 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Error Detection for Text-to-SQL Semantic Parsing
May 23, 2023
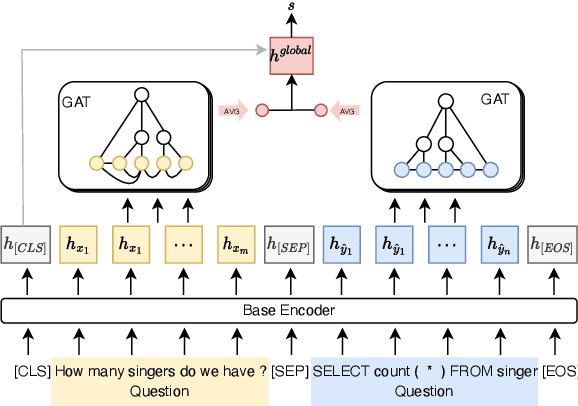

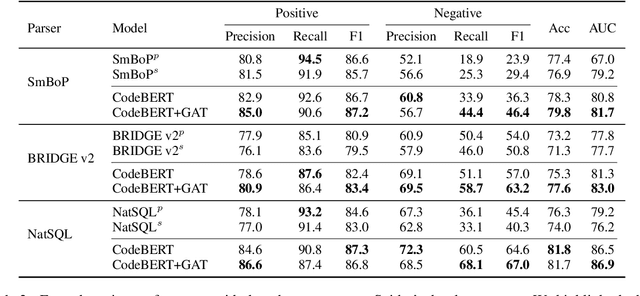
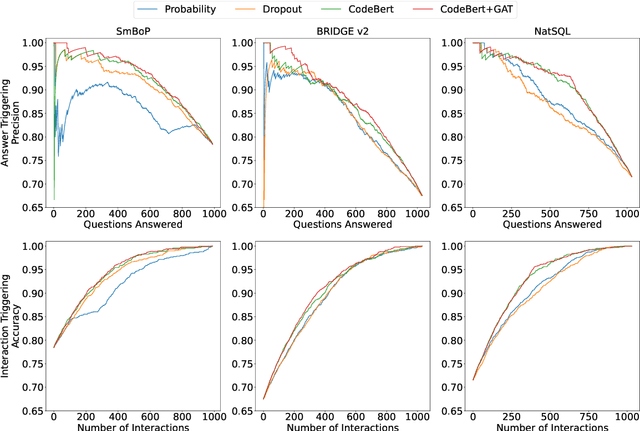
Despite remarkable progress in text-to-SQL semantic parsing in recent years, the performance of existing parsers is still far from perfect. At the same time, modern deep learning based text-to-SQL parsers are often over-confident and thus casting doubt on their trustworthiness when deployed for real use. To that end, we propose to build a parser-independent error detection model for text-to-SQL semantic parsing. The proposed model is based on pre-trained language model of code and is enhanced with structural features learned by graph neural networks. We train our model on realistic parsing errors collected from a cross-domain setting. Experiments with three strong text-to-SQL parsers featuring different decoding mechanisms show that our approach outperforms parser-dependent uncertainty metrics and could effectively improve the performance and usability of text-to-SQL semantic parsers regardless of their architectures.
Improving Text-based Early Prediction by Distillation from Privileged Time-Series Text
Jan 26, 2023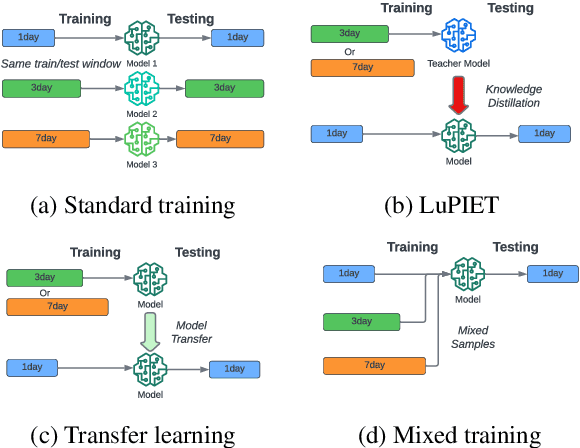
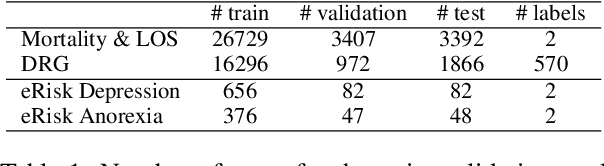
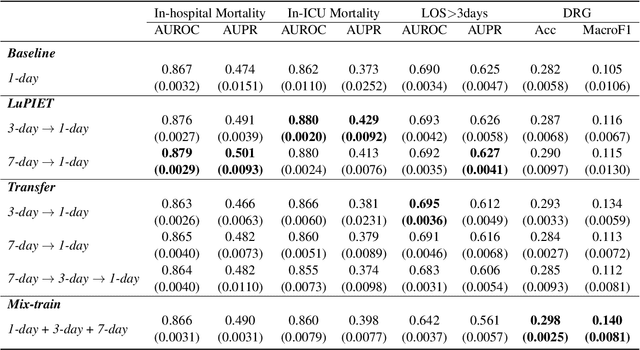
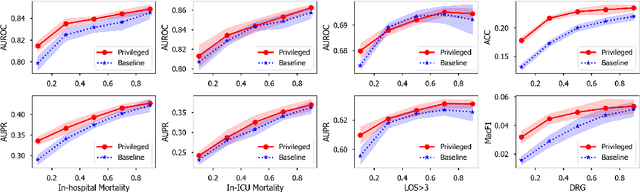
Modeling text-based time-series to make prediction about a future event or outcome is an important task with a wide range of applications. The standard approach is to train and test the model using the same input window, but this approach neglects the data collected in longer input windows between the prediction time and the final outcome, which are often available during training. In this study, we propose to treat this neglected text as privileged information available during training to enhance early prediction modeling through knowledge distillation, presented as Learning using Privileged tIme-sEries Text (LuPIET). We evaluate the method on clinical and social media text, with four clinical prediction tasks based on clinical notes and two mental health prediction tasks based on social media posts. Our results show LuPIET is effective in enhancing text-based early predictions, though one may need to consider choosing the appropriate text representation and windows for privileged text to achieve optimal performance. Compared to two other methods using transfer learning and mixed training, LuPIET offers more stable improvements over the baseline, standard training. As far as we are concerned, this is the first study to examine learning using privileged information for time-series in the NLP context.
FedTADBench: Federated Time-Series Anomaly Detection Benchmark
Dec 19, 2022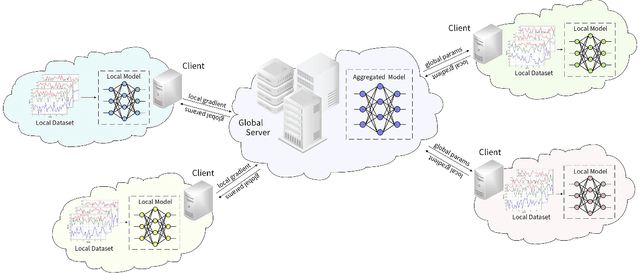
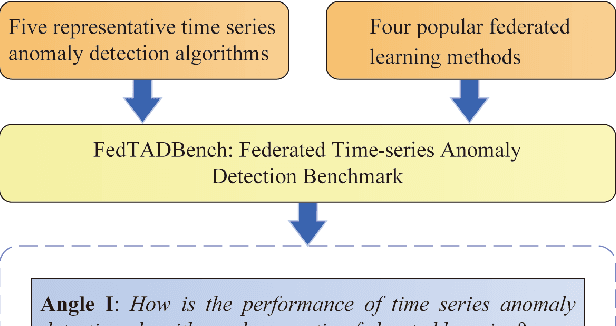
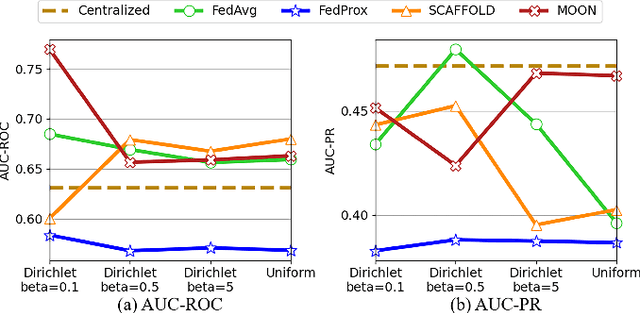
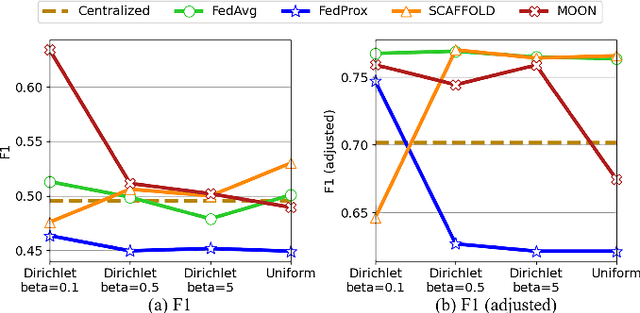
Time series anomaly detection strives to uncover potential abnormal behaviors and patterns from temporal data, and has fundamental significance in diverse application scenarios. Constructing an effective detection model usually requires adequate training data stored in a centralized manner, however, this requirement sometimes could not be satisfied in realistic scenarios. As a prevailing approach to address the above problem, federated learning has demonstrated its power to cooperate with the distributed data available while protecting the privacy of data providers. However, it is still unclear that how existing time series anomaly detection algorithms perform with decentralized data storage and privacy protection through federated learning. To study this, we conduct a federated time series anomaly detection benchmark, named FedTADBench, which involves five representative time series anomaly detection algorithms and four popular federated learning methods. We would like to answer the following questions: (1)How is the performance of time series anomaly detection algorithms when meeting federated learning? (2) Which federated learning method is the most appropriate one for time series anomaly detection? (3) How do federated time series anomaly detection approaches perform on different partitions of data in clients? Numbers of results as well as corresponding analysis are provided from extensive experiments with various settings. The source code of our benchmark is publicly available at https://github.com/fanxingliu2020/FedTADBench.
Towards Total Online Unsupervised Anomaly Detection and Localization in Industrial Vision
May 25, 2023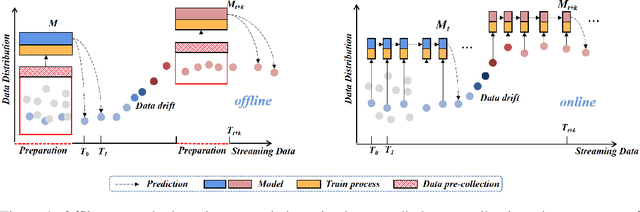

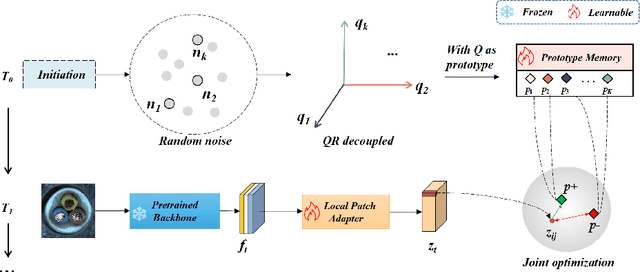
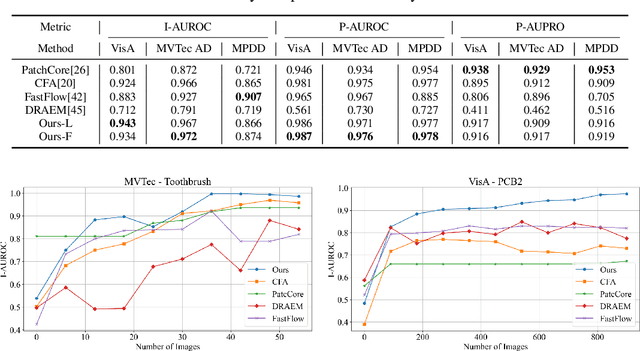
Although existing image anomaly detection methods yield impressive results, they are mostly an offline learning paradigm that requires excessive data pre-collection, limiting their adaptability in industrial scenarios with online streaming data. Online learning-based image anomaly detection methods are more compatible with industrial online streaming data but are rarely noticed. For the first time, this paper presents a fully online learning image anomaly detection method, namely LeMO, learning memory for online image anomaly detection. LeMO leverages learnable memory initialized with orthogonal random noise, eliminating the need for excessive data in memory initialization and circumventing the inefficiencies of offline data collection. Moreover, a contrastive learning-based loss function for anomaly detection is designed to enable online joint optimization of memory and image target-oriented features. The presented method is simple and highly effective. Extensive experiments demonstrate the superior performance of LeMO in the online setting. Additionally, in the offline setting, LeMO is also competitive with the current state-of-the-art methods and achieves excellent performance in few-shot scenarios.
Enhanced 6D Pose Estimation for Robotic Fruit Picking
May 25, 2023
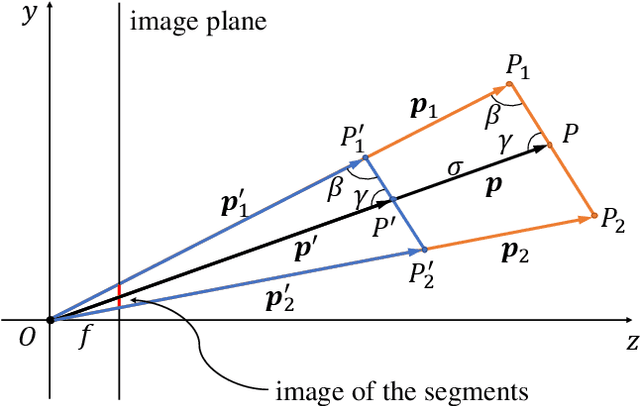

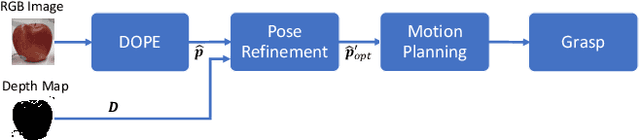
This paper proposes a novel method to refine the 6D pose estimation inferred by an instance-level deep neural network which processes a single RGB image and that has been trained on synthetic images only. The proposed optimization algorithm usefully exploits the depth measurement of a standard RGB-D camera to estimate the dimensions of the considered object, even though the network is trained on a single CAD model of the same object with given dimensions. The improved accuracy in the pose estimation allows a robot to grasp apples of various types and significantly different dimensions successfully; this was not possible using the standard pose estimation algorithm, except for the fruits with dimensions very close to those of the CAD drawing used in the training process. Grasping fresh fruits without damaging each item also demands a suitable grasp force control. A parallel gripper equipped with special force/tactile sensors is thus adopted to achieve safe grasps with the minimum force necessary to lift the fruits without any slippage and any deformation at the same time, with no knowledge of their weight.
Knowledge-Design: Pushing the Limit of Protein Deign via Knowledge Refinement
May 25, 2023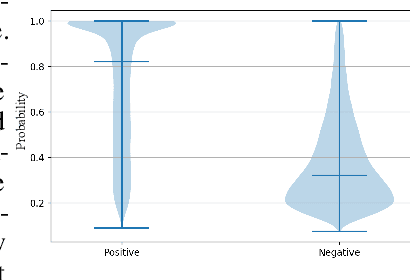
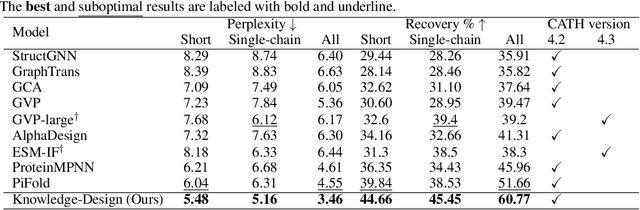
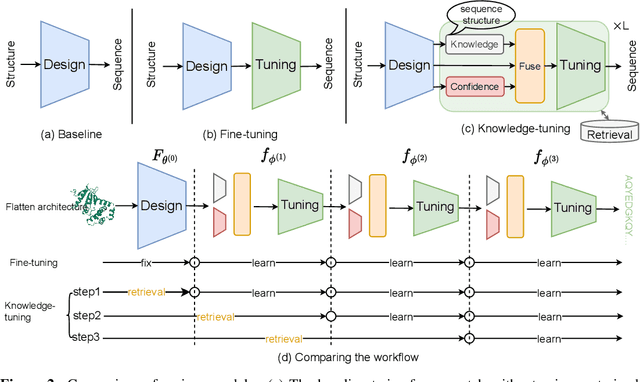
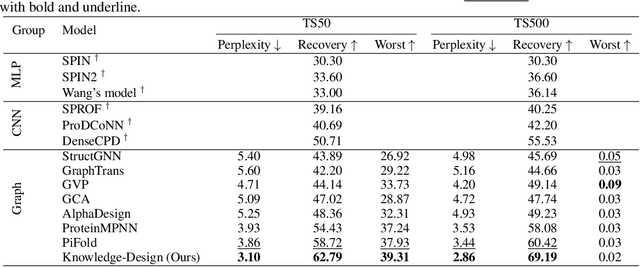
Recent studies have shown competitive performance in protein design that aims to find the amino acid sequence folding into the desired structure. However, most of them disregard the importance of predictive confidence, fail to cover the vast protein space, and do not incorporate common protein knowledge. After witnessing the great success of pretrained models on diverse protein-related tasks and the fact that recovery is highly correlated with confidence, we wonder whether this knowledge can push the limits of protein design further. As a solution, we propose a knowledge-aware module that refines low-quality residues. We also introduce a memory-retrieval mechanism to save more than 50\% of the training time. We extensively evaluate our proposed method on the CATH, TS50, and TS500 datasets and our results show that our Knowledge-Design method outperforms the previous PiFold method by approximately 9\% on the CATH dataset. Specifically, Knowledge-Design is the first method that achieves 60+\% recovery on CATH, TS50 and TS500 benchmarks. We also provide additional analysis to demonstrate the effectiveness of our proposed method. The code will be publicly available.
Grouping Method for mmWave Massive MIMO System: Exploitation of Angular Multiplexing Gain
May 25, 2023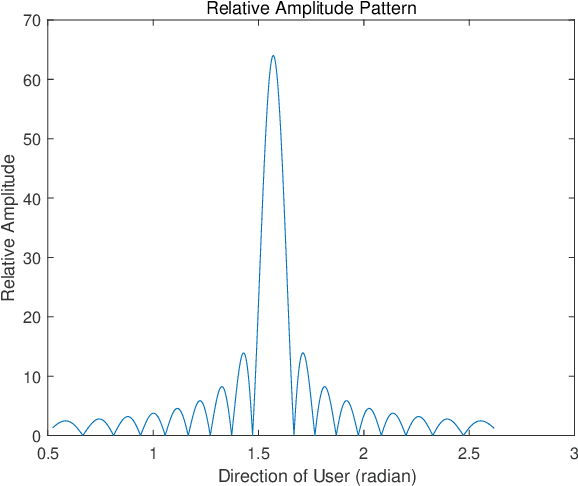
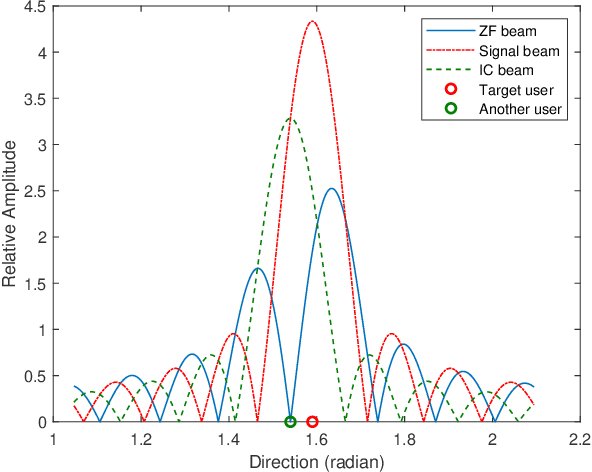
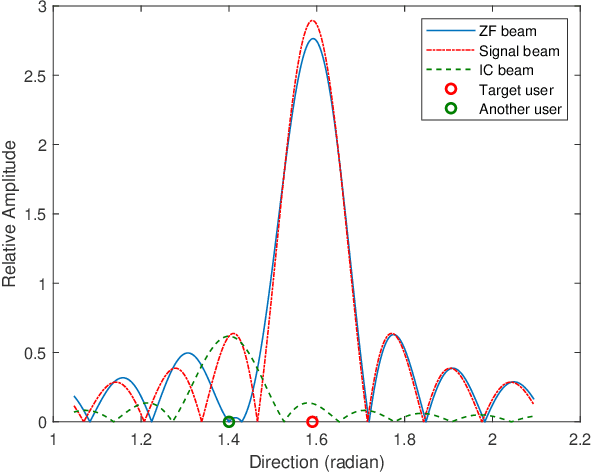
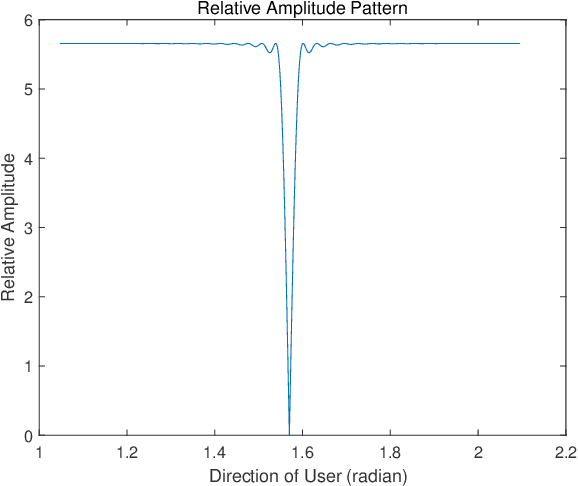
A future millimeter-wave (mmWave) massive multiple-input and multiple-output (MIMO) system may serve hundreds or thousands of users at the same time; thus, research on multiple access technology is particularly important.Moreover, due to the short-wavelength nature of a mmWave, large-scale arrays are easier to implement than microwaves, while their directivity and sparseness make the physical beamforming effect of precoding more prominent.In consideration of the mmWave angle division multiple access (ADMA) system based on precoding, this paper investigates the influence of the angle distribution on system performance, which is denoted as the angular multiplexing gain.Furthermore, inspired by the above research, we transform the ADMA user grouping problem to maximize the system sum-rate into the inter-user angular spacing equalization problem.Then, the form of the optimal solution for the approximate problem is derived, and the corresponding grouping algorithm is proposed.The simulation results demonstrate that the proposed algorithm performs better than the comparison methods.Finally, a complexity analysis also shows that the proposed algorithm has extremely low complexity.
Vision-based UAV Detection in Complex Backgrounds and Rainy Conditions
May 25, 2023

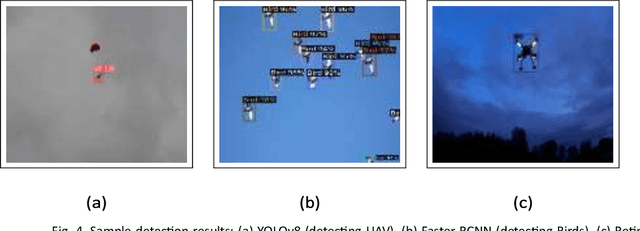

To detect UAVs in real-time, computer vision and deep learning approaches are developing areas of research. There have been concerns raised regarding the possible hazards and misuse of employing unmanned aerial vehicles (UAVs) in many applications. These include potential privacy violations, safety-related issues, and security threats. Vision-based detection systems often comprise a combination of hardware components such as cameras and software components. In this work, the performance of recent and popular vision-based object detection techniques is investigated for the task of UAV detection under challenging conditions such as complex backgrounds, varying UAV sizes, complex background scenarios, and low-to-heavy rainy conditions. To study the performance of selected methods under these conditions, two datasets were curated: one with a sky background and one with complex background. In this paper, one-stage detectors and two-stage detectors are studied and evaluated. The findings presented in the paper shall help provide insights concerning the performance of the selected models for the task of UAV detection under challenging conditions and pave the way to develop more robust UAV detection methods
Response Generation in Longitudinal Dialogues: Which Knowledge Representation Helps?
May 25, 2023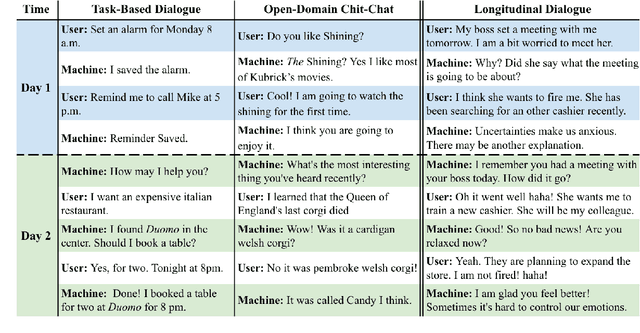

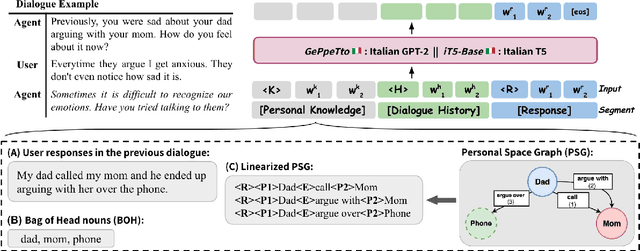
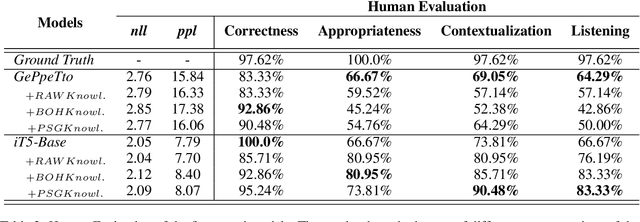
Longitudinal Dialogues (LD) are the most challenging type of conversation for human-machine dialogue systems. LDs include the recollections of events, personal thoughts, and emotions specific to each individual in a sparse sequence of dialogue sessions. Dialogue systems designed for LDs should uniquely interact with the users over multiple sessions and long periods of time (e.g. weeks), and engage them in personal dialogues to elaborate on their feelings, thoughts, and real-life events. In this paper, we study the task of response generation in LDs. We evaluate whether general-purpose Pre-trained Language Models (PLM) are appropriate for this purpose. We fine-tune two PLMs, GePpeTto (GPT-2) and iT5, using a dataset of LDs. We experiment with different representations of the personal knowledge extracted from LDs for grounded response generation, including the graph representation of the mentioned events and participants. We evaluate the performance of the models via automatic metrics and the contribution of the knowledge via the Integrated Gradients technique. We categorize the natural language generation errors via human evaluations of contextualization, appropriateness and engagement of the user.
Learning Robust Statistics for Simulation-based Inference under Model Misspecification
May 25, 2023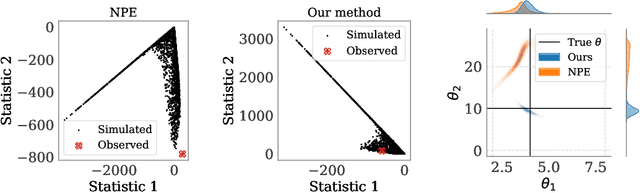
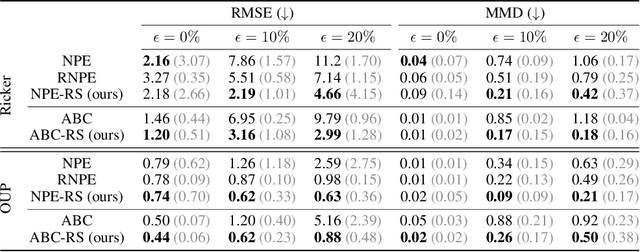
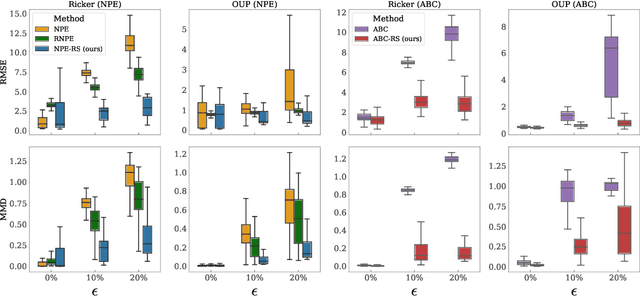
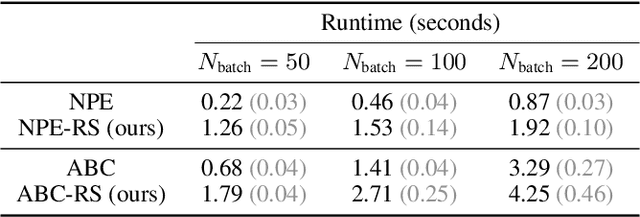
Simulation-based inference (SBI) methods such as approximate Bayesian computation (ABC), synthetic likelihood, and neural posterior estimation (NPE) rely on simulating statistics to infer parameters of intractable likelihood models. However, such methods are known to yield untrustworthy and misleading inference outcomes under model misspecification, thus hindering their widespread applicability. In this work, we propose the first general approach to handle model misspecification that works across different classes of SBI methods. Leveraging the fact that the choice of statistics determines the degree of misspecification in SBI, we introduce a regularized loss function that penalises those statistics that increase the mismatch between the data and the model. Taking NPE and ABC as use cases, we demonstrate the superior performance of our method on high-dimensional time-series models that are artificially misspecified. We also apply our method to real data from the field of radio propagation where the model is known to be misspecified. We show empirically that the method yields robust inference in misspecified scenarios, whilst still being accurate when the model is well-specified.