 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
NIKI: Neural Inverse Kinematics with Invertible Neural Networks for 3D Human Pose and Shape Estimation
May 15, 2023
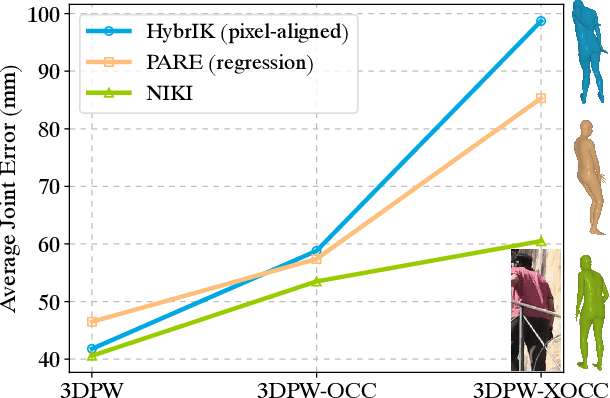
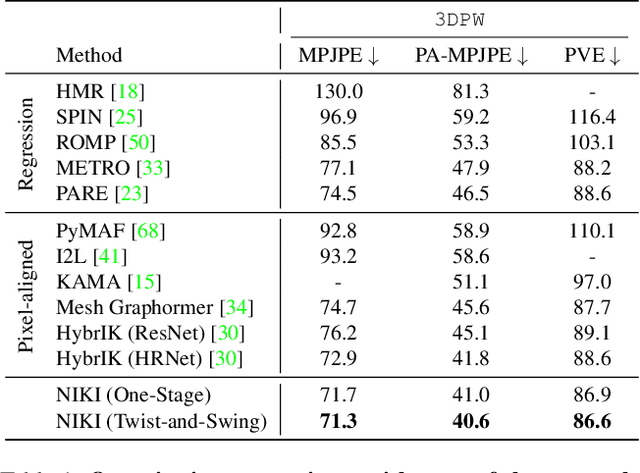
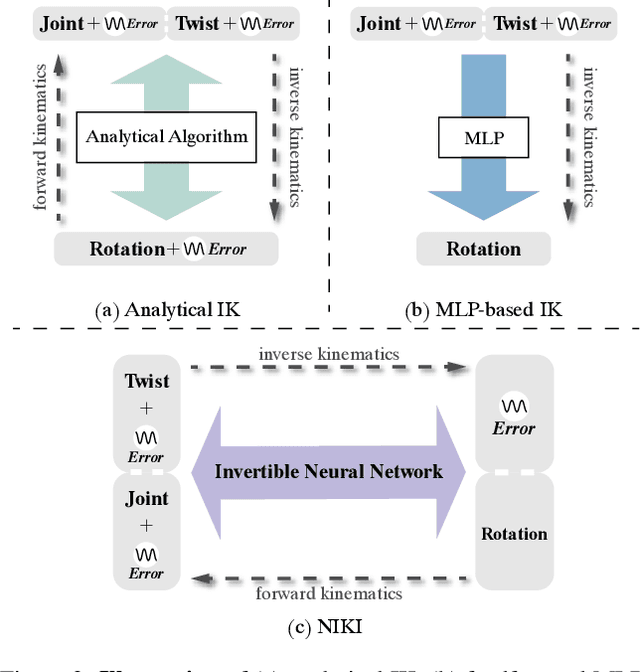
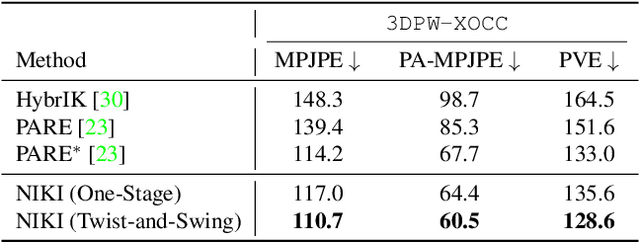
With the progress of 3D human pose and shape estimation, state-of-the-art methods can either be robust to occlusions or obtain pixel-aligned accuracy in non-occlusion cases. However, they cannot obtain robustness and mesh-image alignment at the same time. In this work, we present NIKI (Neural Inverse Kinematics with Invertible Neural Network), which models bi-directional errors to improve the robustness to occlusions and obtain pixel-aligned accuracy. NIKI can learn from both the forward and inverse processes with invertible networks. In the inverse process, the model separates the error from the plausible 3D pose manifold for a robust 3D human pose estimation. In the forward process, we enforce the zero-error boundary conditions to improve the sensitivity to reliable joint positions for better mesh-image alignment. Furthermore, NIKI emulates the analytical inverse kinematics algorithms with the twist-and-swing decomposition for better interpretability. Experiments on standard and occlusion-specific benchmarks demonstrate the effectiveness of NIKI, where we exhibit robust and well-aligned results simultaneously. Code is available at https://github.com/Jeff-sjtu/NIKI
Encoding Domain Expertise into Multilevel Models for Source Location
May 15, 2023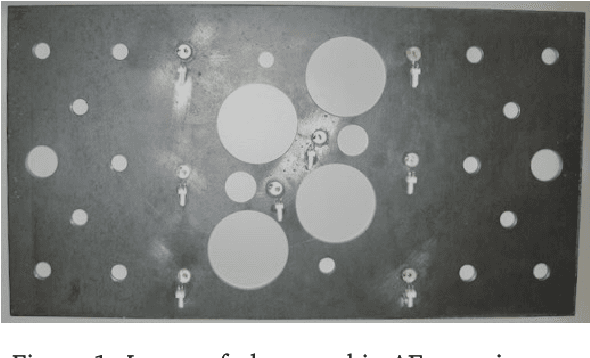
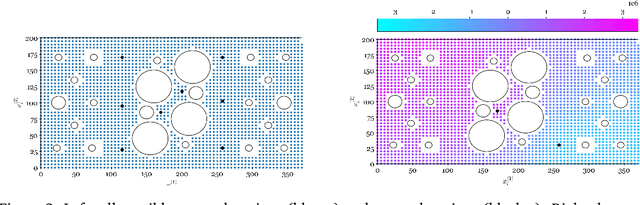
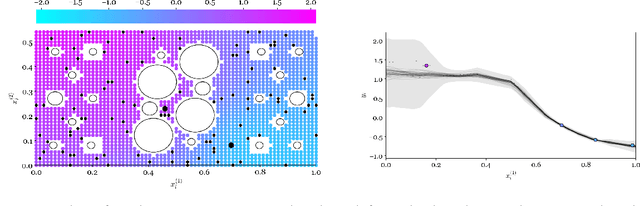
Data from populations of systems are prevalent in many industrial applications. Machines and infrastructure are increasingly instrumented with sensing systems, emitting streams of telemetry data with complex interdependencies. In practice, data-centric monitoring procedures tend to consider these assets (and respective models) as distinct -- operating in isolation and associated with independent data. In contrast, this work captures the statistical correlations and interdependencies between models of a group of systems. Utilising a Bayesian multilevel approach, the value of data can be extended, since the population can be considered as a whole, rather than constituent parts. Most interestingly, domain expertise and knowledge of the underlying physics can be encoded in the model at the system, subgroup, or population level. We present an example of acoustic emission (time-of-arrival) mapping for source location, to illustrate how multilevel models naturally lend themselves to representing aggregate systems in engineering. In particular, we focus on constraining the combined models with domain knowledge to enhance transfer learning and enable further insights at the population level.
Capturing Humans' Mental Models of AI: An Item Response Theory Approach
May 15, 2023


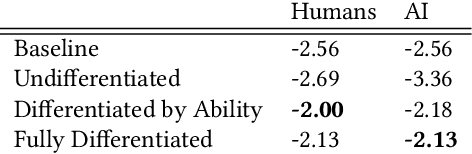
Improving our understanding of how humans perceive AI teammates is an important foundation for our general understanding of human-AI teams. Extending relevant work from cognitive science, we propose a framework based on item response theory for modeling these perceptions. We apply this framework to real-world experiments, in which each participant works alongside another person or an AI agent in a question-answering setting, repeatedly assessing their teammate's performance. Using this experimental data, we demonstrate the use of our framework for testing research questions about people's perceptions of both AI agents and other people. We contrast mental models of AI teammates with those of human teammates as we characterize the dimensionality of these mental models, their development over time, and the influence of the participants' own self-perception. Our results indicate that people expect AI agents' performance to be significantly better on average than the performance of other humans, with less variation across different types of problems. We conclude with a discussion of the implications of these findings for human-AI interaction.
Perceptive Locomotion through Whole-Body MPC and Optimal Region Selection
May 15, 2023


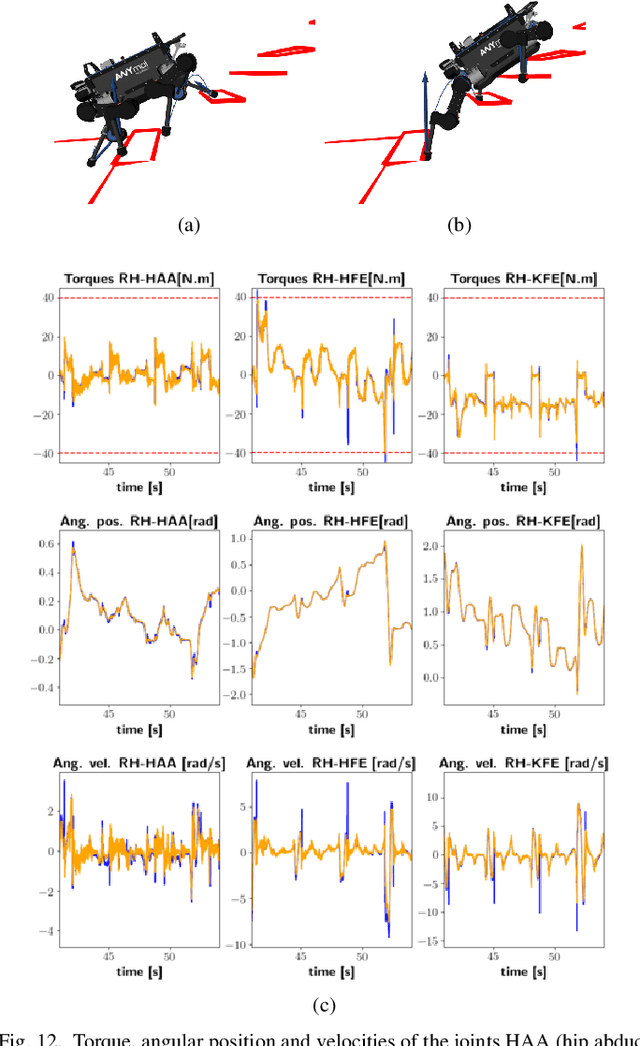
Real-time synthesis of legged locomotion maneuvers in challenging industrial settings is still an open problem, requiring simultaneous determination of footsteps locations several steps ahead while generating whole-body motions close to the robot's limits. State estimation and perception errors impose the practical constraint of fast re-planning motions in a model predictive control (MPC) framework. We first observe that the computational limitation of perceptive locomotion pipelines lies in the combinatorics of contact surface selection. Re-planning contact locations on selected surfaces can be accomplished at MPC frequencies (50-100 Hz). Then, whole-body motion generation typically follows a reference trajectory for the robot base to facilitate convergence. We propose removing this constraint to robustly address unforeseen events such as contact slipping, by leveraging a state-of-the-art whole-body MPC (Croccodyl). Our contributions are integrated into a complete framework for perceptive locomotion, validated under diverse terrain conditions, and demonstrated in challenging trials that push the robot's actuation limits, as well as in the ICRA 2023 quadruped challenge simulation.
LB-SimTSC: An Efficient Similarity-Aware Graph Neural Network for Semi-Supervised Time Series Classification
Jan 17, 2023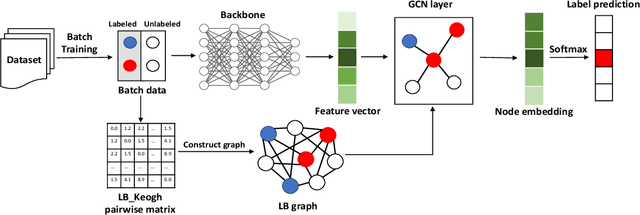
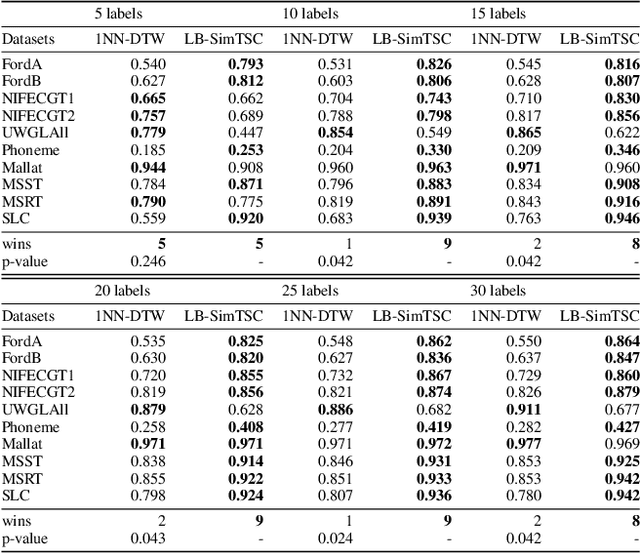
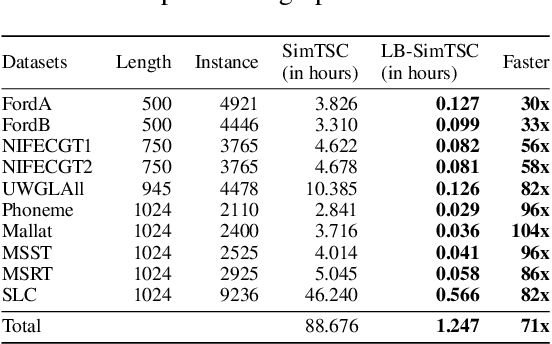
Time series classification is an important data mining task that has received a lot of interest in the past two decades. Due to the label scarcity in practice, semi-supervised time series classification with only a few labeled samples has become popular. Recently, Similarity-aware Time Series Classification (SimTSC) is proposed to address this problem by using a graph neural network classification model on the graph generated from pairwise Dynamic Time Warping (DTW) distance of batch data. It shows excellent accuracy and outperforms state-of-the-art deep learning models in several few-label settings. However, since SimTSC relies on pairwise DTW distances, the quadratic complexity of DTW limits its usability to only reasonably sized datasets. To address this challenge, we propose a new efficient semi-supervised time series classification technique, LB-SimTSC, with a new graph construction module. Instead of using DTW, we propose to utilize a lower bound of DTW, LB_Keogh, to approximate the dissimilarity between instances in linear time, while retaining the relative proximity relationships one would have obtained via computing DTW. We construct the pairwise distance matrix using LB_Keogh and build a graph for the graph neural network. We apply this approach to the ten largest datasets from the well-known UCR time series classification archive. The results demonstrate that this approach can be up to 104x faster than SimTSC when constructing the graph on large datasets without significantly decreasing classification accuracy.
Suspicious Vehicle Detection Using Licence Plate Detection And Facial Feature Recognition
Apr 18, 2023


With the increasing need to strengthen vehicle safety and detection, the availability of pre-existing methods of catching criminals and identifying vehicles manually through the various traffic surveillance cameras is not only time-consuming but also inefficient. With the advancement of technology in every field the use of real-time traffic surveillance models will help facilitate an easy approach. Keeping this in mind, the main focus of our paper is to develop a combined face recognition and number plate recognition model to ensure vehicle safety and real-time tracking of running-away criminals and stolen vehicles.
Dynamic Graph Node Classification via Time Augmentation
Dec 07, 2022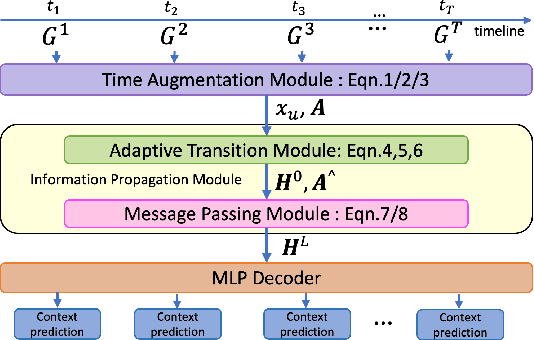
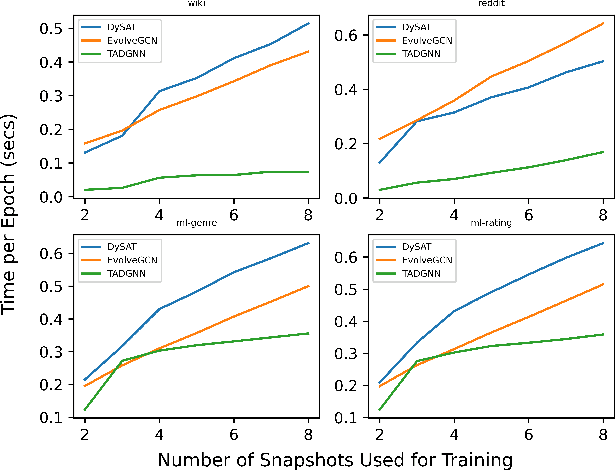

Node classification for graph-structured data aims to classify nodes whose labels are unknown. While studies on static graphs are prevalent, few studies have focused on dynamic graph node classification. Node classification on dynamic graphs is challenging for two reasons. First, the model needs to capture both structural and temporal information, particularly on dynamic graphs with a long history and require large receptive fields. Second, model scalability becomes a significant concern as the size of the dynamic graph increases. To address these problems, we propose the Time Augmented Dynamic Graph Neural Network (TADGNN) framework. TADGNN consists of two modules: 1) a time augmentation module that captures the temporal evolution of nodes across time structurally, creating a time-augmented spatio-temporal graph, and 2) an information propagation module that learns the dynamic representations for each node across time using the constructed time-augmented graph. We perform node classification experiments on four dynamic graph benchmarks. Experimental results demonstrate that TADGNN framework outperforms several static and dynamic state-of-the-art (SOTA) GNN models while demonstrating superior scalability. We also conduct theoretical and empirical analyses to validate the efficiency of the proposed method. Our code is available at https://sites.google.com/view/tadgnn.
RUPNet: Residual upsampling network for real-time polyp segmentation
Jan 06, 2023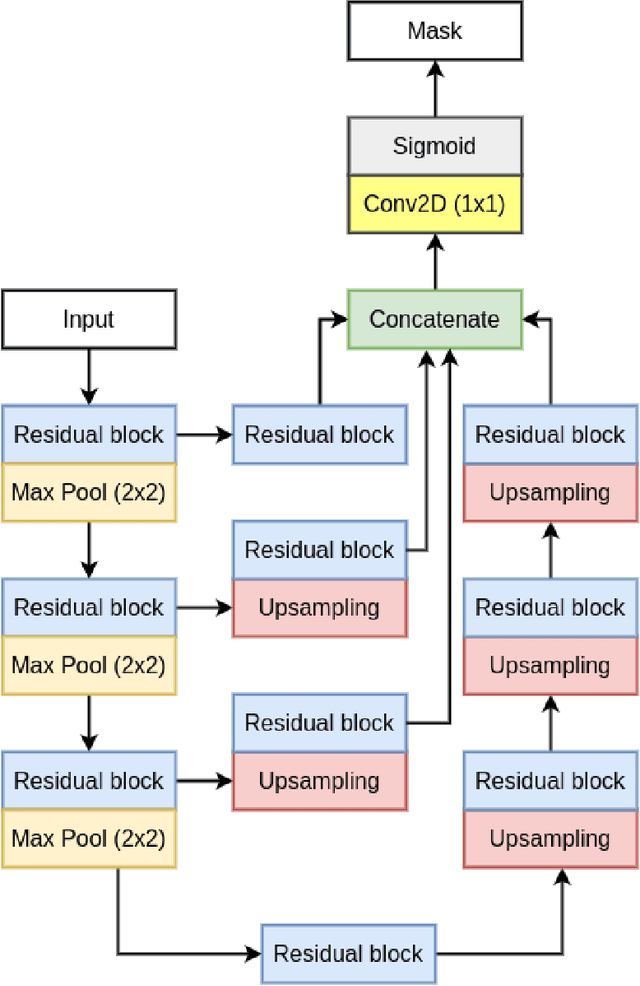
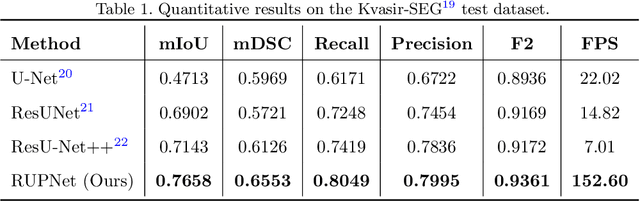
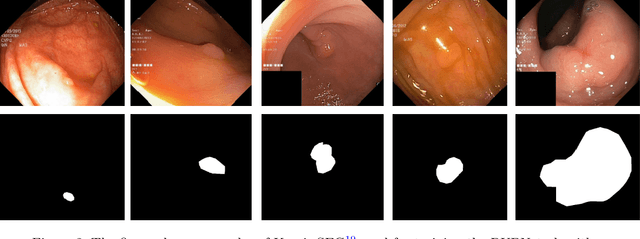
Colorectal cancer is among the most prevalent cause of cancer-related mortality worldwide. Detection and removal of polyps at an early stage can help reduce mortality and even help in spreading over adjacent organs. Early polyp detection could save the lives of millions of patients over the world as well as reduce the clinical burden. However, the detection polyp rate varies significantly among endoscopists. There is numerous deep learning-based method proposed, however, most of the studies improve accuracy. Here, we propose a novel architecture, Residual Upsampling Network (RUPNet) for colon polyp segmentation that can process in real-time and show high recall and precision. The proposed architecture, RUPNet, is an encoder-decoder network that consists of three encoders, three decoder blocks, and some additional upsampling blocks at the end of the network. With an image size of $512 \times 512$, the proposed method achieves an excellent real-time operation speed of 152.60 frames per second with an average dice coefficient of 0.7658, mean intersection of union of 0.6553, sensitivity of 0.8049, precision of 0.7995, and F2-score of 0.9361. The results suggest that RUPNet can give real-time feedback while retaining high accuracy indicating a good benchmark for early polyp detection.
Test-time Adaptation vs. Training-time Generalization: A Case Study in Human Instance Segmentation using Keypoints Estimation
Dec 12, 2022
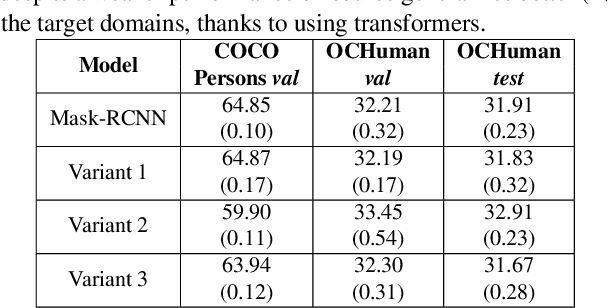

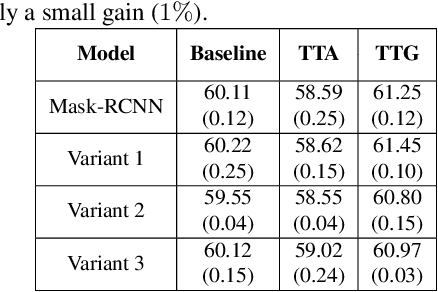
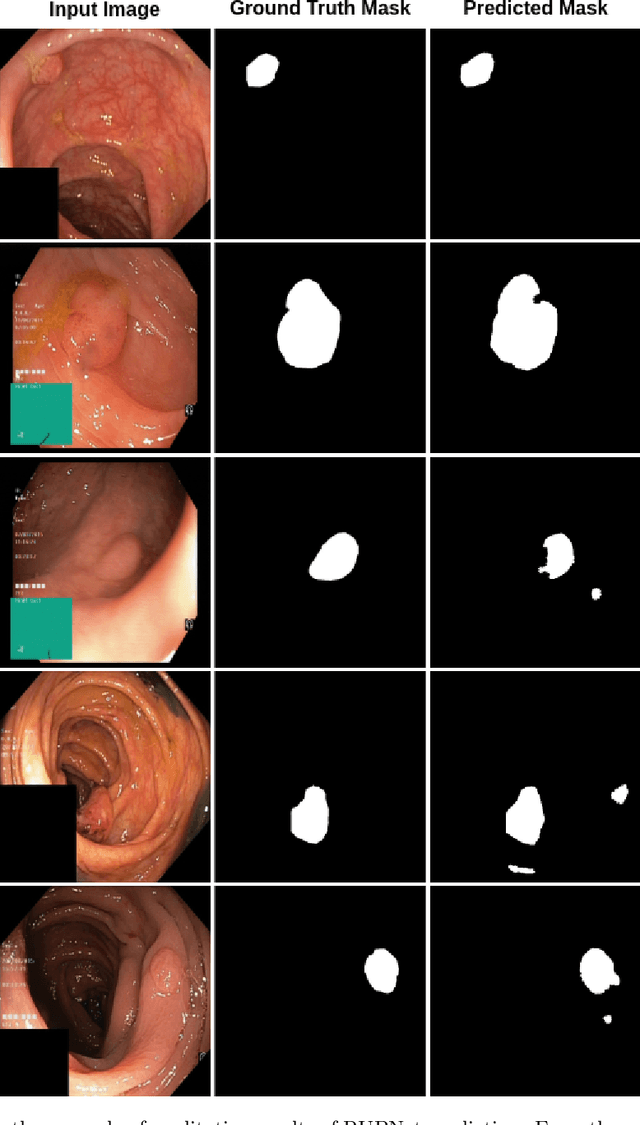
We consider the problem of improving the human instance segmentation mask quality for a given test image using keypoints estimation. We compare two alternative approaches. The first approach is a test-time adaptation (TTA) method, where we allow test-time modification of the segmentation network's weights using a single unlabeled test image. In this approach, we do not assume test-time access to the labeled source dataset. More specifically, our TTA method consists of using the keypoints estimates as pseudo labels and backpropagating them to adjust the backbone weights. The second approach is a training-time generalization (TTG) method, where we permit offline access to the labeled source dataset but not the test-time modification of weights. Furthermore, we do not assume the availability of any images from or knowledge about the target domain. Our TTG method consists of augmenting the backbone features with those generated by the keypoints head and feeding the aggregate vector to the mask head. Through a comprehensive set of ablations, we evaluate both approaches and identify several factors limiting the TTA gains. In particular, we show that in the absence of a significant domain shift, TTA may hurt and TTG show only a small gain in performance, whereas for a large domain shift, TTA gains are smaller and dependent on the heuristics used, while TTG gains are larger and robust to architectural choices.
Walk4Me: Telehealth Community Mobility Assessment, An Automated System for Early Diagnosis and Disease Progression
May 05, 2023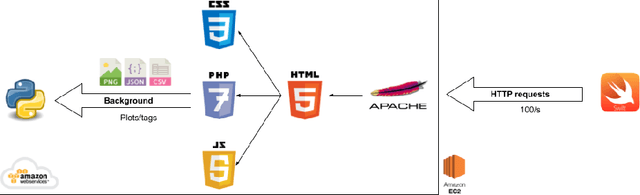
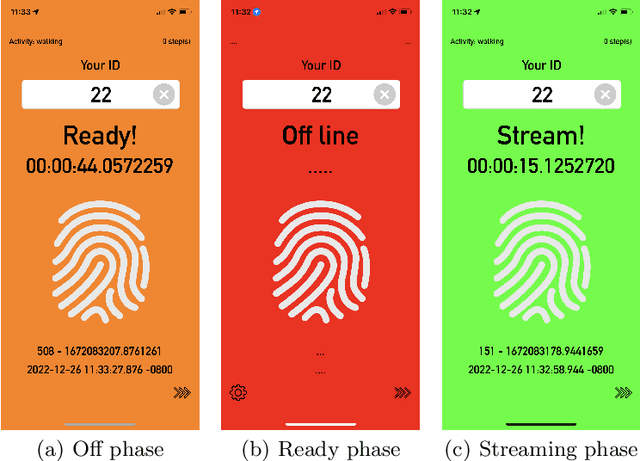
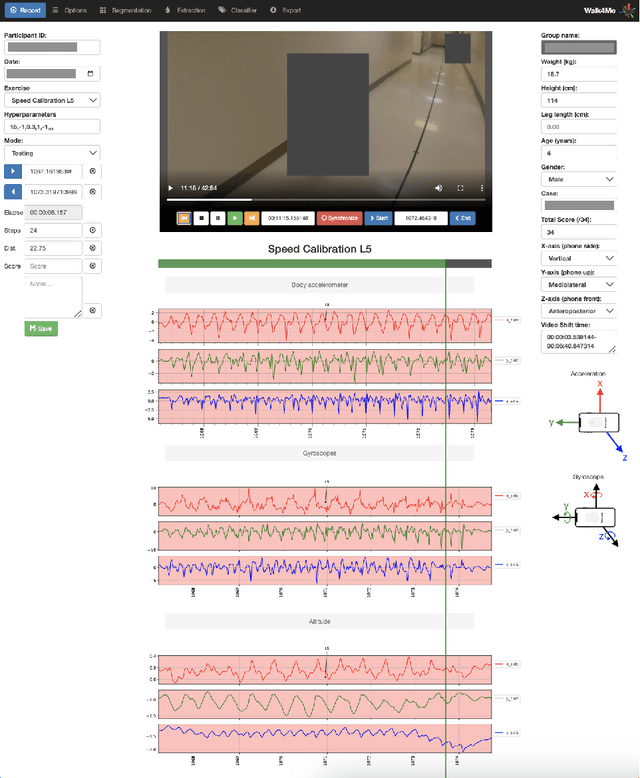
We introduce Walk4Me, a telehealth community mobility assessment system designed to facilitate early diagnosis, severity, and progression identification. Our system achieves this by 1) enabling early diagnosis, 2) identifying early indicators of clinical severity, and 3) quantifying and tracking the progression of the disease across the ambulatory phase of the disease. To accomplish this, we employ an Artificial Intelligence (AI)-based detection of gait characteristics in patients and typically developing peers. Our system remotely and in real-time collects data from device sensors (e.g., acceleration from a mobile device, etc.) using our novel Walk4Me API. Our web application extracts temporal/spatial gait characteristics and raw data signal characteristics and then employs traditional machine learning and deep learning techniques to identify patterns that can 1) identify patients with gait disturbances associated with disease, 2) describe the degree of mobility limitation, and 3) identify characteristics that change over time with disease progression. We have identified several machine learning techniques that differentiate between patients and typically-developing subjects with 100% accuracy across the age range studied, and we have also identified corresponding temporal/spatial gait characteristics associated with each group. Our work demonstrates the potential of utilizing the latest advances in mobile device and machine learning technology to measure clinical outcomes regardless of the point of care, inform early clinical diagnosis and treatment decision-making, and monitor disease progression.