 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Improving End-to-End SLU performance with Prosodic Attention and Distillation
May 14, 2023
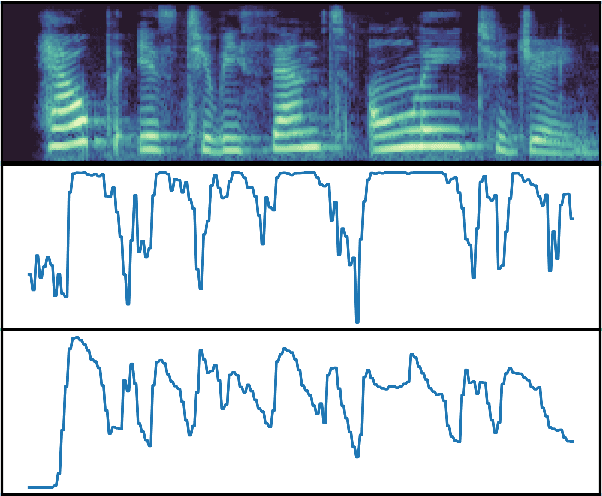
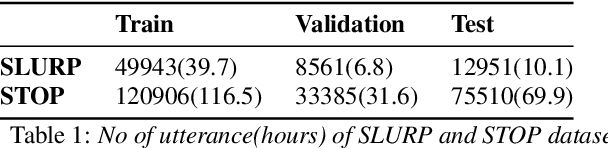
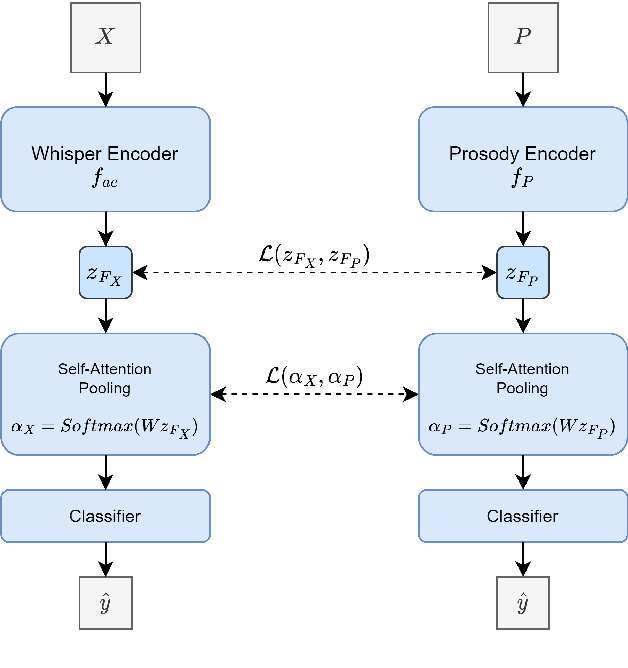
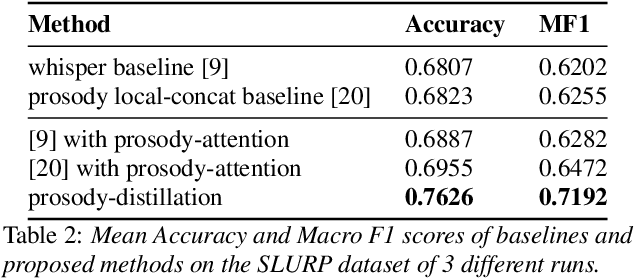
Most End-to-End SLU methods depend on the pretrained ASR or language model features for intent prediction. However, other essential information in speech, such as prosody, is often ignored. Recent research has shown improved results in classifying dialogue acts by incorporating prosodic information. The margins of improvement in these methods are minimal as the neural models ignore prosodic features. In this work, we propose prosody-attention, which uses the prosodic features differently to generate attention maps across time frames of the utterance. Then we propose prosody-distillation to explicitly learn the prosodic information in the acoustic encoder rather than concatenating the implicit prosodic features. Both the proposed methods improve the baseline results, and the prosody-distillation method gives an intent classification accuracy improvement of 8\% and 2\% on SLURP and STOP datasets over the prosody baseline.
SpeckleNN: A unified embedding for real-time speckle pattern classification in X-ray single-particle imaging with limited labeled examples
Feb 14, 2023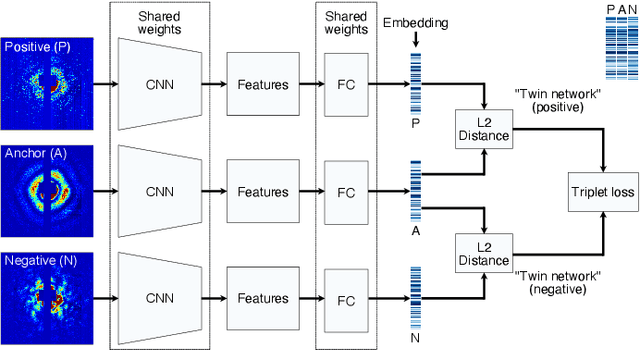
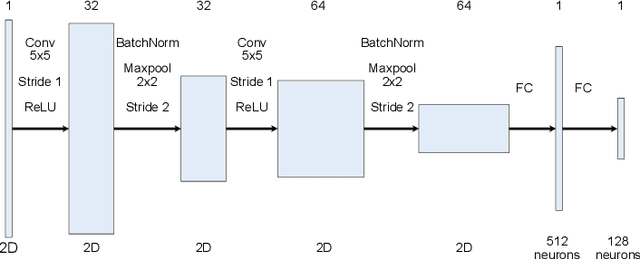
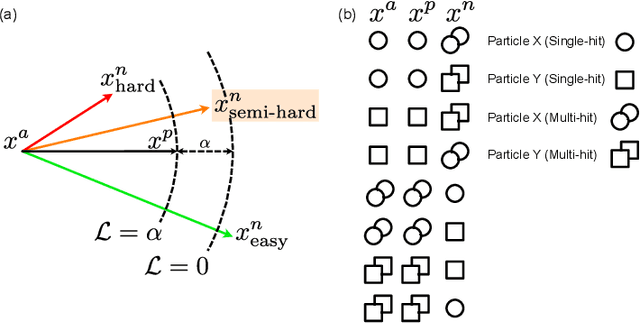
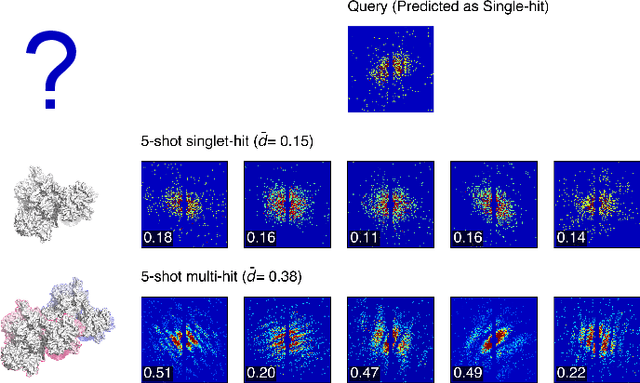
With X-ray free-electron lasers (XFELs), it is possible to determine the three-dimensional structure of noncrystalline nanoscale particles using X-ray single-particle imaging (SPI) techniques at room temperature. Classifying SPI scattering patterns, or "speckles", to extract single hits that are needed for real-time vetoing and three-dimensional reconstruction poses a challenge for high data rate facilities like European XFEL and LCLS-II-HE. Here, we introduce SpeckleNN, a unified embedding model for real-time speckle pattern classification with limited labeled examples that can scale linearly with dataset size. Trained with twin neural networks, SpeckleNN maps speckle patterns to a unified embedding vector space, where similarity is measured by Euclidean distance. We highlight its few-shot classification capability on new never-seen samples and its robust performance despite only tens of labels per classification category even in the presence of substantial missing detector areas. Without the need for excessive manual labeling or even a full detector image, our classification method offers a great solution for real-time high-throughput SPI experiments.
Towards a real-time demand response framework for smart communities using clustering techniques
Mar 01, 2023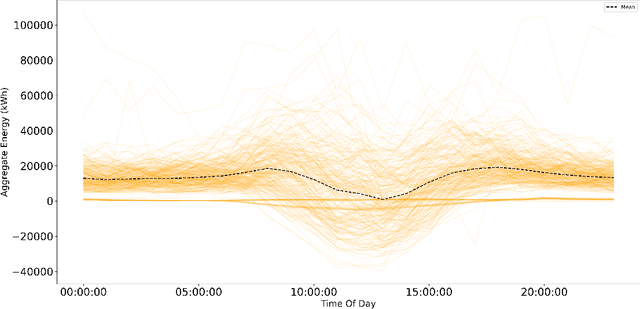
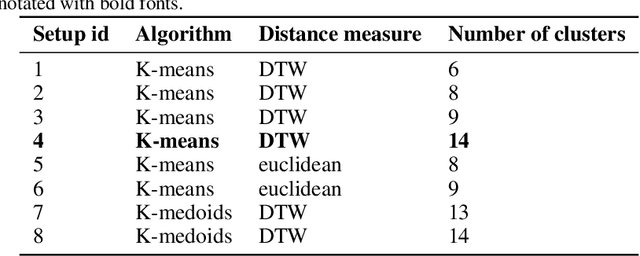
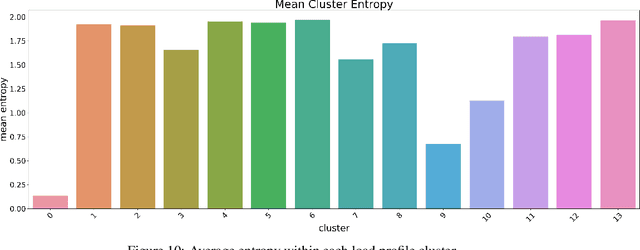
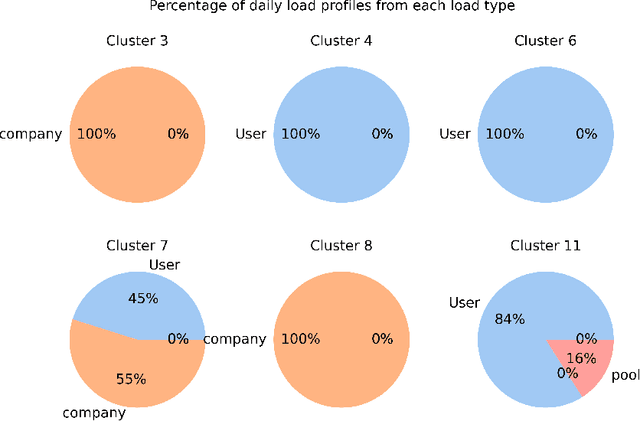
The present study explores the use of clustering techniques for the design and implementation of a demand response (DR) program for commercial and residential prosumers. The goal of the program is to shift the participants' consumption behavior to mitigate two issues a) the reverse power flow at the primary substation, that occurs when generation from solar panels in the local grid exceeds consumption and b) the system wide peak demand, that typically occurs during hours of the late afternoon. For the clustering stage, three popular algorithms for electrical load clustering are employed -- namely k-means, k-medoids and a hierarchical clustering algorithm -- alongside two different distance metrics -- namely euclidean and constrained Dynamic Time Warping (DTW). We evaluate the methods using different validation metrics including a novel metric -- namely peak performance score (PPS) -- that we propose in the context of this study. The best setup is employed to divide daily prosumer load profiles into clusters and each cluster is analyzed in terms of load shape, mean entropy and distribution of load profiles from each load type. These characteristics are then used to distinguish the clusters that would be most likely to aid with the DR schemes would fit each cluster. Finally, we conceptualize a DR system that combines forecasting, clustering and a price-based demand projection engine to produce daily individualized DR recommendations and pricing policies for prosumers participating in the program. The results of this study can be useful for network operators and utilities that aim to develop targeted DR programs for groups of prosumers within flexible energy communities.
Autoregressive models for biomedical signal processing
May 01, 2023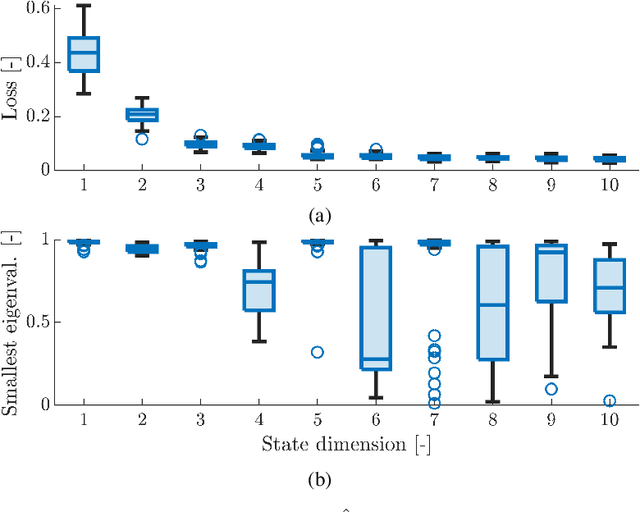
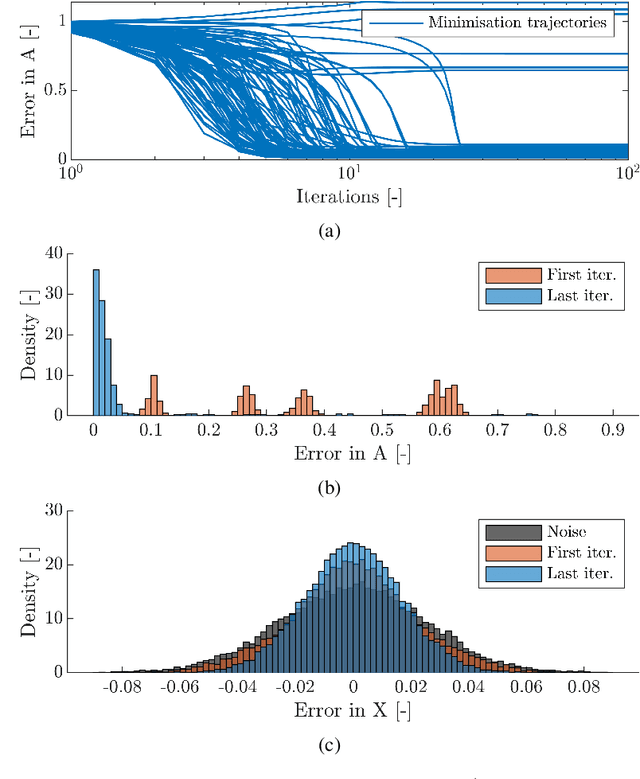
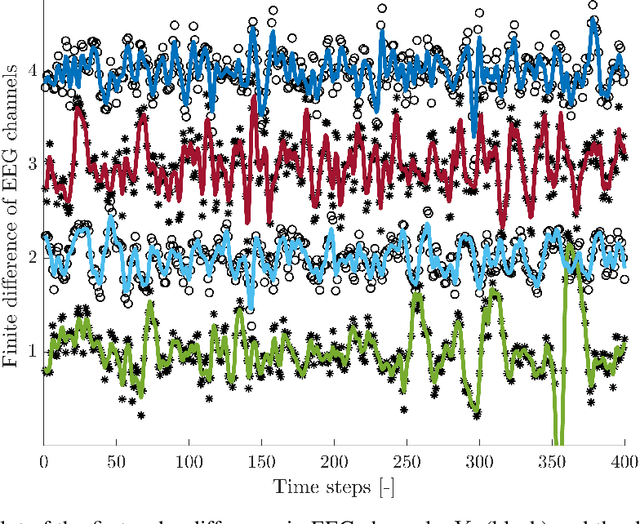
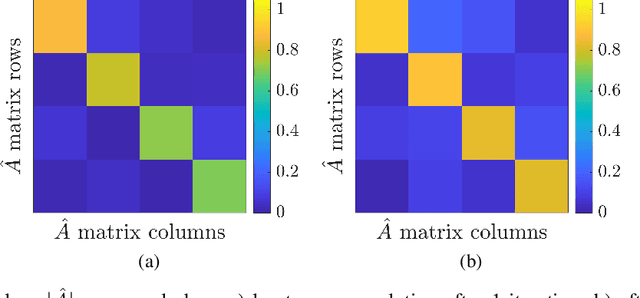
Autoregressive models are ubiquitous tools for the analysis of time series in many domains such as computational neuroscience and biomedical engineering. In these domains, data is, for example, collected from measurements of brain activity. Crucially, this data is subject to measurement errors as well as uncertainties in the underlying system model. As a result, standard signal processing using autoregressive model estimators may be biased. We present a framework for autoregressive modelling that incorporates these uncertainties explicitly via an overparameterised loss function. To optimise this loss, we derive an algorithm that alternates between state and parameter estimation. Our work shows that the procedure is able to successfully denoise time series and successfully reconstruct system parameters. This new paradigm can be used in a multitude of applications in neuroscience such as brain-computer interface data analysis and better understanding of brain dynamics in diseases such as epilepsy.
Semantically Aligned Task Decomposition in Multi-Agent Reinforcement Learning
May 18, 2023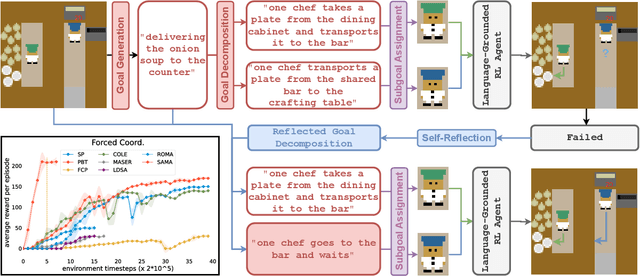

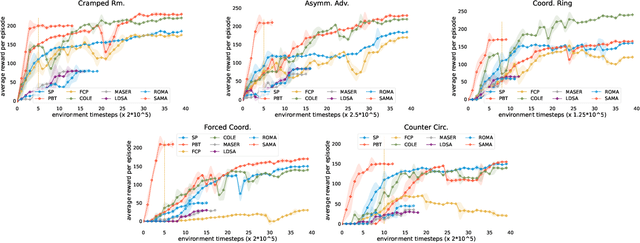

The difficulty of appropriately assigning credit is particularly heightened in cooperative MARL with sparse reward, due to the concurrent time and structural scales involved. Automatic subgoal generation (ASG) has recently emerged as a viable MARL approach inspired by utilizing subgoals in intrinsically motivated reinforcement learning. However, end-to-end learning of complex task planning from sparse rewards without prior knowledge, undoubtedly requires massive training samples. Moreover, the diversity-promoting nature of existing ASG methods can lead to the "over-representation" of subgoals, generating numerous spurious subgoals of limited relevance to the actual task reward and thus decreasing the sample efficiency of the algorithm. To address this problem and inspired by the disentangled representation learning, we propose a novel "disentangled" decision-making method, Semantically Aligned task decomposition in MARL (SAMA), that prompts pretrained language models with chain-of-thought that can suggest potential goals, provide suitable goal decomposition and subgoal allocation as well as self-reflection-based replanning. Additionally, SAMA incorporates language-grounded RL to train each agent's subgoal-conditioned policy. SAMA demonstrates considerable advantages in sample efficiency compared to state-of-the-art ASG methods, as evidenced by its performance on two challenging sparse-reward tasks, Overcooked and MiniRTS.
Massively Scalable Inverse Reinforcement Learning in Google Maps
May 18, 2023
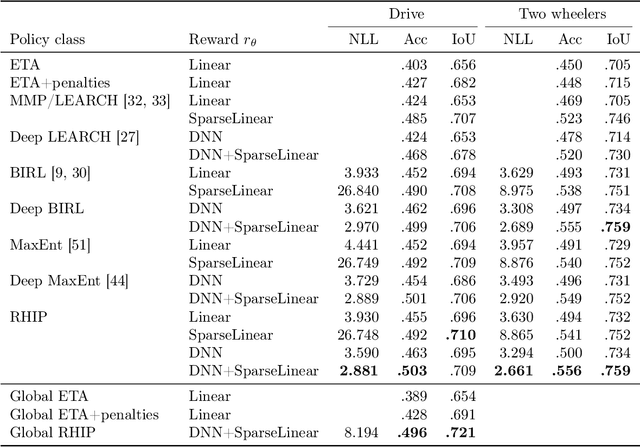
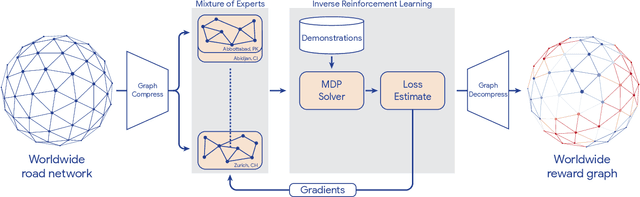
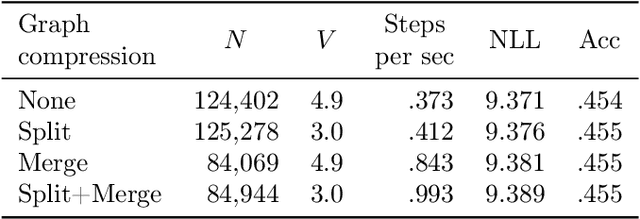
Optimizing for humans' latent preferences is a grand challenge in route recommendation, where globally-scalable solutions remain an open problem. Although past work created increasingly general solutions for the application of inverse reinforcement learning (IRL), these have not been successfully scaled to world-sized MDPs, large datasets, and highly parameterized models; respectively hundreds of millions of states, trajectories, and parameters. In this work, we surpass previous limitations through a series of advancements focused on graph compression, parallelization, and problem initialization based on dominant eigenvectors. We introduce Receding Horizon Inverse Planning (RHIP), which generalizes existing work and enables control of key performance trade-offs via its planning horizon. Our policy achieves a 16-24% improvement in global route quality, and, to our knowledge, represents the largest instance of IRL in a real-world setting to date. Our results show critical benefits to more sustainable modes of transportation (e.g. two-wheelers), where factors beyond journey time (e.g. route safety) play a substantial role. We conclude with ablations of key components, negative results on state-of-the-art eigenvalue solvers, and identify future opportunities to improve scalability via IRL-specific batching strategies.
Lyapunov-Driven Deep Reinforcement Learning for Edge Inference Empowered by Reconfigurable Intelligent Surfaces
May 18, 2023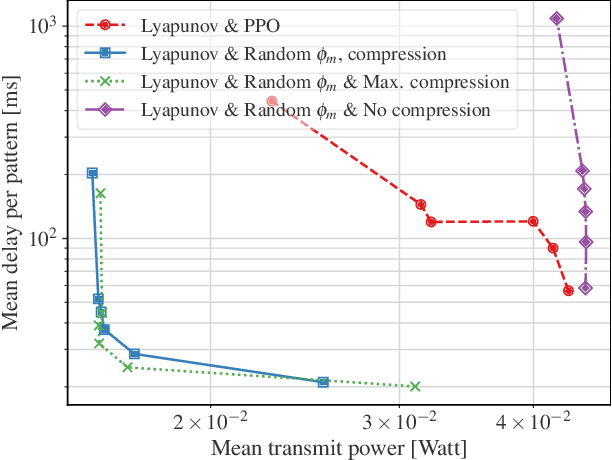
In this paper, we propose a novel algorithm for energy-efficient, low-latency, accurate inference at the wireless edge, in the context of 6G networks endowed with reconfigurable intelligent surfaces (RISs). We consider a scenario where new data are continuously generated/collected by a set of devices and are handled through a dynamic queueing system. Building on the marriage between Lyapunov stochastic optimization and deep reinforcement learning (DRL), we devise a dynamic learning algorithm that jointly optimizes the data compression scheme, the allocation of radio resources (i.e., power, transmission precoding), the computation resources (i.e., CPU cycles), and the RIS reflectivity parameters (i.e., phase shifts), with the aim of performing energy-efficient edge classification with end-to-end (E2E) delay and inference accuracy constraints. The proposed strategy enables dynamic control of the system and of the wireless propagation environment, performing a low-complexity optimization on a per-slot basis while dealing with time-varying radio channels and task arrivals, whose statistics are unknown. Numerical results assess the performance of the proposed RIS-empowered edge inference strategy in terms of trade-off between energy, delay, and accuracy of a classification task.
Collaborative Generative AI: Integrating GPT-k for Efficient Editing in Text-to-Image Generation
May 18, 2023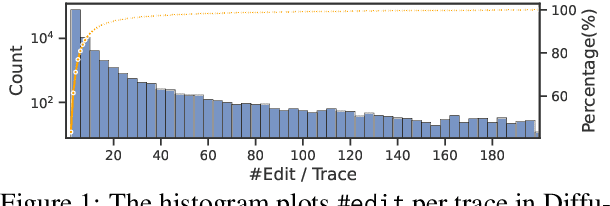
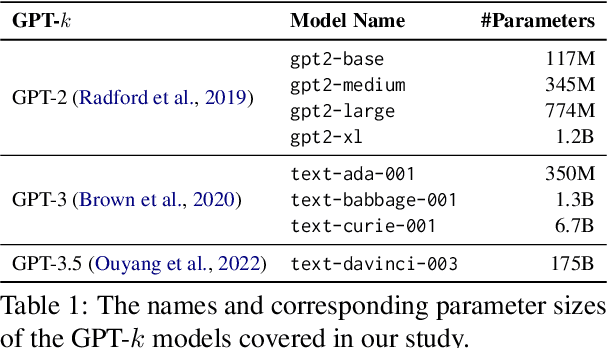
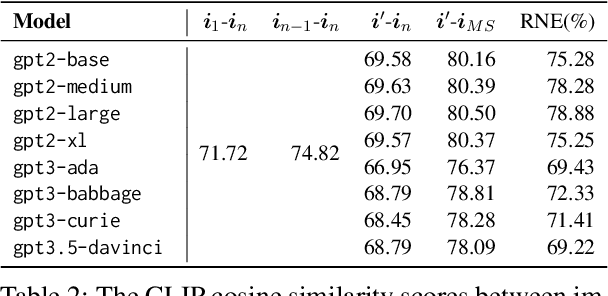
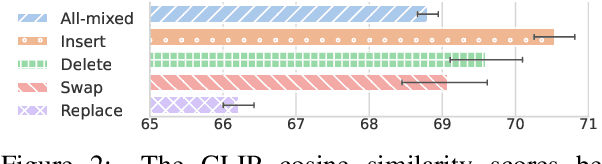
The field of text-to-image (T2I) generation has garnered significant attention both within the research community and among everyday users. Despite the advancements of T2I models, a common issue encountered by users is the need for repetitive editing of input prompts in order to receive a satisfactory image, which is time-consuming and labor-intensive. Given the demonstrated text generation power of large-scale language models, such as GPT-k, we investigate the potential of utilizing such models to improve the prompt editing process for T2I generation. We conduct a series of experiments to compare the common edits made by humans and GPT-k, evaluate the performance of GPT-k in prompting T2I, and examine factors that may influence this process. We found that GPT-k models focus more on inserting modifiers while humans tend to replace words and phrases, which includes changes to the subject matter. Experimental results show that GPT-k are more effective in adjusting modifiers rather than predicting spontaneous changes in the primary subject matters. Adopting the edit suggested by GPT-k models may reduce the percentage of remaining edits by 20-30%.
Machine learning for phase-resolved reconstruction of nonlinear ocean wave surface elevations from sparse remote sensing data
May 18, 2023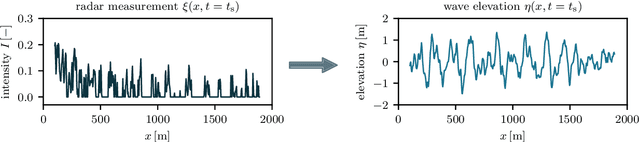
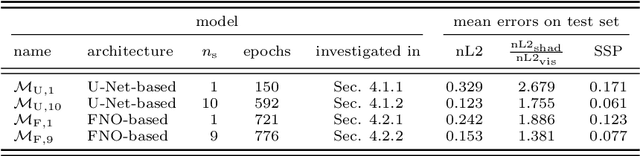
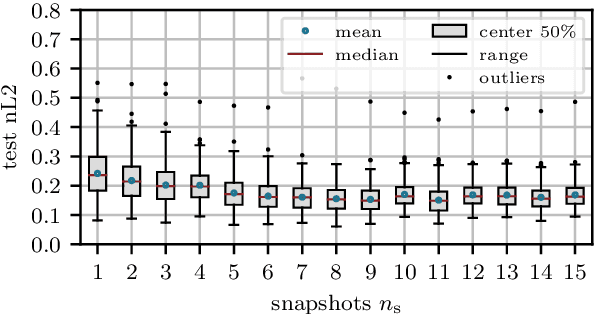
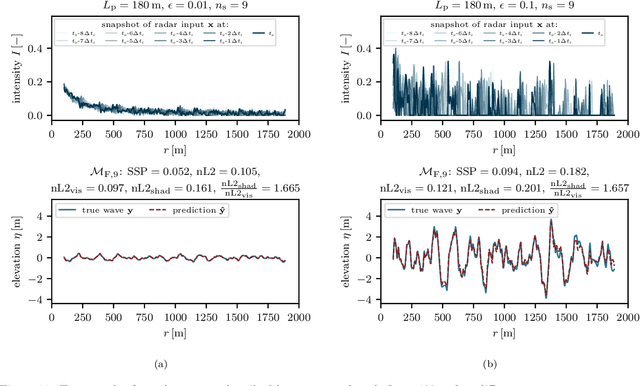
Accurate short-term prediction of phase-resolved water wave conditions is crucial for decision-making in ocean engineering. However, the initialization of remote-sensing-based wave prediction models first requires a reconstruction of wave surfaces from sparse measurements like radar. Existing reconstruction methods either rely on computationally intensive optimization procedures or simplistic modeling assumptions that compromise real-time capability or accuracy of the entire prediction process. We therefore address these issues by proposing a novel approach for phase-resolved wave surface reconstruction using neural networks based on the U-Net and Fourier neural operator (FNO) architectures. Our approach utilizes synthetic yet highly realistic training data on uniform one-dimensional grids, that is generated by the high-order spectral method for wave simulation and a geometric radar modeling approach. The investigation reveals that both models deliver accurate wave reconstruction results and show good generalization for different sea states when trained with spatio-temporal radar data containing multiple historic radar snapshots in each input. Notably, the FNO-based network performs better in handling the data structure imposed by wave physics due to its global approach to learn the mapping between input and desired output in Fourier space.
Meta-Auxiliary Network for 3D GAN Inversion
May 18, 2023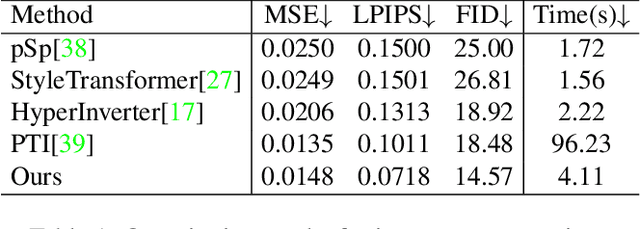
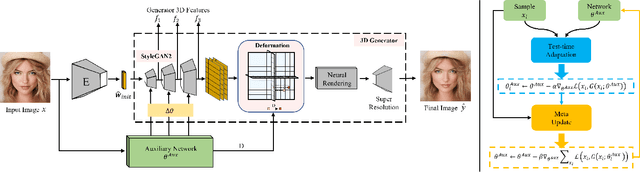
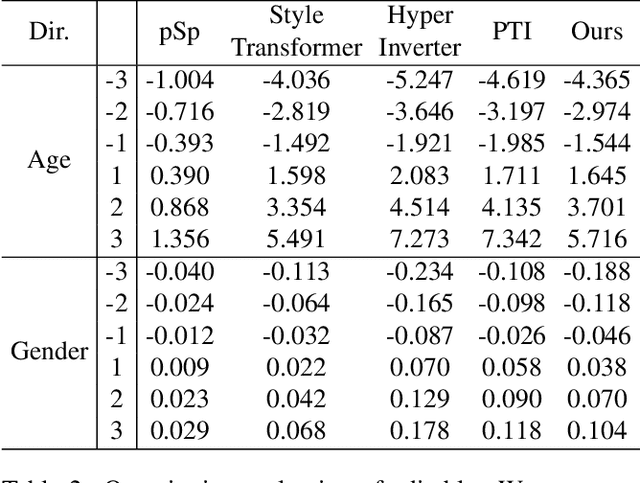
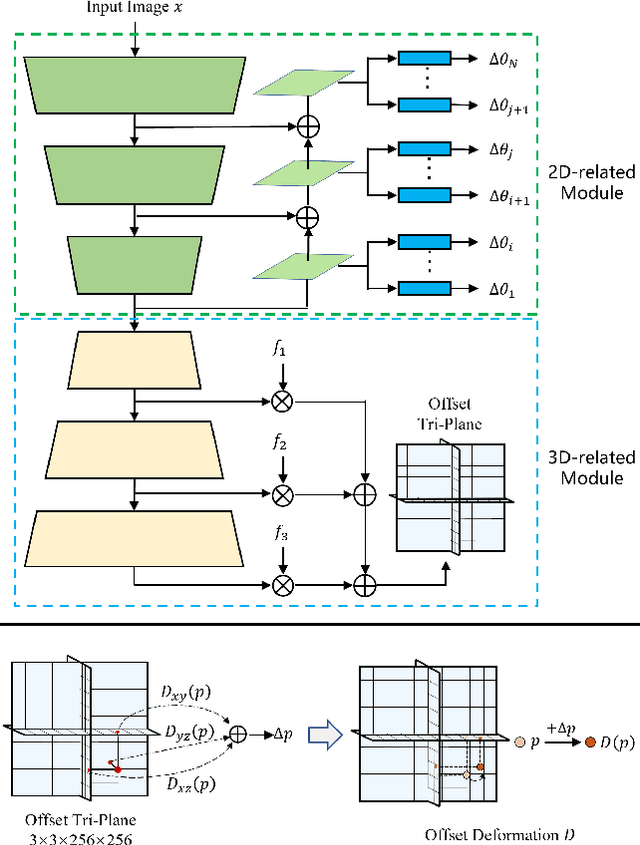
Real-world image manipulation has achieved fantastic progress in recent years. GAN inversion, which aims to map the real image to the latent code faithfully, is the first step in this pipeline. However, existing GAN inversion methods fail to achieve high reconstruction quality and fast inference at the same time. In addition, existing methods are built on 2D GANs and lack explicitly mechanisms to enforce multi-view consistency.In this work, we present a novel meta-auxiliary framework, while leveraging the newly developed 3D GANs as generator. The proposed method adopts a two-stage strategy. In the first stage, we invert the input image to an editable latent code using off-the-shelf inversion techniques. The auxiliary network is proposed to refine the generator parameters with the given image as input, which both predicts offsets for weights of convolutional layers and sampling positions of volume rendering. In the second stage, we perform meta-learning to fast adapt the auxiliary network to the input image, then the final reconstructed image is synthesized via the meta-learned auxiliary network. Extensive experiments show that our method achieves better performances on both inversion and editing tasks.