 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
An Entire Renal Anatomy Extraction Network for Advanced CAD During Partial Nephrectomy
May 23, 2023
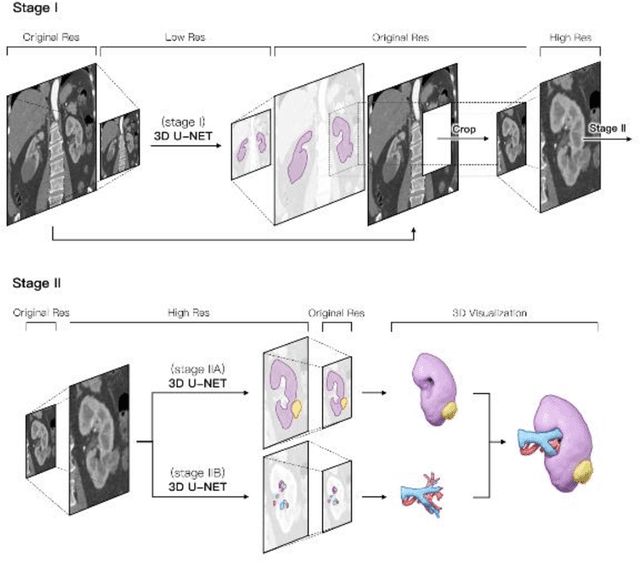
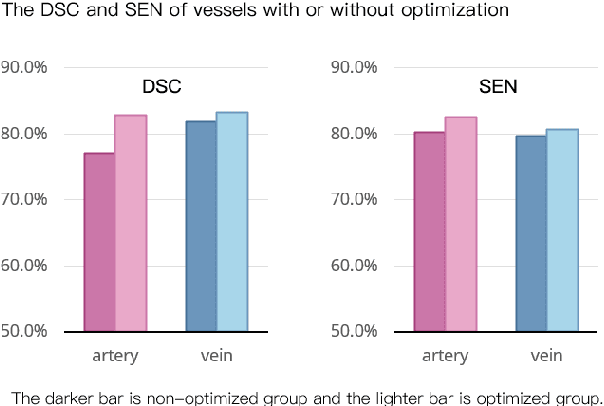
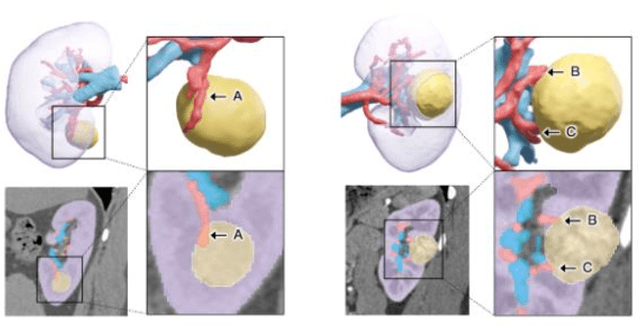
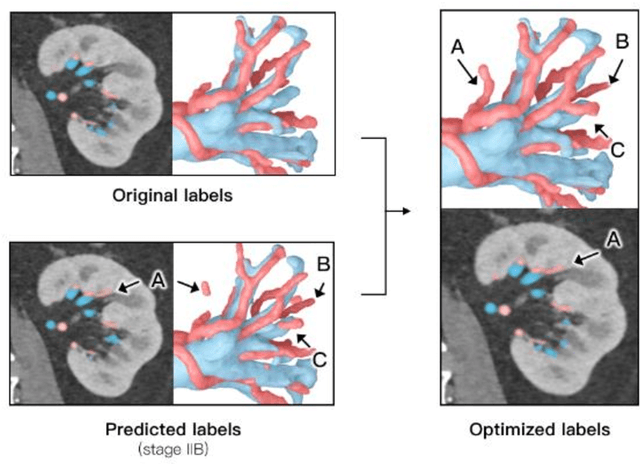
Partial nephrectomy (PN) is common surgery in urology. Digitization of renal anatomies brings much help to many computer-aided diagnosis (CAD) techniques during PN. However, the manual delineation of kidney vascular system and tumor on each slice is time consuming, error-prone, and inconsistent. Therefore, we proposed an entire renal anatomies extraction method from Computed Tomographic Angiographic (CTA) images fully based on deep learning. We adopted a coarse-to-fine workflow to extract target tissues: first, we roughly located the kidney region, and then cropped the kidney region for more detail extraction. The network we used in our workflow is based on 3D U-Net. To dealing with the imbalance of class contributions to loss, we combined the dice loss with focal loss, and added an extra weight to prevent excessive attention. We also improved the manual annotations of vessels by merging semi-trained model's prediction and original annotations under supervision. We performed several experiments to find the best-fitting combination of variables for training. We trained and evaluated the models on our 60 cases dataset with 3 different sources. The average dice score coefficient (DSC) of kidney, tumor, cyst, artery, and vein, were 90.9%, 90.0%, 89.2%, 80.1% and 82.2% respectively. Our modulate weight and hybrid strategy of loss function increased the average DSC of all tissues about 8-20%. Our optimization of vessel annotation improved the average DSC about 1-5%. We proved the efficiency of our network on renal anatomies segmentation. The high accuracy and fully automation make it possible to quickly digitize the personal renal anatomies, which greatly increases the feasibility and practicability of CAD application on urology surgery.
ChatGPT as your Personal Data Scientist
May 23, 2023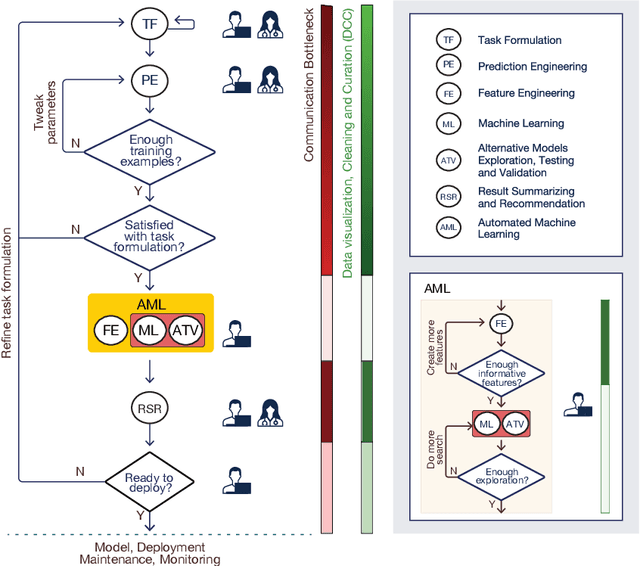
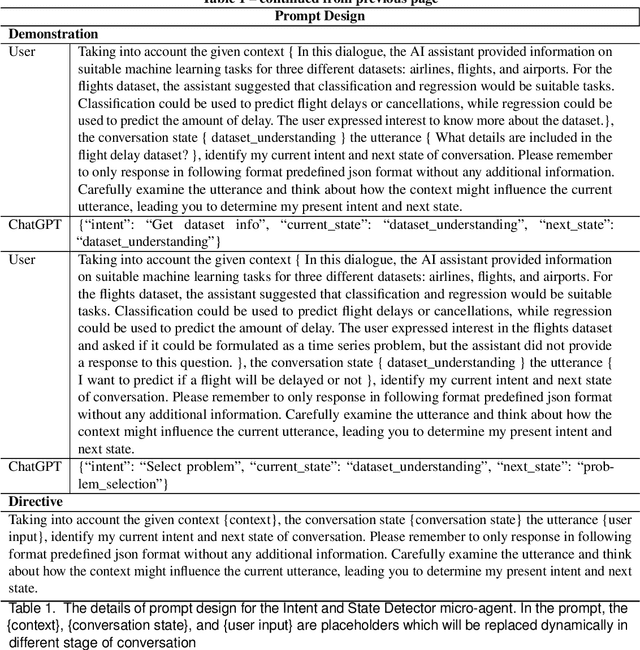
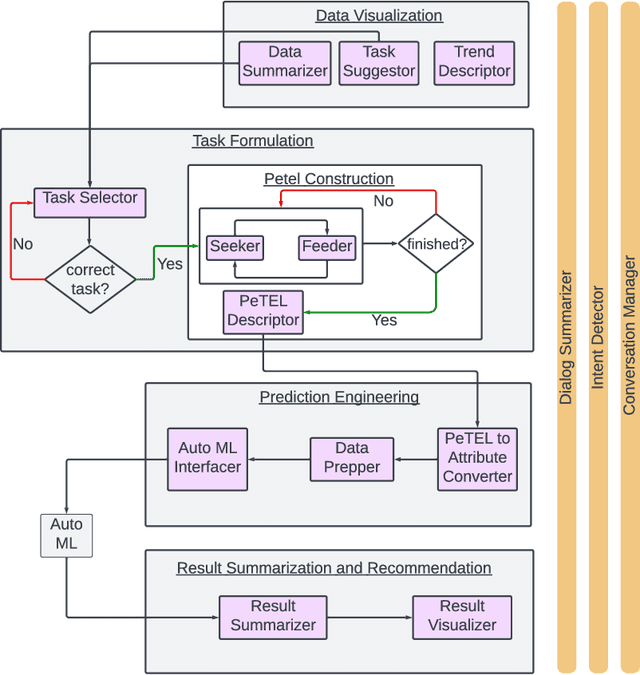

The rise of big data has amplified the need for efficient, user-friendly automated machine learning (AutoML) tools. However, the intricacy of understanding domain-specific data and defining prediction tasks necessitates human intervention making the process time-consuming while preventing full automation. Instead, envision an intelligent agent capable of assisting users in conducting AutoML tasks through intuitive, natural conversations without requiring in-depth knowledge of the underlying machine learning (ML) processes. This agent's key challenge is to accurately comprehend the user's prediction goals and, consequently, formulate precise ML tasks, adjust data sets and model parameters accordingly, and articulate results effectively. In this paper, we take a pioneering step towards this ambitious goal by introducing a ChatGPT-based conversational data-science framework to act as a "personal data scientist". Precisely, we utilize Large Language Models (ChatGPT) to build a natural interface between the users and the ML models (Scikit-Learn), which in turn, allows us to approach this ambitious problem with a realistic solution. Our model pivots around four dialogue states: Data Visualization, Task Formulation, Prediction Engineering, and Result Summary and Recommendation. Each state marks a unique conversation phase, impacting the overall user-system interaction. Multiple LLM instances, serving as "micro-agents", ensure a cohesive conversation flow, granting us granular control over the conversation's progression. In summary, we developed an end-to-end system that not only proves the viability of the novel concept of conversational data science but also underscores the potency of LLMs in solving complex tasks. Interestingly, its development spotlighted several critical weaknesses in the current LLMs (ChatGPT) and highlighted substantial opportunities for improvement.
Clustering Indices based Automatic Classification Model Selection
May 23, 2023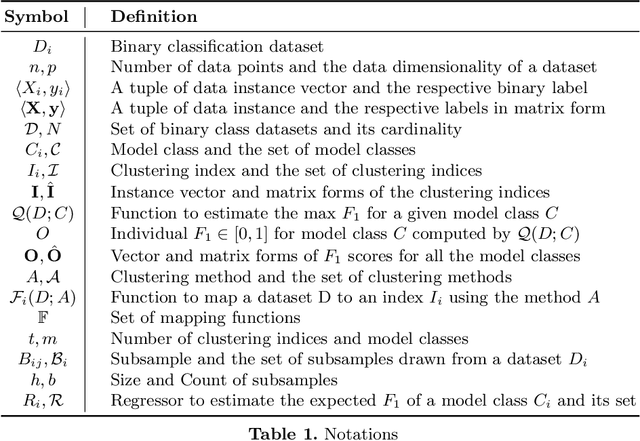
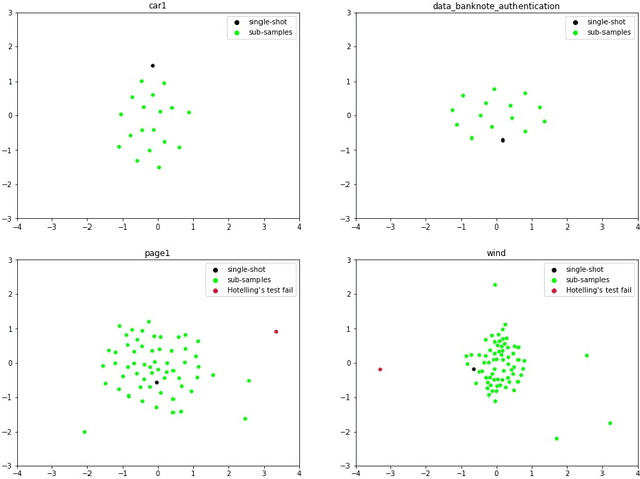
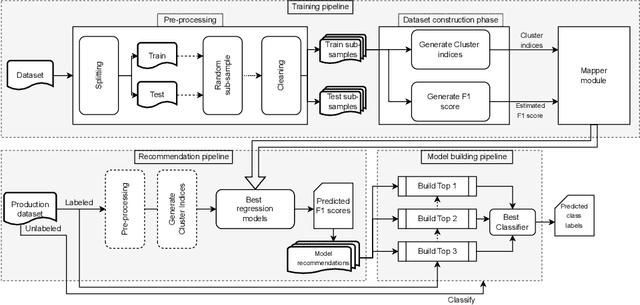
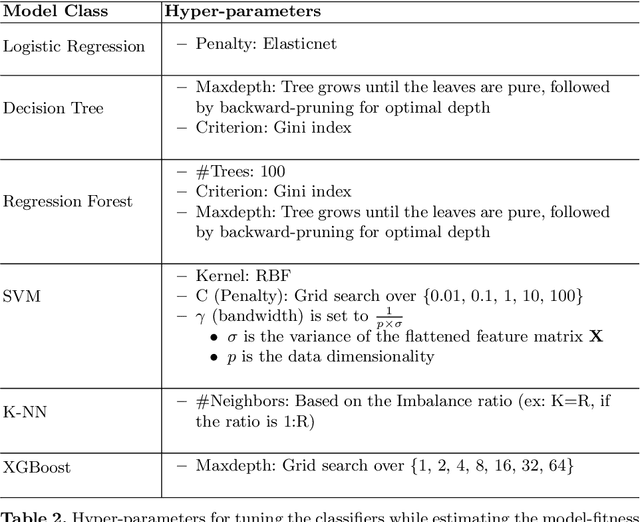
Classification model selection is a process of identifying a suitable model class for a given classification task on a dataset. Traditionally, model selection is based on cross-validation, meta-learning, and user preferences, which are often time-consuming and resource-intensive. The performance of any machine learning classification task depends on the choice of the model class, the learning algorithm, and the dataset's characteristics. Our work proposes a novel method for automatic classification model selection from a set of candidate model classes by determining the empirical model-fitness for a dataset based only on its clustering indices. Clustering Indices measure the ability of a clustering algorithm to induce good quality neighborhoods with similar data characteristics. We propose a regression task for a given model class, where the clustering indices of a given dataset form the features and the dependent variable represents the expected classification performance. We compute the dataset clustering indices and directly predict the expected classification performance using the learned regressor for each candidate model class to recommend a suitable model class for dataset classification. We evaluate our model selection method through cross-validation with 60 publicly available binary class datasets and show that our top3 model recommendation is accurate for over 45 of 60 datasets. We also propose an end-to-end Automated ML system for data classification based on our model selection method. We evaluate our end-to-end system against popular commercial and noncommercial Automated ML systems using a different collection of 25 public domain binary class datasets. We show that the proposed system outperforms other methods with an excellent average rank of 1.68.
Autonomous GIS: the next-generation AI-powered GIS
May 20, 2023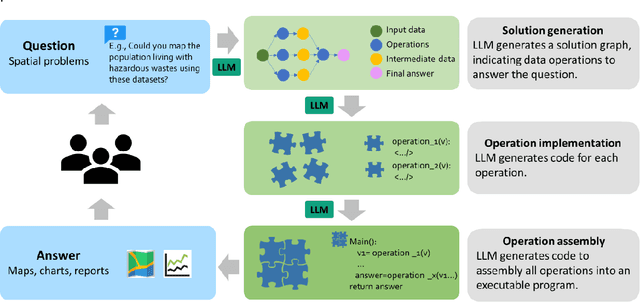
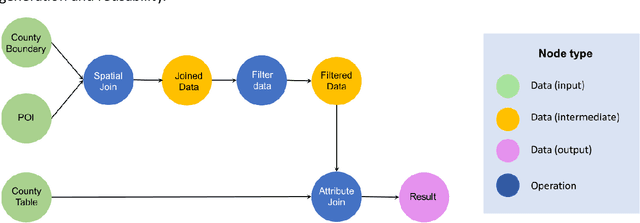


Large Language Models (LLMs), such as ChatGPT, demonstrate a strong understanding of human natural language and have been explored and applied in various fields, including reasoning, creative writing, code generation, translation, and information retrieval. By adopting LLM as the reasoning core, we introduce Autonomous GIS (AutoGIS) as an AI-powered geographic information system (GIS) that leverages the LLM's general abilities in natural language understanding, reasoning and coding for addressing spatial problems with automatic spatial data collection, analysis and visualization. We envision that autonomous GIS will need to achieve five autonomous goals including self-generating, self-organizing, self-verifying, self-executing, and self-growing. We developed a prototype system called LLM-Geo using the GPT-4 API in a Python environment, demonstrating what an autonomous GIS looks like and how it delivers expected results without human intervention using three case studies. For all case studies, LLM-Geo was able to return accurate results, including aggregated numbers, graphs, and maps, significantly reducing manual operation time. Although still in its infancy and lacking several important modules such as logging and code testing , LLM-Geo demonstrates a potential path towards next-generation AI-powered GIS. We advocate for the GIScience community to dedicate more effort to the research and development of autonomous GIS, making spatial analysis easier, faster, and more accessible to a broader audience.
LightESD: Fully-Automated and Lightweight Anomaly Detection Framework for Edge Computing
May 20, 2023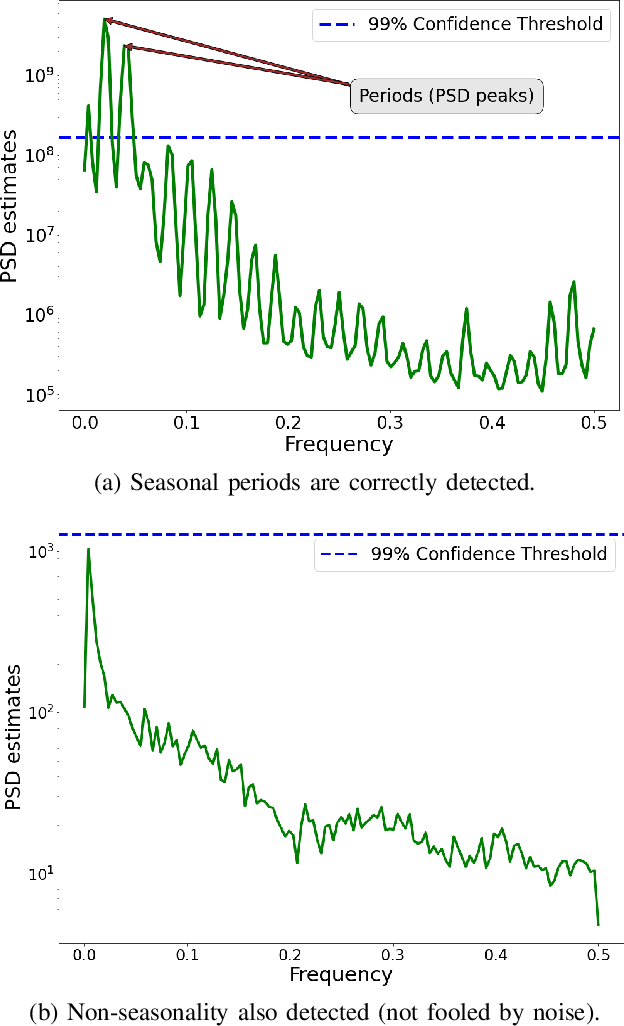
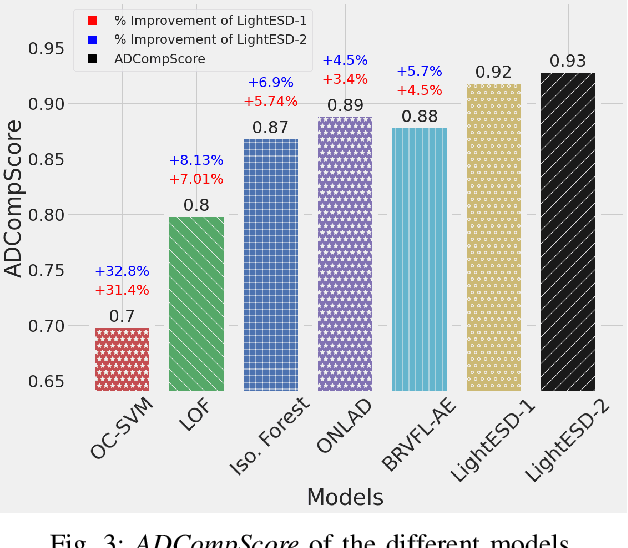
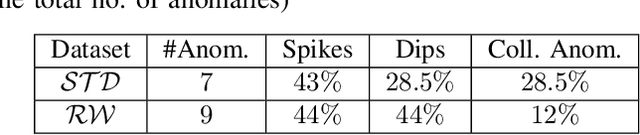
Anomaly detection is widely used in a broad range of domains from cybersecurity to manufacturing, finance, and so on. Deep learning based anomaly detection has recently drawn much attention because of its superior capability of recognizing complex data patterns and identifying outliers accurately. However, deep learning models are typically iteratively optimized in a central server with input data gathered from edge devices, and such data transfer between edge devices and the central server impose substantial overhead on the network and incur additional latency and energy consumption. To overcome this problem, we propose a fully-automated, lightweight, statistical learning based anomaly detection framework called LightESD. It is an on-device learning method without the need for data transfer between edge and server, and is extremely lightweight that most low-end edge devices can easily afford with negligible delay, CPU/memory utilization, and power consumption. Yet, it achieves highly competitive detection accuracy. Another salient feature is that it can auto-adapt to probably any dataset without manually setting or configuring model parameters or hyperparameters, which is a drawback of most existing methods. We focus on time series data due to its pervasiveness in edge applications such as IoT. Our evaluation demonstrates that LightESD outperforms other SOTA methods on detection accuracy, efficiency, and resource consumption. Additionally, its fully automated feature gives it another competitive advantage in terms of practical usability and generalizability.
Model-based adaptation for sample efficient transfer in reinforcement learning control of parameter-varying systems
May 20, 2023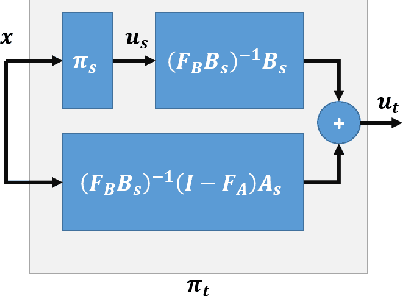


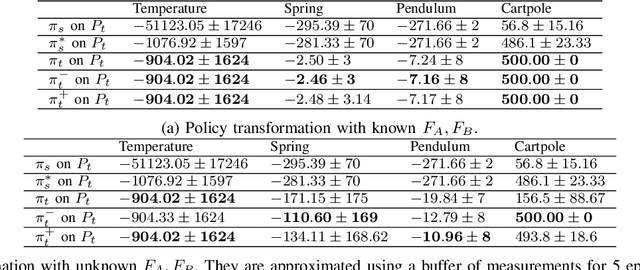
In this paper, we leverage ideas from model-based control to address the sample efficiency problem of reinforcement learning (RL) algorithms. Accelerating learning is an active field of RL highly relevant in the context of time-varying systems. Traditional transfer learning methods propose to use prior knowledge of the system behavior to devise a gradual or immediate data-driven transformation of the control policy obtained through RL. Such transformation is usually computed by estimating the performance of previous control policies based on measurements recently collected from the system. However, such retrospective measures have debatable utility with no guarantees of positive transfer in most cases. Instead, we propose a model-based transformation, such that when actions from a control policy are applied to the target system, a positive transfer is achieved. The transformation can be used as an initialization for the reinforcement learning process to converge to a new optimum. We validate the performance of our approach through four benchmark examples. We demonstrate that our approach is more sample-efficient than fine-tuning with reinforcement learning alone and achieves comparable performance to linear-quadratic-regulators and model-predictive control when an accurate linear model is known in the three cases. If an accurate model is not known, we empirically show that the proposed approach still guarantees positive transfer with jump-start improvement.
LM-Switch: Lightweight Language Model Conditioning in Word Embedding Space
May 22, 2023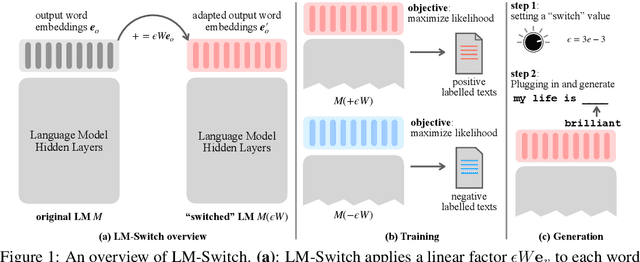
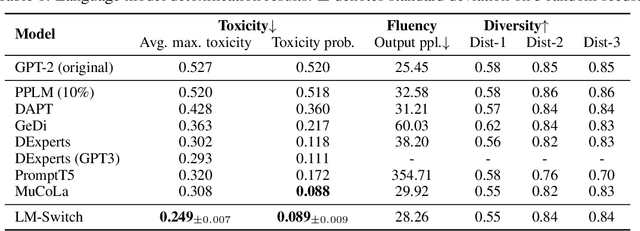
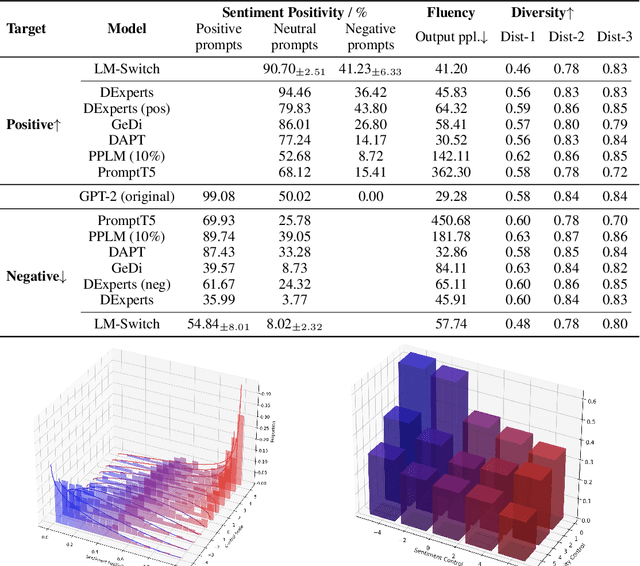
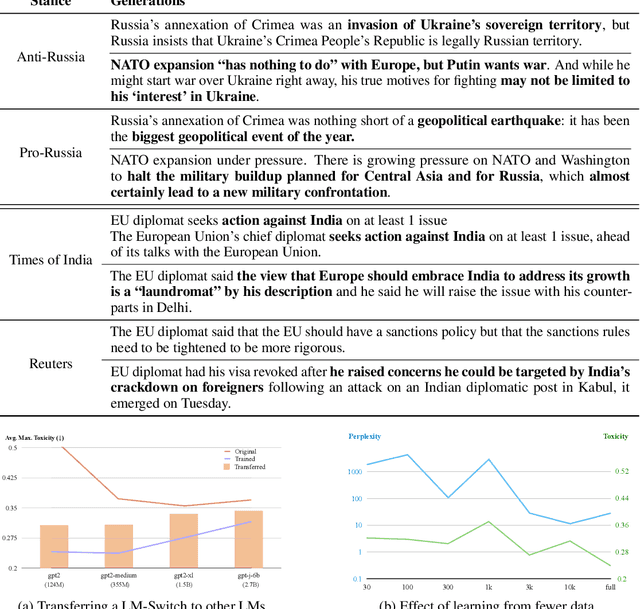
In recent years, large language models (LMs) have achieved remarkable progress across various natural language processing tasks. As pre-training and fine-tuning are costly and might negatively impact model performance, it is desired to efficiently adapt an existing model to different conditions such as styles, sentiments or narratives, when facing different audiences or scenarios. However, efficient adaptation of a language model to diverse conditions remains an open challenge. This work is inspired by the observation that text conditions are often associated with selection of certain words in a context. Therefore we introduce LM-Switch, a theoretically grounded, lightweight and simple method for generative language model conditioning. We begin by investigating the effect of conditions in Hidden Markov Models (HMMs), and establish a theoretical connection with language model. Our finding suggests that condition shifts in HMMs are associated with linear transformations in word embeddings. LM-Switch is then designed to deploy a learnable linear factor in the word embedding space for language model conditioning. We show that LM-Switch can model diverse tasks, and achieves comparable or better performance compared with state-of-the-art baselines in LM detoxification and generation control, despite requiring no more than 1% of parameters compared with baselines and little extra time overhead compared with base LMs. It is also able to learn from as few as a few sentences or one document. Moreover, a learned LM-Switch can be transferred to other LMs of different sizes, achieving a detoxification performance similar to the best baseline. We will make our code available to the research community following publication.
Appraising the Potential Uses and Harms of LLMs for Medical Systematic Reviews
May 22, 2023
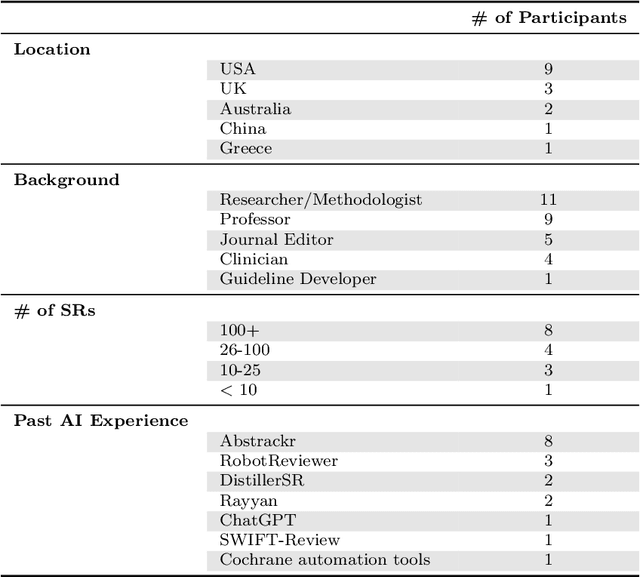
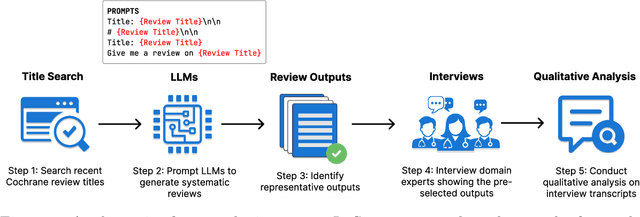
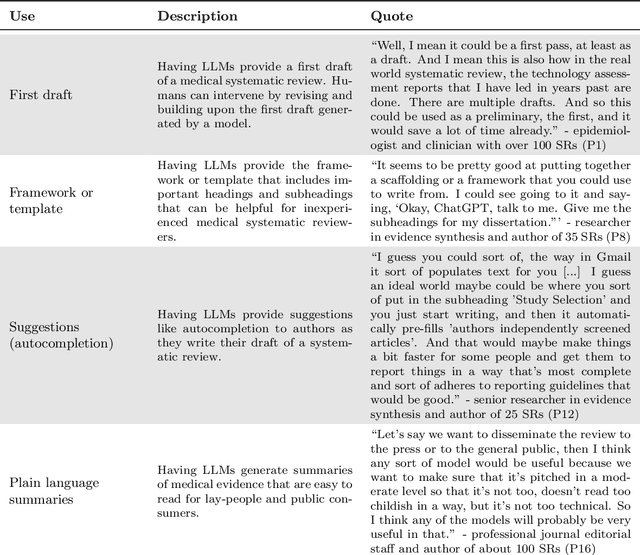
Medical systematic reviews are crucial for informing clinical decision making and healthcare policy. But producing such reviews is onerous and time-consuming. Thus, high-quality evidence synopses are not available for many questions and may be outdated even when they are available. Large language models (LLMs) are now capable of generating long-form texts, suggesting the tantalizing possibility of automatically generating literature reviews on demand. However, LLMs sometimes generate inaccurate (and potentially misleading) texts by hallucinating or omitting important information. In the healthcare context, this may render LLMs unusable at best and dangerous at worst. Most discussion surrounding the benefits and risks of LLMs have been divorced from specific applications. In this work, we seek to qualitatively characterize the potential utility and risks of LLMs for assisting in production of medical evidence reviews. We conducted 16 semi-structured interviews with international experts in systematic reviews, grounding discussion in the context of generating evidence reviews. Domain experts indicated that LLMs could aid writing reviews, as a tool for drafting or creating plain language summaries, generating templates or suggestions, distilling information, crosschecking, and synthesizing or interpreting text inputs. But they also identified issues with model outputs and expressed concerns about potential downstream harms of confidently composed but inaccurate LLM outputs which might mislead. Other anticipated potential downstream harms included lessened accountability and proliferation of automatically generated reviews that might be of low quality. Informed by this qualitative analysis, we identify criteria for rigorous evaluation of biomedical LLMs aligned with domain expert views.
SI-LSTM: Speaker Hybrid Long-short Term Memory and Cross Modal Attention for Emotion Recognition in Conversation
May 04, 2023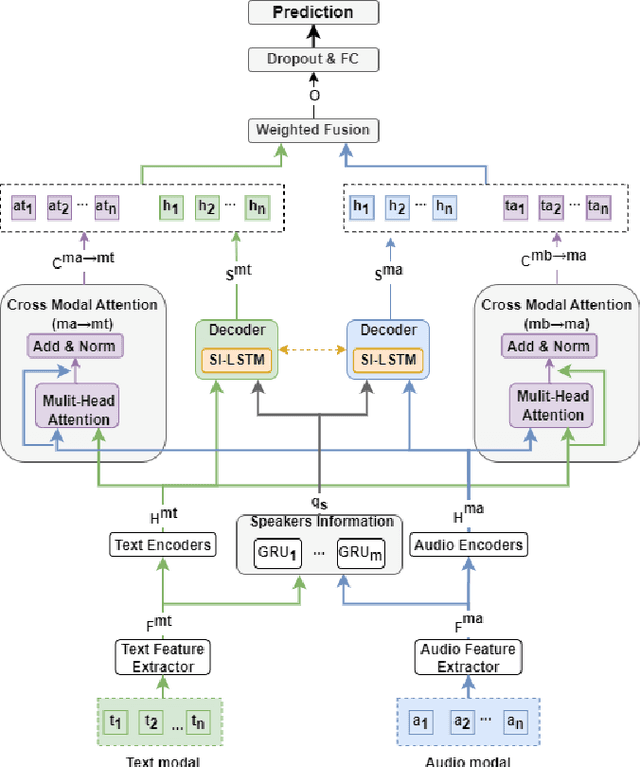
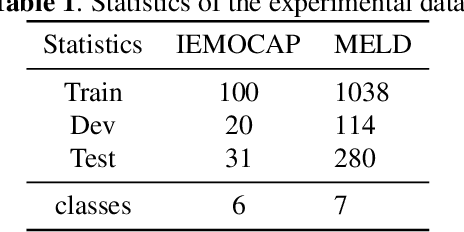
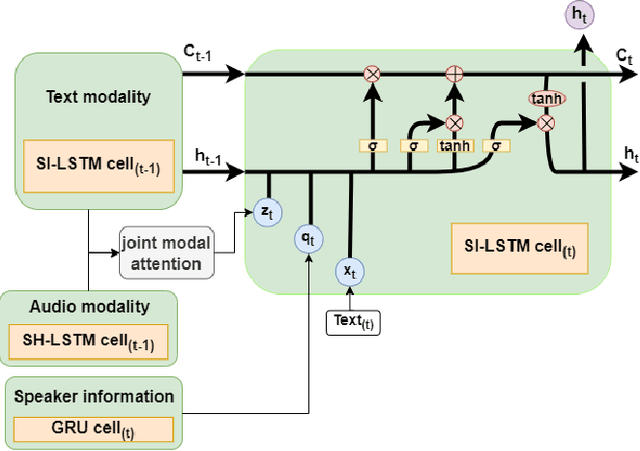
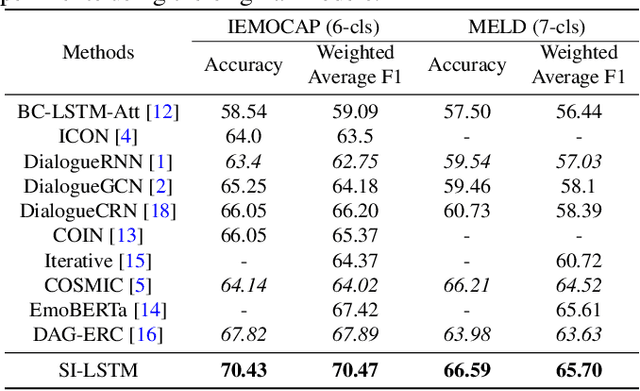
Emotion Recognition in Conversation~(ERC) across modalities is of vital importance for a variety of applications, including intelligent healthcare, artificial intelligence for conversation, and opinion mining over chat history. The crux of ERC is to model both cross-modality and cross-time interactions throughout the conversation. Previous methods have made progress in learning the time series information of conversation while lacking the ability to trace down the different emotional states of each speaker in a conversation. In this paper, we propose a recurrent structure called Speaker Information Enhanced Long-Short Term Memory (SI-LSTM) for the ERC task, where the emotional states of the distinct speaker can be tracked in a sequential way to enhance the learning of the emotion in conversation. Further, to improve the learning of multimodal features in ERC, we utilize a cross-modal attention component to fuse the features between different modalities and model the interaction of the important information from different modalities. Experimental results on two benchmark datasets demonstrate the superiority of the proposed SI-LSTM against the state-of-the-art baseline methods in the ERC task on multimodal data.
A Time Series Approach to Parkinson's Disease Classification from EEG
Jan 20, 2023
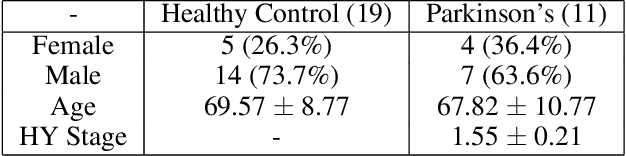
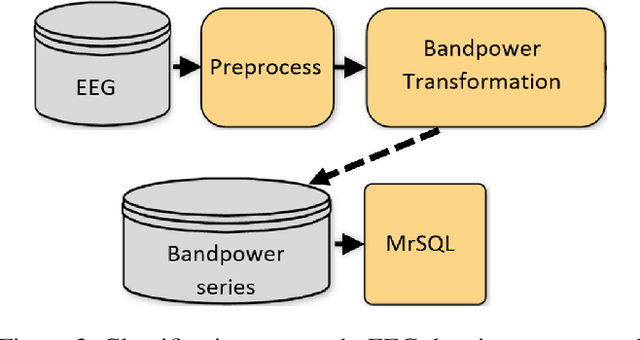
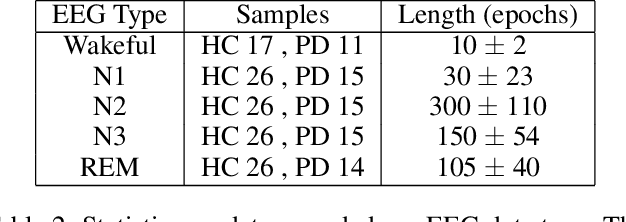
Firstly, we present a novel representation for EEG data, a 7-variate series of band power coefficients, which enables the use of (previously inaccessible) time series classification methods. Specifically, we implement the multi-resolution representation-based time series classification method MrSQL. This is deployed on a challenging early-stage Parkinson's dataset that includes wakeful and sleep EEG. Initial results are promising with over 90% accuracy achieved on all EEG data types used. Secondly, we present a framework that enables high-importance data types and brain regions for classification to be identified. Using our framework, we find that, across different EEG data types, it is the Prefrontal brain region that has the most predictive power for the presence of Parkinson's Disease. This outperformance was statistically significant versus ten of the twelve other brain regions (not significant versus adjacent Left Frontal and Right Frontal regions). The Prefrontal region of the brain is important for higher-order cognitive processes and our results align with studies that have shown neural dysfunction in the prefrontal cortex in Parkinson's Disease.