 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A two stages Deep Learning Architecture for Model Reduction of Parametric Time-Dependent Problems
Jan 25, 2023
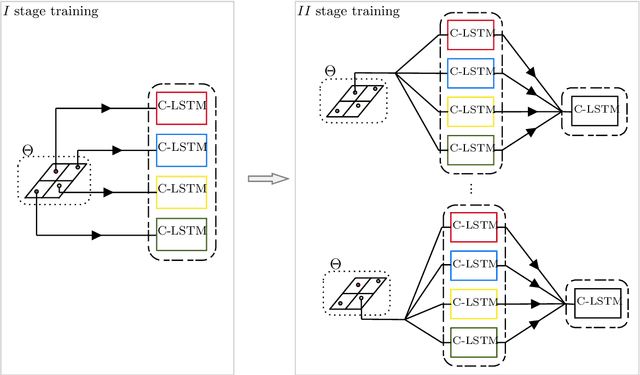
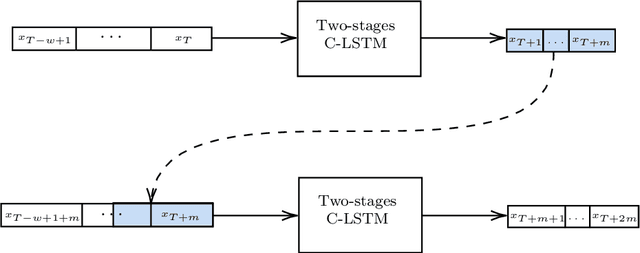
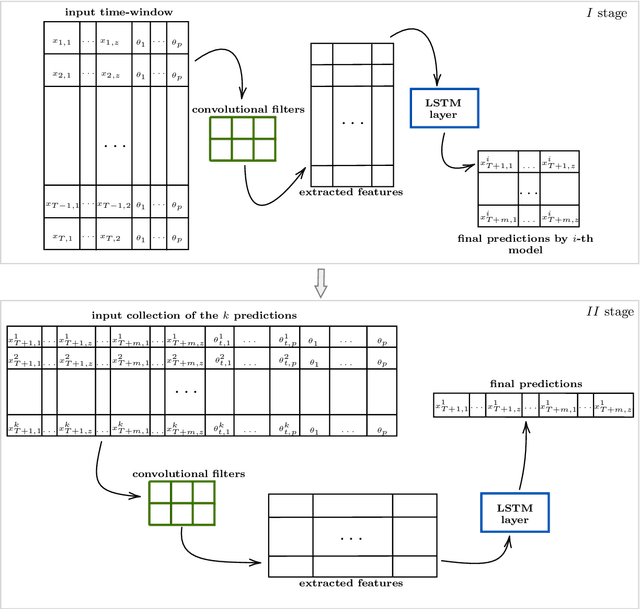
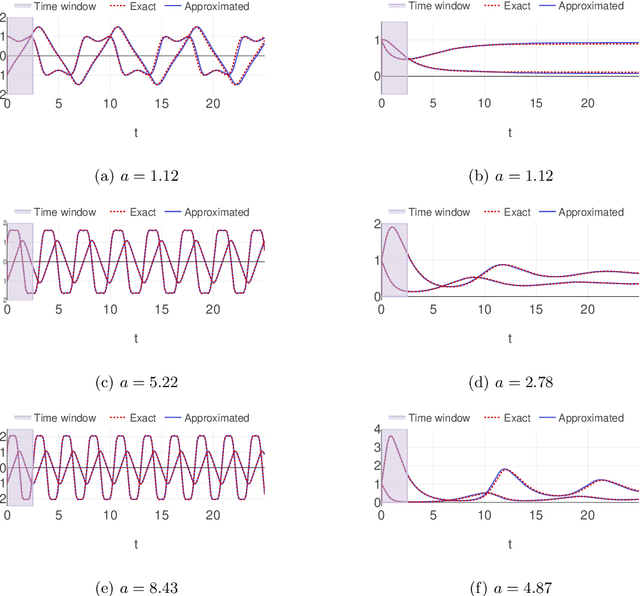
Parametric time-dependent systems are of a crucial importance in modeling real phenomena, often characterized by non-linear behaviors too. Those solutions are typically difficult to generalize in a sufficiently wide parameter space while counting on limited computational resources available. As such, we present a general two-stages deep learning framework able to perform that generalization with low computational effort in time. It consists in a separated training of two pipe-lined predictive models. At first, a certain number of independent neural networks are trained with data-sets taken from different subsets of the parameter space. Successively, a second predictive model is specialized to properly combine the first-stage guesses and compute the right predictions. Promising results are obtained applying the framework to incompressible Navier-Stokes equations in a cavity (Rayleigh-Bernard cavity), obtaining a 97% reduction in the computational time comparing with its numerical resolution for a new value of the Grashof number.
Is end-to-end learning enough for fitness activity recognition?
May 14, 2023



End-to-end learning has taken hold of many computer vision tasks, in particular, related to still images, with task-specific optimization yielding very strong performance. Nevertheless, human-centric action recognition is still largely dominated by hand-crafted pipelines, and only individual components are replaced by neural networks that typically operate on individual frames. As a testbed to study the relevance of such pipelines, we present a new fully annotated video dataset of fitness activities. Any recognition capabilities in this domain are almost exclusively a function of human poses and their temporal dynamics, so pose-based solutions should perform well. We show that, with this labelled data, end-to-end learning on raw pixels can compete with state-of-the-art action recognition pipelines based on pose estimation. We also show that end-to-end learning can support temporally fine-grained tasks such as real-time repetition counting.
Unsupervised Domain Transfer for Science: Exploring Deep Learning Methods for Translation between LArTPC Detector Simulations with Differing Response Models
May 05, 2023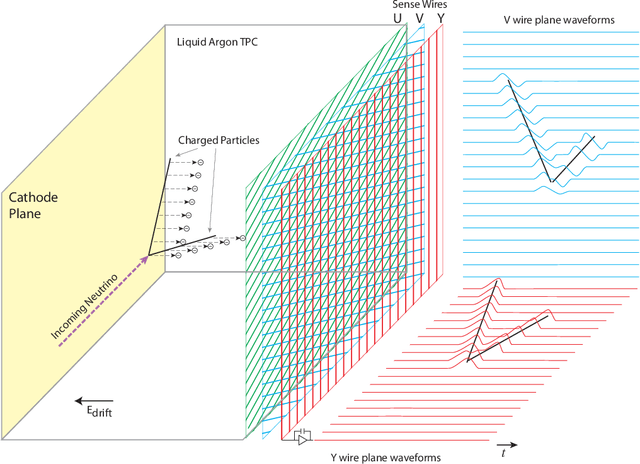
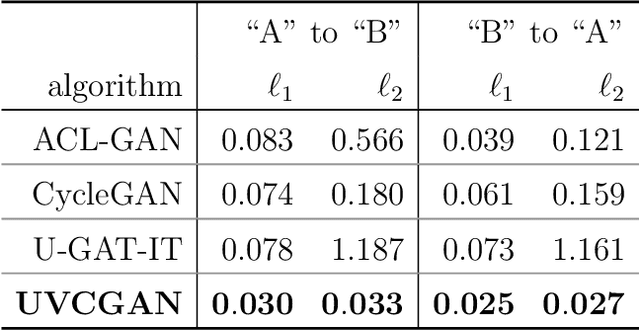
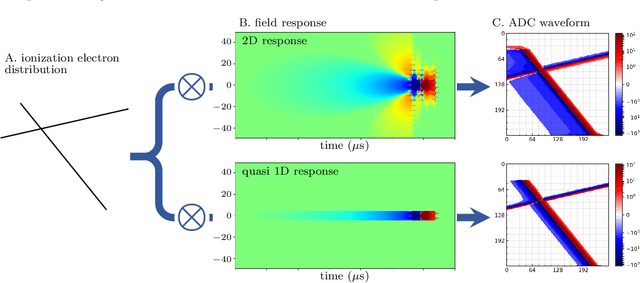
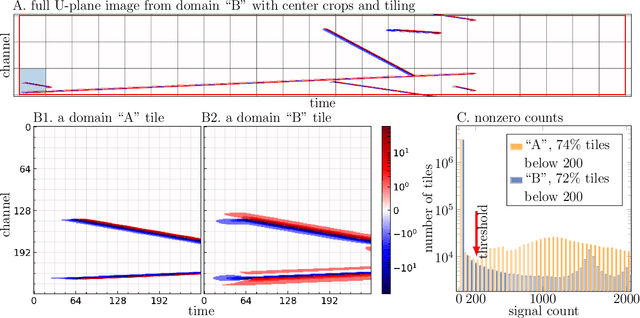
Deep learning (DL) techniques have broad applications in science, especially in seeking to streamline the pathway to potential solutions and discoveries. Frequently, however, DL models are trained on the results of simulation yet applied to real experimental data. As such, any systematic differences between the simulated and real data may degrade the model's performance -- an effect known as "domain shift." This work studies a toy model of the systematic differences between simulated and real data. It presents a fully unsupervised, task-agnostic method to reduce differences between two systematically different samples. The method is based on the recent advances in unpaired image-to-image translation techniques and is validated on two sets of samples of simulated Liquid Argon Time Projection Chamber (LArTPC) detector events, created to illustrate common systematic differences between the simulated and real data in a controlled way. LArTPC-based detectors represent the next-generation particle detectors, producing unique high-resolution particle track data. This work open-sources the generated LArTPC data set, called Simple Liquid-Argon Track Samples (or SLATS), allowing researchers from diverse domains to study the LArTPC-like data for the first time. The code and trained models are available at https://github.com/LS4GAN/uvcgan4slats.
Near-realtime Facial Animation by Deep 3D Simulation Super-Resolution
May 05, 2023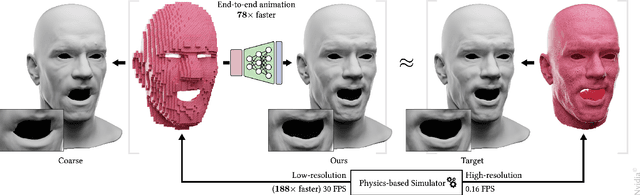
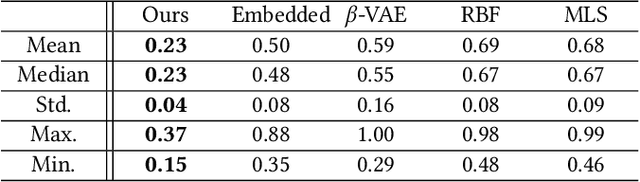
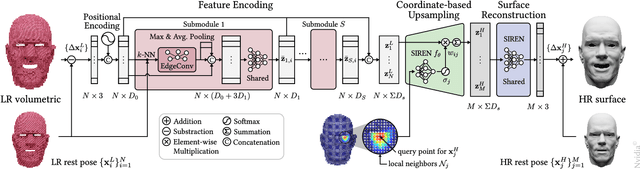
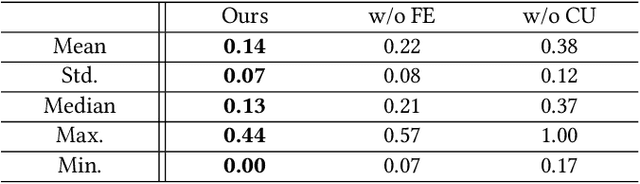
We present a neural network-based simulation super-resolution framework that can efficiently and realistically enhance a facial performance produced by a low-cost, realtime physics-based simulation to a level of detail that closely approximates that of a reference-quality off-line simulator with much higher resolution (26x element count in our examples) and accurate physical modeling. Our approach is rooted in our ability to construct - via simulation - a training set of paired frames, from the low- and high-resolution simulators respectively, that are in semantic correspondence with each other. We use face animation as an exemplar of such a simulation domain, where creating this semantic congruence is achieved by simply dialing in the same muscle actuation controls and skeletal pose in the two simulators. Our proposed neural network super-resolution framework generalizes from this training set to unseen expressions, compensates for modeling discrepancies between the two simulations due to limited resolution or cost-cutting approximations in the real-time variant, and does not require any semantic descriptors or parameters to be provided as input, other than the result of the real-time simulation. We evaluate the efficacy of our pipeline on a variety of expressive performances and provide comparisons and ablation experiments for plausible variations and alternatives to our proposed scheme.
Self-supervised Activity Representation Learning with Incremental Data: An Empirical Study
May 01, 2023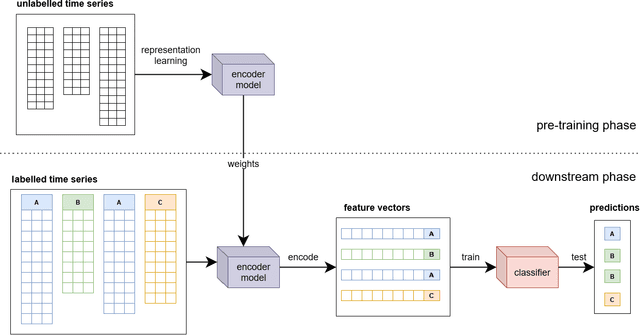
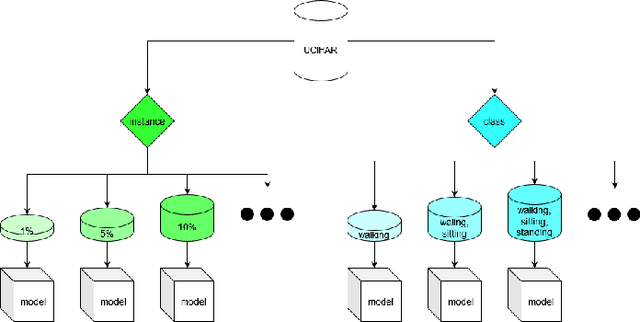
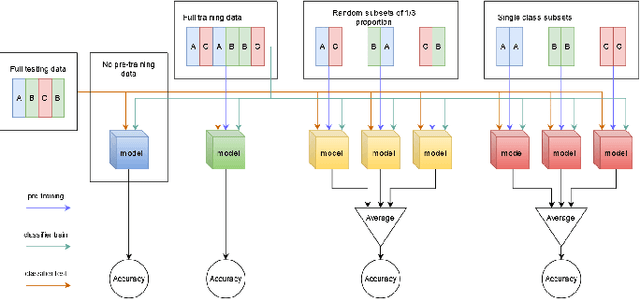
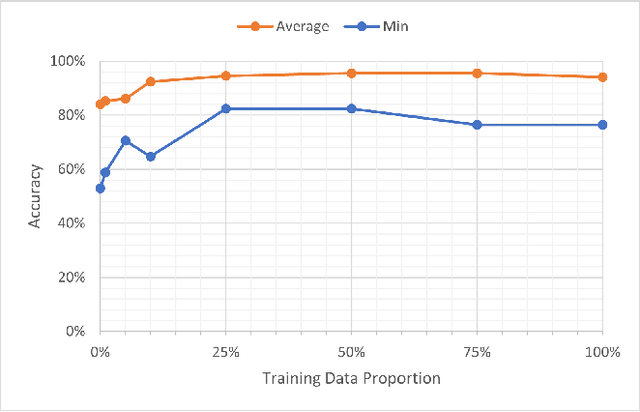
In the context of mobile sensing environments, various sensors on mobile devices continually generate a vast amount of data. Analyzing this ever-increasing data presents several challenges, including limited access to annotated data and a constantly changing environment. Recent advancements in self-supervised learning have been utilized as a pre-training step to enhance the performance of conventional supervised models to address the absence of labelled datasets. This research examines the impact of using a self-supervised representation learning model for time series classification tasks in which data is incrementally available. We proposed and evaluated a workflow in which a model learns to extract informative features using a corpus of unlabeled time series data and then conducts classification on labelled data using features extracted by the model. We analyzed the effect of varying the size, distribution, and source of the unlabeled data on the final classification performance across four public datasets, including various types of sensors in diverse applications.
Understanding of Normal and Abnormal Hearts by Phase Space Analysis and Convolutional Neural Networks
May 16, 2023Cardiac diseases are one of the leading mortality factors in modern, industrialized societies, which cause high expenses in public health systems. Due to high costs, developing analytical methods to improve cardiac diagnostics is essential. The heart's electric activity was first modeled using a set of nonlinear differential equations. Following this, variations of cardiac spectra originating from deterministic dynamics are investigated. Analyzing a normal human heart's power spectra offers His-Purkinje network, which possesses a fractal-like structure. Phase space trajectories are extracted from the time series electrocardiogram (ECG) graph with third-order derivate Taylor Series. Here in this study, phase space analysis and Convolutional Neural Networks (CNNs) method are applied to 44 records via the MIT-BIH database recorded with MLII. In order to increase accuracy, a straight line is drawn between the highest Q-R distance in the phase space images of the records. Binary CNN classification is used to determine healthy or unhealthy hearts. With a 90.90% accuracy rate, this model could classify records according to their heart status.
Efficient Computation of General Modules for ALC Ontologies (Extended Version)
May 16, 2023

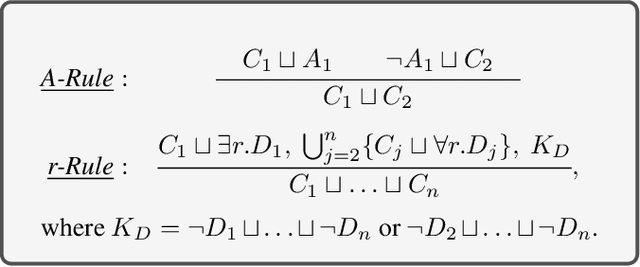

We present a method for extracting general modules for ontologies formulated in the description logic ALC. A module for an ontology is an ideally substantially smaller ontology that preserves all entailments for a user-specified set of terms. As such, it has applications such as ontology reuse and ontology analysis. Different from classical modules, general modules may use axioms not explicitly present in the input ontology, which allows for additional conciseness. So far, general modules have only been investigated for lightweight description logics. We present the first work that considers the more expressive description logic ALC. In particular, our contribution is a new method based on uniform interpolation supported by some new theoretical results. Our evaluation indicates that our general modules are often smaller than classical modules and uniform interpolants computed by the state-of-the-art, and compared with uniform interpolants, can be computed in a significantly shorter time. Moreover, our method can be used for, and in fact improves, the computation of uniform interpolants and classical modules.
TIPS: Topologically Important Path Sampling for Anytime Neural Networks
May 13, 2023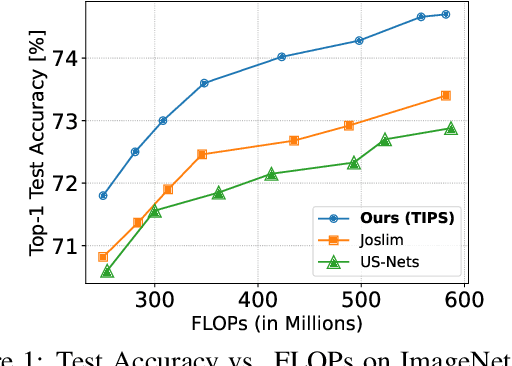
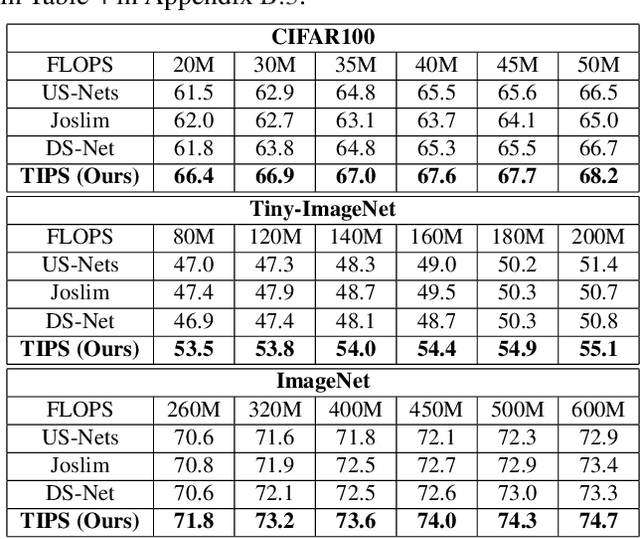
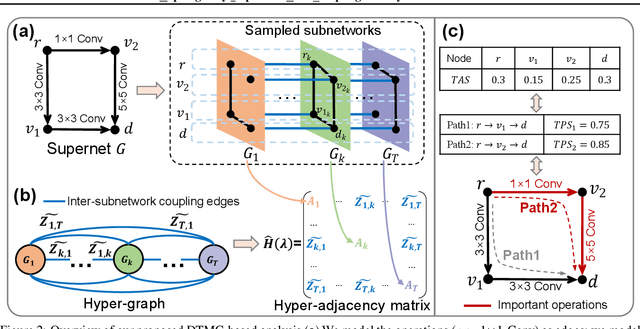
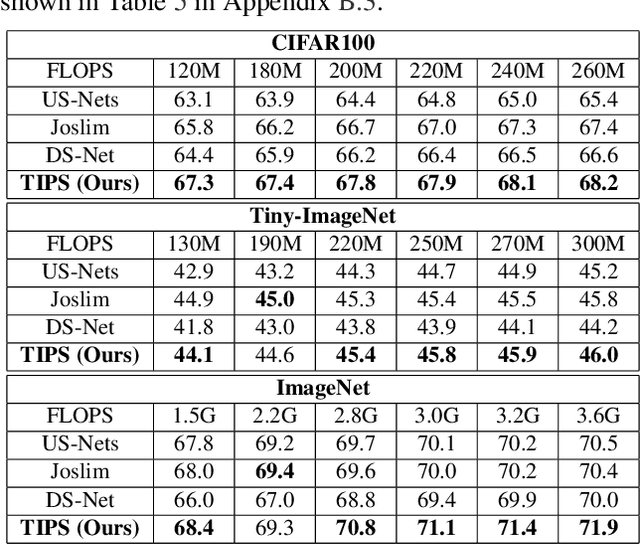
Anytime neural networks (AnytimeNNs) are a promising solution to adaptively adjust the model complexity at runtime under various hardware resource constraints. However, the manually-designed AnytimeNNs are biased by designers' prior experience and thus provide sub-optimal solutions. To address the limitations of existing hand-crafted approaches, we first model the training process of AnytimeNNs as a discrete-time Markov chain (DTMC) and use it to identify the paths that contribute the most to the training of AnytimeNNs. Based on this new DTMC-based analysis, we further propose TIPS, a framework to automatically design AnytimeNNs under various hardware constraints. Our experimental results show that TIPS can improve the convergence rate and test accuracy of AnytimeNNs. Compared to the existing AnytimeNNs approaches, TIPS improves the accuracy by 2%-6.6% on multiple datasets and achieves SOTA accuracy-FLOPs tradeoffs.
Scheduling DNNs on Edge Servers
Apr 19, 2023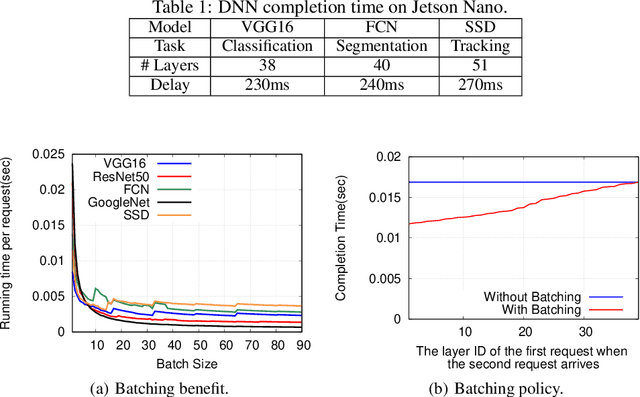
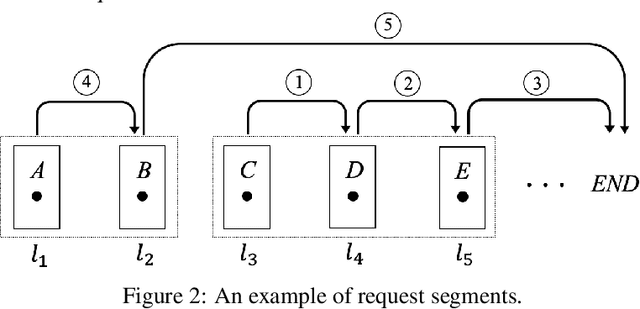
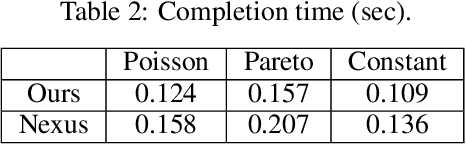
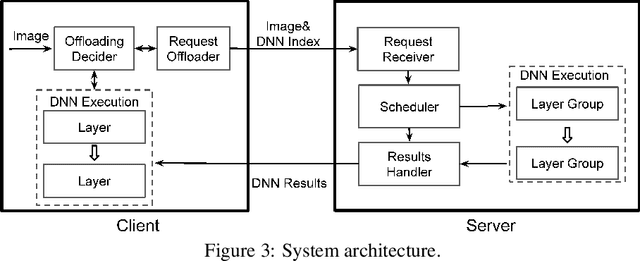
Deep neural networks (DNNs) have been widely used in various video analytic tasks. These tasks demand real-time responses. Due to the limited processing power on mobile devices, a common way to support such real-time analytics is to offload the processing to an edge server. This paper examines how to speed up the edge server DNN processing for multiple clients. In particular, we observe batching multiple DNN requests significantly speeds up the processing time. Based on this observation, we first design a novel scheduling algorithm to exploit the batching benefits of all requests that run the same DNN. This is compelling since there are only a handful of DNNs and many requests tend to use the same DNN. Our algorithms are general and can support different objectives, such as minimizing the completion time or maximizing the on-time ratio. We then extend our algorithm to handle requests that use different DNNs with or without shared layers. Finally, we develop a collaborative approach to further improve performance by adaptively processing some of the requests or portions of the requests locally at the clients. This is especially useful when the network and/or server is congested. Our implementation shows the effectiveness of our approach under different request distributions (e.g., Poisson, Pareto, and Constant inter-arrivals).
A DNN based Normalized Time-frequency Weighted Criterion for Robust Wideband DoA Estimation
Feb 20, 2023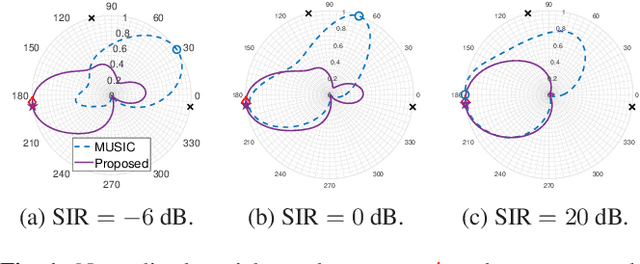

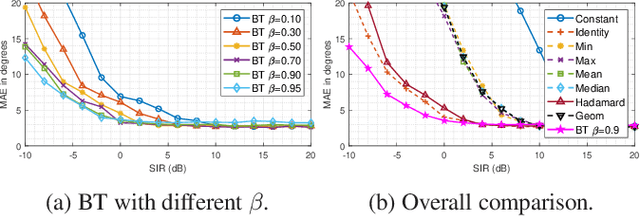
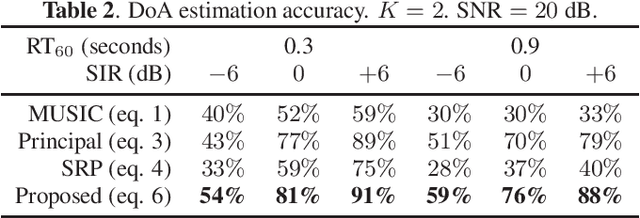
Deep neural networks (DNNs) have greatly benefited direction of arrival (DoA) estimation methods for speech source localization in noisy environments. However, their localization accuracy is still far from satisfactory due to the vulnerability to nonspeech interference. To improve the robustness against interference, we propose a DNN based normalized time-frequency (T-F) weighted criterion which minimizes the distance between the candidate steering vectors and the filtered snapshots in the T-F domain. Our method requires no eigendecomposition and uses a simple normalization to prevent the optimization objective from being misled by noisy filtered snapshots. We also study different designs of T-F weights guided by a DNN. We find that duplicating the Hadamard product of speech ratio masks is highly effective and better than other techniques such as direct masking and taking the mean in the proposed approach. However, the best-performing design of T-F weights is criterion-dependent in general. Experiments show that the proposed method outperforms popular DNN based DoA estimation methods including widely used subspace methods in noisy and reverberant environments.