 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Dissecting Chain-of-Thought: A Study on Compositional In-Context Learning of MLPs
May 30, 2023
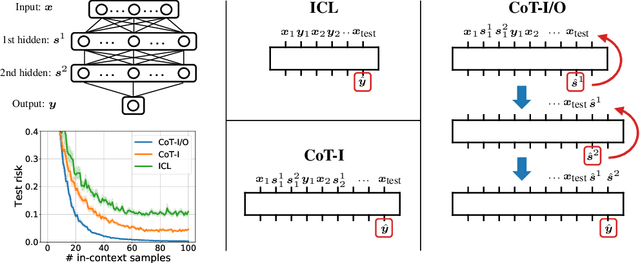
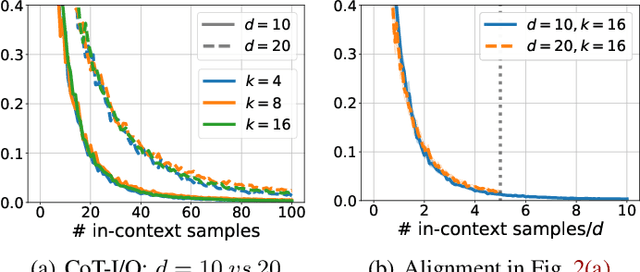
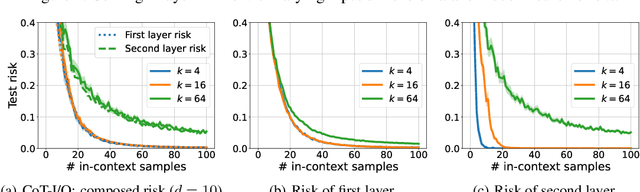
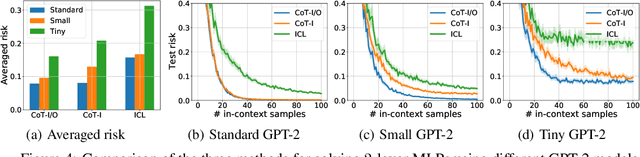
Chain-of-thought (CoT) is a method that enables language models to handle complex reasoning tasks by decomposing them into simpler steps. Despite its success, the underlying mechanics of CoT are not yet fully understood. In an attempt to shed light on this, our study investigates the impact of CoT on the ability of transformers to in-context learn a simple to study, yet general family of compositional functions: multi-layer perceptrons (MLPs). In this setting, we reveal that the success of CoT can be attributed to breaking down in-context learning of a compositional function into two distinct phases: focusing on data related to each step of the composition and in-context learning the single-step composition function. Through both experimental and theoretical evidence, we demonstrate how CoT significantly reduces the sample complexity of in-context learning (ICL) and facilitates the learning of complex functions that non-CoT methods struggle with. Furthermore, we illustrate how transformers can transition from vanilla in-context learning to mastering a compositional function with CoT by simply incorporating an additional layer that performs the necessary filtering for CoT via the attention mechanism. In addition to these test-time benefits, we highlight how CoT accelerates pretraining by learning shortcuts to represent complex functions and how filtering plays an important role in pretraining. These findings collectively provide insights into the mechanics of CoT, inviting further investigation of its role in complex reasoning tasks.
Dynamic and Rapid Deep Synthesis of Molecular MRI Signals
May 30, 2023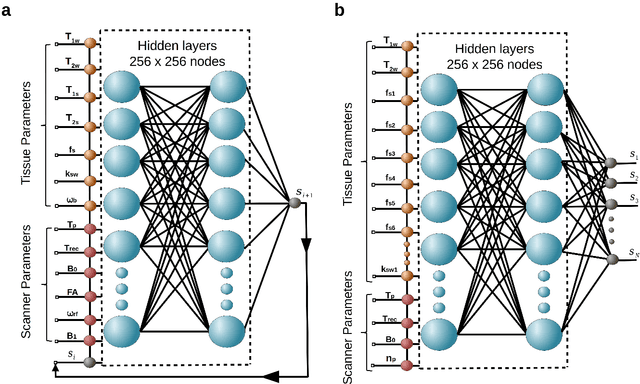

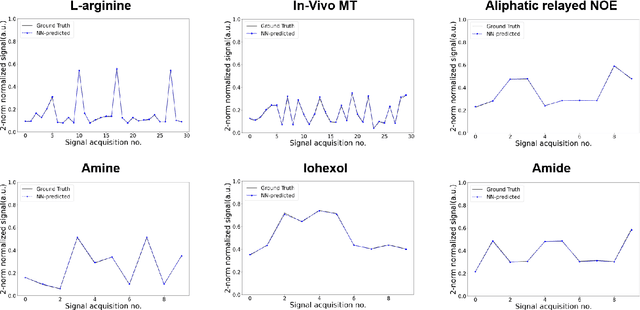
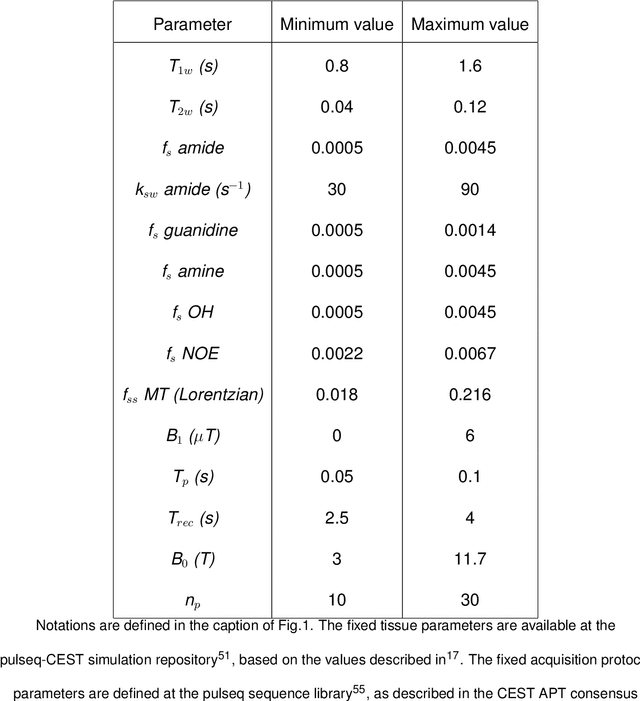
Model-driven analysis of biophysical phenomena is gaining increased attention and utility for medical imaging applications. In magnetic resonance imaging (MRI), the availability of well-established models for describing the relations between the nuclear magnetization, tissue properties, and the externally applied magnetic fields has enabled the prediction of image contrast and served as a powerful tool for designing the imaging protocols that are now routinely used in the clinic. Recently, various advanced imaging techniques have relied on these models for image reconstruction, quantitative tissue parameter extraction, and automatic optimization of acquisition protocols. In molecular MRI, however, the increased complexity of the imaging scenario, where the signals from various chemical compounds and multiple proton pools must be accounted for, results in exceedingly long model simulation times, severely hindering the progress of this approach and its dissemination for various clinical applications. Here, we show that a deep-learning-based system can capture the nonlinear relations embedded in the molecular MRI Bloch-McConnell model, enabling a rapid and accurate generation of biologically realistic synthetic data. The applicability of this simulated data for in-silico, in-vitro, and in-vivo imaging applications is then demonstrated for chemical exchange saturation transfer (CEST) and semisolid macromolecule magnetization transfer (MT) analysis and quantification. The proposed approach yielded 78%-99% acceleration in data synthesis time while retaining excellent agreement with the ground truth (Pearson's r$>$0.99, p$<$0.0001, normalized root mean square error $<$3%).
Cooperative Thresholded Lasso for Sparse Linear Bandit
May 30, 2023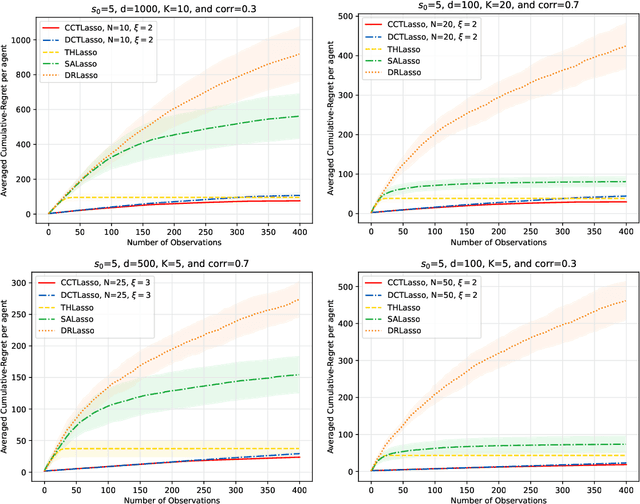
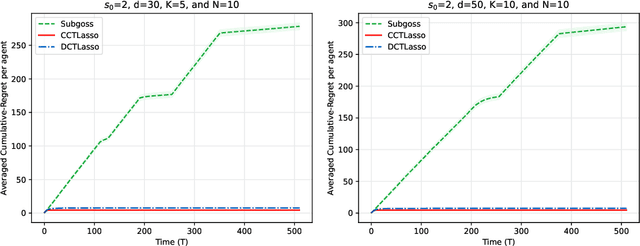
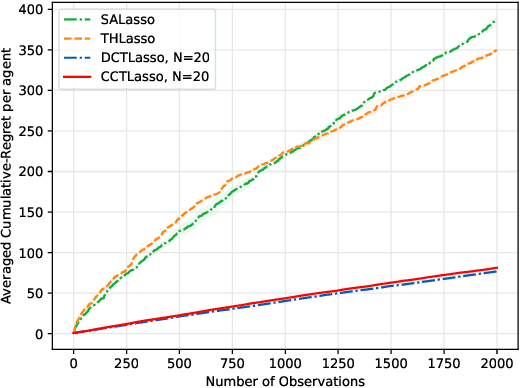
We present a novel approach to address the multi-agent sparse contextual linear bandit problem, in which the feature vectors have a high dimension $d$ whereas the reward function depends on only a limited set of features - precisely $s_0 \ll d$. Furthermore, the learning follows under information-sharing constraints. The proposed method employs Lasso regression for dimension reduction, allowing each agent to independently estimate an approximate set of main dimensions and share that information with others depending on the network's structure. The information is then aggregated through a specific process and shared with all agents. Each agent then resolves the problem with ridge regression focusing solely on the extracted dimensions. We represent algorithms for both a star-shaped network and a peer-to-peer network. The approaches effectively reduce communication costs while ensuring minimal cumulative regret per agent. Theoretically, we show that our proposed methods have a regret bound of order $\mathcal{O}(s_0 \log d + s_0 \sqrt{T})$ with high probability, where $T$ is the time horizon. To our best knowledge, it is the first algorithm that tackles row-wise distributed data in sparse linear bandits, achieving comparable performance compared to the state-of-the-art single and multi-agent methods. Besides, it is widely applicable to high-dimensional multi-agent problems where efficient feature extraction is critical for minimizing regret. To validate the effectiveness of our approach, we present experimental results on both synthetic and real-world datasets.
Edge-MoE: Memory-Efficient Multi-Task Vision Transformer Architecture with Task-level Sparsity via Mixture-of-Experts
May 30, 2023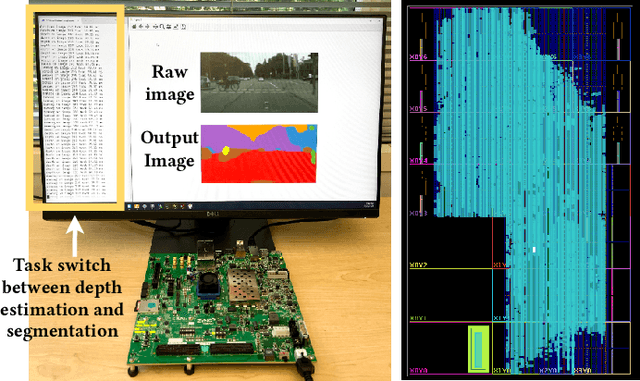


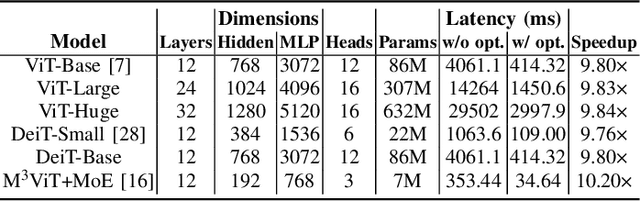
Computer vision researchers are embracing two promising paradigms: Vision Transformers (ViTs) and Multi-task Learning (MTL), which both show great performance but are computation-intensive, given the quadratic complexity of self-attention in ViT and the need to activate an entire large MTL model for one task. M$^3$ViT is the latest multi-task ViT model that introduces mixture-of-experts (MoE), where only a small portion of subnetworks ("experts") are sparsely and dynamically activated based on the current task. M$^3$ViT achieves better accuracy and over 80% computation reduction but leaves challenges for efficient deployment on FPGA. Our work, dubbed Edge-MoE, solves the challenges to introduce the first end-to-end FPGA accelerator for multi-task ViT with a collection of architectural innovations, including (1) a novel reordering mechanism for self-attention, which requires only constant bandwidth regardless of the target parallelism; (2) a fast single-pass softmax approximation; (3) an accurate and low-cost GELU approximation; (4) a unified and flexible computing unit that is shared by almost all computational layers to maximally reduce resource usage; and (5) uniquely for M$^3$ViT, a novel patch reordering method to eliminate memory access overhead. Edge-MoE achieves 2.24x and 4.90x better energy efficiency comparing with GPU and CPU, respectively. A real-time video demonstration is available online, along with our code written using High-Level Synthesis, which will be open-sourced.
DENTEX: An Abnormal Tooth Detection with Dental Enumeration and Diagnosis Benchmark for Panoramic X-rays
May 30, 2023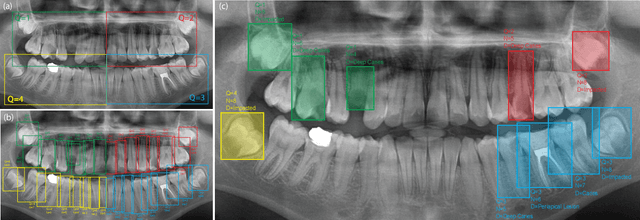
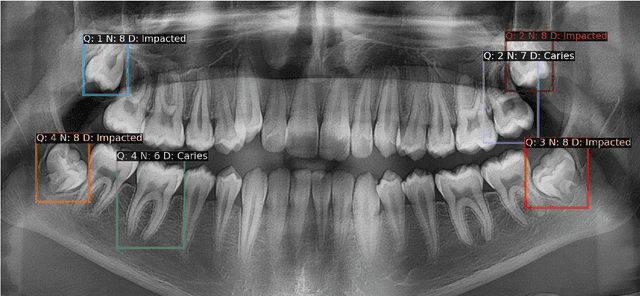
Panoramic X-rays are frequently used in dentistry for treatment planning, but their interpretation can be both time-consuming and prone to error. Artificial intelligence (AI) has the potential to aid in the analysis of these X-rays, thereby improving the accuracy of dental diagnoses and treatment plans. Nevertheless, designing automated algorithms for this purpose poses significant challenges, mainly due to the scarcity of annotated data and variations in anatomical structure. To address these issues, the Dental Enumeration and Diagnosis on Panoramic X-rays Challenge (DENTEX) has been organized in association with the International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI) in 2023. This challenge aims to promote the development of algorithms for multi-label detection of abnormal teeth, using three types of hierarchically annotated data: partially annotated quadrant data, partially annotated quadrant-enumeration data, and fully annotated quadrant-enumeration-diagnosis data, inclusive of four different diagnoses. In this paper, we present the results of evaluating participant algorithms on the fully annotated data, additionally investigating performance variation for quadrant, enumeration, and diagnosis labels in the detection of abnormal teeth. The provision of this annotated dataset, alongside the results of this challenge, may lay the groundwork for the creation of AI-powered tools that can offer more precise and efficient diagnosis and treatment planning in the field of dentistry. The evaluation code and datasets can be accessed at https://github.com/ibrahimethemhamamci/DENTEX
Multiverse at the Edge: Interacting Real World and Digital Twins for Wireless Beamforming
May 10, 2023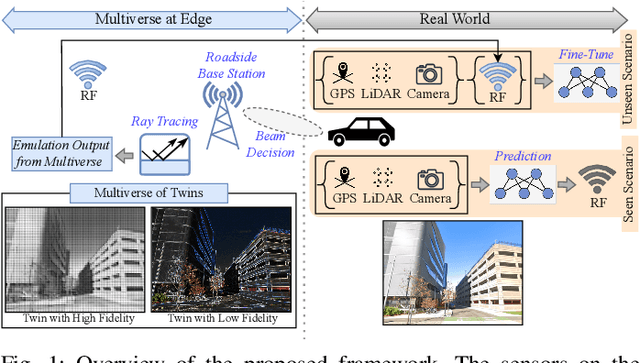
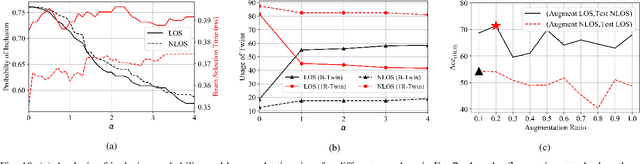
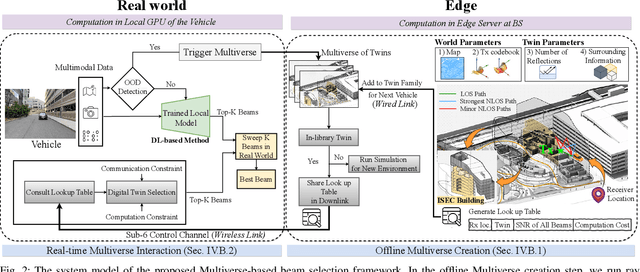
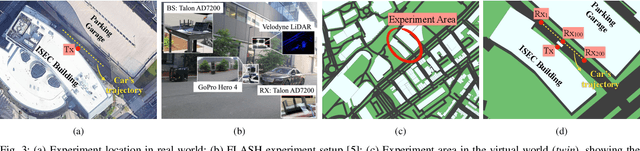
Creating a digital world that closely mimics the real world with its many complex interactions and outcomes is possible today through advanced emulation software and ubiquitous computing power. Such a software-based emulation of an entity that exists in the real world is called a 'digital twin'. In this paper, we consider a twin of a wireless millimeter-wave band radio that is mounted on a vehicle and show how it speeds up directional beam selection in mobile environments. To achieve this, we go beyond instantiating a single twin and propose the 'Multiverse' paradigm, with several possible digital twins attempting to capture the real world at different levels of fidelity. Towards this goal, this paper describes (i) a decision strategy at the vehicle that determines which twin must be used given the computational and latency limitations, and (ii) a self-learning scheme that uses the Multiverse-guided beam outcomes to enhance DL-based decision-making in the real world over time. Our work is distinguished from prior works as follows: First, we use a publicly available RF dataset collected from an autonomous car for creating different twins. Second, we present a framework with continuous interaction between the real world and Multiverse of twins at the edge, as opposed to a one-time emulation that is completed prior to actual deployment. Results reveal that Multiverse offers up to 79.43% and 85.22% top-10 beam selection accuracy for LOS and NLOS scenarios, respectively. Moreover, we observe 52.72-85.07% improvement in beam selection time compared to 802.11ad standard.
RET-LLM: Towards a General Read-Write Memory for Large Language Models
May 23, 2023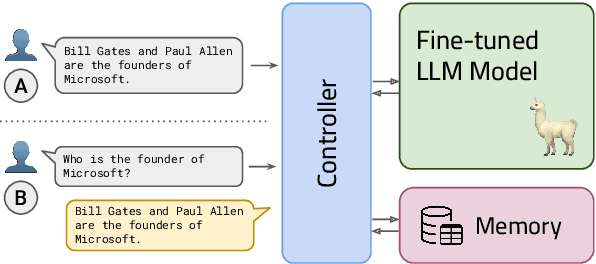

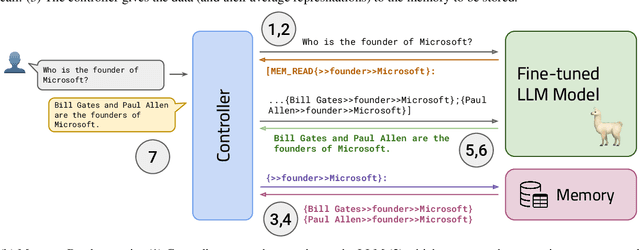

Large language models (LLMs) have significantly advanced the field of natural language processing (NLP) through their extensive parameters and comprehensive data utilization. However, existing LLMs lack a dedicated memory unit, limiting their ability to explicitly store and retrieve knowledge for various tasks. In this paper, we propose RET-LLM a novel framework that equips LLMs with a general write-read memory unit, allowing them to extract, store, and recall knowledge from the text as needed for task performance. Inspired by Davidsonian semantics theory, we extract and save knowledge in the form of triplets. The memory unit is designed to be scalable, aggregatable, updatable, and interpretable. Through qualitative evaluations, we demonstrate the superiority of our proposed framework over baseline approaches in question answering tasks. Moreover, our framework exhibits robust performance in handling temporal-based question answering tasks, showcasing its ability to effectively manage time-dependent information.
Reparo: Loss-Resilient Generative Codec for Video Conferencing
May 23, 2023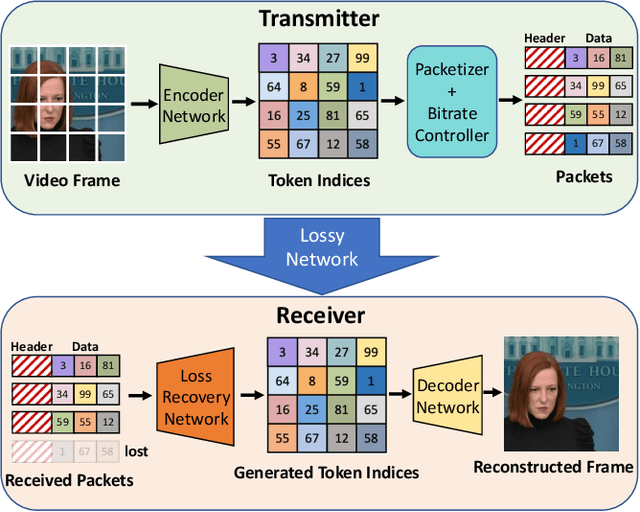

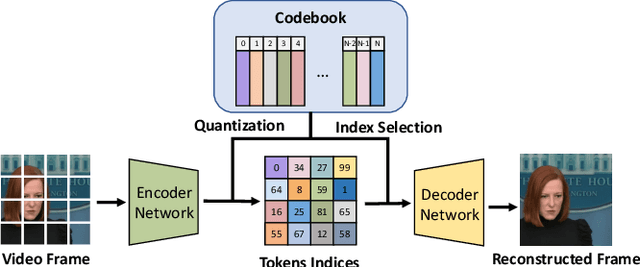
Loss of packets in video conferencing often results in poor quality and video freezing. Attempting to retransmit the lost packets is usually not practical due to the requirement for real-time playback. Using Forward Error Correction (FEC) to recover the lost packets is challenging since it is difficult to determine the appropriate level of redundancy. In this paper, we propose a framework called Reparo for creating loss-resilient video conferencing using generative deep learning models. Our approach involves generating missing information when a frame or part of a frame is lost. This generation is conditioned on the data received so far, and the model's knowledge of how people look, dress, and interact in the visual world. Our experiments on publicly available video conferencing datasets show that Reparo outperforms state-of-the-art FEC-based video conferencing in terms of both video quality (measured by PSNR) and video freezes.
Implementation of Lenia as a Reaction-Diffusion System
May 23, 2023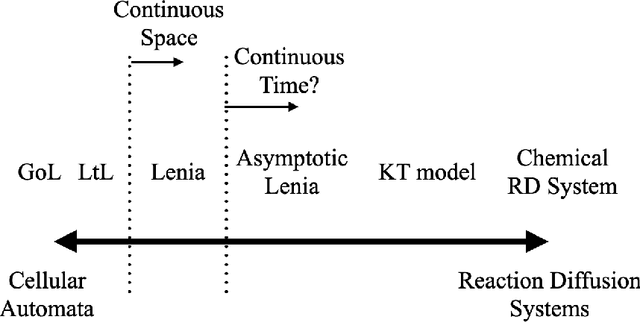
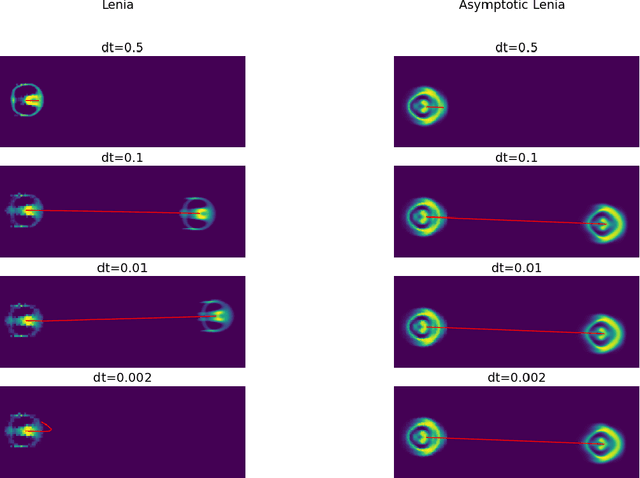
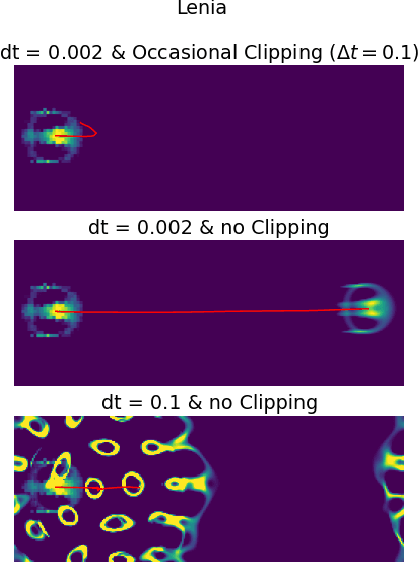
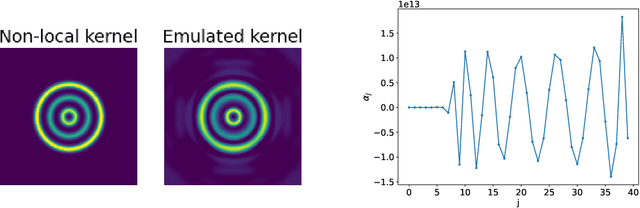
The relationship between reaction-diffusion (RD) systems, characterized by continuous spatiotemporal states, and cellular automata (CA), marked by discrete spatiotemporal states, remains poorly understood. This paper delves into this relationship through an examination of a recently developed CA known as Lenia. We demonstrate that asymptotic Lenia, a variant of Lenia, can be comprehensively described by differential equations, and, unlike the original Lenia, it is independent of time-step ticks. Further, we establish that this formulation is mathematically equivalent to a generalization of the kernel-based Turing model (KT model). Stemming from these insights, we establish that asymptotic Lenia can be replicated by an RD system composed solely of diffusion and spatially local reaction terms, resulting in the simulated asymptotic Lenia based on an RD system, or "RD Lenia". However, our RD Lenia cannot be construed as a chemical system since the reaction term fails to satisfy mass-action kinetics.
Error Detection for Text-to-SQL Semantic Parsing
May 23, 2023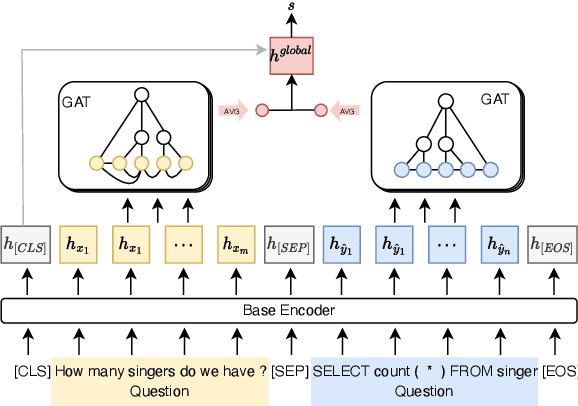

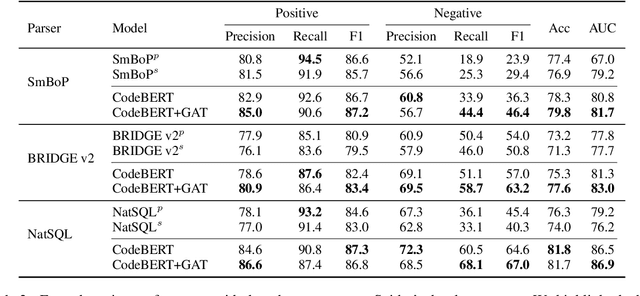
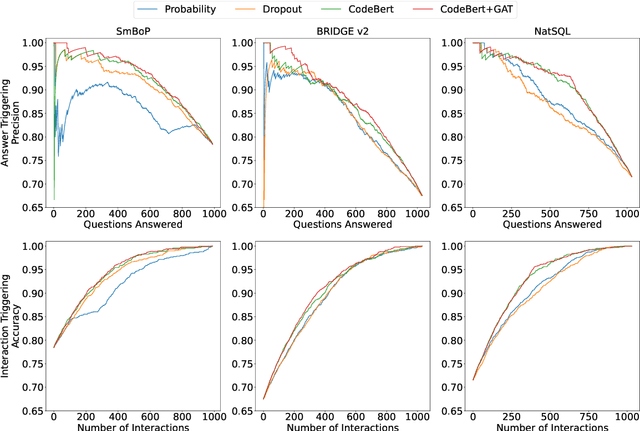
Despite remarkable progress in text-to-SQL semantic parsing in recent years, the performance of existing parsers is still far from perfect. At the same time, modern deep learning based text-to-SQL parsers are often over-confident and thus casting doubt on their trustworthiness when deployed for real use. To that end, we propose to build a parser-independent error detection model for text-to-SQL semantic parsing. The proposed model is based on pre-trained language model of code and is enhanced with structural features learned by graph neural networks. We train our model on realistic parsing errors collected from a cross-domain setting. Experiments with three strong text-to-SQL parsers featuring different decoding mechanisms show that our approach outperforms parser-dependent uncertainty metrics and could effectively improve the performance and usability of text-to-SQL semantic parsers regardless of their architectures.