 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
WavePF: A Novel Fusion Approach based on Wavelet-guided Pooling for Infrared and Visible Images
May 27, 2023
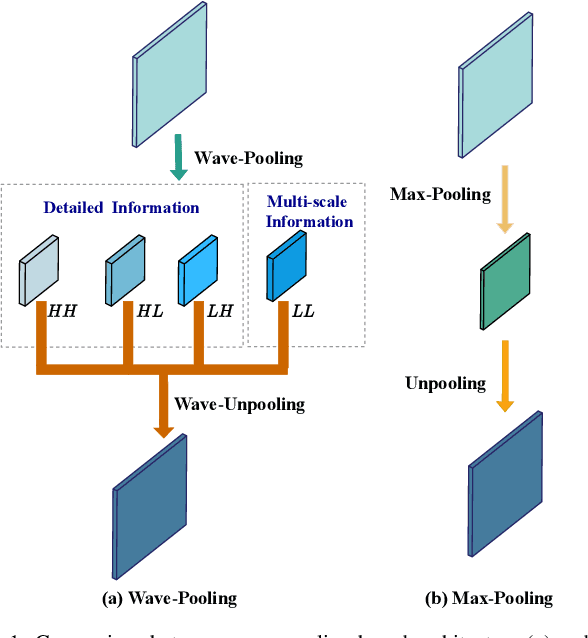
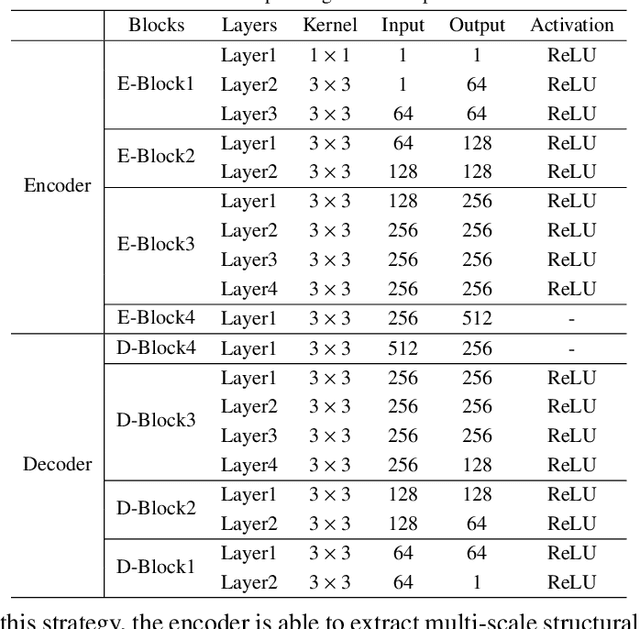

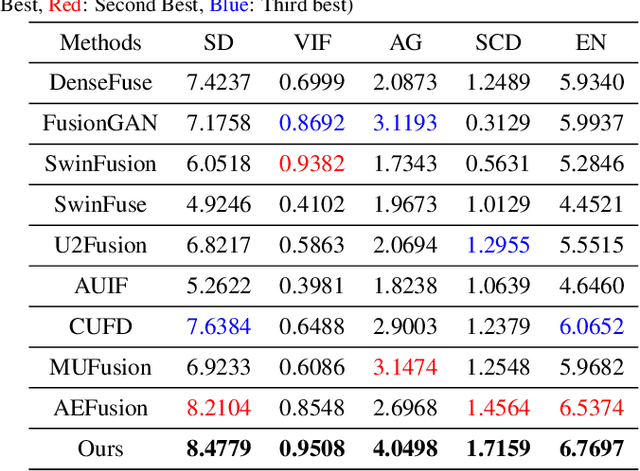
Infrared and visible image fusion aims to generate synthetic images simultaneously containing salient features and rich texture details, which can be used to boost downstream tasks. However, existing fusion methods are suffering from the issues of texture loss and edge information deficiency, which result in suboptimal fusion results. Meanwhile, the straight-forward up-sampling operator can not well preserve the source information from multi-scale features. To address these issues, a novel fusion network based on the wavelet-guided pooling (wave-pooling) manner is proposed, termed as WavePF. Specifically, a wave-pooling based encoder is designed to extract multi-scale image and detail features of source images at the same time. In addition, the spatial attention model is used to aggregate these salient features. After that, the fused features will be reconstructed by the decoder, in which the up-sampling operator is replaced by the wave-pooling reversed operation. Different from the common max-pooling technique, image features after the wave-pooling layer can retain abundant details information, which can benefit the fusion process. In this case, rich texture details and multi-scale information can be maintained during the reconstruction phase. The experimental results demonstrate that our method exhibits superior fusion performance over the state-of-the-arts on multiple image fusion benchmarks
Explanations as Features: LLM-Based Features for Text-Attributed Graphs
May 31, 2023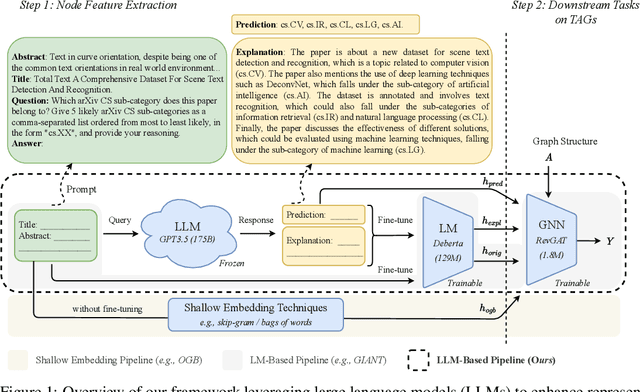
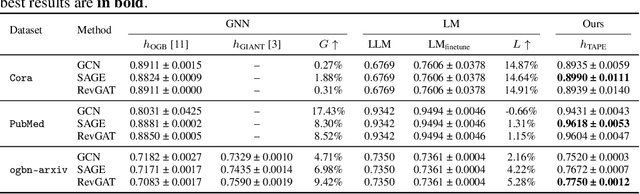
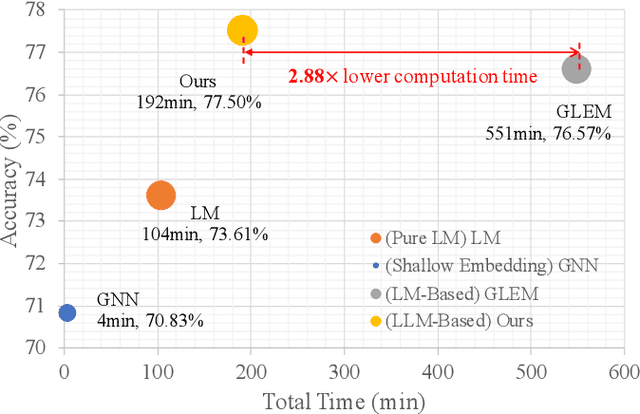
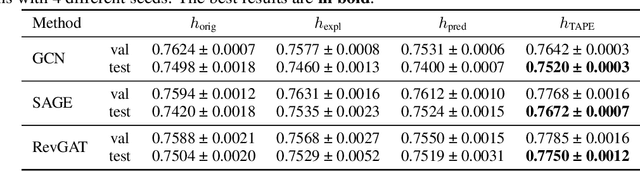
Representation learning on text-attributed graphs (TAGs) has become a critical research problem in recent years. A typical example of a TAG is a paper citation graph, where the text of each paper serves as node attributes. Most graph neural network (GNN) pipelines handle these text attributes by transforming them into shallow or hand-crafted features, such as skip-gram or bag-of-words features. Recent efforts have focused on enhancing these pipelines with language models. With the advent of powerful large language models (LLMs) such as GPT, which demonstrate an ability to reason and to utilize general knowledge, there is a growing need for techniques which combine the textual modelling abilities of LLMs with the structural learning capabilities of GNNs. Hence, in this work, we focus on leveraging LLMs to capture textual information as features, which can be used to boost GNN performance on downstream tasks. A key innovation is our use of \emph{explanations as features}: we prompt an LLM to perform zero-shot classification and to provide textual explanations for its decisions, and find that the resulting explanations can be transformed into useful and informative features to augment downstream GNNs. Through experiments we show that our enriched features improve the performance of a variety of GNN models across different datasets. Notably, we achieve top-1 performance on \texttt{ogbn-arxiv} by a significant margin over the closest baseline even with $2.88\times$ lower computation time, as well as top-1 performance on TAG versions of the widely used \texttt{PubMed} and \texttt{Cora} benchmarks~\footnote{Our codes and datasets are available at: \url{https://github.com/XiaoxinHe/TAPE}}.
Ambiguity in solving imaging inverse problems with deep learning based operators
May 31, 2023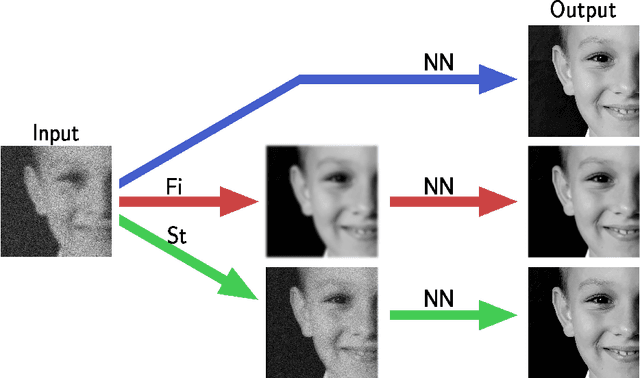
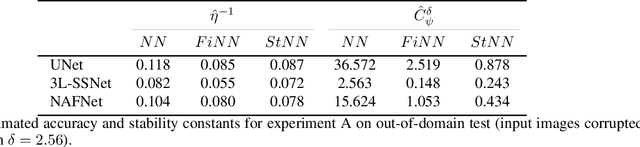

In recent years, large convolutional neural networks have been widely used as tools for image deblurring, because of their ability in restoring images very precisely. It is well known that image deblurring is mathematically modeled as an ill-posed inverse problem and its solution is difficult to approximate when noise affects the data. Really, one limitation of neural networks for deblurring is their sensitivity to noise and other perturbations, which can lead to instability and produce poor reconstructions. In addition, networks do not necessarily take into account the numerical formulation of the underlying imaging problem, when trained end-to-end. In this paper, we propose some strategies to improve stability without losing to much accuracy to deblur images with deep-learning based methods. First, we suggest a very small neural architecture, which reduces the execution time for training, satisfying a green AI need, and does not extremely amplify noise in the computed image. Second, we introduce a unified framework where a pre-processing step balances the lack of stability of the following, neural network-based, step. Two different pre-processors are presented: the former implements a strong parameter-free denoiser, and the latter is a variational model-based regularized formulation of the latent imaging problem. This framework is also formally characterized by mathematical analysis. Numerical experiments are performed to verify the accuracy and stability of the proposed approaches for image deblurring when unknown or not-quantified noise is present; the results confirm that they improve the network stability with respect to noise. In particular, the model-based framework represents the most reliable trade-off between visual precision and robustness.
Efficient PDE-Constrained optimization under high-dimensional uncertainty using derivative-informed neural operators
May 31, 2023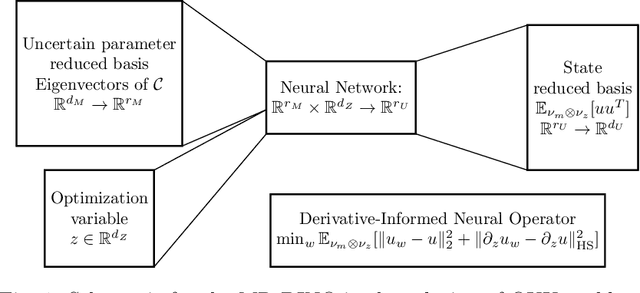

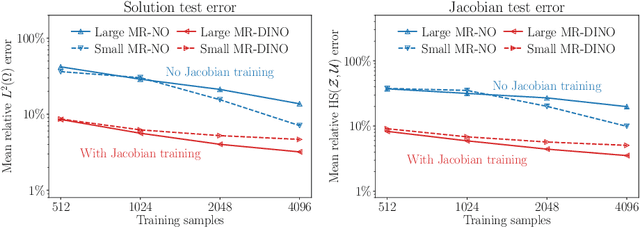
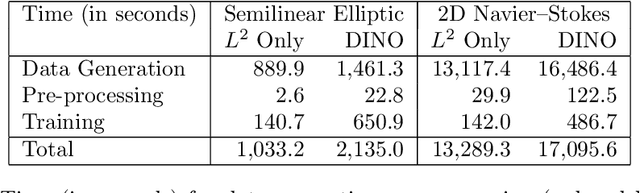
We propose a novel machine learning framework for solving optimization problems governed by large-scale partial differential equations (PDEs) with high-dimensional random parameters. Such optimization under uncertainty (OUU) problems may be computational prohibitive using classical methods, particularly when a large number of samples is needed to evaluate risk measures at every iteration of an optimization algorithm, where each sample requires the solution of an expensive-to-solve PDE. To address this challenge, we propose a new neural operator approximation of the PDE solution operator that has the combined merits of (1) accurate approximation of not only the map from the joint inputs of random parameters and optimization variables to the PDE state, but also its derivative with respect to the optimization variables, (2) efficient construction of the neural network using reduced basis architectures that are scalable to high-dimensional OUU problems, and (3) requiring only a limited number of training data to achieve high accuracy for both the PDE solution and the OUU solution. We refer to such neural operators as multi-input reduced basis derivative informed neural operators (MR-DINOs). We demonstrate the accuracy and efficiency our approach through several numerical experiments, i.e. the risk-averse control of a semilinear elliptic PDE and the steady state Navier--Stokes equations in two and three spatial dimensions, each involving random field inputs. Across the examples, MR-DINOs offer $10^{3}$--$10^{7} \times$ reductions in execution time, and are able to produce OUU solutions of comparable accuracies to those from standard PDE based solutions while being over $10 \times$ more cost-efficient after factoring in the cost of construction.
Putting Natural in Natural Language Processing
May 23, 2023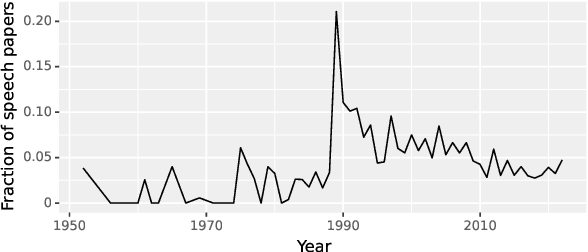
Human language is firstly spoken and only secondarily written. Text, however, is a very convenient and efficient representation of language, and modern civilization has made it ubiquitous. Thus the field of NLP has overwhelmingly focused on processing written rather than spoken language. Work on spoken language, on the other hand, has been siloed off within the largely separate speech processing community which has been inordinately preoccupied with transcribing speech into text. Recent advances in deep learning have led to a fortuitous convergence in methods between speech processing and mainstream NLP. Arguably, the time is ripe for a unification of these two fields, and for starting to take spoken language seriously as the primary mode of human communication. Truly natural language processing could lead to better integration with the rest of language science and could lead to systems which are more data-efficient and more human-like, and which can communicate beyond the textual modality.
Large Language Models are Frame-level Directors for Zero-shot Text-to-Video Generation
May 23, 2023
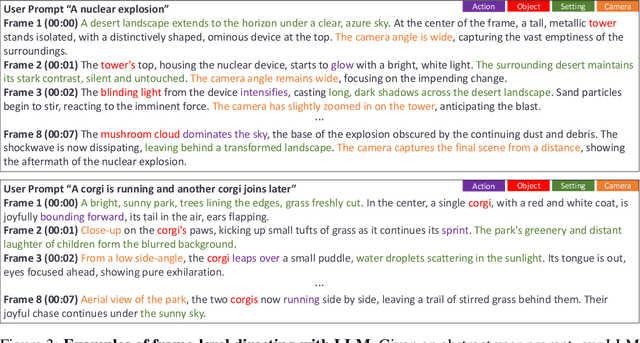
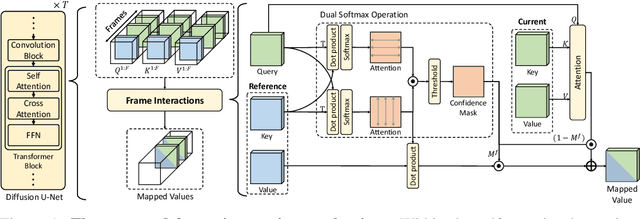
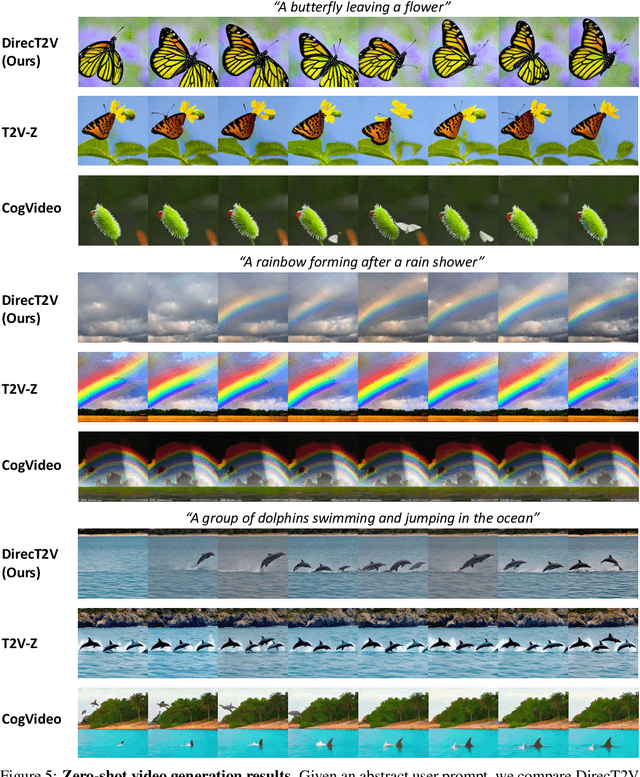
In the paradigm of AI-generated content (AIGC), there has been increasing attention in extending pre-trained text-to-image (T2I) models to text-to-video (T2V) generation. Despite their effectiveness, these frameworks face challenges in maintaining consistent narratives and handling rapid shifts in scene composition or object placement from a single user prompt. This paper introduces a new framework, dubbed DirecT2V, which leverages instruction-tuned large language models (LLMs) to generate frame-by-frame descriptions from a single abstract user prompt. DirecT2V utilizes LLM directors to divide user inputs into separate prompts for each frame, enabling the inclusion of time-varying content and facilitating consistent video generation. To maintain temporal consistency and prevent object collapse, we propose a novel value mapping method and dual-softmax filtering. Extensive experimental results validate the effectiveness of the DirecT2V framework in producing visually coherent and consistent videos from abstract user prompts, addressing the challenges of zero-shot video generation.
A Simple Method for Unsupervised Bilingual Lexicon Induction for Data-Imbalanced, Closely Related Language Pairs
May 23, 2023
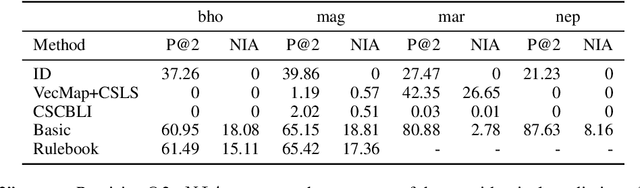
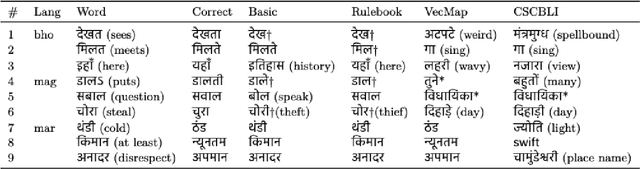

Existing approaches for unsupervised bilingual lexicon induction (BLI) often depend on good quality static or contextual embeddings trained on large monolingual corpora for both languages. In reality, however, unsupervised BLI is most likely to be useful for dialects and languages that do not have abundant amounts of monolingual data. We introduce a simple and fast method for unsupervised BLI for low-resource languages with a related mid-to-high resource language, only requiring inference on the higher-resource language monolingual BERT. We work with two low-resource languages ($<5M$ monolingual tokens), Bhojpuri and Magahi, of the severely under-researched Indic dialect continuum, showing that state-of-the-art methods in the literature show near-zero performance in these settings, and that our simpler method gives much better results. We repeat our experiments on Marathi and Nepali, two higher-resource Indic languages, to compare approach performances by resource range. We release automatically created bilingual lexicons for the first time for five languages of the Indic dialect continuum.
NAIL: Lexical Retrieval Indices with Efficient Non-Autoregressive Decoders
May 23, 2023
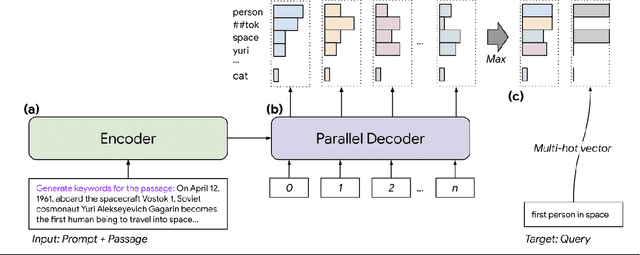
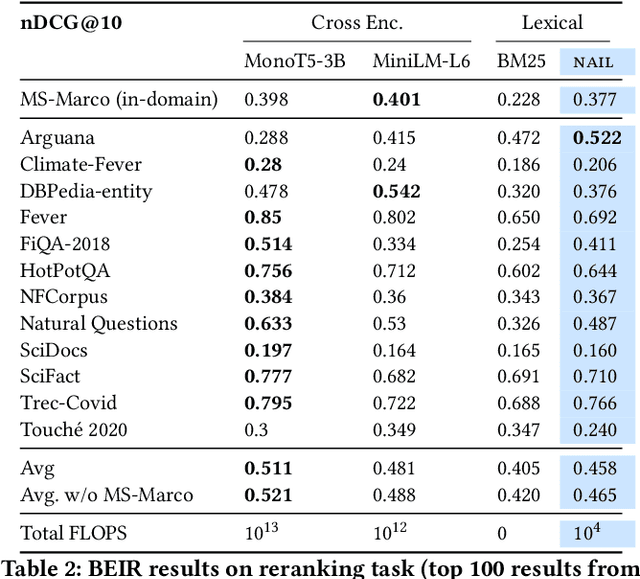
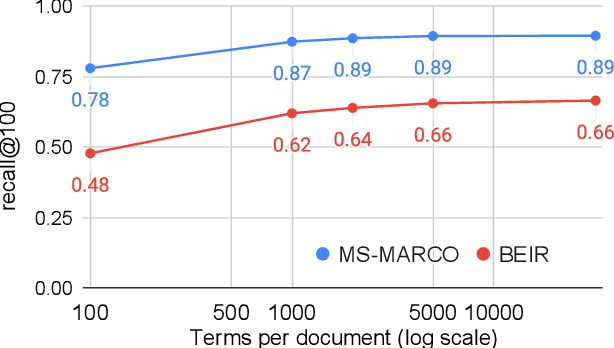
Neural document rerankers are extremely effective in terms of accuracy. However, the best models require dedicated hardware for serving, which is costly and often not feasible. To avoid this serving-time requirement, we present a method of capturing up to 86% of the gains of a Transformer cross-attention model with a lexicalized scoring function that only requires 10-6% of the Transformer's FLOPs per document and can be served using commodity CPUs. When combined with a BM25 retriever, this approach matches the quality of a state-of-the art dual encoder retriever, that still requires an accelerator for query encoding. We introduce NAIL (Non-Autoregressive Indexing with Language models) as a model architecture that is compatible with recent encoder-decoder and decoder-only large language models, such as T5, GPT-3 and PaLM. This model architecture can leverage existing pre-trained checkpoints and can be fine-tuned for efficiently constructing document representations that do not require neural processing of queries.
Goodness of fit by Neyman-Pearson testing
May 23, 2023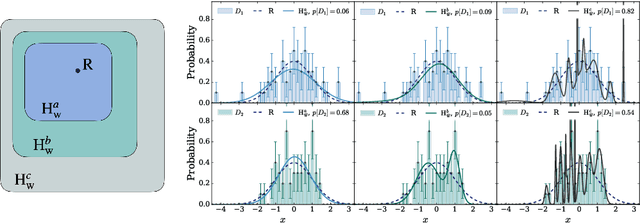
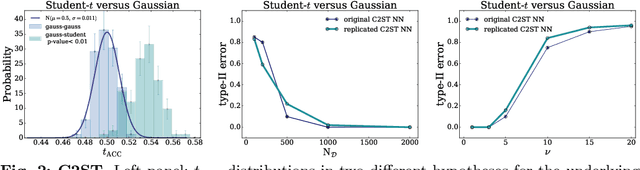
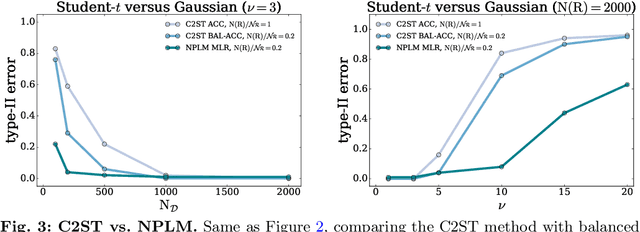
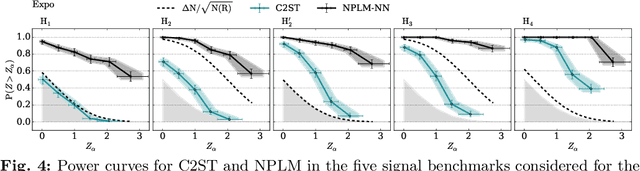
The Neyman-Pearson strategy for hypothesis testing can be employed for goodness of fit if the alternative hypothesis $\rm H_1$ is generic enough not to introduce a significant bias while at the same time avoiding overfitting. A practical implementation of this idea (dubbed NPLM) has been developed in the context of high energy physics, targeting the detection in collider data of new physical effects not foreseen by the Standard Model. In this paper we initiate a comparison of this methodology with other approaches to goodness of fit, and in particular with classifier-based strategies that share strong similarities with NPLM. NPLM emerges from our comparison as more sensitive to small departures of the data from the expected distribution and not biased towards detecting specific types of anomalies while being blind to others. These features make it more suited for agnostic searches for new physics at collider experiments. Its deployment in other contexts should be investigated.
Let's Think Frame by Frame: Evaluating Video Chain of Thought with Video Infilling and Prediction
May 23, 2023


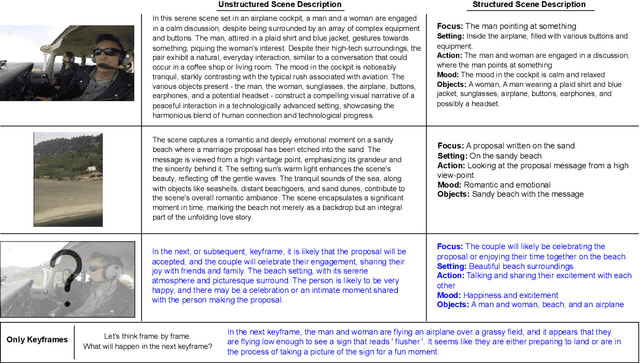
Despite constituting 65% of all internet traffic in 2023, video content is underrepresented in generative AI research. Meanwhile, recent large language models (LLMs) have become increasingly integrated with capabilities in the visual modality. Integrating video with LLMs is a natural next step, so how can this gap be bridged? To advance video reasoning, we propose a new research direction of VideoCOT on video keyframes, which leverages the multimodal generative abilities of vision-language models to enhance video reasoning while reducing the computational complexity of processing hundreds or thousands of frames. We introduce VIP, an inference-time dataset that can be used to evaluate VideoCOT, containing 1) a variety of real-life videos with keyframes and corresponding unstructured and structured scene descriptions, and 2) two new video reasoning tasks: video infilling and scene prediction. We benchmark various vision-language models on VIP, demonstrating the potential to use vision-language models and LLMs to enhance video chain of thought reasoning.