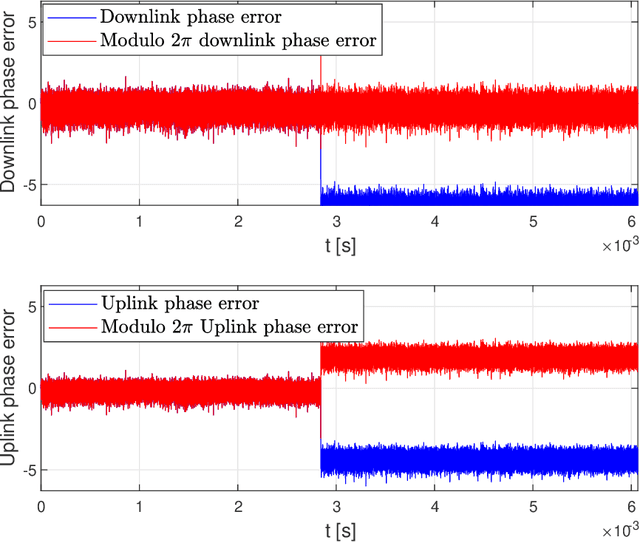
Channel reciprocity can significantly reduce the overhead of obtaining channel-state information at the transmitter (CSIT). However, true reciprocity only exists in time division duplex (TDD). In this paper, we propose a novel tracking method that exploits implicit reciprocity in FDD line-of-sight (LOS) channels as in low-earth-orbit (LEO) satellite communication (SatCom). This channel reciprocity, dubbed pseudo-reciprocity, is crucial for applying multiple-user multiple-input multiple-output (MU-MIMO) to SatCom, which requires CSIT. We consider an LEO SatCom system where multiple satellites communicate with a multi-antenna land terminal (LT). In this innovative method, the LT can track the downlink channel changes and use them to estimate the uplink channels. The proposed method achieves precoding performance that is comparable to precoding with full CSIT knowledge. Furthermore, the use of pseudo reciprocity typically requires only initial CSIT feedback when the satellite rises. Over very long periods of time, pseudo reciprocity can fail as a result of phase ambiguity, which is referred to as cycle slip. We thus also present a closed-form approximation for the expected time until cycle slip, which indicates that in normal operating conditions, these cycle slips are extremely rare. Our numerical results provide strong support for the derived theory.
Using Spatio-Temporal Dual-Stream Network with Self-Supervised Learning for Lung Tumor Classification on Radial Probe Endobronchial Ultrasound Video
May 07, 2023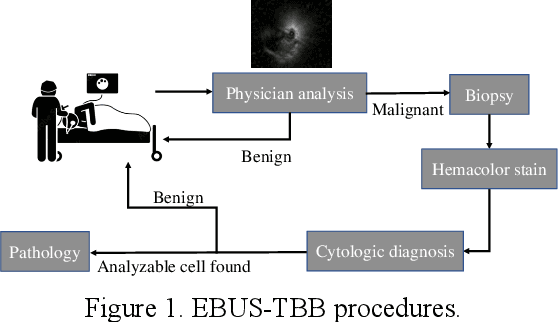
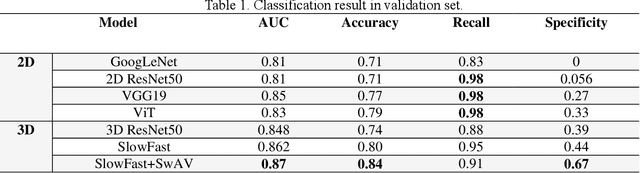
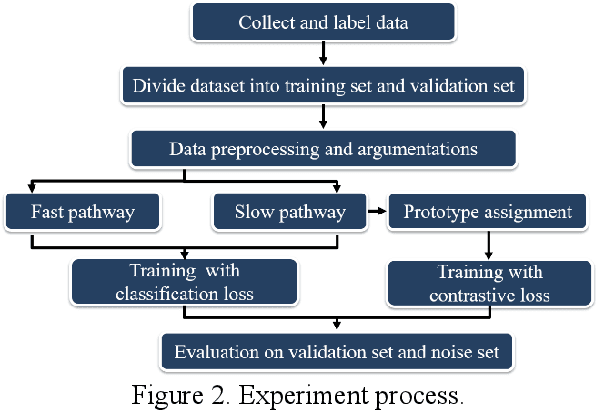
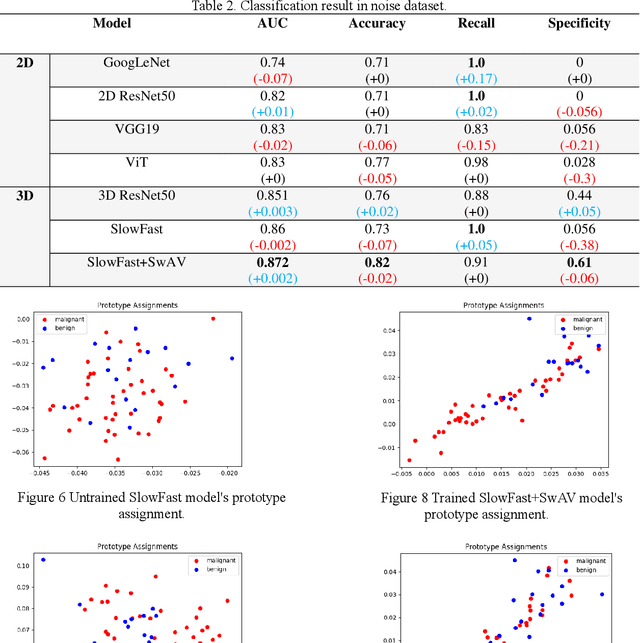
The purpose of this study is to develop a computer-aided diagnosis system for classifying benign and malignant lung lesions, and to assist physicians in real-time analysis of radial probe endobronchial ultrasound (EBUS) videos. During the biopsy process of lung cancer, physicians use real-time ultrasound images to find suitable lesion locations for sampling. However, most of these images are difficult to classify and contain a lot of noise. Previous studies have employed 2D convolutional neural networks to effectively differentiate between benign and malignant lung lesions, but doctors still need to manually select good-quality images, which can result in additional labor costs. In addition, the 2D neural network has no ability to capture the temporal information of the ultrasound video, so it is difficult to obtain the relationship between the features of the continuous images. This study designs an automatic diagnosis system based on a 3D neural network, uses the SlowFast architecture as the backbone to fuse temporal and spatial features, and uses the SwAV method of contrastive learning to enhance the noise robustness of the model. The method we propose includes the following advantages, such as (1) using clinical ultrasound films as model input, thereby reducing the need for high-quality image selection by physicians, (2) high-accuracy classification of benign and malignant lung lesions can assist doctors in clinical diagnosis and reduce the time and risk of surgery, and (3) the capability to classify well even in the presence of significant image noise. The AUC, accuracy, precision, recall and specificity of our proposed method on the validation set reached 0.87, 83.87%, 86.96%, 90.91% and 66.67%, respectively. The results have verified the importance of incorporating temporal information and the effectiveness of using the method of contrastive learning on feature extraction.