 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Development of Automated Neural Network Prediction for Echocardiographic Left ventricular Ejection Fraction
Mar 18, 2024
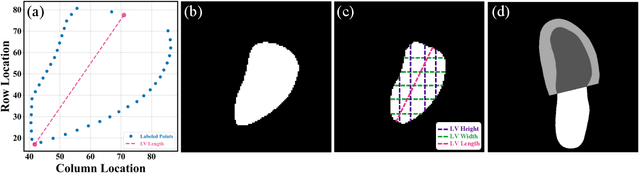

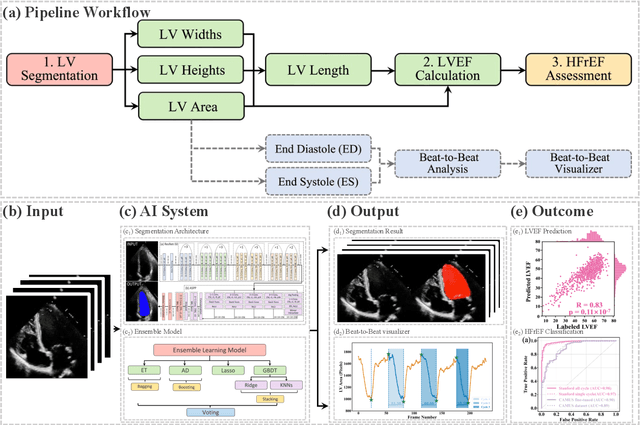
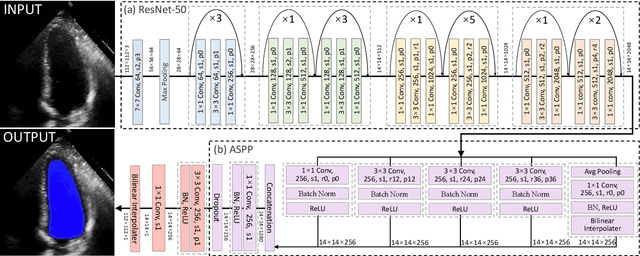
The echocardiographic measurement of left ventricular ejection fraction (LVEF) is fundamental to the diagnosis and classification of patients with heart failure (HF). In order to quantify LVEF automatically and accurately, this paper proposes a new pipeline method based on deep neural networks and ensemble learning. Within the pipeline, an Atrous Convolutional Neural Network (ACNN) was first trained to segment the left ventricle (LV), before employing the area-length formulation based on the ellipsoid single-plane model to calculate LVEF values. This formulation required inputs of LV area, derived from segmentation using an improved Jeffrey's method, as well as LV length, derived from a novel ensemble learning model. To further improve the pipeline's accuracy, an automated peak detection algorithm was used to identify end-diastolic and end-systolic frames, avoiding issues with human error. Subsequently, single-beat LVEF values were averaged across all cardiac cycles to obtain the final LVEF. This method was developed and internally validated in an open-source dataset containing 10,030 echocardiograms. The Pearson's correlation coefficient was 0.83 for LVEF prediction compared to expert human analysis (p<0.001), with a subsequent area under the receiver operator curve (AUROC) of 0.98 (95% confidence interval 0.97 to 0.99) for categorisation of HF with reduced ejection (HFrEF; LVEF<40%). In an external dataset with 200 echocardiograms, this method achieved an AUC of 0.90 (95% confidence interval 0.88 to 0.91) for HFrEF assessment. This study demonstrates that an automated neural network-based calculation of LVEF is comparable to expert clinicians performing time-consuming, frame-by-frame manual evaluation of cardiac systolic function.
Multi-Sample Long Range Path Planning under Sensing Uncertainty for Off-Road Autonomous Driving
Mar 17, 2024
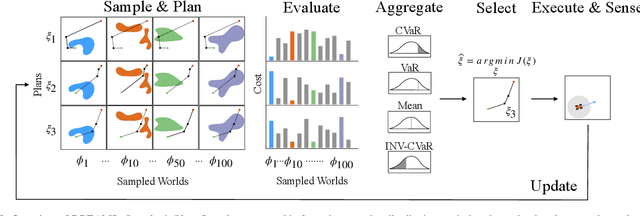

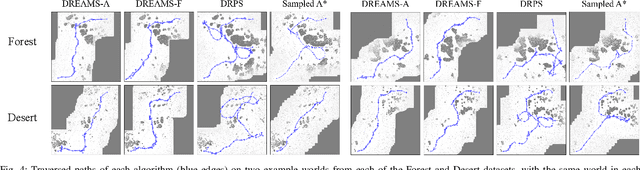
We focus on the problem of long-range dynamic replanning for off-road autonomous vehicles, where a robot plans paths through a previously unobserved environment while continuously receiving noisy local observations. An effective approach for planning under sensing uncertainty is determinization, where one converts a stochastic world into a deterministic one and plans under this simplification. This makes the planning problem tractable, but the cost of following the planned path in the real world may be different than in the determinized world. This causes collisions if the determinized world optimistically ignores obstacles, or causes unnecessarily long routes if the determinized world pessimistically imagines more obstacles. We aim to be robust to uncertainty over potential worlds while still achieving the efficiency benefits of determinization. We evaluate algorithms for dynamic replanning on a large real-world dataset of challenging long-range planning problems from the DARPA RACER program. Our method, Dynamic Replanning via Evaluating and Aggregating Multiple Samples (DREAMS), outperforms other determinization-based approaches in terms of combined traversal time and collision cost. https://sites.google.com/cs.washington.edu/dreams/
SMORE: Similarity-based Hyperdimensional Domain Adaptation for Multi-Sensor Time Series Classification
Feb 27, 2024Many real-world applications of the Internet of Things (IoT) employ machine learning (ML) algorithms to analyze time series information collected by interconnected sensors. However, distribution shift, a fundamental challenge in data-driven ML, arises when a model is deployed on a data distribution different from the training data and can substantially degrade model performance. Additionally, increasingly sophisticated deep neural networks (DNNs) are required to capture intricate spatial and temporal dependencies in multi-sensor time series data, often exceeding the capabilities of today's edge devices. In this paper, we propose SMORE, a novel resource-efficient domain adaptation (DA) algorithm for multi-sensor time series classification, leveraging the efficient and parallel operations of hyperdimensional computing. SMORE dynamically customizes test-time models with explicit consideration of the domain context of each sample to mitigate the negative impacts of domain shifts. Our evaluation on a variety of multi-sensor time series classification tasks shows that SMORE achieves on average 1.98% higher accuracy than state-of-the-art (SOTA) DNN-based DA algorithms with 18.81x faster training and 4.63x faster inference.
Cafe-Mpc: A Cascaded-Fidelity Model Predictive Control Framework with Tuning-Free Whole-Body Control
Mar 14, 2024

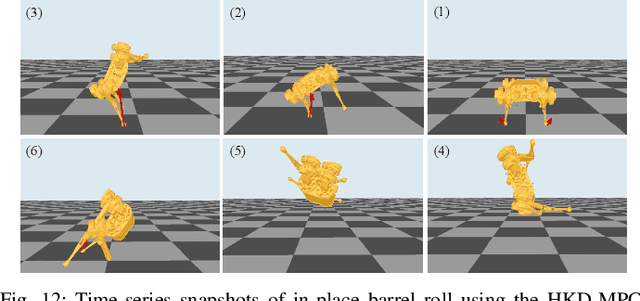
This work introduces an optimization-based locomotion control framework for on-the-fly synthesis of complex dynamic maneuvers. At the core of the proposed framework is a cascaded-fidelity model predictive controller (Cafe-Mpc). Cafe-Mpc strategically relaxes the planning problem along the prediction horizon (i.e., with descending model fidelity, increasingly coarse time steps, and relaxed constraints) for computational and performance gains. This problem is numerically solved with an efficient customized multiple-shooting iLQR (MS-iLQR) solver that is tailored for hybrid systems. The action-value function from Cafe-Mpc is then used as the basis for a new value-function-based whole-body control (VWBC) technique that avoids additional tuning for the WBC. In this respect, the proposed framework unifies whole-body MPC and more conventional whole-body quadratic programming (QP), which have been treated as separate components in previous works. We study the effects of the cascaded relaxations in Cafe-Mpc on the tracking performance and required computation time. We also show that the Cafe-Mpc, if configured appropriately, advances the performance of whole-body MPC without necessarily increasing computational cost. Further, we show the superior performance of the proposed VWBC over the Riccati feedback controller in terms of constraint handling. The proposed framework enables accomplishing for the first time gymnastic-style running barrel rolls on the MIT Mini Cheetah. Video: https://youtu.be/YiNqrgj9mb8.
TTA-Nav: Test-time Adaptive Reconstruction for Point-Goal Navigation under Visual Corruptions
Mar 04, 2024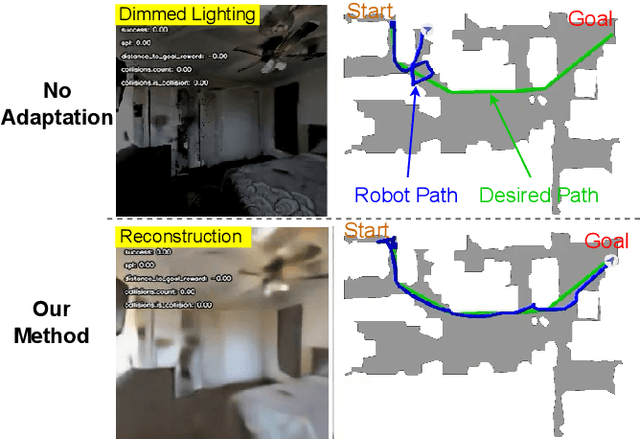
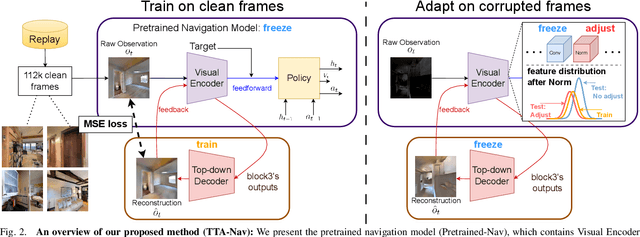


Robot navigation under visual corruption presents a formidable challenge. To address this, we propose a Test-time Adaptation (TTA) method, named as TTA-Nav, for point-goal navigation under visual corruptions. Our "plug-and-play" method incorporates a top-down decoder to a pre-trained navigation model. Firstly, the pre-trained navigation model gets a corrupted image and extracts features. Secondly, the top-down decoder produces the reconstruction given the high-level features extracted by the pre-trained model. Then, it feeds the reconstruction of a corrupted image back to the pre-trained model. Finally, the pre-trained model does forward pass again to output action. Despite being trained solely on clean images, the top-down decoder can reconstruct cleaner images from corrupted ones without the need for gradient-based adaptation. The pre-trained navigation model with our top-down decoder significantly enhances navigation performance across almost all visual corruptions in our benchmarks. Our method improves the success rate of point-goal navigation from the state-of-the-art result of 46% to 94% on the most severe corruption. This suggests its potential for broader application in robotic visual navigation.
Evaluating Named Entity Recognition: Comparative Analysis of Mono- and Multilingual Transformer Models on Brazilian Corporate Earnings Call Transcriptions
Mar 18, 2024
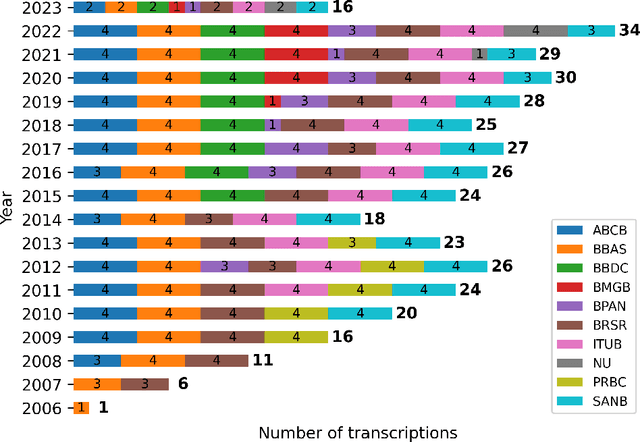

Named Entity Recognition (NER) is a Natural Language Processing technique for extracting information from textual documents. However, much of the existing research on NER has been centered around English-language documents, leaving a gap in the availability of datasets tailored to the financial domain in Portuguese. This study addresses the need for NER within the financial domain, focusing on Portuguese-language texts extracted from earnings call transcriptions of Brazilian banks. By curating a comprehensive dataset comprising 384 transcriptions and leveraging weak supervision techniques for annotation, we evaluate the performance of monolingual models trained on Portuguese (BERTimbau and PTT5) and multilingual models (mBERT and mT5). Notably, we introduce a novel approach that reframes the token classification task as a text generation problem, enabling fine-tuning and evaluation of T5 models. Following the fine-tuning of the models, we conduct an evaluation on the test dataset, employing performance and error metrics. Our findings reveal that BERT-based models consistently outperform T5-based models. Furthermore, while the multilingual models exhibit comparable macro F1-scores, BERTimbau demonstrates superior performance over PTT5. A manual analysis of sentences generated by PTT5 and mT5 unveils a degree of similarity ranging from 0.89 to 1.0, between the original and generated sentences. However, critical errors emerge as both models exhibit discrepancies, such as alterations to monetary and percentage values, underscoring the importance of accuracy and consistency in the financial domain. Despite these challenges, PTT5 and mT5 achieve impressive macro F1-scores of 98.52% and 98.85%, respectively, with our proposed approach. Furthermore, our study sheds light on notable disparities in memory and time consumption for inference across the models.
TnT-LLM: Text Mining at Scale with Large Language Models
Mar 18, 2024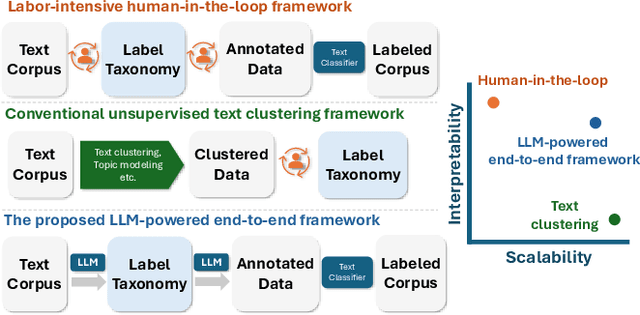
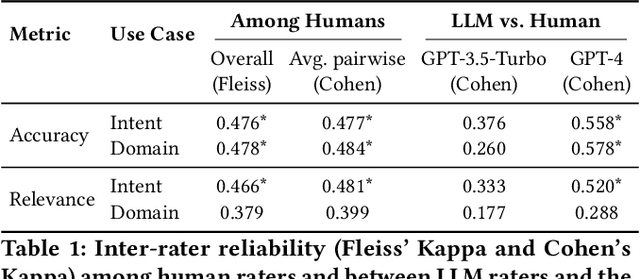
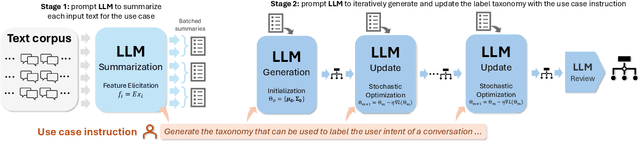
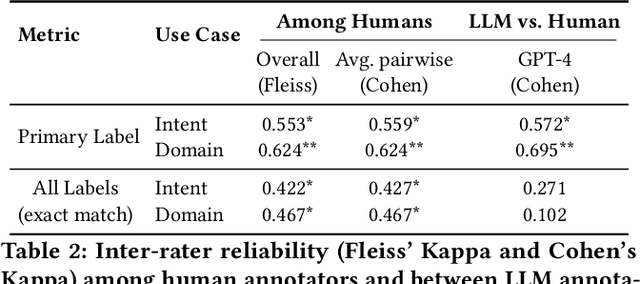
Transforming unstructured text into structured and meaningful forms, organized by useful category labels, is a fundamental step in text mining for downstream analysis and application. However, most existing methods for producing label taxonomies and building text-based label classifiers still rely heavily on domain expertise and manual curation, making the process expensive and time-consuming. This is particularly challenging when the label space is under-specified and large-scale data annotations are unavailable. In this paper, we address these challenges with Large Language Models (LLMs), whose prompt-based interface facilitates the induction and use of large-scale pseudo labels. We propose TnT-LLM, a two-phase framework that employs LLMs to automate the process of end-to-end label generation and assignment with minimal human effort for any given use-case. In the first phase, we introduce a zero-shot, multi-stage reasoning approach which enables LLMs to produce and refine a label taxonomy iteratively. In the second phase, LLMs are used as data labelers that yield training samples so that lightweight supervised classifiers can be reliably built, deployed, and served at scale. We apply TnT-LLM to the analysis of user intent and conversational domain for Bing Copilot (formerly Bing Chat), an open-domain chat-based search engine. Extensive experiments using both human and automatic evaluation metrics demonstrate that TnT-LLM generates more accurate and relevant label taxonomies when compared against state-of-the-art baselines, and achieves a favorable balance between accuracy and efficiency for classification at scale. We also share our practical experiences and insights on the challenges and opportunities of using LLMs for large-scale text mining in real-world applications.
Histo-Genomic Knowledge Distillation For Cancer Prognosis From Histopathology Whole Slide Images
Mar 18, 2024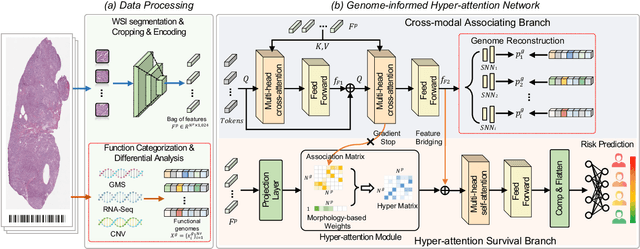
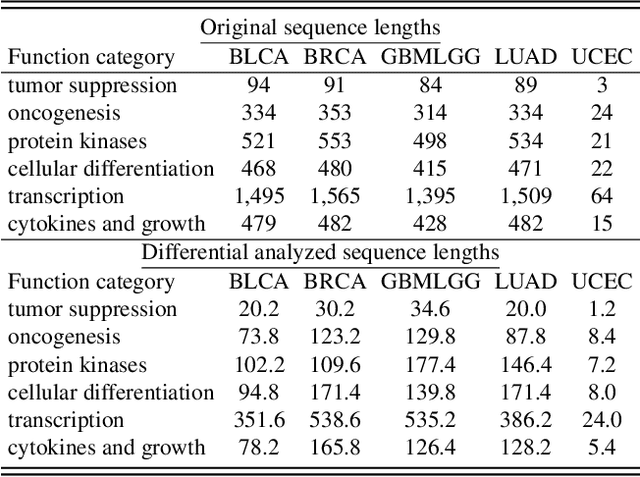
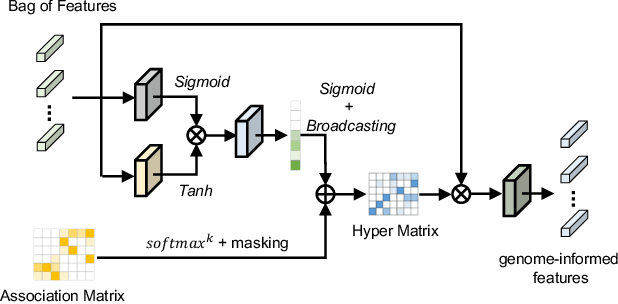
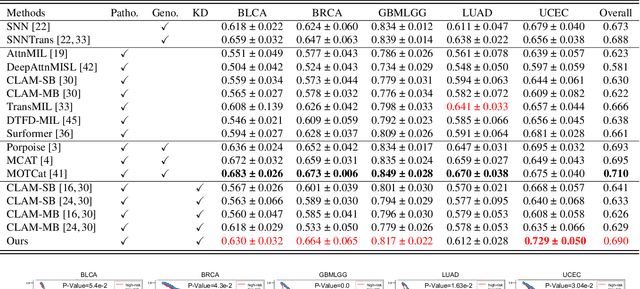
Histo-genomic multi-modal methods have recently emerged as a powerful paradigm, demonstrating significant potential for improving cancer prognosis. However, genome sequencing, unlike histopathology imaging, is still not widely accessible in underdeveloped regions, limiting the application of these multi-modal approaches in clinical settings. To address this, we propose a novel Genome-informed Hyper-Attention Network, termed G-HANet, which is capable of effectively distilling the histo-genomic knowledge during training to elevate uni-modal whole slide image (WSI)-based inference for the first time. Compared with traditional knowledge distillation methods (i.e., teacher-student architecture) in other tasks, our end-to-end model is superior in terms of training efficiency and learning cross-modal interactions. Specifically, the network comprises the cross-modal associating branch (CAB) and hyper-attention survival branch (HSB). Through the genomic data reconstruction from WSIs, CAB effectively distills the associations between functional genotypes and morphological phenotypes and offers insights into the gene expression profiles in the feature space. Subsequently, HSB leverages the distilled histo-genomic associations as well as the generated morphology-based weights to achieve the hyper-attention modeling of the patients from both histopathology and genomic perspectives to improve cancer prognosis. Extensive experiments are conducted on five TCGA benchmarking datasets and the results demonstrate that G-HANet significantly outperforms the state-of-the-art WSI-based methods and achieves competitive performance with genome-based and multi-modal methods. G-HANet is expected to be explored as a useful tool by the research community to address the current bottleneck of insufficient histo-genomic data pairing in the context of cancer prognosis and precision oncology.
SceneSense: Diffusion Models for 3D Occupancy Synthesis from Partial Observation
Mar 18, 2024
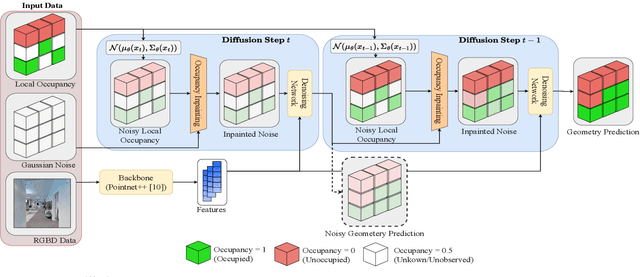
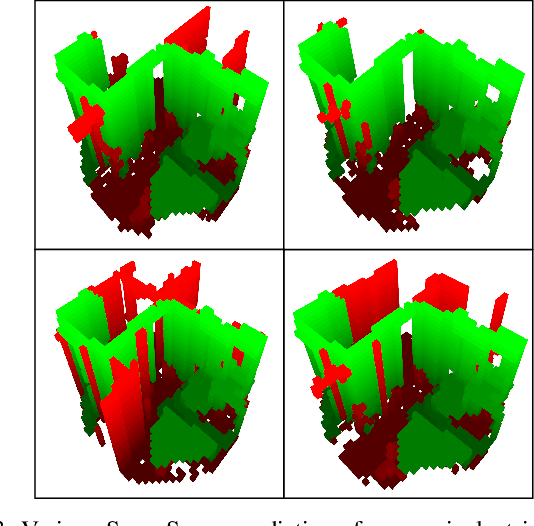

When exploring new areas, robotic systems generally exclusively plan and execute controls over geometry that has been directly measured. When entering space that was previously obstructed from view such as turning corners in hallways or entering new rooms, robots often pause to plan over the newly observed space. To address this we present SceneScene, a real-time 3D diffusion model for synthesizing 3D occupancy information from partial observations that effectively predicts these occluded or out of view geometries for use in future planning and control frameworks. SceneSense uses a running occupancy map and a single RGB-D camera to generate predicted geometry around the platform at runtime, even when the geometry is occluded or out of view. Our architecture ensures that SceneSense never overwrites observed free or occupied space. By preserving the integrity of the observed map, SceneSense mitigates the risk of corrupting the observed space with generative predictions. While SceneSense is shown to operate well using a single RGB-D camera, the framework is flexible enough to extend to additional modalities. SceneSense operates as part of any system that generates a running occupancy map `out of the box', removing conditioning from the framework. Alternatively, for maximum performance in new modalities, the perception backbone can be replaced and the model retrained for inference in new applications. Unlike existing models that necessitate multiple views and offline scene synthesis, or are focused on filling gaps in observed data, our findings demonstrate that SceneSense is an effective approach to estimating unobserved local occupancy information at runtime. Local occupancy predictions from SceneSense are shown to better represent the ground truth occupancy distribution during the test exploration trajectories than the running occupancy map.
DiPaCo: Distributed Path Composition
Mar 15, 2024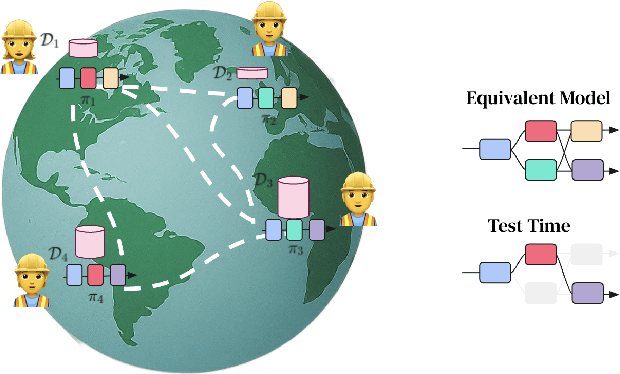
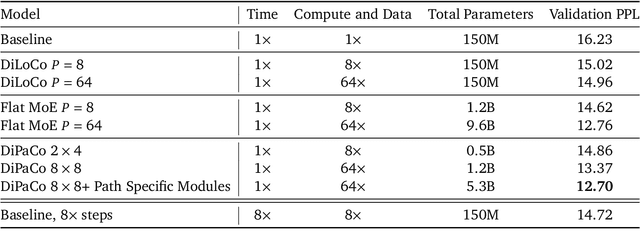


Progress in machine learning (ML) has been fueled by scaling neural network models. This scaling has been enabled by ever more heroic feats of engineering, necessary for accommodating ML approaches that require high bandwidth communication between devices working in parallel. In this work, we propose a co-designed modular architecture and training approach for ML models, dubbed DIstributed PAth COmposition (DiPaCo). During training, DiPaCo distributes computation by paths through a set of shared modules. Together with a Local-SGD inspired optimization (DiLoCo) that keeps modules in sync with drastically reduced communication, Our approach facilitates training across poorly connected and heterogeneous workers, with a design that ensures robustness to worker failures and preemptions. At inference time, only a single path needs to be executed for each input, without the need for any model compression. We consider this approach as a first prototype towards a new paradigm of large-scale learning, one that is less synchronous and more modular. Our experiments on the widely used C4 benchmark show that, for the same amount of training steps but less wall-clock time, DiPaCo exceeds the performance of a 1 billion-parameter dense transformer language model by choosing one of 256 possible paths, each with a size of 150 million parameters.