 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Fourier Transformer: Fast Long Range Modeling by Removing Sequence Redundancy with FFT Operator
May 24, 2023
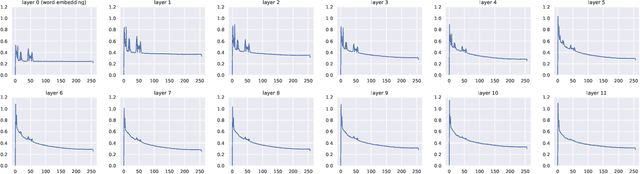
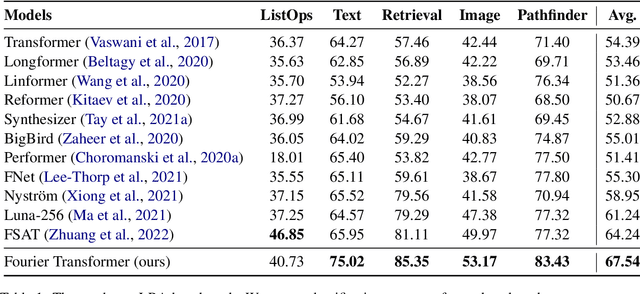
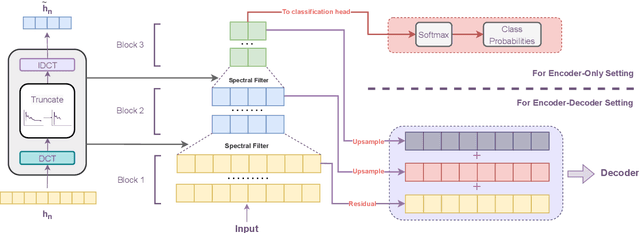
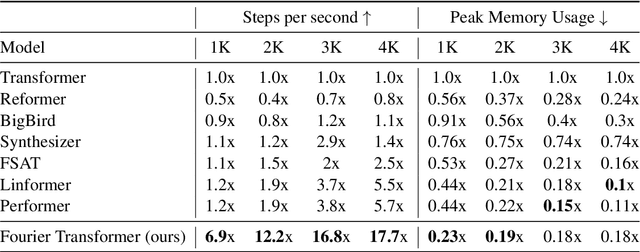
The transformer model is known to be computationally demanding, and prohibitively costly for long sequences, as the self-attention module uses a quadratic time and space complexity with respect to sequence length. Many researchers have focused on designing new forms of self-attention or introducing new parameters to overcome this limitation, however a large portion of them prohibits the model to inherit weights from large pretrained models. In this work, the transformer's inefficiency has been taken care of from another perspective. We propose Fourier Transformer, a simple yet effective approach by progressively removing redundancies in hidden sequence using the ready-made Fast Fourier Transform (FFT) operator to perform Discrete Cosine Transformation (DCT). Fourier Transformer is able to significantly reduce computational costs while retain the ability to inherit from various large pretrained models. Experiments show that our model achieves state-of-the-art performances among all transformer-based models on the long-range modeling benchmark LRA with significant improvement in both speed and space. For generative seq-to-seq tasks including CNN/DailyMail and ELI5, by inheriting the BART weights our model outperforms the standard BART and other efficient models. \footnote{Our code is publicly available at \url{https://github.com/LUMIA-Group/FourierTransformer}}
NuScenes-QA: A Multi-modal Visual Question Answering Benchmark for Autonomous Driving Scenario
May 24, 2023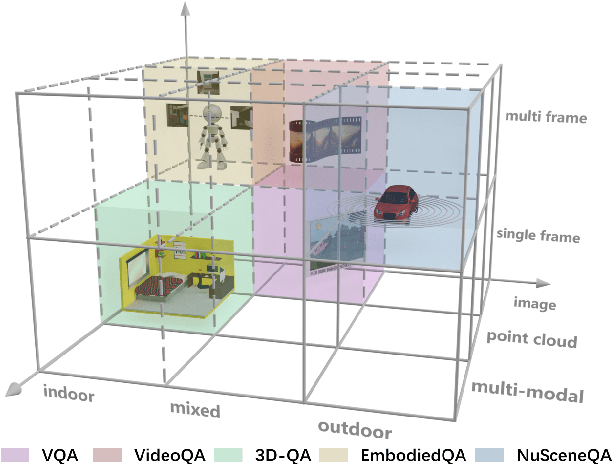
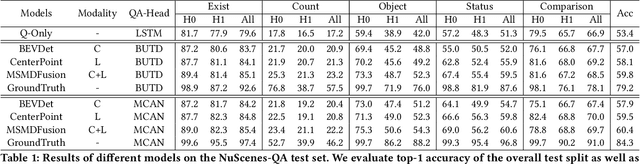
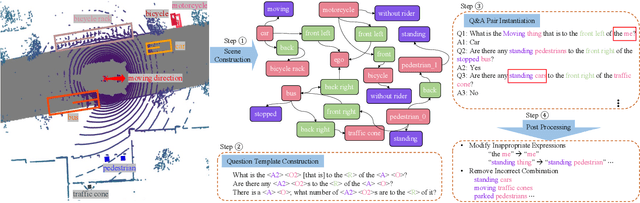
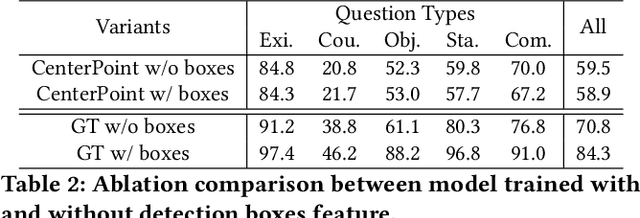
We introduce a novel visual question answering (VQA) task in the context of autonomous driving, aiming to answer natural language questions based on street-view clues. Compared to traditional VQA tasks, VQA in autonomous driving scenario presents more challenges. Firstly, the raw visual data are multi-modal, including images and point clouds captured by camera and LiDAR, respectively. Secondly, the data are multi-frame due to the continuous, real-time acquisition. Thirdly, the outdoor scenes exhibit both moving foreground and static background. Existing VQA benchmarks fail to adequately address these complexities. To bridge this gap, we propose NuScenes-QA, the first benchmark for VQA in the autonomous driving scenario, encompassing 34K visual scenes and 460K question-answer pairs. Specifically, we leverage existing 3D detection annotations to generate scene graphs and design question templates manually. Subsequently, the question-answer pairs are generated programmatically based on these templates. Comprehensive statistics prove that our NuScenes-QA is a balanced large-scale benchmark with diverse question formats. Built upon it, we develop a series of baselines that employ advanced 3D detection and VQA techniques. Our extensive experiments highlight the challenges posed by this new task. Codes and dataset are available at https://github.com/qiantianwen/NuScenes-QA.
Gorilla: Large Language Model Connected with Massive APIs
May 24, 2023
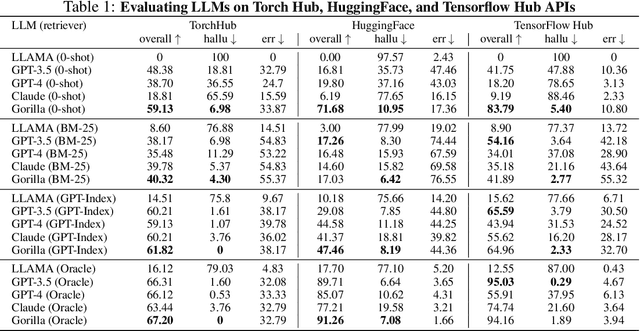
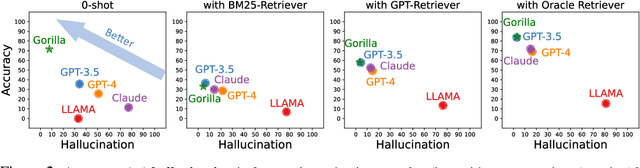
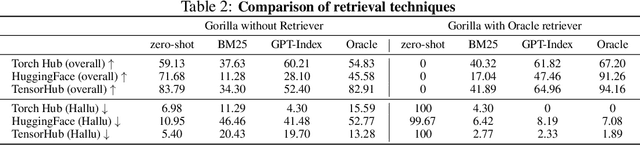
Large Language Models (LLMs) have seen an impressive wave of advances recently, with models now excelling in a variety of tasks, such as mathematical reasoning and program synthesis. However, their potential to effectively use tools via API calls remains unfulfilled. This is a challenging task even for today's state-of-the-art LLMs such as GPT-4, largely due to their inability to generate accurate input arguments and their tendency to hallucinate the wrong usage of an API call. We release Gorilla, a finetuned LLaMA-based model that surpasses the performance of GPT-4 on writing API calls. When combined with a document retriever, Gorilla demonstrates a strong capability to adapt to test-time document changes, enabling flexible user updates or version changes. It also substantially mitigates the issue of hallucination, commonly encountered when prompting LLMs directly. To evaluate the model's ability, we introduce APIBench, a comprehensive dataset consisting of HuggingFace, TorchHub, and TensorHub APIs. The successful integration of the retrieval system with Gorilla demonstrates the potential for LLMs to use tools more accurately, keep up with frequently updated documentation, and consequently increase the reliability and applicability of their outputs. Gorilla's code, model, data, and demo are available at https://gorilla.cs.berkeley.edu
Self-Supervised Learning for Point Clouds Data: A Survey
May 24, 2023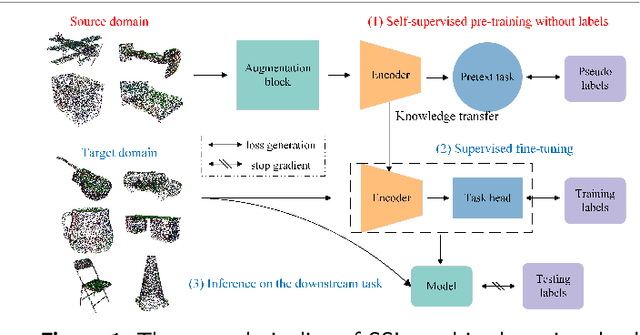
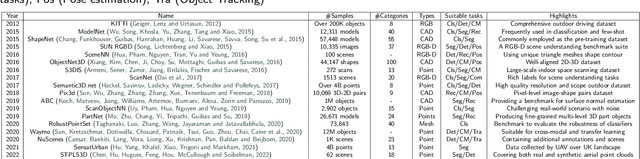
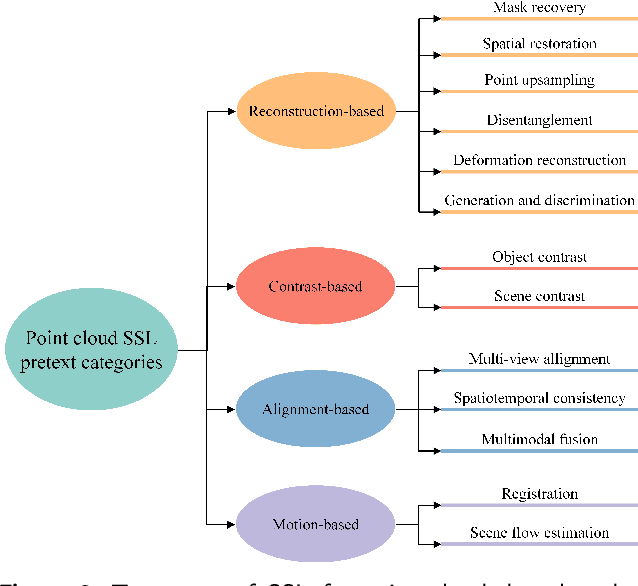

3D point clouds are a crucial type of data collected by LiDAR sensors and widely used in transportation applications due to its concise descriptions and accurate localization. Deep neural networks (DNNs) have achieved remarkable success in processing large amount of disordered and sparse 3D point clouds, especially in various computer vision tasks, such as pedestrian detection and vehicle recognition. Among all the learning paradigms, Self-Supervised Learning (SSL), an unsupervised training paradigm that mines effective information from the data itself, is considered as an essential solution to solve the time-consuming and labor-intensive data labelling problems via smart pre-training task design. This paper provides a comprehensive survey of recent advances on SSL for point clouds. We first present an innovative taxonomy, categorizing the existing SSL methods into four broad categories based on the pretexts' characteristics. Under each category, we then further categorize the methods into more fine-grained groups and summarize the strength and limitations of the representative methods. We also compare the performance of the notable SSL methods in literature on multiple downstream tasks on benchmark datasets both quantitatively and qualitatively. Finally, we propose a number of future research directions based on the identified limitations of existing SSL research on point clouds.
A Causal View of Entity Bias in (Large) Language Models
May 24, 2023
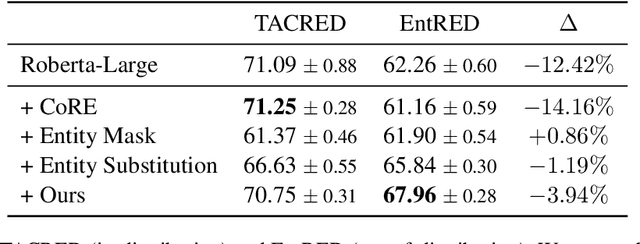
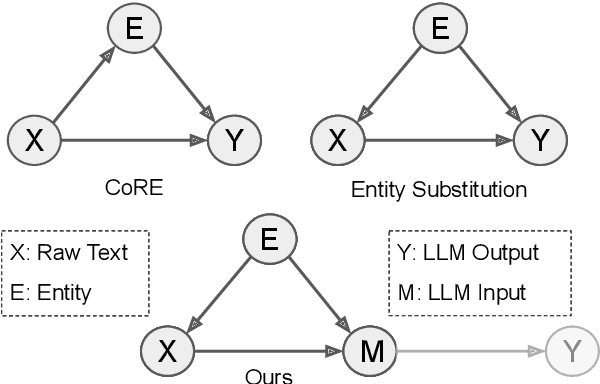
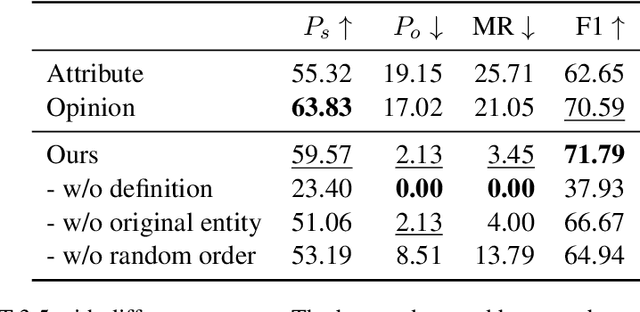
Entity bias widely affects pretrained (large) language models, causing them to excessively rely on (biased) parametric knowledge to make unfaithful predictions. Although causality-inspired methods have shown great potential to mitigate entity bias, it is hard to precisely estimate the parameters of underlying causal models in practice. The rise of black-box LLMs also makes the situation even worse, because of their inaccessible parameters and uncalibrated logits. To address these problems, we propose a specific structured causal model (SCM) whose parameters are comparatively easier to estimate. Building upon this SCM, we propose causal intervention techniques to mitigate entity bias for both white-box and black-box settings. The proposed causal intervention perturbs the original entity with neighboring entities. This intervention reduces specific biasing information pertaining to the original entity while still preserving sufficient common predictive information from similar entities. When evaluated on the relation extraction task, our training-time intervention significantly improves the F1 score of RoBERTa by 5.7 points on EntRED, in which spurious shortcuts between entities and labels are removed. Meanwhile, our in-context intervention effectively reduces the knowledge conflicts between parametric knowledge and contextual knowledge in GPT-3.5 and improves the F1 score by 9.14 points on a challenging test set derived from Re-TACRED.
Thinking Twice: Clinical-Inspired Thyroid Ultrasound Lesion Detection Based on Feature Feedback
May 24, 2023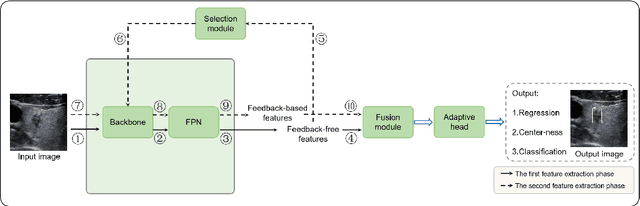
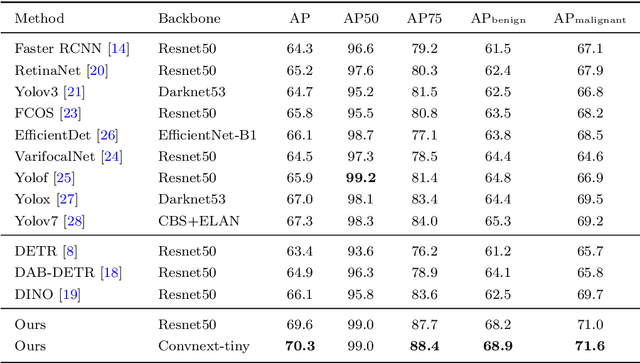
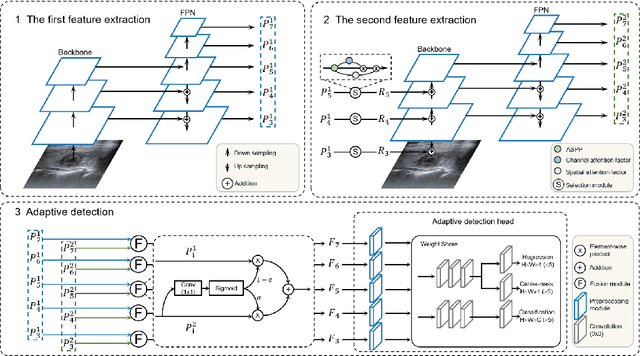

Accurate detection of thyroid lesions is a critical aspect of computer-aided diagnosis. However, most existing detection methods perform only one feature extraction process and then fuse multi-scale features, which can be affected by noise and blurred features in ultrasound images. In this study, we propose a novel detection network based on a feature feedback mechanism inspired by clinical diagnosis. The mechanism involves first roughly observing the overall picture and then focusing on the details of interest. It comprises two parts: a feedback feature selection module and a feature feedback pyramid. The feedback feature selection module efficiently selects the features extracted in the first phase in both space and channel dimensions to generate high semantic prior knowledge, which is similar to coarse observation. The feature feedback pyramid then uses this high semantic prior knowledge to enhance feature extraction in the second phase and adaptively fuses the two features, similar to fine observation. Additionally, since radiologists often focus on the shape and size of lesions for diagnosis, we propose an adaptive detection head strategy to aggregate multi-scale features. Our proposed method achieves an AP of 70.3% and AP50 of 99.0% on the thyroid ultrasound dataset and meets the real-time requirement. The code is available at https://github.com/HIT-wanglingtao/Thinking-Twice.
DC-Net: Divide-and-Conquer for Salient Object Detection
May 24, 2023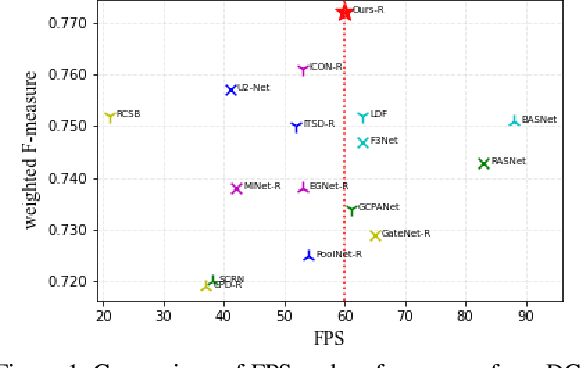
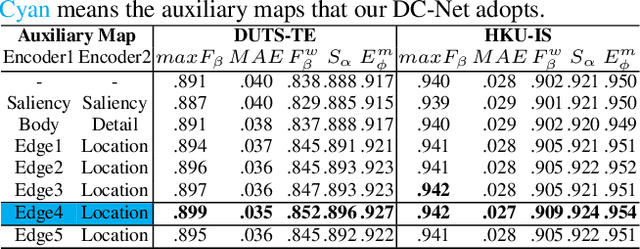

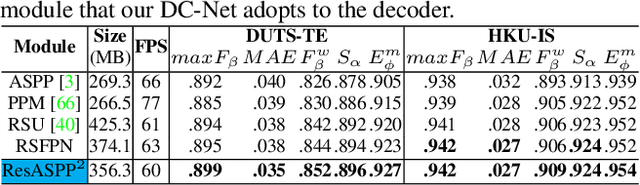
In this paper, we introduce Divide-and-Conquer into the salient object detection (SOD) task to enable the model to learn prior knowledge that is for predicting the saliency map. We design a novel network, Divide-and-Conquer Network (DC-Net) which uses two encoders to solve different subtasks that are conducive to predicting the final saliency map, here is to predict the edge maps with width 4 and location maps of salient objects and then aggregate the feature maps with different semantic information into the decoder to predict the final saliency map. The decoder of DC-Net consists of our newly designed two-level Residual nested-ASPP (ResASPP$^{2}$) modules, which have the ability to capture a large number of different scale features with a small number of convolution operations and have the advantages of maintaining high resolution all the time and being able to obtain a large and compact effective receptive field (ERF). Based on the advantage of Divide-and-Conquer's parallel computing, we use Parallel Acceleration to speed up DC-Net, allowing it to achieve competitive performance on six LR-SOD and five HR-SOD datasets under high efficiency (60 FPS and 55 FPS). Codes and results are available: https://github.com/PiggyJerry/DC-Net.
Automated Driving Architecture and Operation of a Light Commercial Vehicle
May 24, 2023
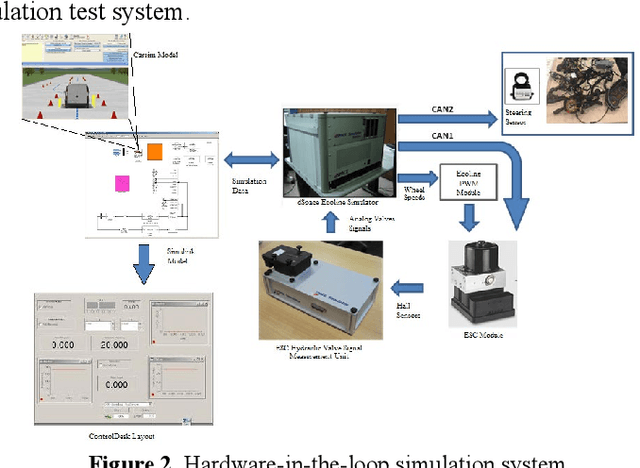

This paper is on the automated driving architecture and operation of a light commercial vehicle. Simple longitudinal and lateral dynamic models of the vehicle and a more detailed CarSim model are developed and used in simulations and controller design and evaluation. Experimental validation is used to make sure that the models used represent the actual response of the vehicle as closely as possible. The vehicle is made drive-by-wire by interfacing with the existing throttle-by-wire, by adding an active vacuum booster for brake-by-wire and by adding a steering actuator for steer-by-wire operation. Vehicle localization is achieved by using a GPS sensor integrated with six axes IMU with a built-in INS algorithm and a digital compass for heading information. Front looking radar, lidar and camera are used for environmental sensing. Communication with the road infrastructure and other vehicles is made possible by a vehicle to vehicle communication modem. A dedicated computer under real time Linux is used to collect, process and distribute sensor information. A dSPACE MicroAutoBox is used for drive-by-wire controls. CACC based longitudinal control and path tracking of a map of GPS waypoints are used to present the operation of this automated driving vehicle.
Diffusion Co-Policy for Synergistic Human-Robot Collaborative Tasks
May 20, 2023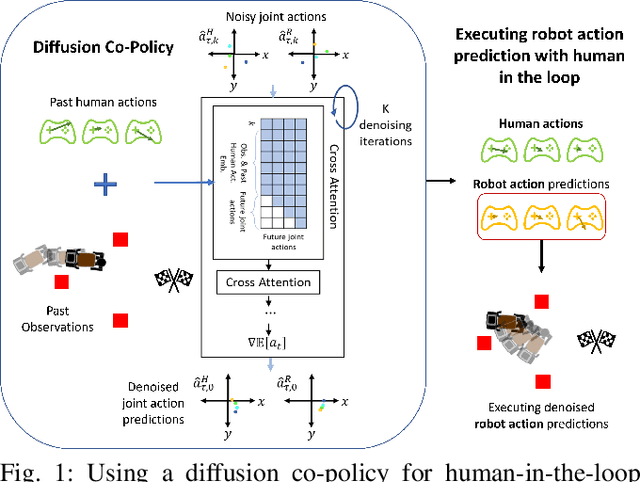
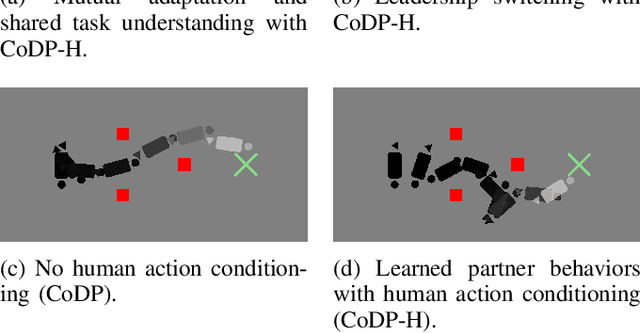

Modeling multimodal human behavior accurately has been a key barrier to increasing the level of interaction between human and robot, particularly for collaborative tasks. Our key insight is that the predictive accuracy of human behaviors on physical tasks is bottlenecked by the model for methods involving human behavior prediction. We present a method for training denoising diffusion probabilistic models on a dataset of collaborative human-human demonstrations and conditioning on past human partner actions to plan sequences of robot actions that synergize well with humans during test time. We demonstrate the method outperforms other state-of-art learning methods on human-robot table-carrying, a continuous state-action task, in both simulation and real settings with a human in the loop. Moreover, we qualitatively highlight compelling robot behaviors that arise during evaluations that demonstrate evidence of true human-robot collaboration, including mutual adaptation, shared task understanding, leadership switching, learned partner behaviors, and low levels of wasteful interaction forces arising from dissent. Project page coming soon.
The Brain Tumor Segmentation (BraTS) Challenge 2023: Brain MR Image Synthesis for Tumor Segmentation (BraSyn)
May 20, 2023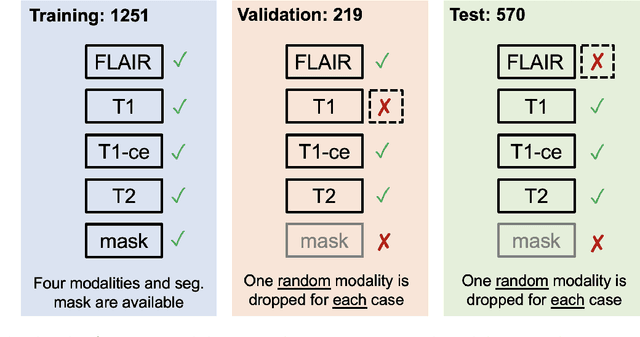
Automated brain tumor segmentation methods are well established, reaching performance levels with clear clinical utility. Most algorithms require four input magnetic resonance imaging (MRI) modalities, typically T1-weighted images with and without contrast enhancement, T2-weighted images, and FLAIR images. However, some of these sequences are often missing in clinical practice, e.g., because of time constraints and/or image artifacts (such as patient motion). Therefore, substituting missing modalities to recover segmentation performance in these scenarios is highly desirable and necessary for the more widespread adoption of such algorithms in clinical routine. In this work, we report the set-up of the Brain MR Image Synthesis Benchmark (BraSyn), organized in conjunction with the Medical Image Computing and Computer-Assisted Intervention (MICCAI) 2023. The objective of the challenge is to benchmark image synthesis methods that realistically synthesize missing MRI modalities given multiple available images to facilitate automated brain tumor segmentation pipelines. The image dataset is multi-modal and diverse, created in collaboration with various hospitals and research institutions.