 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
PLCMOS -- a data-driven non-intrusive metric for the evaluation of packet loss concealment algorithms
May 24, 2023
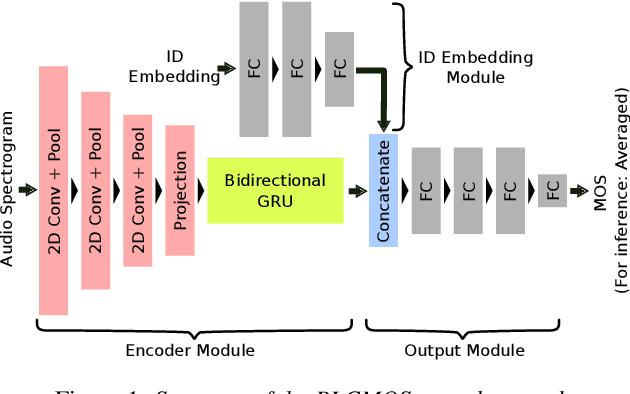
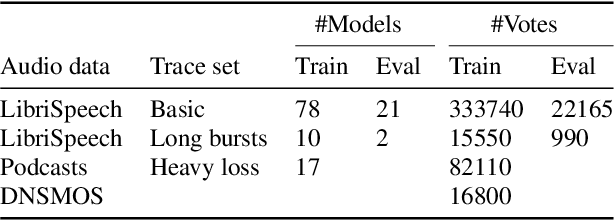
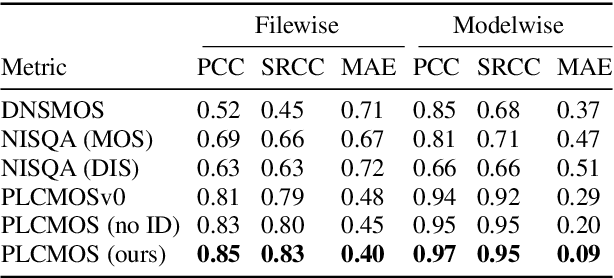
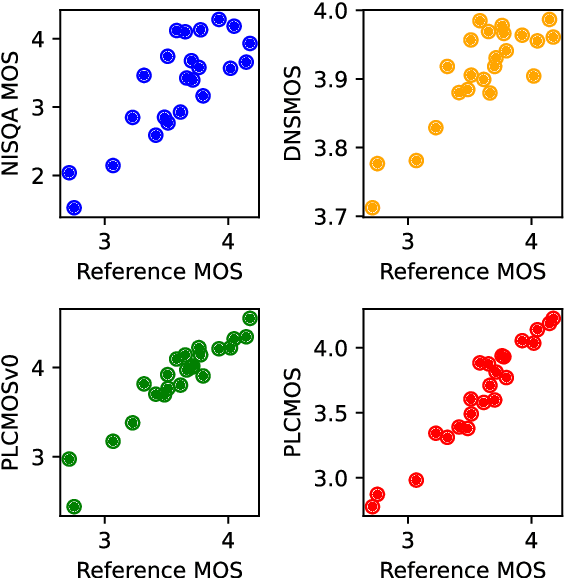
Speech quality assessment is a problem for every researcher working on models that produce or process speech. Human subjective ratings, the gold standard in speech quality assessment, are expensive and time-consuming to acquire in a quantity that is sufficient to get reliable data, while automated objective metrics show a low correlation with gold standard ratings. This paper presents PLCMOS, a non-intrusive data-driven tool for generating a robust, accurate estimate of the mean opinion score a human rater would assign an audio file that has been processed by being transmitted over a degraded packet-switched network with missing packets being healed by a packet loss concealment algorithm. Our new model shows a model-wise Pearson's correlation of ~0.97 and rank correlation of ~0.95 with human ratings, substantially above all other available intrusive and non-intrusive metrics. The model is released as an ONNX model for other researchers to use when building PLC systems.
Active Learning for Natural Language Generation
May 24, 2023
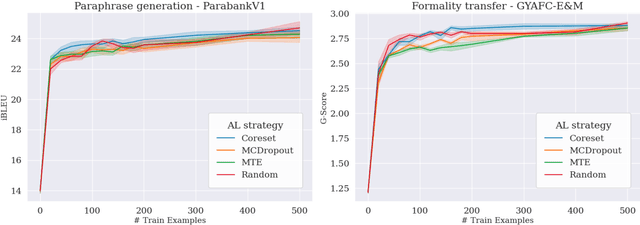
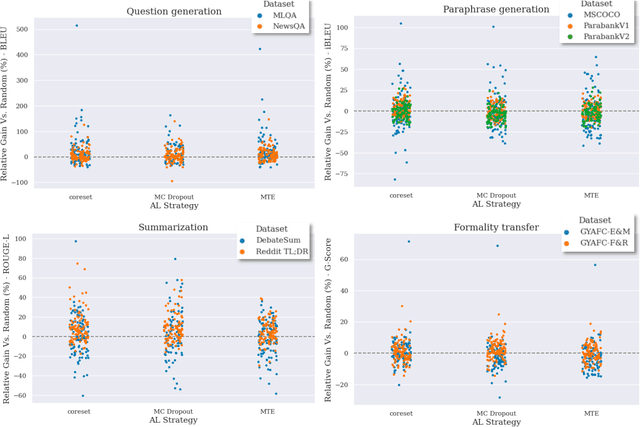

The field of text generation suffers from a severe shortage of labeled data due to the extremely expensive and time consuming process involved in manual annotation. A natural approach for coping with this problem is active learning (AL), a well-known machine learning technique for improving annotation efficiency by selectively choosing the most informative examples to label. However, while AL has been well-researched in the context of text classification, its application to text generation remained largely unexplored. In this paper, we present a first systematic study of active learning for text generation, considering a diverse set of tasks and multiple leading AL strategies. Our results indicate that existing AL strategies, despite their success in classification, are largely ineffective for the text generation scenario, and fail to consistently surpass the baseline of random example selection. We highlight some notable differences between the classification and generation scenarios, and analyze the selection behaviors of existing AL strategies. Our findings motivate exploring novel approaches for applying AL to NLG tasks.
Contrastive Training of Complex-Valued Autoencoders for Object Discovery
May 24, 2023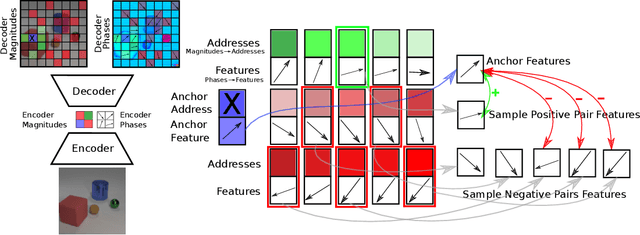
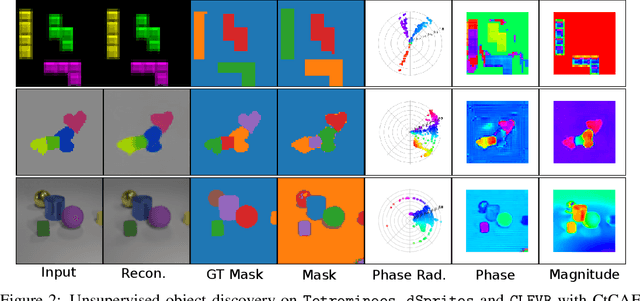
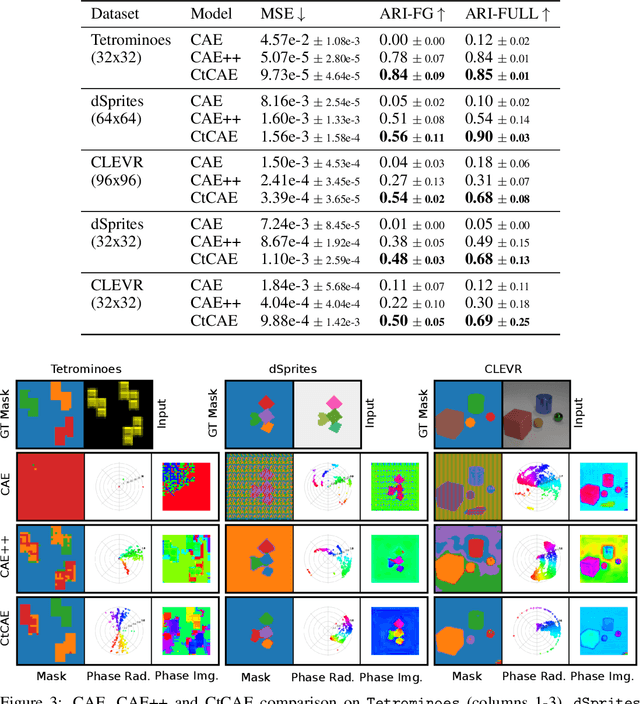
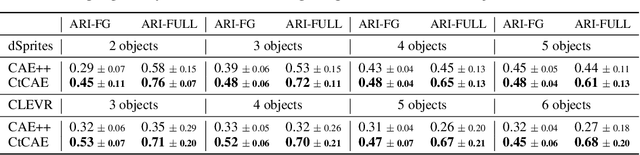
Current state-of-the-art object-centric models use slots and attention-based routing for binding. However, this class of models has several conceptual limitations: the number of slots is hardwired; all slots have equal capacity; training has high computational cost; there are no object-level relational factors within slots. Synchrony-based models in principle can address these limitations by using complex-valued activations which store binding information in their phase components. However, working examples of such synchrony-based models have been developed only very recently, and are still limited to toy grayscale datasets and simultaneous storage of less than three objects in practice. Here we introduce architectural modifications and a novel contrastive learning method that greatly improve the state-of-the-art synchrony-based model. For the first time, we obtain a class of synchrony-based models capable of discovering objects in an unsupervised manner in multi-object color datasets and simultaneously representing more than three objects
A Virtual Reality Tool for Representing, Visualizing and Updating Deep Learning Models
May 24, 2023
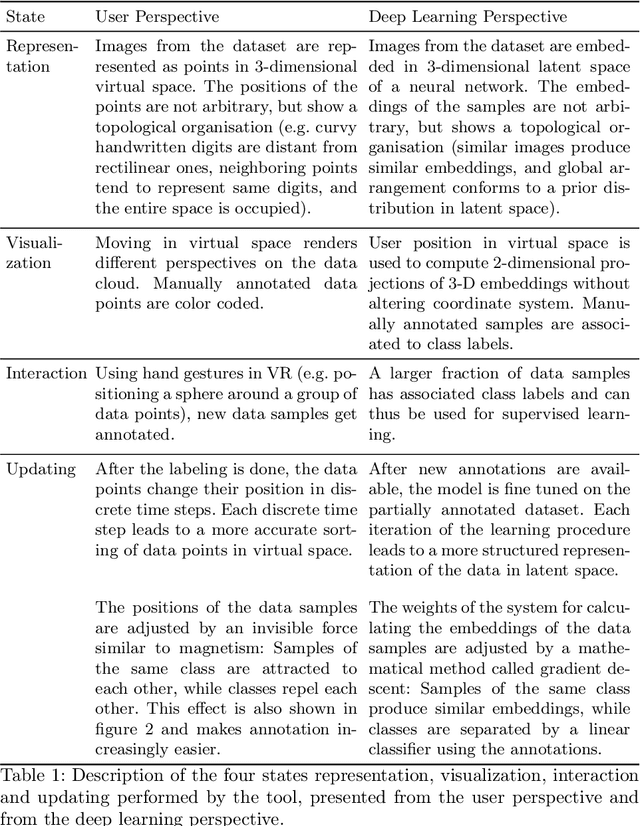
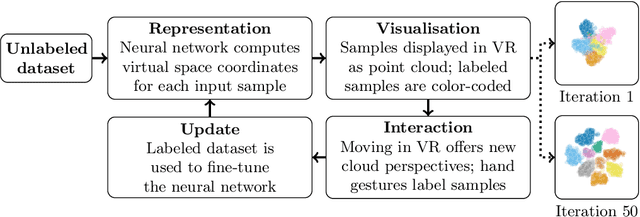
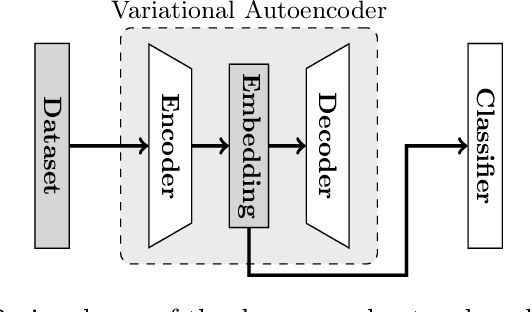
Deep learning is ubiquitous, but its lack of transparency limits its impact on several potential application areas. We demonstrate a virtual reality tool for automating the process of assigning data inputs to different categories. A dataset is represented as a cloud of points in virtual space. The user explores the cloud through movement and uses hand gestures to categorise portions of the cloud. This triggers gradual movements in the cloud: points of the same category are attracted to each other, different groups are pushed apart, while points are globally distributed in a way that utilises the entire space. The space, time, and forces observed in virtual reality can be mapped to well-defined machine learning concepts, namely the latent space, the training epochs and the backpropagation. Our tool illustrates how the inner workings of deep neural networks can be made tangible and transparent. We expect this approach to accelerate the autonomous development of deep learning applications by end users in novel areas.
ASPER: Answer Set Programming Enhanced Neural Network Models for Joint Entity-Relation Extraction
May 24, 2023
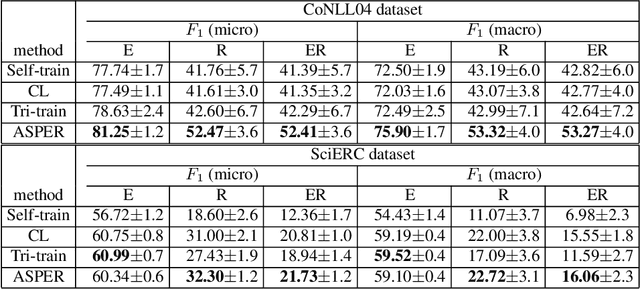
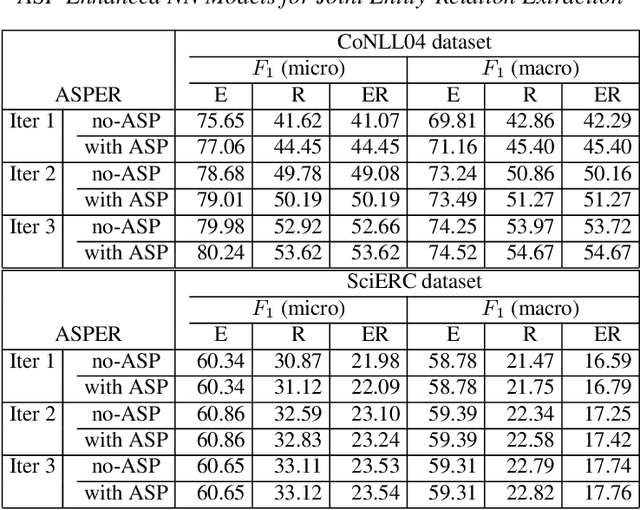
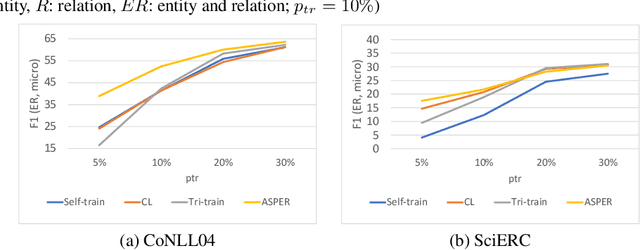
A plethora of approaches have been proposed for joint entity-relation (ER) extraction. Most of these methods largely depend on a large amount of manually annotated training data. However, manual data annotation is time consuming, labor intensive, and error prone. Human beings learn using both data (through induction) and knowledge (through deduction). Answer Set Programming (ASP) has been a widely utilized approach for knowledge representation and reasoning that is elaboration tolerant and adept at reasoning with incomplete information. This paper proposes a new approach, ASP-enhanced Entity-Relation extraction (ASPER), to jointly recognize entities and relations by learning from both data and domain knowledge. In particular, ASPER takes advantage of the factual knowledge (represented as facts in ASP) and derived knowledge (represented as rules in ASP) in the learning process of neural network models. We have conducted experiments on two real datasets and compare our method with three baselines. The results show that our ASPER model consistently outperforms the baselines.
Discounting in Strategy Logic
May 24, 2023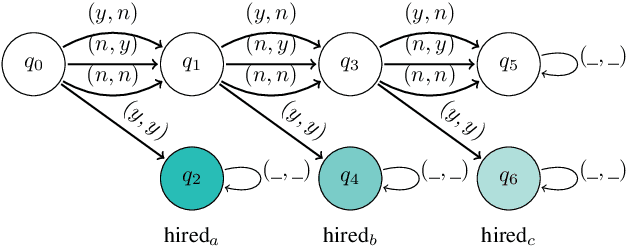
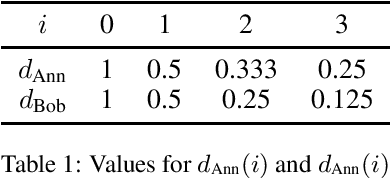
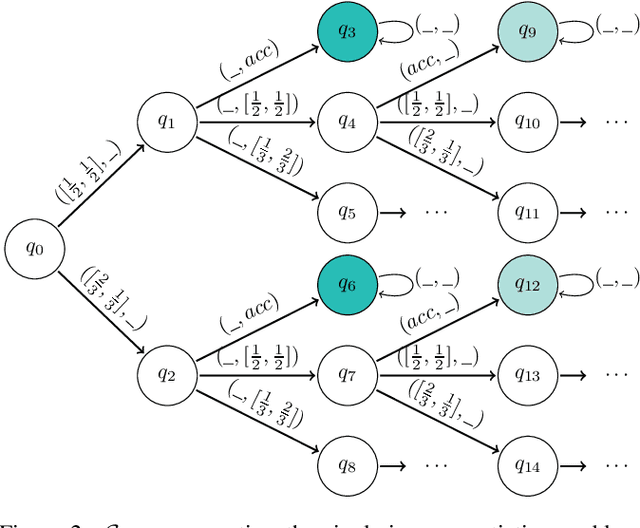
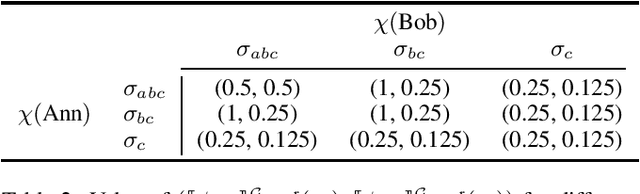
Discounting is an important dimension in multi-agent systems as long as we want to reason about strategies and time. It is a key aspect in economics as it captures the intuition that the far-away future is not as important as the near future. Traditional verification techniques allow to check whether there is a winning strategy for a group of agents but they do not take into account the fact that satisfying a goal sooner is different from satisfying it after a long wait. In this paper, we augment Strategy Logic with future discounting over a set of discounted functions D, denoted SLdisc[D]. We consider "until" operators with discounting functions: the satisfaction value of a specification in SLdisc[D] is a value in [0, 1], where the longer it takes to fulfill requirements, the smaller the satisfaction value is. We motivate our approach with classical examples from Game Theory and study the complexity of model-checking SLdisc[D]-formulas.
Learning the String Partial Order
May 24, 2023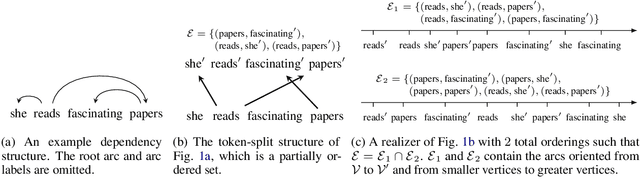
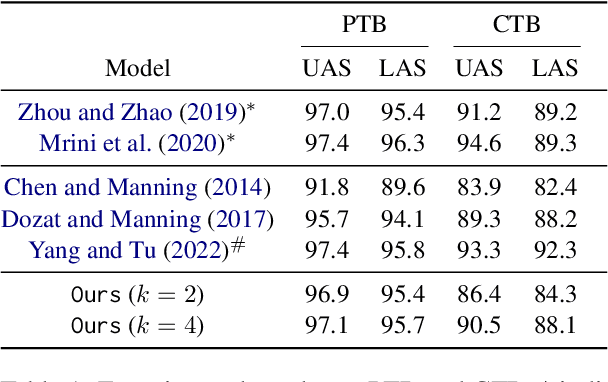
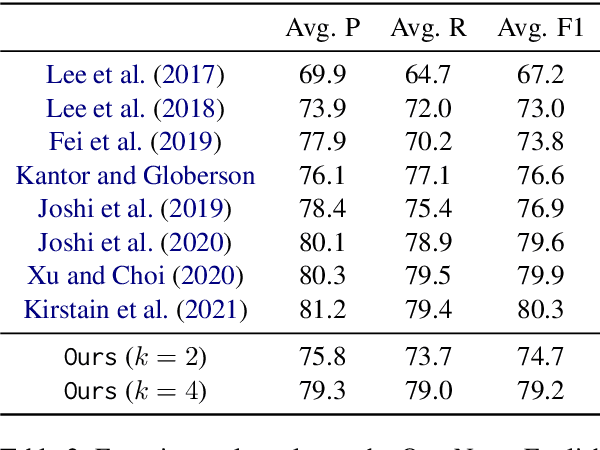
We show that most structured prediction problems can be solved in linear time and space by considering them as partial orderings of the tokens in the input string. Our method computes real numbers for each token in an input string and sorts the tokens accordingly, resulting in as few as 2 total orders of the tokens in the string. Each total order possesses a set of edges oriented from smaller to greater tokens. The intersection of total orders results in a partial order over the set of input tokens, which is then decoded into a directed graph representing the desired structure. Experiments show that our method achieves 95.4 LAS and 96.9 UAS by using an intersection of 2 total orders, 95.7 LAS and 97.1 UAS with 4 on the English Penn Treebank dependency parsing benchmark. Our method is also the first linear-complexity coreference resolution model and achieves 79.2 F1 on the English OntoNotes benchmark, which is comparable with state of the art.
An Emergency Disposal Decision-making Method with Human--Machine Collaboration
May 29, 2023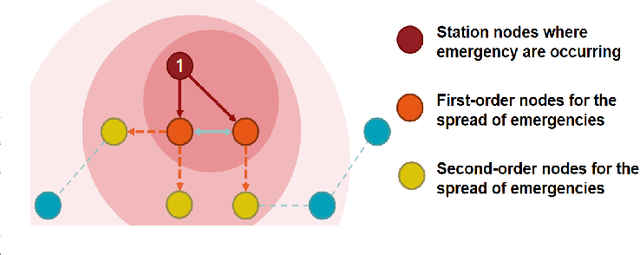
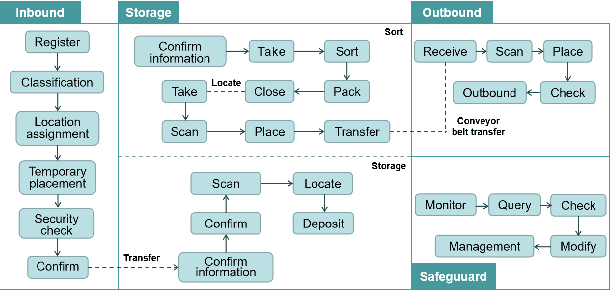
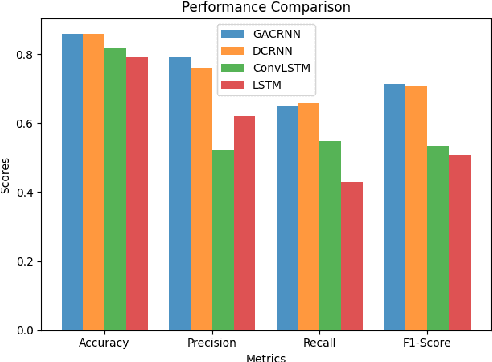
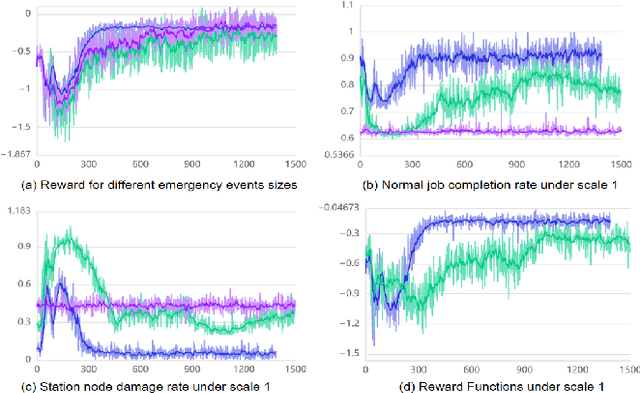
Rapid developments in artificial intelligence technology have led to unmanned systems replacing human beings in many fields requiring high-precision predictions and decisions. In modern operational environments, all job plans are affected by emergency events such as equipment failures and resource shortages, making a quick resolution critical. The use of unmanned systems to assist decision-making can improve resolution efficiency, but their decision-making is not interpretable and may make the wrong decisions. Current unmanned systems require human supervision and control. Based on this, we propose a collaborative human--machine method for resolving unplanned events using two phases: task filtering and task scheduling. In the task filtering phase, we propose a human--machine collaborative decision-making algorithm for dynamic tasks. The GACRNN model is used to predict the state of the job nodes, locate the key nodes, and generate a machine-predicted resolution task list. A human decision-maker supervises the list in real time and modifies and confirms the machine-predicted list through the human--machine interface. In the task scheduling phase, we propose a scheduling algorithm that integrates human experience constraints. The steps to resolve an event are inserted into the normal job sequence to schedule the resolution. We propose several human--machine collaboration methods in each phase to generate steps to resolve an unplanned event while minimizing the impact on the original job plan.
Search-Based Regular Expression Inference on a GPU
May 29, 2023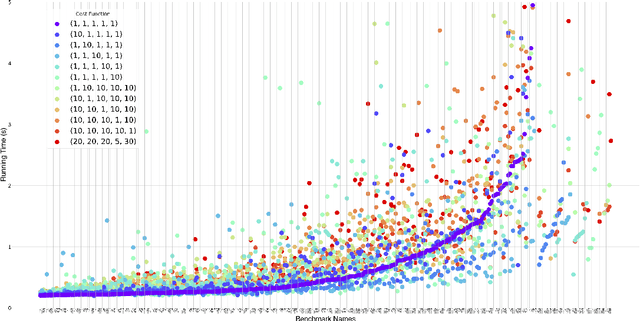
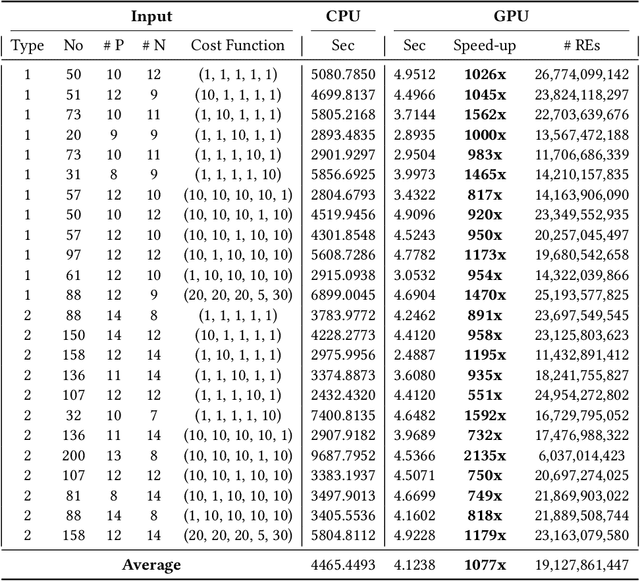
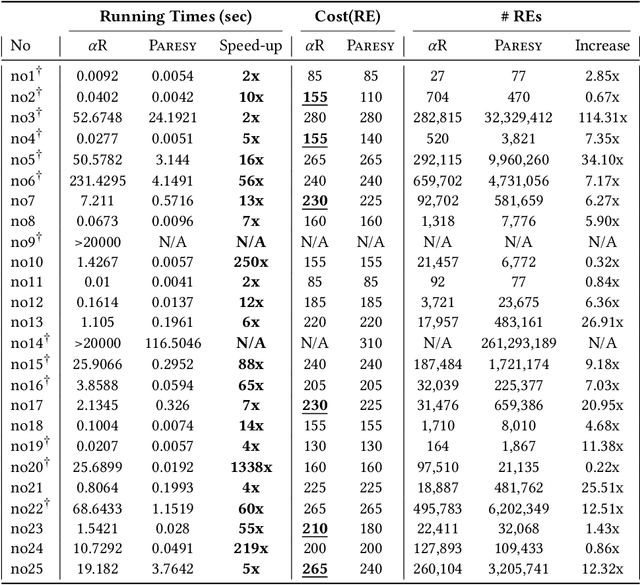
Regular expression inference (REI) is a supervised machine learning and program synthesis problem that takes a cost metric for regular expressions, and positive and negative examples of strings as input. It outputs a regular expression that is precise (i.e., accepts all positive and rejects all negative examples), and minimal w.r.t. to the cost metric. We present a novel algorithm for REI over arbitrary alphabets that is enumerative and trades off time for space. Our main algorithmic idea is to implement the search space of regular expressions succinctly as a contiguous matrix of bitvectors. Collectively, the bitvectors represent, as characteristic sequences, all sub-languages of the infix-closure of the union of positive and negative examples. Mathematically, this is a semiring of (a variant of) formal power series. Infix-closure enables bottom-up compositional construction of larger from smaller regular expressions using the operations of our semiring. This minimises data movement and data-dependent branching, hence maximises data-parallelism. In addition, the infix-closure remains unchanged during the search, hence search can be staged: first pre-compute various expensive operations, and then run the compute intensive search process. We provide two C++ implementations, one for general purpose CPUs and one for Nvidia GPUs (using CUDA). We benchmark both on Google Colab Pro: the GPU implementation is on average over 1000x faster than the CPU implementation on the hardest benchmarks.
RAPHAEL: Text-to-Image Generation via Large Mixture of Diffusion Paths
May 29, 2023

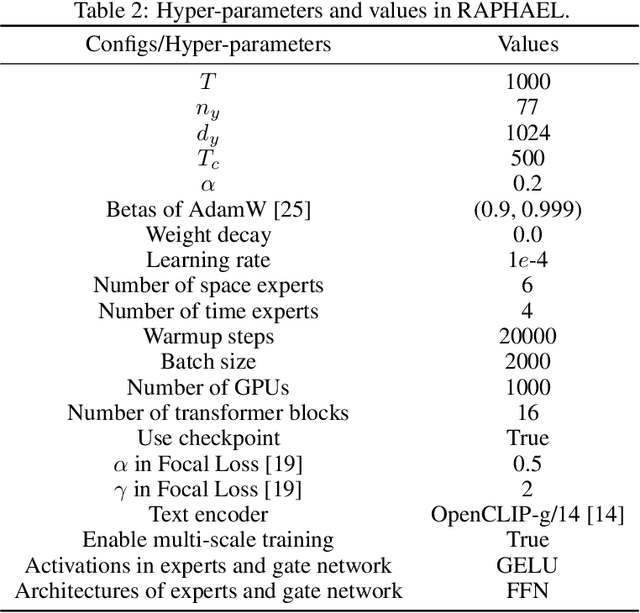
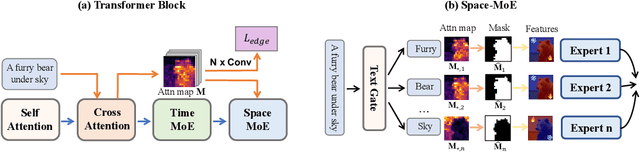
Text-to-image generation has recently witnessed remarkable achievements. We introduce a text-conditional image diffusion model, termed RAPHAEL, to generate highly artistic images, which accurately portray the text prompts, encompassing multiple nouns, adjectives, and verbs. This is achieved by stacking tens of mixture-of-experts (MoEs) layers, i.e., space-MoE and time-MoE layers, enabling billions of diffusion paths (routes) from the network input to the output. Each path intuitively functions as a "painter" for depicting a particular textual concept onto a specified image region at a diffusion timestep. Comprehensive experiments reveal that RAPHAEL outperforms recent cutting-edge models, such as Stable Diffusion, ERNIE-ViLG 2.0, DeepFloyd, and DALL-E 2, in terms of both image quality and aesthetic appeal. Firstly, RAPHAEL exhibits superior performance in switching images across diverse styles, such as Japanese comics, realism, cyberpunk, and ink illustration. Secondly, a single model with three billion parameters, trained on 1,000 A100 GPUs for two months, achieves a state-of-the-art zero-shot FID score of 6.61 on the COCO dataset. Furthermore, RAPHAEL significantly surpasses its counterparts in human evaluation on the ViLG-300 benchmark. We believe that RAPHAEL holds the potential to propel the frontiers of image generation research in both academia and industry, paving the way for future breakthroughs in this rapidly evolving field. More details can be found on a project webpage: https://raphael-painter.github.io/.