 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A robust multi-domain network for short-scanning amyloid PET reconstruction
May 17, 2023
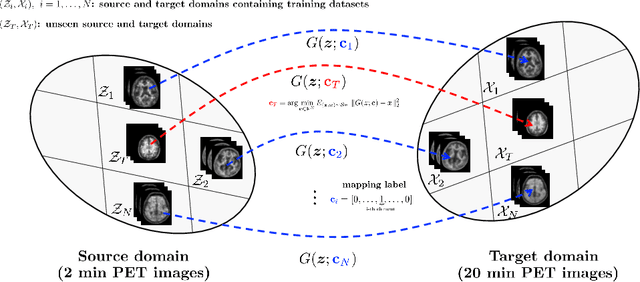
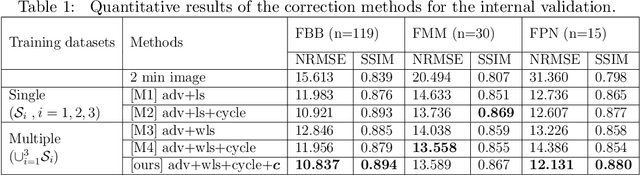
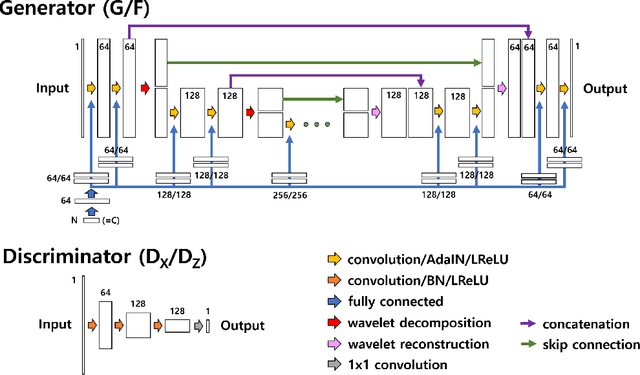
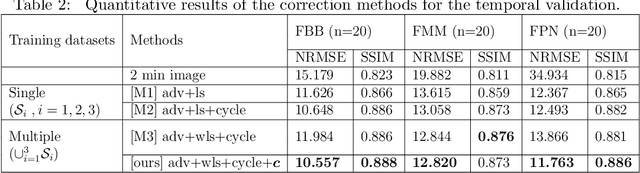
This paper presents a robust multi-domain network designed to restore low-quality amyloid PET images acquired in a short period of time. The proposed method is trained on pairs of PET images from short (2 minutes) and standard (20 minutes) scanning times, sourced from multiple domains. Learning relevant image features between these domains with a single network is challenging. Our key contribution is the introduction of a mapping label, which enables effective learning of specific representations between different domains. The network, trained with various mapping labels, can efficiently correct amyloid PET datasets in multiple training domains and unseen domains, such as those obtained with new radiotracers, acquisition protocols, or PET scanners. Internal, temporal, and external validations demonstrate the effectiveness of the proposed method. Notably, for external validation datasets from unseen domains, the proposed method achieved comparable or superior results relative to methods trained with these datasets, in terms of quantitative metrics such as normalized root mean-square error and structure similarity index measure. Two nuclear medicine physicians evaluated the amyloid status as positive or negative for the external validation datasets, with accuracies of 0.970 and 0.930 for readers 1 and 2, respectively.
Imbalanced Aircraft Data Anomaly Detection
May 17, 2023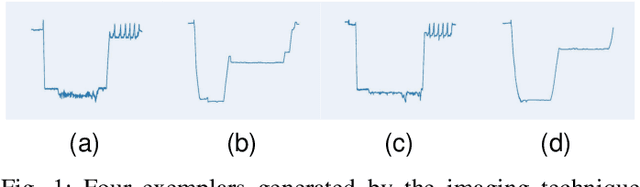
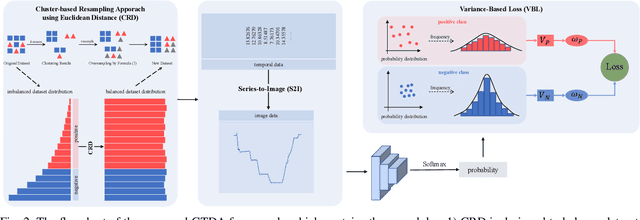
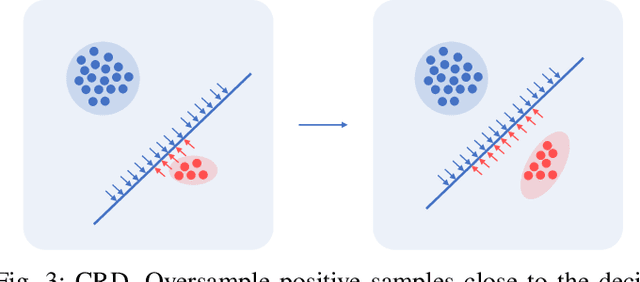
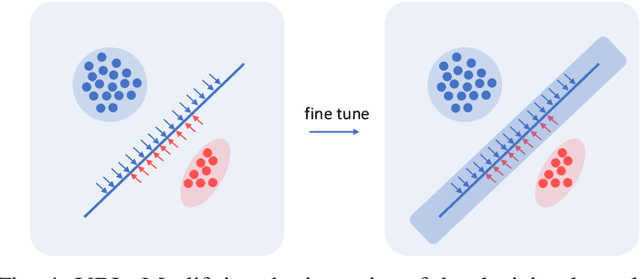
Anomaly detection in temporal data from sensors under aviation scenarios is a practical but challenging task: 1) long temporal data is difficult to extract contextual information with temporal correlation; 2) the anomalous data are rare in time series, causing normal/abnormal imbalance in anomaly detection, making the detector classification degenerate or even fail. To remedy the aforementioned problems, we propose a Graphical Temporal Data Analysis (GTDA) framework. It consists three modules, named Series-to-Image (S2I), Cluster-based Resampling Approach using Euclidean Distance (CRD) and Variance-Based Loss (VBL). Specifically, for better extracts global information in temporal data from sensors, S2I converts the data to curve images to demonstrate abnormalities in data changes. CRD and VBL balance the classification to mitigate the unequal distribution of classes. CRD extracts minority samples with similar features to majority samples by clustering and over-samples them. And VBL fine-tunes the decision boundary by balancing the fitting degree of the network to each class. Ablation experiments on the Flights dataset indicate the effectiveness of CRD and VBL on precision and recall, respectively. Extensive experiments demonstrate the synergistic advantages of CRD and VBL on F1-score on Flights and three other temporal datasets.
Stop Uploading Test Data in Plain Text: Practical Strategies for Mitigating Data Contamination by Evaluation Benchmarks
May 17, 2023Data contamination has become especially prevalent and challenging with the rise of models pretrained on very large, automatically-crawled corpora. For closed models, the training data becomes a trade secret, and even for open models, it is not trivial to ascertain whether a particular test instance has been compromised. Strategies such as live leaderboards with hidden answers, or using test data which is guaranteed to be unseen, are expensive and become fragile with time. Assuming that all relevant actors value clean test data and will cooperate to mitigate data contamination, what can be done? We propose three strategies that can make a difference: (1) Test data made public should be encrypted with a public key and licensed to disallow derivative distribution; (2) demand training exclusion controls from closed API holders, and protect your test data by refusing to evaluate until demands are met; (3) in case of test data based on internet text, avoid data which appears with its solution on the internet, and release the context of internet-derived data along with the data. These strategies are practical and can be effective in preventing data contamination and allowing trustworthy evaluation of models' capabilities.
MultiPlaneNeRF: Neural Radiance Field with Non-Trainable Representation
May 17, 2023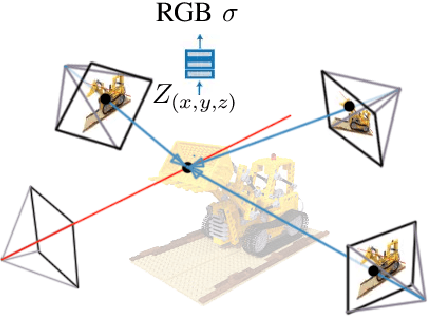
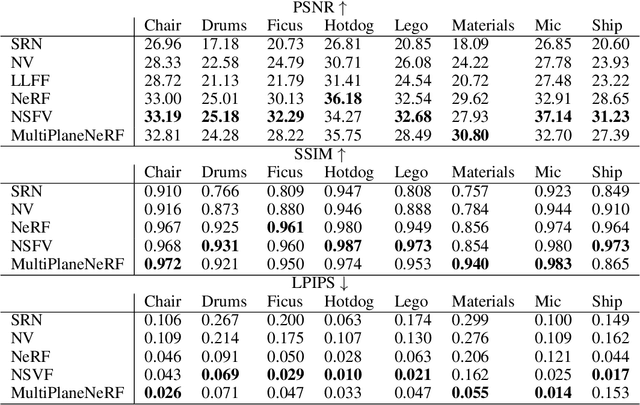


NeRF is a popular model that efficiently represents 3D objects from 2D images. However, vanilla NeRF has a few important limitations. NeRF must be trained on each object separately. The training time is long since we encode the object's shape and color in neural network weights. Moreover, NeRF does not generalize well to unseen data. In this paper, we present MultiPlaneNeRF -- a first model that simultaneously solves all the above problems. Our model works directly on 2D images. We project 3D points on 2D images to produce non-trainable representations. The projection step is not parametrized, and a very shallow decoder can efficiently process the representation. Using existing images as part of NeRF can significantly reduce the number of parameters since we train only a small implicit decoder. Furthermore, we can train MultiPlaneNeRF on a large data set and force our implicit decoder to generalize across many objects. Consequently, we can only replace the 2D images (without additional training) to produce a NeRF representation of the new object. In the experimental section, we demonstrate that MultiPlaneNeRF achieves comparable results to state-of-the-art models for synthesizing new views and has generalization properties.
Inertial-based Navigation by Polynomial Optimization: Inertial-Magnetic Attitude Estimation
May 17, 2023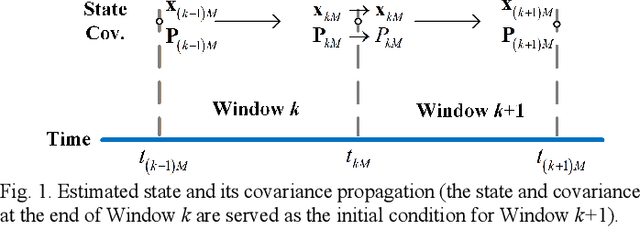
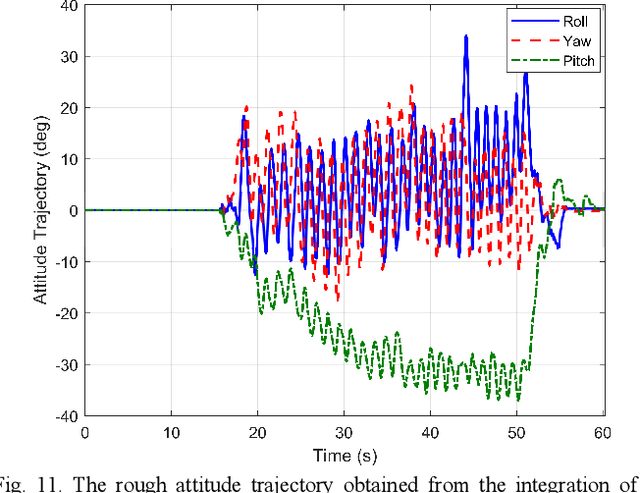
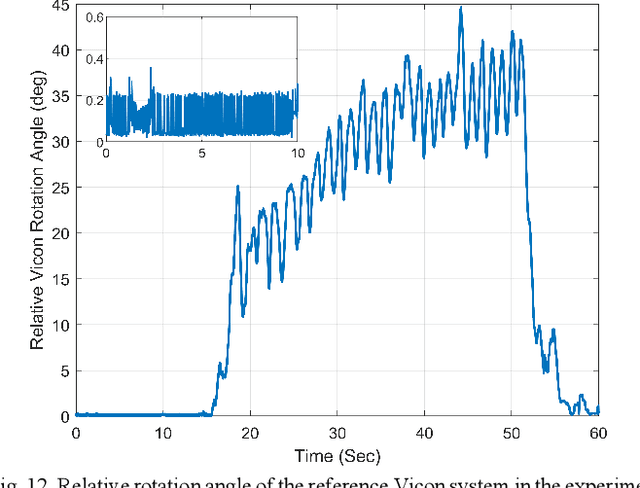
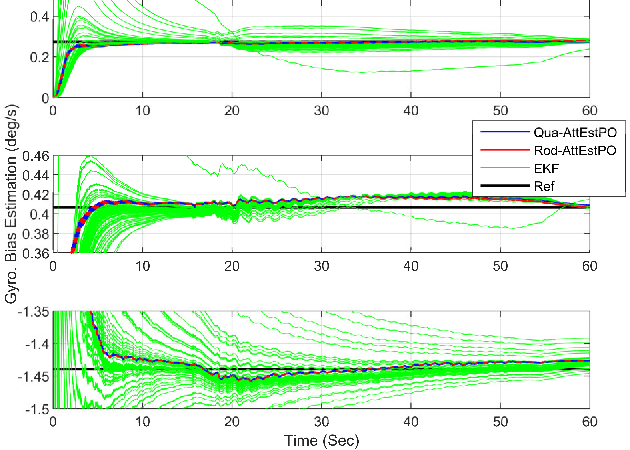
Inertial-based navigation refers to the navigation methods or systems that have inertial information or sensors as the core part and integrate a spectrum of other kinds of sensors for enhanced performance. Through a series of papers, the authors attempt to explore information blending of inertial-based navigation by a polynomial optimization method. The basic idea is to model rigid motions as finite-order polynomials and then attacks the involved navigation problems by optimally solving their coefficients, taking into considerations the constraints posed by inertial sensors and others. In the current paper, a continuous-time attitude estimation approach is proposed, which transforms the attitude estimation into a constant parameter determination problem by the polynomial optimization. Specifically, the continuous attitude is first approximated by a Chebyshev polynomial, of which the unknown Chebyshev coefficients are determined by minimizing the weighted residuals of initial conditions, dynamics and measurements. We apply the derived estimator to the attitude estimation with the magnetic and inertial sensors. Simulation and field tests show that the estimator has much better stability and faster convergence than the traditional extended Kalman filter does, especially in the challenging large initial state error scenarios.
What Matters in Reinforcement Learning for Tractography
May 17, 2023
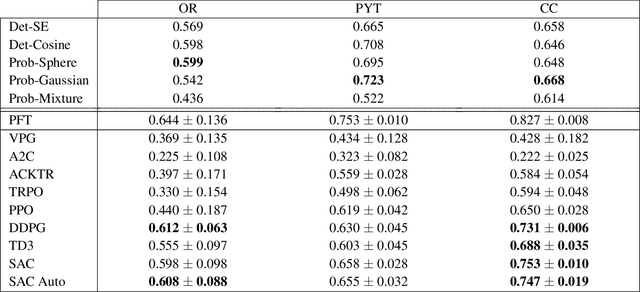
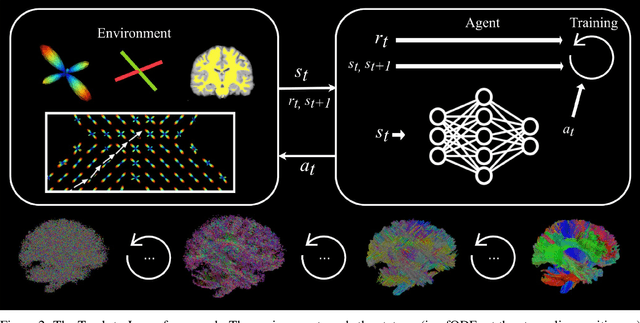
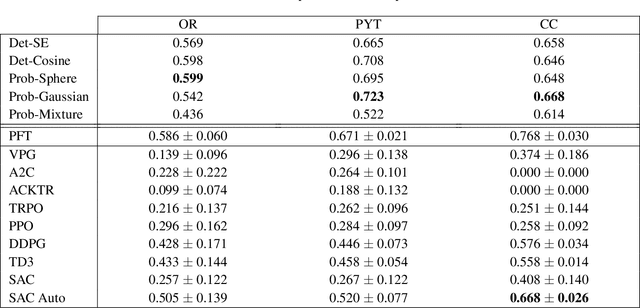
Recently, deep reinforcement learning (RL) has been proposed to learn the tractography procedure and train agents to reconstruct the structure of the white matter without manually curated reference streamlines. While the performances reported were competitive, the proposed framework is complex, and little is still known about the role and impact of its multiple parts. In this work, we thoroughly explore the different components of the proposed framework, such as the choice of the RL algorithm, seeding strategy, the input signal and reward function, and shed light on their impact. Approximately 7,400 models were trained for this work, totalling nearly 41,000 hours of GPU time. Our goal is to guide researchers eager to explore the possibilities of deep RL for tractography by exposing what works and what does not work with the category of approach. As such, we ultimately propose a series of recommendations concerning the choice of RL algorithm, the input to the agents, the reward function and more to help future work using reinforcement learning for tractography. We also release the open source codebase, trained models, and datasets for users and researchers wanting to explore reinforcement learning for tractography.
OSTA: One-shot Task-adaptive Channel Selection for Semantic Segmentation of Multichannel Images
May 08, 2023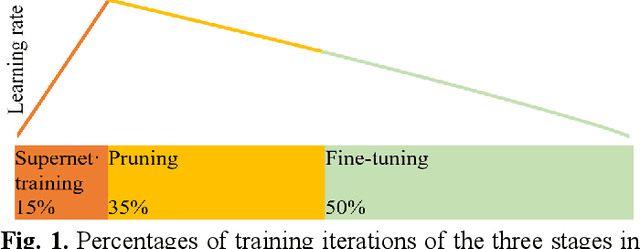
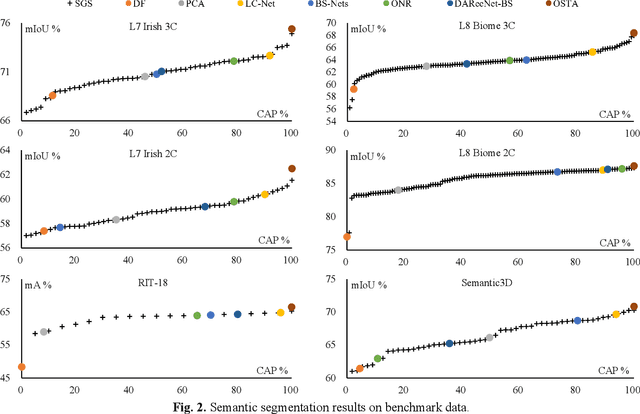

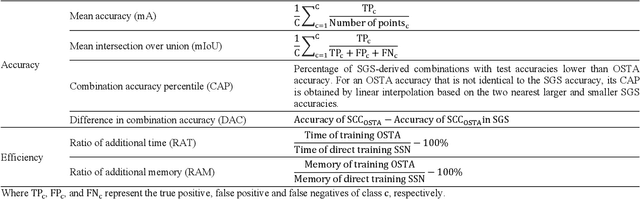
Semantic segmentation of multichannel images is a fundamental task for many applications. Selecting an appropriate channel combination from the original multichannel image can improve the accuracy of semantic segmentation and reduce the cost of data storage, processing and future acquisition. Existing channel selection methods typically use a reasonable selection procedure to determine a desirable channel combination, and then train a semantic segmentation network using that combination. In this study, the concept of pruning from a supernet is used for the first time to integrate the selection of channel combination and the training of a semantic segmentation network. Based on this concept, a One-Shot Task-Adaptive (OSTA) channel selection method is proposed for the semantic segmentation of multichannel images. OSTA has three stages, namely the supernet training stage, the pruning stage and the fine-tuning stage. The outcomes of six groups of experiments (L7Irish3C, L7Irish2C, L8Biome3C, L8Biome2C, RIT-18 and Semantic3D) demonstrated the effectiveness and efficiency of OSTA. OSTA achieved the highest segmentation accuracies in all tests (62.49% (mIoU), 75.40% (mIoU), 68.38% (mIoU), 87.63% (mIoU), 66.53% (mA) and 70.86% (mIoU), respectively). It even exceeded the highest accuracies of exhaustive tests (61.54% (mIoU), 74.91% (mIoU), 67.94% (mIoU), 87.32% (mIoU), 65.32% (mA) and 70.27% (mIoU), respectively), where all possible channel combinations were tested. All of this can be accomplished within a predictable and relatively efficient timeframe, ranging from 101.71% to 298.1% times the time required to train the segmentation network alone. In addition, there were interesting findings that were deemed valuable for several fields.
Pushing the Boundaries of Tractable Multiperspective Reasoning: A Deduction Calculus for Standpoint EL+
May 11, 2023
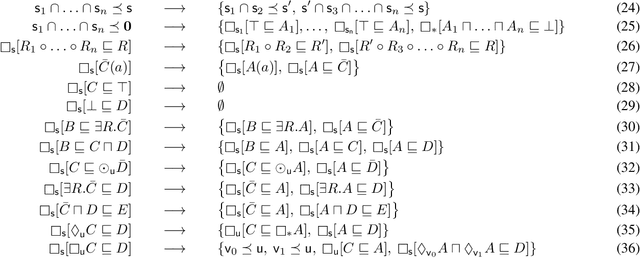

Standpoint EL is a multi-modal extension of the popular description logic EL that allows for the integrated representation of domain knowledge relative to diverse standpoints or perspectives. Advantageously, its satisfiability problem has recently been shown to be in PTime, making it a promising framework for large-scale knowledge integration. In this paper, we show that we can further push the expressivity of this formalism, arriving at an extended logic, called Standpoint EL+, which allows for axiom negation, role chain axioms, self-loops, and other features, while maintaining tractability. This is achieved by designing a satisfiability-checking deduction calculus, which at the same time addresses the need for practical algorithms. We demonstrate the feasibility of our calculus by presenting a prototypical Datalog implementation of its deduction rules.
Fast Pareto Optimization Using Sliding Window Selection
May 11, 2023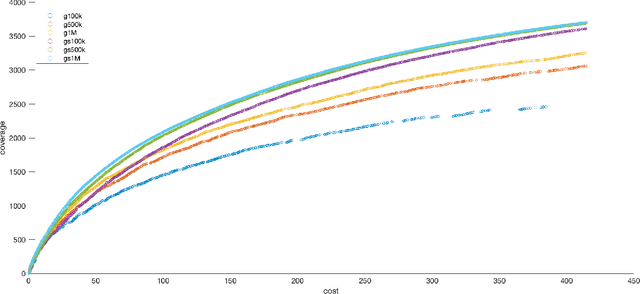
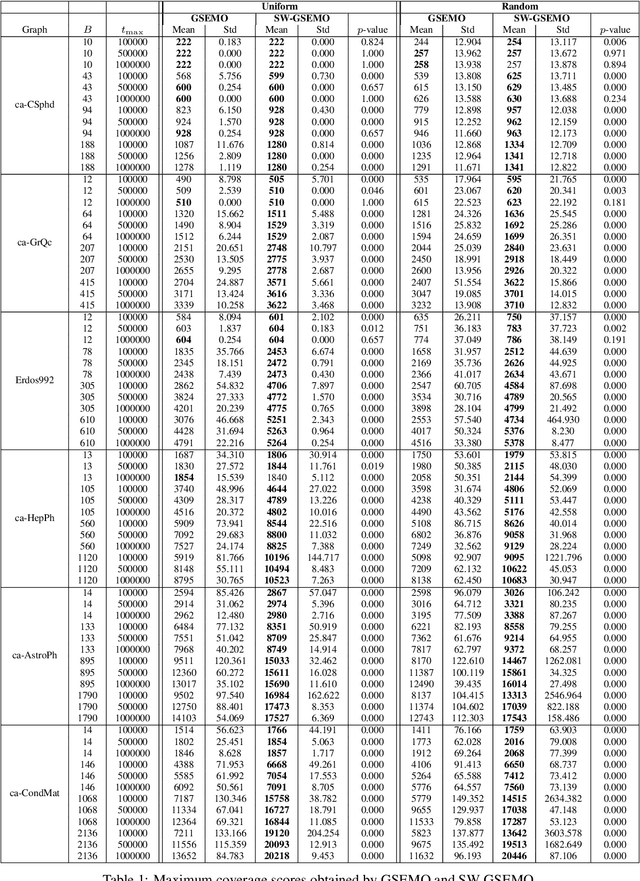
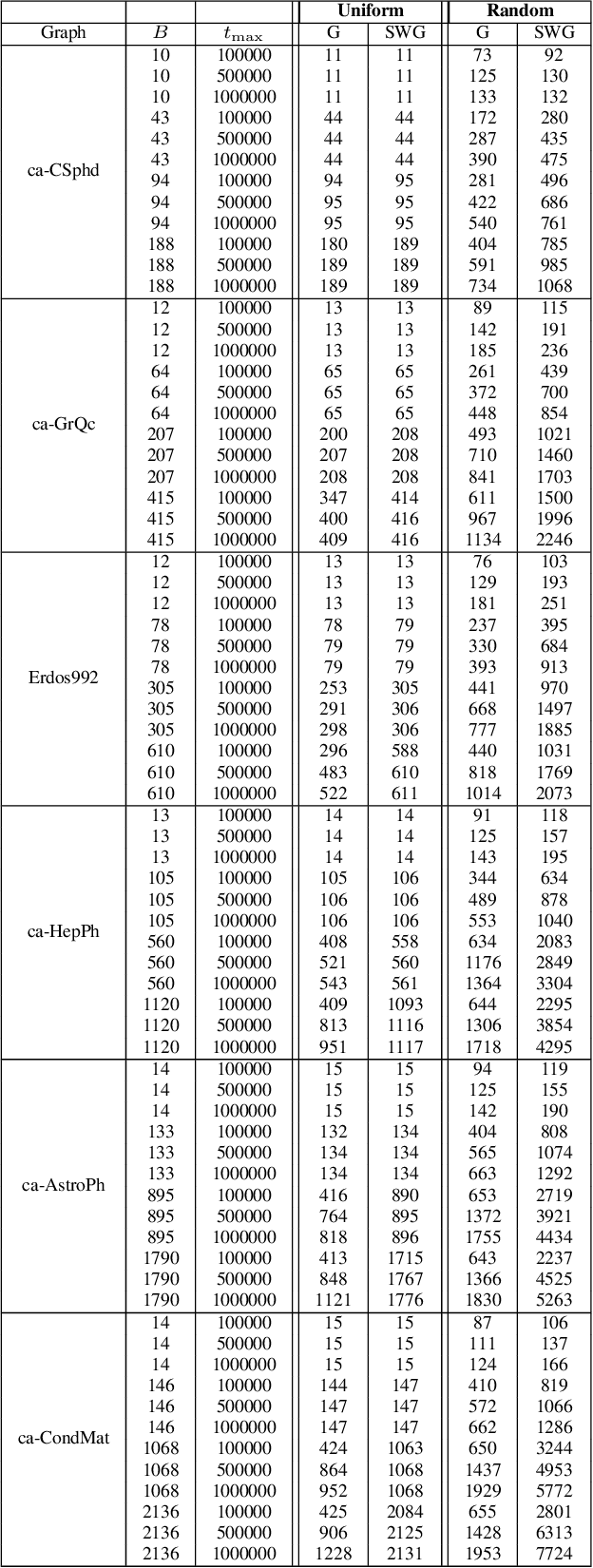
Pareto optimization using evolutionary multi-objective algorithms has been widely applied to solve constrained submodular optimization problems. A crucial factor determining the runtime of the used evolutionary algorithms to obtain good approximations is the population size of the algorithms which grows with the number of trade-offs that the algorithms encounter. In this paper, we introduce a sliding window speed up technique for recently introduced algorithms. We prove that our technique eliminates the population size as a crucial factor negatively impacting the runtime and achieves the same theoretical performance guarantees as previous approaches within less computation time. Our experimental investigations for the classical maximum coverage problem confirms that our sliding window technique clearly leads to better results for a wide range of instances and constraint settings.
Integrating Holistic and Local Information to Estimate Emotional Reaction Intensity
May 09, 2023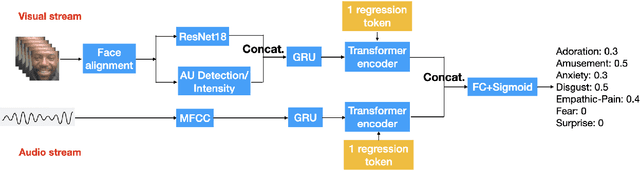
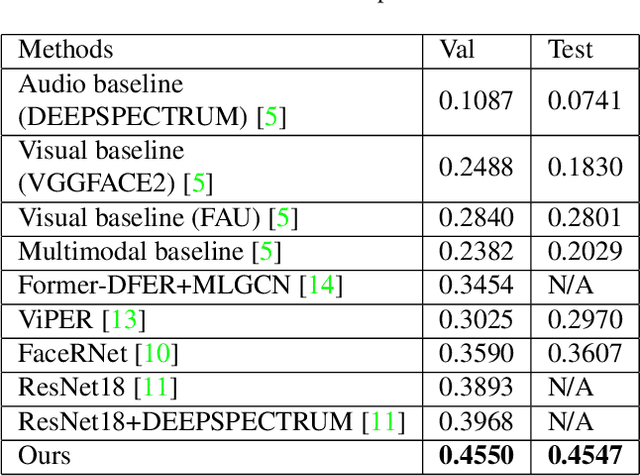
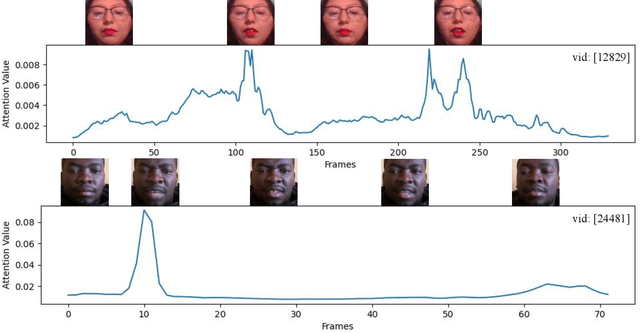
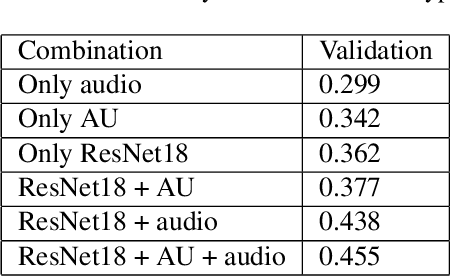
Video-based Emotional Reaction Intensity (ERI) estimation measures the intensity of subjects' reactions to stimuli along several emotional dimensions from videos of the subject as they view the stimuli. We propose a multi-modal architecture for video-based ERI combining video and audio information. Video input is encoded spatially first, frame-by-frame, combining features encoding holistic aspects of the subjects' facial expressions and features encoding spatially localized aspects of their expressions. Input is then combined across time: from frame-to-frame using gated recurrent units (GRUs), then globally by a transformer. We handle variable video length with a regression token that accumulates information from all frames into a fixed-dimensional vector independent of video length. Audio information is handled similarly: spectral information extracted within each frame is integrated across time by a cascade of GRUs and a transformer with regression token. The video and audio regression tokens' outputs are merged by concatenation, then input to a final fully connected layer producing intensity estimates. Our architecture achieved excellent performance on the Hume-Reaction dataset in the ERI Esimation Challenge of the Fifth Competition on Affective Behavior Analysis in-the-Wild (ABAW5). The Pearson Correlation Coefficients between estimated and subject self-reported scores, averaged across all emotions, were 0.455 on the validation dataset and 0.4547 on the test dataset, well above the baselines. The transformer's self-attention mechanism enables our architecture to focus on the most critical video frames regardless of length. Ablation experiments establish the advantages of combining holistic/local features and of multi-modal integration. Code available at https://github.com/HKUST-NISL/ABAW5.