 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Ortho-ODE: Enhancing Robustness and of Neural ODEs against Adversarial Attacks
May 16, 2023
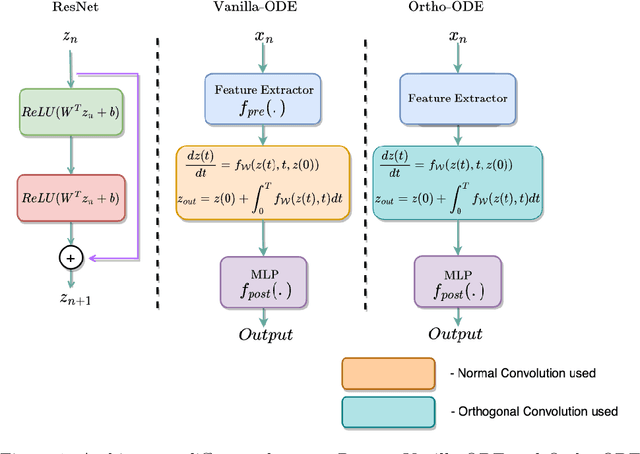
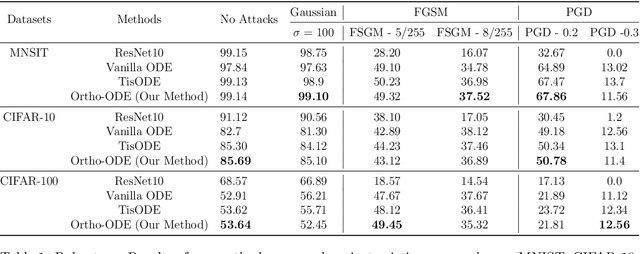
Neural Ordinary Differential Equations (NODEs) probed the usage of numerical solvers to solve the differential equation characterized by a Neural Network (NN), therefore initiating a new paradigm of deep learning models with infinite depth. NODEs were designed to tackle the irregular time series problem. However, NODEs have demonstrated robustness against various noises and adversarial attacks. This paper is about the natural robustness of NODEs and examines the cause behind such surprising behaviour. We show that by controlling the Lipschitz constant of the ODE dynamics the robustness can be significantly improved. We derive our approach from Grownwall's inequality. Further, we draw parallels between contractivity theory and Grownwall's inequality. Experimentally we corroborate the enhanced robustness on numerous datasets - MNIST, CIFAR-10, and CIFAR 100. We also present the impact of adaptive and non-adaptive solvers on the robustness of NODEs.
A Note on Dimensionality Reduction in Deep Neural Networks using Empirical Interpolation Method
May 16, 2023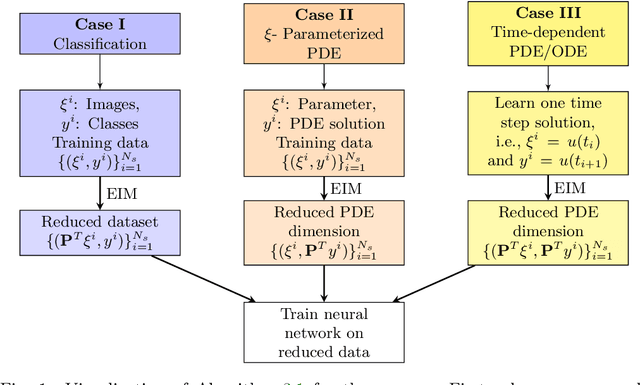


Empirical interpolation method (EIM) is a well-known technique to efficiently approximate parameterized functions. This paper proposes to use EIM algorithm to efficiently reduce the dimension of the training data within supervised machine learning. This is termed as DNN-EIM. Applications in data science (e.g., MNIST) and parameterized (and time-dependent) partial differential equations (PDEs) are considered. The proposed DNNs in case of classification are trained in parallel for each class. This approach is sequential, i.e., new classes can be added without having to retrain the network. In case of PDEs, a DNN is designed corresponding to each EIM point. Again, these networks can be trained in parallel, for each EIM point. In all cases, the parallel networks require fewer than ten times the number of training weights. Significant gains are observed in terms of training times, without sacrificing accuracy.
Generative Adversarial Networks for Brain Images Synthesis: A Review
May 16, 2023
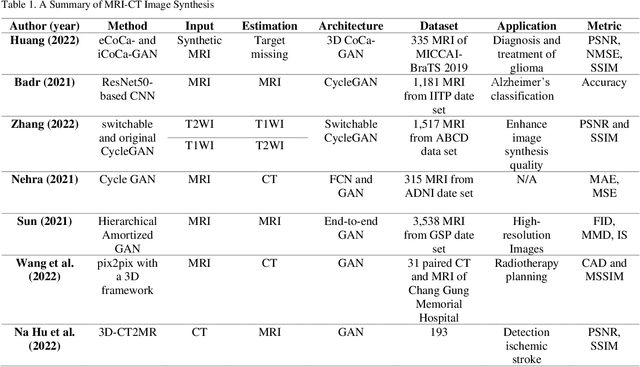
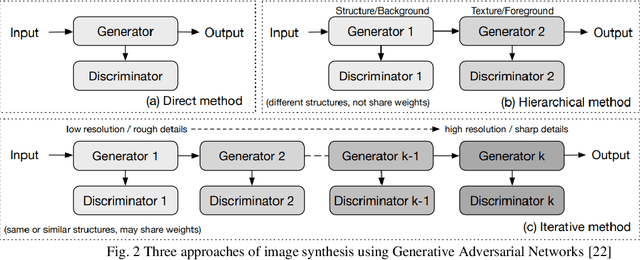
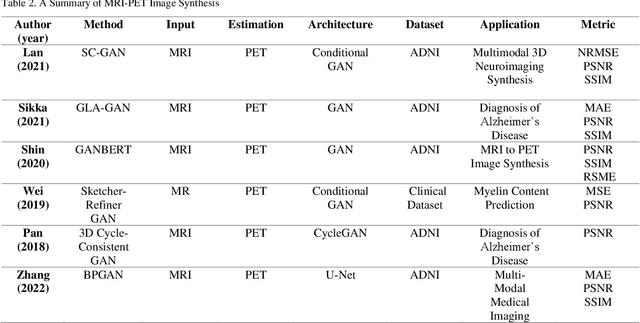
In medical imaging, image synthesis is the estimation process of one image (sequence, modality) from another image (sequence, modality). Since images with different modalities provide diverse biomarkers and capture various features, multi-modality imaging is crucial in medicine. While multi-screening is expensive, costly, and time-consuming to report by radiologists, image synthesis methods are capable of artificially generating missing modalities. Deep learning models can automatically capture and extract the high dimensional features. Especially, generative adversarial network (GAN) as one of the most popular generative-based deep learning methods, uses convolutional networks as generators, and estimated images are discriminated as true or false based on a discriminator network. This review provides brain image synthesis via GANs. We summarized the recent developments of GANs for cross-modality brain image synthesis including CT to PET, CT to MRI, MRI to PET, and vice versa.
M-L2O: Towards Generalizable Learning-to-Optimize by Test-Time Fast Self-Adaptation
Feb 28, 2023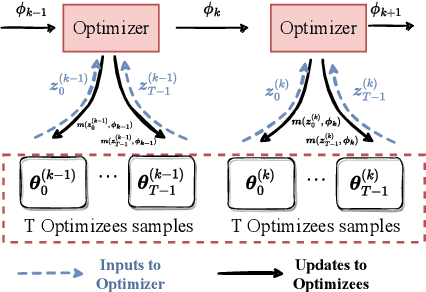
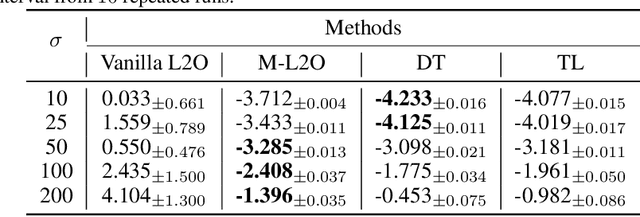
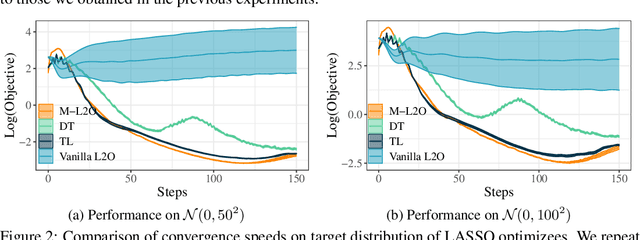
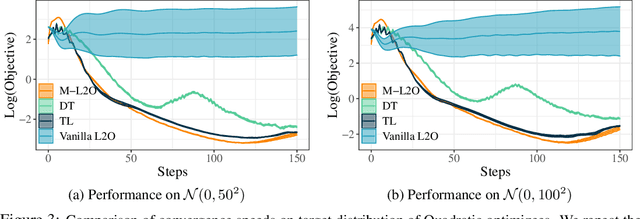
Learning to Optimize (L2O) has drawn increasing attention as it often remarkably accelerates the optimization procedure of complex tasks by ``overfitting" specific task type, leading to enhanced performance compared to analytical optimizers. Generally, L2O develops a parameterized optimization method (i.e., ``optimizer") by learning from solving sample problems. This data-driven procedure yields L2O that can efficiently solve problems similar to those seen in training, that is, drawn from the same ``task distribution". However, such learned optimizers often struggle when new test problems come with a substantially deviation from the training task distribution. This paper investigates a potential solution to this open challenge, by meta-training an L2O optimizer that can perform fast test-time self-adaptation to an out-of-distribution task, in only a few steps. We theoretically characterize the generalization of L2O, and further show that our proposed framework (termed as M-L2O) provably facilitates rapid task adaptation by locating well-adapted initial points for the optimizer weight. Empirical observations on several classic tasks like LASSO and Quadratic, demonstrate that M-L2O converges significantly faster than vanilla L2O with only $5$ steps of adaptation, echoing our theoretical results. Codes are available in https://github.com/VITA-Group/M-L2O.
Toeplitz Neural Network for Sequence Modeling
May 08, 2023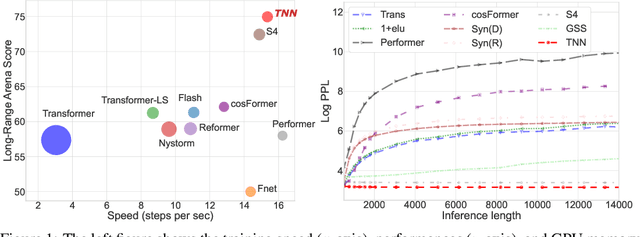

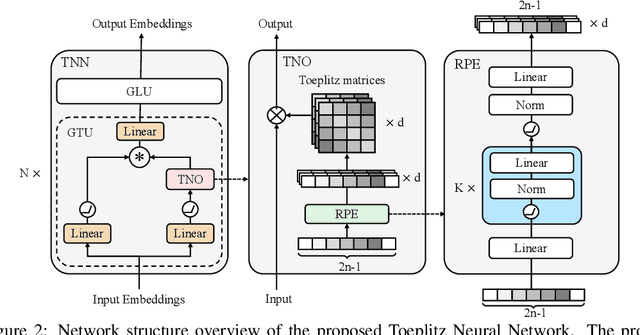
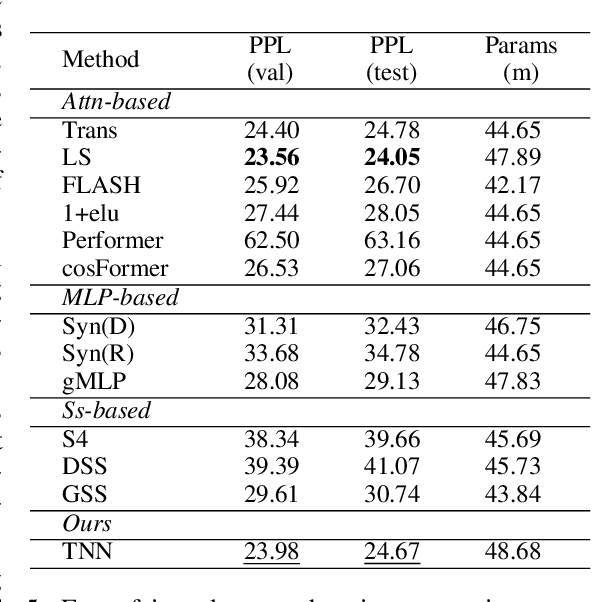
Sequence modeling has important applications in natural language processing and computer vision. Recently, the transformer-based models have shown strong performance on various sequence modeling tasks, which rely on attention to capture pairwise token relations, and position embedding to inject positional information. While showing good performance, the transformer models are inefficient to scale to long input sequences, mainly due to the quadratic space-time complexity of attention. To overcome this inefficiency, we propose to model sequences with a relative position encoded Toeplitz matrix and use a Toeplitz matrix-vector production trick to reduce the space-time complexity of the sequence modeling to log linear. A lightweight sub-network called relative position encoder is proposed to generate relative position coefficients with a fixed budget of parameters, enabling the proposed Toeplitz neural network to deal with varying sequence lengths. In addition, despite being trained on 512-token sequences, our model can extrapolate input sequence length up to 14K tokens in inference with consistent performance. Extensive experiments on autoregressive and bidirectional language modeling, image modeling, and the challenging Long-Range Arena benchmark show that our method achieves better performance than its competitors in most downstream tasks while being significantly faster. The code is available at https://github.com/OpenNLPLab/Tnn.
TR3D: Towards Real-Time Indoor 3D Object Detection
Feb 06, 2023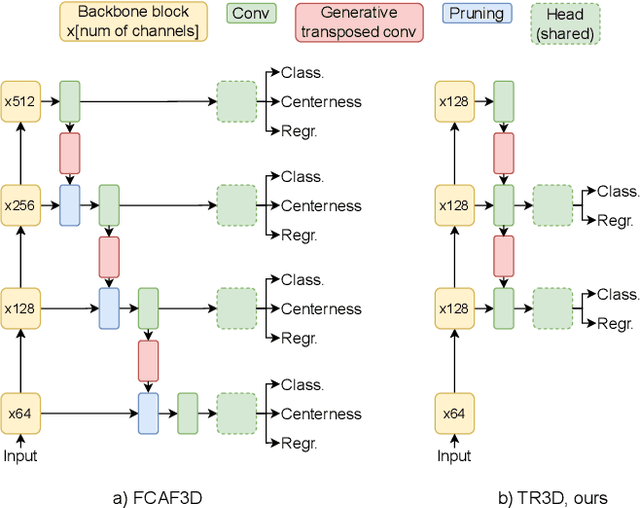
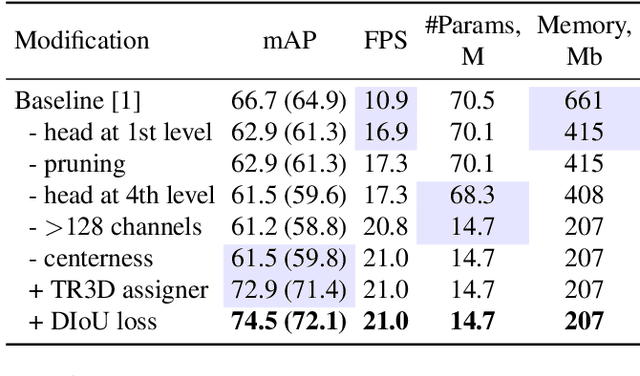

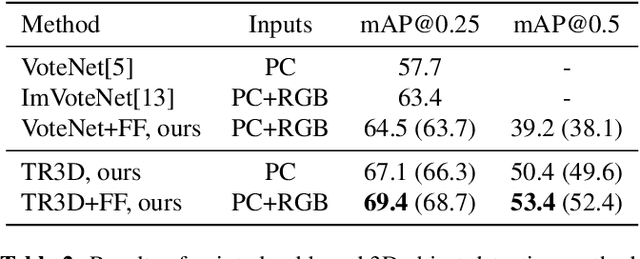
Recently, sparse 3D convolutions have changed 3D object detection. Performing on par with the voting-based approaches, 3D CNNs are memory-efficient and scale to large scenes better. However, there is still room for improvement. With a conscious, practice-oriented approach to problem-solving, we analyze the performance of such methods and localize the weaknesses. Applying modifications that resolve the found issues one by one, we end up with TR3D: a fast fully-convolutional 3D object detection model trained end-to-end, that achieves state-of-the-art results on the standard benchmarks, ScanNet v2, SUN RGB-D, and S3DIS. Moreover, to take advantage of both point cloud and RGB inputs, we introduce an early fusion of 2D and 3D features. We employ our fusion module to make conventional 3D object detection methods multimodal and demonstrate an impressive boost in performance. Our model with early feature fusion, which we refer to as TR3D+FF, outperforms existing 3D object detection approaches on the SUN RGB-D dataset. Overall, besides being accurate, both TR3D and TR3D+FF models are lightweight, memory-efficient, and fast, thereby marking another milestone on the way toward real-time 3D object detection. Code is available at https://github.com/SamsungLabs/tr3d .
HFLIC: Human Friendly Perceptual Learned Image Compression with Reinforced Transform
May 15, 2023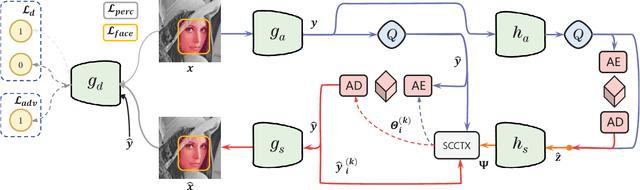
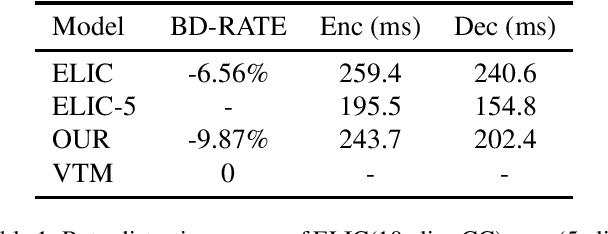
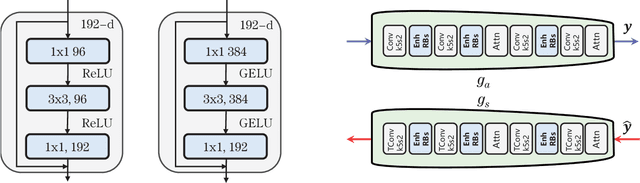
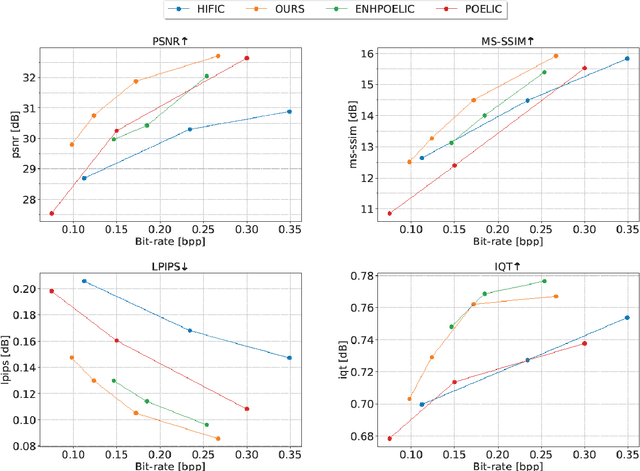
In recent years, there has been rapid development in learned image compression techniques that prioritize ratedistortion-perceptual compression, preserving fine details even at lower bit-rates. However, current learning-based image compression methods often sacrifice human-friendly compression and require long decoding times. In this paper, we propose enhancements to the backbone network and loss function of existing image compression model, focusing on improving human perception and efficiency. Our proposed approach achieves competitive subjective results compared to state-of-the-art end-to-end learned image compression methods and classic methods, while requiring less decoding time and offering human-friendly compression. Through empirical evaluation, we demonstrate the effectiveness of our proposed method in achieving outstanding performance, with more than 25% bit-rate saving at the same subjective quality.
A Momentum-Incorporated Non-Negative Latent Factorization of Tensors Model for Dynamic Network Representation
May 04, 2023A large-scale dynamic network (LDN) is a source of data in many big data-related applications due to their large number of entities and large-scale dynamic interactions. They can be modeled as a high-dimensional incomplete (HDI) tensor that contains a wealth of knowledge about time patterns. A Latent factorization of tensors (LFT) model efficiently extracts this time pattern, which can be established using stochastic gradient descent (SGD) solvers. However, LFT models based on SGD are often limited by training schemes and have poor tail convergence. To solve this problem, this paper proposes a novel nonlinear LFT model (MNNL) based on momentum-incorporated SGD, which extracts non-negative latent factors from HDI tensors to make training unconstrained and compatible with general training schemes, while improving convergence accuracy and speed. Empirical studies on two LDN datasets show that compared to existing models, the MNNL model has higher prediction accuracy and convergence speed.
Dual flow fusion model for concrete surface crack segmentation
May 09, 2023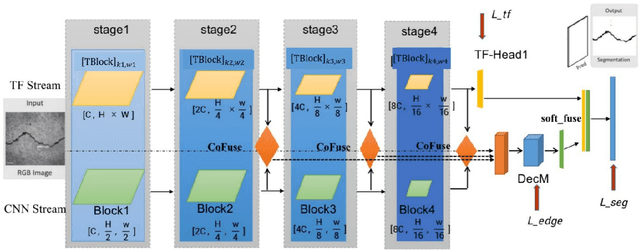
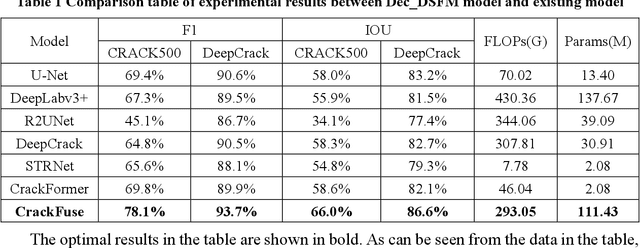
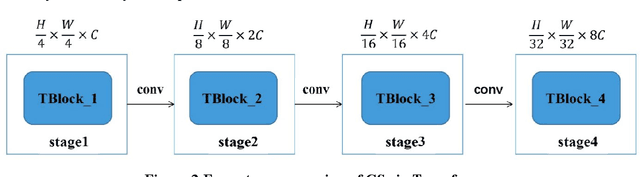
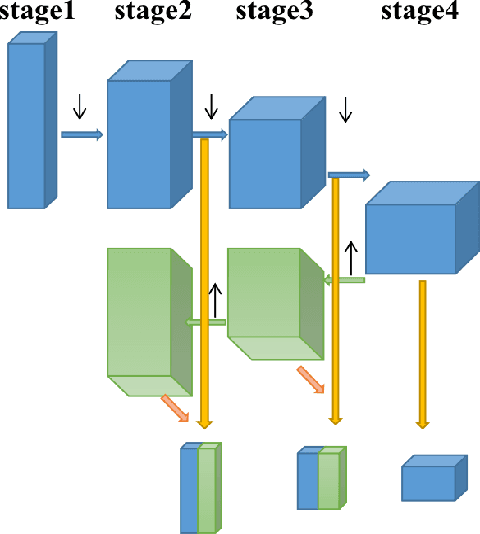
Cracks and other diseases are important factors that threaten the safe operation of transportation infrastructure. Traditional manual detection and ultrasonic instrument detection consume a lot of time and resource costs. With the development of deep learning technology, many deep learning models are widely used in actual visual segmentation tasks. The detection method based on the deep learning model has the advantages of high detection accuracy, fast detection speed and simple operation. However, the crack segmentation based on deep learning has problems such as sensitivity to background noise, rough edges, and lack of robustness. Therefore, this paper proposes a fissure segmentation model based on two-stream fusion, which simultaneously inputs images into two designed processing streams to independently extract long-distance dependent and local detail features, and realizes adaptive prediction through a dual-head mechanism. At the same time, a new interactive fusion mechanism is proposed to guide the complementarity of different levels of features to realize the location and identification of cracks in complex backgrounds. Finally, we propose an edge optimization method to improve segmentation accuracy. Experiments have proved that the F1 value of the segmentation results on the DeepCrack[1] public dataset reached 93.7%, and the IOU value reached 86.6%; the F1 value of the segmentation results on the CRACK500[2] dataset reached 78.1%, and the IOU value reached 66.0%.
GraVAC: Adaptive Compression for Communication-Efficient Distributed DL Training
May 20, 2023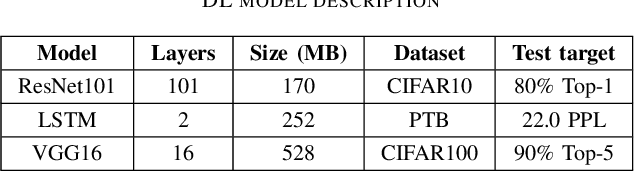
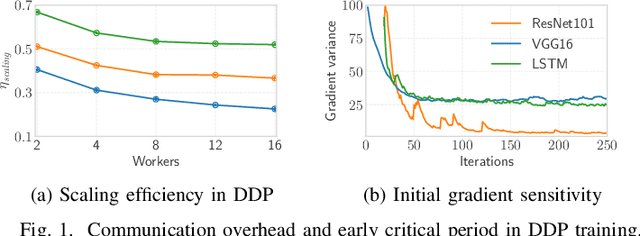
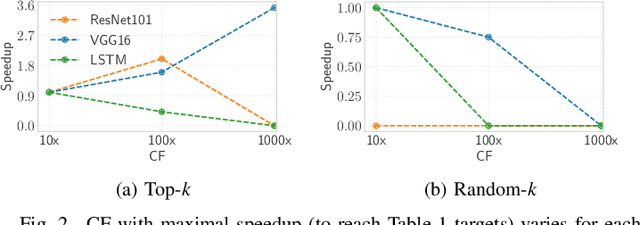
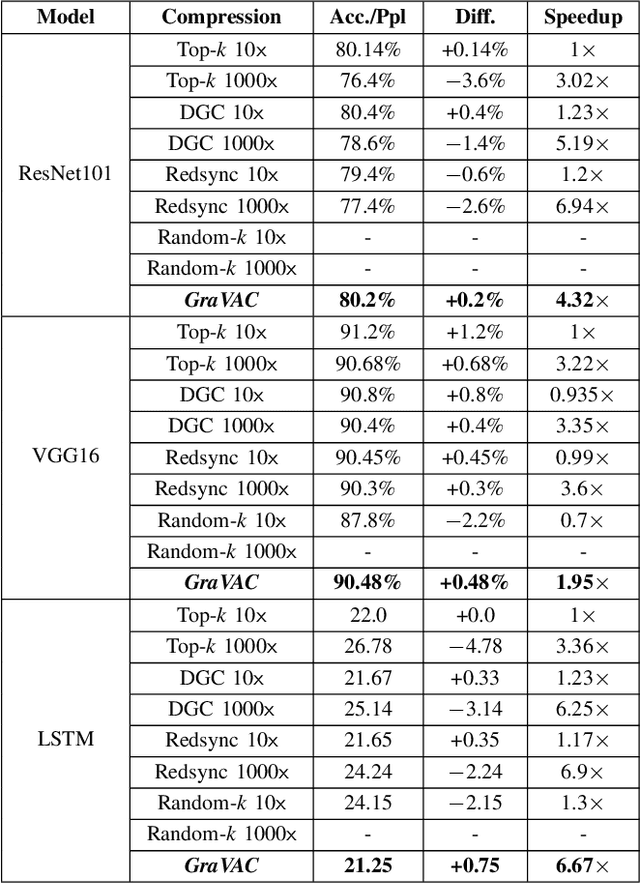
Distributed data-parallel (DDP) training improves overall application throughput as multiple devices train on a subset of data and aggregate updates to produce a globally shared model. The periodic synchronization at each iteration incurs considerable overhead, exacerbated by the increasing size and complexity of state-of-the-art neural networks. Although many gradient compression techniques propose to reduce communication cost, the ideal compression factor that leads to maximum speedup or minimum data exchange remains an open-ended problem since it varies with the quality of compression, model size and structure, hardware, network topology and bandwidth. We propose GraVAC, a framework to dynamically adjust compression factor throughout training by evaluating model progress and assessing gradient information loss associated with compression. GraVAC works in an online, black-box manner without any prior assumptions about a model or its hyperparameters, while achieving the same or better accuracy than dense SGD (i.e., no compression) in the same number of iterations/epochs. As opposed to using a static compression factor, GraVAC reduces end-to-end training time for ResNet101, VGG16 and LSTM by 4.32x, 1.95x and 6.67x respectively. Compared to other adaptive schemes, our framework provides 1.94x to 5.63x overall speedup.