 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Time series generation for option pricing on quantum computers using tensor network
Feb 27, 2024
Finance, especially option pricing, is a promising industrial field that might benefit from quantum computing. While quantum algorithms for option pricing have been proposed, it is desired to devise more efficient implementations of costly operations in the algorithms, one of which is preparing a quantum state that encodes a probability distribution of the underlying asset price. In particular, in pricing a path-dependent option, we need to generate a state encoding a joint distribution of the underlying asset price at multiple time points, which is more demanding. To address these issues, we propose a novel approach using Matrix Product State (MPS) as a generative model for time series generation. To validate our approach, taking the Heston model as a target, we conduct numerical experiments to generate time series in the model. Our findings demonstrate the capability of the MPS model to generate paths in the Heston model, highlighting its potential for path-dependent option pricing on quantum computers.
Protect and Extend -- Using GANs for Synthetic Data Generation of Time-Series Medical Records
Mar 01, 2024Preservation of private user data is of paramount importance for high Quality of Experience (QoE) and acceptability, particularly with services treating sensitive data, such as IT-based health services. Whereas anonymization techniques were shown to be prone to data re-identification, synthetic data generation has gradually replaced anonymization since it is relatively less time and resource-consuming and more robust to data leakage. Generative Adversarial Networks (GANs) have been used for generating synthetic datasets, especially GAN frameworks adhering to the differential privacy phenomena. This research compares state-of-the-art GAN-based models for synthetic data generation to generate time-series synthetic medical records of dementia patients which can be distributed without privacy concerns. Predictive modeling, autocorrelation, and distribution analysis are used to assess the Quality of Generating (QoG) of the generated data. The privacy preservation of the respective models is assessed by applying membership inference attacks to determine potential data leakage risks. Our experiments indicate the superiority of the privacy-preserving GAN (PPGAN) model over other models regarding privacy preservation while maintaining an acceptable level of QoG. The presented results can support better data protection for medical use cases in the future.
Evaluating Named Entity Recognition: Comparative Analysis of Mono- and Multilingual Transformer Models on Brazilian Corporate Earnings Call Transcriptions
Mar 18, 2024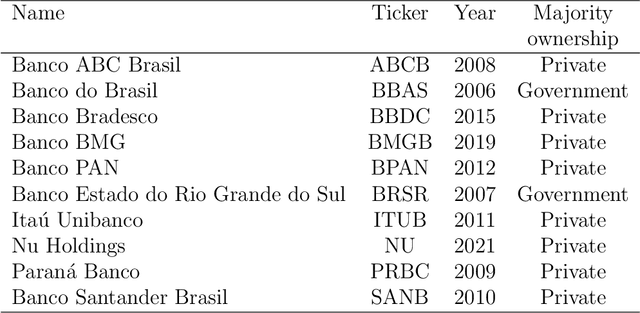
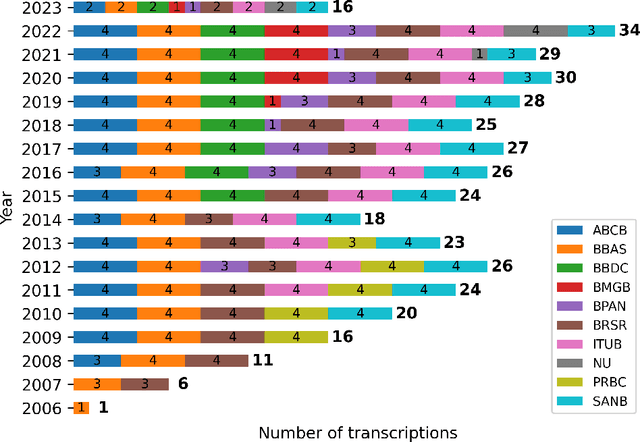

Named Entity Recognition (NER) is a Natural Language Processing technique for extracting information from textual documents. However, much of the existing research on NER has been centered around English-language documents, leaving a gap in the availability of datasets tailored to the financial domain in Portuguese. This study addresses the need for NER within the financial domain, focusing on Portuguese-language texts extracted from earnings call transcriptions of Brazilian banks. By curating a comprehensive dataset comprising 384 transcriptions and leveraging weak supervision techniques for annotation, we evaluate the performance of monolingual models trained on Portuguese (BERTimbau and PTT5) and multilingual models (mBERT and mT5). Notably, we introduce a novel approach that reframes the token classification task as a text generation problem, enabling fine-tuning and evaluation of T5 models. Following the fine-tuning of the models, we conduct an evaluation on the test dataset, employing performance and error metrics. Our findings reveal that BERT-based models consistently outperform T5-based models. Furthermore, while the multilingual models exhibit comparable macro F1-scores, BERTimbau demonstrates superior performance over PTT5. A manual analysis of sentences generated by PTT5 and mT5 unveils a degree of similarity ranging from 0.89 to 1.0, between the original and generated sentences. However, critical errors emerge as both models exhibit discrepancies, such as alterations to monetary and percentage values, underscoring the importance of accuracy and consistency in the financial domain. Despite these challenges, PTT5 and mT5 achieve impressive macro F1-scores of 98.52% and 98.85%, respectively, with our proposed approach. Furthermore, our study sheds light on notable disparities in memory and time consumption for inference across the models.
TnT-LLM: Text Mining at Scale with Large Language Models
Mar 18, 2024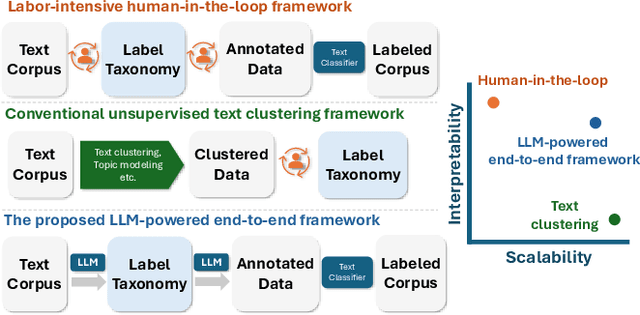
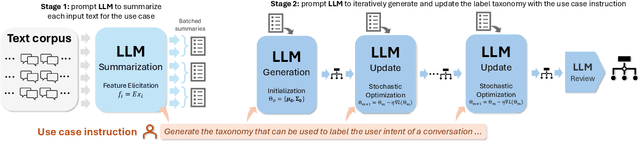
Transforming unstructured text into structured and meaningful forms, organized by useful category labels, is a fundamental step in text mining for downstream analysis and application. However, most existing methods for producing label taxonomies and building text-based label classifiers still rely heavily on domain expertise and manual curation, making the process expensive and time-consuming. This is particularly challenging when the label space is under-specified and large-scale data annotations are unavailable. In this paper, we address these challenges with Large Language Models (LLMs), whose prompt-based interface facilitates the induction and use of large-scale pseudo labels. We propose TnT-LLM, a two-phase framework that employs LLMs to automate the process of end-to-end label generation and assignment with minimal human effort for any given use-case. In the first phase, we introduce a zero-shot, multi-stage reasoning approach which enables LLMs to produce and refine a label taxonomy iteratively. In the second phase, LLMs are used as data labelers that yield training samples so that lightweight supervised classifiers can be reliably built, deployed, and served at scale. We apply TnT-LLM to the analysis of user intent and conversational domain for Bing Copilot (formerly Bing Chat), an open-domain chat-based search engine. Extensive experiments using both human and automatic evaluation metrics demonstrate that TnT-LLM generates more accurate and relevant label taxonomies when compared against state-of-the-art baselines, and achieves a favorable balance between accuracy and efficiency for classification at scale. We also share our practical experiences and insights on the challenges and opportunities of using LLMs for large-scale text mining in real-world applications.
Histo-Genomic Knowledge Distillation For Cancer Prognosis From Histopathology Whole Slide Images
Mar 18, 2024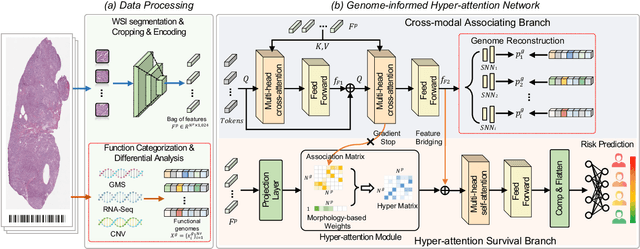
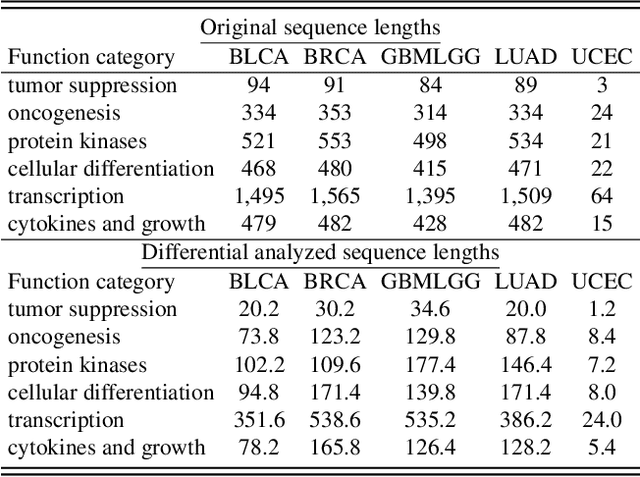
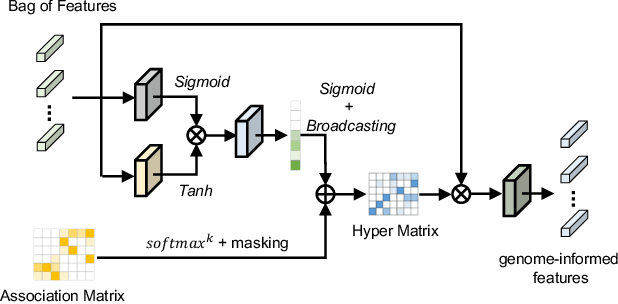
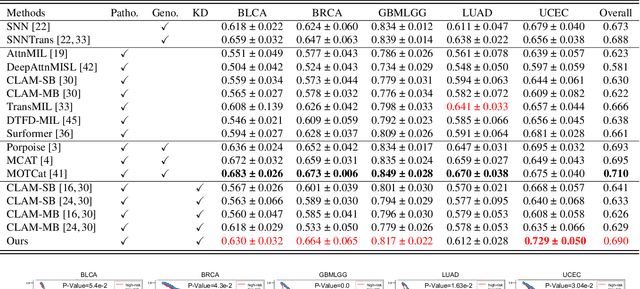
Histo-genomic multi-modal methods have recently emerged as a powerful paradigm, demonstrating significant potential for improving cancer prognosis. However, genome sequencing, unlike histopathology imaging, is still not widely accessible in underdeveloped regions, limiting the application of these multi-modal approaches in clinical settings. To address this, we propose a novel Genome-informed Hyper-Attention Network, termed G-HANet, which is capable of effectively distilling the histo-genomic knowledge during training to elevate uni-modal whole slide image (WSI)-based inference for the first time. Compared with traditional knowledge distillation methods (i.e., teacher-student architecture) in other tasks, our end-to-end model is superior in terms of training efficiency and learning cross-modal interactions. Specifically, the network comprises the cross-modal associating branch (CAB) and hyper-attention survival branch (HSB). Through the genomic data reconstruction from WSIs, CAB effectively distills the associations between functional genotypes and morphological phenotypes and offers insights into the gene expression profiles in the feature space. Subsequently, HSB leverages the distilled histo-genomic associations as well as the generated morphology-based weights to achieve the hyper-attention modeling of the patients from both histopathology and genomic perspectives to improve cancer prognosis. Extensive experiments are conducted on five TCGA benchmarking datasets and the results demonstrate that G-HANet significantly outperforms the state-of-the-art WSI-based methods and achieves competitive performance with genome-based and multi-modal methods. G-HANet is expected to be explored as a useful tool by the research community to address the current bottleneck of insufficient histo-genomic data pairing in the context of cancer prognosis and precision oncology.
SceneSense: Diffusion Models for 3D Occupancy Synthesis from Partial Observation
Mar 18, 2024
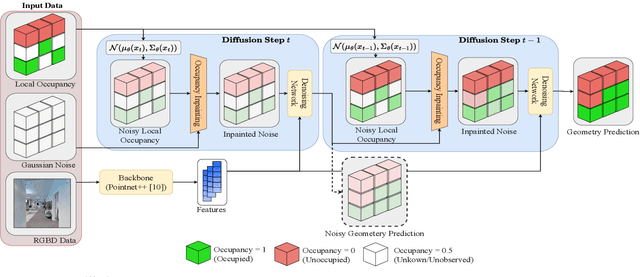
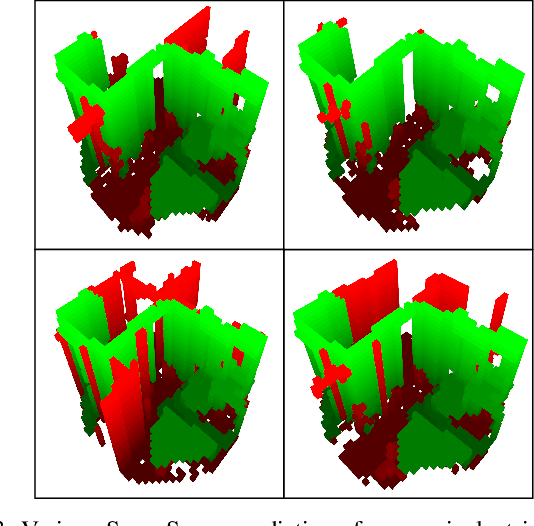

When exploring new areas, robotic systems generally exclusively plan and execute controls over geometry that has been directly measured. When entering space that was previously obstructed from view such as turning corners in hallways or entering new rooms, robots often pause to plan over the newly observed space. To address this we present SceneScene, a real-time 3D diffusion model for synthesizing 3D occupancy information from partial observations that effectively predicts these occluded or out of view geometries for use in future planning and control frameworks. SceneSense uses a running occupancy map and a single RGB-D camera to generate predicted geometry around the platform at runtime, even when the geometry is occluded or out of view. Our architecture ensures that SceneSense never overwrites observed free or occupied space. By preserving the integrity of the observed map, SceneSense mitigates the risk of corrupting the observed space with generative predictions. While SceneSense is shown to operate well using a single RGB-D camera, the framework is flexible enough to extend to additional modalities. SceneSense operates as part of any system that generates a running occupancy map `out of the box', removing conditioning from the framework. Alternatively, for maximum performance in new modalities, the perception backbone can be replaced and the model retrained for inference in new applications. Unlike existing models that necessitate multiple views and offline scene synthesis, or are focused on filling gaps in observed data, our findings demonstrate that SceneSense is an effective approach to estimating unobserved local occupancy information at runtime. Local occupancy predictions from SceneSense are shown to better represent the ground truth occupancy distribution during the test exploration trajectories than the running occupancy map.
TRELM: Towards Robust and Efficient Pre-training for Knowledge-Enhanced Language Models
Mar 17, 2024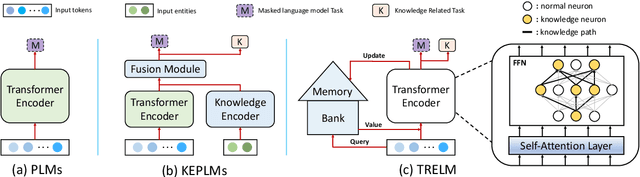

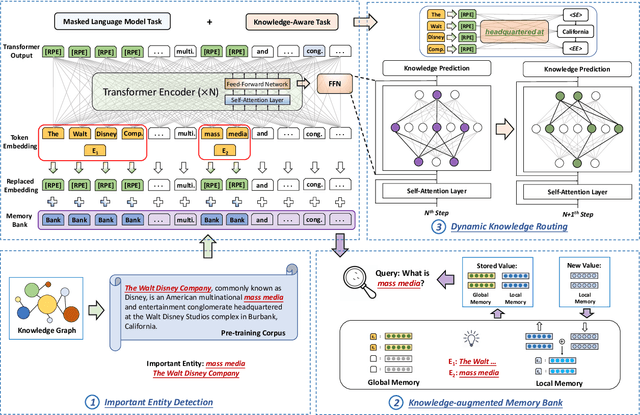
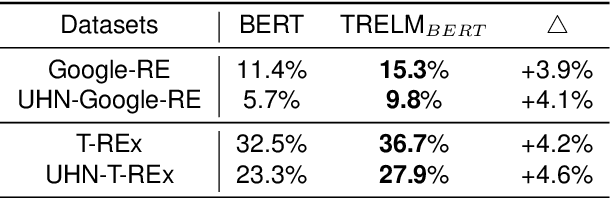
KEPLMs are pre-trained models that utilize external knowledge to enhance language understanding. Previous language models facilitated knowledge acquisition by incorporating knowledge-related pre-training tasks learned from relation triples in knowledge graphs. However, these models do not prioritize learning embeddings for entity-related tokens. Moreover, updating the entire set of parameters in KEPLMs is computationally demanding. This paper introduces TRELM, a Robust and Efficient Pre-training framework for Knowledge-Enhanced Language Models. We observe that entities in text corpora usually follow the long-tail distribution, where the representations of some entities are suboptimally optimized and hinder the pre-training process for KEPLMs. To tackle this, we employ a robust approach to inject knowledge triples and employ a knowledge-augmented memory bank to capture valuable information. Furthermore, updating a small subset of neurons in the feed-forward networks (FFNs) that store factual knowledge is both sufficient and efficient. Specifically, we utilize dynamic knowledge routing to identify knowledge paths in FFNs and selectively update parameters during pre-training. Experimental results show that TRELM reduces pre-training time by at least 50% and outperforms other KEPLMs in knowledge probing tasks and multiple knowledge-aware language understanding tasks.
TimeSeriesBench: An Industrial-Grade Benchmark for Time Series Anomaly Detection Models
Feb 26, 2024Driven by the proliferation of real-world application scenarios and scales, time series anomaly detection (TSAD) has attracted considerable scholarly and industrial interest. However, existing algorithms exhibit a gap in terms of training paradigm, online detection paradigm, and evaluation criteria when compared to the actual needs of real-world industrial systems. Firstly, current algorithms typically train a specific model for each individual time series. In a large-scale online system with tens of thousands of curves, maintaining such a multitude of models is impractical. The performance of using merely one single unified model to detect anomalies remains unknown. Secondly, most TSAD models are trained on the historical part of a time series and are tested on its future segment. In distributed systems, however, there are frequent system deployments and upgrades, with new, previously unseen time series emerging daily. The performance of testing newly incoming unseen time series on current TSAD algorithms remains unknown. Lastly, although some papers have conducted detailed surveys, the absence of an online evaluation platform prevents answering questions like "Who is the best at anomaly detection at the current stage?" In this paper, we propose TimeSeriesBench, an industrial-grade benchmark that we continuously maintain as a leaderboard. On this leaderboard, we assess the performance of existing algorithms across more than 168 evaluation settings combining different training and testing paradigms, evaluation metrics and datasets. Through our comprehensive analysis of the results, we provide recommendations for the future design of anomaly detection algorithms. To address known issues with existing public datasets, we release an industrial dataset to the public together with TimeSeriesBench. All code, data, and the online leaderboard have been made publicly available.
An Improved Strategy for Blood Glucose Control Using Multi-Step Deep Reinforcement Learning
Mar 15, 2024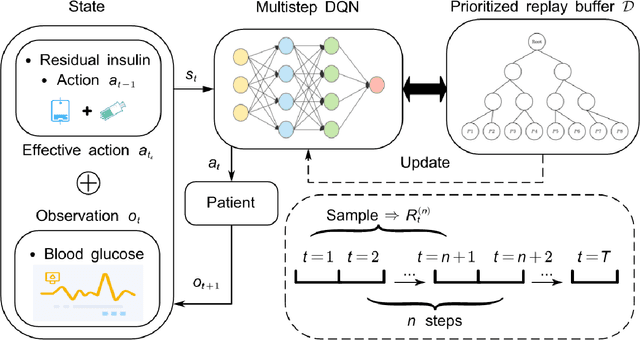
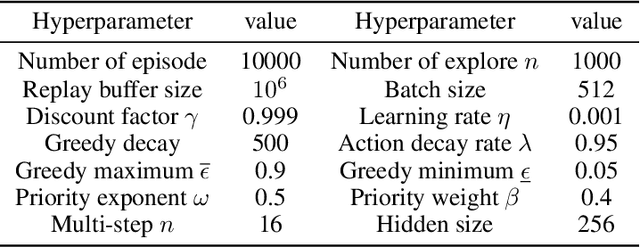
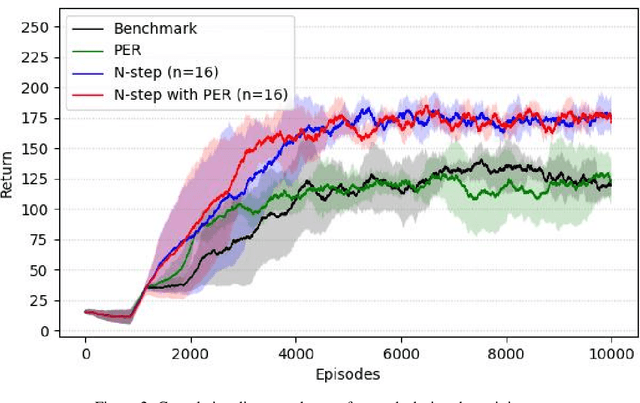
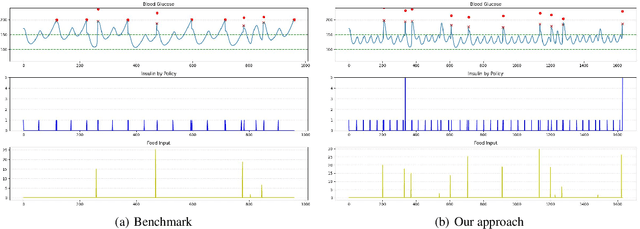
Blood Glucose (BG) control involves keeping an individual's BG within a healthy range through extracorporeal insulin injections is an important task for people with type 1 diabetes. However,traditional patient self-management is cumbersome and risky. Recent research has been devoted to exploring individualized and automated BG control approaches, among which Deep Reinforcement Learning (DRL) shows potential as an emerging approach. In this paper, we use an exponential decay model of drug concentration to convert the formalization of the BG control problem, which takes into account the delay and prolongedness of drug effects, from a PAE-POMDP (Prolonged Action Effect-Partially Observable Markov Decision Process) to a MDP, and we propose a novel multi-step DRL-based algorithm to solve the problem. The Prioritized Experience Replay (PER) sampling method is also used in it. Compared to single-step bootstrapped updates, multi-step learning is more efficient and reduces the influence from biasing targets. Our proposed method converges faster and achieves higher cumulative rewards compared to the benchmark in the same training environment, and improves the time-in-range (TIR), the percentage of time the patient's BG is within the target range, in the evaluation phase. Our work validates the effectiveness of multi-step reinforcement learning in BG control, which may help to explore the optimal glycemic control measure and improve the survival of diabetic patients.
Reinforcement Learning with Elastic Time Steps
Feb 22, 2024Traditional Reinforcement Learning (RL) algorithms are usually applied in robotics to learn controllers that act with a fixed control rate. Given the discrete nature of RL algorithms, they are oblivious to the effects of the choice of control rate: finding the correct control rate can be difficult and mistakes often result in excessive use of computing resources or even lack of convergence. We propose Soft Elastic Actor-Critic (SEAC), a novel off-policy actor-critic algorithm to address this issue. SEAC implements elastic time steps, time steps with a known, variable duration, which allow the agent to change its control frequency to adapt to the situation. In practice, SEAC applies control only when necessary, minimizing computational resources and data usage. We evaluate SEAC's capabilities in simulation in a Newtonian kinematics maze navigation task and on a 3D racing video game, Trackmania. SEAC outperforms the SAC baseline in terms of energy efficiency and overall time management, and most importantly without the need to identify a control frequency for the learned controller. SEAC demonstrated faster and more stable training speeds than SAC, especially at control rates where SAC struggled to converge. We also compared SEAC with a similar approach, the Continuous-Time Continuous-Options (CTCO) model, and SEAC resulted in better task performance. These findings highlight the potential of SEAC for practical, real-world RL applications in robotics.