 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
What Matters in Reinforcement Learning for Tractography
May 17, 2023
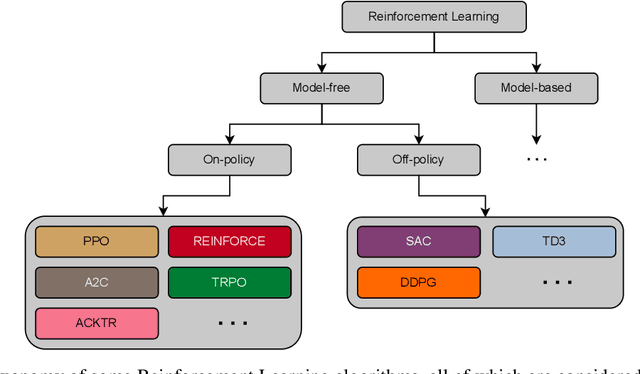
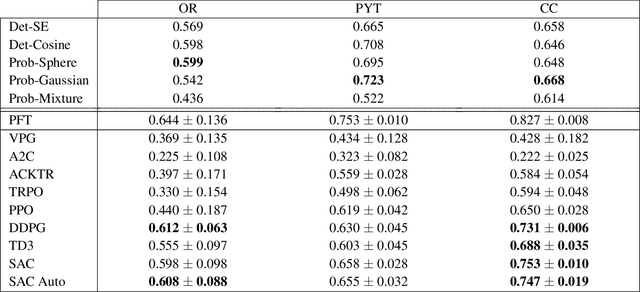
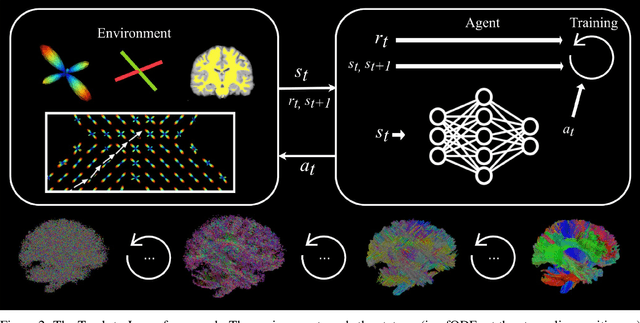
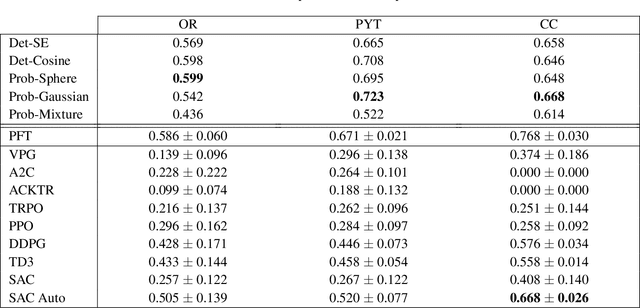
Recently, deep reinforcement learning (RL) has been proposed to learn the tractography procedure and train agents to reconstruct the structure of the white matter without manually curated reference streamlines. While the performances reported were competitive, the proposed framework is complex, and little is still known about the role and impact of its multiple parts. In this work, we thoroughly explore the different components of the proposed framework, such as the choice of the RL algorithm, seeding strategy, the input signal and reward function, and shed light on their impact. Approximately 7,400 models were trained for this work, totalling nearly 41,000 hours of GPU time. Our goal is to guide researchers eager to explore the possibilities of deep RL for tractography by exposing what works and what does not work with the category of approach. As such, we ultimately propose a series of recommendations concerning the choice of RL algorithm, the input to the agents, the reward function and more to help future work using reinforcement learning for tractography. We also release the open source codebase, trained models, and datasets for users and researchers wanting to explore reinforcement learning for tractography.
Inertial-based Navigation by Polynomial Optimization: Inertial-Magnetic Attitude Estimation
May 17, 2023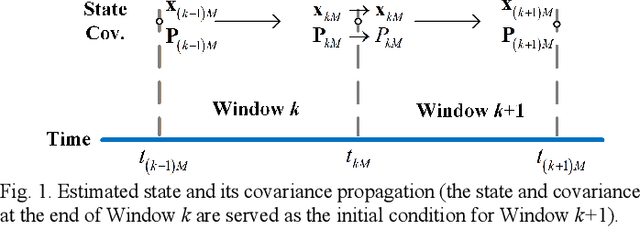
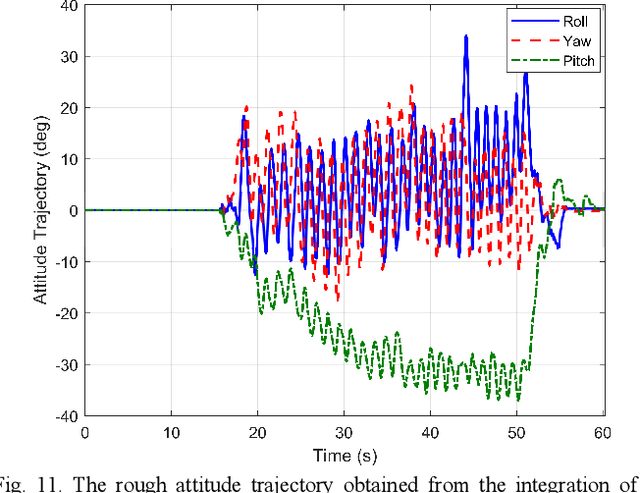
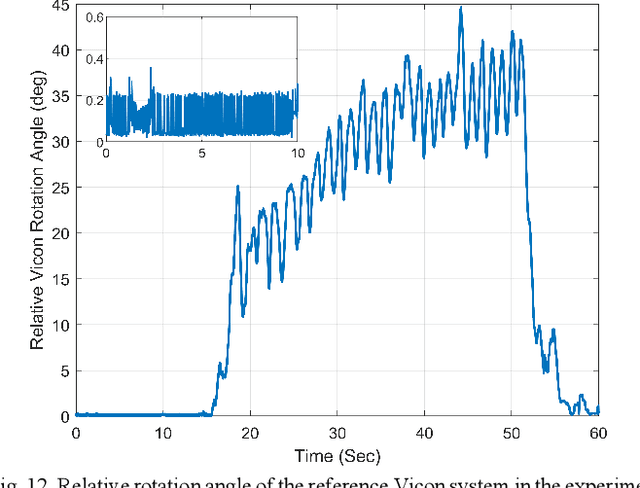
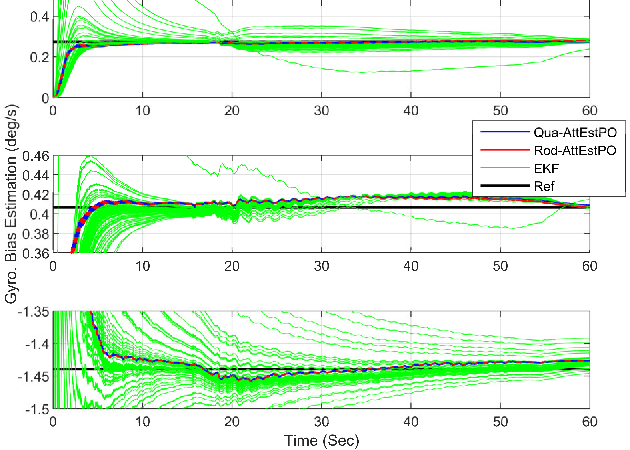
Inertial-based navigation refers to the navigation methods or systems that have inertial information or sensors as the core part and integrate a spectrum of other kinds of sensors for enhanced performance. Through a series of papers, the authors attempt to explore information blending of inertial-based navigation by a polynomial optimization method. The basic idea is to model rigid motions as finite-order polynomials and then attacks the involved navigation problems by optimally solving their coefficients, taking into considerations the constraints posed by inertial sensors and others. In the current paper, a continuous-time attitude estimation approach is proposed, which transforms the attitude estimation into a constant parameter determination problem by the polynomial optimization. Specifically, the continuous attitude is first approximated by a Chebyshev polynomial, of which the unknown Chebyshev coefficients are determined by minimizing the weighted residuals of initial conditions, dynamics and measurements. We apply the derived estimator to the attitude estimation with the magnetic and inertial sensors. Simulation and field tests show that the estimator has much better stability and faster convergence than the traditional extended Kalman filter does, especially in the challenging large initial state error scenarios.
Stop Uploading Test Data in Plain Text: Practical Strategies for Mitigating Data Contamination by Evaluation Benchmarks
May 17, 2023Data contamination has become especially prevalent and challenging with the rise of models pretrained on very large, automatically-crawled corpora. For closed models, the training data becomes a trade secret, and even for open models, it is not trivial to ascertain whether a particular test instance has been compromised. Strategies such as live leaderboards with hidden answers, or using test data which is guaranteed to be unseen, are expensive and become fragile with time. Assuming that all relevant actors value clean test data and will cooperate to mitigate data contamination, what can be done? We propose three strategies that can make a difference: (1) Test data made public should be encrypted with a public key and licensed to disallow derivative distribution; (2) demand training exclusion controls from closed API holders, and protect your test data by refusing to evaluate until demands are met; (3) in case of test data based on internet text, avoid data which appears with its solution on the internet, and release the context of internet-derived data along with the data. These strategies are practical and can be effective in preventing data contamination and allowing trustworthy evaluation of models' capabilities.
Uncertainty in Real-Time Semantic Segmentation on Embedded Systems
Dec 20, 2022
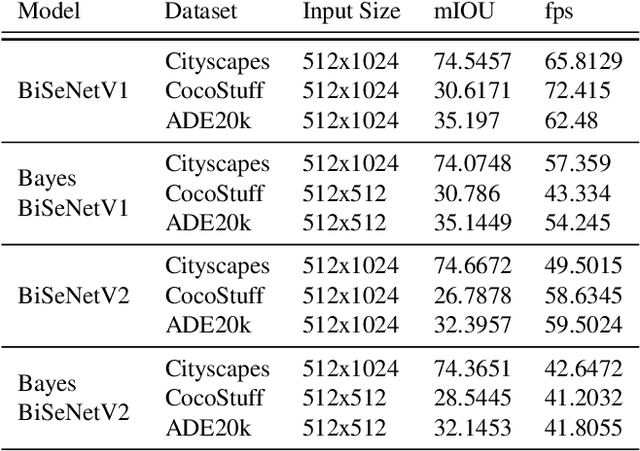
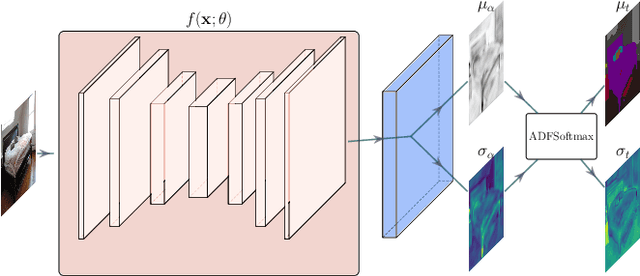

Application for semantic segmentation models in areas such as autonomous vehicles and human computer interaction require real-time predictive capabilities. The challenges of addressing real-time application is amplified by the need to operate on resource constrained hardware. Whilst development of real-time methods for these platforms has increased, these models are unable to sufficiently reason about uncertainty present. This paper addresses this by combining deep feature extraction from pre-trained models with Bayesian regression and moment propagation for uncertainty aware predictions. We demonstrate how the proposed method can yield meaningful uncertainty on embedded hardware in real-time whilst maintaining predictive performance.
Unlimiformer: Long-Range Transformers with Unlimited Length Input
May 02, 2023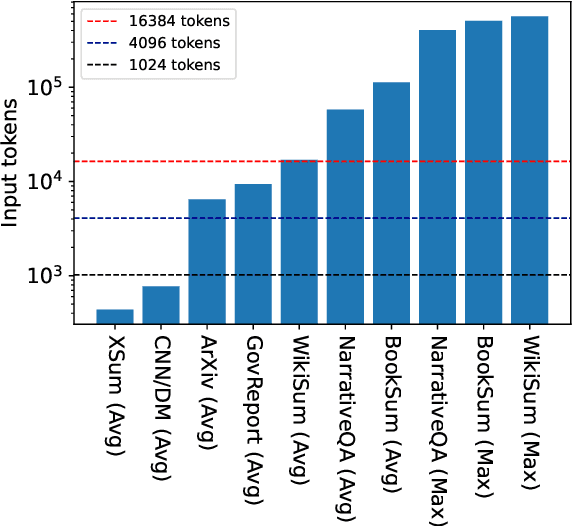


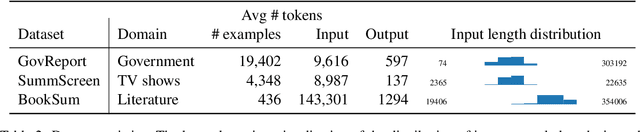
Transformer-based models typically have a predefined bound to their input length, because of their need to potentially attend to every token in the input. In this work, we propose Unlimiformer: a general approach that can wrap any existing pretrained encoder-decoder transformer, and offload the attention computation across all layers to a single $k$-nearest-neighbor index; this index can be kept on either the GPU or CPU memory and queried in sub-linear time. This way, we can index extremely long input sequences, while every attention head in every decoder layer retrieves its top-$k$ keys, instead of attending to every key. We demonstrate Unlimiformers's efficacy on several long-document and multi-document summarization benchmarks, showing that it can summarize even 350k token-long inputs from the BookSum dataset, without any input truncation at test time. Unlimiformer improves pretrained models such as BART and Longformer by extending them to unlimited inputs without additional learned weights and without modifying their code. We make our code and models publicly available at https://github.com/abertsch72/unlimiformer .
Mixed-Integer Optimal Control via Reinforcement Learning: A Case Study on Hybrid Vehicle Energy Management
May 02, 2023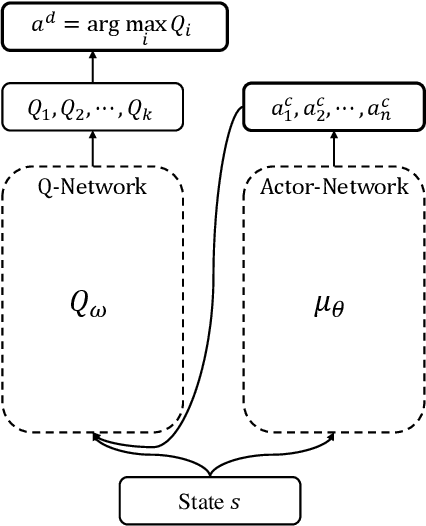
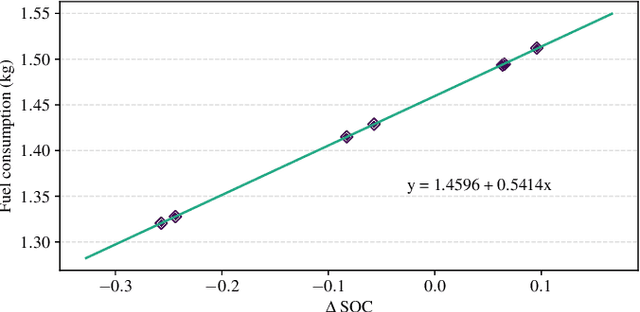
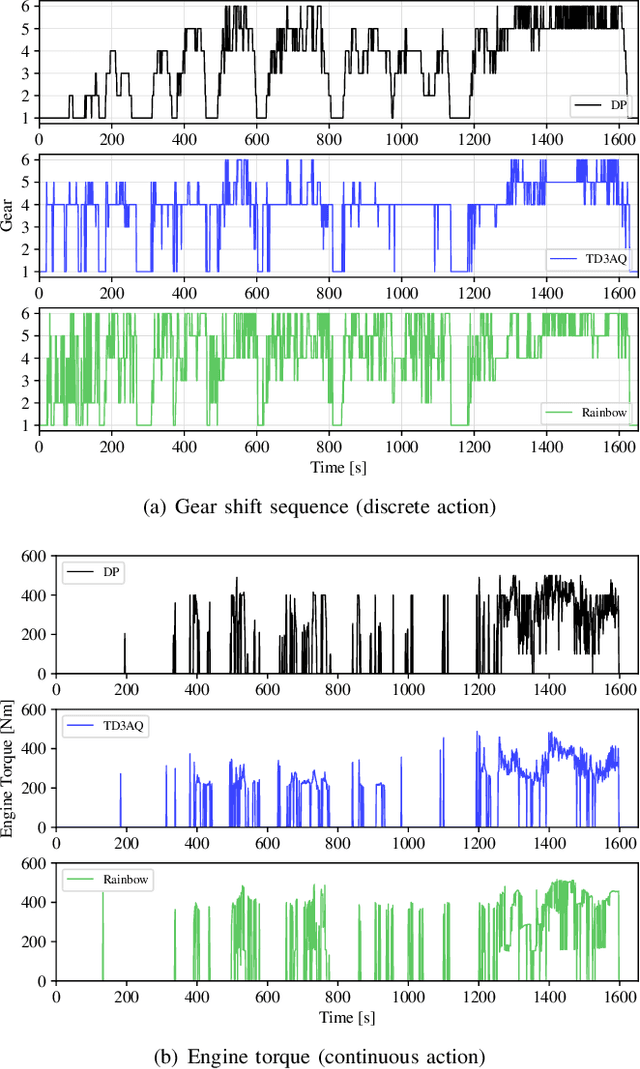
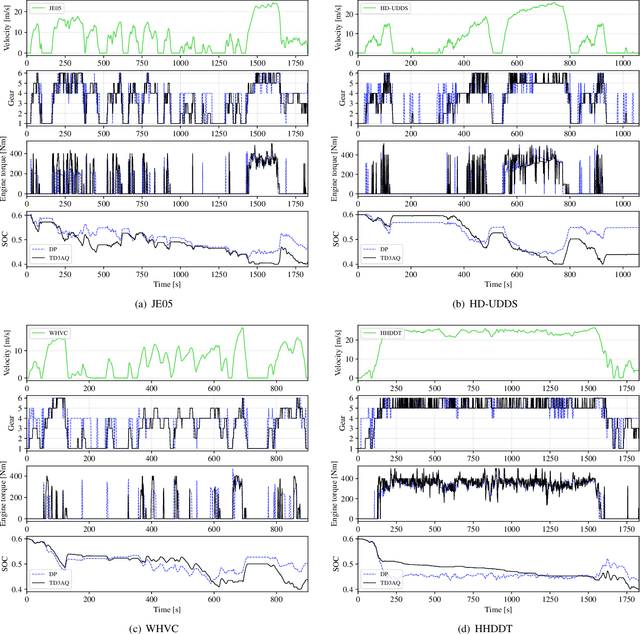
Many optimal control problems require the simultaneous output of continuous and discrete control variables. Such problems are usually formulated as mixed-integer optimal control (MIOC) problems, which are challenging to solve due to the complexity of the solution space. Numerical methods such as branch-and-bound are computationally expensive and unsuitable for real-time control. This paper proposes a novel continuous-discrete reinforcement learning (CDRL) algorithm, twin delayed deep deterministic actor-Q (TD3AQ), for MIOC problems. TD3AQ combines the advantages of both actor-critic and Q-learning methods, and can handle the continuous and discrete action spaces simultaneously. The proposed algorithm is evaluated on a hybrid electric vehicle (HEV) energy management problem, where real-time control of the continuous variable engine torque and discrete variable gear ratio is essential to maximize fuel economy while satisfying driving constraints. Simulation results on different drive cycles show that TD3AQ can achieve near-optimal solutions compared to dynamic programming (DP) and outperforms the state-of-the-art discrete RL algorithm Rainbow, which is adopted for MIOC by discretizing continuous actions into a finite set of discrete values.
Hardware Prototype of a Time-Encoding Sub-Nyquist ADC
Jan 05, 2023
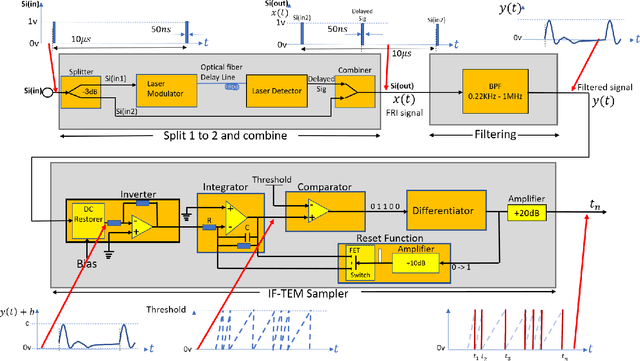

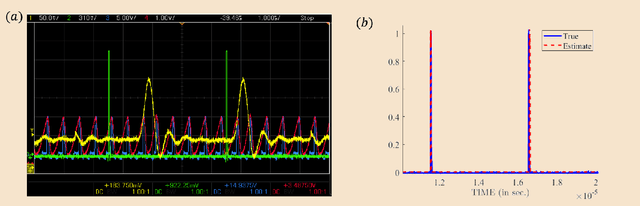
Analog-to-digital converters (ADCs) are key components of digital signal processing. Classical samplers in this framework are controlled by a global clock. At high sampling rates, clocks are expensive and power-hungry, thus increasing the cost and energy consumption of ADCs. It is, therefore, desirable to sample using a clock-less ADC at the lowest possible rate. An integrate-and-fire time-encoding machine (IF-TEM) is a time-based power-efficient asynchronous design that is not synced to a global clock. Finite-rate-of-innovation (FRI) signals, ubiquitous in various applications, have fewer degrees of freedom than the signal's Nyquist rate, enabling sub-Nyquist sampling signal models. This work proposes a power-efficient IF-TEM ADC architecture and demonstrates sub-Nyquist sampling and FRI signal recovery. Using an IF-TEM, we implement in hardware the first sub-Nyquist time-based sampler. We offer a feasible approach for accurately estimating the FRI parameters from IF-TEM data. The suggested hardware and reconstruction approach retrieves FRI parameters with an error of up to -25dB while operating at rates approximately 10 times lower than the Nyquist rate, paving the way to low-power ADC architectures.
Instant-NeRF: Instant On-Device Neural Radiance Field Training via Algorithm-Accelerator Co-Designed Near-Memory Processing
May 09, 2023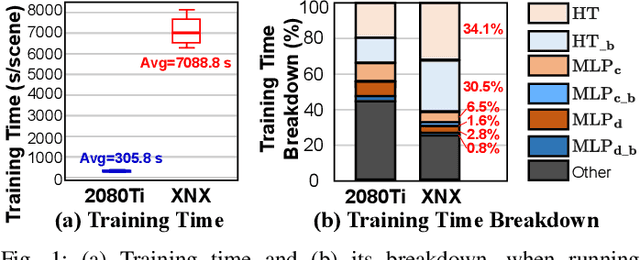
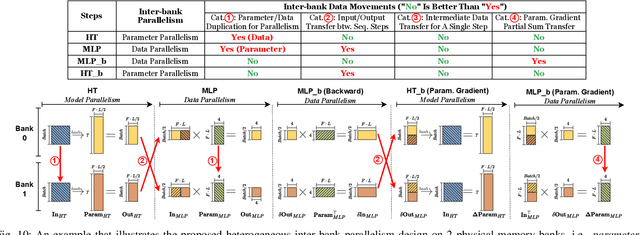
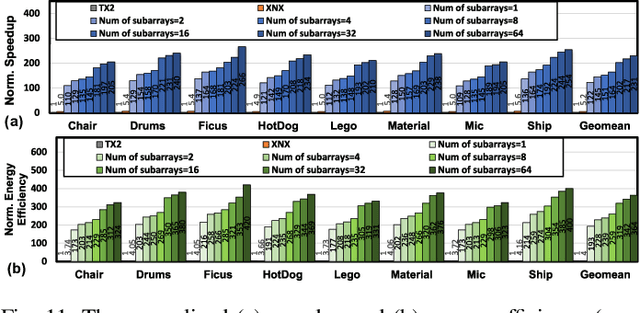
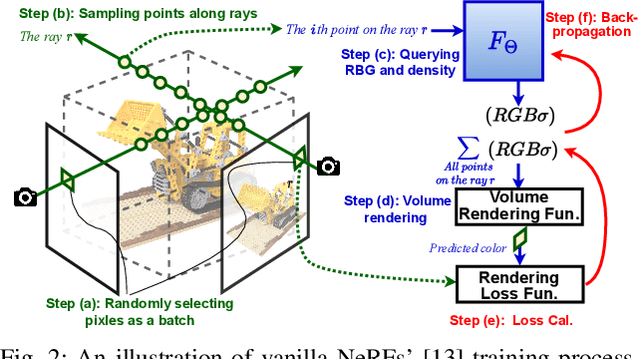
Instant on-device Neural Radiance Fields (NeRFs) are in growing demand for unleashing the promise of immersive AR/VR experiences, but are still limited by their prohibitive training time. Our profiling analysis reveals a memory-bound inefficiency in NeRF training. To tackle this inefficiency, near-memory processing (NMP) promises to be an effective solution, but also faces challenges due to the unique workloads of NeRFs, including the random hash table lookup, random point processing sequence, and heterogeneous bottleneck steps. Therefore, we propose the first NMP framework, Instant-NeRF, dedicated to enabling instant on-device NeRF training. Experiments on eight datasets consistently validate the effectiveness of Instant-NeRF.
Laplacian Convolutional Representation for Traffic Time Series Imputation
Dec 18, 2022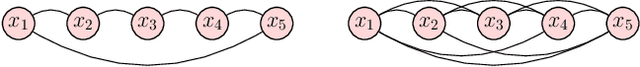
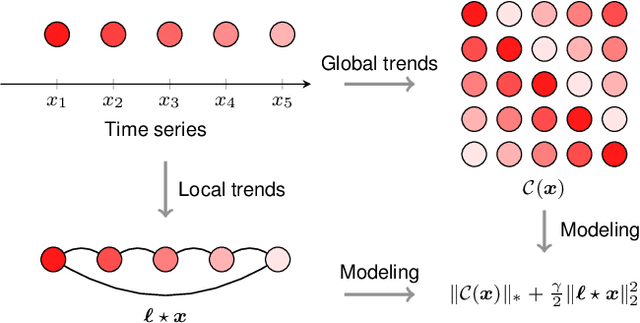
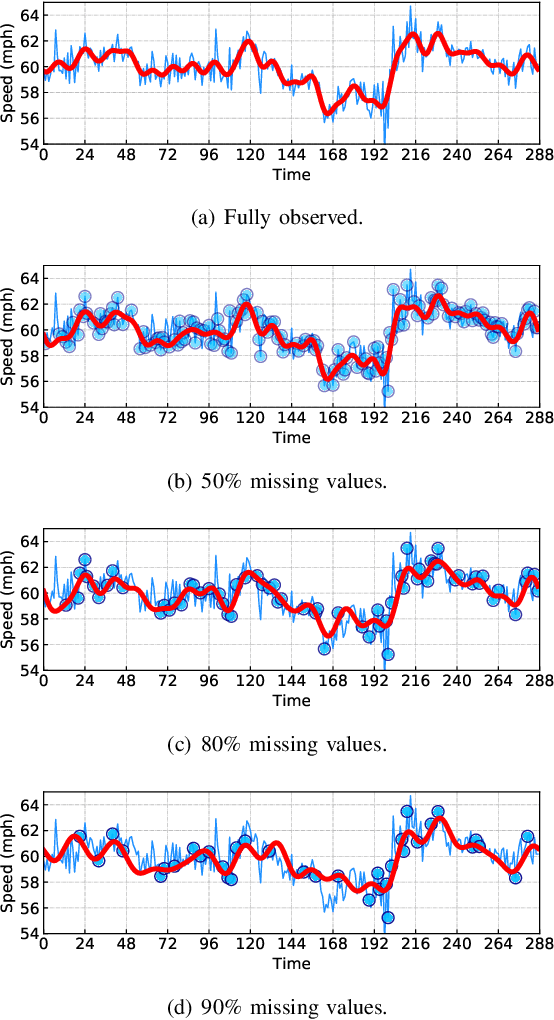
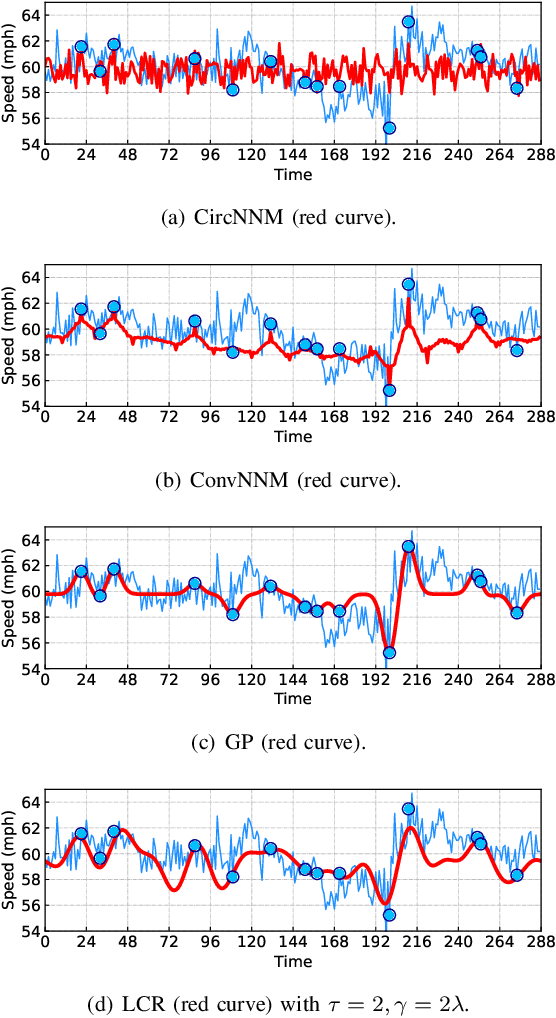
Spatiotemporal traffic data imputation is of great significance in intelligent transportation systems and data-driven decision-making processes. To make an accurate reconstruction from partially observed traffic data, we assert the importance of characterizing both global and local trends in traffic time series. In the literature, substantial prior works have demonstrated the effectiveness of utilizing low-rankness property of traffic data by matrix/tensor completion models. In this study, we first introduce a Laplacian kernel to temporal regularization for characterizing local trends in traffic time series, which can be formulated in the form of circular convolution. Then, we develop a low-rank Laplacian convolutional representation (LCR) model by putting the nuclear norm of a circulant matrix and the Laplacian temporal regularization together, which is proved to meet a unified framework that takes a fast Fourier transform (FFT) solution in a relatively low time complexity. Through extensive experiments on some traffic datasets, we demonstrate the superiority of LCR for imputing traffic time series of various time series behaviors (e.g., data noises and strong/weak periodicity). The proposed LCR model is an efficient and effective solution to large-scale traffic data imputation over the existing baseline models. Despite the LCR's application to time series data, the key modeling idea lies in bridging the low-rank models and the Laplacian regularization through FFT, which is also applicable to image inpainting. The adapted datasets and Python implementation are publicly available at https://github.com/xinychen/transdim.
Basis Function Encoding of Numerical Features in Factorization Machines for Improved Accuracy
May 23, 2023
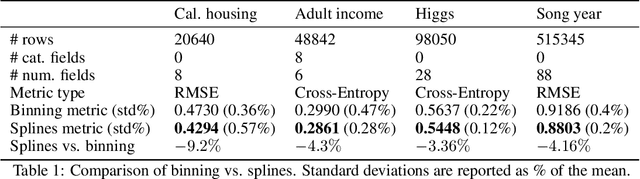
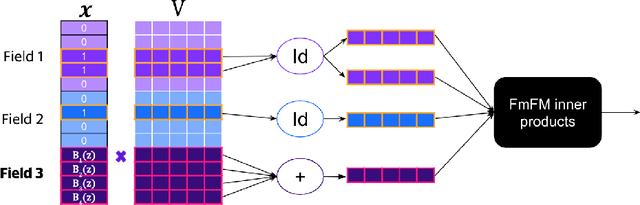

Factorization machine (FM) variants are widely used for large scale real-time content recommendation systems, since they offer an excellent balance between model accuracy and low computational costs for training and inference. These systems are trained on tabular data with both numerical and categorical columns. Incorporating numerical columns poses a challenge, and they are typically incorporated using a scalar transformation or binning, which can be either learned or chosen a-priori. In this work, we provide a systematic and theoretically-justified way to incorporate numerical features into FM variants by encoding them into a vector of function values for a set of functions of one's choice. We view factorization machines as approximators of segmentized functions, namely, functions from a field's value to the real numbers, assuming the remaining fields are assigned some given constants, which we refer to as the segment. From this perspective, we show that our technique yields a model that learns segmentized functions of the numerical feature spanned by the set of functions of one's choice, namely, the spanning coefficients vary between segments. Hence, to improve model accuracy we advocate the use of functions known to have strong approximation power, and offer the B-Spline basis due to its well-known approximation power, availability in software libraries, and efficiency. Our technique preserves fast training and inference, and requires only a small modification of the computational graph of an FM model. Therefore, it is easy to incorporate into an existing system to improve its performance. Finally, we back our claims with a set of experiments, including synthetic, performance evaluation on several data-sets, and an A/B test on a real online advertising system which shows improved performance.